Course Materials Book
This book is the home of the majority of materials used within the Core Developer Track of the Polkadot Blockchain Academy.
Read the Book
We suggest the online version for general use, but cloning, installing, and building this book offline is a great option on-the-go.
Hosted Online
The latest version is hosted at: https://polkadot-blockchain-academy.github.io/pba-book/
Build Offline
The Core Developer Track of the Academy is Rust heavy and as such, you need to install rust before you can continue.
In order to make your life easy 😉, there is a set of tasks that use cargo make.
With cargo make installed, you can list all tasks included to facilitate further installation, building, serving, formatting, and more with:
# Run from the top-level working dir of this repo
makers --list-all-steps
The tasks should be self-explanatory, if they are not - please file an issue to help us make them better.
License and Use Policies
All materials found within this repository are licensed under Mozilla Public License Version 2.0 - See the License for details.
In addition to the license, we ask you read and respect the Academy's Code of Conduct and help us foster a healthy and scholarly community of high academic integrity.
Learn more about and apply for the next Academy today!
🪄 Using this Book
This book contains all the Academy's content in sequence.
It is intended to read from start to finish, in order, and following the index.md page for each module.
📔 How to use mdBook
This book is made with mdBook - a Rust native documentation tool. Please give the official docs there a read to see what nice features are included. To name a few key items:
| Icon | Description |
|---|---|
| Opens and closes the chapter listing sidebar. | |
| Opens a picker to choose a different color theme. | |
| Opens a search bar for searching within the book. | |
| Instructs the web browser to print the entire book. | |
| Opens a link to the website that hosts the source code of the book. | |
| Opens a page to directly edit the source of the page you are currently reading. |
Search
Pressing the search icon () in the menu bar, or pressing the S key on the keyboard will open an input box for entering search terms.
Typing some terms will show matching chapters and sections in real time.
Clicking any of the results will jump to that section. The up and down arrow keys can be used to navigate the results, and enter will open the highlighted section.
After loading a search result, the matching search terms will be highlighted in the text.
Clicking a highlighted word or pressing the Esc key will remove the highlighting.
🎞️ How-to use reveal.js Slides
Most pages include embedded slides that have a lot of handy features.
These are with reveal-md: a tool built with reveal.js to allow for Markdown only slides, with a few extra syntax items to make your slides look and feel awesome with very little effort.
📝 Be use to have the slides
iframeon a page active (🖱️ click on it) to use slide keybindings... Otherwise those are captured by themdbooktools! (sis search for the book, and speaker notes for the slides)
Be a power user of these by using the keybindings to interact with them:
- Use
spaceto navigate all slides: top to bottom, left to right.- Use
down/uparrow keys to navigate vertical slides. - Use
left/rightarrow keys to navigate horizontal slides.
- Use
- Press
Escoroto see anoverviewview that arrow keys can navigate. - Press
sto open up speaker view.
👀 Speaker notes include very important information, not to be missed!
💫 Slides Demo
Tryout those keybindings (🖱️ click on the slides to start) below:
(🖱️ expand) Raw Markdown of Slides Content
--- title: How-to use Reveal.js Slides description: How to use reveal.js duration: 5 minuets ---How-to use Reveal.js Slides
These slides are built with reveal.js.
These slides serve as a feature demo of reveal for you! 🎉
What are we going to see:
-
How to use Reveal.js Features
- Useful
reveal.jstips - Speaker Notes
- Useful
How to use Reveal.js Features
Press the down/up keys to navigate _vertical slides_
Try doing down a slide.
---v
Use the keybindings!
-
Overview mode: “O” to see a birds-eye view of your presentation, “ESC” to return to the highlighted slide (you can quickly navigate with arrows)
-
Full-screen: “F”, “ESC” to exit full-screen mode
-
Speaker mode: “S” it synchronizes 2 windows: one with the presentation, and another with a timer and all speaker notes!
-
Zoom-in: ALT+click make the view zoom at the position of your mouse’s pointer; very useful to look closely at a picture or chart surrounded by too much bullet points.
---v
Speaker Notes & Viewer
Press the s key to bring up a popup window with speaker view
You need to unblock popups to have the window open
Notes:
This is a note just for you. Set under a line in your slide starting with "Note:" all
subsequent lines are just seen in speaker view.
Enjoy!
😎
☝️ All slides Slides Content is available on all pages.
This enables search to work throughout this book to jump-to-location for any keywords you remember related to something covered in a lesson 🚀.
📖 Learn More
📒 Book Overview
This book contains a set of course materials covering both the conceptual underpinnings and hands-on experience in developing blockchain and web3 technologies. Students will be introduced to core concepts in economic, cryptographic, and computer science fields that lay the foundation for approaching web3 development, as well as hands-on experience developing web3 systems in Rust, primarily utilizing the ecosystem of tooling provided by Polkadot and Substrate.
🙋 This book is designed specifically for use in an in-person course. This provides far more value from these materials than an online only, self-guided experience could provide.
✅ The Academy encourages everyone to apply to the program Our program is facilitated a few times a year at prestigious places around the world, with on the order of ~50-100 students per cohort.
👨🎓 Learning Outcomes
By the end of the Polkadot Blockchain Academy, students will be able to:
- Apply economic, cryptographic, and computer science concepts to web3 application design
- Robustly design and evaluate security of web3, both at the protocol and user application level
- Write a smart contract using one of a number of languages and deploy it to a blockchain
- Implement a Substrate based blockchain
- Deploy a parachain utilizing Substrate, Cumulus, and Polkadot
- Employ FRAME to accelerate blockchain and parachain development
- Configure XCM for cross-consensus messaging between parachains
🖋️ Nomenclature
The academy uses explicit terms to describe materials use within as content categories defined here:
- Lesson: a segment of content (1-2 hours) that is one of:
- Lecture: An oral presentation that consists primarily of slide based content.
Most content in this book is of this type.
- Exercise: a short (5-10 minutes) exercise for to be completed during a lecture (code snippets, mini-demos, etc.).
- Workshop: these are step-by-step, longer (0.5-3 hours) guided in-class material (live-coding, competitions, games, etc.). Workshops are instructor lead, and hand-held to get everyone to the same result.
- Activity: these are self-directed activities for individuals and/or small groups. Activities are not guided or "hand-held" by the instructor like workshops are.
- Lecture: An oral presentation that consists primarily of slide based content.
Most content in this book is of this type.
- Assignment: a graded piece of work, typically one per week is assigned.
- Assignments are not public - these are only accessible by Academy Faculty, Staff, and (in a derivative form) Students.
🪜 Course Sequence
The course is segmented into modules, with the granular lessons intended to be completed in the sequence provided in the left-side navigation bar.
| Module | Topic |
|---|---|
| 🔐 Cryptography | Applied cryptography concepts and introduction to many common tools of the trade for web3 builders. |
| 🪙 Economics and Game Theory | Applied economics and game theory fundamental to the architecture and operation of web3 applications. |
| ⛓️ Blockchains and Smart Contracts | Blockchain and applications built on them covered in depth conceptually and hands-on operation and construction. |
| 🧬 Substrate | The blockchain framework canonical to Polkadot and Parachains covered in depth, at a lower level. |
| 🧱 FRAME | The primary Substrate runtime framework used for parachain development. |
| 🟣 Polkadot | The Polkadot blockchain covered in depth, focus on high-level design and practically how to utilize its blockspace. |
| 💱 XCM | The cross consensus messaging format covered from first principals to use in protocols. |
The lessons include materials used, with links and instructions to required external materials as needed.1
Notably, the graded assignments for the Academy and some solutions to public activities and exercises remain closed source, and links are intentionally left out of this book. These materials may be shared as needed with students in person during the Academy.
🔐 Cryptography
“Cryptography rearranges power: it configures who can do what, from what”
Phillip Rogaway, The Moral Character of Cryptographic Work
Applied cryptography concepts and introduction to many common tools of the trade for web3 builders.
Introduction to Cryptography
How to use the slides - Full screen (new tab)
Introduction to Cryptography
Some Useful Equations
Notes:
Just kidding!
Goals for this lesson
- Understand the goals of cryptography
- Understand some network and contextual assumptions
- Learn what expectations cryptography upholds
- Learn the primitives
Notes:
In this first lesson,
Cryptography Landscape

Notes:
What is covered in this course is all connected subjects. We will not cover any details for hybrid or interactive protocols in the course.
Operating Context
The internet is a public space.
We communicate over public channels. Adversaries may want to:
- Read messages not intended for them
- Impersonate others
- Tamper with messages
Notes:
Use e-mail as an example of an flawed system.
Some examples include:
- An attacker may impersonate your boss, trying to get you to send them money
- An attacker may change a message sent over a network, e.g. an instruction to transfer 100 EUR to 10000 EUR
Probably best for the teacher to ask students to participate with examples of application messages, not just person-to-person messages.
Operating Context
Resources are constrained.
- Network, storage, computation, etc.: We don't want to send, store, or operate on the same data, but we want guarantees about it, e.g. that we agree on a message's contents.
- Privacy: We must assume that all channels can be monitored, and thus closed channels are heavily constrained (i.e. assumed to not exist).
Open vs. Closed Channels
Cryptography based on public systems is more sound.
Kerckhoff's Principle: Security should not rely on secret methods,
but rather on secret information.
Notes:
There is no such thing as a "closed channel" :)
- Methods can be reverse engineered. After that, the communication channel is completely insecure. For example, CSS protection for DVDs.
- We always work with public, open protocols.
Cryptographic Guarantees*
- Data confidentiality
- Data authenticity
- Data integrity
- Non-repudiation
Notes:
Cryptography is one of the (most important) tools we have to build tools that are guaranteed to work correctly. This is regardless of who (human, machine, or otherwise) is using them and their intentions (good or bad).
Why an asterisk? There generally are no perfect & absolute guarantees here, but for most practical purposes the bounds on where these fail are good enough to serve our needs as engineers and users. Do note the assumptions and monitor their validity over time (like quantum tech).
Important Non-Guarantee
- Data availability
Cryptography alone cannot make strong guarantees that data is available to people when they want to access it.
Notes:
There are many schemes to get around this, and this topic will come up later in the course. We will touch on erasure coding, which makes data availability more efficient.
Data Confidentiality
A party may gain access to information
if and only if they know some secret (a key).
Confidentiality ensures that a third party cannot read my confidential data.
Notes:
The ability to decrypt some data and reveal its underlying information directly implies knowledge of some secret, potentially unknown to the originator of the information. Supplying the original information (aka plain text message) can be used in a "challenge game" mechanism as one means of proving knowledge of the secret without compromising it.
Mention use of the term "plaintext".
Allegory: A private document stored on server where sysadmin has access can be subpoenaed, violating assumed Attorney-Client Privilege on the document.
---v
Confidentiality in Communication Channels
Suppose Alice and Bob are sending confidential messages back and forth. There are some subtypes of confidentiality here:
- Forward Secrecy: Even if an adversary temporarily learns Alice's secret, it cannot read future messages after some point.
- Backwards Secrecy: Even if an adversary temporarily learns Alice's secret, it cannot read past messages beyond some previous point.
Data Authenticity
Users can have the credible expectation that the stated origin of a message is authentic.
Authenticity ensures that a third party cannot pretend I created some data.
Notes:
- Digital signatures should be difficult (practically speaking: impossible) to forge.
- Digital signatures should verify that the signer knows some secret, without revealing the secret itself.
Data Integrity
If data is tampered with, it is detectable. In other words, it possible to check if the current state of some data is the consistent with when it was created.
Integrity ensures that if data I create is corrupted, it can be detected.
---v
Physical Signatures
Physical signatures provide weak authenticity guarantees
(i.e. they are quite easy to forge), and no integrity guarantees.
---v
An Ideal Signature
Notes:
For example, if you change the year on your university diploma, the dean's signature is still valid. Digital signatures provide a guarantee that the signed information has not been tampered with.
Non-repudiation
The sender of a message cannot deny that they sent it.
Non-repudiation ensures if Bob sends me some data, I can prove to a third party that they sent it.
One-Way Functions
One-way functions form the basis of both
(cryptographic) hashing and asymmetric cryptography. A function $f$ is one way if:
- it is reasonably fast to compute
- it is very, very slow to undo
Notes:
There are a lot of assumptions about why these functions are hard to invert, but we cannot rigorously prove it. We often express inversion problems in terms of mathematical games or oracles.
Hash Functions
Motivation: We often want a succinct, yet unique representation of some (potentially large) data.
A fingerprint, which is much smaller than a person, yet uniquely identifies an individual.
Notes:
The following slides serve as an intro. Many terms may be glossed over, and covered in detail later. There are lessons later in this module dedicated to hashes and hash-based data structures.
---v
Hash Function Applications
Hashes can be useful for many applications:
- Representation of larger data object
(history, commitment, file) - Keys in a database
- Digital signatures
- Key derivation
- Pseudorandom functions
Symmetric Cryptography
Symmetric encryption assumes all parties begin with some shared secret information, a potentially very difficult requirement.
The shared secret can then be used to protect further communications from others who do not know this secret.
In essence, it gives a way of extending a shared secret over time.
Notes:
Remember that these communications are over an open channel, as we assumed that all channels can be monitored.
Symmetric Encryption
For example, the Enigma cipher in WW2. A channel was initiated by sharing a secret ("key") between two participants. Using the cipher, those participants could then exchange information securely.
However, since the key contained only limited entropy ("information"), enough usage of it eventually compromised the secret and allowed the allies to decode messages. Even altering it once per day was not enough.
Notes:
When communicating over a channel that is protected with only a certain amount of entropy, it is still possible to extend messages basically indefinitely by introducing new entropy that is used to protect the channel sufficiently often.
Asymmetric Cryptography
-
In asymmetric cryptography, we devise a means to transform one value (the "secret") into some corresponding counterpart (the "public" key), preserving certain properties.
-
We believe that this is a one-way function (that there is no easy/fast inverse of this function).
-
Aside from preserving certain properties, we believe this counterpart (the "public key") reveals no information about the secret.
Asymmetric Encryption
Using only the public key, information can be transformed ("encrypted") such that only those with knowledge of the secret are able to inverse and regain the original information.
Digital Signatures
-
Using the secret key, information can be transformed ("signed") such that anyone with knowledge of the information and the counterpart public key is able to affirm the operation.
-
Digital signatures provide message authenticity and integrity guarantees.
-
There are two lessons are dedicated to digital signatures,
this is strictly an intro.
Digital Signatures
Signing function: a function which operates on some
message data and some secret to yield a signature.
A signature proves that the signer had knowledge of the secret,
without revealing the secret itself.
The signature cannot be used to create other signatures, and is unique to the message.
Notes:
A signing function is a pure function which operates on some message data (which may or may not be small, depending on the function) and some secret (a small piece of information known only to the operator). The result of this function is a small piece of data called a signature.
Pure means that it has no side effects.
It has a special property: it proves (beyond reasonable doubt) that the signer (i.e. operator of the signing function) had knowledge of the secret and utilized this knowledge with the specific message data, yet it does not reveal the secret itself, nor can knowledge of the signature be used to create other signatures (e.g. for alternative message data).
Non-repudiation for Crypgraphic Signatures
There is cryptographic proof that the secret was known to the producer of the signature.
The signer cannot claim that the signature was forged, unless they can defend a claim that the secret was compromised prior to signing.
Practical Considerations
Symmetric cryptography is much faster, but requires more setup (key establishment) and trust (someone else knows the secret).
Asymmetric cryptography is slow, but typically preserves specific algebraic relationships, which then permit more diverse if fragile protocols.
Hybrid Cryptography
Hybrid cryptography composes new mechanisms from different cryptographic primitives.
For example:
- Symmetric encryption can provide speed, and often confidentiality,
- Hash functions can reduce the size of data while preserving identity,
- Asymmetric cryptography can dictate relations among the participants.
Certifications
Certifications are used to make attestations about public key relationships.
Typically in the form of a signature on:
- One or more cryptographically strong identifiers (e.g. public keys, hashes).
- Information about its ownership, its use and any other properties that the signer is capable of attesting/authorizing/witnessing.
- (Meta-)information about this information itself, such as how long it is valid for and external considerations which would invalidate it.
Notes:
- Real application is the hierarchy of SSL certs.
- Root keys -> State level entities -> Smaller entities.
- Web of Trust & GPG cross-signing
- In the case of signature-based certificates, as long as you have the signature, data, and originating public key, you can trust a certificate no matter where it came from. It could be posted on a public message board, sent to you privately, or etched into stone.
Entropy, Randomness, and Key Size
- Entropy: Amount of non-redundant information contained within some data.
- Randomness: Unpredictability of some information. Less random implies lower entropy.
- Key size: Upper limit of possible entropy contained in a key. Keys with less random (more predictable) data have less entropy than this upper bound.
- One-time pad: A key of effectively infinite size. If it is perfectly random (i.e. has maximal entropy), then the cipher is theoretically unbreakable.
Notes:
Mention the upcoming "many time pad" activity, that exploits using a one time pad multiple times.
Randomness Generation
#![allow(unused)] fn main() { fn roll_die() -> u32 { // Guaranteed random: it was achieved through a real-life die-roll. 4u32 } }
- Pseudo-random sequences
- Physical data collection (e.g. cursor movement, LSB of microphone)
- Specialised hardware (e.g. low-level noise on silicon gates, quantum-amplifiers)
Notes:
LSB := Least Significant Bit
Summary
Cryptography is much more than encryption.
- Communicate on public networks, in the open
- Access information
- Have expectations about a message's authenticity and integrity
- Prove knowledge of some secret information
- Represent large amounts of data succinctly
Questions
What insights did you gain?
Notes:
Addresses and Keys
How to use the slides - Full screen (new tab)
Addresses and Keys
Outline
- Binary Formats
- Seed Creation
- Hierarchical Deterministic Key Derivation
Binary Display Formats
When representing binary data, there are a few different display formats you should be familiar with.
Hex: 0-9, a-f
Base64: A-Z, a-z, 0-9, +, /
Base58: Base64 without 0/O, I/l, +, and /
Notes:
Be very clear that this is a display format that we use to transmit binary data through text. The same data can be encoded with any of these formats, it's just important to know which one you're using to decode. Data is not typically stored in these formats unless it has to be transmitted through text.
Binary Display Formats Example
Every hex character is 4 bits. Every base64 character is 6 bits. base58 characters are usually about 6 bits.
binary: 10011111 00001010 10011110 10011000 01001100 11010011 10110010 00000101
hex: 9 f 0 a 9 e 9 8 4 c d 3 b 2 0 5
base64: n w q e m E z T s g U=
base58: T b u H z e 3 c t k c
hex: 9f0a9e984cd3b205
base64: nwqemEzTsgU=
base58: TbuHze3ctkc
Notes:
It turns out that converting from hex/base64 to base58 can in theory take n^2 time!
Mnemonics and Seed Creation
Notes:
These are all different representation of a secret. Fundamentally doesn't really change anything.
Seeds are secrets
Recall, both symmetric and asymmetric cryptography require a secret.
Mnemonics
Many wallets use a dictionary of words and give people phrases,
often 12 or 24 words, as these are easier to back up/recover than byte arrays.
Notes:
High entropy needed. People are bad at being random. Some people create their own phrases... this is usually stupid.
Dictionaries
There are some standard dictionaries to define which words (and character sets) are included in the generation of a phrase. Substrate uses the dictionary from BIP39.
| No. | word |
|---|---|
| 1 | abandon |
| 2 | ability |
| 3 | able |
| 4 | about |
| 5 | above |
The first 5 words of the BIP39 English dictionary
Mnemonic to Secret Key
Of course, the secret key is a point on an elliptic curve, not a phrase.
BIP39 applies 2,048 rounds of the SHA-512 hash function
to the mnemonic to derive a 64 byte key.
Substrate uses the entropy byte array from the mnemonic.
Portability
Different key derivation functions affect the ability to use the same mnemonic in multiple wallets as different wallets may use different functions to derive the secret from the mnemonic.
Cryptography Types
Generally, you will encounter 3 different modern types of cryptography across most systems you use.
- Ed25519
- Sr25519
- ECDSA
We will go more in depth in future lectures!
Notes:
You may have learned RSA in school. It is outdated now, and requires huge keys.
What is an address?
An address is a representation of a public key, potentially with additional contextual information.
Notes:
Having an address for a symmetric cryptography doesn't actually make any sense, because there is no public information about a symmetric key.
Address Formats
Addresses often include a checksum so that a typo cannot change one valid address to another.
Valid address: 5GEkFD1WxzmfasT7yMUERDprkEueFEDrSojE3ajwxXvfYYaF
Invalid address: 5GEkFD1WxzmfasT7yMUERDprk3ueFEDrSojE3ajwxXvfYYaF
^
E changed to 3
Notes:
It hasn't been covered yet, but some addresses even go extra fancy and include an error correcting code in the address.
SS58 Address Format
SS58 is the format used in Substrate.
It is base58 encoded, and includes a checksum and some context information. Almost always, it is 2 bytes of context and 2 bytes of checksum.
base58Encode( context | public key | checksum )
Notes:
| here stands for concatenation.
For ECDSA, the public key is 33 bytes, so we use the hash of it in place of the public key.
There are a lot more variants here, but this is by far the most common one.
HDKD
Hierarchical Deterministic Key Derivation
Hard vs. Soft
Key derivation allows one to derive (virtually limitless)
child keys from one "parent".
Derivations can either be "hard" or "soft".
Hard vs. Soft
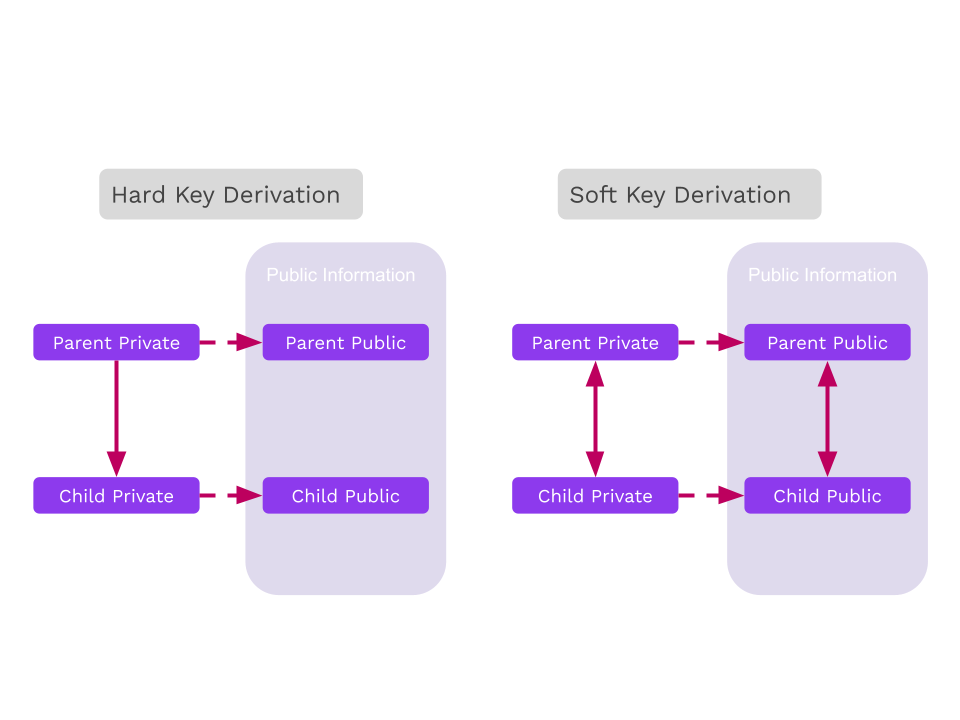
Hard Derivation
Hard derivation requires the secret key and derives new child secret keys.
Typical "operational security" usages should favor hard derivation over soft derivation because hard derivations avoid leaking the sibling keys, unless the original secret is compromised.
Always do hard paths first, then conclude in soft paths.
Hard Derivation in Wallets
Wallets can derive keys for use in different consensus systems while only needing to back up one secret plus a pattern for child derivation.
Hard Derivation in Wallets
Let's imagine we want to use this key on multiple networks, but we don't want the public keys to be connected to each other.
Subkey Demo
Hard Derivation
Notes:
Hard keys: Take a path (data like a name/index), concatenate with the original key, and hash it for a new key. They reveal nothing about keys above them, and only with the path between it and children could they be recovered.
Soft Derivation
Soft derivation allows one to create derived addresses from only the public key. Contrary to hard derivation, all keys are related.
Notes:
- With any key and the paths to children and. or parents, the public and private keys can be recovered.
- Soft derivations can break some niche advanced protocols, but our sr25519 crate avoids supporting protocols that conflict with soft derivations.
Soft Derivation
- Note that these generate new addresses, but use the same secret seed.
- We can also use the same paths, but only using the Account ID from
//polkadot. It generates the same addresses!
Soft Derivation in Wallets
Wallets can use soft derivation to link all payments controlled by a single private key, without the need to expose the private key for the address derivation.
Use case: A business wants to generate a new address for each payment, but should be able to automatically give customers an address without the secret key owner deriving a new child.
Notes:
On the use case, taking each payment at a different address could help make the association between payment and customer.
See: https://wiki.polkadot.network/docs/learn-accounts#soft-vs-hard-derivation
Subkey Demo
Soft Derivation
Notes:
See the Jupyter notebook and/or HackMD cheat sheet for this lesson.
Mention that these derivations create entirely new secret seeds.
Questions
Subkey Signature and HDKD (Hierarchical Deterministic Key Derivation) Demo
Here are subkey examples for reference on use. Compliments the formal documentation found here.
Key Generation
subkey generate
Secret phrase: desert piano add owner tuition tail melt rally height faint thunder immune
Network ID: substrate
Secret seed: 0x6a0ea68072cfd0ffbabb40801570fa5e9f3a88966eaed9dedaeb0cf140b9cd8d
Public key (hex): 0x7acdc47530002fbc50f413859093b7df90c27874aee732dca940ea4842751d58
Account ID: 0x7acdc47530002fbc50f413859093b7df90c27874aee732dca940ea4842751d58
Public key (SS58): 5Eqipnpt5asTm7sCFWQeJjsNJX5cYVJMid3zjKHjDUGKBJTo
SS58 Address: 5Eqipnpt5asTm7sCFWQeJjsNJX5cYVJMid3zjKHjDUGKBJTo
Sign
echo -n 'Hello Polkadot Blockchain Academy' | subkey sign --suri 'desert piano add owner tuition tail melt rally height faint thunder immune'
Note, this changes each execution, this is one viable signature:
f261d56b80e4b53c70dd2ba1de6b9384d85a8f4c6d912fd86acab3439a47992aa85ded04ac55c7525082dcbc815001cd5cc94ec1a907bbd8e3138cfc8a382683
Verify
echo -n 'Hello Polkadot Blockchain Academy' | subkey verify '0xf261d56b80e4b53c70dd2ba1de6b9384d85a8f4c6d912fd86acab3439a47992aa85ded04ac55c7525082dcbc815001cd5cc94ec1a907bbd8e3138cfc8a382683' \
'0x7acdc47530002fbc50f413859093b7df90c27874aee732dca940ea4842751d58'
Expect
Signature verifies correctly.
Tamper with the Message
Last char in
Public key (hex)- AKA URI - is changed:
echo -n 'Hello Polkadot Blockchain Academy' | subkey verify \
'0xf261d56b80e4b53c70dd2ba1de6b9384d85a8f4c6d912fd86acab3439a47992aa85ded04ac55c7525082dcbc815001cd5cc94ec1a907bbd8e3138cfc8a382683' \
'0x7acdc47530002fbc50f413859093b7df90c27874aee732dca940ea4842751d59'
Error: SignatureInvalid
Hard Derivation
subkey inspect 'desert piano add owner tuition tail melt rally height faint thunder immune//polkadot' --network polkadot
Secret Key URI `desert piano add owner tuition tail melt rally height faint thunder immune//polkadot` is account:
Network ID: polkadot
Secret seed: 0x3d764056127d0c1b4934725cb9faecf00ed0996daa84d24a903b906f319e06bf
Public key (hex): 0xce6ccb0af417ade10062ac9b553d506b67d16c61cd2b6ce85330bc023db7e906
Account ID: 0xce6ccb0af417ade10062ac9b553d506b67d16c61cd2b6ce85330bc023db7e906
Public key (SS58): 15ffBb8rhETizk36yaevSKM2MCnHyuQ8Dn3HfwQFtLMhy9io
SS58 Address: 15ffBb8rhETizk36yaevSKM2MCnHyuQ8Dn3HfwQFtLMhy9io
subkey inspect 'desert piano add owner tuition tail melt rally height faint thunder immune//kusama' --network kusama
Secret Key URI `desert piano add owner tuition tail melt rally height faint thunder immune//kusama` is account:
Network ID: kusama
Secret seed: 0xabd92064a63df86174acfd29ab3204897974f0a39f5d61efdd30099aa5f90bd9
Public key (hex): 0xf62e5d444f89e704bb9b412adc472f990e9a9f40725ac6ff3abee1c9b7625a63
Account ID: 0xf62e5d444f89e704bb9b412adc472f990e9a9f40725ac6ff3abee1c9b7625a63
Public key (SS58): J9753RnTdZJct5RmFQ6gFVdKSyrEjzYwvYUBufMX33PB7az
SS58 Address: J9753RnTdZJct5RmFQ6gFVdKSyrEjzYwvYUBufMX33PB7az
Soft Derivation from Secret
subkey inspect 'desert piano add owner tuition tail melt rally height faint thunder immune//polkadot/0' --network polkadot
Secret Key URI `desert piano add owner tuition tail melt rally height faint thunder immune//polkadot/0` is account:
Network ID: polkadot
Secret seed: n/a
Public key (hex): 0x4e8dfdd8a386ae37b8731dba5480d5cc65739023ea24f1a09d88be1bd9dff86b
Account ID: 0x4e8dfdd8a386ae37b8731dba5480d5cc65739023ea24f1a09d88be1bd9dff86b
Public key (SS58): 12mzv68gS8Zu2iEdt4Ktkt48JZSKyFSkAVjvtgYhoa42NLNa
SS58 Address: 12mzv68gS8Zu2iEdt4Ktkt48JZSKyFSkAVjvtgYhoa42NLNa
subkey inspect 'desert piano add owner tuition tail melt rally height faint thunder immune//polkadot/1' --network polkadot
Secret Key URI `desert piano add owner tuition tail melt rally height faint thunder immune//polkadot/1` is account:
Network ID: polkadot
Secret seed: n/a
Public key (hex): 0x2e8b3090b17b12ea63029f03d852af71570e8e526690cc271491318a45785e33
Account ID: 0x2e8b3090b17b12ea63029f03d852af71570e8e526690cc271491318a45785e33
Public key (SS58): 1242YwUZGBQ84btGSGdSX4swf1ibfSaCDR1sr1ejC9KQ1NbJ
SS58 Address: 1242YwUZGBQ84btGSGdSX4swf1ibfSaCDR1sr1ejC9KQ1NbJ
Soft Derivation from Public
Note: We use addresses here because Subkey does not derive paths from a raw public key (AFAIK).
subkey inspect 12mzv68gS8Zu2iEdt4Ktkt48JZSKyFSkAVjvtgYhoa42NLNa/0
Public Key URI `12mzv68gS8Zu2iEdt4Ktkt48JZSKyFSkAVjvtgYhoa42NLNa/0` is account:
Network ID/Version: polkadot
Public key (hex): 0x40f22875159420aca51178d1baf2912c18dcb83737dd7bd39dc6743da326dd1c
Account ID: 0x40f22875159420aca51178d1baf2912c18dcb83737dd7bd39dc6743da326dd1c
Public key (SS58): 12UA12xuDnEkEsEDrR4T4Cf3S1Hyi2C7B6hJW8LTkcsZy8BX
SS58 Address: 12UA12xuDnEkEsEDrR4T4Cf3S1Hyi2C7B6hJW8LTkcsZy8BX
subkey inspect 12mzv68gS8Zu2iEdt4Ktkt48JZSKyFSkAVjvtgYhoa42NLNa/1
Public Key URI `12mzv68gS8Zu2iEdt4Ktkt48JZSKyFSkAVjvtgYhoa42NLNa/1` is account:
Network ID/Version: polkadot
Public key (hex): 0xc62ec5cd7d83e1f41462d455bb47b6bad9ed5a14741a920ead8366c63746391b
Account ID: 0xc62ec5cd7d83e1f41462d455bb47b6bad9ed5a14741a920ead8366c63746391b
Public key (SS58): 15UrNnNSMpX49F3mWcCX7y4kMGcvnQxCabLMT3d8U5abpwr3
SS58 Address: 15UrNnNSMpX49F3mWcCX7y4kMGcvnQxCabLMT3d8U5abpwr3
Hash Functions
How to use the slides - Full screen (new tab)
Hash Functions
Introduction
We often want a succinct representation of some data
with the expectation that we are referring to the same data.
A "fingerprint"
Hash Function Properties
- Accept unbounded size input
- Map to a bounded output
- Be fast to compute
- Be computable strictly one-way
(difficult to find a pre-image for a hash) - Resist pre-image attacks
(attacker controls one input) - Resist collisions
(attacker controls both inputs)
Hash Function API
A hash function should:
- Accept an unbounded input size (
[u8]byte array) - Return a fixed-length output (here, a 32 byte array).
#![allow(unused)] fn main() { fn hash(s: &[u8]) -> [u8; 32]; }
Example
Short input (5 bytes):
hash('hello') =
0x1c8aff950685c2ed4bc3174f3472287b56d9517b9c948127319a09a7a36deac8
Large input (1.2 MB):
hash(Harry_Potter_series_as_string) =
0xc4d194054f03dc7155ccb080f1e6d8519d9d6a83e916960de973c93231aca8f4
Input Sensitivity
Changing even 1 bit of a hash function completely scrambles the output.
hash('hello') =
0x1c8aff950685c2ed4bc3174f3472287b56d9517b9c948127319a09a7a36deac8
hash('hellp') =
0x7bc9c272894216442e0ad9df694c50b6a0e12f6f4b3d9267904239c63a7a0807
Rust Demo
Hashing a Message
Notes:
See the Jupyter notebook and/or HackMD cheat sheet for this lesson.
- Use a longer message
- Hash it
- Verify the signature on the hash
Speed
Some hash functions are designed to be slow.
These have applications like password hashing, which would slow down brute-force attackers.
For our purposes, we generally want them to be fast.
Famous Hash Algorithms
- xxHash a.k.a TwoX (non-cryptographic)
- MD5
- SHA1
- RIPEMD-160
- SHA2-256 (aka SHA256) &c.
- SHA3
- Keccak
- Blake2
xxHash64 is about 20x faster than Blake2.
Hash Functions in Blockchains
- Bitcoin: SHA2-256 & RIPMD-160
- Ethereum: Keccak-256 (though others supported via EVM)
- Polkadot: Blake2 & xxHash (though others supported via host functions)
Notes:
Substrate also implements traits that provide 160, 256, and 512 bit outputs for each hasher.
Exercise: Write your own benchmarking script that compares the performance of these algorithms with various input sizes.
Hashing Benchmarks
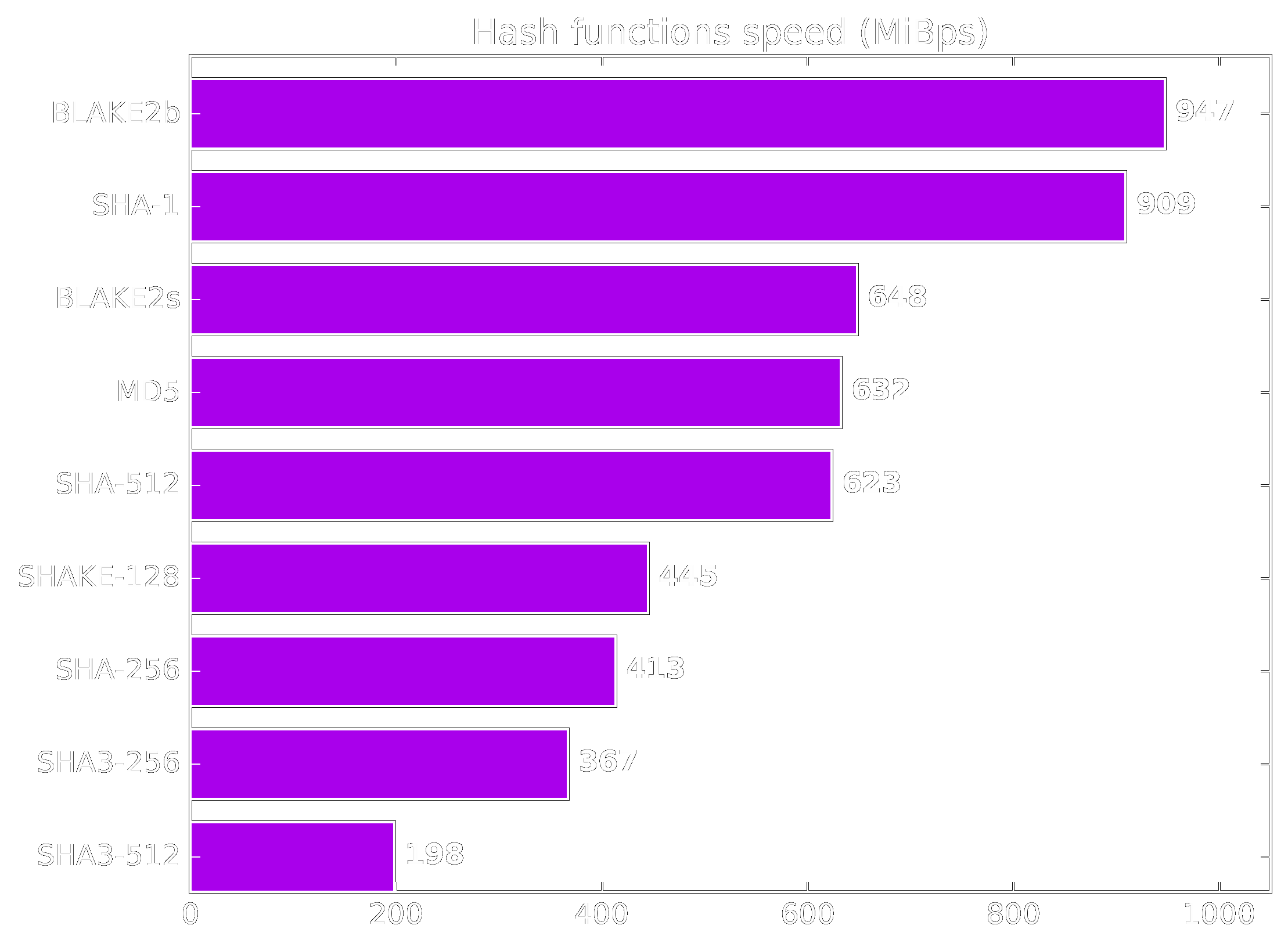
Notes:
Benchmarks for the cryptographic hashing algorithms. Source: https://www.blake2.net/
XXHash - Fast hashing algorithm
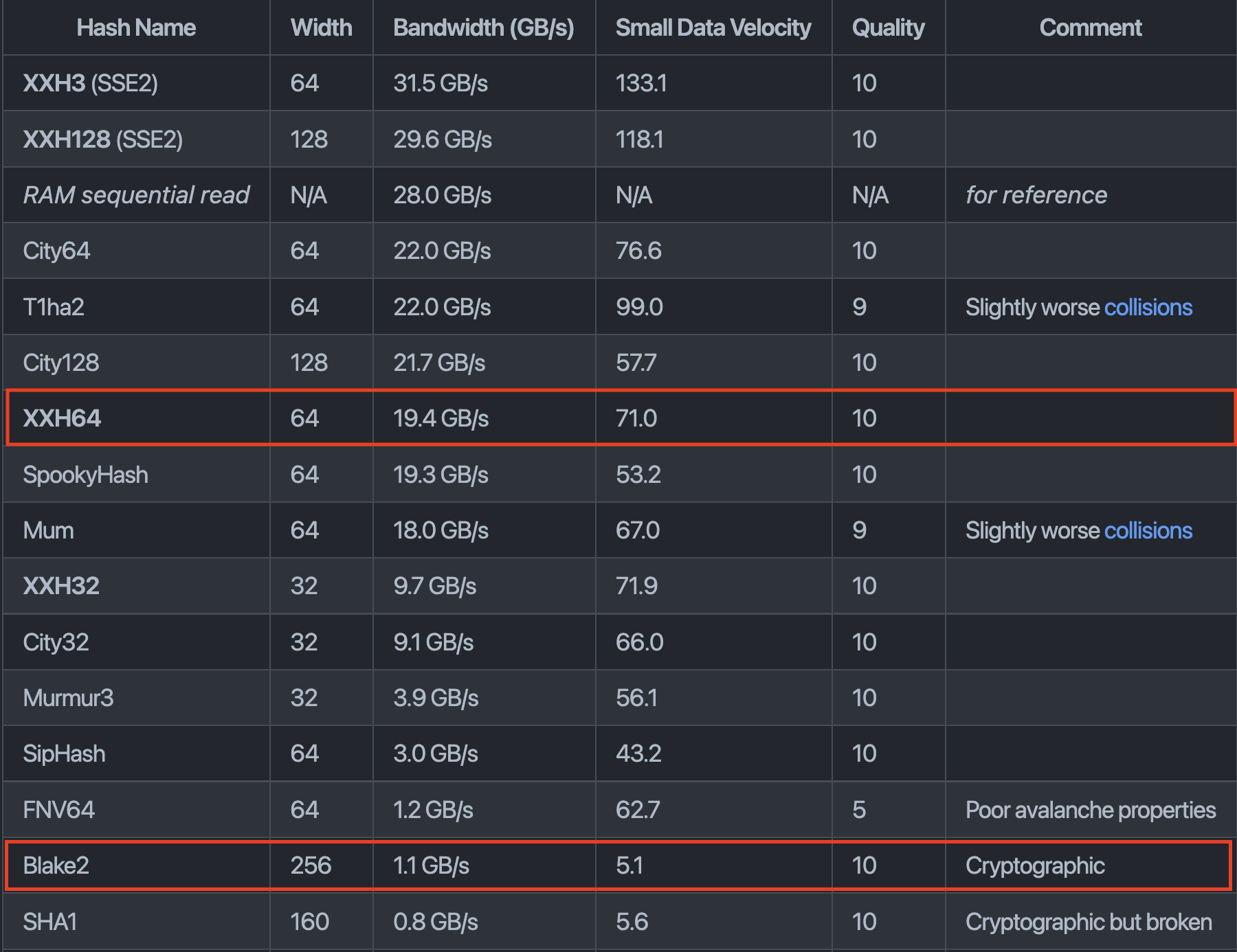
Notes:
Benchmarks for the XX-hash algorithms. Source: https://github.com/Cyan4973/xxHash#benchmarks
Non-Cryptographic Hash Functions
Non-cryptographic hash functions provide weaker
guarantees in exchange for performance.
They are OK to use when you know that the input is not malicious.
If in doubt, use a cryptographic hash function.
One Way
Given a hash, it should be difficult to find an input value (pre-image)
that would produce the given hash.
That is, given H(x), it should be difficult to find x.
Notes:
We sometimes add random bytes to pre-images to prevent guesses based on context (e.g., if you are hashing "rock, paper, scissors", then finding a pre-image is trivial without some added randomness.)
Second Pre-Image Attacks
Given a hash and a pre-image, it should be difficult to find another
pre-image that would produce the same hash.
Given H(x), it should be difficult to find any x'
such that H(x) == H(x').
Notes:
Since most signature schemes perform some internal hashing, this second pre-image would also pass signature verification.
Collision Resistance
It should be difficult for someone to find two messages that
hash to the same value.
It should be difficult to find an x and y
such that H(x) == H(y).
Collision Resistance
Difference from second pre-image attack:
In a second pre-image attack, the attacker only controls one input.
In a collision, the attacker controls both inputs.
They may attempt to trick someone into signing one message.
Notes:
Attacker has intention to impersonate the signer with the other. Generally speaking, even finding a single hash collision often results in the hash function being considered unsafe.
Birthday Problem
With 23 people, there is a 6% chance that someone will be born on a specific date, but a 50% chance that two share a birthday.
- Must compare each output with every other, not with a single one.
- Number of possible "hits" increases exponentially for more attempts, reducing the expected success to the square-root of what a specific target would be.

Birthday Attack
Thus, with a birthday attack, it is possible to find a collision of a hash function in $\sqrt {2^{n}}=2^{^{\frac{n}{2}}}$, with $\cdot 2^{^{\frac{n}{2}}}$ being the classical preimage resistance security.
So, hash function security is only half of the bit space.
Notes:
e.g., a 256 bit hash output yields 2^128 security
Partial Resistance
It should be difficult for someone to partially (for a substring of the hash output) find a collision or "second" pre-image.
- Bitcoin PoW is a partial pre-image attack.
- Prefix/suffix pre-image attack resistance reduces opportunity for UI attacks for address spoofing.
- Prefix collision resistance important to rationalize costs for some cryptographic data structures.
Hash Function Selection
When users (i.e. attackers) have control of the input, cryptographic hash functions must be used.
When input is not controllable (e.g. a system-assigned index), a non-cryptographic hash function can be used and is faster.
Notes:
Only safe when the users cannot select the pre-image, e.g. a system-assigned index.
Keccak is available for Ethereum compatibility.
Applications
Cryptographic Guarantees
Let's see which cryptographic properties apply to hashes.
---v
Confidentiality
Sending or publically posting a hash of some data $D$ keeps $D$ confidential, as only those who already knew $D$ recognize $H(D)$ as representing $D$.
Both cryptographic and non-cryptographic hashes work for this. only if the input space is large enough.
---v
Confidentiality Bad Example
Imagine playing rock, paper, scissors by posting hashes and then revealing. However, if the message is either "rock", "paper", or "scissors", the output will always be either:
hash('rock') = 0x10977e4d68108d418408bc9310b60fc6d0a750c63ccef42cfb0ead23ab73d102
hash('paper') = 0xea923ca2cdda6b54f4fb2bf6a063e5a59a6369ca4c4ae2c4ce02a147b3036a21
hash('scissors') = 0x389a2d4e358d901bfdf22245f32b4b0a401cc16a4b92155a2ee5da98273dad9a
The other player doesn't need to undo the hash function to know what you played!
Notes:
The data space has to be sufficiently large. Adding some randomness to input of the hash fixes this. Add x bits of randomness to make it x bits of security on that hash.
---v
Authenticity
Anyone can make a hash, so hashes provide no authenticity guarantees.
---v
Integrity
A hash changes if the data changes, so it does provide integrity.
---v
Non-Repudiation
Hashes on their own cannot provide authenticity, and as such cannot provide non-repudiation.
However, if used in another cryptographic primitive that does provide non-repudiation, $H(D)$ provides the same non-repudation as $D$ itself.
Notes:
This is key in digital signatures. However, it's important to realize that if $D$ is kept secret, $H(D)$ is basically meaningless.
Content-Derived Indexing
Hash functions can be used to generate deterministic
and unique lookup keys for databases.
Notes:
Given some fixed property, like an ID and other metadata the user knows beforehand, they can always find the database entry with all of the content they are looking for.
Data Integrity Checks
Members of a peer-to-peer network may host and share
file chunks rather than large files.
In Bittorrent, each file chunk is hash identified so peers can
request and verify the chunk is a member of the larger,
content addressed file.
Notes:
The hash of the large file can also serve as a signal to the protocol that transmission is complete.
Account Abstractions
Public keys can be used to authorize actions by signing of instructions.
The properties of hash functions allow other kinds of representations.
Public Key Representation
Because hashes serve as unique representations of other data,
that other data could include public keys.
A system can map a plurality of key sizes to a fixed length
(e.g. for use as a database key).
For example, the ECDSA public key is 33 bytes:
Public key (hex):
0x02d82cdc83a966aaabf660c4496021918466e61455d2bc403c34bde8148b227d7a
Hash of pub key:
0x8fea32b38ed87b4739378aa48f73ea5d0333b973ee72c5cb7578b143f82cf7e9
^^
Commitment Schemes
It is often useful to commit to some information
without storing or revealing it:
- A prediction market would want to reveal predictions only after the confirming/refuting event occurred.
- Users of a system may want to discuss proposals without storing the proposal on the system.
However, participants should not be able to modify their predictions or proposals.
Commit-Reveal
- Share a hash of data as a commitment ($c$)
- Reveal the data itself ($d$)
It is normal to add some randomness to the message
to expand the input set size:
$$ hash(message + randomness) => commitment $$
Commitment: 0x97c9b8d5019e51b227b7a13cd2c753cae2df9d3b435e4122787aff968e666b0b
Reveal
Message with some added randomness:
"I predict Boris Johnson will resign on 7 July 2022. facc8d3303c61ec1808f00ba612c680f"
Data Identifiers
Sometimes people want to store information in one place and reference it in another. For reference, they need some "fingerprint" or digest.
As an example, they may vote on executing some privileged instructions within the system.
The hash of the information can succinctly represent the information and commit its creator to not altering it.
Data Structures (in Brief)
This is the focus of a later lesson.
Notes: For now, just a brief introduction.
Pointer-Based Linked Lists
Pointer-based linked lists are a foundation of programming.
But pointers are independent from the data they reference,
so the data can be modified while maintaining the list.
That is, pointer-based linked lists are not tamper evident.

Hash-Based Linked Lists
Hash-based lists make the reference related to the data they are referencing.
The properties of hash functions make them a good choice for this application.
Any change at any point in the list would create downstream changes to all hashes.
Merkle Trees
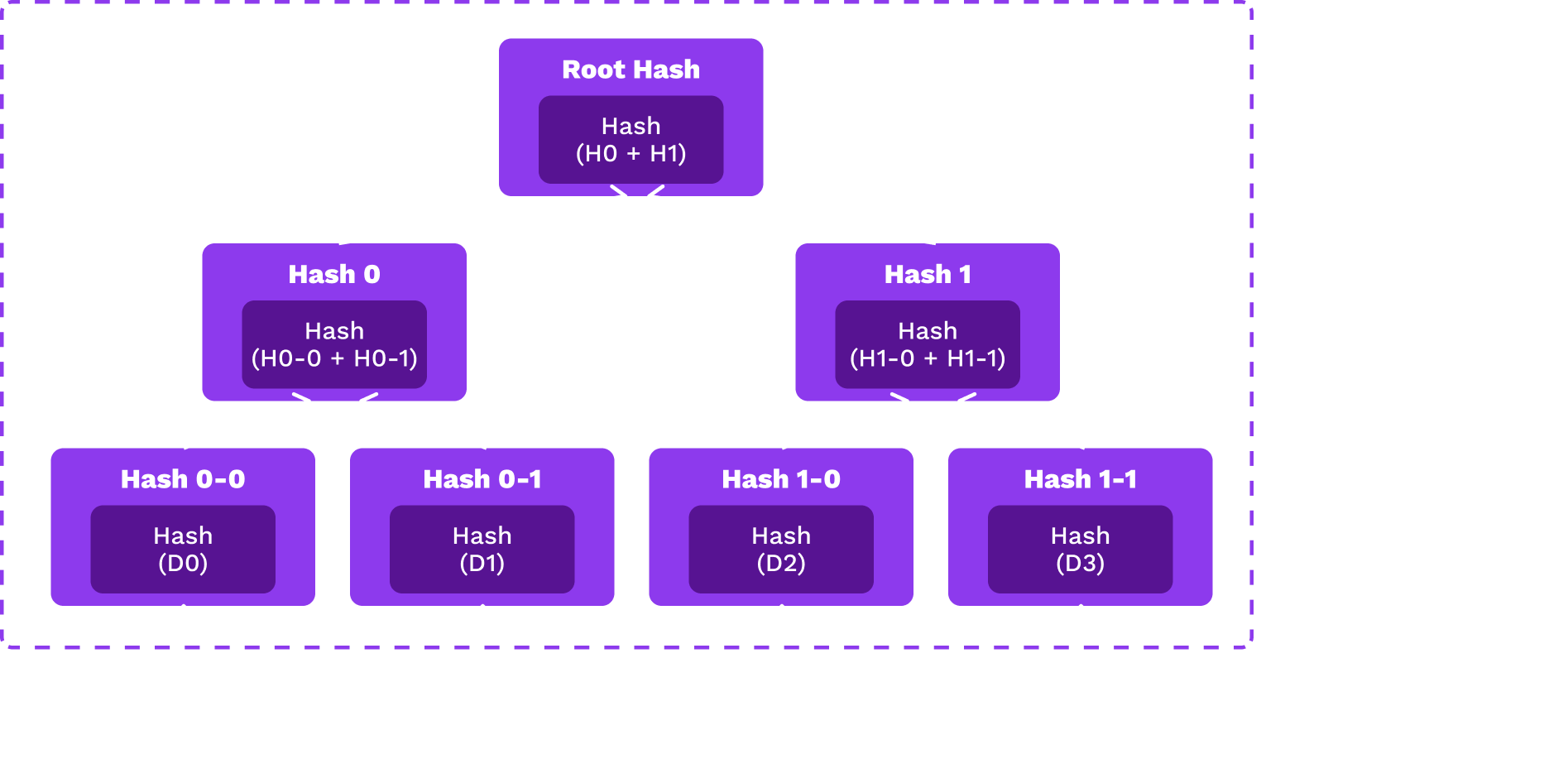
Notes:
Each leaf is the hash of some data object and each node is the hash of its children.
Proofs
Merkle trees allow many proofs relevant to the rest of this course,
e.g. that some data object is a member of the tree
without passing the entire tree.
More info in the next lesson.
Questions
Hash Examples in Substrate
Sr25519 Signatures
Sr25519 hashes the message as part of its signing process.
Transactions
In transactions in Substrate, key holders sign a
hash of the instructions when the instructions
are longer than 256 bytes.
Database Keys
TwoX64 is safe to use when users (read: attackers)
cannot control the input, e.g. when a
database key is a system-assigned index.
Blake2 should be used for everything else.
Again, there is a whole lesson on hash-based data structures.
Other Uses of Hashes in Substrate
Hashes are also used for:
- Generating multisig accounts
- Generating system-controlled accounts
- Generating proxy-controlled accounts
- Representing proposals
- Representing claims (e.g. the asset trap)
Activity: Crack the Many Time Pad
Instructors: there is a private guide associated with this activity to assist with hints and further details, be sure to review this before starting.
Introduction
The symmetric one-time pad is known to be secure when the key is only used once. In practice key distribution is not always practical, and users sometimes make the critical mistake of reusing a pre-shared key.
In this activity, you will experience first hand why reusing the key is detrimental to security.
The Challenge
The following several ciphertexts were intercepted on a peer-to-peer communication channel:
- Messages definitively originate in the USA, destined for the UK.
- Each line contains one hex encoded message, in it's entirety.
- We believe all messages were encrypted with the same key.
Your task is to use cryptanalysis to recover the plaintexts of all messages, as well as the encryption key used for them.
160111433b00035f536110435a380402561240555c526e1c0e431300091e4f04451d1d490d1c49010d000a0a4510111100000d434202081f0755034f13031600030d0204040e
050602061d07035f4e3553501400004c1e4f1f01451359540c5804110c1c47560a1415491b06454f0e45040816431b144f0f4900450d1501094c1b16550f0b4e151e03031b450b4e020c1a124f020a0a4d09071f16003a0e5011114501494e16551049021011114c291236520108541801174b03411e1d124554284e141a0a1804045241190d543c00075453020a044e134f540a174f1d080444084e01491a090b0a1b4103570740
000000000000001a49320017071704185941034504524b1b1d40500a0352441f021b0708034e4d0008451c40450101064f071d1000100201015003061b0b444c00020b1a16470a4e051a4e114f1f410e08040554154f064f410c1c00180c0010000b0f5216060605165515520e09560e00064514411304094c1d0c411507001a1b45064f570b11480d001d4c134f060047541b185c
0b07540c1d0d0b4800354f501d131309594150010011481a1b5f11090c0845124516121d0e0c411c030c45150a16541c0a0b0d43540c411b0956124f0609075513051816590026004c061c014502410d024506150545541c450110521a111758001d0607450d11091d00121d4f0541190b45491e02171a0d49020a534f
031a5410000a075f5438001210110a011c5350080a0048540e431445081d521345111c041f0245174a0006040002001b01094914490f0d53014e570214021d00160d151c57420a0d03040b4550020e1e1f001d071a56110359420041000c0b06000507164506151f104514521b02000b0145411e05521c1852100a52411a0054180a1e49140c54071d5511560201491b0944111a011b14090c0e41
0b4916060808001a542e0002101309050345500b00050d04005e030c071b4c1f111b161a4f01500a08490b0b451604520d0b1d1445060f531c48124f1305014c051f4c001100262d38490f0b4450061800004e001b451b1d594e45411d014e004801491b0b0602050d41041e0a4d53000d0c411c41111c184e130a0015014f03000c1148571d1c011c55034f12030d4e0b45150c5c
011b0d131b060d4f5233451e161b001f59411c090a0548104f431f0b48115505111d17000e02000a1e430d0d0b04115e4f190017480c14074855040a071f4448001a050110001b014c1a07024e5014094d0a1c541052110e54074541100601014e101a5c
0c06004316061b48002a4509065e45221654501c0a075f540c42190b165c
00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
Instructions
-
Team up with 2-4 students to complete this activity.
-
Briefly inspect the ciphertext to see if you can identify patterns that may hint some things about their origin.
-
Research based on what we know bout the messages to find clues to help come up with a theory and game plan to complete your task.
-
Write a program in Rust that finds the key to generate the plaintext from the provided cipher texts.
The general steps are:- Find the length of the longest input cipher text.
- Generate a key of that length.
- Find what the correct key is...
Note that this task is intended to be a bit vague, give it your best effort. We will be sharing hints as time progresses for everyone. Don't hesitate to ask for support if you're feeling stuck, or just ask your peers!
Finished?
Once complete, let a faculty know!
One last ciphertext using the same key that should prove tricky:
1f3cb1f3e01f3fd1f3ea1f3e61f3e01f3e71f3b31f3a91f3c81f3a91f3f91f3fc1f3fb1f3ec1f3e51f3f01f3a91f3f91f3ec1f3ec526e1b014a020411074c17111b1c071c4e4f0146430d0d08131d1d010707040017091648461e1d0618444f074c010e19594f0f1f1a07024e1d041719164e1c1652114f411645541b004e244f080213010c004c3b4c0911040e480e070b00310213101c4d0d4e00360b4f151a005253184913040e115454084f010f114554111d1a550f0d520401461f3e01f3e71f3e81f3e71f3ea1f3e01f3e81f3e51f3a91f3e01f3e71f3fa1f3fd1f3e01f3fd1f3fc1f3fd1f3e01f3e61f3e71f3a7
Notice a pattern? why might that be... 🤔
If you want more to do, find ways to improve your solution, perhaps:
- Create a tool that automates the cipher key generation.
- Add a way to generate new cipher texts.
- Create your own cipher texts using other cipher methods.
- Provide a new set of ciphertexts that were intentionally constructed not to use the most common English words.
Citation
This activity is cribbed from Dan Boneh's Coursera Cryptography I course.
Encryption
How to use the slides - Full screen (new tab)
Encryption
Goals for this lesson
- Learn about the differences between symmetric and asymmetric encryption.
Symmetric Cryptography
Symmetric encryption assumes all parties begin with some shared secret information, a potentially very difficult requirement.
The shared secret can then be used to protect further communications from others who do not know this secret.
In essence, it gives a way of extending a shared secret over time.
Symmetric Encryption
Examples: ChaCha20, Twofish, Serpent, Blowfish, XOR, DES, AES
Symmetric Encryption API
Symmetric encryption libraries should generally all expose some basic functions:
fn generate_key(r) -> k;
Generate ak(secret key) from some inputr.fn encrypt(k, msg) -> ciphertext;
Takeskand a message; returns the ciphertext.fn decrypt(k, ciphertext) -> msg;
Takeskand a ciphertext; returns the original message.
It always holds that decrypt(k, encrypt(k, msg)) == msg.
Notes:
The input r is typically a source of randomness, for example the movement pattern of a mouse.
Symmetric Encryption Guarantees
Provides:
- Confidentiality
- Authenticity*
Does not provide:
- Integrity*
- Non-Repudiation
Notes:
- Authenticity: The message could only be sent by someone who knows the shared secret key. In most cases, this is functionally authentication to the receiving party.
- Integrity: There is no proper integrity check, however the changed section of the message will be gibberish if it has been changed. Detection of gibberish could function as a form of integrity-checking.
Non-repudiation for Symmetric Encryption
There is cryptographic proof that the secret was known to the producer of the encrypted message.
However, knowledge of the secret is not restricted to one party: Both (or all) parties in a symmetrically encrypted communication know the secret. Additionally, in order to prove this to anyone, they must also gain knowledge of the secret.
Notes:
The degree of non-repudiation given by pure symmetric crytography is not very useful.
Symmetric Encryption
Example: XOR Cipher
The encryption and decryption functions are identical: applying a bitwise XOR operation with a key.
Plain: 1010 -->Cipher: 0110
Key: 1100 | 1100
---- | ----
0110--^ 1010
Notes:
A plaintext can be converted to ciphertext, and vice versa, by applying a bitwise XOR operation with a key known to both parties.
Symmetric Encryption
⚠ Warning ⚠
We typically expect symmetric encryption to preserve little about the original plaintext. We caution however that constructing these protocols remains delicate, even given secure primitives, with two classical examples being unsalted passwords and the ECB penguin.
ECB penguin

Original image
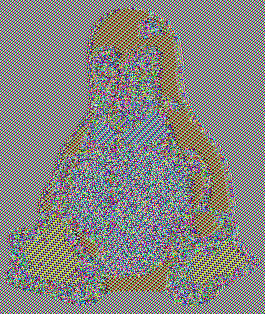
Encrypted image
(by blocks)

Encrypted image
(all at once)
Notes:
The ECB penguin shows what can go wrong when you encrypt a small piece of data, and do this many times with the same key, instead of encrypting data all at once.
Image sources: https://github.com/robertdavidgraham/ecb-penguin/blob/master/Tux.png and https://github.com/robertdavidgraham/ecb-penguin/blob/master/Tux.ecb.png and https://upload.wikimedia.org/wikipedia/commons/5/58/Tux_secure.png
Asymmetric Encryption
- Assumes the sender does not know the recipient's secret "key" 🎉😎
- Sender only knows a special identifier of this secret
- Messages encrypted with the special identifier can only be decrypted with knowledge of the secret.
- Knowledge of this identifier does not imply knowledge of the secret, and thus cannot be used to decrypt messages encrypted with it.
- For this reason, the identifier may be shared publicly and is known as the public key.
Asymmetric Encryption

Why "Asymmetric"?
Using only the public key, information can be transformed ("encrypted") such that only those with knowledge of the secret are able to inverse and regain the original information.
i.e. Public key is used to encrypt but a different, secret, key must be used to decrypt.
Asymmetric Encryption API
Asymmetric encryption libraries should generally all expose some basic functions:
fn generate_key(r) -> sk;
Generate ask(secret key) from some inputr.fn public_key(sk) -> pk;
Generate apk(public key) from the private keysk.fn encrypt(pk, msg) -> ciphertext;
Takes the public key and a message; returns the ciphertext.fn decrypt(sk, ciphertext) -> msg;
For the inputsskand a ciphertext; returns the original message.
It always holds that decrypt(sk, encrypt(public_key(sk), msg)) == msg.
Notes:
The input r is typically a source of randomness, for example the movement pattern of a mouse.
Asymmetric Encryption Guarantees
Provides:
- Confidentiality
Does not provide:
- Integrity*
- Authenticity
- Non-Repudiation
Notes:
- Authenticity: The message could only be sent by someone who knows the shared secret key. In most cases, this is functionally authentication to the receiving party.
- Integrity: There is no proper integrity check, however the changed section of the message will be gibberish if it has been changed. Detection of gibberish could function as a form of integrity-checking.
Diffie-Hellman Key Exchange

Mixing Paint Visualization
Notes:
Mixing paint example. Image Source: https://upload.wikimedia.org/wikipedia/commons/4/46/Diffie-Hellman_Key_Exchange.svg
Authenticated Encryption
Authenticated encryption adds a Message Authentication Code to additionally provide an authenticity and integrity guarantee to encrypted data.
A reader can check the MAC to ensure the message was constructed by someone knowing the secret.
Notes:
Specifically, this authenticity says that anyone who does not know the sender's secret could not construct the message.
Generally, this adds ~16-32 bytes of overhead per encrypted message.
AEAD (Authenticated Encryption Additional Data)
AEAD is authenticated with some extra data which is unencrypted, but does have integrity and authenticity guarantees.
Notes:
Authenticated encryption and AEAD can work with both symmetric and asymmetric cryptography.
AEAD Example
Imagine a table with encrypted medical records stored in a table, where the data is stored using AEAD. What are the advantages of such a scheme?
UserID -> Data (encrypted), UserID (additional data)
Notes: By using this scheme, the data is always associated with the userID. An attacker could not put that entry into another user's entry.
Hybrid Encryption
Hybrid encryption combines the best of all worlds in encryption. Asymmetric encryption establishes a shared secret between the sender and a specific public key, and then uses symmetric encryption to encrypt the actual message. It can also be authenticated.
Notes:
In practice, asymmetric encryption is almost always hybrid encryption.
Cryptographic Properties
| Property | Symmetric | Asymmetric | Authenticated | Hybrid + Authenticated |
|---|---|---|---|---|
| Confidentiality | Yes | Yes | Yes | Yes |
| Authenticity | Yes* | No | Yes* | Yes |
| Integrity | No* | No* | Yes | Yes |
| Non-repudiation | No | No* | No | No* |
Notes:
- Symmetric-Authentication and Authenticated-Authenticity: The message could only be sent by someone who knows the shared secret key. In most cases, this is functionally authentication to the receiving party.
- Symmetric-Integrity and Asymmetric-Integrity: There is no proper integrity check, however the message will be gibberish if it has been changed. Detection of gibberish could function as a form of integrity-checking.
- Non-Repudation: Even though none of these primitives provide non-repudiation on their own, it's very possible to add non-repudation to asymmetric and hybrid schemes via signatures.
- Note that encryption also, most importantly, makes the data available to everyone who should have access.
Questions
Digital Signature Basics
How to use the slides - Full screen (new tab)
Digital Signatures Basics
Signature API
Signature libraries should generally all expose some basic functions:
fn generate_key(r) -> sk;
Generate ask(secret key) from some inputr.fn public_key(sk) -> pk;
Return thepk(public key) from ask.fn sign(sk, msg) -> signature;
Takesskand a message; returns a digital signature.fn verify(pk, msg, signature) -> bool;
For the inputspk, a message, and a signature; returns whether the signature is valid.
Notes:
The input r could be anything, for example the movement pattern of a mouse.
For some cryptographies (ECDSA), the verify might not take in the public key as an input. It takes in the message and signature, and returns the public key if it is valid.
Subkey Demo
Key Generation and Signing
Notes:
See the Jupyter notebook and/or HackMD cheat sheet for this lesson.
- Generate a secret key
- Sign a message
- Verify the signature
- Attempt to alter the message
Hash Functions
There are two lessons dedicated to hash functions.
But they are used as part of all signing processes.
For now, we only concern ourselves with using Blake2.
Hashed Messages
As mentioned in the introduction,
it's often more practical to sign the hash of a message.
Therefore, the sign/verify API may be used like:
fn sign(sk, H(msg)) -> signature;fn verify(pk, H(msg), signature) -> bool;
Where H is a hash function (for our purposes, Blake2).
This means the verifier will need to run the correct hash function on the message.
Cryptographic Guarantees
Signatures provide many useful properties:
- Confidentiality: Weak, the same as a hash
- Authenticity: Yes
- Integrity: Yes
- Non-repudiation: Yes
Notes:
If a hash is signed, you can prove a signature is valid without telling anyone the actual message that was signed, just the hash.
Signing Payloads
Signing payloads are an important part of system design.
Users should have credible expectations about how their messages are used.
For example, when a user authorizes a transfer,
they almost always mean just one time.
Notes:
There need to be explicit rules about how a message is interpreted. If the same signature can be used in multiple contexts, there is the possibility that it will be maliciously resubmitted.
In an application, this typically looks like namespacing in the signature payload.
Signing and Verifying

Notes:
Note that signing and encryption are not inverses.
Replay Attacks
Replay attacks occur when someone intercepts and resends a valid message.
The receiver will carry out the instructions since the message contains a valid signature.
- Since we assume that channels are insecure, all messages should be considered intercepted.
- The "receiver", for blockchain purposes, is actually an automated system.
Notes:
Lack of context is the problem. Solve by embedding the context and intent _within the message being signed. Tell the story of Ethereum Classic replays.
Replay Attack Prevention
Signing payloads should be designed so that they can
only be used one time and in one context.
Examples:
- Monotonically increasing account nonces
- Timestamps (or previous blocks)
- Context identifiers like genesis hash and spec versions
Signature Schemes
ECDSA
- Uses Secp256k1 elliptic curve.
- ECDSA (used initially in Bitcoin/Ethereum) was developed to work around the patent on Schnorr signatures.
- ECDSA complicates more advanced cryptographic techniques, like threshold signatures.
- Nondeterministic
Ed25519
- Schnorr signature designed to reduce mistakes in implementation and usage in classical applications, like TLS certificates.
- Signing is 20-30x faster than ECDSA signatures.
- Deterministic
Sr25519
Sr25519 addresses several small risk factors that emerged
from Ed25519 usage by blockchains.
Use in Substrate
- Sr25519 is the default key type in most Substrate-based applications.
- Its public key is 32 bytes and generally used to identify key holders (likewise for ed25519).
- Secp256k1 public keys are 33 bytes, so their hash is used to represent their holders.
Questions
Advanced Digital Signatures
How to use the slides - Full screen (new tab)
Advanced Digital Signatures
Certificates
A certificate is essentially a witness statement concerning one or more public keys. It is a common usage of digital signatures, but it is not a cryptographic primitive!
Notes:
A certificate is one issuing key signing a message containing another certified key, which attests to some properties or relationship about the certified key.
We must already trust the issuing key to give this attestation any significance, traditionally provided under "Certificate Authority" or "Web of Trust" schemes.
Certificates
A certification system specified conventions on who is allowed to issue certificates, the rules over their issuance (e.g. time limits and revocation) as well as their format and semantics.
For example, the certificate transparency protocol for TLS certificates helps protect against compromised Certificate Authorities.
Notes:
Certificate transparency: explanation and dashboard
- Maybe mention PGP web-of-trust style schemes
Certificates in Web3
We are building systems that don't have a "Certificate Authority".
But we can still use certificates in some niche instances.
Notes:
Potential example to give verbally:
- Session keys are a set of keys that generally run in online infrastructure. An account, whose keys are protected, can sign a transaction to certify all the keys in the set.
- Session keys are used to sign operational messages, but also in challenge-response type games to prove availability by signing a message.
Multi-Signatures
We often want signatures that must be signed
by multiple parties to become valid.
- Require some threshold of members to
agree to a message - Protect against key loss
Types of Multi-Signature
- Verifier enforced
- Cryptographic threshold
- Cryptographic non-threshold
(a.k.a. signature aggregation)
Verifier Enforced Multiple Signatures
We assume that there is some verifier, who can check that some threshold of individual keys have provided valid signatures.
This could be a trusted company or third party. For our purposes, it's a blockchain.
Verifier Enforced Multiple Signatures
Multiple signatures enforced by a verifier generally provide a good user experience, as no interaction is required from the participants.
Notes:
This good experience comes at the cost of using state and more user interactions with the system, but is generally low.
Even in a web3 system, the verifier can be distinct from the blockchain. 5 people can entrust a verifier with the identity of "all 5 signed this" associated to a verifier-owned private key.
Cryptographic Multi-Sigs
We want a succinct way to demonstrate that everyone from some set of parties have signed a message. This is achieved purely on the signer side (without support from the verifier).
Example: "The five key holders have signed this message."
Key Generation for Multi-Sigs
In regular multi-signatures,
signatures from individual public keys are aggregated.
Each participant can choose their own key to use for the multi-signature.
Notes:
In some cases, a security requirement of these systems is that every participant demonstrates ownership of the public key submitted for the multi-signature, otherwise security can be compromised.
Cryptographic Threshold Multi-Sigs
This makes more compact signatures compatible with legacy systems. Unlike a regular multi-sig, the public key is associated with a threshold number of signing parties, so not all parties are needed to take part in the signing process to create a valid signature.
This requires MPC protocols and may need multiple rounds of interaction to generate the final signature. They may be vulnerable to DoS from a malfunctioning (or malicious) key-holder.
Example: "5 of 7 key holders have signed this message."
Notes:
These require multi-party computation (MPC) protocols, which add some complexity for the signing users.
Key Generation - Threshold
Threshold multi-signature schemes require that all signers run a distributed key generation (DKG) protocol that constructs key shares.
The secret encodes the threshold behavior, and signing demands some threshold of signature fragments.
This DKG protocol breaks other useful things, like hard key derivation.
Schnorr Multi-Sigs
Schnorr signatures are primarily used for threshold multi-sig.
- Fit legacy systems nicely, and can reduce fees on blockchains.
- Reduce verifier costs in bandwidth & CPU time, so great for certificates.
- Could support soft key derivations.
Schnorr Multi-Sigs
However, automation becomes tricky.
We need agreement upon the final signer list and two random nonce contributions from each prospective signer, before constructing the signature fragments.
BLS Signatures
BLS signatures are especially useful for aggregated (non-threshold) multi-signatures (but can be used for threshold as well).
Signatures can be aggregated without advance agreement upon the signer list, which simplifies automation and makes them useful in consensus.
Verifying individual signatures is slow, but verifying aggregated ones is relatively fast.
(Coming to Substrate soonish.)
BLS Signatures
Allows multiple signatures generated under multiple public keys for multiple messages to be aggregated into a single signature.
- Uses heavier pairing friendly elliptic curves than ECDSA/Schnorr.
- Very popular for consensus.
BLS Signatures
However...
- DKGs remain tricky (for threshold).
- Soft key derivations are typically insecure for BLS.
- Verifiers are hundreds of times slower than Schnorr, due to using pairings, for a single signature.
- But for hundreds or thousands of signatures on the same message, aggregated signature verification can be much faster than Schnorr.
Schnorr and BLS Summary
Schnorr & BLS multi-signatures avoid complicating verifier logic,
but introduce user experience costs such as:
- DKG protocols
- Reduced key derivation ability
- Verification speed
Ring Signatures
- Ring signatures prove the signer lies within some "anonymity set" of signing keys, but hide which key actually signed.
- Ring signatures come in many sizes, with many ways of presenting their anonymity sets.
- Anonymous blockchain transactions typically employ ring signatures (Monero, ZCash).
Notes:
- ZCash uses a ring signature based upon Groth16 zkSNARKs which makes the entire chain history be the anonymity set.
- Monero uses ring signatures with smaller signer sets.
- Ring signatures trade some non-repudation for privacy.
Questions
Hash Based Data Structures
How to use the slides - Full screen (new tab)
Hash Based Data Structures
Comparison to
Pointer Based Data Structures
- A hash references the content of some data;
- A pointer tells you where to find it;
- We can not have cycles of hashes.
Hash Chains

A hash chain is a linked list using hashes to connect nodes.
Notes:
Each block has the hash of the previous one.
Merkle Trees
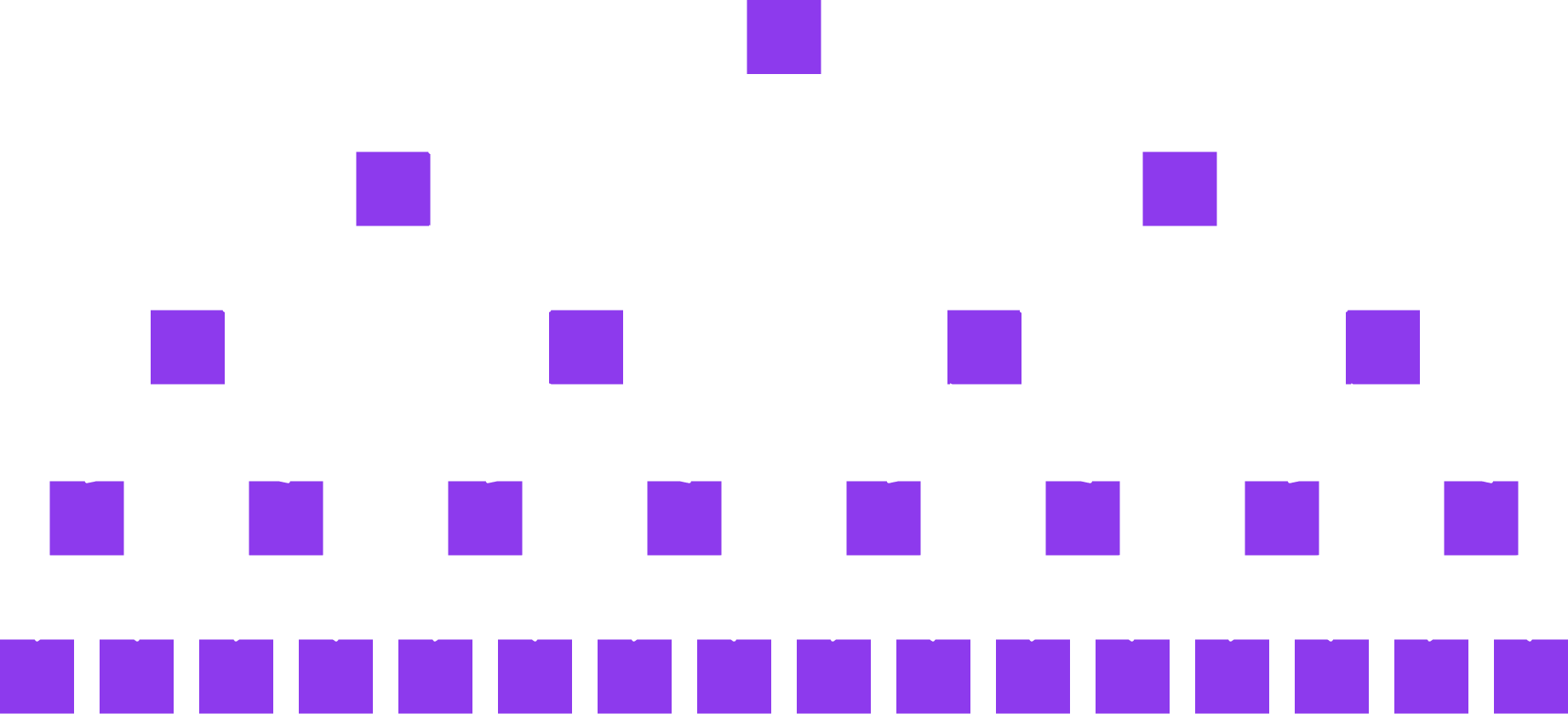
A binary Merkle tree is a binary tree using hashes to connect nodes.
Notes:
Ralph Merkle is a Berkeley alum!
Proofs
- The root or head hash is a commitment to the entire data structure.
- Generate a proof by expanding some but not all hashes.
Crucial for the trustless nature of decentralised cryptographic data systems!
Proofs: Merkle Copaths
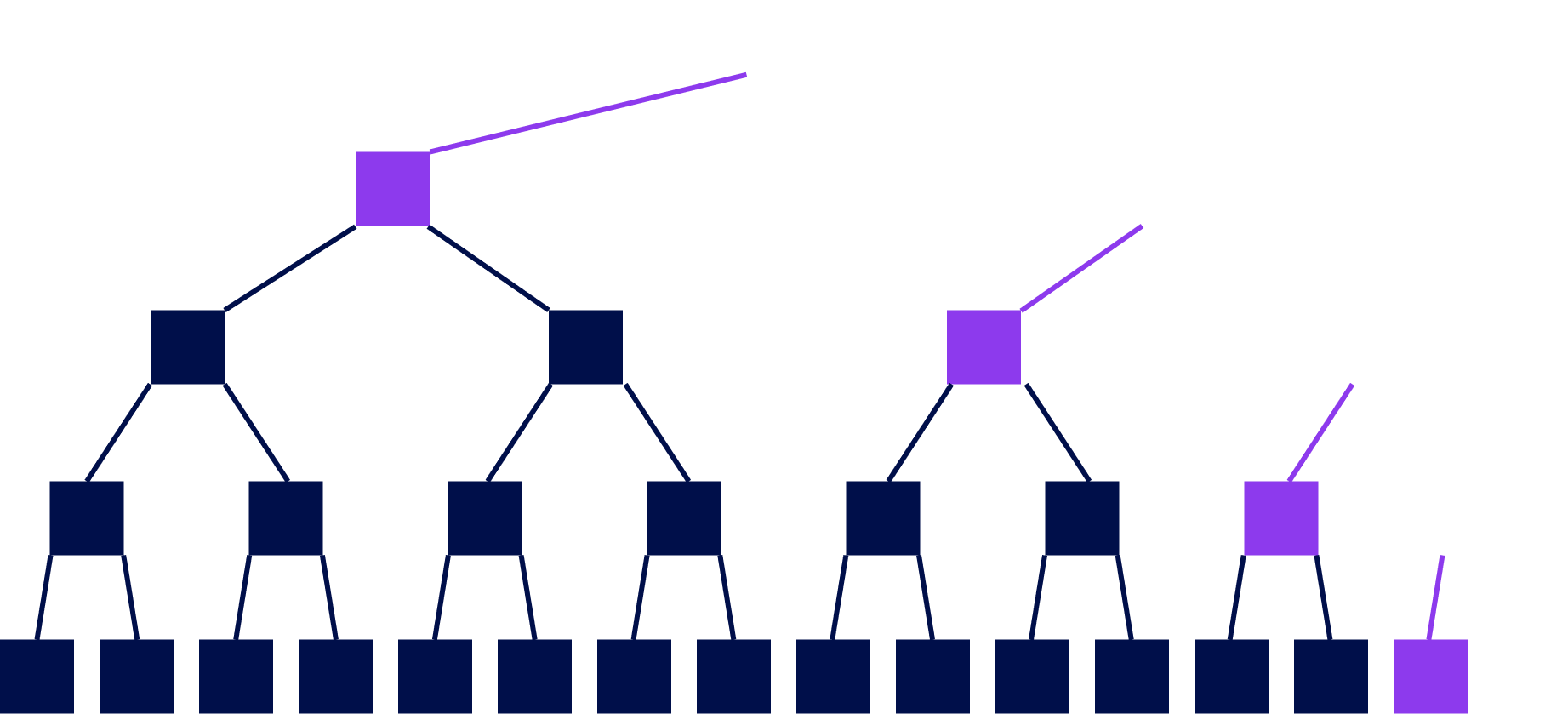
Notes:
Given the children of a node, we can compute a node Given the purple nodes and the white leaf, we can compute the white nodes bottom to top. If we compute the correct root, this proves that the leaf was in the tree
Security
Collision resistance: we reasonably assume only one preimage for each hash,
therefore making the data structure's linkage persistent and enduring (until the cryptography becomes compromised 😥).
Notes:
Explain what could happen when this fails.
Proof Sizes
Proof of a leaf has size $O(\log n)$
and so do proofs of updates of a leaf
Key-Value Databases and Tries
Key-value database
The data structure stores a map key -> value.
We should be able to:
put(key, value)get(key)delete(key)
Provability in key-value databases
We should also be able to perform the following operations for a provable key-value database:
- For any key, if
<key,value>is in the database, we can prove it. - If no value is associated to a key, we need to be able to prove that as well.
Types of Data Structures
- Trees are rooted, directed acyclic graphs where each child has only one parent.
- Merkle Trees are trees which use hashes as links.
- Tries are a particular class of trees where:
- Given a particular piece of data, it will always be on a particular path.
- Radix Tries are a particular class of a trie where:
- The location of a value is determined the path constructed one digit at a time.
- Patricia Tries are radix tries which are optimized to ensure lonely node-paths are consolidated into a single node.
Notes:
Just a selection we'll cover in this course.
Radix Trie
Words: to, tea, ted, ten, inn, A.
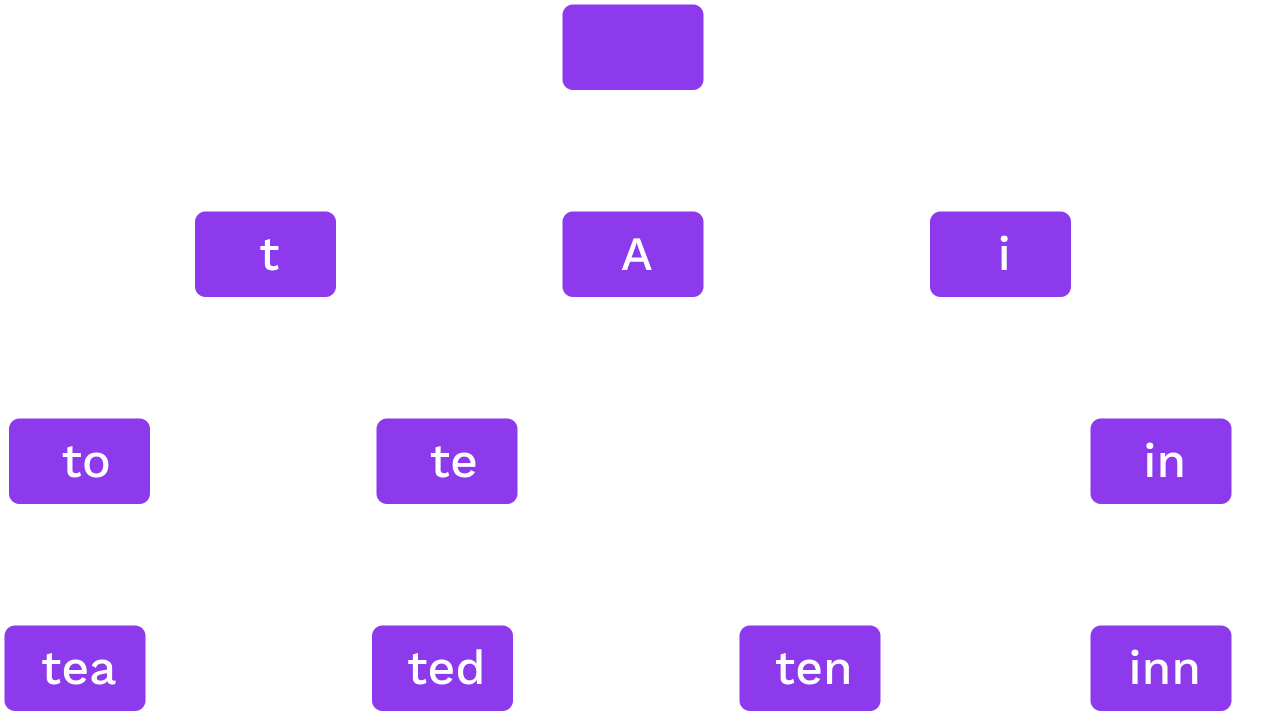
Each node splits on the next digit in base $r$
Notes:
In this image, $r$ is 52 (26 lowercase + 26 uppercase).
Patricia Trie
Words: to, tea, ted, ten, inn, A.
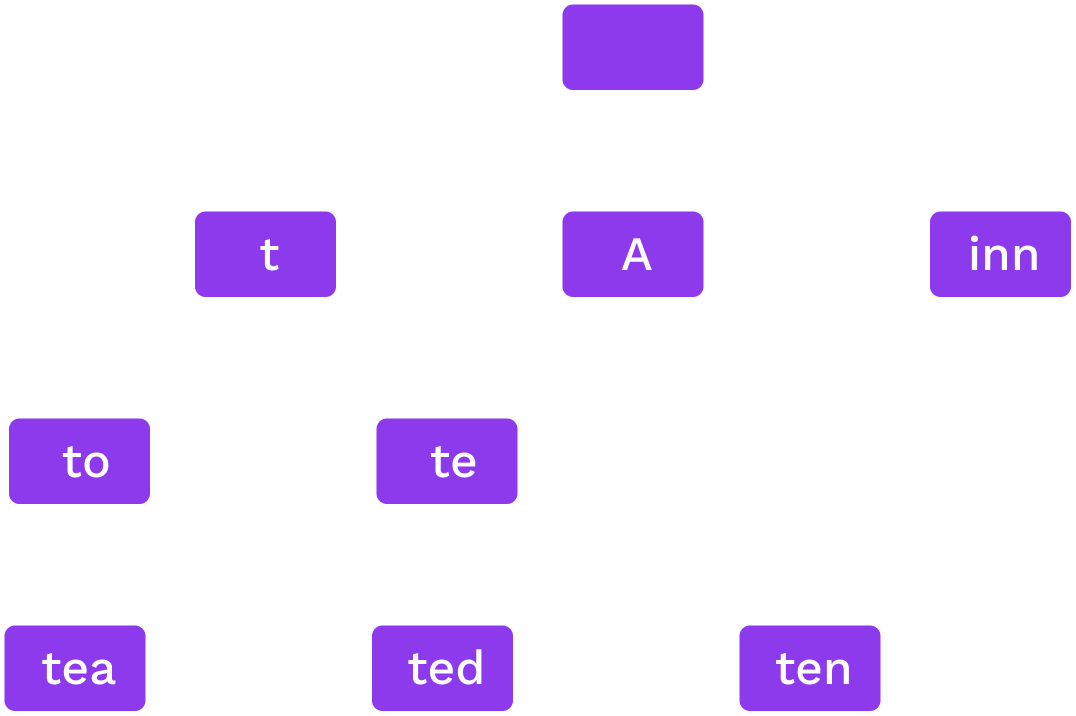
If only one option for a sequence we merge them.
Patricia Trie Structures
#![allow(unused)] fn main() { pub enum Node { Leaf { partial_path: Slice<RADIX>, value: Value }, Branch { partial_path: Slice<RADIX>, children: [Option<Hash>; RADIX], value: Option<Value>, }, } }
Notes:
The current implementation actually makes use of dedicated "extension" nodes instead of branch nodes that hold a partial path. There's a good explanation of them here.
Additionally, if the size of a value is particularly large, it is replaced with the hash of its value.
Hash Trie
- Inserting arbitrary (or worse, user-determined) keys into the Patricia tree can lead to highly unbalanced branches, enlarging proof-sizes and lookup times.
- Solution: pre-hash the data before inserting it to make keys random.
- Resistance against partial collision is important.
- Could be a Merkle trie or regular.
Computational and Storage
Trade-offs
What radix $r$ is best?
- Proof size of a leaf is $r \log_r n$
- $r=2$ gives the smallest proof for one leaf
...but:
- Higher branching at high levels of the tree can give smaller batch proofs.
- For storage, it is best to read consecutive data so high $r$ is better.
Merkle Mountain Ranges
- Efficient proofs and updates for a hash chain
- Append only data structure
- Lookup elements by number
Merkle Mountain Ranges
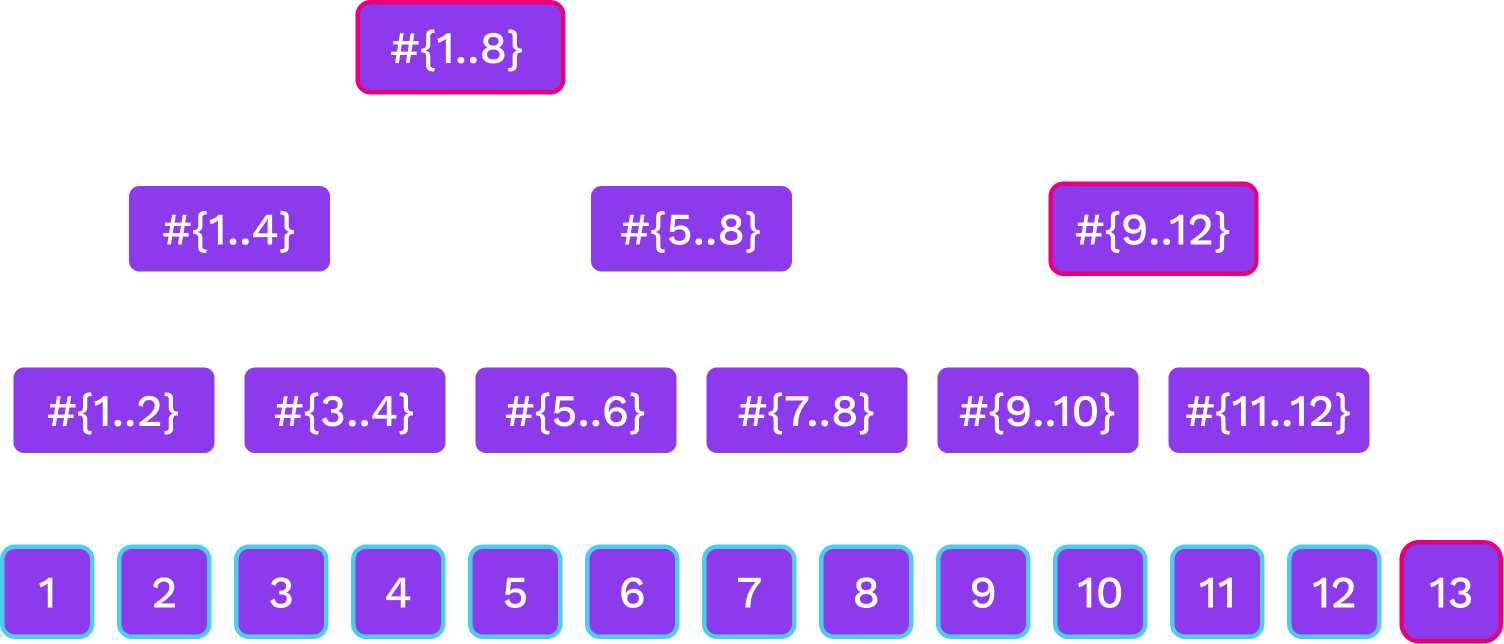
Notes:
we have several Merkle trees of sizes that are powers of two. The trees that are here correspond to the binary digits of 13 that are 1.
Merkle Mountain Ranges
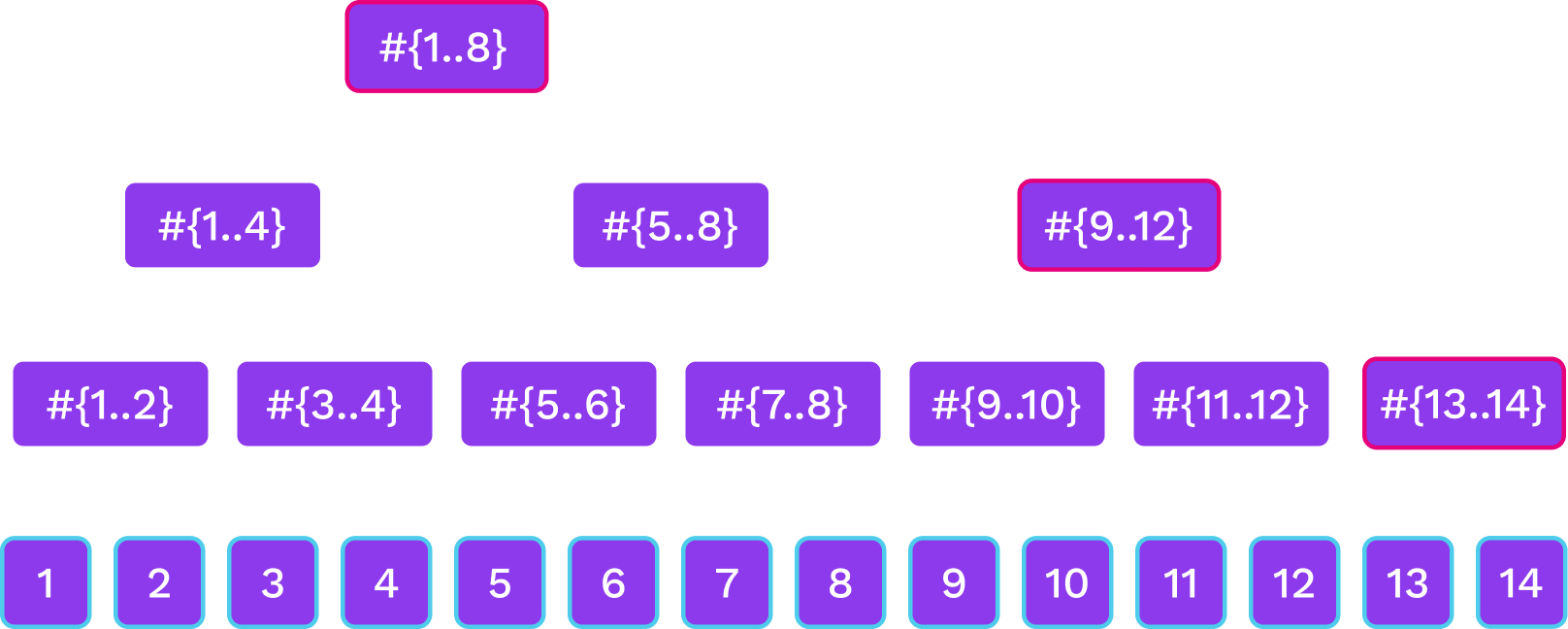
Merkle Mountain Ranges
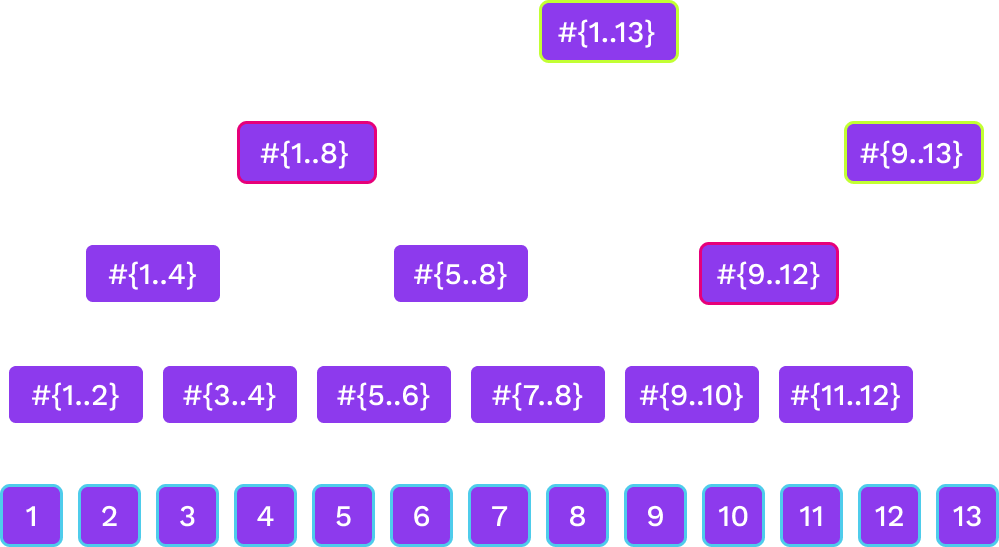
Notes:
- Not as balanced as a binary tree but close
- Can update the peak nodes alone on-chain
Questions
Exotic Primitives
How to use the slides - Full screen (new tab)
Exotic Primitives
Outline
Verifiable Random Functions
(VRFs)
-
Used to obtain private randomness, that is publicly verifiable
-
A variation on a signature scheme:
- still have private/public key pairs, input as message
- in addition to signature, we get an output
VRF Interface
-
sign(sk, input) -> signature -
verify(pk, signature) -> option output -
eval(sk,input) -> output
Notes:
The output of verification being an option represents the possibility of an invalid signature
VRF Output properties
- Output is a deterministic function of key and input
- i.e. eval should be deterministic
- It should be pseudo-random
- But until the VRF is revealed, only the holder
of the secret key knows the output - Revealing output does not leak secret key
VRF Usage
- Choose input after key, then the key holder cannot influence the output
- The output then is effectively a random number known only to the key holder
- But they can later reveal it, by publishing the VRF proof (signature)
Notes:
The signature proves that this is the output associated to their input and public key.
VRF Example
- Playing a card game in a distributed and trustless way
- For player A to draw a card, the players agree on a new random number x
- A's card is determined by
eval(sk_A,x) mod 52 - To play the card, A publishes the signature
VRF Extensions
-
Threshold VRFs / Common coin
- Generate the same random number if $t$ out of $n$ people participate
-
RingVRFs
- The VRF output could be from any one of a group of public keys.
Notes:
Common coins were used in consensus before blockchains were a thing. Dfinity based their consensus on this. But this needs a DKG, and it's unclear if a decentralized protocol can do those easily.
A participant in a RingVRF could still only reveal one random number.
Erasure Coding
Magical data expansion
-
Turn data into pieces (with some redundancy) so it can be reconstructed even if some pieces are missing.
-
A message of $k$ symbols is turned into a coded message of $n$ symbols and can be recovered from any $k$ of these $n$ symbols
Erasure Coding Intuition
Erasure coding relies on both parties sharing an understanding of what possible messages are valid. This lets mistakes be noticed and corrected.
Imagine you are receiving a message, and you know ahead of time that the only two possible messages you would receive are file and ruin.
Notes:
This concept of a subset of messages being valid is super common in real life, and occurs all over the place. At a restaurant, when they ask you if you want soup or salad, even if you mumble they will probably understand you.
---v
Erasure Coding Intuition
How would you classify each of the following words?
file pile pale tale tall rule tail rail rain ruin
---v
Erasure Coding Intuition
How would you classify each of the following words?
file pile pale tale tall rule tail rail rain ruin
You can classify them based on how close they are to a valid input. This also means we can find the errors in these messages.
Notes:
There is no perfect way to separate these, but one very reasonable one is to do it based on the edit distance of the received word with any valid messsage you could receive.
---v
Erasure Coding Intuition
Now, you are receiving messages that could be msg1 or msg2. Can you apply the same technique? Is it as easy to separate received messages?
What if you receive msg3?
Notes:
If the messages are not far apart, it is impossible to distinguish in many cases. There is not enough "distance" between the two possibilities.
---v
Erasure Coding Intuition
With erasure coding, we extend each message magically so they are different enough. The sender and receiver know the same encoding procedure. These extensions will be very different, even if the messages are similar.
msg1 jdf and msg2 ajk
Notes:
It is actually always possible to make the extra magic only appended to the message. This is called a systematic encoding.
For those curious about how the "magic" works:
The magic here is polynomials, and the fact that a polynomial of degree $n$ is completely determined by $n+1$ points. There are many good explanations online.
Erasure Coding

Erasure Coding Classical use
- Used for noisy channels
- If a few bits of the coded data are randomly flipped,
we can still recover the original data - Typically $n$ is not much bigger than $k$
Use in Decentralized Systems
-
We have data we want to keep publicly available
- but not have everyone store
- but we don't trust everyone who is storing pieces
-
Typically we use $n$ much bigger than $k$
Shamir Secret Sharing
Redundancy for your secrets
-
Turn data (typically a secret) into pieces so it can be reconstructed from some subset of the pieces.
-
A secret is turned into $n$ shares, and be recovered by any $k$ of the shares. $k-1$ shares together reveals nothing about the secret.
Shamir Secret Sharing
Notes:
Image source: https://medium.com/clavestone/bitcoin-multisig-vs-shamirs-secret-sharing-scheme-ea83a888f033
Pros and Cons
- Can reconstruct a secret if you lose it.
- So can other people who collect enough shares.
Proxy Reencryption
Generate keys to allow a third party to transform encrypted data so someone else can read it, without revealing the data to the third party.
Proxy Reencryption
Notes:
Proxy Reencryption API
fn encrypt(pk, msg) -> ciphertext;
Takes your public key and a message; returns ciphertext.fn decrypt(sk, ciphertext) -> msg;
Takes your private key and a ciphertext; returns the message.fn get_reencryption_key(sk, pk) -> rk;
Takes your private key, and the recipient's public key; returns a reencryption key.fn reencrypt(rk, old_ciphertext) -> new_ciphertext;
Take a reencryption key, and transform ciphertext to be decrypted by new party.
ZK Proofs
How do we do private operations on a public blockchain
and have everyone know that they were done correctly?
Notes:
(we are working on substrate support for these and will use them for protocols)
What is a ZK Proof?
-
A prover wants to convince a verifier that something is true without revealing why it is true.
-
They can be interactive protocols, but mostly we'll be dealing with the non-interactive variety.
What can we show?
-
NP relation:
function(statement, witness) -> bool -
Prover knows a witness for a statement:
-
They want to show that they know it (a proof of knowledge)
-
... Without revealing anything about the witness (ZK)
-
ZK Proof Interface
-
NP relation:
function(statement, witness) -> bool -
prove(statement, witness) -> proof -
verify(statement, proof) -> bool
ZK Proof Example
Example: Schnorr signatures are ZK Proofs
- They show that the prover knows the private key (the discrete log of the public key) without revealing anything about it.
- The statement is the public key and the witness the private key.
zk-SNARK
Zero-Knowledge Succinct Non-interactive Argument of Knowledge
- Zero knowledge - the proof reveals nothing about the witness that was not revealed by the statement itself.
- Succinct - the proof is small
- Proof of knowledge - if you can compute correct proofs of a statement, you should be able to compute a witness for it.
What can we show?
-
NP relation:
function(statement, witness) -> bool-
They want to show that they know it (a proof of knowledge)
-
... Without revealing anything about the witness (ZK)
-
-
With a small proof even if the witness is large (succinctness)
What can we show?
- There are many schemes to produce succinct ZK proofs of knowledge (ZK-SNARKs) for every NP relation.
ZK Proof Scaling
A small amount of data, a ZK proof, and execution time can be used to show properties of a much larger dataset which the verifier doesn't need to know.
Scaling via ZK Proofs in Blockchain
- Large amount of data - a blockchain
- Verifier is e.g. an app on a mobile phone
Notes:
e.g. Mina do a blockchain with a constant size proof (of correctness of execution and consensus) using recursive SNARKs.
Scaling via ZK Proofs in Blockchain
-
The verifier is a blockchain: very expensive data and computation costs.
-
Layer 2s using ZK rollups
Notes:
Of which Ethereum has many, ZKsync, ZKEVM etc. Polkadot already scales better!
Privacy
A user has private data, but we can show
publicly that this private data is correctly used.
An example would a private cryptocurrency:
- Keep who pays who secret
- Keep amounts secret,
But show they are positive!
Notes:
You can do some of keeping amounts secret without ZK-SNARKs, but the positive part is difficult. To do everything well, ZK-SNARKs are needed in e.g. ZCash and its many derivatives e.g. Manta.
Practical Considerations
-
Very powerful primitive
-
Useful for both scaling and privacy
-
One can design many protocols with ZK Proofs that wouldn't otherwise be possible
Downside
- Slow prover time for general computation
- To be fast, need to hand optimize
- Very weird computation model:
Non-deterministic arithmetic circuits
Downsides Conclusion?
- So if you want to use this for a component,
expect a team of skilled people to work for at least a year on it... - But if you are watching this 5 years later,
people have built tools to make it less painful.
Succinct Proving
with Cryptography?
- ZK friendly hashes
- Non-hashed based data structures
- RSA accumulators
- Polynomial commitment based
(Verkle trees)
Summary
- VRF: Private randomness that is later publicly verifiable
- Erasure Coding: Making data robust against losses with redundancy
- Shamir Secret Sharing: Redundancy for your secrets.
- Proxy Re-encryption: Allow access to your data with cryptography.
- ZK Proofs: Just magic, but expensive magic
Questions
Cryptography In Context
How to use the slides - Full screen (new tab)
Cryptography in Context
Outline
- Keeping Secrets Secret
- Security and Usability
Secrets
What is a secret in cryptography?
Data that you know, that nobody else knows.
How Secrets Stay Secret
In order for a cryptographic secret to stay secret, the only thing about it that can be revealed is the output of known, secured cryptographic operations.
- A (sufficiently random) secret can be hashed, and the hash revealed.
- A private key can be used to generate a public key, and the public key revealed.
- A private key can be used to generate a signature, and the signature revealed.
How Secrets Get Leaked
- Inadvertently leaking information about the secret during normal operation.
- Compromised digital or physical security leading to private key loss.
Notes:
Let's go over each of these in order.
Bad Randomness
Some algorithms require randomness. If the randomness is compromised, the private key or encrypted message can possibly be exposed.
Notes:
Side Channel Attacks
A side channel attack is when a cryptographic system is attacked, and the attacker has another source of information outputted by the system.
Timing Attacks
A timing attack can be possible if any of the following
depend on the contents of a secret:
- Which instructions execute
- Branching (if statements)
- Memory access patterns
Notes:
There are many crazy forms of side channel attack, but the primary one is timing. Timing is also the only one that gets reliably sent back over a long distance.
An Example
Imagine this is the source code for a password checker:
#![allow(unused)] fn main() { fn verify_password(actual: &[u8], entered: &[u8]) -> bool { if actual.len() != entered.len() { return false; } for i in 0..actual.len() { if entered.get(i) != actual.get(i) { return false; } } true } }
What's the problem?
Notes:
Imagine you compile this into a little binary, and you are able to hit it repeatedly. When sending a guess into this, what information do you get back?
A boolean, and the amount of time from sending the password to getting back a response.
The problem is that the amount of time for a response reveals information about the password. An attacker can send in guesses repeatedly, and if it takes a longer amount of time to respond, that means more of the guess is correct.
Example (Cont)
What if we changed the code to look like this?
#![allow(unused)] fn main() { fn verify_password(actual: &[u8], entered: &[u8]) -> bool { actual == entered } }
Is this safe?
Notes: Now, we don't see any difference in the amount of lines of code or loops, right?
Example (Cont)
What does the source code look like?
#![allow(unused)] fn main() { // Use memcmp for bytewise equality when the types allow impl<A, B> SlicePartialEq<B> for [A] where A: BytewiseEq<B>, { fn equal(&self, other: &[B]) -> bool { if self.len() != other.len() { return false; } // SAFETY: `self` and `other` are references and are thus guaranteed to be valid. // The two slices have been checked to have the same size above. unsafe { let size = mem::size_of_val(self); memcmp(self.as_ptr() as *const u8, other.as_ptr() as *const u8, size) == 0 } } } }
Is this safe?
Notes:
Ok, still no. It looks like now the attacker can still figure out if the length of the password based on an early return. But what if we make sure all passwords are 16 bytes long. Now we are just using a single syscall. Is is safe then?
Example (Cont)
Let's check on memcmp.
memcmp(3) — Linux manual page
/* snip */
NOTES
Do not use memcmp() to compare security critical data, such as
cryptographic secrets, because the required CPU time depends on
the number of equal bytes. Instead, a function that performs
comparisons in constant time is required. Some operating systems
provide such a function (e.g., NetBSD's consttime_memequal()),
but no such function is specified in POSIX. On Linux, it may be
necessary to implement such a function oneself.
So how could we do it?
This is from the subtle crate, which provides constant time equality.
#![allow(unused)] fn main() { impl<T: ConstantTimeEq> ConstantTimeEq for [T] { /// Check whether two slices of `ConstantTimeEq` types are equal. /// /// # Note /// /// This function short-circuits if the lengths of the input slices /// are different. Otherwise, it should execute in time independent /// of the slice contents. /* snip */ #[inline] fn ct_eq(&self, _rhs: &[T]) -> Choice { let len = self.len(); // Short-circuit on the *lengths* of the slices, not their // contents. if len != _rhs.len() { return Choice::from(0); } // This loop shouldn't be shortcircuitable, since the compiler // shouldn't be able to reason about the value of the `u8` // unwrapped from the `ct_eq` result. let mut x = 1u8; for (ai, bi) in self.iter().zip(_rhs.iter()) { x &= ai.ct_eq(bi).unwrap_u8(); } x.into() } } }
Notes:
Now we've seen how hard it can be just to stop a very simple leak of timing information. Let's see what an actual cryptographic library concerns itself with.
Ed25519's Guarantees
This is an excerpt from the ed25519 description.
- Foolproof session keys. Signatures are generated deterministically; key generation consumes new randomness but new signatures do not. This is not only a speed feature but also a security feature.
- Collision resilience. Hash-function collisions do not break this system. This adds a layer of defense against the possibility of weakness in the selected hash function.
Ed25519's Guarantees (Cont.)
- No secret array indices. The software never reads or writes data from secret addresses in RAM; the pattern of addresses is completely predictable. The software is therefore immune to cache-timing attacks, hyperthreading attacks, and other side-channel attacks that rely on leakage of addresses through the CPU cache.
- No secret branch conditions. The software never performs conditional branches based on secret data; the pattern of jumps is completely predictable. The software is therefore immune to side-channel attacks that rely on leakage of information through the branch-prediction unit.
Takeway
Preventing side channel attacks is hard! Noticing sidechannel attacks is even harder!
DO NOT ROLL YOUR OWN CRYPTO
Notes:
Be very, very careful whenever you do anything that touches a secret. That includes any operation involving the secret, or reading/writing it somewhere.
When necessary, talk to a security expert or cryptographer.
Using Cryptographic Libraries Safely
- Stay above the abstraction barrier
- Validate each primitive's assumptions when combining primitives
- Use the most reputable library you can
- Realize when things need serious consideration
- Some potentially scary terms: Curve point, padding schemes, IV, twisted curve, pairings, ElGamal
Notes:
Reputableness of a library is some combination of:
- used by many people
- audited for security
- reliable cryptographic literature
- minimal external dependencies
- recommended by cryptographers
If you get low-level enough in cryptography libraries to see these terms referenced in more than just a description, you're probably too low level.
Horror Stories
Notes:
Only go through a few of these based on interest and remaining time.
---v
PS3 Secret Key Leak
Problem: Bad randomness
Description: The ps3 developers didn't use randomness when signing with an algorithm that required randomness.
Consequence: Every PS3 was hardcoded to trust that key. When hackers got the key, they were then able to pretend to be Sony and write any software that ran on the PS3. In practice, it made running pirated games trivial.
Notes:
---v
IOTA's Novel Hash Function
Problem: Rolling your own crypto
Description: IOTA was a cryptocurrency with a value of 1.9B at the time. They wrote their own hash function, and researchers found severe vulnerabilities.
Consequence: Kind security researchers reported the flaw directly to devs. They had to pause the blockchain for 3 days, generate new address for all accounts, and swap to KECCAK.
Notes:
IOTA originally rolled their own hash function in an effort to be quantum-proof.
Some hash function weaknesses are weak. This was not. The proof of concept exploit literally found two hashes that correspond to a message for the blockchain sending a small amount of currency, and another that corresponded to a message sending a huge amount of money.
---v
How the NSA wiretapped all cellphone calls for years
Problem: Small key space / secret technique
Description: The standard for cellphone calls up until the mid-late 2000s (GSM A5/1) used 54-bit keys, and the method was meant to be secret. It did not stay secret, and became extremely easily crackable.
Consequence: Intelligence agencies could and did easily wiretap calls. There were many brute-force attacks against the key space.
Notes:
When the standardization process started, professors proposed 128-bit keys. Western european (british especially) intelligence agencies wanted weaker security. Snowden eventually came out and said the NSA could easily read A5/1 calls.
article source source on weakening
---v
Why HTTPS isn't as secure as you'd hope
Problem: Cryptographic primitive assumptions not upheld
Description: Encryption does not generally hide the length of the underlying message. HTTPS often uses compression before encryption. The compression makes duplicated strings smaller.
Consequence: An exploit called BREACH can reveal a secret from an HTTPS-protected website in under 30 seconds. All websites have had to add mitigation to offset this attack.
Notes:
Mitigation looks like:
- randomizing size of response content after compression
- separating secrest from user input
- disabling HTTP compression (this is expensive though)
- randomizing secrets per request
Physical Security
Notes:
Source is a classic XKCD comic.
Physical Security
Full physical access to a running computer can usually let an attacker have full access to your secrets with enough effort.
Some possible means:
- Scanning all disk storage
- Take out the RAM and swap it into a different computer to read (cold boot attack)
- Proximate side-channel attacks
- RF emissions
- Power consumption
- Sound of a computer running
Notes:
Sources for exotic attacks:
- general survey of EM side channel attacks
- sound-based attack
- EM side channel attack from 15m with 500 traces only
HSMs
An HSM is a hardware security module. HSMs can make it much harder to impossible to steal cryptographic keys. An HSM will hold cryptographic keys, and perform operations on them.
Notes:
We don't go into this much, as there are many available resources around physical security and HSMs. This is just bringing up the ideas, in the context of what makes a cryptographic secret actually secret.
Security and Usability
The accessibility of a secret is typically inversely proportional to the security.
Making a secret more secure is often impractical, depending on the usage.
Notes:
This is not explicitly true in all cases, but it is a good rule of thumb. Additionally, note that impractical != impossible.
Thought Experiment
Suppose I give you a secret that's too long to memorize.
At the end of a year, if nobody else knows the secret, I'll give you a million dollars.
What do you do?
Thought Experiment
Suppose I give you a secret that's too long to memorize.
At the end of a year, if nobody else knows the secret, I'll give you a million dollars.
What do you do?
Destroy it
Thought Experiment
Suppose I give you a secret that's too long to memorize.
At the end of a year, if nobody else knows the secret and you present me the secret, I'll give you a million dollars.
What do you do?
Thought Experiment
Suppose I give you a secret that's too long to memorize.
At the end of a year, if nobody else knows the secret and you present me the secret, I'll give you a million dollars.
What do you do?
Hide it somewhere secure
Notes: Like a bank vault, box buried in the woods, etc
Thought Experiment
Suppose I give you a secret that's too long to memorize.
At the end of a year, if nobody else knows the secret and you present me the secret once per month, I'll give you a million dollars.
What do you do?
Thought Experiment
Suppose I give you a secret that's too long to memorize.
At the end of a year, if nobody else knows the secret and you present me the secret every day, I'll give you a million dollars.
What do you do?
Application to Cryptographic Secrets
Cryptographic secrets are easy to have multiple of.
So don't make users use the same one for everything!
As much as possible, one root secret shouldn't be both used regularly, and extremely valuable.
Questions
🪙 Economics and Game Theory
Applied economics and game theory fundamental to the architecture and operation of web3 applications.
Learning Outcomes
Completing this module will enable you to:
- Understand and discuss the basic principles of economics, including the influence of incentives on human behavior, supply and demand, the value of time, and the role of prices in allocating resources.
- Analyze and comprehend the principles of game theory, including strategic games, Nash equilibrium, and the role of incentives in shaping outcomes.
- Understand and apply the concepts of price discovery mechanisms and their implications in various market settings.
- Understand the principles of collective decision-making, including voting systems, group decision-making processes, and the role of consensus in collective decisions.
Economics Basics
How to use the slides - Full screen (new tab)
Economics Module
Overview
- Economics Basics
- Game Theory Basics
- Price Finding Mechanisms
- Collective Decision Making
Notes:
- Focus on the pure economic concepts and not diving into blockchain yet.
- That is covered by another lecture doing so.
- Economics of polkadot for the founders track later.
- Interactive: Ask questions!
Economics Basics
Cryptography
- Provides assurances about the conduct of machines
- Objective in nature
- Promotes deterministic actions
- Serves as a toolbox to secure certain actions in the digital world.
Economics
- Offers predictions about the actions of people
- Intrinsically subjective
- Driven by individual preferences
- Serves as a toolbox to understand which actions humans are likely to undertake.
🤖$~~~$ 🤝 $~~~$👪
Notes:
- Cryptography would be meaningless without humans using it.
- Crypto & Econ pair well! Together they are the toolbox to design unstoppable systems.
- They have a great symphony: where cryptography's has boundaries, economics offers solutions and vice versa.
Why are economic concepts
important?
- help make better decisions in daily- and professional life.
- model & reason about how others make decisions.
- better understand (crypto-)economic protocols.
- understand the broader context of web3/blockchain.
Notes:
- It is also important to understand the limits of these economic concepts and when they might not work as intended.
Outline
- Lesson
- Incentives: What motivates others to do things?
- Demand & Supply: Market Equilibrium, Influences, and Elasticity.
- Market Forms: Monopoly, Oligopoly, and Perfect Competition.
- Economics of Specialization: Comparative Advantage, Opportunity Costs, Gains from Trade.
- Time as Ultimate Resource: The interaction between Time and Value.
- Behavioral Biases: Where human decision making might be different than traditional economic theories predict.
- Discussion & Workshop
- Discussions to foster and apply concepts we learned.
- Hands-on applications.
Guiding Human Behavior
An incentive is a bullet, a key:
an often tiny object with astonishing power to change a situation.
-- Steven Levitt --
Notes:
- Human behavior is driven by incentives.
- The aggregation of these behaviors lead to societies.
- Carefully designing incentives lays the ground for functioning systems.
- You might be asked to implement certain protocols, which you have to judge if they make sense / can be improved.
Understanding Incentives
- Motivate individuals or groups to perform certain actions.
- Historically, incentives were designed to influence human behavior both on a macroeconomic and microeconomic level.
- Most commonly, people refer to money, that fall under the umbrella of extrinsic incentives.
- But not all incentives are monetary!
Different Types of Economic Incentives
- In a workplace setting (microeconomic level), employees are often motivated by various forms of economic incentives:
- Flat Rate: A fixed amount of salary irrespective of performance.
- Piece Rate: Pay based on the quantity of output produced.
- Bonus: Additional rewards for excellent performance.
- Relative Incentives: Rewards relative to the performance of others (competitive incentives).
Notes:
- Question: What are the advantages / disadvantages of those incentives?
Rationality in Economics
- Economic theories often assume rationality, implying that actors:
- Are primarily driven by monetary gains (payoff maximization).
- Act in self-interest.
- Have unlimited cognitive resources.
- Remark: In this, all factors can be translated into monetary terms.
Incentives often work well
- Interest rates set by central banks.
- Lower rates: Encourage borrowing and investing.
- Higher rates: Slow down inflation and stabilize the economy.
Incentives can Backfire
- In India during British rule, the British Government was concerned about the large number of venomous Cobras.
- They offered a bounty for every dead cobra.
- People started to breed cobras at home to sell them.
- Once the government stopped the program, breeders released the cobras causing larger numbers than before.
Goodhart's Law
When a measure becomes a target, it ceases to be a good measure
Crowding Out
- In Haifa (Israel) parents often got their kids late from day care.
- This caused childcare workers frustration.
- Idea: fine parents for getting their kids late.
- The program was rolled out in some day cares and not others.
- Traditional economic theory:
- Less or at least equally many late parents.
- BUT: The opposite happened, the number of late parents even increased.
- After the fine was abolished, parents still were more late.
- Extrinsic motivation can crowd out intrinsic motivation.
Notes:
- Question: Why did that happen?
- Gneezy & Rustichini (2000): A fine is a price.
The Power of Intrinsic Incentives
- Beyond monetary gain, people are also motivated by intrinsic factors.
- Social preferences (Reciprocity, Fairness, Social Norms, Inequality Aversion, Altruism).
- Personal morals, and deeply-held beliefs.
- Economic models often fail to account for these motivations, leading to unexpected outcomes in real-world applications.
From Humans to Automated Agents
- The digital age emphasizes the importance of automated actors in our economic systems.
- Algorithms and bots, respond to incentives, often financial ones, automatically.
- This shifts the application of incentives beyond a human context and into the realm of digital systems and automated processes.
Notes:
- Still, not always financial incentives - reputation scores
- While automated agents existed for a while, they become much more accessible for everybody due to blockchain technology
- Your electric car might soon have a wallet that automatically pays for charging at a red light.
- Or you might be able to pay for priority green lights.
Conclusion
- Incentives continue to be fundamental to interactions in society, whether among humans or between automated systems.
- As we understand more about incentives in different contexts, we can better design them to influence behavior effectively.
- Intrinsic motivations remain important, but in certain contexts, like automated systems, monetary incentives also play a significant role.
- The challenge is to balance these factors to achieve the desired outcomes.
Demand & Supply: The Pillars of Market Equilibrium
- A common model to help predict and rationalize the price
which emerges from a market. - Can be used to (gu)estimate the quantity
of produced goods vs. their market prices.
Notes:
- A famous artist dies and her art increases in price.
- An unusually nice summer reduces hotel prices in popular vacations destinations.
Law of Demand: A Basic Principle
- When prices increase, quantity demanded of a good (generally) decreases.
Notes:
- Question: Anybody know exceptions?
- Exception are "Veblen goods" where demand increases when price increases. These are typically luxury goods that signal something (e.g. status, reputation) in addition to being useful to consumption. Examples are jewelry, luxury cars, etc.
- This is not a contradiction to the law of demand because the good's social value depends on the price; i.e., the good "changes" and becomes more desirable as the price increases.
Visualizing Demand: The Demand Curve
Notes:
- Question: What influences the aggregate market demand?
- The market demand is the sum of all individual curves.
Influences on demand?
- Price (Demand moves along the curve)
- Size of consumer base
- Average disposable income of consumer base
- Price of substitution goods
- Preferences prevalent within consumer base
- Expectations prevalent within consumer base
Notes:
- In the ice cream example, a substitution good could be frozen yoghurt: if its price goes down, the demand for ice cream will decrease.
- If people's appetite for ice cream increases (perhaps via advertisement), the demand will increase.
- In people expect a shortage of ice cream in the near future, the demand will increase immediately.
Moving the demand curve
Law of Supply: The Other Side of the Coin
- If the price of a good increases, the quantity supplied also increases
(because suppliers can make more profit!).
Notes:
- That is, assuming that suppliers manage to sell all produced goods at said price.
- For example, if the ice cream price increases the store will hire a second employee to sell more scoops per hour.
- As another example, some petroleum deposits are easier and cheaper to extract than others, so some deposits will be extracted only if the oil price is above a certain threshold.
Demand and Supply Interplay: Market Equilibrium
- What happens when Price is higher than the Eq. Price?
- What if the Quantity is lower than the Eq. Quantity?
- Moving either supply or demand leads to new Eq.
Notes:
- Where the curves meet we obtain a point of equilibrium, which establishes a market quantity and a market price.
- If price is higher than equilibrium price, there is more supply than demand, so some goods remain unsold, and sellers will be forced to reduce the price to get rid of their stock. Similarly if the price is lower than equilibrium price, there is more demand than supply, which leads to shortages of the good; sellers will notice this and increase the price. Hence, we always converge to the equilibrium price.
- Similarly, if the quantity supplied is too low, there is a business opportunity to supply more unit of the good and make a profit, so eventually someone will increase the supply quantity.
Elasticity
- Measures how much buyers and sellers respond to changes in market conditions.
- Sensitivity of quantity demanded or supplied to changes in price.
- High elasticity: small price changes have large impact on quantity demanded or supplied.
- Low elasticity (== inelasticity): price changes do not affect quantity demanded or supplied.
Notes:
- Draw a diagram with price on y and quantity on x and draw an almost vertical line tilted towards the left.
- Demand for Gasoline. Low elasticity: If price goes up people buy only a little less, if price goes up they only buy a little more.
- High Elasticity: luxury goods, where buyers can easily adjust their consumption.
- Low Elasticity: essential goods such as energy / medicine.
Conclusion: The Dynamics of Demand and Supply
- Demand/supply model forces in markets and can be used to estimate equilibrium quantity/price.
- All other things being equal:
- demand decreases with increasing price.
- supply increases with increasing price.
- There are different factors influencing supply & demand curves.
- Elasticity.
- Some shift the equilibrium on the curve.
- Others move the entire curves.
Market forms
(Or: why monopoly bad?)
- Typically, economists distinguish between three market forms.
- Perfect competition: Many firms, many consumers.
- Oligopoly: Few firms, many consumers.
- Monopoly: One firm, many consumers.
- The more competition a firm faces, the less market power it has.
- Market power: ability to affect the price (through choosing a certain production level).
Notes:
- Special form of Oligopoly is the Duopoly with two firms, something that we see later.
Market Form Examples
- Monopoly:
- Postal services in many European countries.
- Railway services in many European countries.
- Oligopoly:
- Cloud provider (AWS, Google, ...)
- Mobile phone service.
- Perfect Competition:
- Consumer products with low barrier to entry (e.g., kebab stand in Berlin, espresso bar in Italy)
Why discuss this?
- Current web2 landscape consists of several firms with a lot of market power in their respective market segment.
- We want to understand, from an economic perspective, why too much market power is not a good thing.
Perfect Competition
- Under perfect competition ...
- there are so many firms that a single firm's production quantity does not affect market price.
- the marginal costs (cost of one additional unit) of production equals the market price.
- firms have 0 profit.
Notes:
- This makes sense: The firm produces up to the point where an additional unit costs exactly what it gets for it on the market.
- Notice that having the market price be equal to the marginal production costs is pretty surprising, as it is ideal from a point of view of society welfare, even though every firm is acting selfishly.
- In this perfect world, firms will have zero economic profit, meaning they make just enough money to cover production costs and keep the company running.
Monopoly
- Monopolist: single seller of the good or service, serves the entire market.
- Market characterized by a high barrier of entry (e.g. big investment, legal restrictions).
- Monopolist is therefore sole price-setter and serves only to maximize their own profits.
- This leads to sub-optimal pricing and sub-optimal society welfare: consumers either pay more than they should ("monopolist tax") or are excluded from market.
Oligopolies
- Oligopolies are somewhere between monopolies and perfect competition.
- Because of the competition between firms
- prices are lower, and
- overall market participation is higher.
What did we learn?
- Markets differ in how much market power the firms possess.
- Economics typically distinguishes between three forms (ordered by increasing market power):
- Perfect competition: many firms in the market.
- Oligopoly: few firms in the market.
- Monopoly: one firm in the market.
- The problem of monopoly is the result of an inefficiently high price.
Economics of Specialization
(or: why bother trading at all?)
It is the maxim of every prudent master of a family, never to attempt to make at home what it will cost him more to make than to buy.
-- Adam Smith, 1776 --
Notes:
- In this part, we take a closer look at the following concepts:
- Comparative advantage.
- Opportunity costs.
- Gains from trade.
The economic question
- Empirical puzzle: many countries trade even though one has an absolute advantage in producing many of the traded goods.
- E.g., the US is well-equipped to cheaply produce both
- complex computer chips, and
- agricultural goods (e.g., potatoes).
- However, the US specializes in producing the former and importing many agricultural goods.
- Question: Why do countries specialize; why do they trade?
Comparative advantage
- Consider the following example:
- Suppose Alice can produce 10kg of meat and 20kg of potatoes per hour.
- Suppose Bob can produce 2kg of meat and 10kg of potatoes per hour.
- Alice has an absolute advantage over Bob at producing both goods.
- BUT, Alice has only a comparative advantage over Bob at producing meat.
- Alice has lower opportunity costs of producing meat (in terms of foregone potatoes).
- That is, to produce one kg of meat Alice gives up much less produced potatoes than Bob would.
- By the same observation, Bob has a comparative advantage at producing potatoes.
Notes:
- Comparative advantage of meat:
- Opp. cost Alice: 1kg meat = 2kg potatoes
- Opp. cost Bob: 1kg meat = 5kg potatoes
- Comparative advantage of potatoes:
- Opp. cost Alice: 1kg potatoes = 1/2kg meat
- Opp. cost Bob: 1kg potatoes = 1/5kg meat
Comparative advantage II
- If both focus on their comparative advantage, then total welfare is higher than in a situation of autarky!
- Why?
- Suppose both require both meat and potatoes.
- Situation A - Autarky: both divide their time equally between producing meat and producing potatoes.
- Situation B - Trade: Alice focuses most of her time to produce meat and some to produce potatoes, while Bob focuses only on producing potatoes.
- Total production of meat and potatoes is higher in Situation B!
- Specialization result: With trade, both are both better off than in Situation A.
Notes:
-
Assume one working day with one worker (8 hrs).
-
Autarky:
- Alice: 4hrs _ 10 meat, 4hrs _ 20 potatoes = 40 meat, 80 potatoes
- Bob: 4hrs _ 2 meat, 4hrs _ 10 potatoes = 8 meat, 40 potatoes
-
Trade:
- Alice: 5hrs _ 10 meat, 3hrs _ 20 potatoes = 50 meat, 60 potatoes
- Bob: 0hrs _ 2 meat, 8hrs _ 10 potatoes = 0 meat, 80 potatoes
- Alice could trade 9 meat for 30 potatoes:
- Alice: 41 meat, 90 potatoes
- Bob: 9 meat, 50 potatoes
Absolute vs Comparative Advantage
- Alice can produce both meat and potatoes more efficiently than Bob - this is an absolute advantage.
- However, the choice to specialize isn't just about absolute production efficiency.
- What matters for trade is which good Alice can produce at a lower opportunity cost - this is comparative advantage.
Notes:
- What does that tell us about daily life?
- Stick with what you are good at: It's often good to stick things where you have a comparative advantage: For example, assume you are a great software engineer with a job that has a high salary, but you also want to help clean up the ocean. Instead of giving up your job and go clean the ocean, you might want to allocate some of your salary to ocean cleanup, having a larger effect.
- Realize that absolute advantage is not allOnly because one co-worker has a total advantage in two dimensions of the job, another co worker can still have the comparative advantage in one of the tasks.
- Question: What are your opportunity costs of being here?
Time: The Ultimate Resource
- Time is the one resource that is uniformly distributed and yet cannot be accumulated or saved for later.
- It's always moving, never at rest.
- This unique property of time lends it incredible implications.
- This concept has big impact in the context of money and finance.
The Relationship of Time and Money
- Money now is worth more than the same amount in the future.
- Why?
- Again, opportunity costs: The money at hand now could be invested, potentially earning more money.
- This potential earning capacity bestows more value to present money over future money.
Present Value: The Value of Now
- Present Value brings some future value back to the present moment.
- It estimates what value would make you indifferent between getting some value now vs. later.
- It reflects the worth of a future promise in today's terms, based on the potential earnings we could achieve now.
Notes:
- There are formulas to calculate how much a future payout in the future is worth today.
- You need to make assumptions about your rate of return in the meantime.
- Often risk free rate is used.
Time Value of Money: A Guiding Principle
- It underlines the importance of wise decisions today for a brighter tomorrow.
- It shows that nothing is for free. You always give up something.
- It's a fundamental cornerstone guiding personal savings, investments, and wide-ranging financial decisions.
Behavioral Biases
- Behavioral biases are systematic errors in decision-making when people use mental shortcuts (heuristics) to process information and make judgments.
- For a long time economic theory was built on the assumption that all actors are rational.
- No regard for fairness, altruism, equality.
- All available information is considered.
- No influence of emotions.
- This works well in many circumstances (e.g., on an aggregate level or assuming highly rational actors like firms executives) but in many it doesn't.
- Most humans are prone to behavioral biases and are influenced by social preferences.
Behavioral Economics
- Behavioral economics is mainly concerned with the bounds of rationality of economic agents.
- Influenced by psychological aspects such as emotions, cognition as well as cultural and societal factors.
- Psychologist Daniel Kahnemann received the 2002 Nobel Prize for Prospect Theory, a fundamental theory in Behavioral Economics.
- PT models the fact that individuals assess their losses differently than their gains.
Behavioral Economics
- Behavior is not random!
- Key behavioral biases include:
- Confirmation Bias - Decision makers focus on information that cater to their prior belief / opinion and neglect other information.
- Sunk Cost Fallacy - Instead of cutting losses, decision makers continue to pour resources into a failed endeavour.
- Herding Effect - People follow the crowd without making their own informed decision.
- Gambler's Fallacy - In many situations probabilities of repeated events are independent from each other. Often decision makers fail to understand this.
- Default Effect - People tend to stick with pre-selected choices.
- Overconfidence - People overestimate their abilities.
- Any other biases you know?
Notes:
- Confirmation bias especially pronounced in todays time where people get trapped in echo chambers fostered by algorithms that keep feeding you information that you want to hear.
- Overconfidence: If asked, more than 50% of people think they drive above average. BUT has also positive effects. Sometimes overconfident people are better than others and statistically perform better in practice.
- Anchoring Effect
- Endowment Effect: This bias occurs when we overvalue something simply because we own it.
- Hindsight Bias - This is the tendency to believe, after an outcome is already known, that you would have predicted or could have foreseen the outcome. It is often referred to as the "I knew it all along" effect.
- Availability Bias - People make decisions based on the information that is readily available to them, rather than the complete data set. This bias can often lead to inaccurate conclusions.
Behavioral Economics
Simply put, the stock market is a creation of man and therefore reflects human idiosyncrasy.
-- Ralph Nelson Elliott --
Break (10 minutes)
Classroom Discussions
Notes:
- Roughly 20 minutes
Behavioral Biases
- Which biases might be responsible for the following situations?
- How can we mitigate the impact of those biases?
Situation 1:
Warren Buffett announces that he increased his exposure to Apple by buying more stocks. The price of AAPL goes up.
Notes:
- Herding effect
- Cannot be in the hope of a price response by Buffett's trade because it already happened.
- Self-fulfilling prophecy
- Maybe still rational?
Situation 2:
A stock investor bought a big position in Disney at around 100 USD per share. Then, the scandal unfolds and the price plummets. The investor keeps buying in at 80 USD, 50 USD and finally at 5 USD, 3 USD and 1 USD. When a friend asks him to stop he keeps arguing to recover the losses by "buying the dip" and to "further reducing the average buying price".
Notes:
- Sunk Cost Fallacy
- Learn to accept losses
Situation 3:
Peter wants to buy a new smartphone and fancies the new iPhone. Mentally, he is already looking forward to finally buy it, but a friend urges him to do some more research. He agrees and is reading through articles that pop up after googling "Why you should buy the new iPhone".
Notes:
- Confirmation Bias
- Mitigating by actively looking outside the echo-chamber that is just catering to your opinion.
Situation 4:
A Swiss energy company could increase the number of new renewable electricity contracts from 3% to 80-90% by pre-selecting the green option when customers were renewing their energy contracts.
Notes:
- Default effect
- Is it always good? People might consume more energy because they feel better about their contract, companies can exploit this effect "default to accept all cookies".
- https://www.bbc.com/news/science-environment-56361970
- Paper
Titan Submersible Incident
- On 18 June 2023, Titan, a submersible operated by American tourism company OceanGate, imploded during an expedition to the Titanic wreck.

Titan Submersible Incident
- On board were Stockton Rush (OceanGate CEO), Paul-Henri Nargeolet (deep sea explorer), Hamish Harding and Shahzada Dawood (billionaire businessmen), and Suleman Dawood (Shahzada's son).
- Communication was lost 1 hour and 45 minutes into the dive and the vessel failed to resurface later that day.
- Four days later, a debris field containing parts of Titan was discovered near the Titanic.
Prior Safety Concerns
- Many industry experts had expressed safety concerns about Titan.
- OceanGate, including CEO Rush, had not sought certification for Titan.
- They published the following blog post to give reasoning:

Notes:
- What biases could be happening here?
- Survivor bias: is the logical error of concentrating on entities that passed a selection process while overlooking those that did not. This can lead to incorrect conclusions because of incomplete data.
- What bias are we facing maybe? Hindsight Bias: is the common tendency for people to perceive past events as having been more predictable than they were.
Where do you see yourself or others suffer from behavioral biases?
Notes:
Open class discussion.
Monopoly
- We have seen: Monopolists' market power leads to inefficient outcomes.
- Web 2.0 is full of firms that have a monopoly-like position in their respective domain:
- Uber
- AirBnb
- ...
- How do these firms exert their market power, if not over price-setting?
Notes:
- transparency? (stealing tips!)
- fees (uber, airbnb)
- surge pricing (uber)
- opaque auction mechanism (google in the case of online ads)
Activities
Academy Games
Activities Today & Tomorrow
- You can earn points by applying the concepts presented in this course to similar situations when playing with/against your colleagues.
- In session 2.1, 2.2 and 2.3, you can increase your budget (starting at 0) during several economic games.
- We have a total budget of $2250 for this.
- The budget is split between all the games that we play and total points earned by all of you are dynamically adjusted to correspond to the budget.
- In 2.3, there is a big final: You can use your earnings to bid for amazing NFTs by a professional artist in an experimental auction setting.
Sign-in
- You will sign in to each of the games with your Polkadot wallet.
- You should always sign in with the same wallet to keep earning points to that wallet.
- Make sure not to forget your wallet credentials, because your final payout / NFT will be tied to that wallet.
Disclaimer
- If a bug occurs and the reward points are messed up or something else goes wrong, we may intervene.
- We cannot help you recovering your Polkadot wallet. If you lose access, you need to create a new account in the games but you will lose previous earnings.
Tracking your payoff
- Your balance is tracked in a wallet app.
- The points are translated to USD after each game.
- You can constantly check your balance by opening the wallet app link and sign in with your wallet.
Notes:
- Completely trusted and centralized xD
- If you leave your cookies you can simply log back in otherwise you need to log in again.
Everybody got a wallet?
Game 1: Ultimatum game
- You are randomly matched with another student in the classroom.
- The interaction is anonymous.
- Player 1 gets an endowment of 100 points.
- Player 1 can offer Player 2 between 0 and 100 points.
- Player 2 sees the offer and can decide to accept or reject the offer.
- If the offer is accepted, the endowment is split according to the offer.
- If the offer is rejected, both get 0 points.
- Budget for the game $500.
- There is no right or wrong here. It is your choice how to behave in this context!
Game 1: Questions?
Let's start!
Link will be distributed!
Game 1: Discussion
- What were your strategies here?
- What do you think we would expect from rational players?
- Why did people offer something?
- What did we measure here?
Notes:
- What would we expect from rational players (they do not know the concept of Nash Equilibrium yet but intuitively they can argue).
- What do you expect the data to look like?
- Did we measure fairness? No.
- How could we measure fairness?
- Dictator game
- Talk about results in the literature:
- Many people offer 40-50%
- Almost nobody offers more than 50%
- Many people reject below 30%
- This is not only because of the stakes. There are experiments in Thailand and Indonesia where they play with half year salary.
Game 1: Results!
Game 2: Cournot Competition
- Economic model
- Firms compete by setting quantities
- Identical product
- Demand always meets supply
- Named after French mathematician Augustin Cournot.
Notes:
- Game 1: Cournot Competition with 2 firms (players from the audience) for 10 rounds
- THe basic outline was given by Antoine Augustin Cournot in 1844, we will hear it again in GT.
Game 2: Overview
- Cournot competition (Duopoly!)
- 2 firms (you play 1 firm!)
- Each of you individually set a quantity to produce.
- All units are sold, but the price decreases in the quantity.
- Repeated over 10 rounds
- Points accumulate and are added to your budget.
- Budget for the game: $500
Game 2: Rules
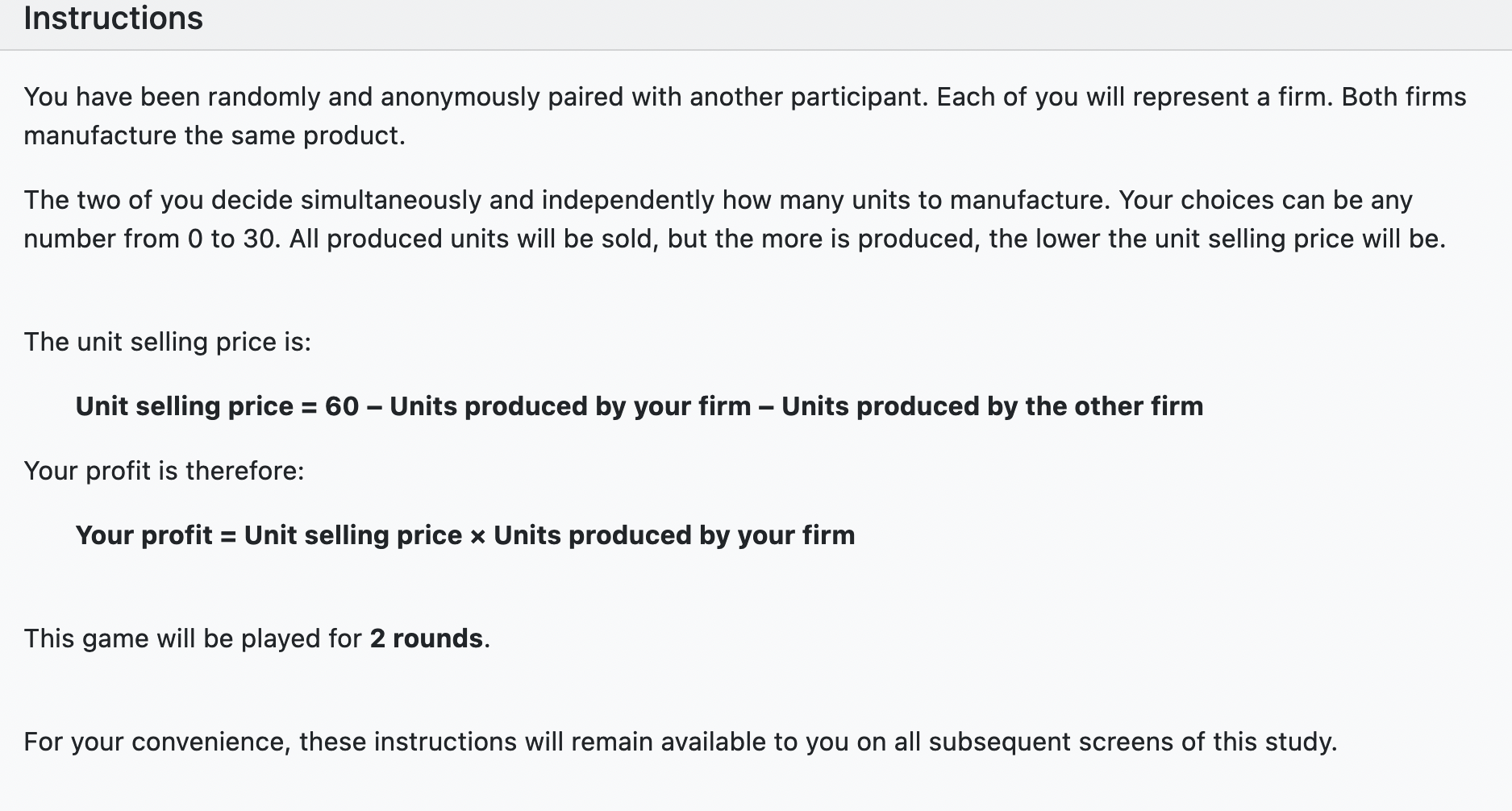
Notes:
- 10 rounds not 2.
Game 2: Questions?
Let's start!
Link will be distributed!
Game 2: Discussions
- What strategy did you employ?
- Did your behavior change over the rounds?
- What was the best choice for each firm?
Notes:
- Calculate equilibrium:
- $\pi = P(Q) * q$
- For Firm 1: $\pi = (60 - q_1 - q_2) * q_1$
- solve for optimal $q_1$ -> delta-pi / delta-q1 = -2q_1 - q_2 + 60 =! 0
- q_1* = (60 - q_2) / 2
- q_2* = (60 - q_1) / 2
- q1* = (60 - (60-q1*)/2) / 2
- = 30 - 15 + (q_1*/4) = q_1*
- = q_1* = q_2* = 20
- Show with example. If firm 1 plays 20 then 19 leads to smaller payoff and 21 for other firm.
Game 2: Results!
Conclusion
We learned:
- fundamental economic concepts that are important to navigate in private- and professional life.
- the notion of rationality and what to expect from actors that behave this way.
- that especially human individuals deviate from rationality and behave differently.
- the importance of time on value.
- to engage in economic situations with other human actors.
Game Theory Basics
How to use the slides - Full screen (new tab)
Game Theory Basics
Notes:
Game theory is a field of study at the intersection of mathematics and economics. It consider an economic system to be a game and people to be players. According to the rules of the game, it analyzes the players' best strategies and then uses this analysis to explain the observed behavior of the economic system.
Game theory is an interesting an powerful tool, because it's fairly simple and intuitive, yet extremely powerful to make predictions. Hence, it's a good idea to learn game theoretical principles and keep them in the back of your mind when designing economic systems.
Outline
- Lesson
- What is Game Theory?
- What is a Game?
- Types of Games
- Common Games
- Nash Equilibrium
- Equilibrium Selection
- Workshop & Activities
- Discussions & more games
What is Game Theory?
Game theory studies strategic situations where the outcome for each participant or 'player' depends on the actions of all others. It formulates models to represent these scenarios and predicts the most likely or optimal outcomes.
Notes:
- Game theory is all about the power of incentives.
- Helps you understand and design systems and guide behavior of participants.
Game Theory in Web3
In the context of blockchains, game theoretic reasoning is used for modelling and understanding.
Notes:
- The term is heavily over-used.
- 9/10 times people using the term they simply mean there is some economic structure behind their protocols.
- Rarely real game theoretic analysis is done.
Modelling
- Tokenomics: Macroeconomic design of a token (inflation, utility, etc.).
- Business Logic: Interaction of the token with different modules of a protocol.
- Consensus: Providing sufficient incentives to guarantee that participating nodes agree on a distributed state of the network.
- Collaboration: Nudging (aggregated) human behavior and their interaction with the protocol.
Understanding
- Economics: Interaction between different protocols and how finite resources are allocated among all of them.
- Security: Testing economic security of protocols against various types of attacks.
History of Game Theory
- Early “game theoretic” considerations going back to ancient times.
- “Game theoretic” research early 19th century, still relevant.
- The systematic study of games with mathematically and logically sound frameworks started in the 20th century.
- Modern game theory is used in economics, biology, sociology, political science, psychology, among others.
- In economics, game theory is used to analyze many different strategic situations like auctions, industrial economics, and business administration.
Notes:
- In Plato's texts, Socrates recalls the following considerations of a commentator of the Battle of Delium:
- An example is a soldier considering his options in battle: if his side is likely to win, his personal contribution might not be essential, but he risks injury or death. If his side is likely to lose, his risk of injury or death increases, and his contribution becomes pointless.
- This reasoning might suggest the soldier is better off fleeing, regardless of the likely outcome of the battle.
- If all soldiers think this way, the battle is certain to be lost.
- The soldiers' anticipation of each other's reasoning can lead to a self-fulfilling prophecy: they might panic and retreat before the enemy even engages, resulting in a defeat.
- Spanish conqueror Cortez, when landing in Mexico with a small force who had good reason to fear their capacity to repel attack from the far more numerous Aztecs, removed the risk that his troops might think their way into a retreat by burning the ships on which they had landed
- Antoine Augustin Cournot, a french mathematician, already described a duopoly game with respective solution in 1844.
- We will see this later.
- Examples:
- Biology: Animals fight for resources or are peaceful, why cooperation evolved
- Political science: Art of conflict, escalation and de-escalation between nations.
Game theory is abstract
- Game theoretic models aim to get at the essence of a given strategic problem.
- This often requires many simplifying assumptions.
- Pro: Abstraction makes the problem amenable to analysis and helps to identify the key incentives at work.
- Con: A certain lack of realism.
- In any case: Modeling a strategic situation always entails a tradeoff between tractability and realism.
Notes:
- Need to explain what we mean by lack of realism:
- Often people have more choices than we model.
- Often people take other things into consideration when making choices than the model allows.
- Often people know more/less than we assume.
- How to resolve the tradeoff between tractability and realism is often subjective and depends on the taste of the modeler.
What is a Game?
Definition: (Economic) Game
- A game is a strategic interaction among several players, that defines common knowledge about the following properties:
- all the possible actions of the players
- all the possible outcomes
- how each combination of actions affects the outcome
- how the players value the different outcomes
Definition: Common Knowledge
- An event $X$ is common knowledge if:
- everyone knows $X$,
- everyone knows that everyone knows $X$,
- everyone knows that everyone knows that everyone knows $X$,
- ... and so on ad infinitum.
Examples: Common Knowledge
Auctions
- Actions: Bids.
- Outcome: Winner and Payment.
Price-competition
between firms
- Actions: Price charged.
- Outcome: Demand for each firm, profit of each firm.
Notes:
Crucial feature of a game: outcome not only depends on own actions but also on the actions of the other players.
Types of games
Game theory distinguishes between:
- static & dynamic games
- complete & incomplete information games
Static and Dynamic Games
| Static Game | Dynamic Game | |
|---|---|---|
| Definition | All players take their actions at the same time | Players move sequentially and possibly multiple times, (at least partially) observing previous actions |
| Simple Example | Rock-Paper-Scissors | Tic-Tac-Toe |
| Economic Example | Sealed-bid auction. | All bidders submit their bids simultaneously (in a sealed envelope). |
| English auction. | Auctioneer publicly raises price if at least one bidder accepts the price. | |
| Representation | Payoff Matrix | Decision Tree |
Notes:
- Also referred to as simultaneous or sequential games
Completeness of Information in Games
| Game of Complete Information | Game of Incomplete Information | |
|---|---|---|
| Information available | All information relevant to decision-making is known. | Not all information relevant to decision-making is known. |
| Simple Example | Chess | Poker |
| Economic Example | Sealed auction for seized Bitcoin. | Used-car market: the resale value of a used car is opaque. |
Notes:
- There is also the notion of perfect and imperfect information which we should skip here. More info: https://economics.stackexchange.com/questions/13292/imperfect-vs-incomplete-information
Quiz
Three firms want to hire an engineer...
- The engineer brings added value to each firm of 300,000 USD per year.
- The payoff of the firm is known by everyone to be 300,000 USD minus the salary.
- The payoff to the engineer is salary minus cost of working, which is known to everyone.
- All firms make a salary offer at the same time.
Quiz Questions:
- Is this game static or dynamic? What would need to change in the description of the game such that it would fall in the other category?
- Is this game of complete or incomplete information? What would need to change in the description of the game such that it would fall in the other category?
Notes:
-
The game is static. For it to be dynamic, firms would need to make offers sequentially, knowing what the firms before had offered.
-
The game is of complete information. To make information incomplete, we would need to have that the value of hiring the engineer differs between firms and is unknown between firms. Or that the cost of working for the engineer is not known to the firms. The point is that we need to have uncertainty over payoffs.
- This lesson focuses on static games of complete information.
- When we look at auctions in lesson Price finding mechanisms, we will also consider games of incomplete information, both dynamic and static.
Utility
- Core concept of Game Theory.
- Can transform any outcome to some value that is comparable.
- For example: What is better? Scenario A: Going for a vacation to France and drink Wine, or Scenario B: going to Germany and drink Beer?
- Those dimensions are only comparable if we give both some value like U(A) = 5, U(B) = 3.
- Essential assumption: Agents are utility maximizers.
- Monetary payouts can also be transformed to utility.
- Simplest assumption U(x) = x.
- But that is likely not true in reality.
- Most things have diminishing rates of returns.
Notes:
- Expected Utility is the average utility we get from comparing several outcomes and weigh them with the probability they occur.
- In the following, we won't need that, because either we deal with money or other dimensions that are comparable.
Common Games
Prisoners' Dilemma
A fundamental problem:
Even though everyone knows there is a socially optimal course of actions, no one will take it because they are rational utility maximizers.
It's a static game of complete information.
Notes:
One of the most famous games studied in game theory.
- Static because both players take their action at the same time.
- Complete because everybody is aware of all the payouts.
Bonnie and Clyde
Bonnie and Clyde are accused of robbing two banks:
- The evidence for the first robbery is overwhelming and will certainly lead to a conviction with two years of jail.
- The evidence for the second robbery is not sufficient and they will be convicted only if at least one of them confesses to it.
Bonnie and Clyde
In the interrogation they both are offered the following:
- If you both confess you both go to jail for 4 years.
- If you do not confess but your partner does, you go to jail for 5 years: 1 extra year for obstruction of justice.
- However, if you confess but your partner does not, we reduce your jail time to one year.
Notes:
They are interrogated in different rooms, apart from each other.
Bonnie and Clyde
- Cooperate ($C$) with each other and not say anything
- Defect ($D$) and confess their crime
Notes:
- They can either cooperate or defect
- First payoff is Clyde, second is Bonnie
Bonnie and Clyde
Choosing D is a dominant strategy: a strategy that is always optimal for a player, regardless of what the other players do.
Notes:
No matter what Clyde does, D is always the best choice. So, they end up both defecting, resulting in 4 years each. It would be in their best interest to cooperate and not to say anything. This would minimize the total jail time for the two. However, both Bonnie and Clyde are rational utility maximizers. So, they end up in a situation where they not only fare worse individually (4 instead of 2) but also jointly (the total jail time is 8 years rather than 4 years).
Nash-Equilibrium
- Fundamental concept in Game Theory
- A NE is a set of strategies, one for each player, such that no player can unilaterally improve their outcome by changing their strategy, assuming that the other player's strategy remains the same.
- In the Prisoner's Dilemma, D/D is the only NE.
Prisoners' Dilemma IRL
- Nuclear Arms Race: NATO and Russia prefer no arms race to an arms race. Yet, having some arms is preferable to having no arms, irrespective of whether the other one is armed.
- OPEC: Limiting oil supply is in the best interest of all. However, given the high price that thus results, everyone has an incentive to increase individual oil supply to maximize profits.
Notes:
OPEC: Organization of the Petroleum Exporting Countries. It is something like a cartel that agree on limiting the global oil production and keep the oil price artificially high.
OPEC and Cartels generally seems to overcome the Prisoners' Dilemma... More on that later.
Ultimatum Game
- We played it before.
- Sequential game.
- The Nash Equilibrium can be reasoned by backwards induction.
- The proposer has the following considerations:
- What would the recipient accept?
- Answer: every payoff (larger than 0).
- Therefore, I should offer, since I want to maximize my payout, something equal or slightly higher than 0.
- That means, the proposer offering something small and the recipient always accepting is the only NE.
Notes:
- We saw that empirically that is not the case.
- Fairness concerns are too strong in that setting.
Coordination Game
- The prediction of play in the Prisoner's Dilemma was easy: both will defect.
- This is the optimal thing to do no matter what the other player does.
- In other games, predictions of play are not so clear.
- One instance is the coordination game.
Coordination Game
A coordination game is a type of static game in which a player will earn a higher payoff when they select the same course of action as another player.
Coordination Game Example
- Choose $L$ or $R$.
- The numbers represent the payoffs a player receives.
- The players only obtain utility if they coordinate their actions.
Notes:
Examples:
- Driving on the right/left side of the road.
- Money adoption.
- Standard adoption.
Coordination Game Example
- The coordination game has two outcomes $(L,L)$ and $(R,R)$ that stand out.
- Clearly, if the other player chooses $L$ ($R$), then it is optimal for the other to do so also.
- So, in the outcomes $(L,L)$ and $(R,R)$ the players choose mutually optimal actions.
Notes:
- That is, for both players it holds:
- Playing $L$ is a best response to the other player playing $L$.
- Playing $R$ is a best response to the other player playing $R$.
Coordination Game Example
- Both $(L,L)$ and $(R,R)$ are instances of Nash equilibrium.
- By their very nature, coordination games always have multiple equilibria.
- The outcome $(D,D)$ in the Prisoner's dilemma is the unique Nash equilibrium.
Notes:
Nash equilibrium: If other players follows the recommended strategy, then the best response for you is to do the same. As the same logic is true for other players, it's reasonable to assume that everybody will indeed follow the recommended strategy.
However, a Nash equilibrium is a weaker notion than a dominant strategy, because if the other players don't follow the recommended strategy, it is not clear what your best response should be.
Equilibrium selection
- So, which outcome does the theory of Nash equilibrium predict in the coordination game?
- None? Both?
- Sometimes people switch between equilibria (if they are made to)...

Sweden, 1967.
Notes:
- The NE does not predict any outcome.
- Sweden switched from left-side driving to right-side.
Schelling Points
- Nash equilibrium does not predict which strategies the players actually take.
- This is especially pronounced in games with multiple equilibria (e.g., coordination games).
- There are theories that offer insights into which strategies players actually take.
Notes:
- In the 1950s American economist Thomas Schelling ran a couple of informal experiments in which he asked his students (quote on slide)
Schelling Points
If you are to meet a stranger in New York City, but you cannot communicate with the person, then when and where will you choose to meet?
- Literally any point and time is a Nash equilibrium...
- However, most people responded: noon at (the information booth at) Grand Central Terminal.
- Basic idea: in case of multiple equilibria, social norms may help to choose one.
Notes:
- Imagine you are held in prison.
- You and your significant other is asked to guess a number.
- If you both guess the same number, you are set free.
- You have the following options: 0.231, 1, or 0.823
- Guessing both the same number is a NE every time.
- It's highly likely you will walk free.
Summary (so far...)
- Typology of games: static/dynamic, complete/incomplete information.
- Three canonical games: Prisoner's Dilemma, Ultimatum-, and Coordination Game.
- The Prisoner's Dilemma has a unique Nash equilibrium, which is dominant, whereas the Coordination game has two Nash equilibria.
- To select among multiple equilibria, the concept of a Schelling Point is sometimes used.
Why are theories of equilibrium important?
- Nash Equilibria are used to predict the behavior of others in a closed system.
- If you can identify a unique Nash Equilibrium or the Schelling point in a system, you have a strong prediction of user behavior.
- So, you can begin to drive user behavior by designing incentives accordingly.
Public Goods
- Non-excludable No-one can be excluded from consumption
- Non-rivalrous My consumption does not affect yours
- e.g., fireworks, street-lighting.
Notes:
- We will now talk about public goods and common goods, which are goods enjoyed by everyone.
- This is, of course, a very important and very tricky class of goods in a collective.
Common Goods
- Non-excludable No-one can be excluded from consumption
- Rivalrous My consumption reduces your possibility to consume
- i.e., a public park, an office coffee machine.
Notes:
- Recall: Public good was non-rivalrous.
Examples:
- Public park: anyone can go; too many people spoil the experience or kills the grass.
- Coffee machine in the office: anyone can use it; too many users may cause congestion or the amount of coffee may be limited.
Public vs.
- Main difference is that in a common good your consumption reduces the value of the good to others.
- This is called a consumption externality that you impose on others (and others impose on you.)
- The tragedy of the commons is that, because you do not take this externality into account, consumption is higher than would be socially optimal.
Stylized Public Good Game:
- $N$ players have 10 US dollars each, say, $N=4$.
- Each player can choose how much to place into a project.
- Funds in the project are magically multiplied by a factor $\alpha$, say, $\alpha=2$.
- Finally, the funds in the project are split equally among all players.
- What would be best for the individual?
- What would be best for the collective?
- As long as $\alpha>1$, it's best for the collective to contribute as much money as possible, because the money in the project increases magically, so we end up with more money that we started with.
- However, the problem is that everyone benefits from the project funds regardless of their individual contribution (it is a common good). If a player decreases their initial contribution by one dollar, their individual payoff decreases by $\alpha/N$ dollars, so as long as $\alpha<N$, it is best for each individual to contribute zero.
- As a result, we can expect that no one will contribute anything, and the money-multiplying powers of the project will be unused. This opportunity cost is a tragedy of the commons.
- Finally, if $\alpha\geq N$ then it would be individually better to contribute everything, and we would not have a tragedy of the commons.
- Fishing gives private benefit but might destroy the broader ecosystem, which has its own value for everyone (e.g., due to tourism).
- Because individual fishermen do not pay for the damage they cause to the broader ecosystem, they will fish too much.
- Producing a good yields private profit but reduces air quality for everyone.
- Because there is no price attached to air quality, the firms do not have to pay for its reduction and, hence, will produce too much.
- There should be fishing/production/mining! After all, there are always benefits to these activities.
- The tragedy of the commons is that the externality is not priced into these activities, driving them to inefficiently high levels.
- Next up class activities.
- Why it might not fail:
- Other incentives:
- Intrinsic motivation
- Reputation concerns (your github history is part of your CV)
- Reciprocity
- Direct benefit: Some contributors also use the software and benefit from improvements.
- Other incentives:
- Need a white board!
- Give Class about 5 minuets to discuss in small groups on this
- Then have 10 minutes to ask the class you solve the 2x2 matrix and discuss (on next slide).
- What is/are the Nash Equilibrium/Equilibria here?
- Which type of games does this remind you of?
- How would you translate this game to real scenarios?
- Game of chicken or Hawk-Dove Game
- "Anti-Coordination Game" with the tension between competition and mutual benefit of compromise.
- Real-world situations of conflict, where both would prefer not to fight but would actually like to intimidate, leading to a real conflict.
- Two businesses would be better off not to engage in price war, but it would be good to be the only one to reduce the price to grab some market share.
- roughly 70 minutes
- We divide the classroom into three groups and play a guessing game.
- The budget for this game is: $250.
- The game is simple: each player enters a number from 1 to 100.
- The player who guessed closest to 2/3 of the average number wins.
- If multiple people win, the payoff is split equally.
- The game is repeated for ten rounds.
- What number did you choose / what was your strategy? (which group were you in?)
- Did your strategy change over time?
- A number above 2/3*100 does not make sense
- If everybody believes that, choosing a number above 2/3*2/3*100 does not make sense
- ... it goes to 0
- But does 0 Win? No!
- Question: Who made these considerations?
- Empirical results:
- Financial Times asked their readers to submit their solution: Winning number was 13 (~1500 participants)
- Other news magazine: ~3700 subjects, winning number 16.99, ~2800 subjects, winning number 14.7
- There were spikes at 33 (response to randomness), 22 (response to that), and 0 (rationality)
- Level-k-thinking: 1 or 2 steps most prevalent, seldom more than that.
- Question: What would be the NE for multiplication of 1 of the mean?
- It becomes a coordination game where all players choose the same value.
- You play a Prisoner's Dilemma (groups of 2) over 10 rounds.
- You will be randomly matched to another student in the class.
- Budget for this game: $500
- You have the option to chat between rounds.
- Important: Keep the chat civil and do not reveal any identifying information about yourself.
- We will read the chat.
- We will play a public good game as presented in the lesson.
- Budget for this game: $500
- Groups of 4 over 10 periods.
- Money in the project is multiplied by factor $1.6$.
- With one additional mechanism: After each round each player sees the contributions of the other players and can decide to deduct points from them (at own costs).
- What was your strategy?
- Were your groups able to sustain cooperation?
- Did you cooperate?
- Did you punish?
- Additional free rider problem: Punishment was fixed to 100% of the other's points. That means, it was better to hope for other players to punish a player.
- They cooperate maybe because they did not understand the game.
- How could we characterize players to types?
- Freerider
- Cooperators
- Altruists
- What do you think happens when playing this ...
- ... for one round?
- ... for many rounds?
- ... when allowing for communication?
- ... with different group sizes?
- One Round: Little contribution.
- Many Rounds: Some little contribution but quickly to 0.
- Some longer and stronger contribution but eventually going to 0 quickly
- Different group sizes: Larger groups are more prone to freeriding, i.e., cooperation collapses more quickly.
- Question: How can we distinguish freerider from those that only freeride because they expect others to freeride?
- Answer: Ask them to provide a "conditional cooperation table" - i.e., they should state how much they contribute given other's /(average) contributions.
- Real freeriders have 0 even if others contribute.
- the basics of game theoretic concepts.
- different types of games.
- how games can be modeled.
- how to apply game theoretic thinking in our decision making in certain games.
- A central topic of economics is price finding in markets.
- How does a buyer and a seller agree on the price of a good?
- As we saw yesterday, a market price must balance supply and demand.
- Demand: number of items bought by consumers at a given price.
- Supply: number of items produced and sold at a given price.
- Supply-demand model works well for big markets.
- We have lots of buyers, sellers, lots of info.
- Predictable market price, balancing supply and demand.
- Only sensible price at which a buyer and seller can trade.
- When a particular good has a large number of buyers and sellers, and we have a well established market with lots of real-life trading data, we can develop a supply-demand model.
- It allows us to accurately predict the price at which the market will converge to for a good, which is the point at which supply and demand balance out.
- It only makes sense to trade at market price: if lower, the seller can easily find another buyer willing to pay more, if higher, the buyer can easily find another seller willing to charge less.
- Gov't sells radio frequencies to broadcasters.
- A painting by a famous artist trades hands.
- An oil well goes on sale with unknown amount of oil.
- The supply-demand model does not work in these examples
- First example: there is a single buyer
- Second example: very few buyers and sellers, trades are very infrequent, and goods are not standardized
- Third example: not enough public data about the good.
- In second and third cases, buyers may have wildly different personal valuations of the good.
- A standardized good could be a liter of milk. A less standardized good is a wedding ring, or a painting
- Selena wants to sell one item of a good.
- Two buyers, Alice and Bob.
- Each buyer has a secret valuation $v_A$ and $v_B$:
how much they are willing to pay for the item. - We consider the limit case of one single seller and two buyers, to keep things simple.
- Throughout the talk we assume that a buyer will purchase the item if the price is below or equal to their valuation.
- All of Selena's income is profit.
- Alice and Bob each have random valuations between 0 and 1.
- The valuations are secret but their distribution is well-known.
- We saw the notion of an abstraction already in game theory class: we lose a bit in realism, but gain in structure which allows us to make precise statements, and develop a richer theory. The intuition and conclusions still apply in real life.
- In particular, we are assuming that each of the three characters has a certain amount of information about the valuations of the other players, namely the distribution they are sampled from, and they can use this info to strategize their actions.
- Assuming that each valuation $v_i$ follows a uniform distribution between 0 and 1 simplifies Selena's life, because she knows that for any value $x\in [0,1]$, the probability that a bidder's valuation is below $x$ is exactly $x$, i.e., $P[v_i\leq x]=x$.
- However, assuming a uniform distribution is just for pedagogical reasons: most results in auction theory can be extended to more general distributions.
- Simplest solution: Selena posts a price $p$, sells item to first taker.
- What is her optimal price $p$? One maximizing her expected revenue.
- Expected revenue: price $\times$ prob. of making a sale.
- For price $p$, prob. of making a sale is $(1-p^2)$.
- Hence her expected revenue is $p \cdot ( 1-p^2)$.
-
If both buyers accept the posted price, we assume the firm selects a random buyer to trade with.
-
The proof of this and all other math formulas can be found in the slides, for anyone interested.
-
Assuming that 100% of the sale price is profit for the seller, this profit is
- $p$ in case of selling, $0$ otherwise, where
- $(1-p^2)$ is the probability of selling the item.
- To see this probability, consider conversely that the probability that none of the buyers accepts the price must be $p^2$, because each valuation must be below $p$, and these are two individual events each happening with probability $p$ (recall: valuations are uniformly distributed between 0 and 1).
-
$Pr{v_i \leq x}$ is the probability that the randomly drawn value of valuation $v_i$ is below $x$.
-
Independent values will be important: when is this (not) a sensible assumption? (Example: oil drilling rights auctions, ...)
-
Uniform distribution is just for pedagogical reasons; standard model allows for more general distributions.
- At the optimum point, expected revenue is $\approx 0.38$.
- We will see that an auction can do better.
- Prices, valuations, and revenue are given in the same currency unit, say, USD.
- How do we maximize the expected revenue function $f(p)=p ( 1-p^2)$? The function has a unique peak, so at the maximum, the first derivative must be zero.
- The function is maximized for a $p$ satisfying $$ f'(p)=1-p^2 - 2p^2 = 0 \implies p = \sqrt{1/3}.$$
- Expected revenue is then $f(\sqrt{1/3})=\frac{2}{3}\sqrt{1/3}\approx 0.38.$
- Auctions can be superior to posting a price.
- We discuss four important auction formats.
- How to make buyers reveal their secret valuations.
- Bid shilling.
- The revenue-equivalence theorem.
- Guides on what auction format to use in practice.
- Auctions can provide more revenue to the seller, as we will see.
- In a market with a posted price, buyers never need to reveal their valuation (i.e., how much they would actually be willing to pay for an item). In auctions, the same is generally true, as they may bid values much lower than their valuations, but there is an auction format where they tend to bid their actual valuations (called truthful bidding).
- There is a specific sense in which, in theory, all four auction formats provide the same revenue for Selena.
- However, in practice, some formats may be better suited than others, and we will see some such examples.
- Alice and Bob (bidders) submit bids based on own valuations.
- Selena (auctioneer) selects winner to allocate the item to.
- The winner's payment is a function of the bids.
- Bidders submit bids to auctioneer, which are a declaration of how much they are willing to pay for the item. In an ideal world, a bid equals the bidder's valuation (this is called a truthful bid), but of course depending on the bidder's strategy they may choose to underbid or overbid.
- In this lesson we will have some fun analyzing the bidders' best strategies as well as the auctioneer's best strategies.
- Both the winner and the winner's payment will dependent on the bids and the auction rules. The payment cannot be higher than the winner's bid, but it could be lower.
- Auctions yield a higher revenue because they create competition among buyers.
- There are two broad classes:
- Static Auctions: bidders submit their bids at the same time.
- Dynamic Auctions: bidders submit bids over time.
- The difference is whether or not bidders can react to the bids of others and adjust their own.
- Static auctions are also called sealed-bid auctions.
- In static auctions, bidders give their bids simultaneously and cannot change it later.
- Static auctions are also called sealed-bid auctions, as many times in practice the bids are submitted in sealed envelopes to the auctioneer.
- Static auctions
- with a first-price payment rule
- with a second-price payment rule
- Dynamic Auctions
- with ascending price (a.k.a. English auctions)
- with descending price (a.k.a. Dutch auction)
- Example, Selena auctions off a painting. Suppose in a static auction, Alice bids 1000 and Bob bids 2000. In a first-price format, Bob wins and pays 2000. In a second-price format, Bob still wins but only pays 1000.
- The English format became popular in England. Selena continuously raises the price as long as at least 2 bidders accept it. As soon as only one bidder remains, they win and pay the current price.
- The Dutch format became popular in the Netherlands, particularly in the tulip market. Selena starts at a high price and continuously lowers it as long as there are no takers. As soon as a bidder accepts the price, they win and pay the current price.
- We are gonna analyze each of these four formats, and take the opportunity to discuss relevant notions in auction theory along the way.
- For me, the second-price auction is the least intuitive format. But it turns out to be one of the nicest and easiest to analyze, so we will start there.
- Why make the winner pay the second highest bid?
- Least intuitive format, but strategically simplest for bidders.
- Simply bid your valuation truthfully!
- A bidder wants to maximize their expected profit:
- own valuation - price paid, in case they win
- zero, otherwise
- Out of the four formats, we start our analysis with second-price static auctions, i.e., Alice and Bob give their bids in sealed envelopes to Selena, and she declares the winner to be the one with the highest bid, but the price to pay is only second highest bid.
- To analyze the bidders' best strategy, we assume that each bidder wants to maximize their expected profit. Again, this is a sensible but strong assumption, as they could have some other equally sensible objectives. By the end of the lesson we will highlight how this assumption can be a bit unrealistic in practice.
- Truthful equilibrium: a dominant strategy to bid truthfully.
- Dominant strategy: outcome is at least as good as the outcome of any other strategy, no matter what the other bidder bids.
- We can immediately say that you should never overbid (i.e., bid above your valuation), because in that case your profit can only be zero (if you lose) or negative (if you win). So the key question is whether you should ever underbid.
- In the case that Bob's bid is higher than your valuation, bidding truthfully or underbidding both lead to losing and having a revenue of zero.
- But if Bob's bid is lower than your valuation, any bid between these two values leads to you winning and having the same profit (namely the difference of these values), hence there is no gain in underbidding. However if you underbid too much, you run the risk of losing and having zero profit.
- Hence in both cases we see that underbidding does not increase your profit, and can only decrease your chance of winning. So it is better to bid exactly your valuation.
- The proof can be easily generalized to any number of bidders (to obtain that in a second-price auction, it is a dominant strategy for each bidder to bid truthfully.
- Selena's expected revenue is expected value of 2nd highest valuation.
- For two independent variables uniformly sampled from $[0,1]$, the expected value of the minimum is $1/3\approx 0.33$.
- This is not quite as good as posting a price (which provided expected revenue $0.38$). Why not?
- Let $F(x)$ be the cumulative density function (CDF) of the lowest of Alice and Bob's valuations, $\min{v_A, v_B}$, where $v_A$ and $v_B$ are independent variables sampled uniformly from $[0,1]$.
- By definition, for any $x$ in $[0,1]$, $F(x)$ is the probability that the lower valuation is below $x$, or equivalently, $g(x):=1-F(x)$ is the probability that both valuations are above $x$; clearly $g(x)=(1-x)^2$, and hence $F(x)=1-(1-x)^2$.
- From the CDF, we can compute the probability density function (PDF) by derivation: $f(x)=\frac{d}{dx}F(x)=2(1-x)$.
- Finally, the expected value is computed from the PDF with the integral formula $$\int_0^1 x\cdot f(x) dx = 2\int_0^1 (x-x^2)dx=2\cdot \left(\frac{1}{2}-\frac{1}{3}\right)=\frac{1}{3}.$$
- Because the format we considered is not optimal for the auctioneer!
- The optimal auction involves a reserve price $r>0$:
- If no bid is above $r$, nobody wins.
- If one bid is above $r$, the payment is $r$.
- If both bids are above $r$, the payment is the second-highest bid.
- The proof idea is that if $r=0.5$, half of the time one valuation is above it and the other is below it, and the reserve price increases the paying price. On the other hand, if both valuations are below $r$ then there is no sale, which decreases Selena's revenue, but this case only happens one quarter of the time. Finally, if both valuations are above $r$, the presence of a reserve price does no affect the result. Overall, there is a positive net gain in Selena's expected revenue. Below we present the formal proof.
- The probability that both valuations are below $r$ is $r^2$, the prob. that $r$ is in between the valuations is $2r(1-r)$, and the prob.that both valuations are above $r$ is $(1-r)^2$. You can check that these probabilities sum up to one.
- In the first case Selena's revenue is zero, and in the second case it is $r$. Hence the expected revenue for the first two cases is $2r^2(1-r)$.
- To compute the expected revenue of the third case, we simply copy the integral formula for the expected value (from a couple of slides ago), but we restrict the integration limits to $[r, 1\]$: \begin{align} \int_r^1 x\cdot f(x) dx &= 2\int_r^1 (x-x^2)dx\ &=2\cdot \left[\frac{x^2}{2}-\frac{x^3} {3}\right\]_r^1 \&=\frac{1}{3} - r^2 + \frac{2}{3}r^3. \end{align}
- Putting all terms together, we obtain that the expected revenue is $$R(r)=0+2r^2(1-r)+\left(\frac{1}{3} - r^2 + \frac{2}{3}r^3\right)=\frac{1}{3}+r^2-\frac{4}{3}r^3.$$
- To maximize the auctioneer's expected revenue function $R(r)$ above:
- We evaluate the function at all the local extrema (minima and maxima).
- Since the function is continuous and differentiable, the local extrema are found at the borders $r=0$ and $r=1$, and at the roots of the derivative $R'(r)=2r-4r^2=0$. These roots are $r=0$ and $r=1/2$.
- By inspecting all these points, we find that the global maximum is found at $r=1/2$, with a value of $R(1/2)=5/12\approx 0.42$.
- Literature: Myerson, Roger B. "Optimal auction design." Mathematics of Operations Research 6, No. 1 (1981): 58-73.
- Selena continually raises the price.
- At any price, you decide whether to stay or leave.
- If you leave, you may not return.
- If you are the last one in the auction you win
and pay the price at which the second-to-last
bidder left. - Next we move to English auctions, which have a very similar analysis.
- Notice it has a flavor of a second-price auction: the price you pay is decided by another bidder, not you.
- In a sense, these two auction formats are strategically equivalent!
- English auction is strategically equivalent to static second-price auction.
- It is a dominant strategy to stay until the price reaches one's valuation.
- The expected revenue for Selena is the also the same!
- Consequently, these two formats are also revenue equivalent.
- Why is staying until the price reaches your valuation a dominant strategy?
- If you leave you get zero utility.
- If you stay while the price is below your valuation, your eventual utility may be zero or positive, so there is no incentive to leave.
- If you stay while the price is above your valuation, your utility is zero or negative, so you should leave immediately.
- Second-price and English auctions popular among theorists, not so popular among practitioners.
- One reason is that they are prone to shill-bidding: bidder that acts on behalf of the auctioneer to drive up the price.
- Both second-price auctions and English auctions have the truthful bidding property, which is very satisfactory for theorists. However, as you can probably tell, they are not so popular in practice.
- A shill bidder has no intention of winning, but just increasing the price that the winner must pay. They do it to benefit the auctioneer.
- Shill bidding is frowned upon, sometimes illegal, but it is usually hard or impossible to prove and to prevent.
- The winning bidder pays her bid.
- Other rules same as in the second-price auction; i.e.,
- all bidders submit their bids simultaneously,
- the highest bid wins.
- New topic, time to wake up!
- We move on to first-price auction, which as you recall, is a type of sealed auction.
- Its analysis is more involved, and the resulting optimal bidding strategy is quite different from before.
- Bidding truthfully can never be optimal: if you win, you earn nothing.
- Underbidding is strictly better, you win sometimes and when you do you have a positive utility.
- Recall Nash equilibrium we already covered.
- A Nash equilibrium is a "recommended strategy per player", such that if you assume that the other bidder will follow their recommendation, then the best you can do is to follow yours.
- As the same is true for the other players, it is indeed a reasonable assumption to think the other players will follow their recommendation.
- However, if the other players picks an unexpected strategy, your recommended strategy may be suboptimal. In this sense, a Nash equilibrium is a weaker concept than a dominant strategy, in which the strategy of the other players is irrelevant.
- If you bid 0, winning prob. is zero.
- If you bid your valuation, profit is zero.
- Hence, there is a sweet spot between 0 and your valuation where your expected profit is maximal.
- It turns out this is bidding half your valuation, at which point you and Bob each wins half of the time.
- Unfortunately, the full proof is outside the scope of the presentation, but we provide it here in the lesson notes.
- Assume you are Alice, with valuation $v_A$ and bid $b_A$.
- Assuming that Bob's bid $b_B$ equals half his valuation $v_B$, that $v_B$ is sampled uniformly at random between 0 and 1, and that your bid $b_A$ is at most $1/2$, your winning probability is: \begin{align} Pr[winning] &= Pr[b_B\leq b_A] \ &= Pr[v_B/2 \leq b_A] \ &= Pr[v_B \leq 2b_A] \ &= 2b_A. \end{align}
- Your profit in case of winning is $(v_A-b_A)$, hence your expected profit is $2b_A(v_A-b_A)$.
- It can be checked that this expression is maximized for $b_A=v_A/2$.
- In summary, if Bob bids half his valuation, it is optimal for Alice to bid has her valuation, and vice versa. Together we have a Nash equilibrium.
- Reasonable to assume each bidder bids half their valuation.
- Hence, Selena's revenue is $\frac{1}{2}\max{v_A, v_B}$.
- The expected value of $\max{v_A, v_B}$ is $2/3$.
- Hence, her expected revenue is $1/3$.
- I find this result fascinating. The optimal strategies are so different, but somehow the fact that you underbid is exactly compensated by the fact that you pay more when you win.
- Is there a deeper connection going on here? Or is it just a coincidence that the expected revenues are all the same so far?
- Formal proof of the expected revenue: recall that the valuations $v_A$ and $v_B$ are assumed to be independent variables uniformly drawn from $[0,1]$.
- The cumulative density function (CDF) of the higher valuation, $\max{v_A, v_B}$, is $F(x)=x^2$. This is because $F(x)$ is lower than $x$ only if both valuations are below $x$, and these are two independent events each happening with probability $x$.
- Then, the probability density function (PDF) is $f(x)=F'(x)=2x$.
- And the formula for the expected value of $\max{v_A, v_B}$ is $$R = \int\limits_0^1 x\cdot f(x)\mathrm d x = \int\limits_0^1 2x^2 \mathrm d v = \frac{2}{3}.$$
- This is a theorem established by Myerson in 1981.
- Notice all auction formats are not strategically equivalent (namely, you should bid truthfully in some formats but not in others), yet they are still revenue equivalent for the auctioneer.
- This result is very surprising to me, and one of the coolest results in game theory.
- Selena continually lowers the price.
- As soon as a bidder accepts the price,
they are declared winners and auction is over. - Winner pays the price they accepted.
- We finally say a few words about the fourth and last auction format.
- Notice it has a flavor of a first-price auction: you pick the price you pay. So you definitely do not want to bid truthfully, but rather underbid.
- The auctioneer continually lowers the price.
- At any price, you can decide whether or not to accept the price.
- If you are the first to accept the price, you win and pay the price you just accepted.
- It turns out that the Dutch auction is strategically equivalent and revenue equivalent to the static first-price auction.
- The price that you accept in the Dutch auction corresponds to the price that you'd bid in a static first-price auction.
- The tradeoffs that the bidders face are very similar: take the current price or wait a bit at the risk of another bidder accepting first. It is an equilibrium to wait till the price is half your valuation.
- Static first-price auction.
- Static second-price auction.
- English auction.
- Dutch auction.
- First-price and Dutch auctions are strategy equivalent.
- Second-price and English auctions are strategy equivalent.
- All four actions are revenue equivalent.
- Having a reserve price increases the expected revenue, and it beats posting a price.
- Of course, Bob may react the same way and also bid more in an attempt to bid more often. As a result, they may still win about 50% of the time each, but both end up bidding too much due to their risk aversion.
- In contrast, in our analysis for second-price auctions, the bidders' aversion to risk is not a factor.
- Important: If you want to maximize the auctioneer's revenue and don't mind playing psychological games with the bidders, you should choose first price auctions over second-price auctions.
- Front runners are a known problem in eBay, trading platforms, and blockchain networks, etc.
- Front runners have a special, faster setup that allows them to see an incoming message from a bidder, react to it by creating their own message, and make their message get registered first in the system.
- eBay uses such types of auctions, and is infamous for having snipers.
- Similar to first-price auction
- except that ending time is unpredictable.
- At ending time, current highest bidder wins, pays own bid.
- Sniping protection: the longer you wait to bid, the higher the chances the auction ends.
- Fun fact: candle auctions were popular in England in the 17th and 18th centuries.
- They would use a candle (hence the name). When the flame extinguishes, the auction is over.
- Fun fact: Polkadot implemented a candle auction for assigning block space to applications.
- You have the chance to bid on one of 25 unique NFTs that are created by a professional artist.
- Use your budget that you accumulated during the last Academy Games.
- Everything that you will not use for bidding (or if your bid was lower than your budget), you will receive in cash at the end of the Academy.
- 100% of the revenue of the auctions goes to the artist.
- You are randomly assigned to one of three auction formats
- Canadian Artist living in Great Britain.
- Diverse Practice: Post-digital fine art in NFT, digital art, film, photography, sound and video art, installation, and performance.
- Exhibitions: Works showcased offline in cities like London, Sydney, Bath, Anglesey, and Swansea, and online in various publications.
- Art is exhibited in Tides Fine Art Gallery, Mumbles, Wales.
- The initial bidding phase lasts 30 seconds.
- Every valid bid resets the timer.
- You need to bid at least 30 cents more than the previous highest bid.
- Whoever has the highest bid at the end, wins. Winners pay their bids.
- Auction Format from the 16th Century.
- The auction lasts for exactly 4 minutes.
- A “candle mechanism” randomly determines, after the auction, when the auction ended
- Grace-period of 1 minute.
- Candle Phase of 3 minutes.
- Whoever had the highest bid when the auction actually ended, wins.
- Similar to eBay auctions.
- Auction lasts for 4 minutes.
- Whoever has the highest bid at the end of the auction, wins.
- Winners pay their bids.
- Each group of five players is bidding on a one dollar note.
- Minimum bid is 5 cents, bid increments of 5 cents.
- Auction lasts 90 seconds.
- Highest bidder gets the prize.
- Both highest and second highest bidders pay respective bids.
- Thought experiment designed by economist Martin Shubik.
- Serves as analogy for war: it may be apparent for both sides that even winning the war won't make up for the losses, yet both sides are motivated to keep spending money on it.
- You could get 1 dollar for 5 cents if no one else bids.
- But if you end up second you have a loss.
- Would you consider the auction paradoxical?
- Did you catch yourself acting irrational?
- Did you observe any phases in the game?
- Why do you think the game could be considered an analogy for war?
- Common systems
- Goals and trade-offs
- Common mechanisms
- Desirable criteria
- This lesson will be markedly less "exact" than the previous ones in the module. It will be less math and more critical thinking.
- Hence, I encourage class participation.
- However, many topics may be contentious and we might not be able to agree, especially not within the lesson time. The objective of the lesson is to awaken your curiosity on the topic, and I encourage you to continue the discussions outside the classroom.
- In the second half of the lesson we'll talk about voting mechanisms, which are widely used within many decision making systems.
- A way to gather the opinions of a heterogenous collective.
- A way to aggregate their preferences in a concise way.
- A way to reach a decision over the definition, resources, privilege or authority of a collective.
- In this lesson we will study some of the different ways in which people can make decisions as a unit.
- When people think of collective decision making, they usually only think of voting for a representative or representatives, and then letting them make all the decisions. But it is important to remember that this is just one of many possible mechanisms to reach a decision as a collective.
- A prerequisite for the formation of countries, companies, dynasties, i.e., strong institutions.
- Agile decision making helps collective react to external changes: war, trade, migration.
- Internally, they enable stability and progress: money, laws, private property.
- Even high tech, highly automated projects remain human collectives at their core.
- A project's decision-making mechanisms ensure its strength and relevance over time.
- We should consider these mechanisms along with the project's economics and security.
- We use the words "collectives" in a very broad sense, to include not only nations and dynasties, but also modern collectives like tech companies, social networks, and online communities. It is important to remember that these are human collectives, no matter how technical or automated they appear.
- Only well designed decision-making mechanisms can ensure that a collective stays strong and relevant over time. Otherwise, it will disintegrate due to internal discontent or external changes.
- Hence, analyzing a project's decision making mechanisms is just as important as analyzing the soundness of its cryptography, economics and security.
- Dictator, unelected or elected.
- Unelected committee (Zurich guilds).
- Representative democracy -- elected committee.
- Political parties
- Direct democracy -- all participate in all decisions.
- Can you think of other examples?
- In the middle ages, the city of Zurich in Switzerland was run by guilds (merchants, farmers, tailors). Women, and anyone outside these guilds, had no say in the decision-making process.
- The three key goals of any decision making process are utility, legitimacy and practicality.
- While utility is about the objective quality of the final result, legitimacy is about the perceived quality of the process. A mechanism is considered legitimate if most people trust the process, agree with it and feel empowered by it, even if they may not personally like the outcome.
- For instance, if Fifa had decided unilaterally that Argentina wins the world cup, this decision making mechanism would have the same utility but not the same legitimacy as playing the games: everyone would be angry at it.
- Finally, the practicality goal plays an important role especially if we have a very large population, or a short time window to make a decision, e.g., in an emergency.
- A dictator is practical. Is it legitimate?
- Direct democracy is legitimate. Why not always use this?
- Which mechanism maximizes utility?
- Which is best in case of war?
- This is the type of questions we are gonna explore in this lesson.
- Direct democracy is considered legitimate but is unfortunately slow. If would not be the right mechanism for an emergency, such as war.
- In the next slides, we look more closely at some of the most common systems.
- Legitimate?
- It is very practical.
- Good in case of an emergency.
- Only stable as long as the individual is stable (unlikely to be forever!).
- What's wrong with a dictator? We typically think of it as illegitimate, but keep in mind that kings used to be considered legitimate in the past. And even today, the owner of a large tech company may be able to make unilateral decisions that impact millions of lives, and we consider this to be legitimate.
- It is practical and allows for fast decision making in case of an emergency. For example, in the next pandemic, would you like to have every city vote on whether and when face masks should be mandatory in public spaces? Or would you prefer to have an authority impose it?
- You could also argue that it leads to stability, as people can expect things to stay the way they are for the foreseeable future, and can plan accordingly. However, we also have several real-life examples where a dictator behaves erratically.
- Lots of different things to lots of different people.
- Democracy doesn't really exist, only systems which are democratic to a some degree.
- Every person is consulted on every decision.
- Considered highly legitimate.
- Good at revealing the collective's opinions.
- Leads to progress as anyone can propose ideas.
- Direct democracy represents an extreme where every person is consulted on every decision, for instance via referendums.
- It is great at revealing the people's opinions, and adapting at evolving opinions.
- Similarly, if we assume that anyone is free to raise a proposal in direct democracy, then there is a sort of "free market of ideas". This leads to quick progress, because innovative ideas that challenge the status quo are not silenced.
- For instance, imagine a two-party system like the US where people are forced to pick one of two parties, instead of directly casting their vote on every decision. Imagine the left party traditionally supports legalizing abortion and banning firearms, while the right party traditionally supports banning abortion and legalizing firearms. Such idiosyncrasy could have made sense in the past, but if there is a shift in preferences whereby more and more people want to legalize both abortions and guns, the system will not have the means to detect these preferences and adapt properly.
- Similarly, if neither the left party nor the right party supports universal healthcare, then people who support healthcare do not have a voice.
- Of course, similar issues remain for a multi-party system (more than two political parties), and the issues are even worse in a dictatorship.
- Not very practical:
asking everyone to vote. - One decision at a time.
- Not great for emergencies.
- On the down side, direct democracy is unfortunately not very practical for two reasons. First, because asking every person to vote very slow. In particular, having a referendum would probably not be wise in an emergency such as war, or a detected vulnerability in a computer network.
- We saw that direct democracy is legitimate but not practical. How does it fare in terms of utility? Relatively well, but we argue here that it is not ideal, due to something called the voting paradox.
- Suppose the collective must decide between options A and B, and I personally value option A as worth zero and option B as worth $100 to me.
- Now, if most people vote for A, then A wins even if I vote for B, and if most people vote for B, then B wins even if I don't vote at all. Hence the most likely event is that my vote does not change the outcome.
- When the number of voters is in the millions, the likelihood that my vote actually changes the outcome is tiny, well below $0.1%$. My expected profit for voting is then (my profit for B - myr profit for A)$\times$prob. that my vote flips the result.
- In this example, my expected profit is less than 10 cents, which probably does not justify the effort of voting.
- Voting paradox is a known concept in voting theory: if voters are rational and self interested, they should not vote. The fact that many people vote means that they are either not rational, or not self interested.
- Indeed, we see for instance that in Switzerland, where direct democracy is used, the turnout is typically around 30%, and it's even lower in other systems.
- Only a basic interpretation. Better technology and progressive voting systems (OpenGov!) can mitigate this issue.
- A notion related to the voting paradox is that of rational ignorance: when the expected benefit we obtain from voting is minimal, we might not vote judiciously, even when we vote.
- We have limited time and limited capacity to learn things, so we will give preference to acquiring the knowledge that personally brings us the most expected potential benefit.
- In the previous example, if our expected benefit for voting at most 10 cents, and it takes us two hours to understand what the best option is, it may be wiser to vote at random even if we vote, and use that time to learn to code, or learn to play guitar, etc.
- Another consequence of rational ignorance is that someone's vote can be biasable. If you don't have a strong opinion about a vote because you haven't spent the time to learn about the issue deeply, you're more likely to be easily influenceable.
-
Representative democracy: elect a committee, whose members represent well the preferences of the passive people.
-
Delegated voting: give your voting power to a person who understands the issue well, so you don't have to.
- We saw that a critique of direct democracy is that it's unrealistic to expect everyone in the population to invest their time to understand every issue, and then vote.
- This leads to low turnout, which raises the question of legitimacy if a majority of the population does not voice their opinion.
- Liquid democracy/delegation
- OpenGov/multi-track delegation
- Quadratic "replacement" voting
- OpenGov/Optimistic approval
- ...
- Both solutions based on desire of representing every clique in the collective.
- Delegated voting is organic, helps with turnout, but remains slow.
- A committee ignores preferences of small cliques, but can take complex decisions fast.
- However, people naturally tend to congregate with other people with similar preferences, to form what we call cliques. So, you tend to be well represented by voters in your clique. The idea of both systems is to "sample" some opinions for every clique.
- From my point of view, delegated voting remains very close in spirit to direct democracy, as every individual remains free to vote directly if they choose to do so, or they can choose a representative that represents them very well. We gain in terms of practicality as now fewer people need to vote, but the process is still slow and can only take binary decisions.
- On the other hand, a committee is a bit closer to a dictator. It does a good job at representing the most common preferences of the collective, but not the preferences of small cliques. On the other hand, it can make subtle, non-binary decisions, and can make them fast.
- Hence, it could be a good idea to use delegated voting for important, binary decisions (such as whether to make abortions legal), and an elected committee to make emergency decisions (such as what to do in case of war). I encourage you to consider how you would design an ideal decision making system.
- Before we argued that pure direct democracy might not maximize utility. Now we also argue that a pure dictatorship is also not ideal for utility.
- Imagine that a group of friends meet every week to watch a movie, and 40% of members always pick comedy while 30% pick dramas and 30% pick action movies.
- Would it be fair if a comedy is chosen every time? Or what would decision-making system would you choose?
- What if the percentages were 60%, 20%, 20%? Is it now fair to always pick a comedy, since it makes a majority of people happy?
- A dictatorship system is captured by definition.
- A majority vote can lead to capture
if the minority's opinion is consistently ignored.
Known as "tyranny of the majority". - It can affect legitimacy.
- Although a dictatorship is obviously a captured system, other systems also have varying degrees of risk of being captured.
- For instance, as we saw with the movie club example, a majority vote can also lead to capture.
- In turn, this can not only negatively affect the utility goal but also the legitimacy goal, if a group of people feel that their voice is always ignored.
- As a curious note, we mention a system called random dictator.
- It works quite well in the example of the movie club: every week, pick a person at random and let them select the movie to watch.
- On the other hand, it would be a bad idea for a country to let a random dictator decide on the tax policy every month. This is because in the case stability is more important than avoiding a tyranny of the majority.
- Very efficient.
- Very capture resistant (on average).
- Terrible for stability.
- Where is it used?
- A random dictator system is captured in the short term, but it is highly resistant to capture in the long term. This is because every clique, even very small ones, will have their voice heard with a frequency proportional to the clique size.
- In fact, a version of random dictator is used in most blockchain consensus protocol, both based in proof-of-work and proof-of-stake. We do this for efficiency, and because stability of block production is not a priority, while the highest priority is to resist capture by an adversarial minority.
- This is because, if most block producers act honestly, then it is a Nash equilibrium to also act honestly when it is your turn to produce a block. But if a minority manages to capture the system for some amount of time, and arbitrarily decide on the content of a majority of blocks produced during this time, then the minority has an incentive to attack the network for personal gain.
- A dictatorship is fully captured but also stable.
- Direct democracy is at risk of capture, and still stable.
- A random dictatorship is most resistant to capture, but unstable.
- In this chart we consider the size of a clique or constituent, and plot it against the influence it will have over the collective decision in expectation.
- For instance, if there is an unelected dictator then no clique, big or small, has any influence on decisions.
- In a two-party system, only fairly large constituents will have a voice, while small constituents will have no voice.
- If we elect a larger committee then smaller constituents are more likely to be represented and hence have an influence on the final decision.
- Finally, in a random dictator system we have that every constituent, no matter how small, has a chance of influencing the final decision in proportion to the constituent size.
- In general, we see that there is a trade-off between being resistant to capture and being stable.
- Goals: utility, legitimacy and practicality.
- In emergencies, practicality may be more relevant.
- Simple direct democracy is legitimate, not so practical.
- Dictatorship is practical, not legitimate.
- Probably neither extreme maximizes utility.
- With new technology, we have better tools & mechanisms to make direct democracy effective
- Widely used within decision-making systems.
- Candidates to choose from: people, policies.
- Voters who declare preferences through ballots.
- A mechanism takes these ballots as input, and outputs a single candidate as the winner.
- Many criteria to judge the mechanism.
- New topic, wake up!
- Voting mechanisms are some of the most popular ways to make collective decisions, and have been for centuries.
- Why do you think that is? They are used for the election of leaders, for decision making within a governance body, choosing the winners in contests, among friends to decide on a restaurant, or in a family to name a dog.
- Without a doubt, one of the most desirable criteria for a collective decision making mechanism is simplicity, meaning that it should be easy to understand and participate for the population. This is probably a big pro for voting mechanisms.
- In the next slides we will explore some of the most popular voting mechanisms, along with some of the most popular criteria used to compare them.
- What criteria do you think are most intuitive and desirable for a mechanism? Fairness? Proportionality? Utility? How would you define these terms precisely?
- Single-vote mechanisms: plurality, two-round.
- Ranked-vote mechanisms: Borda count, ranked-pairs.
- Vote splitting, strategic voting.
- Monotonicity criterion.
- Two main types, depending on how the voters declare their preferences: in single-vote mechanisms, each voter selects one candidate, while in ranked-vote mechanisms, each voter ranks all candidates.
- Plurality voting: Candidate with most votes wins, even if they do not receive an absolute majority of votes.
- Two-round voting: Top two candidates are voted on again. The candidate with most votes in second round wins.
- These are some of the most popular voting mechanisms. They are certainly among the simplest ones.
- Plurality is also known as "first past the post" in the UK, where it is widely used.
- Consider also the generalization - multi-round mechanisms
- 1st: 8 votes for A, 5 votes for B, 7 votes for C.
- 2nd: 8 votes for A, 12 votes for C.
- Recall that voters only vote for a single voter per round. But for convenience in what follows we assume we know the full candidate ranking of each voter, so we can analyze what would happen if any two out of the three candidates go head to head in the second round.
- Are they equivalent? No. Look at the example above where there are three candidates A, B and C, and 20 voters with three types of preferences.
- In plurality voting, we would only get to see the first column, and elect A with 8 votes.
- In two-round, candidates A and C would go to second round, where the 5 voters in the last row would change their vote from B to C, and candidate C would win with 12 votes.
- In general, several seemingly reasonable mechanisms result in different winners for the same collection of voters' preferences. This is why we need to look more closely into what properties we want out of a mechanism.
- Which of these mechanisms is better? Here is an argument against plurality voting.
- In 2014, Candidate Chandu Sahu, from a political party called BJP in India, was a favorite to win in an election against opponent Ajit Jogi. To his surprise, on the day of the elections there were 10 other independent candidates registered with the same exact name. Apparently most of these candidates had no history in politics, but someone found them and offered them money to run on the elections. Of course, the obvious suspect is the opponent, but it was never proven. Luckily, the original Chandu Sahu still managed to win, but by only a razor-thin margin of 1200 votes, as the other 10 fake candidates accumulated around 70 thousand votes.
- This technique is known as vote splitting, and plurality voting is well known to be susceptible to it.
- Imagine B and C are similar candidates, and most people prefer either over A.
- Known issue in plurality. Two-round helps alleviate it.
- Imagine that candidates B and C are very similar, i.e., they have similar points of view (or a similar name!) In the example, we see that a majority of the population prefers either of them to A, but since their votes are split, both candidates would lose out to A in plurality voting.
- This issue is known as vote splitting. Two-round voting helps reduces its effect.
- In electoral systems that implement plurality voting, vote splitting is sometimes used as a weapon by the less popular party (in our example, A), who strategically nominates a candidate similar to their rival to split their votes.
- In turn, a common defense against vote splitting is to form alliances among similar candidates.
- A voter raising their rank for the winning candidate, or lowering their rank for a losing candidate, should not change the winner.
- Plurality is monotonic, two-round voting is not.
- Conversely, here is an argument against two-round voting.
- Monotonicity is one of the most intuitive criteria that we would expect from a voting rule. It says that the winning candidate should be stable relative to monotonic changes of the voter's preferences. In particular, if a voter raises their preference for the current winner, or lowers their preference for other candidates, then the winner should not change.
- Failure of this criterion means that the mechanism is susceptible to strategic voting, because a rational voter may be better off hiding their real preferences.
- 1st: 8 votes for A, 6 votes for B, 7 votes for C.
- 2nd: 11 votes for A, 10 votes for C.
- We will see now that two-round voting is not monotonic.
- In this example, there are 21 voters, with 6 types of preferences.
- In two-round voting, A and C go to the second round, where A wins 11 against 10.
- 1st: 10 votes for A, 6 votes for B, 5 votes for C.
- 2nd: 10 votes for A, 11 votes for B.
-
But now suppose the 2 voters in the bottom row raise their preference for A. They simply swap the positions of A and C in their ranking.
-
Now C doesn't make it to the second round. In the second round, now B wins 11 to 10 against A.
-
Hence, two-round voting is not monotonic.
-
If the bottom-row voters want candidate A to win, they are better off marking C as their top preference.
- A mechanism that is not monotone is susceptible to strategic voting.
- This is the case with two-round voting.
- Indeed, in the previous example, the bottom-row voters want candidate A to win, but are better off marking C as their top preference.
- In 1770, Jean-Charles de Borda showed 2-round may elect a candidate that would lose out head-to-head to every other candidate.
- Are there monotonic mechanisms better than plurality voting?Yes!
- But they require more information from the voters: they need to rank all the candidates.
- The unfair nature of plurality voting was pointed out in 1770 by French mathematician Jean-Charles de Borda, in a presentation at the French Royal Academy of Sciences.
- He proved that plurality voting can elect the least favorite candidate: one that would be defeated by every other candidate in a head-to-head election.
- Going back to our first example, recall that A was the winner in plurality voting, yet if A and B go head-to-head, A loses 8 to 12, and if A and C go head-to-head, again A loses 8 to 12.
- Finally, if B and C go head-to-head, B would win 15 to 5, so in a sense B is the overall winner of pair-wise elections.
- Each voter gives a rank of all $k$ candidates
- Interpreted as if giving $k-1, k-2, \cdots, 1, 0$ points
- Add up all points, select candidate with most points.
- Borda count is monotone.
- Borda proposed a new election mechanism, known today as the Borda count, that can be thought of as a generalization of two-round voting.
- If there are $k$ candidates, this is interpreted as if the a voter gives $k-1$ points to their favorite candidate, $k-2$ points to their second favorite candidate, and so on until their least favorite candidate gets zero points. Then, we elect the candidate that received the most points overall.
- In our example, we see that B wins, as expected. We highlight that for the exact same example, the winner was A under plurality and C under two-round!
- Borda count is arguably more fair.
- But plurality and two-round voting are simpler.
- Simplicity seems to be important in practice.
- No voting mechanism is perfect.
- In the area of voting theory, there are many other voting mechanisms known, and many other possible criteria to classify them. Voting theory is a fascinating topic at the intersection between mathematics and political theory.
- In general, we see that the rules with better properties tend to be more complicated, which is unfortunately why they are not used as much. Hence, we can say that no mechanism is perfect.
- Still, some mechanisms will be a better fit than others depending on our priorities for a system.
- We saw that ranked-based voting, like Borda count, seems to be more fair (utility), but it is less simple to participate (practicality), which is probably why it's not so popular.
- We saw that representative democracy and delegated voting can be seen as sampling opinions from the collective, so that not everyone has to vote. In the exercise we take the sampling idea literally.
- Is this new mechanism more or less legitimate? Does it have higher utility? I think it has higher utility but less legitimacy.
- Is it practical? It could be an issue to have a sampling process that is verifiably random and unbiased. This affects practicality and legitimacy.
- While there is a lot of active research in this topic, there is no fully satisfactory solution yet.
- The goals at odds are legitimacy and utility. If people don't trust the process then it is not legitimate, even if it has many advantages in theory.
- The president could try to educate people about the new system, but should probably not impose it.
- Mostly for operational reasons
- As the validator set size increases, the communication costs grow quickly (superlinearly), while the increase in security grows slowly past a certain point.
- It is not sensible to run nodes for only sporadic participation. Validators would naturally tend to form pools anyway, to decrease the variance of their revenue, and profit from economies of scale.
- Yes, for instance if we vote to increase the staking rewards, all validators would support it, but this negatively affects stakeholders who are using their tokens in other ways (such as in financial applications like lending).
- Which economic pieces build the the Polkadot Network?
- What are their mechanisms and incentives?
- How are those pieces interrelated?
- Native token of the Polkadot network.
- 1 DOT = \(1\mathrm{e}{10}\) Plancks
-
Planck = smallest unit of account.
- Reference to Planck Length = the smallest possible distance in Physics.
-
Utility Token with several use-cases:
- Governance (decentralization)
- Bonding in slot auctions (utility)
- Staking (security)
- Message passing (e.g., transfers)
- Expansion in token supply.
- Token minted from thin air.
- Used to pay staking rewards for validators and nominators.
- (Indirectly) fund Treasury.
- Central economic variables of the model are:
- Exogenous:
- Staking rate (Total amount of staked DOT / Total amount of DOT).
- Endogenous:
- Optimal staking rate (a sufficient backing for validators to provide reasonable security).
- Total inflation rate (10%).
- Different states of DOT:
- Liquid: Used for messaging and liquidity on markets.
- Bonded (Staking): Economic mass that guarantees the security of the network.
- Bonded (Parachains): The demand for DOT tokens by parachains.
- The goal is to obtain (some) sensible ratio between those three token states.
- Central variable: Ideal staking rate (currently ~53.5%).
- Highest staking rewards at the ideal staking rate.
- Incentives to (increase) decrease the staking rate it is (below) above the optimal.
- Staking inefficiencies -> Treasury.
- Ideal staking rate scales with number of active parachains (0.5% less with each parachain).
- In the fiat-world, inflation has a negative connotation.
- This is a general discussion in economics.
- My take on this:
- Predictable (maximum) inflation is good.
- It incentivizes to work with the tokens (i.e., bond for good parachains, use for message passing).
- Deflation can cause a halt of economic activity, because people start hoarding tokens.
- The current system incentivizes to move the staking rate to the ideal rate.
- Then, Treasury inflow would be 0 DOT.
- That is not sustainable.
- Proposed change: Detach inflation to stakers from total inflation and divert the rest to Treasury directly.
- Nominated Proof-Of-Stake (NPoS).
- Economic incentives of validators and nominators are aligned with those of the network.
- Good behavior is rewarded with staking rewards.
- Malicious / Neglecting behavior is punished (slashed).
- Currently, minimum total stake is ~1.6M DOTs.
- The total stake in the system directly translates to the economic security that it provides.
- Total stake is pooled from validators (self-stake) and their nominators (nominated stake)
- High degree of inclusion
- High security
- The goal is to get as much skin-in-the-game as possible.
- What makes Validators resilient:
- Self-stake
- Reputation (identity)
- High future rewards (self-stake + commission)
- Bond tokens for up to 16 validators that they deem trustworthy.
- They have an incentive to find the best ones that match their preferences.
- They are tasked to collectively curate the set of active validators.
- What are staking rewards for?
- Validators: Hardware, networking, and maintenance costs, resilience.
- Nominators: Curation of the active set of validators, sort out the good from the bad ones (Invisible Hand).
- The job of nominators is to find and select suitable validators.
- Nominators face several trade-offs when selecting validators:
- Security, Performance, Decentralization
- Ideally those variables in their historic time-series.
- Economic Background:
- Self-stake as main indicator of skin-in-the-game.
- Higher commission, ceteris paribus, leaves a validator with more incentives to behave.
- Various sources of trust
- Efficient validator recommendation is one of my research topics.
- Parachains (or cores) are the layer-1 part of the protocol.
- Blockchains of their own that run in parallel.
- Highly domain specific and have high degree of flexibility in their architecture.
- Share same messaging standard to be interoperable and exchange messages through the Relay Chain.
- Polkadot: 43 Parachains, Kusama: 46 Parachains.
- Their state transition function (STF) is registered on the Relay Chain.
- Validators can validate state transitions without knowing all the data on the Parachain.
- Collators keep the parachain alive (but are not needed for security).
- Offer their utility to the network.
- The access to the network is abstracted into the notion of “slots”.
- Leases for ~2 years on Polkadot (~1 year on Kusama).
- Only limited amount of slots available (networking).
- The slots are allocated through a candle auction.
- Bonded tokens held (trustlessly) in custody on the Relay Chain.
- The tokens will be refunded after the slot expires.
- Tokens cannot be used for anything (staking, transacting, liquidity, governance).
- That means, tokens locked cause opportunity costs.
- An approximation is the trust-free rate of return from staking.
- Parachains need to compete with those costs and generate benefits that exceed those opportunity costs.
- Sufficient crowdloan rewards.
- Sufficient economic activity on-chain that justifies renewal.
- Slot mechanism creates constant demand for DOT token.
- It is costly to be and remain a parachain.
- Natural selection mechanism to select useful parachains.
- Continuous pressure to gather funds for extending slots.
- Parachains pay for security.
- Every parachain is as secure as the Relay Chain.
- Polkadot is a security alliance with network effects.
- Not only scaling number of transactions, but it also scaling of security.
- Security is a pie of limited size, because financial resources are limited.
- Every chain that secures itself need cut a piece of the cake, which leaves less to others (zero-sum).
- Shared security protocols allow to keep the cake whole and entail it to all participants.
- Shared security is a scaling device, because the amount of stake you need to pay stakers to secure 100 shards is less than you need to pay stakers to secure 100 individual chains.
- Based on Gav’s Keynote at Polkadot Decoded 2023.
- A new narrative of the whole Polkadot system.
- We move away from regarding Parachains as a distinct entity but rather regard Polkadot as global distributed computer.
- It's spaces and apps rather than chains.
- This computer has computation cores that can be allocated flexible to applications that need it.
- Coretime can be bought, shared, resold.
- Security: The scarcest resource in blockchain, crucial in preventing consensus faults or 51% attacks that could compromise transactions.
- Availability: Ensuring blockspace is available without long waiting times or uncertain costs for a smooth, seamless interaction within the decentralized ecosystem.
- Flexibility: The ability of blockspace to be fine-tuned by the consumer for specific use-cases.
- A networked collection of individual blockspace producers (blockchains) offering secured, fit-for-purpose, efficiently-allocated, and cost-effective blockspace.
- A valuable aspect of a blockspace ecosystem is its connective tissue of shared security and composability.
- Dapp developers or blockspace providers can focus on their unique features, reusing existing capabilities within the ecosystem.
- For example, a supply chain traceability application could use different types of blockspace for identity verification, asset tokenization, and source traceability.
- It's not yet finalized how they work but likely:
- Around 75% of cores are allocated to the market.
- Cores are sold for 4 weeks as NFT by a broker.
- Unrented cores go to the instantaneous market.
- Price de-/increases relative to demand.
- Current tenants have a priority buy right for their core(s).
- This allows for low barriers of entry for people to simply deploy their code to a core and test stuff
- It makes blockspace more efficient, because not all teams can/want to have a full block every 6/12 seconds.
- The treasury is an on-chain fund that holds DOT token and is governed by all token holders of the network.
- Those funds come from:
- Transactions
- Slashes
- Staking inefficiencies (deviations from optimal staking rate)
- Through governance, everybody can submit proposals to initiate treasury spending.
- It currently holds around 46M DOT.
- Spending is incentivized by a burn mechanism (1% every 26 days).
- A DAO (decentralized autonomous organization) that has access to funds and can make funding decisions directed by the collective (that have vested interest in the network).
- This has huge potential that might not yet have been fully recognized by the people.
- This provides the chain the power to fund its own existence and improves the utility in the future. It will pay…
- … core developers to improve the protocol.
- … researchers to explore new directions, solve problems and conduct studies that are beneficial for the network.
- … for campaigns educating people about the protocol.
- … for systems-parachains (development & collators).
- A truly decentralized and self-sustaining organization.
- Polkadot is a system that offers shared security and cross-chain messaging.
- Security scales, i.e., it takes less stake to secure 100 parachains than 100 individual chains.
- The DOT token captures the utility that the parachains provide and converts it to security.
- The slot mechanics (renewal, auctions) creates a market where parachains need to outcompete opportunity costs to be sustainable (i.e., they need to be useful).
- Polkadot is a DAO that will be able to fund its own preservation and evolution.
- There are many changes to come with Polkadot 2.0 creating a much more agile system.
- Agile Coretime RFC
- Discussion on Changing Inflation Model
- Talk about Polkadot 2.0
- Nominating and Validator Selection On Polkadot
- No tampering
- No eavesdropping
- Authorship
- The starting state
(aka genesis state) - The history of transitions
- The current state
- Generalization of Bitcoin: provides a quasi-Turing-complete VM
- Uses an account-based system
- Accounts can store balances, but can also store executable code (smart contracts)
- Each contract can have its own internal state and API
- Game Servers (AOE or Minecraft)
- Twitter, Instagram, Facebook, etc.
- Journalism and sources
- Banks
- Lawyers, notaries, regulators
- Trust that we are seeing information from the same database*
- Trust that if a tweet is from X, then X wrote that tweet*
- Trust that others see our messages as from us*
- Trust that the messages we see are the messages the users wrote*
- Trust that we're interacting with the application as equals
- Censoring user interaction
- Restricting users interaction
- Failing to produce requested data
- Mutating state opaquely
- Shared state and state change rules
- Custom rendering, moderation, interfaces
- Ride sharing platform
- Voting system
- Blackjack table
- The app you just built
- History of p2p networks
- Discuss the network layer and network conditions that blockchains operate on(Mostly)
- Talk about traditional web2 network overlays pros vs cons with web3 network overlays
- Discuss attacks and how to address along with the underlying threat model
- First operational packet-switching network
- Developed in the late 1960s by DARPA(The Defense Advanced Research Projects Agency)
- Laid the foundation for the modern internet
- Mode of data transmission in which a message is broken into a number of parts that are sent independently(Packets)
- Packets are sent over whatever route is optimal
- Packets are reassembled at the destination
- P2P is a decentralized form of network structure
- Unlike client-server model, all nodes (peers) are equal participants
- Data is shared directly between systems without a central server
- Peers contribute resources, including bandwidth, storage space, and processing power
- Launched in 1999, popular P2P platform
- Central server for indexing, P2P for transfers
- Shutdown in 2001 due to legal issues
- Each node serves as both a client and a server no central server
- Query all connected nodes for files
- Gain peer connections to the network via Bootnodes
- Ordered to shutdown in 2010 by United States Court
- Check local filestore for file and if it is not available, forward the request to all connected peers.
- Gnutella generates a significant amount of network traffic by flooding the network with requests.
- No privileged nodes
- Less bottlenecks with bandwidth
- DOS resistant
- No centralized infrastructure necessary (Except internet for now...)
- No single node or nodes (CDN) have access to all of the content or files or is critical for operating the network. Each node has a copy of the data.
- No central node carrying all of the load of traffic. Block production and Block peering/importing can be mentioned here.
- Difficult to overload the network or DOS (Not a single node is privileged).
- Although many nodes are run on Centralized cloud compute platforms, they don't have to be (Typically).
- Since it is permissionless, a node can share malicious resources
- Latency
- Difficult to regulate illicit activity
- The network is limited by nodes with the weakest hardware
- Latency may be an issue if we need to wait for many peers to receive the data produced from a single node since everyone may not have a direct connection. Mention finality time!
- No central point to go and snoop all users data (for better or for worse).
- Why we have hardware requirements for blockchain networks.
- Talk about how we have and want block 45 being peered to others
- Connect to a peer
- Ask peer for a list of their known nodes
- Connect to random subset of peers from the list
- Repeat steps 2 and 3
- What are some of the types of applications that lend themselves to this kind of network topology? Can anyone think of any?
- File sharing(Music)?
- Messaging and communication?
- Bootnode/bootnodes (More on this later in Substrate)
- Must know someone who is participating in the network initially(Bootnode)
- Can anyone think of a way to exploit some of these networks?
- What would be some things to try to take advantage of?
- Distorts view of the healthy normal honest state of the network
- Transaction confirmations can be fictions
- Flood a target node with a bunch of malicious peer addresses
- The targeted node then stores these malicious peers and utilizes them when re-syncing on next bootup
- DOS targeted node to take it offline to force a resync with these new malicious peers
- Restrict inbound connections in some way
- Random selection of peers to connect with
- Deterministic node selection (Bootnodes)
- Restricting new nodes (Probably not what we want...)
- Be wary of new connections with other nodes
- Don't just take the most recent request for connections to avoid the flooding
- Bootnodes with higher credibility and trust (Can be a bottleneck) - Rotate bootnodes as they are also subject to attacks
- Turing Completeness, as a standard bytecode would respect
- Support for tooling that makes it executable on every machine
- Inside the Linux Kernel -> eBPF
- Inside browsers -> Wasm
- Inside Blockchains -> Wasm
- Full nodes
- Light nodes (Wasm inside Wasm)
- LLVM Toolchain -> LLVM IR
- Portability
- Avoid Hardware Centralization - Determinism
- Make consensus possible - Hardware Independence
- Efficiency
- Tool Simplicity
- Support as Compilation Target
- Sandboxing
- Hardware Independence: It should not be tightly related to a specific architecture, otherwise the execution on different machine could be convoluted
- Efficiency: the execution of a PAB should be efficient, the problem for a PAB is that in the execution time is also considered the "translation" to the machine's bytecode or the interpretation
- Support as Compilation Target: The PAB should be possible to be compiled by as many as possible High Level languages
- Tool Simplicity: If the tools that makes the PAB executable are extremely complex then nobody will use it
- Compilation takes too much time -> compiling bomb
- Access to the environment -> "buffer overflow" techniques
- Hardware-independent
- Binary instruction format for a stack-based virtual machine
- Supported as compilation target by many languages
- Rust, C, C++ and many others
- Fast (with near-native performance)
- Safe (executed in a sandboxed environment)
- Open (programs can interoperate with their environment)
- Stack push operations can be grouped to its consuming instruction.
- Labels can be applied to elements.
- Blocks can enclosed with parenthesis instead of explicit start/end instructions.
- How does communication with the environment work?
- How the memory is managed?
- How is it executed?
- the wasm blob may expect parameters from the embedder
- embedder -> wasm
- the embedder may act on a return value from the wasm
- wasm -> embedder
- Every interaction with the environment can be done only by a set of functions, called Host Functions, provided by the embedder and imported in wasm
- The embedder is able to call the functions defined in wasm blob, called Runtime API, and pass arguments through a shared memory
- This area will be used also used as a frontier for data sharing
- To make everything secure the Embedder is doing incredibly convoluted things
- Ahead Of Time Compilation
- Just in Time Compilation
- Single Pass Compilation
- Interpretation
- ...
- It is a stand alone wasm environment
- Wasmtime is built on the optimizing Cranelift code generator to quickly generate high-quality machine code either at runtime (JIT) or ahead-of-time (AOT)
- It executes the compiled wasm blob in sandboxed environment while keeping everything extremely secure
- wasmtime book: https://docs.wasmtime.dev/
- Used in substrate as embedder for the blockchain logic
- It is a wasm environment with support for embedded environment such as WebAssembly itself
- Focus on simple, correct and deterministic WebAssembly execution
- The technique of execution is interpretation but:
- The wasm code is transpiled to WasmI IR, another stack-based bytecode
- The WasmI IR is then interpreted by a Virtual Machine
- The Ethereum Virtual Machine executes a stack machine
- Interesting: here the bytecode was create to be executed in a blockchain, so instructions are not hardware-dependent but there are instruction tightly related to Cryptography and others blockchain instructions
- Wasm is always used but with different tools
- They use CosmWasm as Embedder and internally is used Wasmer, a Single Pass Compiler
- eBPF is used as PAB, but intrinsically eBPF has a lot of restrictions
- Solana forked the eBPF backend of LLVM to makes every program to be compiled in eBPF
- The Embedder is rBFP, a virtual machine for eBPF programs
- RISC-V is a new instruction-set architecture
- main goals are:
- real ISA suitable for direct native hardware implementation
- avoids “over-architecting”
- Let's make a simple Rust crate that compiles to Wasm!
- Clone the repo
- A target triple consists of three strings separated by a hyphen, with a possible fourth string at the end preceded by a hyphen.
- The first is the architecture, the second is the "vendor", the third is the OS type, and the optional fourth is environment type.
wasm32-unknown-emscripten: Legacy, provides some kind ofstd-like environmentwasm32-unknown-unknown✓ WebAssembly: Can compile anywhere, can run anywhere, nostdwasm32-wasi✓ WebAssembly with WASI
Notes:
Overfishing
Air pollution
But...
Notes:
To be precise, in the last example the so-called "tragedy" is not that producing a good leads to air pollution; after all, this may be unavoidable if we want to consume the good. The tragedy is that even if we agree on the level of production and air pollution that is economically ideal for the collective, we will end up with more pollution.
Break (10 minutes)
Notes:
Open Source
Providing open-source software is like contributing to a public good and the community will therefore sooner or later collapse!
Notes:
Design a 2x2 game
Jack and Christine are rivals and keep taunting each other in front of others. At one time, Jack challenges Christine to a game of chicken. He proposes that they both get in their cars and drive towards each other on a road. In the middle of the distance between each other, there is a small bridge with a single lane. Whoever swerves away before the bridge chickened out. If both keep straight, there is no way to avoid a strong collision between the two cars. All friends will be present to see the result.
Design this game in a 2x2 matrix and assign payoffs to the different outcomes.
Notes:
Design a 2x2 game
Notes:
Workshop: Games
Notes:
Game 1: Guessing Game
Game 1: Questions?
Don't ask about strategies!
Game 1: Guessing Game
Link will be distributed!
Game 1: Discussion
Notes:
Game 1: Results!
Game 2: Prisoner's Dilemma
Game 2: Payoffs
| The other participant | |||
|---|---|---|---|
| Cooperate | Defect | ||
| You | Cooperate | 200 points, 200 points | 0 points, 300 points |
| Defect | 300 points, 0 points | 100 points, 100 points |
Game 2: Questions?
Game 2: Let's go!
Link will be distributed!
Game 2: Results!
Game 3: Public Good Game
Game 3: Instructions

Game 3: Contribution
Game 3: Punishment
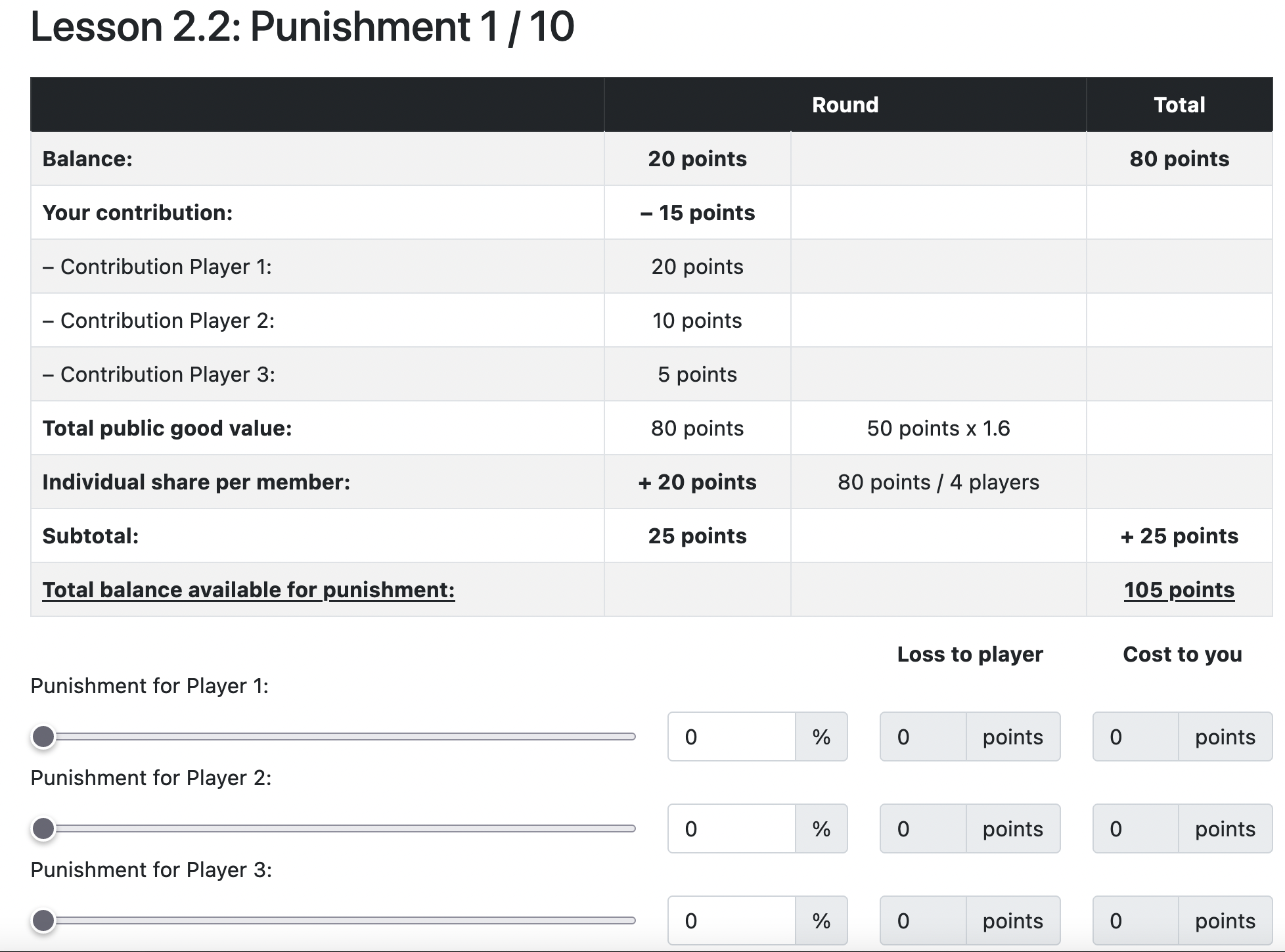
Game 3: Payout
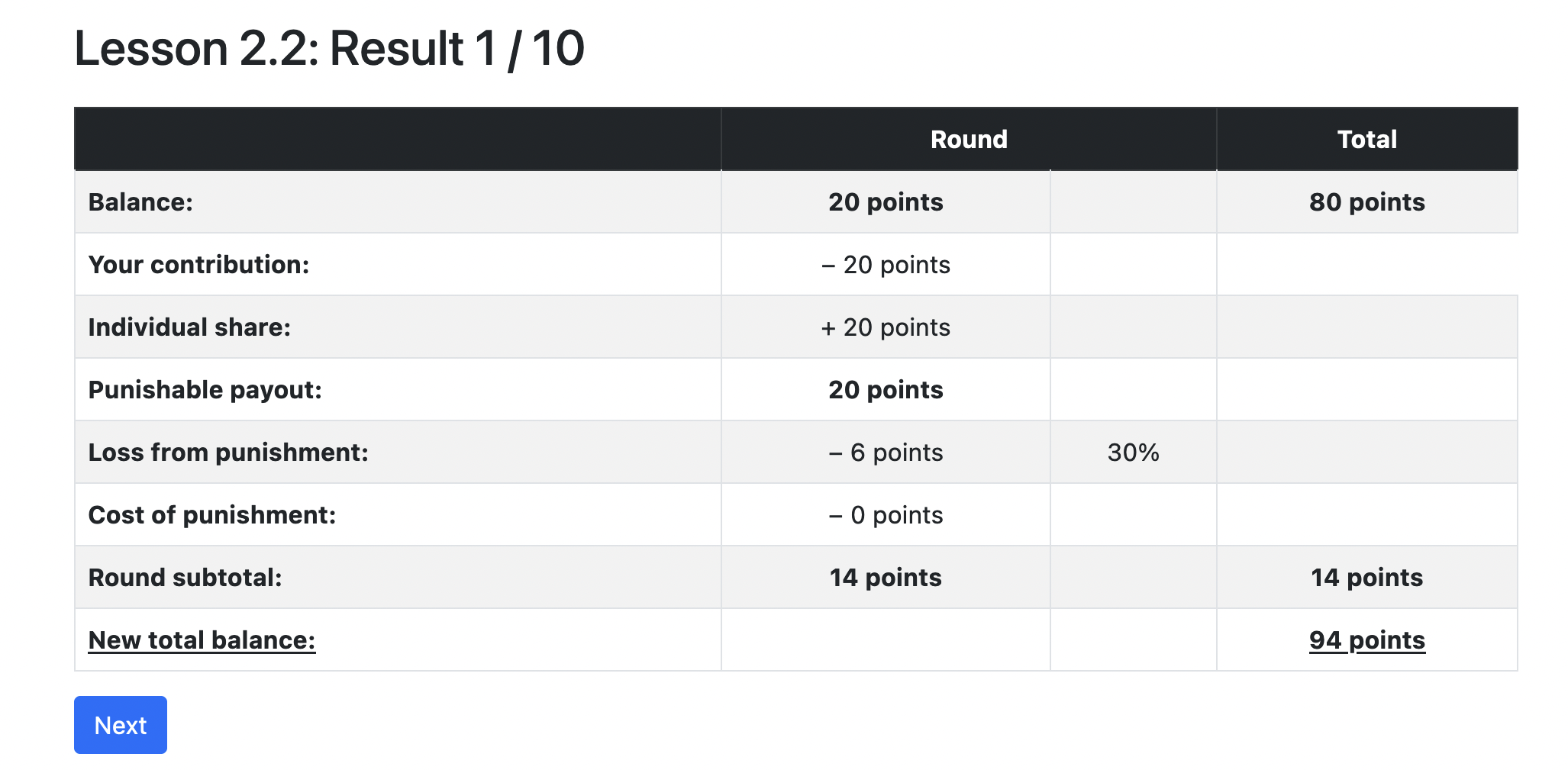
Game 3: Questions?
Game 3: Let's go!
Link will be distributed!
Game 3: Discussion
Notes:
Game 3: Results!
Game 3: Discussion
Notes:
What about empirical evidence?
Summary
Questions
Further Reading
Price Finding Mechanisms
How to use the slides - Full screen (new tab)
Price Finding Mechanisms
Introduction
Supply / demand for BIG markets

Notes:
Supply-demand for BIG markets
Notes:
What about difficult markets?
Notes:
Image source: https://funkypriceguide.com/collectible/512-gold-hopper-2018-sdcc-fundays/
What about difficult markets?
Today we focus on markets with few buyers or sellers, few trades, or non-standardized goods.
Notes:
A simple model
How does Selena optimally sell the item?
Notes:
Let's assume...
Notes:
Price posting
Notes:
Price posting
Notes:
Auctions
Lesson summary
Notes:
Auctions
An auction is a competitive game for buyers, where the seller makes the rules.
Notes:
Auction formats
Notes:
Auction formats
Four auction formats we discuss today:
Notes:
Second-price auction
Notes:
Second-price auction

Notes:
TIP: use arrow chars in unicode for style: https://www.htmlsymbols.xyz/arrow-symbols
Second-price auction
Expected revenue
Notes:
Reserve price
Reserve price
Fact: Under any reserve price $r$, it is still optimal to bid truthfully, and if Selena sets $r=0.5$, her expected revenue is $\approx 0.42$, so it is better than posted price (where expected revenue was $\approx 0.38$).
Reserve price

Notes:
English auction
Recall the rules:
Notes:
English auction
Notes:
Shill bidding
Notes:
First-price auction
Notes:
First-price auction
Bidding in the first-price auction is not truthful.
First-price auction
Equilibrium strategy: It is a Nash equilibrium for each bidder to bid half their own valuation.
Nash equilibrium: A set of strategies, one per player, where no one has an incentive to change their strategy.
Notes:
First-price auction
Intuition: suppose you are Alice
Notes:
First-price auction
Expected revenue
The same as in second-price auction!
Notes:
Revenue Equivalence
Fact: When valuations are secret and independent, there is no reserve price, and item goes to highest bidder, then all auction mechanisms are revenue equivalent.
Notes:
Dutch auctions
Notes:
Dutch Auction
Recall the rules:
Dutch Auction
Recap
Analyzed important auction formats:
Learned under standard assumptions:
Break (10 minutes)
Discussion
Independence of valuations
In our analysis, it was important to assume that bidders' valuations are independent from one another.
Can you think of examples where this assumption isn't sensible?
Independence of valuations
Answer:
Sensible: - a piece of art, where the bidders are final clients.
Not sensible: drilling rights to an oil well. Bidders will have similar estimates of amount of oil, hence valuations are highly correlated.
Common value auctions
Special scenario: there is a unique valuation of item, but each bidder only has a private estimate of it.
In these cases, it is observed that sealed-bid auctions tend to give higher revenue than dynamic auctions.
Why do you think this is the case?
Common value auctions
The auction may be used as a means of gathering information from other participants to triangulate a price
Answer: In a dynamic auction, a bidder can use the bids of others as additional signals of the correct valuation. If bids so far seem high, my initial estimate must be low, and vice versa, so I can adjust my personal estimate. Hence estimates converge.
In a static auction, there is no convergence of estimates, so it is more likely that some bidders keep unusually high estimates. As a result, there is a higher chance that the winner ends up paying more than the correct valuation. This is known as the winner's curse.
Equivalence of revenues
It is observed in practice that first-price auctions lead to higher revenue than second-price auctions.
This violates the equivalence of revenues, so an assumption in our analysis fails consistently.
What do you think it is?
Equivalence of revenues
Answer: Risk aversion. People prefer lower uncertainty games, even if this means lower expected profits.
Would you rather win a million dollars with a 50% chance, or 300 thousand with a 90% chance?
In Nash equilibrium analysis for first-price auctions, we claimed that if Bob bids half his valuation, then Alice should bid half hers, so each wins 50% of time. But we implicitly assumed that Alice is risk neutral. Yet she might prefer to bid more and win more often.
Notes:
Front Running
Computer systems may have front runners: special nodes can see an incoming bid, react by creating their own bid, and make it look like their bid was created first.
If you run an auction on a system with front runners, which of the four auctions would you use? Why?
Notes:
Front Running
Answer: Meet front runner Fred.
In a Dutch auction, if Fred is a bidder he waits for first bidder to signal accepting the price, and Fred makes the signal first. He's guaranteed to win with least possible price.
In second-price auction, if Fred is auctioneer he can shill bid successfully: when a highest bid arrives, he creates bid slightly under it and makes it appear as if it was created first.
Front Running
Answer: Meet front runner Fred.
In a first-price auction, if Fred is bidder and if he can "open the seals" he can win by slightly outbidding highest bid. (Poor data privacy, a common issue in computer systems)
Hence, it might be best to run an English auction.
Sniping
In a dynamic auction with a fixed bidding time window, sniping is placing a highest bid as late as possible, so other bidders can't react and overbid you. The practice leads to low revenue. Particularly bad when done by a front runner (microseconds).
How to protect an auction from snipers?
Notes:
Sniping
Answer: candle auctions.
Dynamic first-price auction with random ending time.

Sniping
Answer: candle auctions.
Dynamic first-price auction with random ending time.
Notes:
Workshop: Auction Games
NFT Auction
The Artist & NFTs!
Jeremy Gluck (Nonceptualism)

Format 1: Activity Rule Auction
Format 2: Candle Auction
Format 3: Hard Close Auction
Auction 2: Questions?
Auction 2: NFT Auction
Link will be distributed!
Auction 2: Discussion
Auction 2: Results!
Further Reading
Polkadot & Kusama Auctions
Data & Background information:
Questions
Bonus Game: Dollar Auction
Notes:
Dollar Auction: Questions?
Dollar Auction
Discussion
Auction 1: Results!
Collective Decision Making
How to use the slides - Full screen (new tab)
Collective Decision Making
Lesson highlights
Decision
making systems
Voting mechanisms
Notes:
Collective decision making
An umbrella term that contains voting mechanisms,
governance processes, policy making, budget allocation.
Collective decision making
Notes:
Why?
Why?
Notes:
A more profound interpretation
Long you live and high you fly
Smiles you'll give and tears you'll cry
And all you touch and all you see
Is all your life will ever be
-- Pink Floyd (Breathe)
Any single entity may be identified as the aggregate of its (inter-)actions with its external environment. If a system's governance wholly defines these, it may properly be considered to identify the entity.
Common systems
Notes:
Goals
| Utility | - decision maximizes society's welfare - it reflects people's preferences |
| Legitimacy | - decision is considered fair - people trust the process |
| Practicality | - process is fast - it is simple to understand |
Notes:
Goals
Notes:
Dictator
Notes:
Democracy

Notes:
Simple Direct Democracy
Notes:
Simple Direct democracy
Compare to a two-party system
Notes:
Simple Direct democracy
Notes:
Voting paradox
Does direct democracy maximize utility? Probably not.
Example: Option A: 0 dollars Option B: 100 dollars
Prob. that my vote flips the result from A to B: <0.1%.
So, my expected profit for voting is <10 cents.
Notes:
Voting paradox
Voting paradox: For a rational, self-interested voter, voting costs will normally exceed the expected benefits.
Minimal chance that single vote changes collective decision, so most of the time the individual voting benefit is zero.
A common good game: globally optimal if everyone votes, but personally optimal not to vote.
Notes:
Voting paradox
Voting paradox: For a rational, self-interested voter, voting costs will normally exceed the expected benefits.
It leads to a low turnout, which affects legitimacy.
Turnout: percentage of people who choose to vote.
Notes:
Rational ignorance
Rational ignorance: refraining from learning when the cost of educating oneself on an issue exceeds the expected potential benefit.
As a result, most people will not vote judiciously.
Notes:
Rational ignorance
Whether or not someone votes can be biasable.
40% of the population supports a new proposal, while 60% rejects it. However, a company who will profit from the decision lobbies for the 'aye'. 50% of supporters and 30% of detractors vote. As a result, the proposal passes.
Notes:
Solutions to the voting paradox
Notes:
Advanced Forms of Democracy
Solutions to the voting paradox
Notes:
System capture
Does a dictatorship maximize utility? Also probably not.
System capture: A decision-making system in which a clique manages to impose its opinion consistently.
Their special interest is prioritized over the interest of the collective, leading to a decrease of general welfare.
Notes:
System capture
Example: in a movie club, 40% of people like comedy, 30% like drama, 30% like action.
Should they watch a comedy every time?
What if it was 60%, 20%, 20%?
Notes:
System capture
Notes:
Random dictator
Whenever there is a decision to be made,
pick a person at random in the collective
and let them decide as a dictator.
Notes:
Random dictator
Notes:
Capture resistance vs. stability
Notes:
Recap
Voting mechanisms
Notes:
Voting mechanisms
We will see the following notions:
Notes:
Single-vote mechanisms
Mechanisms where each voter picks one candidate.
Notes:
Single-vote mechanisms
Plurality: 8 votes for A, 5 votes for B, 7 votes for C.
Two-round:
| 1st | 2nd | 3rd | |
|---|---|---|---|
| 8 voters | A | B | C |
| 7 voters | C | B | A |
| 5 voters | B | C | A |
Notes:
Vote splitting
Notes:
Image source: https://indianexpress.com/article/political-pulse/the-10-other-sahus-how-namesakes-almost-cost-bjps-chandu-lal-sahu-a-win/
Vote splitting
| 1st | 2nd | 3rd | |
|---|---|---|---|
| 8 voters | A | B | C |
| 7 voters | C | B | A |
| 5 voters | B | C | A |
Notes:
Monotonicity criterion
Notes:
Monotonicity Criterion
Two-round:
| 1st | 2nd | 3rd | |
|---|---|---|---|
| 6 voters | A | B | C |
| 2 voters | A | C | B |
| 3 voters | B | A | C |
| 3 voters | B | C | A |
| 5 voters | C | B | A |
| 2 voters | C | A | B |
Notes:
Monotonicity Criterion
Bottom-row voters raise their preference for A.
Two-round:
| 1st | 2nd | 3rd | |
|---|---|---|---|
| 6 voters | A | B | C |
| 2 voters | A | C | B |
| 3 voters | B | A | C |
| 3 voters | B | C | A |
| 5 voters | C | B | A |
| 2 voters | A | C | B |
Notes:
Strategic voting
A mechanism in which a voter increases the chances of a candidate by not voting for them.
Notes:
Ranked-vote mechanisms
Mechanisms where each voter ranks all candidates.
| 1st | 2nd | 3rd | |
|---|---|---|---|
| 8 voters | A | B | C |
| 7 voters | C | B | A |
| 5 voters | B | C | A |
Notes:
Borda count
Notes:
Borda Count
| 2 points | 1 point | 0 points | |
|---|---|---|---|
| 8 voters | A | B | C |
| 7 voters | C | B | A |
| 5 voters | B | C | A |
16 points for A, 25 points for B, 19 points for C.
Notes:
Recap
Notes:
Break
Notes:
10 minutes
Discussion
Goals clash
We mentioned that the main goals of a decision-making system are utility, legitimacy and practicality.
Can you think of real-life scenarios where these goals clash?
Notes:
Sampling voters
In a country that runs referendums periodically, the turnout is only 2%, and older people tend to vote much more often than younger people.
The president changes the voting mechanism so that in each referendum, only 5% of the population elected uniformly at random is allowed to vote. As a result, every person is allowed to participate in one out of 20 referendums on average.
It is now observed that 80% of the people allowed to vote actually vote, so the global turnout grows from 2% to 4%. Moreover, the previously correlation between age and willingness to vote decreases considerably.
Would you support this new mechanism?
Notes:
A holy grail
A "holy grails" of voting theory is finding a voting mechanism that simultaneously offers local privacy and global transparency: no one should be able to see another person's ballot, but enough aggregate information about the ballots should be public so that everyone can verify the correctness of the result.
Suppose such a mechanism is created using cryptography; however, it requires every voter to use a private key and be trained in the basics of cryptography. A nation's president proposes to use such a mechanism, but the feedback from the population is negative, because people don't trust digital voting or cryptography.
What goals are at odds here? What would you do as president?
Notes:
Proof of Stake
In a Proof-of-stake (PoS) based blockchain network, validators are the nodes that participate in the consensus protocol and produce blocks. While it is possible to have a "pure" PoS mechanism where every token holder can participate in consensus directly (imitating PoW), most high-profile projects bound the number of validators that get to be active at any given moment.
Instead, these project opt for "representative democracy" and let token holders express their preferences for the set of active validators. Examples of blockchain projects that do this are: Polkadot, Cardano, Cosmos, EOS, Tezos and Tron.
What do you think are the main reasons behind this choice?
Notes:
Secure Validators
We saw that it's critically important for security to ensure that the set of validators is not captured by an adversary. Suppose we succeed, so that a super majority of validators participate in consensus honestly.
A priori, the mechanism for electing validators can be completely independent of the mechanism for deciding on upgrades. However, some projects merge them together. In particular, consider a project that on any referendum, delegates the voting power of all the passive stakeholders to the set of validators.
Does this constitute capture of the governance body?
Can you think of examples where the interests of validators are markedly different from the interests of the collective?
Notes:
The Economics of Polkadot
How to use the slides - Full screen (new tab)
The Economics of Polkadot
Overview
Remark: There are currently many changes planned

Token Economics
DOT Token
Inflation Model
Inflation Model
Inflation Model
Inflation
Notes:
Question: What do you think about Inflation?
Potential changes incoming
Staking: Concept
Validators
Nominators
Rewards

Validator Selection
Parachains
What are Parachains?
Parachain Slots
Economic Intuition
What do Parachains get?
Outlook Polkadot 2.0
Core Attributes of Blockspace
Blockspace Ecosystem
Bulk markets
Why the change?
Treasury
Treasury as DAO
How does it all fit together?

Takeaways
Further Resources
⛓️ Blockchains and Smart Contracts
Blockchain and applications built on them covered in depth conceptually and hands-on operation and construction.
Blockchains and Smart Contracts Overview
How to use the slides - Full screen (new tab)
Blockchains and Smart Contracts Overview
Upholding Expectations
What is the core problem we want to solve?
Trustless provisioning of infrastructure.
Notes:
Something kind of like a server, that doesn't rely on a server operator, and has strong guarantees like Cryptography has to offer.
One framing: Coming to a shared understanding of a common history, and therefore a common state, of a system.
Comparison with Cryptography
Cryptography provides strong guarantees about messages without a trusted party, regardless of the conduit over which a message was transported.
Notes:
Crypto guarantees:
Application Disentanglement
Removing trust allows us to unpackage applications.
Notes:
The idea here is to discuss how applications are often seen as an entire bundle: e.g. Instagram is the database, the algorithms, the UX. But when we have credible expectations that we're interacting with the same system, rules, data, it's possible to build lots of ways to access and interact with the system. It also removes the need for a central authority to deal with all appeals/complaints from various users.
Desired Properties
---v
Permissionless access
Anyone should be able to access and interact with the system.
---v
Privacy
Users should have credible expectations about what information they give up about themselves.
---v
Authenticity
Users should have credible expectations about the messages they see, regardless of the platform the messages are on.
---v
Finality
Users should be able to form credible expectations about when a state transition is final.
---v
Behavior
The system should behave as expected, even if system operators do not.
---v
Unstoppability
No individual actor, company, state, or coalition should be able to degrade any of these properties.
A Shared History

Notes:
So now we understand the goals of web3. How do we achieve them? The key is allowing users to agree on a shared history. The simplest blockchains do nothing more than timestamp and attest to a stream of historical records. In Web 2 users have no visibility into the history of the app. They must trust the provider to accurately represent the current state. By giving the service provider the power to change the story, we give them the power to shape our understanding of reality and consequently our behavior.
---v
A Shared History
Any large-scale operation - whether a modern state, a medieval church, or an archaic tribe - is rooted in common stories that exist only in people's collective imaginations.
Telling effective stories is not easy. The difficulty lies ... in convincing everyone else to believe it. Much of history revolves around this question: How does one convince millions of people to believe particular stories about gods, nations, or LLCs?
-- Yuval Noah Harari, Sapiens --
---v
Shared Story of a State Machine
If we agree on:
Then we MUST agree on:
Notes:
Now that we have a formal math-y model of systems that we care about, we can see that the notion of shared stories being powerful is more than slick language of philosophical mumbo jumbo. Even the term genesis state (or genesis block) is taken straight from mythology. We aren't newly discovering or inventing the idea that having a shared understanding of our past is important. It dates back to pre-history. We are just formalizing it and applying it to digital services.
Blockchains (Finally)
A blockchain can be thought of in three parts
State Machine
What does the state hold?
What are the rules to change it?
Shared History (data structure)
Which potential histories exist?
Consensus
Which history is the real one?
What part of history is final?
Notes:
First, each blockchain tracks some state machine. We've discussed several examples of what that might be already, we'll code some simple examples shortly, and we'll spend all of module 5 digging into how to create a blockchain-friendly production-ready state machine.
Next is the Blockchain Data structure. This data structure is basically a linked list of state transitions. But unlike the linked lists you studied in your data structures course, it isn't just linked by memory addresses or any other malleable thing. Instead it is cryptographically linked so that if anyone presents a different history, you can tell right away that you don't agree on a shared history. We'll dive into this data structure in the next lesson.
Finally, is a consensus mechanism. Defining a state machine alone does not uniquely define a history. There are many possible valid histories. Just like the many worlds interpretation of quantum mechanics. To really agree on the current state, we need to agree on which of the possible histories is the real one.
---v
Short History of Blockchains
---v
Bitcoin
Uses an unspent transaction output (UTXO) model & Proof of Work (PoW) consensus.
Notes:
Who knows where the figure is from?
CLICK
Bitcoin was first. It was a money app. The first app chain. It hosts a smart contract in the broad definition.
It was the first time most people considered a digital service that was not run by a particular person.
Figure source: Bitcoin white paper
---v
Litecoin, Monero, Dogecoin

Notes:
Only a few year later people realized they could fork the code and make small changed and improvements. Some changes were trivial. Some were interesting: monero and privacy.
For me personally, this was a small crisis. I thought bitcoin was the one global one. Aren't these other coins undermining the narrative? NO! The point is that anytime you don't like the system or have an idea for a better one, you can do it! If you don't like bitcoin, build your own coin and make it better. Let the market decide.
---v
Ethereum
---v
Smart contracts - Two Definitions
Broad Definition "Szabo definition"
A machine program with rules that we could have defined in a contract, but instead a machine performs or verifies performance.
Narrow Definition "web3 definition"
A program that specifies how users can interact with a state machine and is deployed permissionlessly to a blockchain network
Rocket Cash
Web2 digital cash example.
📥 Clone to start: Rocket Cash
See the README included in the repository for further instructions.
Digital Services as State Machines
How to use the slides - Full screen (new tab)
Digital Services as State Machines
Web0
Telegraph, Telephone
Users transmit information peer-to-peer.
Crypto not typically used except by military, but upheld guarantees when used.

Notes:
I want to go through a brief history of the web. This is not a history course, but it is important to understand the context of the web and how we got to where we are today. I will be using the term "web" to refer to the internet, but I will also be using it to refer to the world wide web. The internet is the physical infrastructure that allows computers to communicate with each other. The world wide web is one of the several utilizes including e-mail, File Transfer Protocol (FTP), Internet Relay Chat (IRC), Telnet, and Usenet that form the Internet. Okay so let's back up before all of that though - The term web0 isn't a common nomenclature - but basically this is old school Telegraph and telephones and in this era users transmitted information peer-to-peer. There was no intermediary. There was no service provider. There was no web server. There was no database. I would call up a friend - be connected via a wire - and we would talk, end to end. sure there are switchboard operators, but you could think of it as one really long wire connecting me to my friend I'm calling. Which is actually a perfect scenario for cryptography to uphold its guarantees. Once I talk to the switchboard operator and get routed to you, then we can just talk over our Cipher. It's really peer to peer, which is great! However, people were not really aware of the threat model and cryptography was not really used except by the military. But when it was used, it was used to uphold its guarantees. So this is like a property that we want to try to restore in web3.
Web1
Introduction of always-on servers.
Still mostly peer-to-peer.
Cryptography more often, but still not ubiquitous.
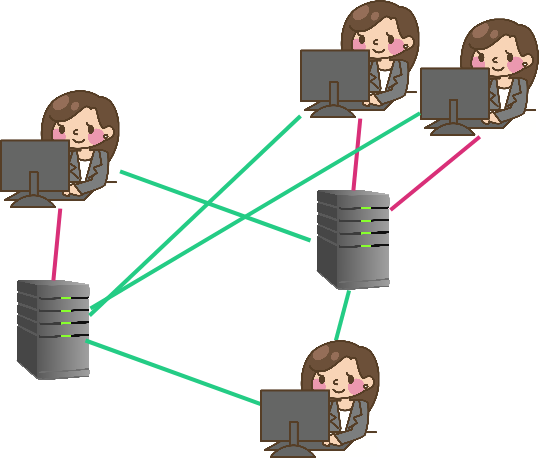
Notes:
Web 1 brings us to the 70s and 80s (maybe early 90s). This is an introduction to always-on servers. so with web0, with the telephone - I pick up my phone when I'm calling someone or when someone calls me and then I put it down and I'm offline the rest of the time. But in web1, we have these always on servers but it's still mostly peer-to-peer because people, at least two kind of a first order approximation had their own servers so in the clipart, we've got users and their servers - these pink lines are a connection to your own server. So this user has her own server and these two users maybe share a server - I don't know, they work for the same company or go to the same University or something and then this user doesn't have her own, maybe she's just consuming information and she's more of a casual user. So web1 is pretty similar to web0 and cryptography did start to become used a little bit more, but it still was not very ubiquitous and it's basically just because of the kinds of applications that people were using web1 for - it was mostly just for sharing information. Classic example is publishing - you would publish your paper or your data set and the whole idea is if you're publishing something, you really don't need to be keeping it secret, and in fact you're actually trying to NOT have it be secret. You're trying to put it out there for everyone to use and read. Now authenticity guarantees for sure would have still been great here - to know that your data didn't get tampered with along the wire... but again the threat model just wasn't in practice quite so bad and so like people got away without cryptography.
Web2
Introduction of Digital Services with Rich State.
Administered by service providers: "Send us your information."
However, users must place faith in the service provider.
Cryptographic guarantees are about interactions with the service provider, not peers.
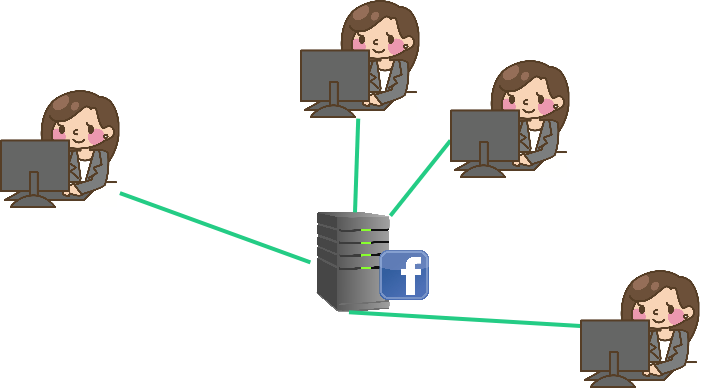
Notes:
So that brings us to web2. 1999 or 2004, wherever you want to put it really. Web2 brings the introduction of Digital Services with Rich state - so we're talking about web apps. Who here remembers Myspace? I was obsessed with curating my top 8. And then of course Facebook or whatever social media platform and beyond. But it's not just media either, there's eBay and Amazon and you can register to vote online and there's all these Services where you just go online you fill some data into a web form - maybe you don't even have to do a page reload - and that basically submits a transaction to some back-end server somewhere! So we begin to get these really really useful Digital Services. You can even think about things like Google search for example, that hardly existed in web1. Notice that there are no more pink lines in the diagram - people don't have their own servers - they're all connected to this one Central server. Obviously in reality it isn't a single Central server, but the the point kind of remains - it's a small number of centralized service providers.
---v
Digital Services
People rely on digital services every day. They are inescapable and valuable.
Notes:
I should note - Digital services are not bad in and of themselves. They are very valuable. We use all of these every day. We are even using some to administer this course. But they are also hard to escape. What are other examples? I have some listed here - online banking, what else?
And the key thing here is that they're all administered by these service providers and the model is - don't call your friend on the phone and communicate directly with them anymore - instead send us your information -
---v
Trust Example
Two users on Twitter:
Notes:
Or rather, send your Tweet directly to Twitter server and then we'll publish it and then when your friend comes to us, we'll tell them that this is what you tweeted. trust me bro, this is what lauren tweeted, it's real. So this is asking you to place trust in the service provider. Once web2 became popular, cryptography became a bit more widespread. Look at the icon at the top of your browser - let's use github for example - That is ensuring me that I'm communicating over SSL to GitHub and they're encrypting all the communication and I am too, which is awesome! Because suddenly we're using this really cool cryptography that we've been developing over decades! But here's the thing - say if you go to pull my repo, you're not pulling it from me anymore, you're pulling it from github. So GitHub knows that nothing was corrupted between me and them and you know that nothing was corrupted between GitHub and you. But the thing is, github's right there - they could change my repo if they wanted to or they could maybe even have the power to take my repo offline. But here, the slide reminds us that we all essentially accept a trusting relationship with the service provider. We trust that we're seeing information from the same database, we trust that if a tweet is from Aaron, then Aaron wrote that tweet, we trust that others see our messages as from us, we trust that the messages we see are the messages the users wrote, and we trust that we're interacting with the application as equals. Cryptography actually provides a lot of these guarantees, but not when an intermediary has stepped in between users.
---v
God Mode Enabled
In web 2, service providers can perform abuses:
Notes:
Okay in summary, these are the problems that trusted service providers can do to us. They can censor our interactions, they can restrict our interactions, they can fail to produce requested data, and they can mutate state opaquely.
---v
Thought experiment: Digital Currency
Bitcoin's application was digital currency - a trivially simple application.
Could this be built with Web2 technology?
Notes:
Let's do a thought experiment. Bitcoin came out 2009, it's a trivially simple application. n Bitcoin's application was digital currency. When you think about just the money thing - sending money from one person to another. How many of you think that if I give you like a weekend hackathon project, you could develop some kind of web2 style service and deploy it to AWS or digitalocean or wherever - that would basically act like a currency where I could log in and send my peers money. Could you build this with web2 technology? Yep you absolutely could. This is the kind of simple app you might build in a Freshman year course. You just need to maintain a set of bank notes and their owners (or alternatively a set of accounts and their balances.) So why didn't this exist in web 2? I hope this is pretty obvious. Because the provider could print money. Or steal money. Right? The moment somebody pisses me off I can go and freeze their funds or whatever. So even though coding the cryptocurrency application is like super simple it's totally useless because there's no incredible way to build trust in it. And that's what the blockchain is about. And that's what Joshy is going to speak to very soon.
---v
Distributed Applications in Web 2
Providers run redundant data centers to prevents accidents.
But it still assumes benevolent participants and some trusted leader.
Notes:
Something we should call out - there are some distributed applications in web2, but it's a little bit different than what we're talking about here. It's not like AWS folks are noobs and they have all their stuff in one Data Center and the moment that there's an earthquake or a fire or whatever everything that hosted on AWS goes down. They're better than that, they have data centers all over the world. But the difference there is that all of those data centers are operating as trusted peers. So one of them will lead and those changes will be synced to the others and the moment one goes down it fails back to the next one to keep the services live. Which is for sure a good thing, I'm not hating on that aspect of it, but the point that I'm making is that it doesn't make it trustless just because it's geographically distributed. It just makes it more resistant to accidents. AWS could still cut it down. Ultimately, the point is that in web2, the masses become beholden to the service providers who were free to extract value and manipulate the users.
Web3
A provision of digital services without the need to trust a service provider.
Providers do not need to be trusted; they are economically incentivized to behave honestly.
Notes:
Okay so web3 - We want to maintain the value, versatility, and richness of Web2, but remove the trust, and possibility of extractive behavior. Here I have: It's a provision of digital services without the need to trust a service provider. At an abstract level, the way that we make people trustworthy is that we give them economic incentives to behave honestly. So throughout this course we're going to design protocols and we're going to say things like, as long as two-thirds of the operators in this protocol are following the protocol, then all these guarantees I talked about are upheld! That's great. But then the glaring question is: well okay - how do you make sure that two-thirds of the operators are following the protocol? It always come back to economic incentives. Hence why you had econ and tokenomics last week. Because that's how we're going to get all of these mutually distrusting, not otherwise incentive aligned parties to agree to follow the protocol - by creating the incentive such that following the protocol is the best strategy: they can maximize their own utility by following the protocol.
---v
Desired Approach
Allow users to interact with a common system without trusting any intermediaries.
Opens the door to new application stacks:
Notes:
We want to allow users to interact with the system without having to trust intermediaries who might stand in the middle between the users. If we can do that, it opens the door to this new application stack where we disentangle all the layers.
OKAY - so we're at the halfway point within this lecture, let's check in. At this point, we've been through the history of the web and hopefully understand the evolution from simple peer to pee communications to straight up digital services.
Adding to that, from my from first lecture, we ALSO understand that both software and contracts are solutions to expressing agreements, and during Aaron's activity, we practiced building a simple web2 style smart contract.
Now I want to start formalizing the semantics of how we actually build a smart contract.
It turns out there is a mathematical (or computer science maybe?) term called a state machine. And it maps really well to what we just built and the kinds of interactions we want to build.
State Machines

Notes:
What's interesting is that most systems, maybe all of them, but definitely most that we care about can be modeled as state machines. So State machine, it's not a real machine that you can build and touch and operate and stuff like that. It's a model comprised of a set of states and a set of rules about how to transition between the states. Looking at the diagram, maybe my state machine starts in state one over here and then somebody pokes it in some particular way, or to use more blockchain-y lingo, they send a transaction and that puts the state machine into into State-two. And so, what we're going to be doing with the blockchain is tracking a complete history of all of these transitions and if we know the history of all the transitions, then we should know what state we're in right now
---v
Labelled Transition Systems
Sometimes you can map the entire state space as an LTS.
Other times it is too big.
Notes:
There's this notion of a labelled transition system. Sometimes if your state machine is simple enough you can actually map the entire State space as a labeled transition system. Most of the times when we're building real world applications, it's a little too big. But labeled transition systems are a really good model to keep in your mind when you're thinking about designing your state machines. Consider if we tried to map all possible states of a social media app or a digital currency. Sometimes an LTS drawing like this is useful, other times it would be too large or even infinite. Even still, sometimes drawing part of it can help you think about what the states and transitions might be.
---v
Example: Light Switch
Simple Switch: 2 States, 1 Transition
Labelled Transition System

History

Notes:
Let's look at a simple example. A light switch. CLICK It has two states: on and off. And one transition: flipping the switch. We can draw this as a labeled transition system. CLICK And we can also draw a history of the transitions that have happened. So if we know the history of all the transitions, then we should know what state we're in right now. So we start in some State down here for example where the light is on and then when a transition comes in it's we already know what kind of transition it's going to be. There's only one - it's the toggle transition that turns the light off and Etc and Etc and this could go on forever. Right now this is such a simple State machine that like this isn't going to be a very interesting history it's just going to be toggle toggle toggle toggle forever. But with that information, if if for some reason knowing whether this light was on or off is like super important to your Society or your community, you've now achieved it - or at least we know a way to start achieving it.
---v
State Machine Example: Digital Cash
Each state is a set of bank notes. Where a bank note has an amount and an owner. A transition involves a user consuming (spending) some bank notes and creating new ones.

Notes:
Let's look at a more interesting example. Digital cash. This is one where I can't draw the entire label transition system because it's way too huge. But I can draw a little bit of it. Each state is a set of bank notes. Where a bank note has an amount and an owner. A transition involves a user consuming (spending) some bank notes and creating new ones. Not all conceivable transitions are valid. Imagine a user consuming a bank note worth 5 coins, and creating two new ones each worth 3 coins. That's not allowed. So we have to be careful about what transitions are allowed and what transitions are not allowed. And again, if we know the history of all the transitions, then we should know what state we're in right now.
---v
Sate Machine Example: Social Media
Each state is a set of posts and their associated comments and emoji reaction counts. A transition involves, making a new post, or reacting to someone elses, or commenting

Notes:
state is a set of posts and their associated comments and emoji reaction counts. A transition involves, making a new post, or reacting to someone elses, or commenting There is not a single model here. Some state machines will allow deleting or editing posts, while others will not. Some will allow disliking posts while others only allow liking. Here the diagram basically we see - if the state starts out simple with this one Post in it and then someone makes a new post (and there would have to be more details in here about who's posting and what they're posting)But then we get to this new state and then maybe the next transition is that somebody likes post number one and so now the state contains a record that this thing is liked. Just to drive the point home the idea is that if you know the starting State and you know the history of the transitions, then you know the the current state and so you can sit and watch as every transition comes in you can validate them yourselves and say this one's good we're adding it to our history or this one's bad we're chucking it's invalid transition. And then therefore you can know the final state
---v
More State Machine Examples:
Notes:
There are all kinds of these - uber, polkadot's governance, and gambling! Take a moment to brainstorm with your table about each of these three examples as well as the app you built in the previous activity. For each example, write out what are the state transitions and the the states. If possible, draw a complete LTS. If that is not possible, draw a partial LTS.
---v
Garage Door Lock

Notes:
One more team exercise. Draw a state transition diagram for a garage door lock keypad.
If the user enters the correct 4 digits, the door opens (or closes if it was already open). The thing is, you could enter some random digits before you enter the correct code, and it would still open after the correct code. As you sketch your states, be sure to handle that correctly.
This example is drawn from https://eng.libretexts.org/Under_Construction/Book%3A_Discrete_Structures/09%3A_Finite-State_Automata/9.02%3A_State_Transition_Diagrams which has many other excellent examples
Build Some State Machines
Blockchain From Scratch Activity
Chapter 1 State Machines
Notes:
This activity is going to run over the next four days. We will have a good amount of time to work on it in class. We will also set some minimum completion goals each evening.
Blockchain from Scratch
Learn the fundamentals of blockchain by building it from scratch. In Rust.
📥 Clone to start: Blockchain from Scratch
See the README included in the repository for further instructions.
Peer-to-Peer (P2P) Networking
How to use the slides - Full screen (new tab)
Peer-to-Peer Networking
Introduction/Agenda
ARPANET
Notes:
Total Information Awareness (TIA): In the early 2000s, DARPA initiated the TIA program aimed at developing technologies for mass surveillance and data analysis. The project raised concerns about privacy and civil liberties, eventually leading to its cancellation in 2003 due to public outcry.
Packet Switching
Packet Switching

Notes:
Mention that headers contain some addressing, destination information, and ordering typically depending
Packet Switching

Packet Switching

Packet Switching

Packet Switching

Peer-to-Peer (P2P) Networks
Historical P2P applications
Notes:
Napster, Limewire
Napster
Notes:
Napster's story is closely tied with the band Metallica. In 2000, Metallica discovered that a demo of their song "I Disappear" was being circulated via Napster before its official release. This led to Metallica filing a lawsuit against Napster for copyright infringement. Napster had to comply by banning hundreds of thousands of users from their platform who were sharing Metallica's music. This was a turning point in digital copyright law and played a significant role in Napster's eventual shutdown in 2001.
Napster Setup

Napster Setup

Napster Setup

Napster Setup

Gnutella(Limewire)
Notes:
Client-Server vs Peer-to-Peer (P2P) Networks
| Client-Server Network | P2P Network | |
|---|---|---|
| Structure | Centralized: One or more central servers control the network | Decentralized: All nodes (peers) participate equally |
| Data Flow | Server provides data to clients | Peers directly share data with each other |
| Resource Management | Servers manage resources and control access | Peers contribute resources including bandwidth, storage space, and processing power |
| Scalability | Can be limited by server capacity | Highly scalable due to the distribution of resources |
| Security | Centralized security measures, single point of failure | Potential for some security issues, malware(Depending on how it is implemented) |
Centralized vs Decentralized Networks

Notes:
Talk about how when a partition happens in P2P vs Centralized. In p2p, only one node needs to have a full copy in order for the file to be able to be distributed across the network.
Centralized vs Decentralized Networks

Centralized vs Decentralized Networks

Centralized vs Decentralized Networks

Advantages to Decentralized Networks
Notes:
Difficulties or Disadvantages
Notes:
Gossip Protocol

Notes:
---v
Gossip Protocol

Notes:
Talk about advertising vs just blind sending and how that can be inefficient
Structured vs Unstructured P2P Networks
| Structured P2P Networks | Unstructured P2P Networks | |
|---|---|---|
| Organization | Nodes are organized following specific protocols and structures (like Distributed Hash Tables) | Nodes are connected in an ad-hoc manner without any particular organization |
| Search Efficiency | Efficient search operations due to structured nature | Search operations may be less efficient and can involve flooding the network |
| Flexibility | Less flexible as changes in topology require restructuring | Highly flexible as nodes can freely join, leave, and reorganize |
| Privacy | Data location is predictable due to structured organization | Greater potential for anonymity |
Discovery
Applications
Notes:
Initial Discovery
Notes:
Attacks
Notes:
Attacks

Notes:
Attacks

Eclipse Attack Execution
Preventing Attacks
Notes:
Conclusion
P2P networks offer us a path forward towards applications which are more decentralized and censorship resilient
Blockchain from Scratch
Learn the fundamentals of blockchain by building it from scratch. In Rust.
📥 Clone to start: Blockchain from Scratch
See the README included in the repository for further instructions.
Platform Agnostic Bytecode
How to use the slides - Full screen (new tab)
Platform Agnostic Bytecode
Review of Compilers
🤯 Fun Side Reading: Reflections on Trusting Trust
Notes:
Just a very quick reminder of how compilers work. Humans write programs in some human readable language like Lauren talked about. Then the compiler translates the semantics of that program into an equivalent program in a much lower more machine-readable language called a bytecode.
CLICK
Whenever I show this diagram or talk about compilers, I always like to mention one of my favorite essays ever. Ken Thompson's 1984 Turing Award lecture.
Definition
A PAB is a bytecode that follows two main principles:
Notes:
Ideally a bytecode like this is designed to be executed on a virtual machine that follows general known patterns.
High Level Languages
PABs
Architecture's bytecode
Notes:
From left to right you can see different levels of abstraction over the program that will ultimately be run on some machine. Generally, from a high level language you need two compilation step if you want to pass through a PAB.
Other examples of PABs used right now:
---v
Compiling in a PAB

Notes:
So when we are using a PAB, we need to compile twice. This is, of course, the cost to using a PAB. In this lesson we'll also explore the advantages.
What a PAB allows is:
Notes:
The main goal of a PAB is to make the code portable, you should be able to compile it once and then share it around without caring about the architecture on which will be executed. Of course in a decentralized network we want that different nodes, with different architectures came up to the same result if the input are the same, that's called determinism, if a PAB would not have determinism then reaching consensus is impossible.
---v
That's why PABs are so important
Desireable Features
Notes:
---v
Sandboxing?
An environment for running untrusted code without affecting the host.

A SmartContract is Arbitrary Code that may be executed on other people's infrastructure, we don't want SmartContracts capable of destroying the nodes on which they are executed
Notes:
CLICK read definition
The term sandbox is an analogy to kids playing in a sandbox. The parent puts the kid in the sandbox and tells them they can play in the sandbox and they are safe as long as they stay in. Don't go in the woods and get bitten by a snake or in the road and get hit by a car. Just stay in the sandbox.
Of course the analogy isn't perfect. The children in the sandbox stay there because the parent asked them to. They could leave anytime they wanted to. For actual untrusted code, a better analogy would be a walled garden or a Jail
---v
Sandboxing?

A sandboxed environment must be created by the executor of the PAB.
Notes:
Of course the security can be seen by various point of view and some examples are:
Those things can't be addressed by the PAB itself but they can give good guidelines and code design to make an 100% secure implementation of the executor possible.
PAB's lifecycle example







WebAssembly
Wasm's key points
Notes:
Wasm seems to respect every rating points we defined before
Stack-Based Virtual Machine Example
Adding two number in wasm text representation (.wat)
(module
(import "console" "log" (func $log (param i32)))
(func $main
;; load `10` and `3` onto the stack
i32.const 10
i32.const 3
i32.add ;; add up both numbers
call $log ;; log the result
)
(start $main)
)






Notes:
Wasm has also a text representation, Wat has some features that allow for better readability:
Instructions push results to the stack and use values on the stack as arguments, the compilation process generally translate this stack-based bytecode to register based, where registers are used to pass values to instructions as a primary mechanism. The compilation will try to elide the wasm stack and work with only the architecture registers.
There is another type of stack used in wasm and that's called: shadow stack, resource to learn more: https://hackmd.io/RNp7oBzKQmmaGvssJDHxrw
Wasm seems to be a perfect PAB, but
Notes:
Assuming all the things we said before wasm seems to be perfect but how those things really works?
Communication with the Environment
Let's call Embedder the program that will take the wasm blob as input and execute it
---v
Problem
Wasm has no ambient access to the computing environment in which code is executed
Solution

Notes:
Memory
In addition to the stack Wasm has also access to memory provided by the embedder, the Linear Memory.
Notes:
From Wasm the Linear Memory is byte addressable Linear Memory can be manipulated using functions called 'store' and 'load'
The Rust compiler uses for dynamic/heap memory and to pass non primitives values to functions by emulating an additional stack within the linear memory, this emulated stack (the shadow stack) is what we would understand as stack in other architectures
---v
Example


Notes:
Here's an example, wasm sees linear memory like a byte array and if it tries to access the second byte, it would use an index 1. When it's time to execute it the embedder will see this access and translate the linear memory access at index 1 to a standard memory access to base_linear_memory + 1.
Buffer overflow? Wasm uses 32 bit, this makes impossible to have an offset bigger then 4GiB, this means that the embedder can leave those 4GiB free in its virtual memory to makes impossible to the wasm blob to access any environment information. Even if the offset is only positive there are embedded that are defining as protected the 2GiB before the BLM so that if for some reason the wasm code trick the embedder to treat the offset as a signed number that would cause an Operating System error.
How Wasm is executed
There are multiple ways to execute wasm:
Notes:
AOT: Compile all the code at the beginning, this allows to makes a lot of improvement to the final code efficiency JIT: The code is compiled only when needed, examples are functions that are compiled only when called, this leave space only to partials improvements SPC: This is a specific technique of compilation that is made in linear time, the compilation is done only passing once on the code Interpretation: The wasm blob is treated as any other interpreted language and executed in a Virtual Machine
---v
Wasmtime
Notes:
Cranelift is a fast, secure, relatively simple and innovative compiler backend. It takes an intermediate representation of a program generated by some frontend and compiles it to executable machine code
---v
Wasm lifecycle in Wasmtime




---v
Wasmi
Notes:
proposal to switch from a stack based ir to registry based ir https://github.com/paritytech/wasmi/issues/361
paper explaining the efficiency of translating wasm to registry based code https://www.intel.com/content/www/us/en/developer/articles/technical/webassembly-interpreter-design-wasm-micro-runtime.html
Due to it's characteristics it is mainly used to execute SmartContracts on chain
---v
Wasm lifecycle in Wasmi




Alternatives
---v
EVM
---v
CosmWasm
---v
Solana eBPF
Notes:
https://forum.polkadot.network/t/ebpf-contracts-hackathon/1084
---v
RISC-V ?!
Being so simple and "Hardware-Independent" there are work in progress experiments to test if it is suitable to become the new polkadot smart contract language
Notes:
Discussion about using RISC-V as smart contract language: https://forum.polkadot.network/t/exploring-alternatives-to-wasm-for-smart-contracts/2434
RISC-V Instruction Set Manual, Unprivileged ISA: https://github.com/riscv/riscv-isa-manual/releases/download/Ratified-IMAFDQC/riscv-spec-20191213.pdf
Activity: Compiling Rust to Wasm
---v
Activity: Compiling Rust to Wasm
---v
Rust -> Wasm Details
#![allow(unused)] fn main() { #[no_mangle] // don't re-name symbols while linking pub extern "C" fn add_one() { // use C-style ABI ... } }
and if a library:
[lib]
crate-type = ["cdylib"]
---v
Activity: Compiling Rust to Wasm
rustup target add wasm32-unknown-unknown
cargo build --target wasm32-unknown-unknown --release
wasmtime ./target/wasm32-unknown-unknown/release/wasm-crate.wasm --invoke <func_name> <arg1> <arg2> ...
---v
Additional Resources! 😋
Check speaker notes (click "s" 😉)
Notes:
-
More on PAB:
-
More on Rust target spec:
-
Lin Clark's awesome talks on WASI (not super relevant to our work though):
-
wasm-unknownvswasm-wasi: -
extern "C": -
Chapter 11 of this book is a great read: https://nostarch.com/rust-rustaceans
Wasm Executor
In this activity, you will practice compiling Rust code to a few different wasm targets. You will also learn to embed a web assembly executor in your own binary application. We will focus on Rust, but also briefly look at executing wasm from Python to demonstrate the platform agnostic nature of Wasm.
📥 Clone to start: Wasm Executor Activity
See the README included in the repository for further instructions.
Blockchain Structure
How to use the slides - Full screen (new tab)
Blockchain Structure

Shared Story
A Blockchain cryptographically guarantees that a history of events has not been tampered with. This allows interested parties to have a shared history.
Notes:
And it allows them to know whether they have identical histories in O(1) by just comparing the tip of the chain.
Hash Linked List

Notes:
This is a simplified blockchain. Each block has a pointer to the parent block as well as a payload.
---v
Hash Linked List

Notes:
The pointer is a cryptographic hash of the parent block. This ensures data integrity throughout the entire history of the chain. This is the simplest form that a blockchain could take and indeed it allows us to agree on a shared history.
---v
Hash Linked List

Notes:
This ensures data integrity throughout the entire history of the chain. This is the simplest form that a blockchain could take and indeed it allows us to agree on a shared history.
---v
Genesis Block

Notes:
The first block in the chain is typically called a the "Genesis block" named after the first book in the judaeo-christian mythology - The beginning of our shared story. The parent hash is chosen to be some specific value. Typically we use the all-zero hash, although any fixed widely agreed-upon value would also do.
State Machines (Again)
A state machine defines:
- Set of valid states
- Rules for transitioning between states

---v
Blockchain meet State Machine

Notes:
The simplest way to join a blockchain to a state machine is to to make the blockchain's payload a state machine transition. By doing so, we effectively track the history of a state machine in a cryptographically guaranteed way.
---v
Where do the States Live?
Somewhere else!

Notes:
There is a state associated with each block. But typically the state is NOT stored in the block. This state information is redundant because it can always be obtained by just re-executing the history of the transitions. It is possible to store the state in the blocks, but the redundancy is undesirable. It wastes disk space for anyone who wants to store the history of the chain. Storing the state in the block is not done by any moderately popular blockchain today. If you want to store the states, you are welcome to do so. Software that does this is known as an Archive node or an indexer. But it is stored separately from the block ...Pause... One more time to make sure it sinks in: The state is NOT in the block.
---v
State Roots
A cryptographic anchor to the state

Notes:
Some data redundancy can be good to help avoid corruption etc. It is common for a block to contain a cryptographic fingerprint of the state. This is known as a state root. You think of it as a hash of the state. In practice, the state is typically built into a Merkle tree like structure and the tree root is included. Not all blockchains do this. Notably bitcoin doesn't. But most do. We'll go into details about exactly how this state root is calculated for Substrate in the next two modules, but for now we just consider the state root to be some kind of cryptographic fingerprint.
Forks

A state machine can have different possible histories. These are called forks.
Notes:
You can think of them like alternate realities. We need to decide which of the many possible forks is ultimately the "real" one. This is the core job of consensus and we will talk about it in two upcoming lessons in this module.
---v
Invalid Transitions

Notes:
Before we even get to hardcore consensus, we can rule out some possibilities based on the state machine itself
Realistic Blockchain Structure

- Header: Summary of minimal important information about this block
- Body: A batched list of state transitions
Notes:
The header is a minimal amount of information. In some ways it is like metadata. The body contains the real "payload". It is almost always a batch of state transitions. There are many name aliases for what is included in the body:
- Transitions
- Transactions
- Extrinsics
---v
Blocks in Substrate
#![allow(unused)] fn main() { /// Abstraction over a Substrate block. pub struct Block<Header, Extrinsic: MaybeSerialize> { /// The block header. pub header: Header, /// The accompanying extrinsics. pub extrinsics: Vec<Extrinsic>, } }
Notes:
This example is from Substrate and as such it strives to be a general and flexible format, we will cover Substrate in more depth in the next module. This is representative of nearly all real-world blockchains
Headers
Exact content varies per blockchain. Always contains the parent hash. Headers are the actual hash-linked list, not entire blocks.
Notes:
The parent hash links blocks together (cryptographically linked list). The other info is handy for other infrastructure and applications (more on that later).
---v
Header Examples
Bitcoin
- Version
- Previous Hash
- Tx Merkle Root
- Time
- N_Bits
- Nonce
Ethereum
- Time
- Block Number
- Base Fee
- Difficulty
- Mix Hash
- Parent Hash
- State Root
- Nonce
---v
Substrate Header
- Parent hash
- Number
- State root
- Extrinsics root
- Consensus Digest
Notes:
Extrinsics root is a crypto link to the body of the block. It is very similar to the state root. Consensus Digest is information necessary for the consensus algorithm to determine a block's validity. It varies widely with the consensus algorithm used and we will discuss it in two upcoming lectures.
---v
Substrate Header (Full Picture)

Extrinsics
Packets from the outside world with zero or more signatures attached.
- Function calls to the STF
- Some functions require signatures (e.g., transfer some tokens)
- Others don't, but usually have some validation means
DAGS
Directed Acyclic Graphs
Notes:
In math there is a notion of a Directed Acyclic Graph. Define graph, than directed, than acyclic. Blockchains are examples of DAGs. Actually blockchains are a specific kind of a DAG called a tree. Sometimes you will hear me talk about the "block tree" which really means all the histories of the chain.
But there are more kinds of DAGs than just trees. Consider if someone authored a block that looks like this.
CLICK
---v
DAGS
Directed Acyclic Graphs

Notes:
What if a block could have more than one parent!? It could allow parallelization and increased throughput! But it also leads to problems. What if there are conflicting transactions in the two parent histories? How do you even know if there are conflicting histories?
Blockchain 💒 P2P Networks

Notes:
So hopefully some parts of this figure look familiar. What do you see here?
- Diverse servers.
- In a p2p network.
- Each with their own view of the blockchain.
---v
Nodes
Software agents that participate in blockchain network.
May perform these jobs:
- Gossip blocks
- Execute and Validate blocks
- Store blocks
- Store states
- Gossip transactions
- Maintain a transaction pool
- Author blocks
- Store block headers
- Answer user requests for data (RPC)
Many nodes only perform a subset of these tasks
---v
Types of Nodes
- Full Nodes
- Light Nodes (aka Light clients)
- Authoring nodes
- Archive nodes
- RPC nodes
Blockspace
A resource created, and often sold, by a decentralized blockchain network.
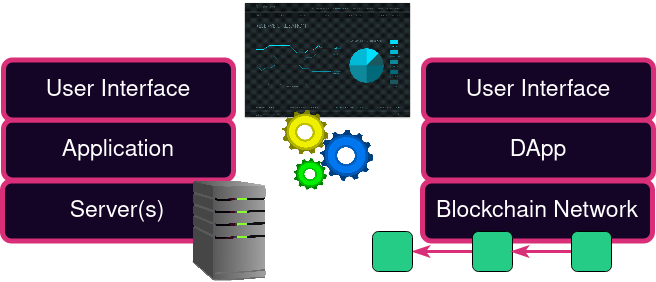
Learn more:
- Article: https://a16zcrypto.com/posts/article/blockspace-explained/
- Article: https://www.rob.tech/polkadot-blockspace-over-blockchains/
- Podcast: https://www.youtube.com/watch?t=5330&v=jezH_7qEk50
Notes:
A Blockchain network is a replacement for a centralized server. It sells a product to application deployers. The state machine is the application layer, and the blockchain is the server replacement. In the same way that applications pay data centers for server resources like cpu time, disk space, bandwidth etc. Applications (maybe via their developers or users) pay for the privilege of having their history attested to and their state tracked by a trustless unstoppable consensus layer.
---v
Transaction Pool
- Contains transactions that are not yet in blocks.
- Constantly prioritizing and re-prioritizing transactions.
- Operates as a blockspace market.
Notes:
Sometimes known as mempool (thanks bitcoin 🙄) Authoring nodes determine the order of upcoming transactions. In some sense they can see the future.
Foreshadow forks where players disagree on the rules History: dao fork bch fork foreshadow consensus: arbitrary additional constraints for a block to be valid
Let's #BUIDL It
Blockchain from Scratch
Learn the fundamentals of blockchain by building it from scratch. In Rust.
📥 Clone to start: Blockchain from Scratch
See the README included in the repository for further instructions.
Consensus Authoring
How to use the slides - Full screen (new tab)
Consensus: Authoring
---v
Consensus is...
...a decision making process that strives to achieve acceptance of a decision by all participants.
---v
Blockchain Consensus is...
...a decentralized consensus system to reach agreement over a shared history of a state machine.
---v
Blockspace

Blockchain consensus systems produce a resource called blockspace.
Strong incentive alignments and strong guarantees make for high quality blockspace.
Notes:
As we discussed blockspace represents the right to contribute to the shared history. This is a valuable resource that is offered to users as a product. We will discuss the selling of this resource in a later lecture on allocation and fees. The consensus system used plays a large role in determining the quality of the blockspace.
Forks Review

There are going to be forks. We need to decide which one is the real one.
We can rule some forks out to reduce the problem space. Then we are left to decide which is canonical.
Notes:
Forks represent alternate courses that history could take. They arise every time there is a difference of opinion.
You can think of them at a social level. Court cases, arguments, wars. Ideally we can resolve them peacefully
You can think of them at a very low physics-y level. Every time an electron encounters a potential barrier it either reflects of tunnels. When consensus is high-quality, the result is as objective as the outcome of a physical process.
Five Aspects of Consensus
- State machine validity
- Arbitrary / Political validity
- Authorship throttling
- Fork choice heuristic
- Finality
Notes:
The first two aspects are relatively simple and I'll discuss them briefly right now. The third and fourth are the main topic of this lecture. The fifth is covered in detail two lectures from now in great detail.
The first three aspects are about ruling possibilities out. The fourth and fifth are about deciding between any remaining possibilities.
---v
State Machine Validity
Some forks can be ruled out simply because they contain invalid state transitions.
Notes:
Example spending more money than you have. Noting your present location such that you would have traveled faster than speed of light since last record. Calling a smart contract with invalid parameters.
---v
Arbitrary / Political Validity
Similar to state machine validity.
Examples:
- Blocks that are too big
- Blocks that have "hack" transactions
- Empty blocks
- Block with Even state roots
Notes:
This concept is similar to the previous slide. In some sense this is even the same. This allows us to rule out some forks just for not having properties that we like. Or for having properties that we dislike.
Not everyone will agree on these properties ad that leads to long-term network splits.
Authorship Throttling
Real-world blockchains impose additional restrictions on who can author blocks. Why?

Notes:
These blockchains are supposed to be permissionless right? At least many of them are. Some are even very hardcore about that goal. So why would we want to restrict the authoring. Answer: So the nodes are not overwhelmed. Unthrottled authoring leads to fork chaos. If anyone authored at any moment there would be blocks raining down left and right. It would be impossible to check them all. It would be DOS central. So we need some organization / order to the process.
---v
Leader Election
We need to elect a small set (or ideally a single) entity who are allowed to author next.
In pre-blockchain consensus this was called the "leader", and still often is.
Notes:
By electing a few leaders, we are able to throttle the authoring.
---v
Liveness
The ability of the system to keep authoring new blocks
Notes:
Before we go on, I want to introduce the concept of liveness. It is a desireable property that consensus systems want to have. Systems that have better liveness properties offer higher quality blockspace. Chains without liveness guarantees become stalled.
Proof of Work
Satoshi's Big invention.
Solve a Pre-image search - earn the right to author.
---v
Proof of Work: Pros
- Permissionless (or so we thought)
- Requires an external scarce resource: Energy
- Blind: Nobody knows the next author until the moment they publish their block
- Expensive to author competing forks - Clear incentive
Notes:
On the surface one big strength of PoW is that anyone can spin up a node and join at any time without anyone's permission. This is clearly how it was described in the whitepaper. In practice, many systems now have such a high hashrate that your home computer is useless. It is now permissioned by who can afford and acquire the right hardware.
The reliance on an external resource is good in some sense because it is an objective measure of the market's valuation of the consensus system. This helps valuate the blockspace.
The blindness is a good property because it makes it impossible to perform a targeted attack (DOS or physical) on the next leader to stall the network.
Some attacks rely on the leader authoring two competing forks and gossiping them to different parts of the network. With PoW, it costs energy for every block you author. This makes it expensive to perform such attacks. This provides an economic incentive for authors to only author blocks on the "correct" fork.
---v
Proof of Work: Cons
- Energy Intensive
- Irregular block time
- Not so permissionless
Notes:
Energy consumption is more often considered a negative property. Sometimes called proof of waste. I won't go that far, but in a world where climate change is a reality, it is certainly not ideal to be spending so much energy if we can get away with far less.
Worth noting that some PoW schemes (eg Monero's) strive to minimize the energy impact by choosing algorithms that are "asic resistant". While these are decidedly better than Bitcoin's, they do not fundamentally solve the problem. Just alleviate it somewhat in practice.
Secondly, the block time is only probabilistically known. When waiting for block to be authored, there are sometimes spurts of blocks followed by long stretches without any.
Although it seems permissionless on its face, in practice, to be a bitcoin miner you need to have expensive specialized hardware.
---v
Why Author at All?
- Altruism - You feel good about making the world a better place
- Your Transitions - Because you want to get your own transitions in
- Explicit incentives - Eg block reward
Notes:
If it costs energy to author blocks, why would anyone want to author to begin with?
Mining only when you want to get your transaction in seems like a good idea to me. People who don't want to self author, can pay other a fee to do it for them. This is the purpose of transaction fees. Most chains have transaction fees specified in the transactions themselves which go to the author
Some networks also add an explicit incentives such as a 50BTC reward per block.
Proof of Authority
Traditional class of solutions.
Divide time into slots.
Certain identities are allowed to author in each slot.
Prove your identity with a signature.
---v
Proof of Authority: Pros
- Low energy consumption
- Stable block time
Notes:
Stable block time is a property of high-quality block space. It allows applications that consume the blockspace to have expectations about throughput. In PoW you will occasionally have long periods without a block which can negatively affect applications.
---v
Proof of Authority: Cons
- Permissioned
- No external resource to aid valuation
- Incentives for honesty are not always clear
Notes:
Does anything bad happen if they misbehave? Not inherently. We will need an incentive for that.
Some PoA Schemes
Reminder: PoA is a family of leader election schemes
---v
Aura
The simple one.
Everyone takes turns in order.
#![allow(unused)] fn main() { authority(slot) = authorities[slot % authorities.len()]; }
Notes:
Pros:
- Simple
- Single leader elected in each slot
Cons:
- Not blind - welcome targeted attacks
---v
Babe
Blind Assignment for Blockchain Extension
- In each slot, compute a VRF output.
- If it is below a threshold, you are eligible to author.
- If eligible, author a block showing VRF proof
- If NOT eligible, do nothing
Notes:
Pros:
- No fixed order helps alleviate DOS attacks
Cons:
- Some slots have no authors - There is a workaround for this.
- Other slots have multiple authors which leads to forks - There is no workaround for this.
---v
Sassafras

Single blind VRF-based leader election
🙈TBH, IDK how it works internally.
But Jeff does!
Notes:
- Has most of the Pros of PoW (except for the external resource based valuation hint)
- Has all the Pros of PoA
---v
Sassafras Analogy

Sassafras is kinda cards against humanity
Sassafras Analogy



---v
Sassafras Analogy
Ring VRF outputs are "cards". You anonymously "play" the best aka smallest cards in your hand.
Those cards are sorted, not by funniness since they're just numbers, but by the number.
The order in which they wind up is the block production order.
You claim the ones that're yours by doing a non-ring VRF with identical outputs.
---v
Proof of Stake
It's just PoA in disguise 🤯
Uses an economic staking game to select the authorities.
Restores the permissionlessness to at least PoW levels.
Restores clear economic incentives
Notes:
There is an economic game called staking as part of the state machine that allows selecting the authorities who will participate in the PoA scheme. Actually there isn't just one way to do it, there are many. Kian will talk a lot more about this and about the way it is done in Polkadot later. I'll just give the flavor now.
The basic idea is that anyone can lock up some tokens on chain (in the state machine). The participants with the most tokens staked are elected as the authorities. There is a state transition that allows reporting authority misbehavior (eg authoring competing blocks at the same height), and the authority loses their tokens. There are often block rewards too like PoW.
---v
💒 Consensus 🪢 State Machine
- Loose coupling between consensus and state machine is common
- Eg Block rewards, slashing, authority election
- In PoW there is a difficulty adjustment algorithm
In Substrate there is a concept of a Runtime API - Consensus can read information from state machine.
Notes:
So far I've presented consensus as orthogonal to the state machine. This is mostly true. But in practice it is extremely common for there to be some loose coupling. We already saw an example when we talked about block rewards. The consensus authors are rewarded with tokens (in the state machine) for authoring blocks. Now we see that they can have tokens slashed (in state machine) for breaking consensus protocol. And we see that even the very authorities can be elected in the state machine.
Fork Choice Heuristics
Each node's preference for which fork is best
- Longest chain rule
- Most accumulated work
- Most blocks authored by Alice
- Most total transactions (or most gas)

Notes:
The fork choice allows you, as a network participant, to decide which fork you consider best for now. It is not binding. Your opinion can change as you see more blocks appear on the network
---v
Reorganizations

Dropped transactions re-enter tx pool and re-appear in new blocks shortly
Notes:
Having seen more blocks appear, we now have a different opinion about what chain is best. This is known as a reorg. Re-orgs are nearly inevitable. There area ways to make sure they don't happen at all, but there are significant costs to preventing them entirely. Typically short reorgs are not a big problem, but deep reorgs are.
You can experience this in a social way too.
- Imagine that you are waiting for a colleague to submit a paper. You believe they have submitted it yesterday, but it turns out that they didn't submit it until today or won't submit it until tomorrow. Might be annoying, but not world shattering (usually).
- Imagine that you believe the colleague submitted the paper months ago and the paper has been published. You have applied on a job having listed the publication.
---v
Double Spends

Notes:
The name comes from bitcoin, but the attack generalizes. It exploits the existence of forks. Attacker has to get two conflicting transactions into two forks. And convince a counterparty to believe one chain long enough to take an off-chain action before they see the reorg.
---v
Double Spends

Five Aspects of Consensus
- State machine validity
- Arbitrary / Political validity
- Authorship throttling
- Fork choice heuristic
- Finality
Notes:
We just discussed the first four aspects. Finality will be discussed in an upcoming lesson
Manual Consensus (aka BitStory)
In this activity students will encounter and explore blockchain consensus mechanisms such as PoW, PoA, and PoS by acting them out manually.
Students will collaborate in telling a shared story. The shared story is represented by a blockchain with one word in each block. To add a word to the story, a student must create a valid block, and draw that block on the community whiteboard*

- If no whiteboard is available, you may be able to substitute; a paper, online drawing tool, or even a chalkboard if you are desperate.
Proof of Work
The PoW phase is the original, and a working hasher tool is available here: https://joshorndorff.github.io/BitStory/bitStoryLive.html
To begin we'll explore the Nakamoto style Proof of Work. To add a block a student must:
- Choose a parent block hash to build on
- Choose a word to add to the story
- Find a nonce so that the block's hash meets the required difficulty
The process of finding a nonce is accomplished by entering the parent hash and word into the hasher and repeatedly mashing the increment nonce button until you find a valid one.
In this way students are manually performing the preimage search.
The game ends at a pre-determined time. The winner is the person who authors the most blocks in the longest chain at the end of the game.
Attacks
The instructor can encourage student groups to perform various attacks on the PoW network.
- Censor specific words or plot points by forking around them.
- Publish invaild blocks to trick other miners into wasting their hash rate on invalid chains.
- Perform a hard fork where your block start to have two words each. Some students will like the two-words-per-block rule and keep building on them. Other students (ideally ones who don't know the instructor is in on the shenanigans) may think the two-word blocks are not following the rules, and choose to ignore them. Welcome to bitstory cash.
Formalize the Language
Our previous story had basically no structure. Let's change it to specifically allow a small set of "transaction types". From here on each block will contain a very short sentence (can be abbreviated on the whiteboard) The following is an example and your group is encouraged to make modifications if you like. The degree of formalization is up to you. The more formal it gets, the more it starts to look like real world blockchains.
- Choose a fixed cast of max 3 or 4 characters
- Choose a fixed set of a few locations
- Allow one simple action in each block (a character moves, or does one simple thing)
- Consider letting your characters affect your "real world" by letting them change the difficulty necessary for a block to be valid. You now have a difficulty adjustment algorithm.
Play a few more games. This time each miner write down a few goals that they want to accomplish in-story (eg, bob and alice have a fight, charlie is elected mayor). This time the winners are whoever best accomplishes their in-story goals. Notice that in some cases the goals may al lbe mutually compatible, and in other cases they may not. In subsequent rounds, establish goals together. Try to play at least one round where there are incompatible goals. Miners may choose to form alliances (pools) and censor blocks that don't build on their allies' in-story goals.
Proof of Authority (Aura)
In this phase, students will choose some authorities to act as block authors and a slot duration and they will take turns authoring in order. They should observe that this method is much simpler and less chaotic. It does indeed take less work.
Attacks
- You can skip your slots to slow the progress of the story once it isn't going your way.
- Censor plot points.
- Publish blocks in slots in which they are not valid to try to trick other miners. This may be particularly convincing when the correct author is skipping their slot.
- Polarize the authorities to work on two different forks
Discussion
What attacks worked best in PoW vs PoA. What strengths and weaknesses does each have.
Proof of Stake
One weakness of PoA is that only some of the participants are authors. We can improve this situation by allowing the authority set to rotate. Challenge the students to consider ways in which the authority set might change. What if the story itself is about who is elected as authorities?
Notice that this is the foundation of proof of stake. The on-chain story is about people bonding and unbonding their security deposits. Formalize a new language around this story.
Mixed PoW PoA
Some early PoS designs envisioned interleaving PoS and PoW blocks. Invent such a scheme, and try it out.
Grandpa and finality
This one is a little different. Here we assume an external block production method. At first this can just be one student who is not playing grandpa, but instead being the sole block producer.
The other students use a shared whiteboard to post their pre-votes and pre-commits and personal paper to track which blocks they have finalized.
Hybrid Consensus
If there is time in the activity slot, we can combine any of the block production methods with grandpa. My personal favorite is PoW + Grandpa.
Econ & Game Theory in Blockchain
How to use the slides - Full screen (new tab)
Econ & Game Theory in Blockchain
Notes:
- Presenter Introduction
- Timeline clarification (after mod 2 and 3)
- Today we'll be going through a brand new lecture on Econ & Game Theory in Blockchain
What's the goal?
Notes:
What's the goal of this lecture?
---v
What's the goal?

- Demand & Supply
- Markets
- Nash Equilibrium
- Schelling Point
- ...
Notes:
By now you all should be familiar with all the terms and techniques from the Economy and Game Theory module like the Demand & Supply or Nash equilibrium.
---v
What's the goal?


- Consensus
- Protocol
- Tokens
- State Transition Functions
- ...
Notes:
And you also just finished covering the basics of Blockchains so you all should be familiar with state transition functions as well as have some understanding of consensus protocols.
---v
What's the goal?

Notes:
Having all that in mind, the goal of this lecture is to combine the two and see how the economy and game theory can be applied to blockchain. To do that we'll provide some exemplary use-cases and case studies.
Landscape
Notes:
But first let's start with a quick summary of how we'll be approaching to bridge the gap between the two modules.
---v
Landscape
- Systems as Games

Notes:
Firstly, we'll be looking at various blockchain systems as isolated games.
---v
Landscape
- Systems as Games
- Nodes/Miners/Validators as Players

Notes:
Participants in those games will be for instance the miners, like in the Bitcoin protocol, maybe the validators in the Polkadot protocol or just some users of your smart contract.
---v
Landscape
- Systems as Games
- Nodes/Miners/Validators as Players
- Protocols as Game Rules

Notes:
The protocol is essentially a set of rules that will define the game itself. The one we will be analyzing.
---v
Landscape
- Systems as Games
- Nodes/Miners/Validators as Players
- Protocols as Game Rules
- Cryptocurrencies as Points

Notes:
And to properly analyze those games we need to have some value representation, which in our case will be usually cryptocurrencies.
---v
Landscape
- Systems as Games
- Nodes/Miners/Validators as Players
- Protocols as Game Rules
- Cryptocurrencies as Points
- Rewards & Punishments as Incentives

Notes:
And finally we'll be having various reward and punishment schemes that will shape the incentives of the players.
Now that we have all the elements defining our blockchain games we can look for further parallels.
---v
Market Emergence
Notes:
And first let's take a look at something that hopefully very familiar: Markets
---v
Market Emergence
"A market is a composition of systems, institutions, procedures, social relations or infrastructures whereby parties engage in exchange."
Notes:
So a market is a composition of systems where ppl exchange stuff. This is the simplest way of putting it.
And Markets are the cornerstone of our economy and they are everywhere which also means they are thoroughly studied. Which is very fortunate for us.
Now let's look at something that might also be pretty familiar to many...
---v
Market Emergence
Fee Market
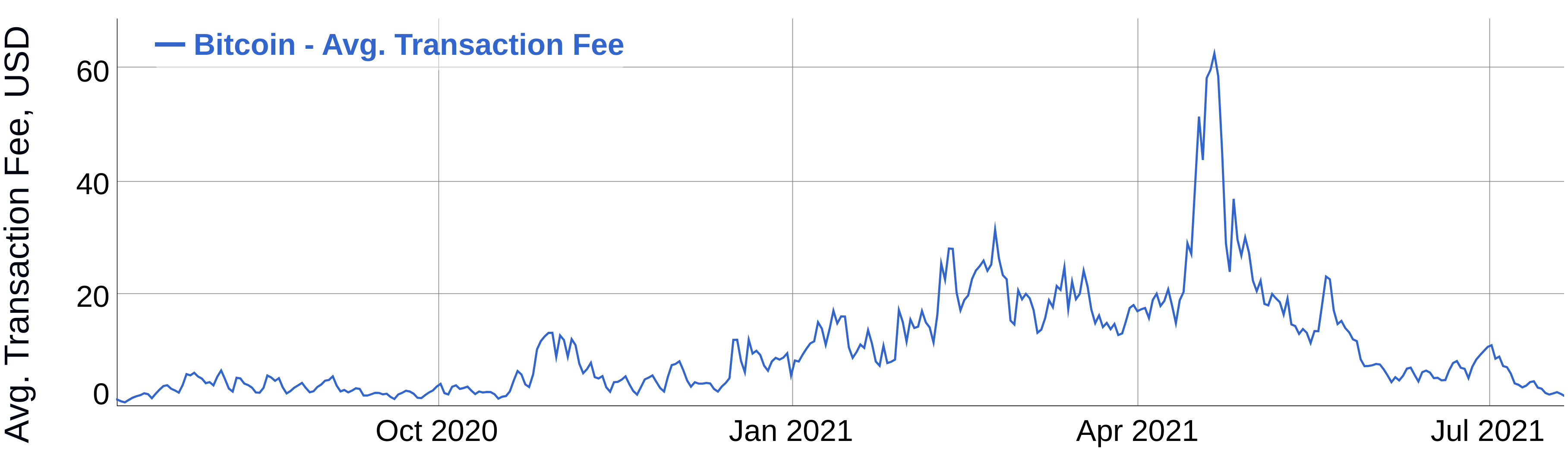
Notes:
The fee market. That's a chart of the average transaction fees in the Bitcoin network over time. As you can see the price is constantly fluctuating.
---v
Market Emergence
Fee Market
- Users bid with the fees
- Miners select highest fee transactions

Notes:
Let's dive a bit deeper. So the users are bidding with how much they are willing to pay and miners are choosing the most lucrative transactions. If miners already included all the best transactions and there are not many new ones coming in they need to start accepting lower fees, so the price drops. But wait...?
---v
Market Emergence
Fee Market

Notes:
What is the actual product being exchanged here? When you have the crude oil market the goods being exchanged are clearly defined. It's crude oil barrels. What is actually being traded in here?
Anyone has an idea what it might be?
---v
Market Emergence
Fee Market
- What is being exchanged is the blockspace
- Miners produce blockspace and effectively auction it to users
Notes:
It's the BLOCKSPACE. Miners secure and produce blockspace and sell it in an auction to various users. Blockspace as a product is actually a pretty new way of thinking about blockchains so I highly suggest checking out the article linked in the notes.
---v
Market Emergence
Fee Market
- The transactions that manage to get into the blocks have fees representative of the current market equilibrium

Notes:
The price of blockspace is determined by the market equilibrium of supply and demand. Demand force is the users willing to transact and supply is the miners producing the blockspace. Transactions that are actually included represent the current equilibrium.
---v
Market Emergence
Fee Market
- In extreme cases the demand can raise so much that the fees overwhelm the network

Notes:
We all know that the transaction fees can sometimes get outrageous. In cases where many users want to transact the demand can skyrocket. And what we see is the price equilibrium following suit.
---v
Market Emergence
Fee Market
- In extreme cases the demand can raise so much that the fees overwhelm the network
- Most economic markets can react to growing demand with increased supply, but that is not directly possible in most blockchains

Notes:
And now let's think of what normal markets do. If our demand and price go extremely high the suppliers would have an incentive to produce more. But in blockchains that's not directly possible. More miners often don't mean more blockspace but MORE SECURE blockspace. That means a better quality blockspace.
So the supply is often fixed and the demand is fluctuating. This is often the cause for the very volatile fee market.
---v
Market Emergence
Fee Market
- In extreme cases the demand can raise so much that the fees overwhelm the network
- Most economic markets can react to growing demand with increased supply, but that is not directly possible in most blockchains

Notes:
And according to that theory some large blockchains actually tried implementing variable size blocks to react to the demand, but it's a pretty complex task and a big tradeoff.
Some of you maybe recognize this image as the CryptoKitties game on Ethereum. It's a game where you can buy and breed digital cats. It was so popular that it actually clogged the Ethereum network and made normal transactions nearly unfeasible. And maybe now you have some additional insights into what actually happened there.
=5 sec pause=
Nash Equilibrium
Notes:
Now let's look at something a bit different that allows us to predict what users would do... a Nash Equilibrium.
---v
Nash Equilibrium
- Strategy from which no player wants to deviate
- But what's the strategy for BTC mining?
Notes:
Nash Equilibrium is strategy from which no player wants to deviate. Pretty simple but what's the strategy for BTC mining? How can we leverage that knowledge?
---v
Nash Equilibrium

Notes:
And more importantly... being honestly is the answer, right?
---v
Nash Equilibrium
Bitcoin Mining
Notes:
Let's dive in and actually see what's the answer. What's the Nash Equilibrium of Bitcoin mining? Is it being honest or dishonest?
---v
Nash Equilibrium
- Only 2 miners
- Block reward = 2
- Difficulty scales with number of honest miners
- Miners are rational actors
- Dishonest miners do not cooperate

Notes:
Here we have a few assumptions, but the main ones are:
- imagine we have only 2 miners
- the block rewards is 2
- miners can be honestly following the protocol or try to cheat and push invalid blocks (for instance one where they get 999 bitcoins)
Let's figure out how many bitcoins each one of them will mine on average.
---v
Nash Equilibrium
.svg)
Notes:
If both miners are not mining honestly, none of them produce valid bitcoin blocks... then there are no ACTUAL bitcoins being mined. Remember that they don't cooperate but for instance try and push blocks with 9999 BTC in their account. So the reward is 0 for both.
---v
Nash Equilibrium
.svg)
Notes:
If both are working honestly and making valid blocks they have an equal chance to mine a block and reap the rewards. Rest of the nodes will accept those blocks but the two miners compete for the same resource so each one will get a single BTC on average (as the mining reward is 2).
---v
Nash Equilibrium
.svg)
Notes:
If one of them is dishonest the other one can still keep working honestly and reap greater rewards as there is no competition. In that case the honest party gains 2 BTC.
Now that we know who earns how many bitcoins in each scenario we need to shift out attention to another important force. Things like Twitter, Facebook or Bitcoin are often deemed as valuable because of their Network Effect.
---v
Nash Equilibrium
Network Effect
"The network effect is a business principle that illustrates the idea that when more people use a product or service, its value increases."
Notes:
Generally the more ppl use some platform or believe in something the more valuable it is. It's a pretty simple concept but it's very important in the blockchain space. Bitcoin is precious to many because many people believe in it and mine it and exchange it. In blockchains if more people use your chain it's more valuable.
---v
Nash Equilibrium
Network Effect
Assumptions revisited:
- Only 2 miners
- Block reward = 2
- Difficulty scales linearly with number of honest miners
- Miners are rational actors
- Dishonest miners do not cooperate
- Token price scales quadratically with the number of honest miners
- 1 honest miner -> 1$
- 2 honest miners -> 4$
Notes:
Let's add this extra assumption into our model. If there are more miners securing the network the coins itself are more valuable. We will use a super simple model here where the price of a coin is a square of the number of miners. We will be investigating small systems so it is a good enough approximation.
---v
Nash Equilibrium
.svg)
Notes:
We can apply the changes by changing the evaluations of the miners coins.
---v
Nash Equilibrium
.svg)
Notes:
If both miners honestly secure the network the coin price is 4 and in case of single honest miner the price is 1.
---v
Nash Equilibrium
.svg)
Notes:
Now we can actually focus on finding the Nash Equilibrium so let's used the simplest method.
---v
Nash Equilibrium
.svg)
Notes:
Assuming Miner B is honest the Miner A needs to choose between a payoff of 4 or 0.
---v
Nash Equilibrium
.svg)
Notes:
He ofc chooses 4 as it's higher. We temporarily mark it with the red circle.
---v
Nash Equilibrium
.svg)
Notes:
Same reasoning for B being dishonest and A chooses 2 over 0.
---v
Nash Equilibrium
.svg)
Notes:
Now we reverse the assumptions and assume A is honest and then B chooses between 4 and 0.
---v
Nash Equilibrium
.svg)
Notes:
Similarly as before he should choose 4 as it's higher.
---v
Nash Equilibrium
.svg)
Notes:
And the last remaining options will result in the circled 2.
---v
Nash Equilibrium
.svg)
Notes:
Now the square with all the options circled is the Nash Equilibrium. In our case it seems to be being honest.
---v
Nash Equilibrium
.svg)
Notes:
Not a big surprise, and being dishonest lands you with zero coins so it was too be expected. But what if we change the assumptions a bit?
---v
Nash Equilibrium
What does it mean exactly to be dishonest?
If multiple miners break the protocol in the same way, it can be seen as a new protocol deviating from the main one.
Notes:
We were assuming that miners are either honest or dishonest, but what does being DISHONEST actually mean?
=fragment=
There are some mainstream rules (the protocol) and if an individual miner breaks them it seems like an isolated mistake or an attempt at cheating. This is what we were analyzing before.
=fragment=
But what if multiple miners break the protocol in the same way? It can be seen as a new protocol deviating from the main one. And that's what we'll be looking at next. The dishonest miners are cooperating.
---v
Nash Equilibrium
- Only 2 miners
- Block reward = 2
- Difficulty scales with number of honest miners
- Token price scales quadratically wih the number of honest miners
- Miners are rational actors
- Decision between which protocol to follow
.svg)
Notes:
Assumptions are pretty much the same but this time around the dishonest miners will cooperate. Effectively they will be following a different modified protocol.
So we will no longer consider them dishonest but they simply follow a different set of rules. Now miners choose to mine for the bitcoin BTC protocol or the bitcoin cash BCH protocol.
---v
Nash Equilibrium
.svg)
Notes:
Let's quickly fill up this table with the same rules as before. Only this time of both miners follow BCH they ofc get the rewards in the BCH token.
---v
Nash Equilibrium
.svg)
Notes:
Just as before we take the extra step and apply the network effect. If both miners secure the network price is 4 and if only 1 the price is 1.
---v
Nash Equilibrium
.svg)
Notes:
Here we have all the prices adjusted.
---v
Nash Equilibrium
.svg)
Notes:
Now let's take a look at what happens if Miner B miners BTC. Miner A would prefer to also mine bitcoin. So they are both mining the same thing.
---v
Nash Equilibrium
.svg)
Notes:
On the other hand if miner B mines BCH then it seems that Miner A prefers to mine BCH...
---v
Nash Equilibrium
.svg)
Notes:
And in fact what we have in here is two distinct Nash Equilibria!
---v
Nash Equilibrium
So is being honest the best strategy?
Not always. If the majority of people are honest then honesty pays off. If the majority of people are dishonest in the same way then be dishonest with them.
Notes:
So is being honest the best strategy?
=fragment=
Not always. If the majority of people are honest then honesty pays off. If the majority of people are dishonest in the same way then be dishonest with them.
=fragment=
In fact it was proven that in PoW following the majority is the true Nash Equilibrium no matter what strategy/protocol they are using as long as it's consistent. So Bitcoin mining is in fact a huge coordination game and this is why honesty AKA following the BTC protocol usually pays off.
- More complex examples will be explored later in the forks lecture on Friday
- Paper investigating PoW Nash Equilibrium and following the majority: https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=7bf78054192d98e999edcdf08971a5eed42518d2
Schelling Point
Notes:
On that topic... What if we have multiple Nash Equilibria? Schelling point often comes to the rescue.
---v
Schelling Point
- A solution that people tend to choose (easiest to coordinate on)
- Generally it is also a Nash Equilibrium
- How in the world can it be useful in Blockchain?
Notes:
So first a Schelling point is a strategy people tend to choose. It is generally a Nash Equilibrium
=fragment=
But how in the world is it useful to us in Blockchain?
---v
Schelling Point
Detective game
- Two partners in crime
- Detective interrogates them individually

Notes:
But before we can fully answer that let's explore a different game that can show you how Schelling points work. And I promise it will be applicable to Blockchain.
So the story goes like that. We have to bank robbers and a detective. The detective interrogates he robbers and tries to make them confess or catch them lying.
---v
Schelling Point
Detective game

Notes:
If any of the robbers spill the beans and tell the truth they both loose the game and go to prison. If both of them lie they get away with it. Seems super simple and it should be pretty straightforward that they both simply need to lie.
Seems like a safe strategy, right? But remember than both of them witnessed the same real events of the robbery...
---v
Schelling Point
Detective game

Notes:
But there are multiple lies they can construct. If they have inconsistent stories the detective will catch them. So now they need to coordinate on a specific lie and have all the details exactly the same or they are screwed.
Contrast it with how easy it would be to just tell the truth. They both witnessed the truth so talking about it in a consistent way is trivial.
---v
Schelling Point
Detective game
Truthful answers are one of the easiest strategies coordinate on, so they are the Schelling Points.
Notes:
That's why we can say that Truthful answers are one of the easiest strategies coordinate on, so they are the Schelling Points. The truth itself is a Schelling point.
And this concept is vital to something in blockchain called...
---v
Schelling Point
Oracles
Oracles are blockchain entities that provide information from the outside world to the blockchain.

Notes:
Oracles. Firstly who in the room heard of oracles? Raise your hands. Oracles are super interesting because what they are trying to achieve is to provide information from the outside world to the blockchain. And that's a very very hard task.
---v
Schelling Point
Oracles
Oracles are blockchain entities that provide information from the outside world to the blockchain.
- What's the temperature in Berkeley?
- Who won the election?
- What's the exchange rate of USD to BTC?
Notes:
Some examples of the information they can provide are for instance what's the current temperature in Berkeley? Who won the election? What's the exchange rate of USD to BTC? and may others.
Let's actually see how they might work is a slightly simplified version with the temperate example.
---v
Schelling Point
Oracles

Notes:
So what's the temperature in Berkeley? Imagine you have a garden in Berkeley and you have on chain insurance that if the temperature is too high you get a payout. So you want to know the temperature in Berkeley.
We know the answer lies somewhere on this axis. But what it is exactly?
---v
Schelling Point
Oracles

Notes:
We can ask some users to submit what they think the temperature is. Some of them will check it themselves, some will use weather apps and some will just guess.
---v
Schelling Point
Oracles

Notes:
What we are hoping for is that the cluster of votes you can see here will be around the actual temperature. The best approach would be to check the median. And why is that?
---v
Schelling Point
Oracles
- Honest participants are naturally coordinated
- Attackers could try to coordinate and lie
Notes:
Honest voters are naturally coordinated. They will check the temperature and vote honestly all within some small margin of error.
People that would lie to skew the results and would submit random values generally wouldn't cluster like the honest voters. To make a more dangerous attack they would need to strategically coordinate on a specific value and all lie about it. It's much harder to pull of than simply checking the temperature outside.
Submitting the truth is the Schelling Point in here and it makes it easy to be honest.
---v
Schelling Point
Oracles
Notes:
But what if there are some attackers? What can we do about them?
---v
Schelling Point
Oracles
If they go unpunished they can repeat the attack until successful
Notes:
If we never punish them they can repeat the attack until they are successful. And that's not good.
---v
Schelling Point
Oracles
If they go unpunished they can repeat the attack until successful
Or even worse, they can make a million fake identities and spam incorrect votes
Notes:
Or even worse, they can make a million fake identities and spam incorrect votes. So we need to punish them.
But this is no longer a problem of a Schelling Point. The Schelling point did its job already. What we are talking about right now are...
Incentives
Notes:
Incentives. Incentives are the next big topic we will be exploring. And they are vital to the blockchain space.
---v
Incentives
"Something that encourages a person to do something."
Notes:
Incentives are things that encourage people to do something.
=fragment=
In our case we want to shape incentives that motivate the users to submit honest values. We need to build out incentives in a way that shapes the expected behavior of the users to honesty.
---v
Incentives
Oracles
If they go unpunished they can repeat the attack until successful
Or even worse, they can make a million fake identities and spam incorrect votes
Notes:
So going back to our oracle problem how can we deal with attackers?
---v
Incentives
Oracles
If they go unpunished they can repeat the attack until successful

Notes:
Let's focus on the second issue of fake identities. How can we prevent that?
---v
Incentives
Oracles
Common problem in blockchain.
Notes:
An attack where a single entity creates multiple fake identities is called a sybil attack and is super common in blockchain. This is one of the things you always will need to ask yourself when you deploy things in blockchain. Is whatever I built safe from Sybil Attacks?
=fragment=
One easy ready solution that is often used is making users lock some funds. Only a user with some funds locked can vote. The strength of the vote is proportional to the stake so making a million accounts makes no sense. This is a very simple solution but it's not always applicable.
---v
Incentives
Oracles
If they go unpunished they can repeat the attack until successful
Notes:
Now let's go back to the first issue of unpunished attackers. How can we deal with them so they don't continue attacking us?
---v
Incentives
Oracles
We already laid out the foundation for punishments.
If such a user would vote incorrectly, we can slash their funds.
Notes:
Interestingly we already laid out the foundation for the defense. Voters have some funds locked in the system so they have Skin in the game.
=fragment=
If they vote incorrectly we can slash their funds. This is a very common solution in blockchain. Incorrect in that case would be very far from the median.
We have designed some protective incentives and now the system seems safe.
---v
Incentives
Oracles
Did we forget about something?
Why would anyone participate in this system?
Notes:
But did we forget about something? Anyone has any idea what it might be? What we are missing?
=fragment=
Why would anyone participate in this system? Why would anyone vote? Why would anyone lock their funds and take the risk?
---v
Incentives
Oracles
No user wants to participate
Getting information from the real world is an effort and they voters are doing the protocol a service

Notes:
Getting information from the real world is an effort and they voters are doing the protocol a service. So we need to incentivize them to participate. We need a rewards scheme or otherwise the network will be a ghost town.
---v
Incentives
Oracles
If users are doing the protocol a service they need to be rewarded

Notes:
If users are doing the protocol a service they need to be rewarded.
=fragment=
One way to do it is to mint some token rewards for well-behaved voters.
=fragment=
Or distribute them from a previously acquired pool of rewards.
But what is crucial here the protocol is safe and dependable only if there is enough voters so the incentives need to be designed in a way that encourages participation.
More precisely, incentives need to be roughly proportional to the value an attacker could gain by compromising the system. Low-stakes oracles don't need to have super aggressive incentives.
---v
Incentives
Oracles
Correct vote = 10$

Notes:
Let's do a quick question. Can we distribute fixed value rewards for correct votes? As an example each Correct vote = 10$
=question time=
=fragment=
No. We should base rewards on the size of the voter's stake. Otherwise the system is vulnerable to sybil attacks. If you have a million fake identities you can vote a million times and get a million times the reward. So the reward should be proportional to the stake.
---v
Incentives
In summary:
- Make it easy to honest users and hard for attackers
- Service to the protocol needs to be rewarded
- Destructive or interfering actions need to be punished
- De-Sybiling the users can help defend against spam
Notes:
Now let's summarize the main points.
We need to make it easy for honest nodes and hard for attackers. The Schelling Point as the foundational part of the design handles that for us.
=fragment=
Service to the protocol needs to be rewarded. We need to incentivize participation to guarantee reliable results.
=fragment=
Destructive or interfering actions need to be punished. We need to disincentivize bad behavior. In our case we did the slashes.
=fragment=
De-Sybiling the users can help defend against spam.
We we have all of that our systems should be properly incentivized and safe... and on that note what happens when the incentives are...
Misaligned Incentives
Notes:
Misaligned. When they promote some behavior that is not good for the network.
---v
Misaligned Incentives
Ethereum State Storage Issue

Notes:
Let's take a look at Ethereum. Ethereum is a blockchain that has a lot of smart contracts. And smart contracts are basically programs that run on the blockchain. They are stored on chain and they can be executed by anyone. For them to work a bunch of code needs to be deployed on the chain.
---v
Misaligned Incentives
Ethereum State Storage Issue
State Storage Replication
Whenever we store something on chain (like a smart contract) it needs to be at least partially replicated among the nodes.

Notes:
And moreover whenever we store something on chain (like a smart contract) it needs to be at least partially replicated among the nodes. Thousands of nodes store the same data which is not super efficient.
---v
Misaligned Incentives
Ethereum State Storage Issue
State Storage Replication Costs
Ethereum deals with the burden of replication by charging more gas for submitting bulky data.
All of that is ON TOP OF any computation gas costs.

Notes:
Ethereum attempts to deal with it by introducing scaling fees. The more data you put in the state the more you need to pay. And that's on top of any computation costs.
---v
Misaligned Incentives
Ethereum State Storage Issue
State Storage Duration
This particular part of the state might be relevant for future state transitions so nodes cannot simply discard it.

Notes:
Note that once we put something in state it has to stay there pretty much indefinitely until we use it again. Because who knows, it might be relevant to some future state transitions. So nodes cannot simply discard it.
Now let's explore an example.
---v
Misaligned Incentives
Ethereum State Storage Issue
Meet Bob
Bob happily deploys his awesome smart contract in Ethereum. He paid a hefty gas fee but so be it.

Notes:
So let's meet Bob. Bob is a developer and he happily deploys his awesome smart contract in Ethereum. He paid a hefty gas fee but so be it. His code was added to the state and now many nodes hold a copy of it.
---v
Misaligned Incentives
Ethereum State Storage Issue
The Problem
Bob decided to become a musician or just no longer likes programming.
He doesn't care about his smart contract anymore.

Notes:
But imagine that one day Bob decides to become a musician or he just no longer likes programming. He doesn't care about his smart contract anymore. But the chain doesn't know about it. His code still lives in the state and has to be continuously replicated and maintained.
---v
Misaligned Incentives
Ethereum State Storage Issue
The Problem Made Worse
Many others like Bob follow suit.
Some of them continue developing but, why bother removing old data? They already paid for it.

Notes:
Now imagine there are hundreds of people like Bob. Some of them even continue developing but, WHY BOTHER removing old data? They already paid for it. And some of them just don't care anymore.
---v
Misaligned Incentives
Ethereum State Storage Issue
"Why Bother?"
Getting data on chain is expensive, but there is no incentive to clean it up.
This is a core misalignment of incentives that lead to Ethereum state size growing out of control.
Notes:
We need to focus on this "why bother" part. This is a core example of a misalignment of incentives that lead to Ethereum state size growing out of control.
Getting the data to state is indeed expensive but once we do... why clean it? There is no incentive to do so. So the chain was getting overwhelmed in junk.
---v
Misaligned Incentives
Ethereum State Storage Issue
The Goal
Design new protocol rules that shape the behavior of the users in a way that they start cleaning up the state.

Notes:
So what can we do about it? What's the goal? We need to design new protocol rules that shape the behavior of the users in a way that they start cleaning up the state. Hopefully without any side effects.
---v
Misaligned Incentives
Ethereum State Storage Issue
The Solution
State Storage Gas Refunds
Pay a hefty fee when deploying data to state, but get some of it refunded when removing it.

Notes:
One of the proposed solutions was the introduction of a Gas Refund. You pay a hefty fee when deploying data to state, but get some of it refunded when removing it. So now there is an incentive to clean up the state.
---v
Misaligned Incentives
Ethereum State Storage Issue
behavior Before

Notes:
So what we had originally is Bob paid for his smart contract and then simply went away to play a guitar.
---v
Misaligned Incentives
Ethereum State Storage Issue
behavior After

Notes:
Afterwards Bob deploys his contract in the same way but before running of to play a guitar he removes it from the state and gets some of the gas back. He likes the extra money so he has an incentive to clean. In here we're presenting the version where he recovers the full value for educational purposes but Ethereum only refunds a portion of the gas.
But wait... So what is the actual cost if he paid 10 and got 10 back? Anyone has any idea? Cost might not be obvious but it is an...
Opportunity Cost
Notes:
Opportunity Cost. It's a very important concept in economics and it's also crucial in blockchain.
---v
Opportunity Cost
"The loss of other alternatives when one option is chosen."

Notes:
d Generally opportunity cost is the loss of other alternatives when making a choice. When choosing between 10 and 30$ the opportunity cost of picking 30 is 10, the other option you are forgoing.
---v
Opportunity Cost
Ethereum State Storage
The Real Cost
Instead of having the funds locked in the storage deposit/refund scheme, Bob could have invested them somewhere else and gain some profit.

Notes:
Going back to the topic of Ethereum the real cost for Bob is not the 10$ he paid for storage as he regains it later. The cost is in losing the opportunity of investing the money elsewhere.
=fragment=
Just locking your funds is sort of a punishment by itself. Even if you regain them later. This is especially true in inflationary systems, and spoiler alert that most of them.
The opportunity cost is a clever mechanism that allows us to include costs without directly charging them, and we also need to be super aware so we don't accidentally punish the users by not thinking of some external opportunity costs.
---v
Opportunity Cost
Extra Examples
- Creating invalid blocks in Bitcoin never gets directly punished even if the block is rejected by the network. The real cost is the opportunity cost, as the miner could have mined a valid block instead.
- Polkadot native token DOT is inflationary (~7.5% per year) but it can be staked to earn rewards (~15% per year). Not staking DOT has an opportunity cost which incentives staking to secure the network.
Notes:
There is a lot of awesome examples of opportunity costs in blockchain. For instance Creating invalid blocks in Bitcoin never gets directly punished even if the block is rejected by the network. The real cost is the opportunity cost, as the miner could have mined a valid block instead.
=fragment=
and the Polkadot native token DOT is inflationary (~7.5% per year) but it can be staked to earn rewards (~15% per year). Not staking DOT has an opportunity cost which incentives staking to secure the network.
And there are also many other staking and DeFi examples out there.
Externalities
Notes:
Now to actually appreciate what the we did in the previous section we need to talk about externalities.
---v
Externalities
"A consequence of an economic activity that is experienced by unrelated third parties."
Notes:
An externality is a consequence of an economic activity that is experienced by some third parties.
As an example, think of the pollution you emit when driving a car. It's a negative externality that affects all the people around you. Alternatively imagine planting a tree in your garden simply because you like how it looks and gives you some shade. The tree improves the quality of air in the neighborhood and that's a positive externality for the people around you.
---v
Externalities
Ethereum State Storage
The clogging of the chain with useless data is a negative externality that affects all the users of the chain.
As protocol designers we need to be aware of such externalities and we can try and limit their effects by pricing them in.
Notes:
In the Ethereum example you could argue that the network getting clogged is the externality of the single developer not cleaning after himself. And it affects all the users of the chain. The chain is an example of a common good.
As protocol engineers or system designers you need to identify those externality costs and price them in.
---v
Externalities
Ethereum State Storage
Negative Externality Cost
In the Ethereum State Storage problem we priced in the negative externality as the opportunity cost of locking your funds.
Notes:
That's what we did with the opportunity cost in Ethereum. We made it so burdening the chain is actually expensive for the perpetrator. We aligned his incentives with the incentives of the chain.
---v
Externalities
Oracles
Positive Externality
Providing the voting services in the Oracle scheme can be seen as a positive externality for the network that can further use this extra information.
The voters are providing a valuable service to the protocol.
Notes:
But not all externalities are negative.
For example the whole oracle scheme makes it so the chain can get information from the real world. This is a positive externality for the network that can further use this extra information.
---v
Externalities
Oracles
The voters are providing a valuable service to the protocol.
So if they submit the vote on chain through a transaction, should they pay any fees?
Notes:
The honest voters are providing a valuable service to the protocol.
=fragment=
So having that mind should they pay any transaction fees when submitting votes?
---v
Externalities
Oracles
Beneficial Transactions
Such a transaction can be totally free.

Notes:
And contrary to the common belief such a transaction can be totally free.
=fragment=
But make sure it cannot be spammed! And it's super important, because if it is free it can be trivial. In our oracle system we can make sure there is only ONE vote per stake. This way we remain safe and can make the transaction free to further incentivize participation.
---v
Free Transactions
There are other free transactions that are not necessarily positive externalities.
Inherent Transactions
- Block rewards in BTC
- Any logic that needs to be executed for every block (is inherent to the block)
Notes:
There are other free transactions that are not necessarily positive externalities. For instance in Bitcoin after mining a block you get a reward. This is a free transaction that is not a positive externality. It's just inherent to the block. Usually any logic that needs to be executed for every block (is inherent to the block) is free.
Complete vs Partial Information Games
Notes:
Now let's look at something totally different. We will talk about a concept crucial to game theory and that is information.
---v
Complete vs Incomplete Information Games
Do players know everything about the game state?
Do players NEED to know everything about the game state?
Notes:
We'll be looking at questions like do players know everything about the game state? Do they NEED to know everything about the game state? And how does it affect the game?
---v
Complete vs Incomplete Information Games
Polkadot Approval Voting (Simplified)

Notes:
To investigate this topic we'll dive deeper into Polkadot and particularly the Approval Voting subsystem. This is something I personally work on at Parity and you will learn a lot more about it in the later modules.
What you need to understand now is that there are some special nodes called validators. They as they name suggests validate if the new blocks in the network are valid and correct.
---v
Complete vs Incomplete Information Games
Polkadot Approval Voting (Simplified)
Approval Checkers
In Polkadot when new blocks are validated, not everyone does the work. Only some randomly chosen validators - called Approval Checkers - are selected to validate candidate blocks.
Notes:
But in Polkadot not every validator does all the work. They share the work and each block is checked only by a subset of validators. They are called Approval Checkers.
---v
Complete vs Incomplete Information Games
Polkadot Approval Voting (Simplified)
Attackers
We assume that attackers can DDoS some but not ALL Validators.
Being DDoS'ed makes them unable to vote in time.

Notes:
We also need to make some assumptions about the attackers willing to disrupt the network. We assume that attackers can DDoS some but not ALL Validators. Being DDoS'ed makes them unable to vote in time.
---v
Complete vs Incomplete Information Games
Polkadot Approval Voting
Default Scenario
- Randomly select 3 Approval Checkers and announce them
- Approval Checkers publish votes if they are selected
- If all the votes received confirm the block is fine it passes
Notes:
A default validation scenario would go like that. We randomly select 3 Approval Checkers and announce them. Approval Checkers publish votes if they are selected. If all the votes received confirm the block is fine it passes.
But there is a problem with it? Does anyone know what it is?
---v
Complete vs Incomplete Information Games
Polkadot Approval Voting
Default Scenario
- Randomly select 3 Approval Checkers and announce them
- Approval Checkers publish votes if they are selected
- Attackers use the information and DDoS the selected before they publish the vote (except their insider)
- If all the votes received confirm the block is fine it passes

Notes:
If the attackers learn who the designated approval checkers are they can focus their attack. And only eliminate the relevant targets thus compromising the network.
---v
Complete vs Incomplete Information Games
Polkadot Approval Voting
What was the Problem?
- Attackers learned everything about the game
- Attackers could use this information before the validators could respond
How do we fix it?
- Limit the information the attackers have access to so they cannot plan ahead
Notes:
So let's ask ourselves what was the problem? The attackers learned everything about the game and could use this information before the validators could respond. The information is the weapon.
=fragment= If we could somehow limit the information the game would change in our favour. We need to make this a game of incomplete information, where some things are hidden.
---v
Complete vs Incomplete Information Games
Polkadot Approval Voting
Improved Scenario
- Each validator uses a VRF to generate a random number
- Validators with a sufficiently small number will have the right to be Approval Checkers
- Approval Checkers reveal themselves by showing their low numbers and publish a vote at the same time
- If all the votes received confirm the block is fine it passes
Notes:
- Let's imagine this new improved scenario. Each validator uses a VRF to generate a random number.
- There is some threshold and validators with a sufficiently small number will have the right to be Approval Checkers.
=fragment=
- Approval Checkers reveal themselves by showing their low numbers (with a vrf proof attached) and publish a vote at the same time. If all the votes received confirm the block is fine it passes.
This method has this nice property that attackers don't learn who the approval checkers are until they reveal themselves. So they cannot plan ahead.
---v
Complete vs Incomplete Information Games
Polkadot Approval Voting
What can the Attackers do?
- They no longer know who the Approval Checkers are so they have to guess
- If they don't guess correctly they get heavily slashed

Notes:
So what can the attackers do? If they can no longer target DDoS they only can attack at random. This vastly reduces their chances of success and makes thm vulnerable to punishment if they fail.
This is pretty much the method used in Polkadot and it's called a VRF based random assignment. It's a game of incomplete information.
---v
Complete vs Incomplete Information Games
Extra Examples
- BABE is a Polkadot mechanism for selecting new block producers (further covered in Polkadot module). It also uses a similar VRF scheme to generate random assignments
Notes:
Some other notable examples you will learn about in later modules are connected to BABE the Polkadot mechanism for selecting new block producers. It also uses a similar VRF scheme to generate random assignments.
Shifting Assumptions
Notes:
By now you might have noticed a pattern that usually we have a list of assumptions.
---v
Shifting Assumptions
- Number of players
- Available actions
- Access to information
- etc
Notes:
Some of the assumptions are connected to the number of players or maybe the access to information. And they are usually pretty stable.
---v
Shifting Assumptions

Notes:
What happens when for some reason the assumptions evolve and change? The game changes as well. Old incentives that were previously sensible may now motivate a vastly different behavior.
---v
Shifting Assumptions
Restaking
The incentive game will be vastly different and the capital will effectively be leveraged (double risk and double rewards).

Notes:
A super good example of that is what is very recently happening in Ethereum. And I mean literally this month. There is a new layer 2 protocol called EigenLayer that allows stakers to stake the same funds for multiple apps at the same time. This is called restaking.
This is not something natively available in Ethereum and it wasn't taken into consideration when slashes/rewards were designed.
---v
Shifting Assumptions
Restaking
Restaking consequences are still not fully understood and the research is ongoing.
Speaker Notes ("S") for further reading.
Notes:
The consequences of restaking are still not fully understood and the research is ongoing. I encourage you to read the speaker notes for further reading. The whole field of blockchain incentivization and protocol design is still developing so there are many unknowns but overall I hope all the methods shown today help you in making more informed decisions later down the line. Thats it...
- Podcast: https://www.youtube.com/watch?v=aP9f_1v9Ulc
- Whitepaper: https://2039955362-files.gitbook.io/~/files/v0/b/gitbook-x-prod.appspot.com/o/spaces%2FPy2Kmkwju3mPSo9jrKKt%2Fuploads%2F9tExk4U2OdiRKGEsUWqW%2FEigenLayer_WhitePaper.pdf?alt=media&token=c20ac4bd-badd-4826-9fb6-492923741c9e
Summary
- Markets - Fee Markets
- Nash Equilibrium - BTC Mining
- Schelling Point - Oracles
- Incentivization - Oracles
- Opportunity cost - Ethereum State Storage Refunds
- Externalities - Ethereum State Storage and Oracles
- Complete vs Incomplete Information Games - Polkadot Approval Voting
- Assumptions - Restaking
Notes:
So to summarize we talked about:
Thanks everyone!
Blockchain from Scratch
Learn the fundamentals of blockchain by building it from scratch. In Rust.
📥 Clone to start: Blockchain from Scratch
See the README included in the repository for further instructions.
Unstoppable Applications
How to use the slides - Full screen (new tab)
Unstoppable Applications
Notes:
Much like tokenomic design, that is a large component in unstoppable apps that incorporate cryptocurrency or other motivating factors, this lesson is far far too short to give you all the tools and techniques to make a robust DApp design.
Instead we strive to highlight the problem space we face and some classes of solutions to them.
Motivation
So far, we have discussed state machines and consensus... in isolation.
Does the contexts in which they operate within matter?
Notes:
- So far mostly on simplified, idealized systems.
- "Black boxes" of cryptography
- Rational actors and assumed complete models of behavior in economics
- Blockchains as an "isolated system" of sorts - external systems cannot be reasoned about in the same way... We will talk about the Oracle Problem.
- In practice there are far more "unknown unknowns" and "black swan" behavior. More to come on that in this lesson.
Discussion
What properties of a system make it "stoppable"?
Notes:
- Web2 context: central providers & authorities, ...
- Web3 context: decentralized, ...
- What properties of a system make it "stoppable"?
Unstoppable Apps Properties
- Anitfragile
- Trustless*
- Censorship-less*
- Accessible*
- ...perhaps more?
Notes:
The "*" indicates the web3 context for defining properties, not generally. Not all of these can apply, nor is is possible all simultaneously apply. We need to craft the system properties based on what we must achieve. In reality we strive for Absolute Unstoppability, but likely cannot grantee it in every possible scenario.
Anitfragile
Some things benefit from shocks; they thrive and grow when exposed to volatility, randomness, disorder, and stressors and love adventure, risk, and uncertainty. Yet, in spite of the ubiquity of the phenomenon, there is no word for the exact opposite of fragile. Let us call it antifragile. Antifragility is beyond resilience or robustness. The resilient resists shocks and stays the same; the antifragile gets better.
-- Antifragile --

Notes:
- Read Antifragile quote, recommend book recommended, see the links throughout slides for more after class.
- Hydra fable & lore: https://en.wikipedia.org/wiki/Lernaean_Hydra - even though can be almost completely destroyed, it is resilient and recovers. Absolutely Unstoppable doesn't mean it cannot be damaged or even paused temporarily, it means it cannot cease to exist and will eventually recover, and ideally come back stronger in doing so.
An N-lemma
Hypothesis: a absolutely Unstoppable App cannot exist.
We must make trade-offs out of all N properties
that a absolutely Unstoppable App would possess.


Notes:
As with crypto, we can have astronomically good odds... But they are not perfect. We want the most robust system possible, given the environment and context the consensus system lives in.
More relevant trilemma:
- Scalability
- Zooko's Triangle (Network IDs)
- More likely!
Web3 Tech Stack
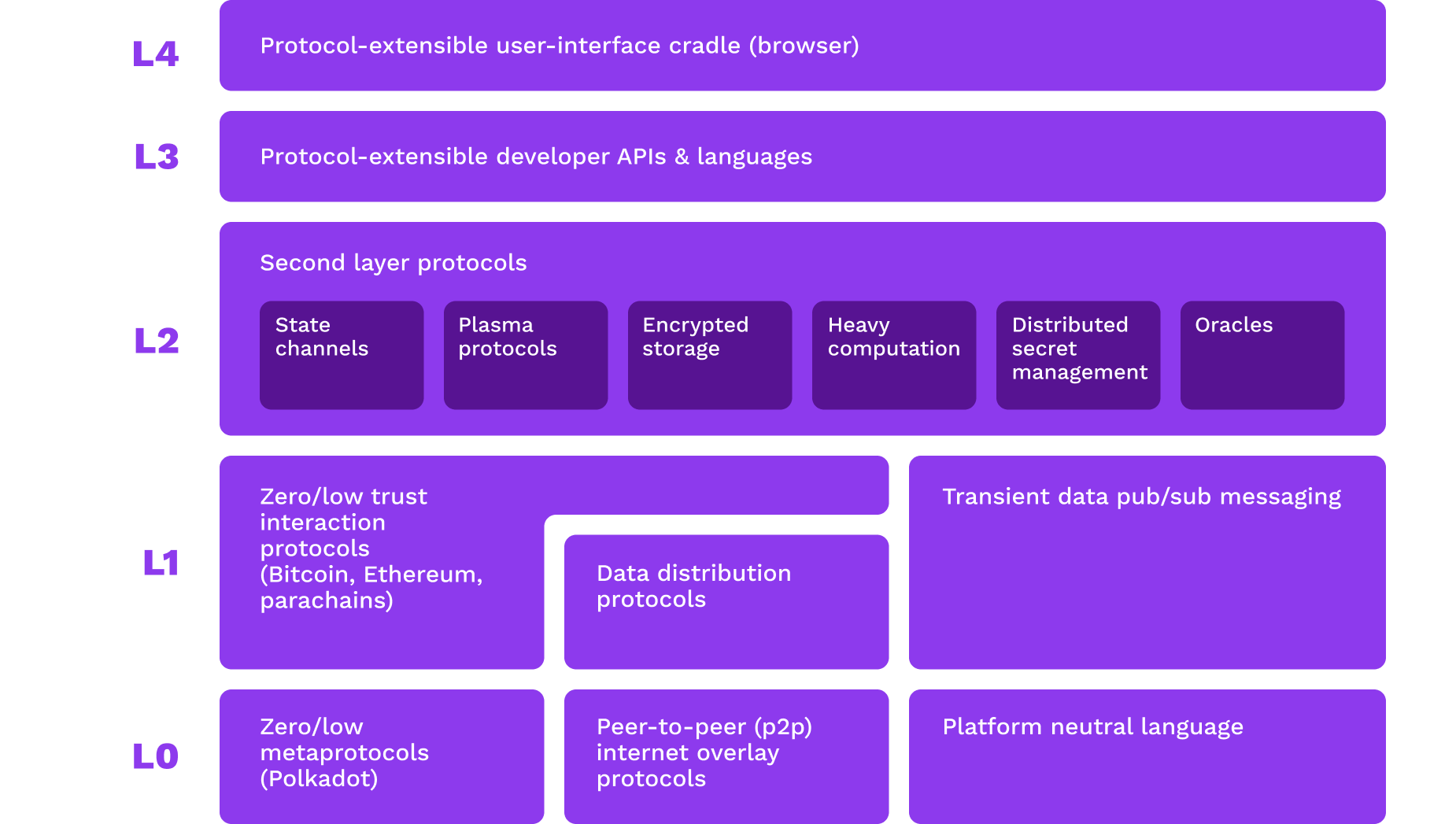
Notes:
This diagram is a bit dated with advancements in the field, but a good approx. representation.
Observation and clarification: DApps canonically refer to smart contract applications. These exist within the context of consensus systems that themselves inherit properties of unstoppability from. The academy is more focused on consensus system engineering - we reason about blockchains themselves - rather than "DApp"s that use those as platforms to operate in or on. The Smart contracts lessons may include detains on unstoppable dapps design considerations.
Much More Than Blockchain Architecture...
Blockchains only form one part of the stack.
Web3 applications must prevent attacks at all layers.
- Networking
- Consensus
- Node access
- Validator power
- Inter-consensus trust
- Human factors
- Extrinsic factors
Notes:
These are for discussion today, but there are many more thank those listed here!
Human Level
Attacking Web3
Notes:
Key point: your "perfect" system in is likely weak to things outside of the "rules"! especially
Image Source: https://xkcd.com/538/
---v
Web3 Criticisms
There are valid criticisms of how many Web3 apps operate today.
- Humans are cheap & lazy...
No individuals run servers. - RPC node providers
- A protocol improves
slowly vs. a platform. - False marketing,
frauds, & scams!
Notes:
https://moxie.org/2022/01/07/web3-first-impressions.html great critique on the state of the space, but founder of Signal messenger.
Not all hope is lost! This is valid mostly in the present, we will discuss these and what we're building to realize a better stack.
Systems Level
---v
Prove it!
We use the word "proof" a lot...
it means many things in different contexts:
- Math → Provable Correct (algo)
- Consensus → Proof of X (security)
- Crypto → [ZK | VRF | Validity | ... ] Proofs
Notes:
The one so far not covered is Provable Correctness - where we can use maths to prove that our logic cannot do unexpected behavior. An interesting example is Cardano's design value proposition using haskell and provably correct most parts of their platform.
We have a lesson and exercise on formal verification methods latter on - this is how we can approach Provable Correctness in the context of Rust and thus Substrate.
BUT this property assumes a complete system model! Nuke proposes that when considering factors outside the consensus system, there cannot be a rigorous proof of correctness as we cannot model the universe.
---v
🔮 Oracle Problem
An oracle provides eternal data to a consensus system.
(i.e. a partial state of an external chain)
The oracle problem relates to the trust in the oracle.
Notes:
- Example: Random Oracle, NOT like VRF we saw in the crypto module that can be in the consensus system.
- Oracle needed for input from anything that lives outside of the boundary of the consensus system.
- Everything in a chain is self-referential. Applications in a consensus system may want to try and reason about something outside itself.
- Inclusive of bridges
---v
🦢 Black Swans
- known bounds of operation assumed impossible
- death spirals
Notes:
Explain example of luna or other system collapse.
---v
🤯 Complexity
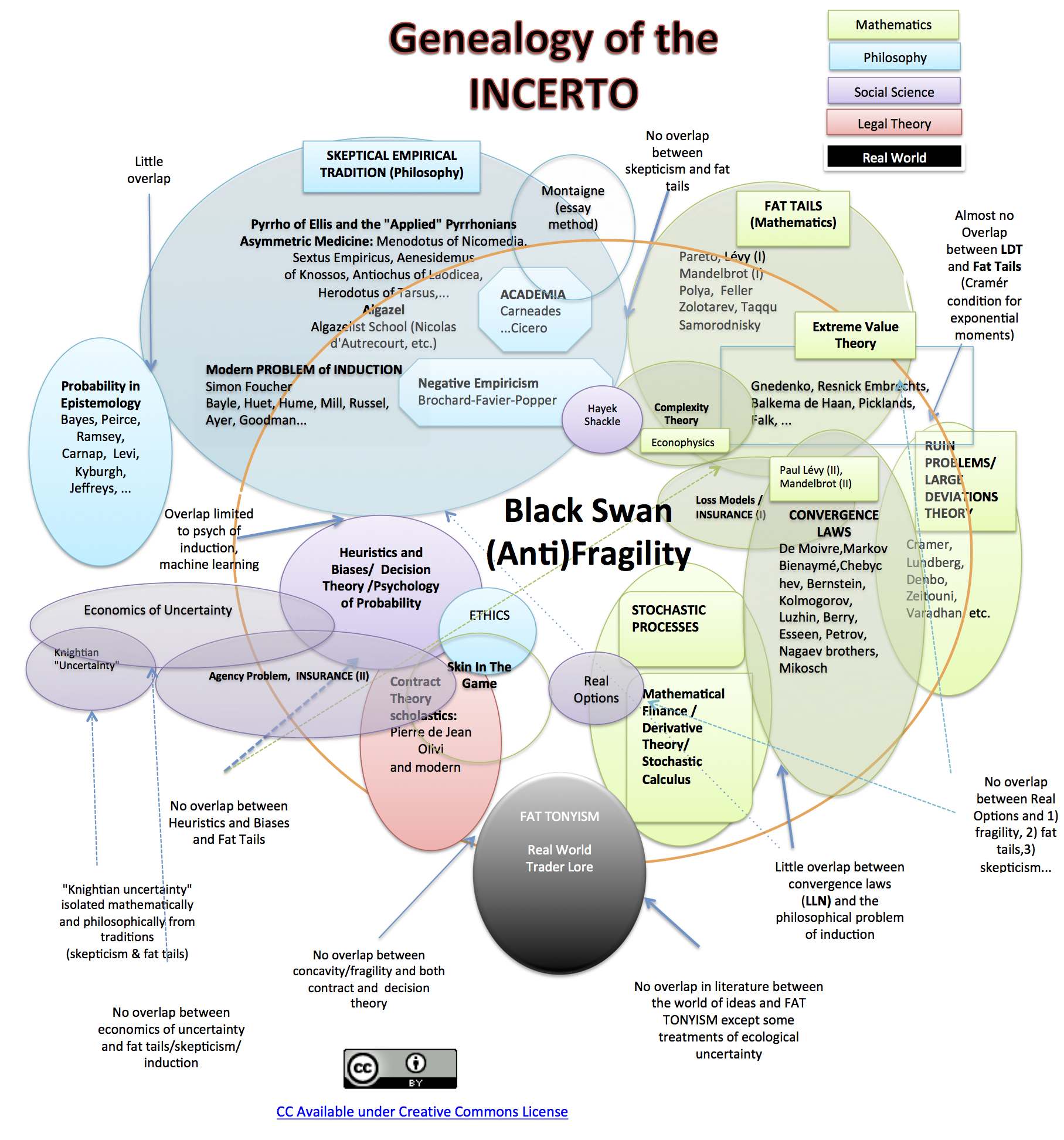
- Illustrating how to map the intricacies of coupled, complicated, interactions of systems.
- * You are not expected to understand this plot 😅
Notes:
- Great talk by the author: https://www.youtube.com/watch?v=S3REdLZ8Xis reference talk by book author.
Example: irrational actors can be represented in a very simple model as a completely random act, or opposite act of what a rational actor would do. If you "fuzz" you system you may discover fragility to irrational actions that could undermine your system. Perhaps it's far easier and more likely than it at first appears to experience a black swan event.
- Image source - Describes the various categories of uncertainty, epistemology limits and statistical subjects touching on Taleb's Black swan / antifragility etc. ideas
---v
👪 Dependency

Notes:
- yes in software and hardware, you are at risk of attack from poisoned deps through non-maintenance, up to targeted exploitation. One mitigation is vendoring these, need systems inn place to monitor. Dependabot is not sufficient.
- Also in dependance on specific operational contexts. For example that it is legal to operate the software for nodes.
Image source: https://xkcd.com/2347/
---v
🦸 Dependency in Polkadot

Foundational to Polkadot ecosystem!
Notes:
- Jaco is effectively the only maintainer of how just about everything communicates with Substrate nodes!
- Capi is on the way, but just getting started.
---v
🙈 Unknown unknowns

Notes:
Outside of the system itself, we cannot guarantee/prove that every possible condition is accounted for in our models & system design. We must expect forces outside our system & it's model may interact in unexpected ways. Assumptions about context must be rigorously evaluated (i.e. - what does finality mean in the chain this pallet or contract lives in?) (Formal mathematical proofs reason only about the things we can and do account for.)
Network Level
---v
🕸️ Peer-to-Peer Networks
---v
Network Attacks
- Entry/Boot nodes and peer discovery
- Data center faults
- Traffic analysis and targeted takedowns
- Eclipse attacks
Notes:
The network lesson covers these, just a reminder that the network is not in the direct command of the consensus system, so it's a threat!
- security & stability
- privacy! On chain might be ZK, but how about the gossip and RPCs?
Boot nodes typically hard coded to "bootstrap" and start peer discovery. Boot nodes can decide what peers to advertize, or can be inaccessible. Common data centers (AWS, GCP, ...) could fail or censor, potentially large number of peers go dark. Hard to hide! Most p2p traffic is easy to identify vs. web2 traffic.
---v
Node Queries
Running a node is hard, most people outsource.

These service have power to deceive, censor, and surveil.
---v
Multi-Chain Applications
If running one node is burdensome, try multiple.
---v
Trustless Messaging
In order to handle messages without trust,
systems must share common finality guarantees.
A should never process a message from B,
where B is reverted and A is not.
---v
A Note on Synchronicity
Smart contracts on a single chain (e.g. Ethereum)
can interact trustlessly because of their shared view of finality.
Asynchronous systems can also share finality.
i.e., be members of the same consensus system.
---v
Discussion
Minimum viable decentralization.
What key aspects should be considered?
Notes:
- Quantitative: nodes needed (for what), incentives, ... FIXME TODO
- Qualitative: social norms, ... FIXME TODO
Consensus
---v
Mining Pools
Proof of Work authority sets have no finite bound.
But people like to organize.
[Collaborating | Colluding] authority sets creates risk.
Notes:
Call out that Nomination pools exist and are discussed in the NPoS lesson latter. Similar issues, but in a more bounded set.
---v
Mining Pools
Notes:
Source: Buy Bitcoin Worldwide
---v
Security Dilution
Security is always a finite resource:
- Centralized: Cost of corruption/influence
- Proof of Work: Number of CPUs in the world
- Proof of Stake: Value (by definition, finite)
---v
Security Dilution
Consensus systems compete for security,
and they have reason to attack each other.
Emergence of obscure/niche "Proof of X" algorithms
to shelter from attack only goes so far.
---v
⚔ Blockchain Wars
Systems with high security have the
incentive to attack systems with low security
whom they perceive as competitors.
For fun and profit.
Notes:
"In a galaxy the universal consensus far far away not so far away..."
---v
⚔ Proof of Work Battles
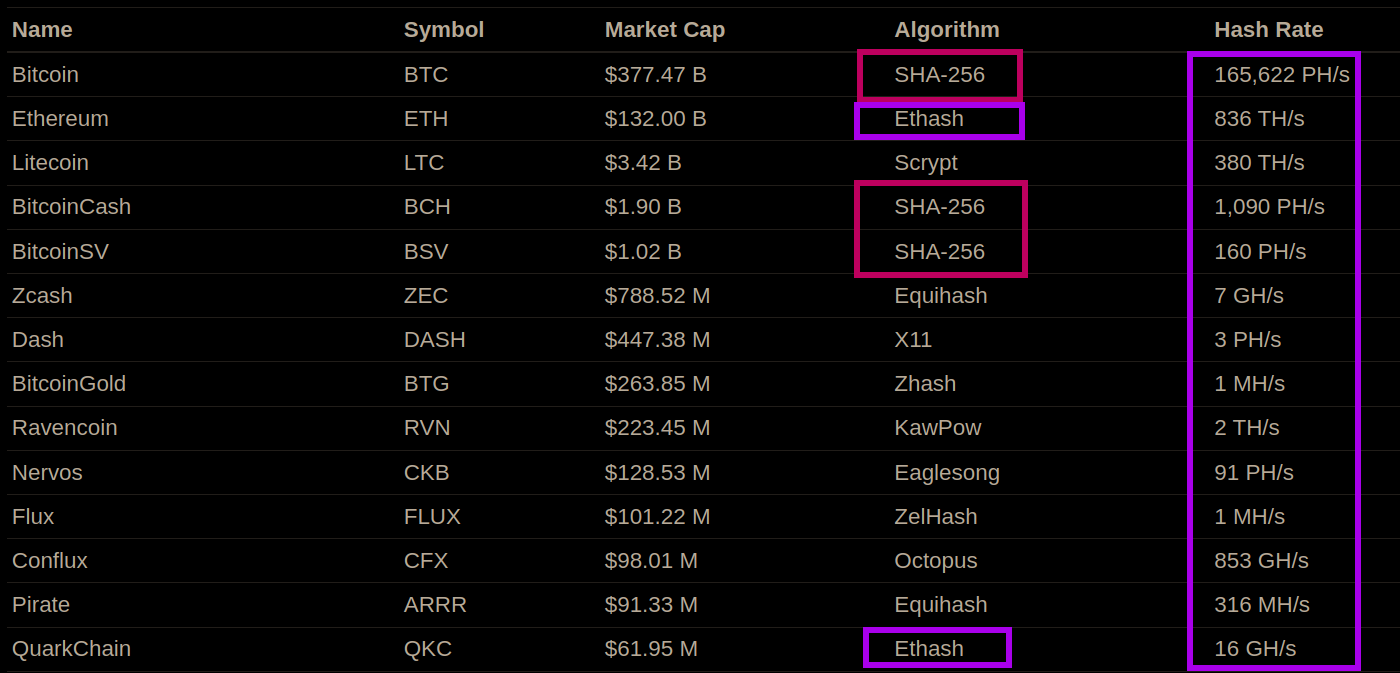
What might it cost to successfully attack?
Notes:
- For PoW, hashing power for the same algo can be attacked! Buying hash power is possible:
- Most GPU miners switch tasks to the mine the highest paying (relative to some base currency) chain using software like https://www.nicehash.com/.
- ASICs are less flexible, but also can to the highest paying coin.
- Example: ETH classic deep re-ogs
---v
Proof of...
Nothing at Stake
Forks are "free" to vote in favor of...
vote on them all!
(If you are not eventually slashed!)
What might it cost to successfully attack?
Notes:
- Unlike PoW where voting on a chain costs something extrinsic to the system, PoS has only intrinsic measures to do accounting of consensus rules.
- Critical: This was a problem with early naive implementations of PoS. Modern PoS schemes avoid this specific problem by having the security deposit and slashing for equivocation (in a few slides)
- Good explainer, source of image: https://golden.com/wiki/Nothing-at-stake_problem-639PVZA
---v
Proof of...
Relatively Nothing at Stake
Risk-to-reward ratio of attacks is
relative to the valuation of the staked assets.
Rational actors take into account
extrinsic motivators in calculating the highest reward.
What might it cost to successfully attack?
Notes:
- Again PoS ha only intrinsic measures to do accounting of consensus rules, but the system doesn't exist in a vacuum: the relative valuation of what is at stake needs to be accounted for.
---v
Validator Consolidation
How many validators does a system need?
Higher numbers should lead to a decrease in the ability for entities to collude.
But validators are expensive, both economically and computationally.
Notes:
Yet another N-lemma to consider.
---v
PoS Economic Security
Proposition: The upper bound of economic security in PoS is relative valuation can secure, that is correlated with the market capitalization of the network.
Market capitalization refers to the total market value of all assets inherent to a single company/chain/token.
Notes:
- This market capitalization could be company shares, or total ETH in existence, or total X token associated with a specific smart contract or parachain.
---v
⚔ PoS Economic Security Battles
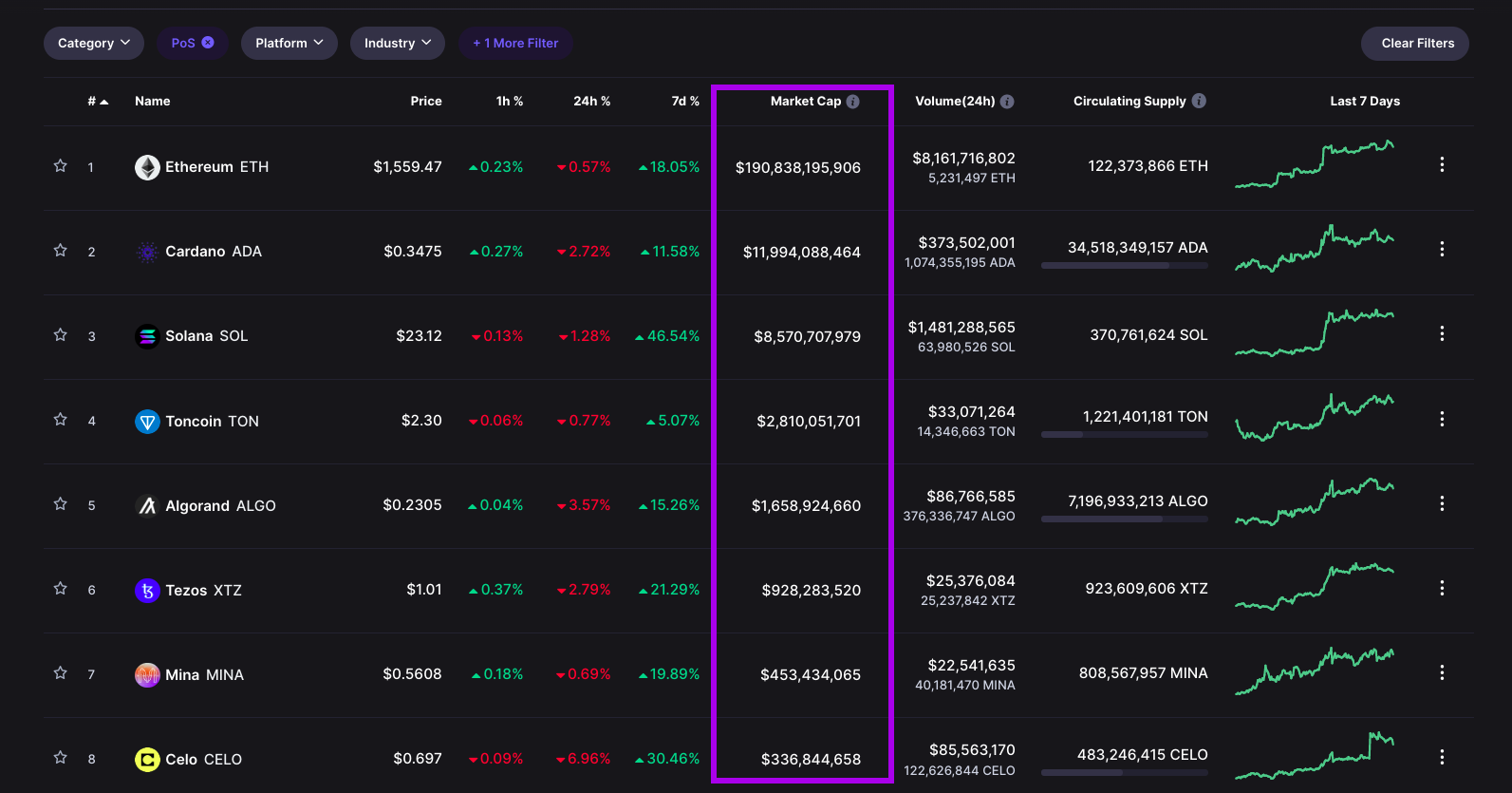
Notes:
Here like in PoW we have relative safety in networks, but there is no way to "hop" from one chain to another, so the war is still in the relative security, but one stake cannot directly attach another stake in a separate consensus system...
What about an system of value within consensus?
---v
DApp PoS Economic Security
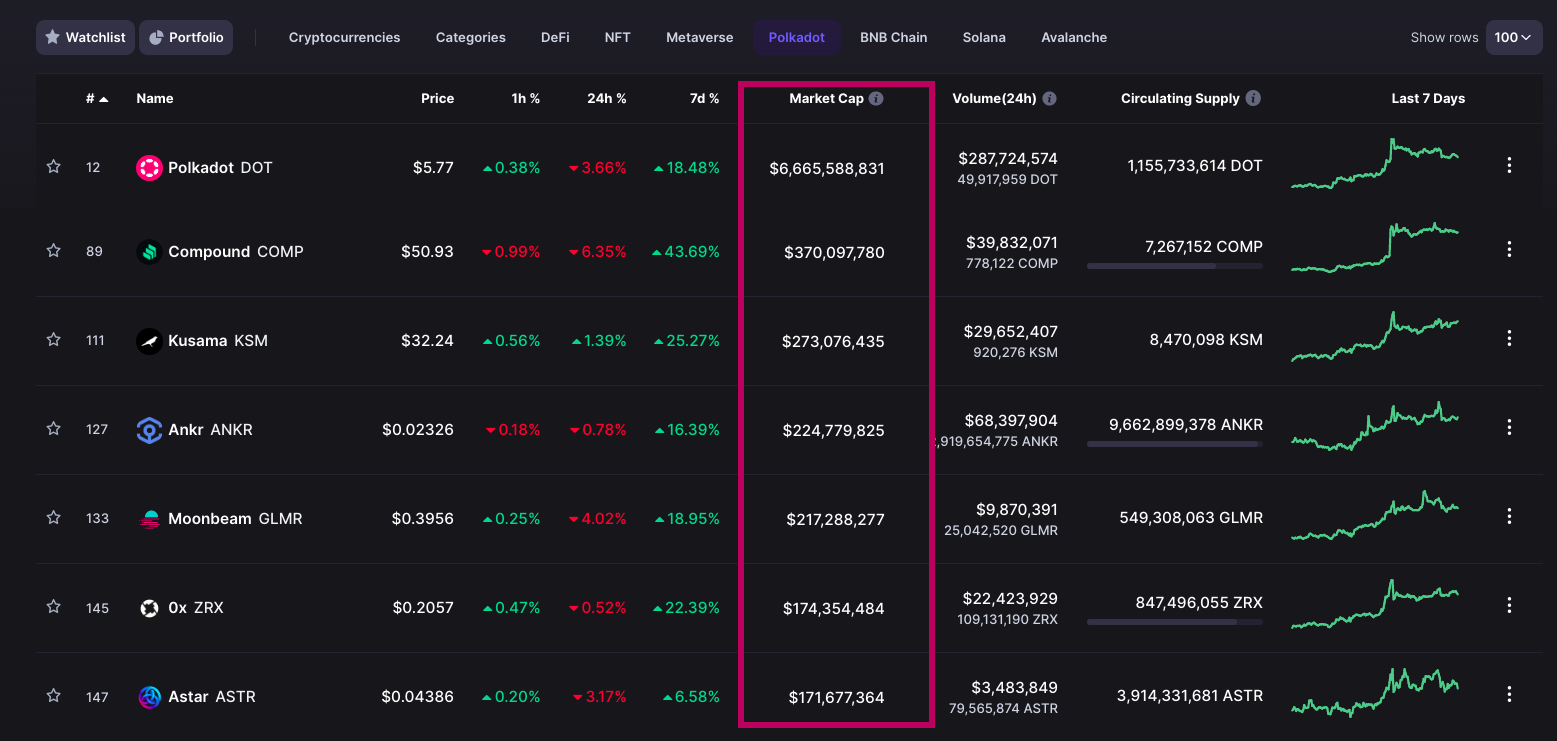
Notes:
Consideration: these notes are an oversimplification! We may talk more about this kind of problem in NPoS lesson (Nuke thinks at least). The details of a formal analysis are out of scope for this Academy.
Proposition: Total applications valuation of their assets (tokens on smart contracts, or parachains) is limited and that limit is correlated with the total economic security of the consensus system they reside in.
In Polkadot's relay chain model, Nuke would argue it's feasible that an attack to extract value from a very highly valued asset could outweighs the cost of obtaining a byzantine level of stake to execute. Therefore the sum of all parachains market cap is also limited as that same level of stake control would enable take over of all chains on it.
Nuke argue this is the same for the sum of all contracts valuations on something like Ethereum.
---v
Authority Misbehavior
- Equivocation
- Authorship: Proposing mutually
exclusive chains - Finality: Voting for mutually
exclusive chains to be final
- Authorship: Proposing mutually
- Invalidity
- Lack of availability
- Intentional protocol abuse (selfish mining)
Notes:
We already talked consensus faults, but abuse is newer. Nuke argues "abuse" as a term here isn't the intended mechanism design, and is adverse to the health of the system. Selfish mining where it's impossible to prove an author is withholding valid blocks to "cheat" by mining ahead of the rest of th network is a good example in the class of attacks that consensus authorities and others may have.
...Could other actors abuse the protocols?
---v
Accountability of Authority
Authority should imply accountability.
No matter how you design an authority selection mechanism, some people will have a privileged position within it.
Those who choose to become authorities should be liable for their actions.
---v
Provability and Equivocation
Some types of misbehavior are harder to prove than others.
Equivocation is simple:
Someone can just produce two signed messages as cryptographic proof.
Others rely on challenge-response games and dispute resolution.
Notes:
Nothing at stake solution, with the possible caveat of long range attacks Weak subjectivity can still potentially cause the same behavior in a much harder to orchestra way, with bad actors having already have their stake released to produce a valid, finalized fork.
---v
Design Considerations
in Polkadot
- More validators increases the state transition throughput of the network: parachains.
- Individual shards have full economic freedom by being members of a larger consensus system.
- Superlinear slashing puts colluding validators at existential risk,
while well-meaning ones should have little to worry about).
Notes:
A few interesting design decisions in Polkadot's architecture.
We will cover polkadot much more in depth latter!
---v
Transaction Censorship and Ordering
Block authors choose the transactions they include and in what order.
- Censorship attacks
- "Maximal extractable value" (MEV)
---v
Web3 Goal: Non-Censorship
There are a lot more system users than system authorities.
However, every transaction must be included by an authority.
If no authority will include a user's transaction, they do not have permissionless access.
If any authority (author) decides not to censor, it may be included.
Notes:
Most present systems have no mechanism to penalize censorship, and a much harder problem can be the ability to discover this is happening on the network at all, depending on the actors involved.
---v
Maximal Extractable Value (MEV)
A measure of the value that block authors can extract based on their knowledge of pending transactions and ability to order them.
- Frontrunning
- Backrunning
- Sandwiching
Notes:
Emergent behavior. Not realized as possible by many until it quietly became the norm.
---v
Maximal Extractable Value
An environment in which detection means certain death...
...identifying someone’s location is as good as directly destroying them.
-- Ethereum is a Dark Forest --
Notes:
Tell the story of this article, basically a white hat engineered obfuscation to try and remove funds in a bugged contract -> someone decoded, realized extractable valued, and front-ran them.
This is now the norm on Ethereum at least, and further it's becoming institutionalized.
---v
👼 Flashbots
Flashbots is a research and development organization formed to mitigate the negative externalities posed by Maximal Extractable Value (MEV) to stateful blockchains, starting with Ethereum.
-- Flashbots --
Notes:
This might be misleading, in that they are profiting in making MeV more effective and institutionalized!
---v
Flashbots 😈
- Flashbots Auction: a marketplace for transaction ordering including the Flashbots Relay and MEV-Geth.
- MEV-Boost: an out-of-protocol implementation of proposer-builder separation (PBS) for proof-of-stake Ethereum.
- Flashbots Protect: an rpc endpoint that anyone can use for protection from frontrunning and failed transactions.
- Flashbots Data: tools and dashboards to improve the transparency of MEV activity on Ethereum and the Flashbots Auction.
Notes:
Centralizing force, as information asymmetry generally drives towards a monopoly on MeV. Competitive landscape for this exists, and to Flashbots' credit, they seem genuine in trying to help the health of Ethereum by decentralizing...
(BUT FIRST a discussion!) Especially in light of recent OFAC pressures revealing fragility in the system...
---v
Discussion
Front-running as a Service (FaaS) & MEV Auctions (MEVA)
A solution or crutch?
Notes:
- Flashbots & Friends
---v
Compliance

Notes:
- code is unstoppable, but platform can sensor. Ability -> responsibility (we may talk more on that latter)
---v
Social Context
Social systems and norms can help cover up weaknesses in protocols.
Public monitor to shame OFAC censors:
Notes:
- Pressure from peers through breaking norms, perhaps even losing of authority in consensus due to this. Peer reputation in computer networks, and here also in human ones.
- Sometimes social pressures are healthy for the system, sometimes toxic depending on point of view and who benefits!
- In monero "run your own node" culture helps keep it decentralized.
Bitcoin big block wars show social pressures help decide the canonical forks. - Normalizing MEV for the profit of middlemen, providing extraction services in the worst case.
---v
Unbundling
Notes:
From before, but here point out how this is getting more fine grained as well, and where a single actor would do it all (early bitcoin for example) we are moving more and more to appear.
- Especially if more things like MeV can be enhanced by doing so.
- This introduces more complexity and interfaces that can provide weakness (especially when a network is required!)
---v
Unbundling
The vision of "blockspace" leadsmore and more to this end
---v
Diversity
Notes:
-
Parity saved ETH (alt clients, and diversity)
- same runtime on chain, it's impossible to have an alt runtime.
-
all on GCP
-
All run same hardware (CPU, etc.)
-
...
-
Image source, and good reference on this: https://mirror.xyz/jmcook.eth/S7ONEka_0RgtKTZ3-dakPmAHQNPvuj15nh0YGKPFriA
Final Thoughts
- Complexity generally increases the risks of failures, but we should not fear it.
$~~~$Hypothesis: this _usually makes systems more brittle._ - Observable behavior trumps models and theory.
$~~~$Complex systems are not intuitive and may show your assumptions and models are wrong! - This lesson was a start down holes... $~~~$We encourage you to keep diving deeper!
Notes:
- Risks and unknown unknowns increase exponentially so in many cases.
- Examples of observables in things like MEV OFAC dominance and Babe fallback dominance etc.
- Looking forward to explore the great unknown horizons in web3 together!
🤝 Together, into the Deep
Questions
Additional Slides
Notes:
For reference mostly, outside of formal class time 😀
Governance... Unstoppable?
Unstoppable Code: The Difference Between Can't and Won't
Notes:
Watch after class! Perhaps assigned informally to everyone to watch in the next few days.
---v
Unstoppable Code
It seizes power from dominate forms of power: governments, corporations, states, associations, cultures, religions. It seizes power, from these big things and gives it to little people. And sooner or later, the people who are losing their undeserved, abusively applied power will start to fight back. And at that point, we will start to find out how unstoppable our code is.
-- Andreas Antonopoulos --
---v
Can't vs. Won't
The moment you go over the the line from "can't to won't, what started as an ability becomes a responsibility. And then if you claim that you don't have the ability anymore, that responsibility just became negligence, criminal negligence.
-- Andreas Antonopoulos --
Notes:
- The difference?
- Silk road founder getting 2 life sentences + 40 years.
- moral relativism -> "who's law?"
- Don't make your "oops clause" -> not too narrow.
DAOs
Decentralized Autonomous Organizations (DAOs).
A coordination mechanism.
---v
Democratic Systems
Democratic Mediums is a directory of patterns
for decision, deliberation, and noise.
Notes:
Very much encouraged to explore after class! Many novel and niece definitions in this wiki.
Modeling Behavior
Token Engineering
{especially the Academy & cadCAD Edu}
Notes:
Mostly free education and tools to dive deeper on tokenomics. Remember, these are models of idealized systems in general, real world conditions will differ!
Consensus Finality
How to use the slides - Full screen (new tab)
Consensus: Finality
Consensus is...
...a decision making process that strives to achieve acceptance of a decision by all participants.
Notes:
If we have external factors like trust relationships or Social hierarchy it can be quite easy.
Trust example: If everyone trusts each other, then any one person can propose an outcome, and all the others will trust that it is in the community's best interest.
Social Hierarchy example: If a community has an executive (President, Queen, CEO), the executive can propose her preference and everyone will accept it based on the external mechanism that keeps her as the executive.
But these conditions are not interesting, and are often not realistic. It gets interesting when we don't make these simplifying assumption.
---v
Five Aspects of Blockchain Consensus
- State machine validity
- Arbitrary / Political validity
- Authorship throttling
- Fork choice heuristic
- Finality
---v
Adversarial Conditions
- The participants want to agree on something
- They don't trust each other
- Some could be faulty, or make mistakes
- Some could be straight up malicious (aka Byzantine)
One Shot Consensus
A single decision to make.
Once it is made, we are done.
---v
Desired Properties
All honest participants...
- Termination - Eventually reach some decision
- Agreement - Reach the same decision
- Integrity - Reach at most one decision, which was proposed by at least one participant.
---v
Also Validity
If all participants unanimously propose the same decision, all honest participants reach that decision.
Notes:
Another desireable property that is sometimes too obvious to say.
Example: Where to go for dinner

- Termination - Stan, Kyle, and Kenny will each eventually decide where to eat.
- Agreement - Stan, Kyle, and Kenny will each decide to eat at the same place.
- Integrity - Stan, Kyle, and Kenny will eat at either Whistlin' Willies or Casa Bonita.
Notes:
Stan, Kyle, Kenny, and Cartman are trying to decide where to have dinner. Stan, Kyle, and Kenny want to have something yummy and spend time together. Cartman is secretly pursuing his own goals and doesn't care whether dinner is yummy. In fact he secretly hopes they won't decide at all so he can go home and eat KFC with his mom.
Stan and Kyle both propose Whistlin' Willie's for dinner. Kenny and Cartman propose Casa Bonita.
In the end Kenny may not agree that Whistlin' Willie's is the best option for dinner, but he will agree that it is the legitimate group decision.
---v
Mistakes vs Malice
Crash Tolerance - A system can keep operating normally when some actors crash or go offline.
Byzantine Fault Tolerance - A system can keep operating normally when some actors are intentionally malicious. Byzantine actors may:
- Crash - Or pretend to have crashed - Byzantine faults are a superset of crash faults
- Lie - Sending false information to peers
- Equivocate - Send inconsistent information to different peers
Notes:
These examples and many others are instances of the Byzantine Generals Problem
---v
Mistake or Malice?

- Consider an Airplane flight computer.
- The pilot must know the airspeed at all times.
- Airspeed sensors can fail.
- Sensors can be buggy.
- Are these malicious?
Notes:
Consider an Airplane flight computer. It is critical that the pilot (human or automated) knows the aircraft's airspeed at all times. Airspeed sensors can fail due to extreme temperatures, icing, solar radiation, and other reasons. For this reason, there are redundant sensors, and they run a consensus protocol.
Imagine that one of the sensors has an overflow bug such that when the airspeed exceeds a certain threshold, maybe u8::max_value(), it actually reports a much lower speed.
Are these crash faults or byzantine?
In a blockchain system, bugs in the code may cause nodes whose operators are intending to be honest, to deviate from the protocol anyway. This is why client diversity is important.
Image source: https://thepointsguy.global.ssl.fastly.net/uk/originals/2020/12/pitot-ice-scaled.jpg
Byzantine Generals Problem
- Divisions plan to attack
- Must make coordinated attack to succeed
- Some generals might be traitors and behave maliciously
Notes:
Several divisions of the Byzantine army are camped around an enemy city. They plan to attack the city, but have not yet decided when to attack. If the attack is coordinated, they will probably be successful, but if it is uncoordinated, they will probably be defeated. What do our three properties mean in this scenario?
- Termination - every honest general will eventually decide when to attack
- Agreement - honest general will all agree to attack ta the same time
- Integrity - the attack time will have been proposed by at least one honest general
Leslie Lamport proposed this problem in the form of a story as a typical representative of the distributed consensus problem.
This is a big moment for us, so let's stop and savor it. Two days ago Lauren kicked us off by talking about human coordination. How it can achieve long railroads and the great pyramids and sports teams and dancing, and even this academic program. Since then we've looked through so many layers of abstraction (contracts, smart contracts, state machines, dags) and so many technical implementation details (P2P networking, platform agnostic bytecodes, blockchain headers, merkle proofs). We've taken a huge class of problems - human coordination problems - and distilled them down to their absolute essence. Human coordinate at global scale reduced to this one cute, carefully stated problem.
---v
Byzantine Generals: Solved

Miguel Castro and Barbara Liskov, 1999
Notes:
Image = Cover page: Practical Byzantine Fault Tolerance
And great news. The problem is solved! At least under some conditions. And also great news. We have a pretty good understanding of under what circumstances it is solvable.
Before I can tell you exactly how and where it can be solved, we have to understand networks a little bit.
History Lesson
Synchrony
A network is one of:
- Synchronous - When sent, a message is received immediately by all.
- Asynchronous - When a message is sent it may be received after some delay, or not at all. The sender doe not know whether it is received. Messages may be received in different orders by different parties.
- Partially Synchronous - When a message is sent, it may be received after some delay up to a maximum delay, $T$. It may not be dropped entirely. Messages may be received in different orders by different parties.
Roughly analogous to real-time (async) vs. turn-based (sync) games.
---v
Sync or Async?
Classify each of these:
- Telephone call
- Mail communication
- Text message
- Jitsi video call
- Element chat
Notes:
- Telephone call is sync. You say something and wait for the other party to reply
- Mail is async. You send a letter, then go do other stuff for several days
- Jitsi video call is basically sync just like the phone call.
- The others can be either. Sometimes you text back and forth quickly and wait for replies. Other times you send and come back later like mail.
Determinism
A system is one of:
- Deterministic - The same inputs give the same outputs every time.
- Probabilistic - The same inputs may not give the same outputs.
$~~~~~~~~~~~~~~~~~~~~~~~~~$ Requires a source of entropy. eg coin flipping.
FLP Impossibility
Excellent Podcast with Ethan Buchman
Notes:
Once it was shown that deterministic consensus is impossible in an async network, the field split into two major parts. Either you:
- Assume the network is (at least partially) synchronous
- Introduce non-determinism
One interesting thing about Nakamoto pow consensus is that it does both.
- Nondeterminism because you don't know who will solve the pow first
- Partial synchrony because it only works if the time to download and execute the block is much less than the time to solve the PoW
Ongoing Consensus
We want to continue agreeing on
an every-growing history of events
Notes:
Blockchains are intended to keep processing and finalizing transactions forever. This is more like deciding where to go to dinner every night over and over.
---v
Desireable Properties
- Safety aka Finality - Nothing bad will happen
- Liveness - Something good will eventually happen
Notes:
Traditional literature typically uses the term safety. Blockchain folks typically talk about finality. They basically mean the same thing.
Finality can be proved to entities that are not involved in consensus.
We spoke about liveness previously in the authoring system. There it means that more blocks will be authored, more blockspace will be created and put up for sale. Here, in finality, it means that more blocks will be finalized. Of course liveness in the finality depends on liveness in the authoring.
These two decisions can be entirely orthogonal to one another, or wrapped up together.
---v
Liveness vs Termination
Earlier I described Termination as desireable,
now I'm saying Liveness is desireable.
Are these at odds with each other?
Notes:
Termination guarantees that, for a given decision, each honest participant will eventually decide something. This concept is relevant when there is a single decision to be made. In the blockchain context, it guarantees that we will eventually know which block is final at height n.
Liveness guarantees that a system that is intended to continue making progress, will indeed eventually make progress. In the context of the blockchain, liveness means that once we've decided what block is final at height n, we will eventually go on to decide what block is final at height n + 1.
Finality in Nakamoto Consensus
- Longest chain rule
- Longest chain is "best"... for now
- Someone could always start mining a chain
and,with low but non-zero probability,
end up with it longer. - There could already be a longer chain
that you just haven't heard of.
The finality is only probabilistic.
Nakamoto consensus in only safe in a synchronous network.
Notes:
This is to say that Nakamoto consensus is NOT safe on the real asynchronous internet. In practice, as long as blocks can be downloaded and executed much more quickly than the target block time, it is usually good enough.
- Longest could also mean most accumulated work
Deterministic Finality
- Based on traditional methods (BFT)
- Requires an honest-majority finite authority set
- Consensus protocol that assumes honest majority
- Economic game that keeps them honest
Notes:
If you want deterministic finality, it basically means employing BFT agreement protocols that we talked about in the history lesson. This means we need a finite authority set with an honest majority. And that means we need incentives to keep them honest.
---v
Incentives: Game Theory!
Abstractly: You behave honestly
when the utility of doing so exceeds the cost.
Incentive designers may potentially:
- Reward honest behavior
- Punish (aka slash) dishonest behavior
Notes:
Many systems use both of these, but doing so is not strictly necessary. Even without slashes, the opportunity cost of staking and the missed rewards from authoring invalid blocks may be sufficient.
It is often the case that blockchain systems give rewards in the authorship and punishments in the finality. There is no fundamental reason for this; it is just a little more straightforward to implement.
---v
What is potentially punishable?
- Authoring when you aren't supposed to
- Failing to author when you are supposed to
- Casting finality votes for conflicting blocks
- Casting a finality vote for a block (or chain)
that includes an invalid state transition.
How severe are each of these offenses?
Do they all warrant a slash?
A full slash?
Notes:
PoW has inherent punishment through wasted energy. BFT based system's don't.
Instead, aspiring participants will typically lock up a security deposit which can be slashed in part or in whole.
---v
Concrete Punishment Example
Let's say a slash is 100 units, and the reporter gets 10%.
I plan to attack.
If my attack is successful,
I expect to gain roughly 200 units worth of utility.
I ask another authority to cooperate with me:
"I'll pay you 20 units to not rat me out for my attack".
How would you respond?
Notes:
"I don't believe you can carry out the attack because someone else will report you and take the 10 units, leaving me with 0."
Case Study: Tendermint
- Authorship is like Aura - simple round robin
- Naive but simple BFT implementation
- If the block has enough votes
by the end of the slot, it is finalized.
Otherwise, it is rejected via timeout. - "Instant finality"
- Forkless - Forks are disallowed
because blocks can only be authored
on finalized parents.
Notes:
Tendermint assumes a partially synchronous network, like all the BFT based systems - That is to say that messages may not arrive immediately, but will arrive within a finite time bound. In practice this means it is slot-based just like so many of the authoring schemes.
Tendermint is often touted as "instant finality". It is instant in the sense that finality is tied to authorship. In practice this means that authorship, which is inherently O(n), is slowed down to stay in sync with finality which is O(n^2). They sacrifice liveness to guarantee absolute safety at all times.
---v
Tendermint Deep Dive
- Wait for a block (or author one if it is your turn)
- Prevote
- If the block is valid, Prevote for it.
- If the block is invalid, Prevote `Nil`
- Precommit
- Wait for 2/3 prevotes then Precommit
- If you don't get 2/3 prevotes, Precommit `Nil`
- Complete
- Wait for 2/3 Precommits them finalize
- If you don't get it, throw the block away
Hybrid Consensus

- Separates block production from finality.
- Block production stays live even if finality lags.
- Allows lower overhead in the finality layer.
- Used in Substrate.
---v
What About Re-Orgs


Notes:
Previously we talked about how a node's view of the best block can change, and that is called a re-org.
---v
Modified Fork Choice Rule


Only extend best finalized chain Notes:
Once you have a finality gadget installed, you have to make sure you only ever author on top of finalized blocks. Even if another chain is longer.
Case Study: Grandpa
- Deterministic finality only
- Requires an external block authoring scheme
with its own liveness proof. - Kind of like Tendermint but better.
- Finalizes chains, not blocks.
---v
Vote on Chains, not Blocks
Notes:
BFT finality with $n$ authorities is in $O(n^2)$. Tendermint does this at every block. This bounds the size of the authority set.
With separated, we treat each vote as a vote not only for one block,but also for each ancestor block. This significantly reduces the number of total messages sent. Allows the chain to stay live even when many validators are offline
A GRANDPA Round
Each validator broadcasts a prevote for the highest block that it thinks should be finalized
- For honest validators, this block must include the chain that was previously finalized
- This new chain could be several blocks longer than the last finalized chain
A validator that is designated as the primary broadcasts the highest block that it thinks could be final from the previous round
A GRANDPA Round
Notes:
- 7 = # Validators
- 5 = # Threshold
A GRANDPA Round
Notes:
- 7 = # Validators
- 5 = # Threshold
A GRANDPA Round
Each validator computes the highest block that can be finalized based on the set of prevotes
- i.e. we find the common ancestor of all votes that has support from more than $\frac{2}{3}N + 1$ validators
- We refer to this block as the prevote GHOST
A GRANDPA Round
Notes:
- 7 = # Validators
- 5 = # Threshold
A GRANDPA Round
We define the round estimate as the highest ancestor of the prevote GHOST for which it is still possible to precommit
- i.e. when no precommit votes have been sent out yet, then:
estimate == prevote GHOST
A GRANDPA Round
Notes:
- 7 = # Validators
- 5 = # Threshold
A GRANDPA Round
If the estimate extends the last finalized chain, then each validator will cast a precommit for that chain.
Each validator waits to receive enough precommits to be able to finalize
- We again find the common ancestor of the estimate which has threshold precommits
- We declare that block as finalized
A GRANDPA Round
Notes:
- 7 = # Validators
- 5 = # Threshold
A GRANDPA Round
Notes:
- 7 = # Validators
- 5 = # Threshold
A GRANDPA Round
The round is deemed completable:
- if the estimate is lower than the prevote GHOST
- or if it's impossible to have a supermajority on any block higher than the current estimate
Validators start a new round after it becomes completable.
A GRANDPA Round
Notes:
- 7 = # Validators
- 5 = # Threshold
A GRANDPA Round
Notes:
- 7 = # Validators
- 5 = # Threshold
A GRANDPA Round
Notes:
- 7 = # Validators
- 5 = # Threshold
A GRANDPA Round (Alt)
Notes:
- 7 = # Validators
- 5 = # Threshold
A GRANDPA Round (Alt)
Notes:
- 7 = # Validators
- 5 = # Threshold
A GRANDPA Round (Alt)
Notes:
- 7 = # Validators
- 5 = # Threshold
A GRANDPA Round (Alt)
Notes:
- 7 = # Validators
- 5 = # Threshold
Summary
- Networks can be {Synchronous, Asynchronous}
- Consensus systems can be {Deterministic, Probabilistic}
- Consensus systems can be {Open participation, Finite participation}
- There is always an assumption that at least {1/2, 2/3} participants are honest
- In decentralized systems, we use Economics and Game Theory
to incentivize honest execution of the consensus protocol
Game Time
Grandpa - The Board Game
- Players: 5+ (4 actual players, 1 author)
- Play time: 15 - 60 min
- Materials: A large whiteboard and many colored markers
Overview
Grandpa is a Byzantine fault tolerant blockchain finality gadget (formal spec). This collaborative board game allows players to learn and practice the Grandpa protocol while also having fun together.
Your goal in the game is to finalize blocks in an ever-growing blockchain data structure. You will work together to share information with other players and reach consensus. But watch out; some players may be Byzantine!

Some less important details of the grandpa protocol (such as primaries, and timeout conditions) are omitted from the board-game for the sake of playability and clarity.
Setup
Select one participant to act as the "author" who is responsible for creating the blockchain structure, but will not actually play the grandpa protocol. The remaining participants are all players in the grandpa protocol.
Give one marker to each participant including the author. Each player should have their own marker color. Avoid colors that are hard to distinguish such as light red and pink. If you have colorblind players, take special care when choosing marker colors.
Choose a goal number of blocks that you wish to finalize together as a team. The game will end when you reach this block number.
Views and Gossip
The grandpa protocol operates in a decentralized asynchronous blockchain network. As such, there is no universal view of the blockchain data structure or the messages that are being passed between players in the protocol. Some players may see more information than others and information may arrive to the various players in different orders.
Divide the whiteboard into a dedicated space for each player in the protocol. Each player should have roughly 50cm X 50cm. The author does not need their own dedicated space.

Throughout the game all participants including the author are responsible for communicating with other players by adding information to other players dedicated spaces. In fact, most of the marks that you make during the game will be on someone else's space rather than your own. For a more realistic game, take care to share information with other players in a different order each time.
Genesis Block
Before game play begins, the author draws a single genesis block labeled G on each player's view.
Each player marks the genesis block as final by shading it with their color in their own view.

Authoring
The author is responsible for creating the blockchain data structure and gossiping it to the players. As the game progresses the author will grow the blockchain by creating descendant blocks of this genesis block. The author may create blocks anywhere in the chain they see fit. They may create forks, or linear runs without forks. They may create a long chain and then go back and create shorter forks from earlier in the chain.
When the author creates a block they should gossip it to all players by drawing it on each player's view. A block is drawn with a pointer to its parent block and a short unique block identifier like a few characters or digits. The author should take care to vary to order in which they place new blocks on various players' views. In fact, the author may even gossip multiple blocks to a single player before going back and gossiping any of them to other players. However the author should ensure that all blocks are eventually gossiped to all players.

DEF yet.In some ways the author acts as a "party host" or "dungeon master" for the game. They should observe the players progress, struggles, and enthusiasm, and author accordingly. If players are struggling to keep up or getting frustrated or overwhelmed the author should slow down the authoring rate or build a simpler chain with fewer forks. If players are easily finalizing blocks or getting bored the author should speed up, create a more complex tree with many forks, or decrease the synchrony.
Game Play
The Grandpa protocols proceeds in rounds. Each player has their own view of what round they are on, and not all players will be on the same round at the same time. In each round, each player casts two votes known as the "prevote" and "precommit" in that order. Each player begins in round 1.
Like many other BFT protocols, Grandpa requires strictly greater than 2/3 of players (not counting the author) to be properly following the protocol. For the remainder of this section this will be referred to as a "threshold".
Prevoting
Each player begins a round by casting their prevote. A prevote can be thought of as a non-binding signal for what the player hopes to finalize in this round. Generally the prevote should be for the longest chain that extends the best finalized block. A player casts their prevote by writing the current round number off to the right of the block they are prevoting for first on their own view, and then on other players' views. Remember you should send your prevotes out to other players in a different order each time, and it is okay to allow some latency between sending it to each player.

ABC in round 2. Their prevote has not yet been gossiped to all players. Players 2 and 4 have not yet cast prevotes for round 2.If a player hasn't yet seen the block you're prevoting for, you may add the block and its parents to their view.
The Prevote Ghost
When a player has seen a threshold of prevotes in the current round, they can may mark the round's "Prevote Ghost" on their own view.
They may also choose to wait a short time to see if any new prevotes are coming in.
The prevote ghost is defined as the highest block that has a threshold of prevotes, and it is marked by drawing the letters PG and a round number off to the left of the block.
For example PG2 for the round two prevote ghost.
(Or optionally 👻2 if you are feeling artistic).

The Estimate
As you mark your prevote ghost, also mark your estimate on your own view to the left of the same block that is the prevote ghost with the letter E and a round number.
For example, E4 for round four's estimate.

A round's estimate is defined as the highest block that is in the chain of the prevote ghost that could possibly achieve a threshold of precommits. So while the estimate begins at the same block as the prevote ghost, it may move up the chain as more precommits come in.
Precommitting
Once you have marked a prevote ghost, you may, again, wait a short time for any more prevotes to come in. Once you get tired of waiting (or when you have seen all the prevotes), you may cast your precommit for the block that you see as the prevote ghost. Mark your precommit first on your own view and then on other players' views by writing the round number off to the right of the block and circling it. Precommits are distinguished from prevotes by the circle. Remember not all players will agree on which block is the prevote ghost, so others may precommit for blocks different than you have.

As you observe more precommits appearing on your view, your estimate may change. Specifically it may move up the chain to ancestor blocks.

GHI to achieve a threshold of precommits, and thus the estimate moves up the chain.Completing a Round
We will decide that some block is finalized in each round, although it may be a block that was already finalized in a previous round. We will only ever finalize an ancestor of the estimate. Once some ancestor of the estimate has achieved a threshold of precommits, you can declare that block finalized by shading it with your color on your view.

After a round has completed, you may choose to erase the votes for that round from your view to keep the board tidy. But you are not required to do so. Be careful not to erase votes for future rounds by accident as some players may have advanced to the next round before you.

Proceed to the next round.
Ending the Game
Grandpa is intended to continue finalizing blocks forever. Since you likely don't want to play this board game forever, the board game does have an end.
The honest players win when they all finalize the goal number of blocks chosen at the beginning without a safety violation.
The Byzantine players (if any; see next section) win when two honest players finalize conflicting blocks or the honest players get fed up and flip the whiteboard over.
Byzantine Actors
Once you have played a few rounds of the game and are able reliably finalize new blocks, you can spice things up by assigning one or more players to be Byzantine. Byzantine players are not required to follow the protocol rules. For example they may:
- Prevote for chains that do not extend the latest finalized chain
- Precommit for blocks other than the ones indicated by the prevote
- Go back and cast votes in previous rounds
- Fail to participate at all.
When first adding Byzantine players, you may assign the Byzantine roles such that everyone knows who is Byzantine. Or, for a more realistic experience, you may assign it blindly by eg drawing straws. Remember that in order for Grandpa to work you must have strictly less than one third of grandpa players Byzantine.
For the most realistic experience, allow players to self select whether they are Byzantine. By doing this there is no guarantee that the honest super majority criteria is met and you experience safety faults where different players finalize conflicting chains.
Designing DAG-based consensus
How to use the slides - Full screen (new tab)
Designing DAG-based consensus
Goals of this lecture
- formalize the consensus problem and related concepts
- provide a framework for designing DAG-based consensus protocols
What is consensus?
- a process of agreeing on the same result among a group of participants
- a fundamental problem in distributed computing
- a key component of blockchain technology stack
Consensus features
liveness, safety, integrity
We have already seen some
Nakamoto
Babe
Grandpa
Sassafras
Tendermint
...
Who is running the protocol?
Participants, called nodes
Nodes
- nodes can be either honest or malicious
- honest nodes follow the protocol
- malicious nodes can deviate from the protocol in any way they want
- malicious nodes can collude with each other
- malicious nodes can be controlled by an adversary
Public key infrastructure
- every node has its own private and public key
- every node signs messages with its private key
- every node verifies messages with other nodes' public keys
Public key infrastructure
authenticated point-to-point communication
Adversary
Adversary can control the network delays, but is computationally bounded, i.e. it cannot break the cryptography (like forging the signatures).
Network
Communication via network... but what kind of network?
Network models
synchronous
partially synchronous
asynchronous
Network models: synchronous
There exists a known upper bound \(\Delta\) on message delivery time.
Intuition: there's a well-defined notion of a protocol round
Network models: asynchronous
There is no upper bound on message delay, though delivery is guaranteed.
Intuition: you can't tell whether a node has crashed or has a long delay
Network models: asynchronous
There is no upper bound on message delay, though delivery is guaranteed.
- We assume that the adversary has full control over the message delays.
- The concept of a timeout is basically useless.
Network models: partially synchronous
There exists a known bound \(\Delta\), and an unknown point in time GST after which the communication becomes synchronous with a delay \(\Delta\).
Intuition: protocol will eventually work synchronously, but it needs to be safe before
Crucial theoretical results
[FLP theorem] It is impossible to have a deterministic protocol that solves consensus in an asynchronous system in which at least one process may fail by crashing.
[Castro-Liskov theorem] It is impossible to have a protocol that solves consensus in a partially synchronous system with \(3f+1\) nodes in which more than \(f\) processes are byzantine.
Crucial theoretical results
[FLP theorem] It is impossible to have a deterministic protocol that solves consensus in an asynchronous system in which at least one process may fail by crashing.
[Castro-Liskov theorem] It is impossible to have a protocol that solves consensus in a partially synchronous system with \(3f+1\) nodes in which more than \(f\) processes are byzantine.
Consequence
The best one can hope for in asynchronous scenario is probabilistic protocol tolerating up to \(f\) faults for \(3f+1\) participants.
✅ Doable!
Note on randomness
Real probability is actually needed in the extremely hostile environment. In case where the adversary is not legendarily vicious, even a dumb (but non-trivial) randomness source will do.
Responsiveness
Responsiveness
Protocols that are not responsive have to wait for \(\Delta\) time to proceed to the next round.
Responsiveness
Protocols that are not responsive have to wait for \(\Delta\) time to proceed to the next round.
- \(\Delta\) must be long enough to allow all honest nodes to send their messages.
- \(\Delta\) must be short enough to allow the protocol to make progress.
- In case of failure, they have to perform a pretty expensive recovery procedure (like the leader change).
Responsiveness
Protocols that are responsive wait for \(2f+1\) messages to proceed to the next round.
Why \(2f+1\)?
Responsiveness
Protocols that are responsive wait for \(2f+1\) messages to proceed to the next round.
Among \(2f+1\) nodes, there are at least \(f+1\) honest ones, i.e. honest majority.
Responsiveness
Protocols that are responsive wait for \(2f+1\) messages to proceed to the next round.
- Asynchronous protocols must be responsive.
- In good network conditions, they significantly much faster.
Checkpoint
Up to this point, we covered:
- consensus problem
- node types and adversary
- inter-node communication
- network models (synchronicity)
- protocol limitations in asynchronous network (honesty fraction and the need for randomness)
- responsiveness
Warmup exercise: broadcast
(In an asynchronous network) reliably send a single message to all other nodes.
- (validity) If the sender is honest and broadcasts a message \(m\), then every honest node outputs \(m\).
- (integrity) If an honest node outputs a message \(m\), then it must have been broadcast by the sender.
- (agreement) If an honest node outputs a message \(m\), every other honest node outputs \(m\).
Reliable broadcast protocol (RBC)

Reliable broadcast in practice
Due to the very high communication complexity we use heuristics or cryptography-based tricks.
Blockchain protocol vs Atomic broadcast
Atomic broadcast

Randomness formalized
Randomness beacon
Atomic broadcast: timeline

Atomic broadcast: timeline

Fun fact
Aleph paper, as the first, also achieved fully asynchronous randomness beacon:
- with efficient setup (\(O(1)\) rounds, \(O(N^2)\) communication)
- with \(O(1)\) expected rounds to output a random value with \(O(N)\) communication per round
Consensus protocols (selection)
Classical protocols:
- [DLS’88], [CR’92],
- PBFT [CL’99]
- Random Oracles … [CKS’05]
- Honey Badger BFT [MXCSS’16]
- Tendermint [BKM’18]
- VABA [AMS’19]
- Flexible BFT [MNR’19]
- HotStuff [YMRGA’19]
- Streamlet [CS’20]
- Grandpa [SKK'20]
DAG-based protocols:
- [L. Moser, P. Meliar-Smith ‘99]
- Hashgraph [B’16]
- Aleph [GLSS’18]
- DAG-Rider [KKNS’21]
- Highway [KFGS’21]
- Narwhal&Tusk [DKSS’22]
- Bullshark [SGSK’22]
DAG-based protocols
DAG
Directed Acyclic Graph

How does it relate to consensus?
Intuition: graph represents the dependencies between messages (units).

Framework core
- We maintain a local DAG representing our knowledge of the units.
- We perform a local, offline consensus on our DAG.
Framework core
- We maintain a local DAG representing our knowledge of the units.
- We perform a local, offline consensus on our DAG.
Framework core (in other words)
- (online): sending and receiving units that contribute to the local DAG
- (offline): everybody performs a local consensus on the DAG, just by looking at it
Clue observations
- local DAGs might differ...
- but they are guaranteed to converge to the same DAG
- the offline consensus is guaranteed to produce the same result
Adversary control

Randomness? Where is randomness?
It is put into the local consensus protocol.
Relation to the atomic consensus problem
- nodes receive transactions and put them into units
- nodes send each other their new units
- (locally) nodes come up with a linear ordering of the units and make blocks from chunks
Digression: block production, information dissemination and finalization
The common approach (e.g. in Substrate):
- production and dissemination is done in the same layer
- afterwards, nodes perform consensus on finalizing disseminated blocks
Natural approach for DAG-based protocols:
- information dissemination happens as 'the first phase'
- block building and (instant) finalization happens locally
Main consequences of the different separation
- block signatures
- speed
Local consensus: goal
Local copies might differ significantly, blocks might have not come to all nodes yet, etc... but we have to make common decision about unit ordering!
Key concept: availability
Intuitively, a unit is available if:
- most of the nodes have it
- it was distributed pretty promptly (we won't call a unit available, if it finally arrived everywhere after a month)
- most of the nodes know that most of the nodes know that most of the nodes know... that it is available (mutual awareness)
Availability
If a unit is available, it is a good candidate for being chosen as an 'anchor' in extending current ordering.
Lightweight case study
Aleph Zero BFT protocol
Head

Building blocks

Choosing head

Availability determination
Units vote for each other's availability.
(Part of) availability determination
VoteU(V) =
- [[U is parent of V]] if V is from the round just after the round of U
0/1if all children of U voted0/1CommonVote(round(U), round(V))otherwise
(U comes from the earlier round than V)
Bonus: generating randomness
Sig sk(nonce)
- randomness must be unpredictable
- delayed reveal
- must depend on \(f+1\) nodes
- cannot be disturbed by the adversary
Standard way

Standard way

Problem: need for trusted dealer!
One simple trick
Everybody is dealing secrets
Combining randomness

Accounting Models & User Abstractions in Blockchains
How to use the slides - Full screen (new tab)
Accounting Models & User Abstractions in Blockchains
Overview
- Cryptography, Signatures, Hash functions, Hash based Data Structures
- Economics/Game Theory
- Blockchain structure
Where do we go from here?
- We have some base elements, ideas, and concepts
- Now, let's put them together into something cool..
What are we talking about?
- Now that we have this structured decentralized tamper proof state machine..
- Let's think of ways we can formulate a state and a state transition in terms of representing users

State User Model

State User Model

How to represent Joshy and Andrew?
User Representation

How to send from Joshy to Andrew? What do you need?

Notes:
What would be catastrophic if we got wrong??
What if we want to spend this?

Notes:
Why do we say spend here and not modify?
Input
Transaction
Notes:
Why do we not send all of the 70 to Andrew?
How to verify this state change is valid?
- We can actually spend this thing signature verification!
- Sum of the inputs is >= sum of the outputs
- No coins are worth 0
- Has this already been spent before?
Notes:
Which did I forget??
Our new state

How do we generalize beyond money?

How do we generalize beyond money?

Notes:
How are we going to verify now that the state transition is valid?
Transaction
Transaction
Is this a good model? Why or why not? Let's discuss
- Scalability
- Privacy
- General Computation
Is there a different way?
Notes:
Now ease them to the solution of Accounts
Accounts

Notes:
Now ease them to the solution of Accounts
State Transition Accounts
State Transition Accounts
How do we verify and handle this transaction?
- Verify enough funds are in Joshy's account
- Verify this amount + Andrews amount don't exceed the max value
- Check the nonce of the transaction
- Do the actual computation of output values
Notes:
Did I forget any?
State Transition Accounts
What did we do differently in Accounts vs UTXO model?
Notes:" />
Verify as opposed to determining the outcome. Not submitting output state in transaction
Account Arbitrary Data

Is this a good model? Why or why not? Lets Discuss
- Scalability
- Privacy
- General Computation
Notes:
Parallelization? Storage space, privacy solutions?
Small shill... Tuxedo 👔
Questions
Adding Privacy to the UTXO model
How to use the slides - Full screen (new tab)
Adding Privacy to the UTXO model
Input/Output-based Cryptocurrencies
- Transactions have a list of unspent transaction outputs (UTXOs) as its inputs
- Each input is signed
- The transaction is allowed to spend as much funds as the sum of its inputs
- The transaction spends funds by creating outputs and by paying a fee
Input/Output-based Cryptocurrencies
- Inputs must only refer to actually existing outputs (membership)
- The output spent must not be prior spent (linkability)
- The output's owner must consent to this transaction (ownership)
- The transaction's inputs and outputs must be balanced (sum check)
Bitcoin
- Bitcoin specifies the spent output. This satisfies membership and linkability
- Each Bitcoin output has a small, non-Turing complete program (Script) specifying how it can be spent
- Each input has a
scriptSigwhich proves the script is satisfied and this is an authorized spend (ownership) - The outputs cannot exceed the inputs, and the remainder becomes the fee (sum check)
ZK Proofs
- ZK-SNARKs - A small proof that's fast to verify (<= $O(\sqrt{n})$)
- ZK-sNARKs - A small proof that's not fast to verify (>= $O(n)$, frequently $O(n log n)$)
- ZK-STARKs - A small proof that's fast to verify, based on hash functions
- All of these can prove the execution of an arbitrary program (via an arithmetic circuit)
- None of these reveal anything about the arguments to the program
Merkle Proofs
- Merkle proofs support logarithmically proving an item exists in a tree
- For 2**20 items, the proof only requires 20 steps
- Even if a ZK proof is superlinear, it's a superlinear encoding of a logarithmic solution
Private Membership
- When an output is created on-chain, add it to the Merkle tree
- When an input specifies an output, it directly includes the output it's spending
- It also includes a Merkle proof the output exists somewhere on chain, embedded in a ZK proof
Pedersen Commitments
- A Pedersen commitment has a value (some number) and a mask (also some number)
- There's as many masks as there private keys, hiding the contained value
- Pedersen commitments can be extended to support multiple values
A New Output Definition
- ID
- Amount
- Owner
- Mask
- All in a single
Pedersen commitment
Private Membership
- We don't prove the included output exists on chain
- We prove an output with identical fields exists on chain yet with a different mask
- This allows spending a specific output without revealing which it is
Ownership and linkability
- A ZK proof can take the output ID and apply some transformation
- For every output ID, the transformation should output a single, unique ID
- Not just anyone should be able to perform this transformation
- This provides linkability, and if only the owner can perform the transformation, ownership
Sum check
- One final ZK proof can demonstrate the sum of inputs - the sum of outputs = fee
- There are much more efficient ways to prove this
Summary
- This hides the output being spent and the amounts transacted
- Combined with a stealth address protocol, which replaces addresses with one time keys, it hides who you're sending to as well
- This builds a currency which is private w.r.t. its on-chain transactions
Light Clients and Bridges
How to use the slides - Full screen (new tab)
Light Clients

What can I say?It's a client but light.
😢 Running a Node is Hard 😭
Ideally:
- Everyone runs their own node.
- It takes a lot of disk, memory, etc
- It takes some know-how
- I don't need it all the time
Notes:
The bitcoin whitepaper clearly assumes that users will run their own nodes. This is the most trustless and decentralized way to operate, and you should do it whenever you can. If you think you can't you're probably wrong. Just ask the Monero community.
There are some reasons not to run a full node and the reality is that not everyone will. So even though we should always run our own nodes, let's look at some alternatives and ways we can make node running more accessible.
---v
RPC Nodes
AKA, trust somebody else's node.
- 🕵️ Spy on you (like infura).
- 🔞 Censor you
- 🤥 Lie to you
- 💔 Steal your boyfriend
Notes:
The easiest thing to do is just trust some expert to run a node for you. Very web2. Lot's of things can go wrong.
So this is definitely not the best option. Let's see if we can do better.
---v
Lighten the Load
For resource constrained systems and people in a hurry
- Phone
- Raspberry pi
- Microcontroller
- Inside Web Browser
Notes:
One of the complaints was that the node takes too much resources. This is especially true if we want people to be able to run the node in all kinds of exotic environments. And we do want that because we want people to run their own node even when they're just paying the bill at dinner from their phone or liking social posts while scrolling on the bus. Let's make the client lighter so it doesn't require as much resources.
---v
Light Client Duties
- ❌ Sync blocks
- ❌ Execute blocks
- ✅ Sync headers
- ❔ Maintain Transaction Pool
- ✅ Checks consensus
- ❌ Maintains state
Notes:
This is what a typical light client does. There is not a single definition of light client. There are varying degrees of lightness to suit your needs.
---v
Trustless
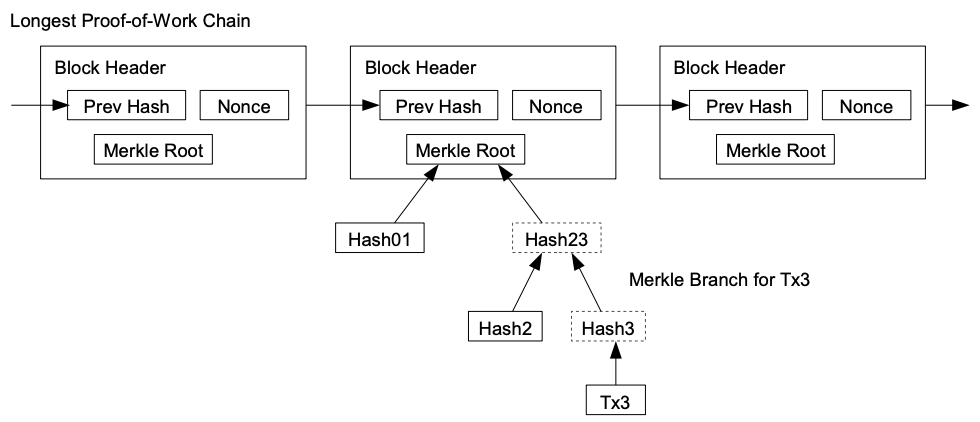
- Relies on full node for data
- Does not have to trust data
- State root helps a lot
Notes:
The figure is from the Bitcoin whitepaper. The concept of light clients has been around since bitcoin. At that time it was known as Simplified Payment Verification. You could confirm that a payment was sent or received. But you couldn't confirm that the tokens in question still existed or anything else about the state.
Chains with state roots can have much more powerful light clients
---v
Syncing Strategies
- Full header sync
- Checkpoints in code
- Warp sync
Notes:
We also need to address the use case of clients that are not always on. For example if you only need your node on your phone, or when using a specific web page, that means it will have some syncing to do.
Doing a full sync is already a lot faster than on a full client because you aren't downloading or executing the blocks. But by the time you have a few million headers, it does still take some time.
The naive solution is to just have relatively recent headers hard-coded in the client. This works pretty well. You already have to trust the client developers for the entire implementation so you aren't trusting a new party at least.
Warp sync is possible when you have deterministic finality. In dead simple PoA you just check that the authorities have signed the latest block and you are good. If you have authority hand-offs, there is more work to be done. You have to check that each authority set signs the transition to the next authority set. But this is still only even N blocks instead of every block.
---v
Self Defense
Stay in the gossip protocol or you might get got.

Notes:
In the main gossip protocol, if authorities finalize two conflicting blocks, then we can prove that they have broken the rules and slash them. If we don't watch the gossip and only peer with a single full node, then our view is entirely defined by that node. They may gossip us an attack chain and we won't know. So it is important to communicate with many different full nodes.
Bridges
Transport layers between independent consensus systems

Notes:
Generally speaking bridges move arbitrary data between unrelated consensus systems. Basically between different blockchains, and those messages can evoke arbitrary side effects on the target chain. To keep it concrete, we'll mostly talk about moving tokens.
---v
Source and Target Chain

Notes:
By convention we speak of bridges as being one-directional. When we talk about trustless bridge design this is a core concept in the design. It is less critical but still useful for trusted bridges.
A two-way bridge is really just two one-way bridge. Think of a two-way street. There is a dedicated lane for each direction.
---v
Source Chain Re-Orgs
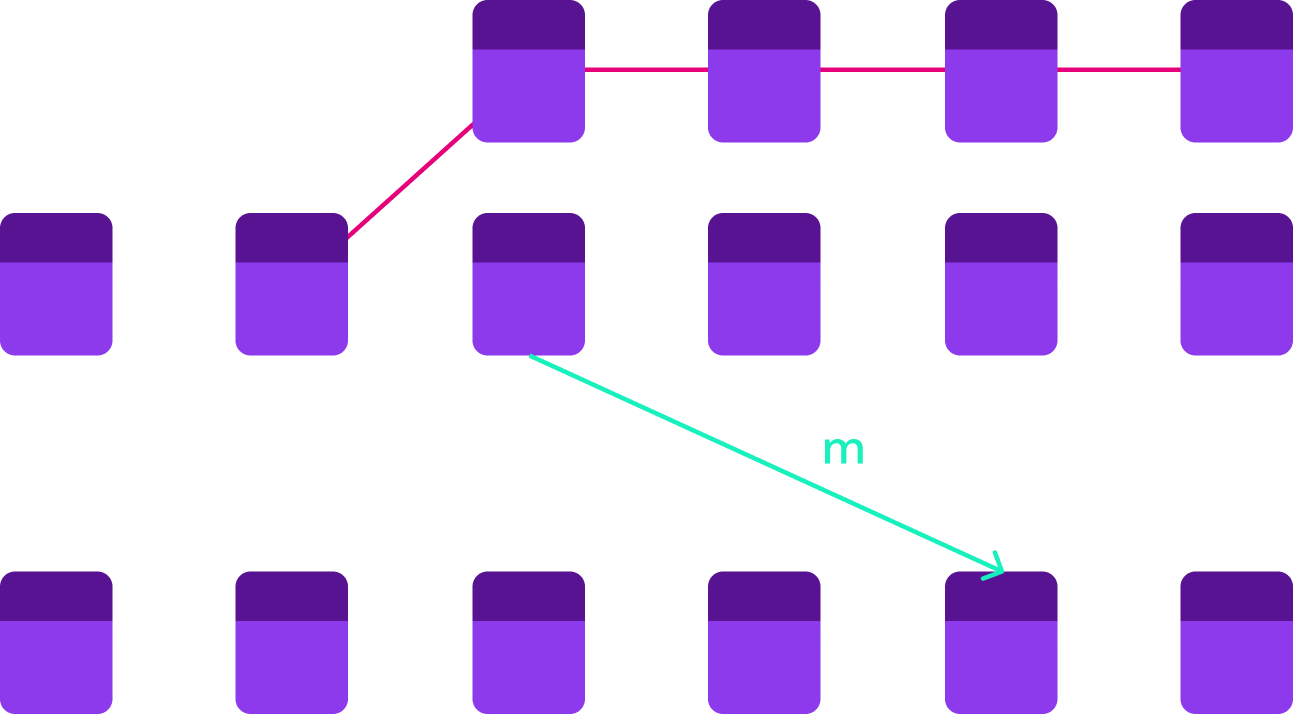
Notes:
On PoW chains this is truly just a judgement call and a prayer. If the source chain has deterministic finality we can do better. We need to wait for finality. But even this isn't foolproof. More on this after we cover the basic design.
---v
Bridge Models
Trust-based
Trusted intermediary makes a transfer manually.
Eg. Wrapped bitcoin on ethereum (WBTC)
Trustless
Trustless is the goal,
like almost everything in web3.
Notes:
The trust based bridges are not at all ideal. You have to entirely trust an intermediary. You send the intermediary tokens on the source chain. Once the intermediary is satisfied that they really own the source tokens, they send you some target tokens on the target chain. Or they don't whatever, not their problem.
You can make they trust properties slightly better by using a multisig or a group of people so you only have to trust some subset of them. But this does not fundamentally eliminate the trust agreement. One classic example is the WBTC foundation. You send them bitcoin, they wait for "enough" block confirmations, and then they mint you an ERC20 token on Ethereum. And they provide the same service in reverse too.
A lot of the trusted bridge design can be improved and we'll talk about that in detail in the next few slides. But it's worth observing here that we will never be able to eliminate the part about "Once the intermediary is satisfied that they really own the source tokens". The bridge can never be stronger than the consensus on the source chain
Trustless bridge design
- Most trustless way to interact with blockchain
is to run a node - This is true for individuals and other blockchains
- A blockchain is extremely resource constrained.
- Run a source chain light client on the target chain
Notes:
---v
BTC Relay

Bridge Design Challenges

Notes:
Bridges present their own set of design challenges beyond what we encounter in regular stand-alone light clients.
---v
Peers?
- How can we peer without networking?
- Enter the Relayer - a permissionless and trustless role
- Need at least one honest relayer
Notes:
On-chain logic doesn't have network IO, so how do we peer? There is a role known as a relayer. It is an off-chain agent who watches the source chain, and submits headers and finality proofs from the source chain to the target chain through transactions. Anyone can start a relayer. It is typically a little piece of software that you run. But there is nothing magic about it. You could perform the relayer task manually by copying header data from an explorer into metamask for example.
You do need at least one honest relayer for the chain to get the correct header info. For this reason a large decentralized relayer group is nice. But even if you don't trust any relayer out there, you can always run your own.
---v
Finality and Equivocation


Notes:
It is not safe to accept headers as finalized immediately even if there is a deterministic finality proof. Let that sink in. Even if there is a valid finality proof, it is not safe to accept them as finalized. Why not?
Because the validators may be equivocating. They don't send equivocations to real nodes on the network because those equivocations will be gossiped around and reported on the source chain and the validators will be slashed accordingly. But remember a light client on the target chain has no way to report such equivocations back to the source chain.
---v
Equivocation Incentives
- Add a Challenge Period and
- Add Fishermen - reverse of relayers
OR
- Stake Relayers so they can be slashed
Notes:
There are basically two classes of solutions. Both of them require a waiting period aka challenge period before accepting a header with a finality proof as final.
One is to add a role of fishermen. They are responsible for noticing when the header candidate on the target chain is different from the one in the main source chain protocol and reporting this behavior back to the source chain so the validators can be slashed there. Two problems:
- Fishermen have weak incentives. If they do a good job there will be no equivocations and they will not get paid.
- Target chain is relying on the foreign source chain to keep the bridge secure instead of owning that security itself.
The other is to have the relayer role require a security deposit. If it turns out that a relayer relays an attack header, that relayer is slashed and the relayer who reports it gets a reward. Relayers will expect to earn some reward for the opportunity cost of their stake which makes the bridge operation more expensive.
Multichain Apps

---v
We have a header, now what?
- App users submit proofs
- Need a source chain transaction?
Submit an spv-style transaction proof - Need some source chain state?
Submit a state proof
Notes:
The header sync is just the foundation. Now Applications can build on top of it with the best possible trust guarantees.
If you need some source chain transaction, your app needs to require an spv-style transaction proof to check against the header's extrinsics root.
If you need some source chain state, your app needs to require a state proof to check against the header's state root.
---v
Multichain Security

Notes:
This kind of trustless bridge with proper incentives gets us information about the source chain to the target chain with security about as high as it was on the source chain. If you are building an app that spans multiple chains consider the security guarantees on both chains. The weaker security of the two is the security your app has. More abstractly, your app consumes two different kinds of blockspace that may be of different qualities. Your app is only as quality as the lower of the blockspaces.
---v
Example: Depository Mint Model
- Send tokens to a contract on source chain
- Message is relayed to destination chain
- Offchain relay and transaction
- XCM
- "Somehow"
- New "wrapped" tokens are minted on the destination chain
Notes:
The same process works in reverse to get the original tokens back. This can get get complex when there are multiple bridges. Are their wrapped tokens interchangeable? What if one of the bridges gets hacked?
EVM, Solidity, and Vyper
How to use the slides - Full screen (new tab)
EVM, Solidity, and Vyper
EVM
Ethereum Virtual Machine
A VM designed specifically for the constraints and features of Ethereum
EVM Properties
- Deterministic: execution outcome easy to agree upon
- Spam-resistant: CPU and other resources are metered at a very granular level
- Turing-complete (with a caveat)
- Stack-based design
- Ethereum-specific (EVM can query block hash, accounts and balances, etc.)
Notes:
It is critical that the EVM be 100% deterministic and that each implementation produce the same outcome. Even the smallest discrepancy between two running nodes would lead to different block hashes, violating consensus about the results.
History of Ethereum
- Nov 2013: Vitalik released WP
- Apr 2014: Gav released YP
- July 2014: $18M raised (ICO lasted 42 days)
- July 2015: Frontier released -- bare bones, Proof of Work
- Sept 2015: Frontier "thawed", difficulty bomb introduced
- July 2016: DAO Fork
- 2016-2019: Optimizations, opcode cost tuning, difficulty bomb delays
- 2020: Staking contract deployed, Beacon Chain launched
- 2021: EIP-1559, prep for The Merge
- 2022: The Merge (Proof of Stake)
- 2023: Staking withdraw support
---v
DAO Hack
- 2016: raised $150M worth of ETH
- Later that year: 3.6M ETH drained
- Reentrancy attack
- "Mainnet" Ethereum forks to retroactively undo hack
- Ethereum Classic: code is law
Notes:
A DAO ("Decentralized Autonomous Organization") is much like a business entity run by code rather than by humans. Like any other business entity, it has assets and can carry out operations, but its legal status is unclear.
The earliest DAO ("The DAO") on Ethereum suffered a catastrophic hack due to a bug in its code. The DAO community disagreed on whether or not to hard-fork and revert the hack, resulting in Ethereum splitting into two different chains.
---v
The first smart contracting platform
Ethereum has faced many challenges as the pioneer of smart contracts.
- Performance: Underpriced opcodes have been attacked as a spam or DoS vector
- High gas fees: Overwhelming demand low block-space supply
- Frontrunning: Inserting transactions before, after, or in place of others in order to economically benefit
- Hacks: Many hacks have exploited smart contract vulnerabilities
- Problems with aggregating smart contract protocols together
- Storage bloat: Misaligned incentives with burden of storage
---v
Idiosyncrasies
- Everything is 256bits
- No floating point arithmetic
- Revert
- Reentrancy
- Exponential memory expansion cost
Gas
Turing completeness and the Halting Problem
-
EVM: Turing-complete instruction set
-
But what about the Halting Problem?
-
Obviously cannot allow infinite loops
-
Solution: Gasometer, a way to pre-pay for each opcode execution
Notes:
The Halting Problem tells us that it's not possible to know that an arbitrary program will properly stop. To prevent such abuse, we check that there is gas remaining before every single opcode execution. Since gas is limited, this ensures that no EVM execution will run forever and that all work performed is properly paid for.
---v
Gasometer
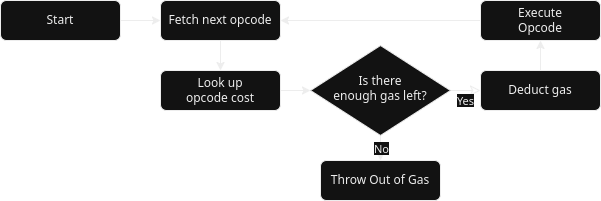
- Checks before each opcode to make sure gas can be paid
- Safe: prevents unpaid work from being done
- Deterministic: results are unambiguous
- Very inefficient: lots of branching and extra work
Notes:
This not only makes it possible to prevent abuse, but crucially allows nodes to agree on doing so. A centralized service could easily impose a time limit, but decentralized nodes wouldn't be able to agree on the outcome of such a limit (or trust each other).
---v
Gas limits and prices
Gas: unit of account for EVM execution resources.
gas_limit: specifies the maximum amount of gas a txn can paygas_price: specifies the exact price a txn will pay per gas
A txn must be able to pay gas_limit * gas_price in order to be valid.
Notes:
This amount is initially deducted from the txn's sender account and any remaining gas is refunded after the txn has executed.
---v
EIP-1559
An improvement to gas pricing mechanism.
gas_price --> max_base_fee_per_gas
\-> max_priority_fee_per_gas
- Separates tip from gas price
base_feeis an algorithmic gas price, this is exactly what is paid and is burned- ...plus maybe tip if (
base_fee < max_base_fee + max_priority_fee) - Algorithmic, congestion-based multiplier controls
base_fee
Notes:
https://eips.ethereum.org/EIPS/eip-1559 Introduced in London hard-fork.
---v
OOG and Gas Estimation
If a txn exhausts its gas_limit without finishing, it will produce an OOG (out-of-gas) error and all changes made in the EVM are reverted (except for fee payment).
In order to estimate the amount of gas a txn will need, an RPC method (eth_estimateGas) can perform a dry-run of the txn and record the amount used.
However, there are a few caveats:
- Run against current state (state may change)
- The RPC node could lie to you
- This is expensive infrastructure overhead and can be a spam vector
Account Types
There are two types of Ethereum accounts. Both use 160-bit account IDs and can hold and send Ether, but they are controlled very differently.
---v
Account Types
Externally-owned Account (EOA)
- Traditional user-controlled account
- Controlled via private keys
- Account ID generated by hashing public key
- Uses an incrementing nonce to prevent replay attacks
Contract Account
- Controlled by immutable bytecode
- May only ever do precisely what the code specifies
- Account ID generated deterministically when bytecode is deployed
Transactions
A transaction is a signed payload from an EoA which contains details about what the transaction should do and how it will pay for itself.
---v
Transactions fields:
- value: 0 or more Ether to send with the txn
- to: the target of this transaction
- input: Optional input data for creating or calling a contract
- gas_limit: Max gas the txn will pay
- gas_price: (or EIP-1559 equivalent)
- nonce: prevents replay attacks and forces ordering
- signature: proves ownership of private keys, allows receiving Account ID
- there can be more
---v
Possible use-cases:
- Call a contract's external function (
inputspecifies function and arguments) - Create a contract (
inputspecifies contract's bytecode) - Neither (
inputempty)
In all cases, Ether can be sent (Neither being a normal Ether send).
---v
Transaction Validity
Before executing (or gossiping) txns, some validity checks should be run:
- Is the
gas_limitsufficient? (21_000minimum at least pays for processing) - Is the signature valid? (Side effect: public key recovered)
- Can the account pay for
gas_limit * gas_price? - Is this a valid (and reasonable) nonce for the account?
Notes:
These checks come with overhead, so it's important to discard invalid txns as quickly as possible if it is invalid. This includes not gossiping it to peers, who have to also verify it.
Opcodes and Bytecode
An opcode is a single byte which represents an instruction for the VM to execute.
The EVM executes bytecode one opcode at a time until it is done, explicitly halts, or the gasometer runs out of gas.
Notes:
Functions compile down into a sequence of opcodes, which we call bytecode. This bytecode is bundled together and becomes the on-chain contract code.
ABI
ABI ("Application Binary Interface") describes the bytecode for a contract by annotating where functions and other objects exist and how they are formatted.
---v
Exercise
Review this Contract Code on Etherscan
---v
Sandboxed Contract State
Contract Accounts contain a sandboxed state, which stores everything that the
contract writes to storage.
Contracts may not write to storage outside of their own sandbox, but they can call other contracts whose bytecode might write to their respective storage.
---v
Calling Contracts
Contract functions can be invoked in two ways different ways:
- EoAs can call a contract functions directly
- Contracts can call other contracts (called "messaging")
---v
Types of contract messaging
- Normal
call: Another contract is called and can change its own state staticcall: A "safe" way to call another contract with no state changesdelegatecall: A way to call another contract but modify our state instead
Notes:
Transactions are the only means through which state changes happen.
---v
Message Object
Within the context of a contract call, we always have the msg object, which lets us know how we were called.
msg.data (bytes): complete calldata (input data) of call
msg.gas (uint256): available gas
msg.sender (address): sender of the current message
msg.sig (bytes4) first 4 bytes of calldata (function signature)
msg.value (uint256) amount of Ether sent with this call
---v
Ether Denominations
Ether is stored and operated on through integer math.
In order to avoid the complication of decimal math, it's stored as a very small integer: Wei.
1 Ether = 1_000_000_000_000_000_000 Wei (10^18)
Notes:
Integer math with such insignificant units mostly avoids truncation issues and makes it easy to agree on outcomes.
---v
Named Denominations
Other denominations have been officially named, but aren't as often used:
wei = 1 wei
kwei (babbage) = 1_000 wei
mwei (lovelace) = 1_000_000 wei
gwei (shannon) = 1_000_000_000 wei
microether (szabo) = 1_000_000_000_000 wei
milliether (finney) = 1_000_000_000_000_000 wei
ether = 1_000_000_000_000_000_000 wei
gwei is often used when talking about gas.
Programming the EVM
The EVM is ultimately programmed by creating bytecode. While it is possible to write bytecode by hand or through low-level assembly language, it is much more practical to use a higher-level language. We will look at two in particular:
- Solidity
- Vyper
Solidity
- Designed for EVM
- Similar to C++, Java, etc.
- Includes inheritance (including MI)
- Criticized for being difficult to reason about security
---v
Basics
// 'contract' is analogous to 'class' in other OO languages
contract Foo {
// the member variables of a contract are stored on-chain
public uint bar;
constructor(uint value) {
bar = value;
}
}
---v
Functions
contract Foo {
function doSomething() public returns (bool) {
return true;
}
}
---v
Modifiers
A special function that can be run as a precondition for other functions
contract Foo {
address deployer;
constructor() {
deployer = msg.sender;
}
// ensures that only the contract deployer can call a given function
modifier onlyDeployer {
require(msg.sender == deployer);
_; // the original function is inserted here
}
function doSomeAdminThing() public onlyDeployer() {
// this function can only be called if onlyDeployer() passes
}
}
Notes:
Although Modifiers can be an elegant way to require preconditions, they can do entirely arbitrary things, and auditing code requires carefully reading them.
---v
Payable
contract Foo {
uint256 received;
// this function can be called with value (Ether) given to it.
// in this simple example, the contract would never do anything with
// the Ether (effectively meaning it would be lost), but it will faithfully
// track the amount paid to it
function deposit() public payable {
received += msg.value;
}
}
Notes:
The actual payment accounting is handled by the EVM automatically, we don't need to update our own account balance.
---v
Types: "Value" Types
contract Foo {
// Value types are stored in-place in memory and require
// a full copy during assignment.
function valueTypes() public {
bool b = false;
// signed and unsigned ints
int32 i = -1;
int256 i2 = -10000;
uint8 u1 = 255;
uint16 u2 = 10000;
uint256 u3 = 99999999999999;
// fixed length byte sequence (from 1 to 32 bytes)
// many bitwise operators can be performed on these
bytes1 oneByte = 0x01;
// address represents a 20-byte Ethereum address
address a = 0x1010101010101010101010101010101010101010;
uint256 balance = a.balance;
// also: Enums
// each variable is an independent copy
int x = 1;
int y = x;
y = 2;
require(x == 1);
require(y == 2);
}
}
---v
Types: "Reference" Types
contract Foo {
mapping(uint => uint) forLater;
// Reference types are stored as a reference to some other location.
// Only their reference must be copied during assignment.
function referenceTypes() public {
// arrays
uint8[3] memory arr = [1, 2, 3];
// mapping: can only be initialized from state variables
mapping(uint => uint) storage balances = forLater;
balances[0] = 500;
// dynamic length strings
string memory foo = "<3 Solidity";
// also: Structs
// Two or more variables can share a reference, so be careful!
uint8[3] memory arr2 = arr;
arr2[0] = 42;
require(arr2[0] == 42);
require(arr[0] == 42); // arr and arr2 are the same thing, so mod to one affects the other
}
}
---v
Data Location
Data Location refers to the storage of Reference Types.
As these are passed by reference, it effectively dictates where this reference points to.
It can be one of 3 places:
- memory: Stored only in memory; cannot outlive a given external function call
- storage: Stored in the contract's permanent on-chain storage
- calldata: read-only data, using this can avoid copies
---v
Data Location Sample
contract DataLocationSample {
struct Foo {
int i;
}
Foo storedFoo;
// Data Location specifiers affect function arguments and return values...
function test(Foo memory val) public returns (Foo memory) {
// ...and also variables within a function
Foo memory copy = val;
// storage variables must be assigned before use.
Foo storage fooFromStorage = storedFoo;
fooFromStorage.i = 1;
require(storedFoo.i == 1, "writes to storage variables affect storage");
// memory variables can be initialized from storage variables
// (but not the other way around)
copy = fooFromStorage;
// but they are an independent copy
copy.i = 2;
require(copy.i == 2);
require(storedFoo.i == 1, "writes to memory variables cannot affect storage");
return fooFromStorage;
}
}
---v
Enums
contract Foo {
enum Suite {
Hearts,
Diamonds,
Clubs,
Spades
}
function getHeartsSuite() public returns (Suite) {
Suite hearts = Suite.Hearts;
return hearts;
}
}
---v
Structs
contract Foo {
struct Ballot {
uint32 index;
string name;
}
function makeSomeBallot() public returns (Ballot memory) {
Ballot memory ballot;
ballot.index = 1;
ballot.name = "John Doe";
return ballot;
}
}
Solidity Hands-On
---v
Dev Environment
We will use the online Remix IDE for our sample coding. It provides an editor, compiler, EVM, and debugger all within the browser, making it trivial to get started.
---v
Flipper Example
Code along and explain as you go
---v
Exercise: Multiplier
- Write a contract which has a
uint256storage value - Write function(s) to multiply it with a user-specified value
- Interact with it: can you force an overflow?
Overflow checks have been added to Solidity. You can disable these by specifying an older compiler. Add this to the very top of your
.solfile:pragma solidity ^0.7.0;
---v
Bonus:
- Prevent your multiplier function from overflowing
- Rewrite this prevention as a
modifier noOverflow()
The constant
constant public MAX_INT_HEX = 0xffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff;may be helpful.
Vyper
- Also designed for the EVM
- Similar to Python
- Intentionally lacks some features such as inheritance
- Auditable: "Simplicity for the reader is more important than simplicity for the writer"
---v
Compared to Solidity
Vyper mostly lacks features found in Solidity, all in the spirit of improving readability. Some examples:
- No Inheritance
- No modifiers
- No function overloading
- No recursive calling (!)
- No infinite-loops
---v
Basics
# There is no `contract` keyword.
# Like Python Modules, a contract is implicitly
# scoped by the file in which it is found.
# storage variables are declared outside of any function
bar: uint
# init is used to deploy a contract and initialize its state
@external
def __init__(val):
self.bar = val
---v
Functions
@external
def doSomething() -> bool:
return True
---v
Decorators and Payable
# Vyper contains decorators for restricting functions:
@external # function can only be called externally
@internal # function can only be called within current context
@pure # cannot read state or environment vars
@view # cannot alter contract state
@payable # function may receive Ether
# also, to cover the most common use case for Solidity's modifiers:
@nonreentrant(<unique_key>) # prevents reentrancy for given id
Notes:
source: https://docs.vyperlang.org/en/stable/control-structures.html#decorators-reference
---v
Types
# value types are small and/or fixed size and are copied
@external
def valueTypes():
b: bool = False
# signed and unsigned ints
i: int128 = -1
i2: int256 = -10000
u: uint128 = 42
u2: uint256 = 42
# fixed-point (base-10) decimal values with 10 decimal points of precision
# this has the advantage that literals can be precisely expressed
f: decimal = 0.1 + 0.3 + 0.6
assert f == 1.0, "decimal literals are precise!"
# address type for 20-byte Ethereum addresses
a: address = 0x1010101010101010101010101010101010101010
b = a.balance
# fixed size byte arrays
selector: bytes4 = 0x12345678
# bounded byte arrays
bytes: Bytes[123] = b"\x01"
# dynamic-length, fixed-bounds strings
name: String[16] = "Vyper"
# reference types are potentially large and/or dynamically sized.
# they are copied-by-reference
@external
def referenceTypes():
# fixed size list.
# It can also be multidimensional.
# all elements must be initialized
list: int128[4] = [1, 2, 3, -4]
# bounded, dynamic-size array.
# these have a max size but initialize to empty
dynArray: DynArray[int128, 3]
dynArray.append(1)
dynArray.append(5)
val: int128 = dynArray.pop() # == 5
map: HashMap[int128, int128]
map[0] = 0
map[1] = 10
map[2] = 20
---v
Enums
enum Suite {
Hearts,
Diamonds,
Clubs,
Spades
}
# "hearts" would be considered a value type
hearts: Suite = Suite.Hearts
---v
Structs
struct Ballot:
index: uint256
name: string
# "someBallot" would be considered a reference type
someBallot: Ballot = Ballot({index: 1, name: "John Doe"})
name: string = someBallot.name
Vyper Hands-On
---v
Remix Plugin
Remix supports Vyper through a plugin, which can be easily enabled from within the IDE. First, search for "Vyper" in the plugins tab:
---v
Remix Plugin
Use Vyper through the new Vyper tab and use "Remote Compiler"
Reentrancy
The DAO Vulnerability
function withdraw() public {
// Check user's balance
require(
balances[msg.sender] >= 1 ether,
"Insufficient funds.
Cannot withdraw"
);
uint256 bal = balances[msg.sender];
// Withdraw user's balance
(bool sent, ) = msg.sender.call{value: bal}("");
require(sent, "Failed to withdraw sender's balance");
// Update user's balance.
balances[msg.sender] = 0;
}
We make a call to withdraw user's balance before updating our internal state.
---v
How can this be avoided?
- Commit state BEFORE contract call
- Modifier that prevents reentrancy (Solidity)
@nonreentrantdecorator (Vyper)
Storing Secrets On-Chain
Can we store secrets on-chain?
What if we want to password-protect a particular contract call?
Obviously we can't store any plaintext secrets on-chain, as doing so reveals them.
---v
Storing Hashed Secrets On-Chain
What about storing the hash of a password on chain and using this to verify some user-input?
Accepting a pre-hash also reveals the secret. This reveal may occur in a txn before it is executed and settled, allowing someone to frontrun it.
---v
Verifying with commit-reveal
One potential solution is a commit-reveal scheme where we hash our reveal with some salt, then later reveal it.
// stored on-chain:
secret_hash = hash(secret)
// first txn, this must execute and settle on chain before the final reveal.
// this associates a user with the soon-to-be-revealed secret
commitment = hash(salt, alleged_secret)
// final reveal, this must not be made public until commitment is recorded
reveal = alleged_secret, salt
verify(alleged_secret == secret)
verify(commitment == hash(salt, alleged_secret))
---v
Alternative: Signature
Another approach is to use public-key cryptography. We can store the public key of some key pair and then demand a signature from the corresponding private-key.
This can be expanded with multisig schemes and similar.
How does this differ from the commit-reveal scheme?
Notes:
Commit-reveal requires that a specific secret be revealed at some point for verification. A signature scheme provides a lot more flexibility for keeping the secret(s) secure.
Contract Workshop
Web2 digital cash example.
📥 Clone to start: Contract Workshop
See the README included in the repository for further instructions.
Start Your Own Blockchain
In this activity, you will get hands on experience operating a blockchain node and seeing it interact with other blockchain nodes.
📥 Clone to start: Academy PoW Node
See the README included in the repository for further instructions.
Learning objectives:
- How to run a node
- What the log messages mean
- Preview: How to configure a network with a chain spec
- Experience peer connections coming and going
- Practice checking for common not-peering issues (different genesis, firewall)
Outline
Clone & Compile
⏰ Because the compile time is quite long, this should be done in advance of class.
Ideally, compilation will be given to you as as homework on the day before to run (at worst) over night. The faculty may also have a docker image ready to go, please request this if needed.
Generate User Keys
With Polkadot JS
Get Tokens
You request tokens from the teacher by sharing your address with the teachers in a public channel. After the first five you have tokens, we pass them on to your peers. This manual approach allows you to get familiar with sending and receiving tokens in your wallet.
Optionally, we may install a faucet or UBI pallet in the chain to allow you to self service after the initial manual distribution.
Optional Treasure Hunt
You could have tokens stored at eg the Alice key or other leaked keys and challenge you to find and recover the tokens. Make up a story/myth about some mysterious figure who lost your key and left clues, etc.
Run Nodes
You start your own nodes and join the network
Start Mining
Node runners can contribute PoW hashrate to the network in exchange for tokens.
Fork the Network
In BA we forked the difficulty, but maybe there is something more compelling. Maybe fork to adjust max block size. Nice because it happened for real in bitcoin. Maybe hard because I believe max block size is controlled in the runtime.
Another idea:
When we launch the chain, we allow PoW block to have either of two valid kinds of seals.
For example, one based on sha3 and another based on keccak.
Then we pretend there is a cultural war and some people like one function or the other hand some people don't care.
When the time comes to fork, we have three different versions of the node available: 1 only accepts sha3, 2 only accepts keccak, 3 is the original that accepts either.
In this way we can see that there will be at least two viable chains (the sha 3 chain and the keccak chain).
If there are a lot of nodes that still run the old version and accept either hash, we will form a third chain.
But if there are only a few such nodes, we will re-org into one of the other two chains, and potentially reorg back and forth between them.
Smart Contracts
The Smart Contracts module has an activity about launching smart contracts on a running chain. When these modules are run back-to-back, it makes an excellent learning experience to use this same chain we just launched to also launch the smart contracts.
Blockchain Forks
How to use the slides - Full screen (new tab)
Blockchain Forks
Landscape
---v
Landscape
Ideal World
In an ideal world blockchains would look like this:

---v
Landscape
Real World
Things don't always go according to plan:

---v
Landscape
Chaotic Real World
And sometimes they get extra messy:

What's the goal?
---v
What's the goal?
Fork Identification

Notes:
There are different forks, they can have different shapes and reasons. We'll try to identify some examples.
---v
What's the goal?
Fork Categorization

Notes:
Why? Forks in the same category will exhibit similar behavior and will require similar handling. Then when making changes we can easily figure out to which box the change belongs and react accordingly.
It's also worth pointing out that the whole web3 space is still very young and we are still figuring out how to name things appropriately. There is definitely still a lot of confusion about the fork types and the convention I will be using here today is based on the naming proposed by the MIT Digital Currencies Initiative. It will cover most of the common terms and hopefully will not be as self-contradictory as some of the terms used within the community.
---v
What's the goal?
Fork Confusion
BABE (sometimes):
Notes:
To demonstrate the confusion think of BABE. BABE can have multiple block authors create blocks at the same time and then the chain forks. What type of a fork is it? Some of you might have heard about soft forks and hard forks, any idea which one it is?
Fork Categorization
---v
Fork Categorization
Forks Family Tree

Notes:
This is the core categorization of forks we'll be waking you through today. You don't need to understand the whole tree as we'll be going step by step. For now let's actually go back to the example from BABE and let's place it on the map.
Transitory Forks
Notes:
For that we'll talk about transitory forks.
---v
Fork Categorization
Transitory Forks
Notes:
One of the simplest forks that is rarely talked about so the name might not sound familiar. They are often also called short-lived forks or temporary forks.
---v
Transitory Forks
Notes:
They usually arise from the fundamental protocol uncertainty or networking lag, but luckily they are usually resolved quickly by the network itself. For instance in BABE even if all the nodes are running the same software those forks can still happen when two nodes roll low enough numbers. In Bitcoin two miners might mine a block at roughly the same time. Over time one of the blocks wins due to some heuristics like the longest chain. Those forks are generally not a problem and only live on short timescales.
Consensus Forks
Notes:
So now let's move to something more interesting. Consensus forks.
---v
Fork Categorization
Consensus Forks

Notes:
Usually when you hear about forks you hear about those guys. They are the other branch and they also come in many flavours we'll discuss in a minute.
---v
Consensus Forks
Validity Set
Notes:
But first before we understand the intricacies of consensus forks we need to understand the concept of the validity set and how it connects to the protocol.
---v
Consensus Forks
Validity Set

Notes:
It's best to see it through an example so let's look at the BTC block. You don't need to understand all the fields that are in it but for now take a look at the blocksize field as well as the block header itself.
Validity Set

---v
Consensus Forks
Validity Set

---v
Consensus Forks
Validity Set

Notes:
So the validity set is a set of all hypothetical blocks that could be produced by the protocol. It's a set of all valid blocks under those rules.
So if there is a block D that for instance is too big, it's blocksize is bigger than the allowed one...
---v
Consensus Forks
Validity Set

Notes:
Then it falls out of the validity set into the universal set of all possible data blobs. Only some of those data blobs are valid blocks.
---v
Consensus Forks
Validity Set

Notes:
Let's actually look at an example. Imagine this is Bitcoins validity set and here we see a few blocks from it. The numbers at the top are initial few digits from the hashes representing those blocks.
Imagine all the Bitcoin nodes suddenly decide they really dislike when the first hash digit is odd. They only like when it's even so they band together and change the protocol to only accept hashes with an even first digit.
---v
Consensus Forks
Validity Set

Notes:
This change in the protocol would reduce the validity set. It would be more constrained then before. Some of the previously valid blocks would no longer be valid under the new rules. What happens in that case? Can we predict that?
---v
Consensus Forks
Validity Set

Notes:
To generally represent the same idea we'll be using the simpler representation on the right. Where the new set N is contained within the old set O. The fancy notion at the bottom says the same N is contained in O.
Soft Forks
To understand the example from a second ago we'll dive into soft forks.
---v
Fork Categorization
Soft Forks

Notes:
Firstly soft forks are a type of a consensus fork and they are results of a change in the protocol and thus the validity set.
---v
Fork Categorization
Soft Forks
- Backwards Compatible
- By making the consensus rules more restrictive the set of valid blocks gets smaller.
- Not every (and often none) of the blocks produced under old rules will get accepted by new nodes.
Notes:
So based on the venn diagram we have on the side we can see that the new consensus rules are more restrictive as the validity set shrinks.
New nodes produce blocks that are always accepted by old nodes. Old nodes generally don't produce blocks accepted by the new nodes.
Before we jump into demonstration is decreasing or increasing blocksize a soft fork?
---v
Fork Categorization
Soft Forks
- Decreasing blocksize
- Accepting only even/odd hashes
- Disallowing some transaction types
Notes:
Decreasing the block size restricts how many different blocks can be constructed so it makes the set smaller. It is a soft fork. The example we had a moment ago with the even hashes is also a soft fork as it adds another constraint on the previous protocol rules restricting them even further. Another good example would be banning some transaction types from use.
Now let's take a look at how forks work in practice and how they vary based on the hash power or staking power in favour of the protocol change.
---v
Fork Categorization
Soft Forks

Notes:
So in this scenario we'll be looking at what happens if nodes with less than 50% hash power or stake want to soft fork. Remember that soft forking is simply making the consensus stricter.
In that case the blocks produced by new nodes are marked with N and they are accepted by the old chain but the old chain mines faster so they don't care about the new nodes. Blocks produced by old nodes are NOT accepted by the new nodes so the longest chain for new nodes is the short chain with only the N blocks. This is effectively a permanent fork.
---v
Fork Categorization
Soft Forks

Notes:
In the similar example when the new nodes control more than 50% power the situation changes drastically. The new nodes mine faster and are the longest chain. But remember that old nodes accept the new blocks so if they new nodes mine faster the old nodes blocks get constantly reorged out. They are forced to update the software if they want their blocks to get accepted at all otherwise they loose all the rewards.
Hidden Forks
Notes:
Now let's take a look at something a bit less known. Hidden forks.
---v
Fork Categorization
Hidden Forks

Notes:
An edge case of soft forks.
---v
Fork Categorization
Hidden Forks

- Conflict-less
- The old, now excluded blocks were allowed but never used in practice.
- New nodes are theoretically stricter but practically accept all old blocks.
- Old nodes accept new blocks.
Notes:
So the venn diagram is exactly the same as in the normal soft fork case. But imagine that the the orange crescent, this is the part we're excluding from the old protocol when shifting to the new one... was never actually used. So for instance the block had an empty field that could have some arbitrary data inside, but everyone left it empty and never checked what was inside. The new protocol puts something meaningful in the empty field but doesn't require it. Because old nodes never used this field pretty much all old blocks will be accepted under the new rules.
TL;DR the stuff we removed from the validity set wasn't even used despite being technically valid.
---v
Fork Categorization
Hidden Forks
- Assigning non-conflicting uses to empty opcodes.
- BTC Ordinals using empty opcodes to implement BTC NFTs.
Notes:
A good example of that assigning new optional use-cases for previously unused opcodes as with the example of the recent Bitcoin Ordinals update.
---v
Fork Categorization
Hidden Forks

Notes:
And the reason why they are hidden... is they are not even manifesting as forks despite the consensus change. All nodes effectively accept each others blocks so there is no conflict.
Hard Forks
Notes:
---v
Fork Categorization
Hard Forks

---v
Fork Categorization
Hard Forks

- Forwards Compatible
- By making the consensus rules less restrictive the set of valid blocks gets bigger.
- Not every (and often none) of the blocks produced under new rules will be accepted by the old nodes.
- Every block produced under old rules will get accepted by new nodes.
---v
Fork Categorization
Hard Forks
- Increasing blocksize
- BTC Cash fork at first*
- Adding new transaction types
- Increasing max nonce value
---v
Fork Categorization
Hard Forks

Notes:
First let's go through the scenario of a hard fork with less than 50% support. Remember that the rules were loosened this time. If new guys accept old blocks so because they have less than 50% power they get constantly reorged out. There is no permanent fork in this scenario and the change will not go through if if it has this limited support.
---v
Fork Categorization
Hard Forks

Notes:
In the case of more than 50% support the new guys miner faster but they are no accepted by the old nodes so they go ahead. Old nodes maintain the old chain and the community is split. So if there is a major change that most people accept but not everyone it will always fork the chain.
Small Summary
Notes:
Now that we've seen both soft and hard forks... If we'd manually increase the difficulty of mining in the BTC network would that be a soft or hard fork? Hard.
Also let's reiterate. We only have permanent forks in soft forks with under 50% support and in hard forks with over 50% support.
Full Forks
---v
Fork Categorization
Full Forks

---v
Fork Categorization
Full Forks

- Fully Incompatible
- Soft + Hard
- By changing the consensus rules the sets can become disjoint or overlapping.
- Most (and often all) blocks produced under one ruleset are not accepted under the other.
---v
Fork Categorization
Full Forks
- Changing the hashing function
- Changing the signature scheme
- Specific combinations of soft and hard forks
- BTC Cash fork in the end*
---v
Fork Categorization
Full Forks

Summary
Notes:
- Bitcoin cash pivot from hard to full because they didn't have enough HP.
- Soft are often preferred for changes because with >50%HP they do not fracture the community (BTC community logic)
- Hard can be preferred as they seem to better represent minorities. If some people don't agree with the majority they naturally fork off and are not peer pressured to follow (ETH community logic)
Thank you!

ink! Workshop
How to use the slides - Full screen (new tab)

Notes:
This workshop was an idea that came from first wave of PBA in Cambridge. The first time it was ever played was back in Buenos Aires. It's very much a PBA right of passage, so it's exciting to be able to play today.
Day 1

Notes:
This is us playing in BA earlier this year.
Components
- We deploy + run.
- Runs game loop.
- Invokes each player.
- Determines the score.
- Your job.
- On big screen during game.
Notes:
The game has three components:
- click the first is a game contract, which is something that we have taken care of. I will deploy it and run it on Rococo. The game contract runs the game loop. It invokes each player contract and it determines the score.
- click And the player.contract, that's your job. so we we have a template for a very basic player and you can basically modify it in any way you like. I will explain the scoring function in a moment.
- click Lastly, we have a front-end that we will put on the big screen here, but it's online, you can open it up on your laptop and follow the game locally.
The Process
- 🧠 Create contract that plays on your behalf
- 🚀 Deploy contract to Rococo testnet
- 🤝 Register contract as player with game contract
- ️🎮 We start the game
- 📺️️ It runs for some minutes, we watch it on screen
Notes:
So the process is as follows:
- click - you brainstorm and create a contract that plays on your behalf ideally in a better way than the other contracts
- click - you deploy the contract to the Rococo testnet
- click - you register your contract as a player with the game contract. We will publish the addresses and it's it's not complicated you can just use contracts UI. I will also show it in a second
- click - then we start the game. We have a script that calls the game contract regularly and the front end will display the changes
- click - so the game will run for some minutes. Your contract will already be uploaded at this point - so you can't do anything. The contract will play on your behalf. Meaning it's hands off. I mean you can also change it with upgradable contract patterns and stuff, but in general, you won't have to. So you can just watch the game play out. If you're familiar with AI agents, that's also a similar idea, where you have an agent that plays a game on your behalf.
How the Game looks
Notes:
This is what the game board itself looks like. You can see, it's a it's a coordinate grid.
How the Game looks

Notes:
this is X1 y0. And the idea is for you, as a contract developer, to paint as many fields of this canvas of the script as possible. There's an API function for how to paint. I'll show it in a minute, but the idea is that in the end the contract that painted the most Fields wins.
How the Game looks
Notes:
So yeah, there's bit of scoring to be done. There's also scoreboard here on the side, where all players will be shown as well as their rank. You will be assigned a random color to your player contract.
How to score?
- Use as little gas as possible to paint as many fields as possible.
- Stay within your gas budget.
- The later you manage to still paint a field the better you score.
- No overpainting! First player to paint a field owns it.
Notes:
This game was designed in a way where all of the best practices for smart contract development will make your player run better. We really tried to gamify some of the concepts that are really best practices of how you should develop a smart contract.
- click - first one is to use as little gas as possible to paint as many fields as possible. Gas consumption is a super big thing as user fees derived from that and the transaction throughput also relates to how big a contract is so the less complex your contract is the better it will do.
- click - There's a certain gas budget allocated per player and if you if you're above that then you just won't make a turn. So you have to stay in an optimal gas budget.
- click - the later in the in the game that you still manage to paint the field the better you score because what will happen is that there will be all kinds of fields painted and it will convert to a place where there's only a few left. so if you have a player that just randomly tries to paint things then at some at some point it just won't no longer work because it doesn't paint the unpainted fields. But in order to find those, you will have to have some more complex logic in your contract.
- click - and lastly, there's no overpainting. So the first player to paint a field owns it. So if you have a contract that just paints the same field over and over again, it will just not work. So you have to have some logic in there that checks whether a field is already painted or not.
Basic Player Contract
#![allow(unused)] fn main() { #[ink::contract] mod player { #[ink(storage)] pub struct Player {} impl Player { #[ink(constructor)] pub fn new() -> Self { Self {} } /// Called during every game round. /// Return `(x, y)` coordinate of pixel you want to color. #[ink(message, selector = 0)] pub fn your_turn(&self) -> Option<(u32, u32)> { Some(1, 2) } } } }
Notes:
So this is a very basic player contract. We have a repository app set up with the template for this - I will share the link in a second. How it looks is - it's a contract that defines the player module.
- click - a super simple player doesn't have to contain any storage whatsoever.
- click- a super simple player also doesn't have to contain any Constructor arguments
- click - and it can just return a random constant value. So this is the most simple player ever. What your player needs to do is to have one message, that has a defined selector, so you don't have to think more about this. It's just that it needs to have this function and this function is called by the game with every round. And whatever you return from this function. This is your your turn for the game. So if in this case you return an option some(1,2), this would mean you paint the pixel at X1 Y2. In that case, it would be a very boring play. Who can tell me what would happen here? (a player that only makes one turn - it always tries to paint the same field. And if someone else also chose the same magic numbers then it wouldn't even make a turn at all.)
- click - So there's a couple things of how you can improve on that and I will show some hints later, but for now what we're gonna do is look at the repository and see how we can get started with this.
How to play
Notes:
This is the Squink-Splash-beginner Repository - it contains a couple of things.
How to play
 Notes:
Notes:
It contains the cargo.toml file and the lib.rs, which is the player that I just showed.
How to play
Notes:
It contains the game metadata. You will need this in order to interact with the game itself, to register your player and so on. but yeah we will show that.
How to play
Notes:
And it has 2 todo files.
The first is some instructions on General setup and the second one is in order to build your player.
Now (1)
github.com/paritytech/squink-splash-beginner ➜ todo-1.md
Notes:
So, the first thing that we are going to do is that I would ask all of you to go to this link here and follow the instructions. We will go around and help whoever has an issue. I think you might even have already used some of the requirements in there, so it may not be super complicated.
Now (2)
github.com/paritytech/squink-splash-beginner ➜ todo-2.md
Notes:
For this stage, you will need the address of the game. We'll post it in the chat. This is a simple example - we're just giving you exposure to the flow of uploading your player contract.
🕹️🎮 Let's play! 🕹️🎮
Notes:
The next slides go over strategy. (maybe wait to to go through until you've played one game)
The Game Contract
pub fn submit_turn(&mut self)
pub fn board(&self) -> Vec<Option<FieldEntry>>
pub fn gas_budget(&self) -> u64
pub fn dimensions(&self) -> (u32, u32)
Notes:
When you deployed it you already saw that there's different functions that you can call. There are a lot of functions that are interesting.
- click - the game runner calls this - if you're interested, you can take a look how it works and there might be some hints for for the game.
- click - then there's a function to to query the board in order to find out if certain fields are already occupied or if they are still free.
- click - there's a function for the gas budget so you can find out how much gas your player is allowed to use per one round. Because worst thing is if you are above this gas budget, then you just won't execute any turn during that round.
- click - there's also function to query the game dimensions. Same thing there, if you paint outside the bounds, then also you just missed one turn.
Things to consider 🧠
- Develop a strategy for your player.
- Use as little gas as possible to paint as many fields as possible.
- Stay within your gas budget.
- The later you manage to still paint a field, the better you score.
- No overpainting! First player to paint a field owns it.
- paritytech/squink-splash-advanced
How to test locally?
paritytech/squink-splash-advanced
Notes:
There's details in here. You could deploy locally to test things out. there's also commands you can use to deploy not using the UI.
Hint: Playfield Dimensions
- Paint within the bounds of the playfield!
- Otherwise you wasted a turn.
Ideas
- You can call your own contract as often as you want!
- Random number
- Query which fields are free
- Query game state via cross-contract call
- Off-chain computation
Notes:
- click Lastly, some ideas for for your agent in the game you can you yourself can call your contract. As often as you want and this won't contribute to the gas used during the game. You can during the game you could also call a set of function of your contract if you want to adapt something.
- click You could also Generate random numbers. There are a couple of libraries out there, if you want to go along those lines you have to pay attention that it's a no standard Library. typically a random number generator libraries they typically have a feature that you need to enable in order to make them no standard compatible
- click A clever strategy would be a query which fields are free. that's a bit more complex with the with the code snippet that we have in this Advanced repository, this would give you a hint.
Day 2

Now
We help you debug!
Then
🕹️🎮🕹️🎮
Thereafter
Solutions Explainer
Use as little gas as possible to paint as many fields as possible.
Stay within your gas budget.
The later you manage to still paint a field, the better you score.
No overpainting! First player to paint a field owns it.
paritytech/squink-splash-advanced
Frontend
Questions
- What strategy did the winner choose?
- What strategies did the others choose?
- What do you think would be the perfect strategy?
Board Dimensions
- Worst 😱
- Cross-contract call to
game
- Cross-contract call to
#![allow(unused)] fn main() { #[ink(message)] pub fn dimensions(&self) -> (u32, u32) }
- Best 👍️
const width: u32new(width: u32, height: u32)
More Pitfalls

- Forgetting
--release
- Iterating over a datastructure in your contract
Avoid iteration
#[ink(message)]
fn pay_winner()
let winner = self.players.find(…);
self.transfer(winner, …);
}
#![allow(unused)] fn main() { #[ink(message)] fn pay_winner( winner: AccountId ) { assert!(is_winner(winner)); self.transfer(winner, …); } }
Strategy 1
Return Random Numbers

Strategy 1
Return Random Number
- Wasm-compatible RNG
- Use Storage to hold seed for random number
- 📈 Uses little Gas
- 📉 Quickly runs into collisions
- 📉 Score function rewards players that late in game still paint fields
Strategy 2
Paint only free fields

Strategy 2
Paint only free fields
- Query board for free fields
- 📈 Succeeds late in game
- 📉 Cross-contract call 💰️
- 📉 Need to iterate over
Mapping:O(n)
Strategy 3
Shift computation off-chain

Strategy 3
Shift computation off-chain
- Off-chain Script
- Query board ➜ Search free field
- Query board ➜ Search free field
-
#![allow(unused)] fn main() { #[ink(message)] fn set_next_turn(turn: …) {} #[ink(message, selector = 0)] pub fn your_turn(&mut self) -> { self.next_turn } }
Strategy 4
Exploit player sorting in game loop

Strategy 4
Exploit player sorting in game loop
- On top of Strategy 3 (off-chain computation).
- Game loop calls players in same order each time.
#![allow(unused)] fn main() { #[ink(message)] fn submit_turn(&mut self) { // -- snip -- for (idx, player) in players.iter_mut().enumerate() { … } // -- snip -- } }
Strategy 4
Exploit player sorting in game loop
#![allow(unused)] fn main() { impl<T: Config> AddressGenerator<T> for DefaultAddressGenerator { fn generate_address( deploying_address: &T::AccountId, code_hash: &CodeHash<T>, input_data: &[u8], salt: &[u8], ) -> T::AccountId { // -- snip -- } } }
➜ All inputs are known
➜ Generate low T::AccountId with known inputs
Strategy 5
Checking these slides already yesterday

Additional Lessons
Coordination and Trust in Web3
How to use the slides - Full screen (new tab)
Coordination and Trust in Web3
Notes:
In this module we're going to talk about Smart Contracts.
Smart Contracts
Two Definitions
Broad Definition
aka Szabo definition
A machine program with rules that we could have defined in a contract, but instead a machine performs or verifies performance.
Notes:
The first question we should answer is "wtf is a smart contract"? The term has been around for a long time (longer than any blockchain platform) and has evolved over time. It was first introduced by this guy Nick Szabo in the '90s.
CLICK - read szabo definition
Szabo's definition is primitive and kind of vague. It might even be argued that it includes all computer programs. But it gets at the essence of his thinking at the time. Szabo studied both law and computer science and his big idea was that agreements that are traditionally legal contracts could be better expressed and enforced as computer programs. Over time, as this vision was gradually realized, the term took on a more specific meaning and was refined quite a bit.
Smart Contracts
Two Definitions
Narrow Definition
aka web3 definition
A program that specifies how users can interact with a state machine and is deployed permissionlessly to a blockchain network
Notes:
click - read web3 definition. This definition is clearly more technical and precise, which is helpful in a lot of ways. At this point though, we haven't even learned all the terms in this web3 definition. As an educator, that deeply pains me. So - my promise to you - by the end of the week, this sentence will 100% make sense to you. The broad definition (szabo's - the first one we just saw) is useful in understanding the broader space, historical context, and its philosophy. This though, the narrow definition is useful when you're talking about deploying code to actual blockchain platforms. In this first lesson today, we'll focus mostly on Szabo's broader notion and explore the ways in which smart contracts are a modern extension to an ancient technology: contracts. We'll also look at some criticisms of the term "smart contract" and some alternatives that might have been better if it weren't already way too late.
Coordination

Examples of coordinated activities:
- dancing, music band
- money, business, trade
- rowing team
- building homes, buildings, roads
Doing the above safely through bureaucracies like inspection and certification procedures, automobile registration
Notes:
Okay so let's do that! Let's rewind a bit. Because before we can understand the ways in which smart contracts are "smart" versions of contracts, we need to understand what contracts are in the first place.
After all, we are standing on the shoulders of giants here.
So, in order to understand what contracts are, we'll start all the way back at human coordination.
We'll see that contracts are just a pretty good technology to achieve coordination, and that smart contracts are an improvement on that technology.
So, let's start here. I'm going to assert that coordinated activity is the basis of so much human behavior. Consider the building we're in right now. It has technicians, janitors, grounds people to run it, not to mention the crew it took to build it. Coordination is what allows this team of workers pictured here to complete a railroad that stretches across a continent. Obviously some coordination require more bureaucracy than others. Building a railroad that crosses many state lines? That will require government approval, inspection, and certification procedures - especially as it relates to safety. But two people dancing? That most definitely could be categorized as coordinate - but can be negotiated or navigated between two individuals.
Coordination
Notes:
There are so many examples of things we as humans can achieve only through coordination, not as individuals, it would be impossible to list them all. I hope it's evident that I think coordination is good a good thing! Because of it, we can build big big things and create beautiful music in a symphony together because of it.
Coordination
Notes:
It is how massive organizations like corporations and governments are able to function.
Voluntary vs Forced Coordination

Notes:
A clarifying attribute of coordination is that it can happen voluntarily or by force. Here, we have a picture of folks working together, let's assume it's voluntarily - as it looks like they're volunteering their time at a community garden. This is a wonderful example of human coordination at its best.
Voluntary vs Forced Coordination

Notes:
But like all things, of course coordination can have it's ugly side. Pictured here, a slave boat, is categorically a coordinated effort; people are forced to work together. Most of us consider slavery a bad outcome. It IS a bad outcome. Even those with sketchier moral compasses would agree that they don't want to be the slaves.
The point I'm making here is this: We want to create conditions (otherwise known as, incentives) where voluntary coordination can happen freely and easily. And thus make slavery as an outcome unlikely. And by building proper tools for voluntary coordination, we can help prevent forced coordination from happening in the first place. And again, voluntary coordination is a good thing between individuals - it's how we together achieve things that are impossible otherwise on our own. Thinking back to our first example of building a railroad - if I were to drive railroad spikes every day for the rest of my life, say I start in Miami where I live now? Maybe I eventually would make it to Georgia? But big collaborative coordination efforts? Railroads made it California! They stretch all over and across a continent!
Business and Trade
- primitive trade
- dead weight loss
- counterparty risk
Notes:
From a historical perspective, one of the first forms of coordination was simple trading. Let's imagine that I grow food and you make houses. So, I'll give you some food, if you build me a house, and I pay your daily wage by giving you food as long as you're building my house. This is a classic example of what is called primitive trade. You the house builder - you need food, so you can only build houses for people who grow food. As in, you can't earn food by building houses for randos who don't have food to pay you with. Obviously there are a whole lot of problems within this situation and it won't scale over time. But it's also a classic example of what is called 'deadweight loss' - The definition of which is: "a cost to society created by market inefficiency, which occurs when supply and demand are out of equilibrium". Another classic example would be if I, for example, grow corn in the summer and you ice fish in the winter. And together, we would love to have some way to feed each other during our off seasons - me to feed you in the summer and you to feed me in the winter - but there's no way to coordinate that because someone has to go first. So let's say I go first and I just give you half of my corn all summer. It's within reason that you could just, you know, piece out and I'm… left with nothing all winter. And that is what we call counterparty risk. And because I don't want to take on that counterparty risk, I don't engage in such a deal, which is then deadweight loss. So, despite the fact that we both kinda want to trade, we have no real way of making it happen. So are we stuck?? Do we just not do the deals because we're afraid of counterparty risk and deadweight loss?
Trust
So you want to coordinate with someone.
But you don't want to get ripped off.
Notes:
Let’s then move on to talk about trust - as it makes sense that it's one common way to achieve coordination. Because let's imagine, you want make an agreement, but you don't want to get ripped off. Trust means that we decide to trust whoever we're coordinating with - we're creating an agreement between one another to not to rip each other off. Say for example we're builders - you and I decide to build your house this week. Well then I in turn believe that we’ll build mine next week.
Personal/Real Trust
vs
Rational Expectations
Personal trust - you can build it over time through a slow give and take like you do with your family or long term business partners. <!!-- .element: class="fragment" -->
Notes:
For those houses to be built, for that coordination to happen, we need credible expectations that the promises we make to one another will be upheld. AKA I have to be willing to trust you - that you are going to fulfill your end of the bargain. So here on the slide, I have two concepts: Personal or 'real' trust vs. rational expectation. CLICK - I like to think of personal trust, as a familial thing - or something that's been developed between people over time - I for example trust that my mom, who is watching my son right now, is taking good care of him. But she and I have gradually built up that trust over many years. This sort of trust happens within families, between friends or neighbors, but it can also happen in business relationships - say for example, you have a new business partner and you start that relationship off by doing say one small deal together. And yeah, you may choose to take on a little risk within the deal, but it’s small. And then the next time you interact, the deal evolves and becomes a little bigger. And maybe that time the other party/person takes on that little bit of risk. At no point is there SO much risk that you could get completely wrecked if they rip you off. Again, there's some, and so by accepting that risk slowly more and more over the years, you two are able to actually build up that personal and real trust.
Trust: A Dirty Word
Less Trust, More Truth
Notes:
Okay pause - I should fully acknowledge that I'm talking a whole lot about this thing trust, and who here has heard or seen ppl in the web3 world wearing hats saying - CLICK - less trust, more truth. Anyone? (check for nods)
So, some personal historical context on me, when I was a newbie in the web3 space, I hadn’t heard this phrase (or slogan rather?). I saw it on ppl’s shirts and felt sort of confused and honestly, kind of excluded from what felt like maybe an inside joke. I remember thinking, wait, I trust people, does that make me wrong... Is that a bad thing? I asked myself the question, why is trust such a dirty world in our world? Well, in time, thanks to some of my fellow instructors in the room, I came to understand that this phrase is referring to the fact that life is not all sunshine and roses! Not all relationships and interactions are filled with trustful actors. In fact, most aren't! Literally every day we're in situations in which we are forced to treat complete strangers as if we've established real, authentic trust between one another. Treat them as if they're a close friend or business partner. And that is definitely bad, and is a dirty word, and is a thing that we really shouldn't do. And yet! This literally happens all the time - every day really -when you give a merchant your credit card number and you trust that they won't go off on an amazon spree with it. Or when you give your social security number to a new employer and you trust that they won't steal your identity. Or when you give your passport to a border agent and you trust that they won't sell it on the black market. Okay, end pause - back to the slides.
Personal/Real Trust
vs
Rational Expectations
- Personal trust - you can build it over time through a slow give and take like you do with your family or long term business partners.
- Rational expectations - you can believe that a person will act faithfully because they are incentivized to do so.
Notes:
So. We know that we don't have the luxury of only interacting with people we truly personally trust. It's impossible to get personal trust with every person you'd in theory like to because it takes a super long time to bootstrap that real kind of relationship. And frankly, sometimes you want to interact with a stranger more immediately, say today, and not have to court them for years upon years. So, again, this should lead us to the question of - how do you handle these every day situations? How DO I trust that the coffee guy isn't going to run off with my credit card details? CLICK - Well, that's where rational expectations come into play. This is a game theory, incentives-based concept. Where you believe credibly that a person will act faithfully according to an agreement you've made - because the incentives make them do so. So, in a sorta loose way you could say this is another kind of trust? But it's not the genuine, real, authentic kind. It's more like, I trust that you will act in a certain way because you are so incentivized to do so and being truthful and upholding your end of the agreement ultimately is your best strategy and option.
Personal Trust for Performance
Personal trust can make things really efficient, and it's reasonable to leverage this trust when it's warranted
Notes:
Again, I want to make sure you're all hearing me when I say that personal/familial trust is not wrong, or bad, or dirty. I don’t want us all walking out here calling our moms and dissolving our trust with them. That just isn’t the scenario we speak to when we say 'trust is dirty'. And further, if you have someone who you genuinely trust, you can actually get things done a whole lot faster and more efficiently by leveraging that trust. So, it may be worth it to bootstrap genuine personal trust. You know, start small, accept a small bit of risk and gradually increase that over time. Again, it's only bad when you have to do that with someone that you don't know or you actively distrust AND they aren't incentivized to return that trust.
Promises and Reputation
- how enforceable is it?
- does it work in small setting?
- does it work in a large setting?
Notes:
So these incentives are obviously really important. Let's talk about what they are or could be. Often they are civic duty based - the fear that society or your town will turn on you if you break your promise. OR they're morality or religion based - you know, you keep your promise to someone out of fear of otherwise going to hell. Or they are based on the fact that you have a reputation to uphold. You don't want to be known as a liar or a cheat. I think you get what I'm saying here, yeah? It's social norms and expectations that keep people. Reputation is on the line. And this can get society pretty far. But, it's not perfect. It's not always enforceable - or rather - a threat of a bad reputation isn't always enough to keep people in line. Or a town grows enough that you can't keep track of everyone's reputation. Or, you know, you're in a big city and you don't care about your reputation because you're never going to see these people again. F trust. F reputation. Outlaw life is for me!
From a sociological perspective, we know that if people within a society tend to keep promises, the society tends to prosper. But! Eventually, it will be sufficiently profitable to defect and to break promises. womp womp!
And this is why we started the lecture off with discussing coordination. So let's quickly merge some of the concepts we’ve discussed thus far. Coordination and trust. Because let’s be real, to achieve things on this planet, it requires some coordination between the 8 billion people here. And sure, genuine personal trust can help in a small village. And promises based on societal reputation and civic incentives can help getting things done across a town. But promises don't get us all the way up to scalable, global trust. When talking with Joshy, about this problem his example, that I can’t seem to get out of my head was that: “It's the modern equivalent of a primitive village deciding "okay everyone, let's all agree we're going to poop in the same corner of our village, not just wherever we feel like it.” So as he says: Promises can make a village of 100 shit in the same corner, but not 8 billion. I think this is his way of saying that we need some bigger and more resilient coordination tools.
Contracts
- Contracts are Promises
- Some involve money, but they're much more general than just money.
- Traditionally, contracts are special promises that the government will enforce.
Notes:
So how do we incentivize people to keep their promises beyond a civic duty? Ding ding ding - Finally! This brings us to the idea of contracts. They're basically, pretty much, promises. They could involve money, a lot of them do, though they don't have to. Ultimately, think of them as abstractions over promises. And someone is enforcing the contract.
On a very small scale, think of siblings fighting over a toy, a parent might encourage them to agree to take turns. Later when it is time to tarde, the parent might remind the child, "you said you would trade in 5 minutes, so now you have to." The parent is big enough to physically overpower the child if it were to come to that, and the child knows it, so therefore it rarely comes to that. The parent in this situation is the enforcer.
Same thing in sports. We all agree to the rules, and agree to let a referee make the judgement calls. The ref is the enforcer. In big leagues, where there can suspend players and affect their career, this works. In the public park, it doesn't always, because the ref is just a peer and there is no real power differential.
Traditionally what you've probably learned is that "enforcer" of these contracts (or promises) is the government. The government, by being the enforcer, can help people engage in so much voluntary coordination just by making them keep their own promises.
And sure, that's valuable because governments are big and powerful. You could say that even in some sense, the government enforcing it is a lot like God enforcing it. As in, the government is big enough to have power over individuals interacting, and if anyone tries to rip someone else off, the government will step in and make sure the contract is upheld.
This essentially allows us to interact as if we trusted each other. And over time, the stickiness sets in and people actually do start to trust each other! Yay, happy days - But wait! What am I talking about? We know the unfortunate truth which is that government having such a power differential over the people is not always a good thing...
Promises with Force


Notes:
This is a picture of the white house being built - CLICK - and of course the pyramids.
Both are impressive works of human coordination. But to the workers they are much different. The construction crew building the white house was engaged in voluntary coordination through employment and they were probably excited about their new government too. The slaves building the pyramids, are engaged in forced coordination, and when they die, their corpses won't even make it in that pyramid, they'll just get thrown out in the desert. Our job, in this smart contract module, is to design systems of coordination that make it likely and easy for voluntary coordination so that it is not necessary or desireable to resort to forced coordination.
Promises with Force
 Notes:
Notes:
We're doing that because contracts, which often require enforcers, who usually is the government - CLICK - Yeah, which could of course not always be a good thing...
What is a Contract Again?
(to summarize)
A promise, made between parties, backed by the government, to coordinate together to accomplish something together.
Notes:
So yeah, that's the goal and what we're trying to solve. But, again, just before we go any further, let’s make sure we’re all on the same page about what a contract itself is. A promise, made between parties, backed by the government, to coordinate together to accomplish something together. The notion of promise is very abstract:
- It could involve coordinating over time.
- It could involve money or even credit.
- It also could have multiple possible valid outcomes.
Okay. Cool. All on the same page? Nodding heads? We can agree we understand this concept?
Smart Contracts 🎉

Notes:
Amazing… because, now onto smart contracts! - CLICK - We've finally made it here, folks, horary! Back in the 90s, this CS guy, Nick Szabo, and some other cypherpunks realized that contract law and computer science actually had a lot in common, and thus developed the idea of smart contracts. And together we'll develop and tease out those same comparisons here.
Smart Contracts - Szabo Definition
A machine program with rules that we could have defined in a contract, but instead a machine performs or verifies performance.
Broad definition aka Szabo definition formulated c 1997
Notes:
So Szabo has this idea of the smart contract - which is basically to write contractual agreements as computer programs in programming languages. And then to run those programs on a computer that will then execute the instructions faithfully with machine-like precision. He was pretty excited about some of the research in multi-party computation that was happening at the time and had a sense that this vision might be right around the corner. Remember, there is a second smart contract definition that we called the "web3 definition" right at the beginning of this lecture. That definition is heavily dependent on content you'll learn during the blockchain module - so Joshy will be sure to build off of that later this week.
https://nakamotoinstitute.org/the-god-protocols/ https://nakamotoinstitute.org/formalizing-securing-relationships/
Smart Contracts 😠👎
Notes:
Of course, I want to caveat that the term isn't perfect and not everybody likes it. As you can see in the tweet, Vitalik has worried that the term is too catchy and gives the wrong impression...
With these caveats and criticisms in mind, it is still worth exploring the idea of contracts as computer programs.
Quick review of how we got here
Notes:
So remember we started all the way back at simple primitive trade. One solution to those problems were to have personal trust with one another. But that doesn't work for everything. So we evolved to use rational expectations based on incentives and reputation and societal norms. But then we had the problem of scalability. Which brought us to, contracts, aka promises, which allowed us to really scale and achieve some incredible coordination. And to ensure that those contracts were upheld, the government functioned as a central point of enforcement. But, as we've seen, that's not always a good thing. And so now, we're going make the next iteration in this long, rich history of how to coordinate: which is the smart contract.
Smart Contract Objectives
- Retain all the value of traditional governmental contracts
- Can trust strangers promises
- Can coordinate with little risk
- etc.
- Remove the need for a powerful government
- Remove ambiguity about what contracts are enforceable
- Make writing and understanding contracts more approachable
- Make contract execution and enforcement more efficient
Notes:
These are the goals of a smart contract. We basically want to keep all the good stuff that contracts brought us, but then of course make them better by not making the government the central point of enforcement. We want to know, without a doubt that the contracts will be enforced. We want them to be approachable, legibility wise, and we want them to be efficient.
Smart Contracts - Two Parts
- Expression
- Execution / Enforcement
Notes:
So, we'll look at smart contracts in two parts. Expression - this is the part about actually codifying or expressing what you agree to unambiguously. From a programmer's perspective, this is by writing code. Or from a lawyer's perspective, this is writing up a bunch of pages of legalese, which basically is a DSL for being really specific in a legal contract. And then the part about making sure it actually happens? and what to do if something goes wrong? That’s the execution or enforcement part. Execution is ultimately where the two worlds contrast - running unstoppable code on a blockchain vs. having courts and judges and police officers and things like that. Essentially the idea of a smart contract is: we're going to take a contract, which we all feel really confident in our definition, and we're going to glue it together with all of Szabo’s incredible Computer Science research that's come out way more recently than contract research, and that all together is the next iteration and improvement on contracts. I should note - of these two parts, Programming languages are good at part 1 and computers are good at part 2.
Expression -- Pt. 1
Domain Specific Languages
Legalese: In witness whereof, the parties hereunto have set their hands to these presents as a deed on the day month and year hereinbefore mentioned.
ink!: signatures = [alice, bob]
Notes:
Okay when we're talking expression we're really talking - Domain Specific Languages (which we say DSL for short). Humans have been inventing DSL forever.
Domain Specific Languages

Notes:
From the ancient greek accounting and administrative language, linear b,
Domain Specific Languages
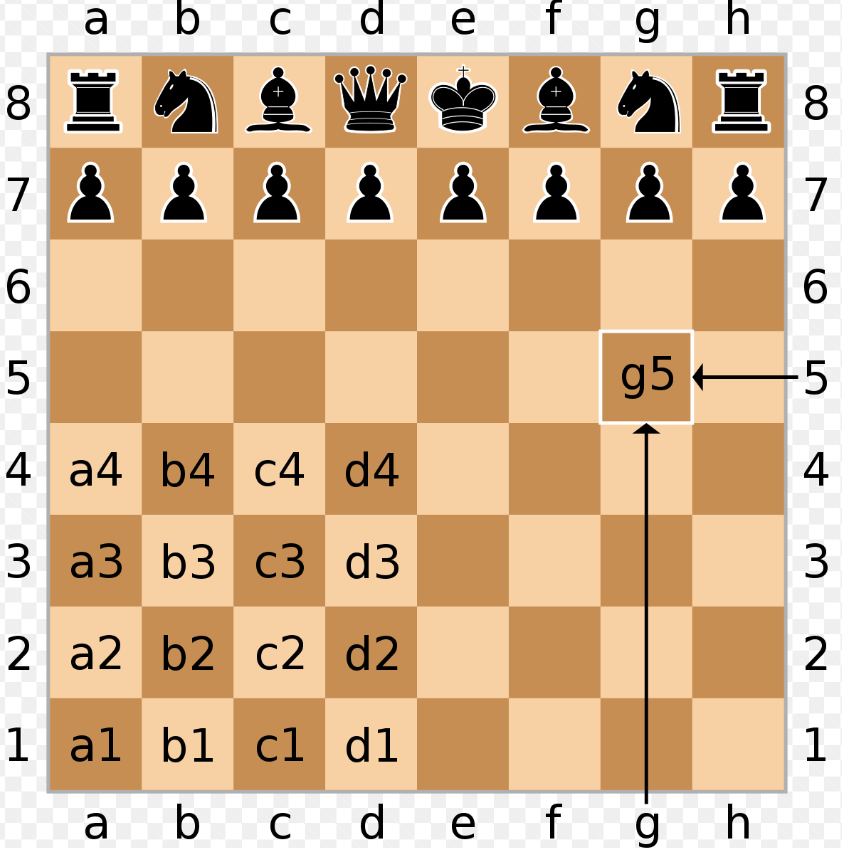
Notes:
to the shorthand for summarizing chess games,
Domain Specific Languages

Notes:
to the ink! programming language that you will soon learn. Contract law is a DSL and is an important part of society. It’s hard to read (read the sentence on the slide). Computer Programming languages are also DSLs, which of course had it’s own evolution, independent from contract law. It can be quite hard to read (asm or solidity), whereas good ones can also be easier to read. But really, the point I'm trying to make here is that legalese contract law and computer programming languages are not so different. They are both DSL meant to precisely express the nuances of detailed human agreements. And they're both hard to read for non experts. Szabo recognized this similarity and thus had the idea that programming may be the future of law.
Coding Style
- Adding laws vs negative diffs
- Elegance vs handling each special case
- Testing and Repeatability
Notes:
Back to the thing about both being hard to read for non-experts, a goal of mine is to make smart contracts more accessible to everyday people so that people can read their own contracts!
HOWEVER since we're talking similarities - we should also speak to the differences. And hence be careful with this legal and coding comparison. The culture of the two can certainly be different:
Execution / Enforcement -- Pt. 2

Notes:
Okay, so now that we understand what it means to express and write a contract, imagine now that the legal agreement has been made, what comes next?
Execution / Enforcement -- Pt. 2

Notes:
Well it must be executed / enforced. Where does that happen? How does that work?
Traditional Execution
- There is rarely an official submission moment.
- Parties Self Execute
- Sometimes, that's it. Success.
- Sometimes it goes to court.
Notes:
So - let’s talk about execution. In a traditional sense, parties often just sign the contract - maybe there is a witness, sometimes even a notary, rarely does it actually get submitted to a judge. On the happy path, no further action is necessary - this is actually a decided strength of the traditional system - it is maximally lazy. When there is a dispute though, parties can go to court for a human judge to rule. A judge enforces through powerful agencies like police and jails, and also through social consensus. In practice there is little consideration for scaling, queue length, ruling priority, resource exhaustion. But in principle there could be. The existing systems of the nation states could be optimized considerably without having to even adopt any real smart contract.
Computerized Execution
- There is a deployment moment
- Sometimes there are checkpoints or milestones or other official interactions
- Sometimes there is dispute resolution
Notes:
Moving beyond traditional execution to computerized: you start some process on some computer and that computer faithfully executes the program for users to interact with. At first you can think of it like a computer in the basement and we walk up to it when we want to interact. This is how nintendo works. Multiple controllers and multiple physically present users. The internet makes it better in some ways. We can interact with our smart contract remotely instead of being physically present. But now, there is the question of the server operator. Are they really executing the correct contract? A corrupt server operator is essentially the same as a corrupt judge. Hmmm... so I wonder how we might solve this?
Code is Law

Notes:
So, after all of that talk comparing law and code, it's inevitable that we get here: 'Code is law' which is another web3-ism you'll hear quite often. We know tech can be used to enforce rules. So we might wonder, do we actually need lawyers? Can code dictate what we can and cannot do? Can smart contracts be the answer? I'm not coming for lawyers. I'm sure they're nice. But could this be the answer to make life more trustless and secure? But this is where we'll end it today. I hope I've primed you with a few lingering questions. These smart contracts do sound cool, but perhaps the execution, where it actually happens, hopefully is a bit opaque and puzzling still. That's what Joshy will be able to speak to this week.
Activity
Notes:
Any questions?
Now I'm going to turn it over to Aaron to demonstrate this idea of expressing contracts as programming code.
Resources, Fees, Ordering
How to use the slides - Full screen (new tab)
Resources, Fees, Ordering
Overview
Notes:
- This lecture is a bit all over the place.
- A bunch of stuff worth covering, but not all directly related.
Fees & Ordering
Fees & Ordering
Blockchains are open, shared systems. They are unrestricted in access.
But restricted in resources.
Permissionless Access
Free ability to access does not mean free cost to access.
Threads
A blockchain runtime is single-threaded.
(For now)
Time
A block must terminate in some amount of time.
Network
Besides execution time, blocks need to propagate throughout the network.
Demand
Many people may want to use the system concurrently.
But the system needs to decide:
- Which state transition calls to include in a block, and
- How to order them.
Brief Interruption #1
The block body contains an ordered set of extrinsics: Packets from the outside world with zero or more signatures attached.
Notes:
Recall from Lecture 1.
Brief Interruption #1 (cont.)
These packets include:
- A call to the system's state transition function
- Some contextual information (e.g. a spec version)
- Perhaps some additional information that would help block authors prioritise
No-Longer Brief Interruption #1 (cont.)
Consider packets with:
- zero signatures attached as "inherents" or "unsigned extrinsics"
- one or more signatures attached as "transactions"
This will be pretty straightforward until it's not.
Fee Models
Different blockchains have different fee models.
For this lecture, we will look at three:
- Size (Bitcoin)
- Step Metering (Ethereum)
- Time (Polkadot)*
* (and coming soon, space)
Size
Bitcoin has a very simple STF: Namely verifying signatures and reassigning UTXOs.
Its block size is limited, and each transaction has some byte-length (instruction, signature, etc.)
Block authors will normally choose the set of transactions that would yield the highest gross fee.
Bitcoin Fee Market
Notes:
- Fee market evolves based on demand
Source: Y Charts (Couldn't find the chart I really wanted (per-byte rate), but can discuss)
Metering
Ethereum has a more complex STF than Bitcoin, namely one that is quasi-Turing-complete.
Users could submit transactions with an unknown number of steps to terminate.
The system uses "gas metering" to halt execution of a transaction and continue to the next.
Metering
Ethereum's STF defines a VM with instruction set, where each instruction costs some "gas".
Users specify:
- Max amount of gas to use
- Cost, in ETH, per unit of gas they are willing to pay
Metering
Each time an instruction is executed, the system deducts its cost from the max gas.
If the program terminates, it only charges for the gas used.
If it runs out of gas, it terminates the program.
Gas Rates
Notes:
Weight
Instead of metering during runtime, meter ahead of time.
Charge a fixed* fee for dispatching some call.
*Fixed
#![allow(unused)] fn main() { #[pallet::weight(100_000_000)] fn my_variable_weight_call(input: u8) -> Refund { let mut refund: Refund = 0; if input > 127 { let _ = do_some_heavy_computation(); } else { let _ = do_some_light_computation(); refund = 80_000_000; } refund } }
Time
Weight is picoseconds of execution time (10E-12).
Calls are benchmarked on some "standard hardware".
(There are some changes in the works about making two-dimensional weight.)
Weight
Using weight reduced the overhead of runtime metering, but requires some more care from developers.
- It must be possible to meter before runtime
- So, users should not be able to deploy untrusted code
- There is no safety net on execution
- Some computation is OK, but should be possible from call inspection
Notes:
Examples:
- User-supplied length of a list that will be iterated over
- Number of calls within a batch
Brief Interruption #2
Some of the gas and weight systems are evolving.
- Ethereum recently added EIP1559, which uses a fee + tip mechanism
- Parity and Web3 Foundation are discussing some changes to the weights model
Fee Strategies
Block authors can include transactions using several strategies:
- Just take those with the highest fee
- Take those with the highest fee to {length, gas, weight} ratio
Fee Burning
Not all the fees must go to the block author (depends on system design).
In fact, this is often a bad design. Block authors will want fees to go up, so may indulge in no-op transactions to boost fees.
Fee Burning Examples
- Polkadot only gives 20% of fees to block authors (80% goes to an on-chain Treasury)
- Since EIP1559, Ethereum burns some of its fees (its "base") from each transaction
In both systems, users can add "tips" to increase the priority of their transaction with authors.
Filling a Block
Depending on the limiting factor, systems can have different limits to call a block full.
- Bitcoin: Size (in bytes)
- Ethereum: Gas limit (sum of all gas limits of transactions)
- Polkadot: Weight (sum of all max expected weights)
Ordering
We've selected some transactions, but the runtime is single-threaded.
Block authors must order them.
Priority Basis
The naive solution is to maintain an order of pending transactions by some "priority".
And just include the top N transactions that fit in a block.
More Advanced
But, many small transactions might result in a higher fee for greedy block authors.
So there could exist a set of transactions that is more profitable than just the top N.
Even some that could be considered attacks.
Execution Models
Transactional Execution
Most blockchains have a "transactional" execution model.
That is, they need to be woken up.
A smart contract, for example, won't execute any code unless someone submits a signed, fee-paying transaction to the system.
Brief Interruption #3
All of the "packets from the outside world" in these systems are signed.
Some key holder signs an instruction that authorises a call and is willing to pay for its execution.
Now is the time to enter the world of unsigned packets.
Free Execution
State machines can have autonomous functions in their state transition function.
System designers can make these functions execute as part of the STF.
In this model, block authors must execute some logic.
Free Execution
These added function calls are powerful, but some care must be taken:
- They still consume execution resources (e.g., weight)
- They need some method of verification (other nodes should be able to accept/reject them)
Hooks
The Substrate lectures will get into these, but for now just a look at some APIs:
#![allow(unused)] fn main() { pub trait Hooks<BlockNumber> { fn on_initialize(_n: BlockNumber) -> Weight {} fn on_finalize(_n: BlockNumber) {} fn on_idle(_n: BlockNumber, _remaining_weight: Weight) -> Weight {} fn on_runtime_upgrade() -> Weight {} fn offchain_worker(_n: BlockNumber) {} } }
Source: /frame/support/src/traits/hooks.rs
The Quest for Infrastructure
How to use the slides - Full screen (new tab)
The Quest for Infrastructure
OR
Where can I actually run these things!?
Quick Review of Smart Contracts
---v
Expression
Write code instead of long confusing legalese
---v
Execution
Let the computer run it instead of the judge interpreting it.
Quick Review of Service Providers
They are the technicians that keep the infra running.
They are the technicians that keep the infra running.
They don't have any particular morals, certainly not the same ones you have.
Notes:
We need people to keep the computers online and replace broken hardware and make sure the data is backed up etc. But those people should be just that, technicians. They are not elected officials or Judges or anything like that. So we don't want to accidentally let them fil that role.
Many, probably even most, data center workers are perfectly good people not trying to scam anyone. The point is that any individual server operator could be evil and it will be easier to coordinate voluntarily if people don't have to trust the server operator to do it.
Where to Run the Contracts?
Notes:
We know we need somewhere to run these things with no back door or trusted party.
We have seen some hints so far. Let's check them out.
---v
Diversity and Redundancy
- Geographical - for natural disasters and terrorist attacks
- Jurisdictional - to resist the incumbent governments - they are the ultimate server operators
- Moral - so all compasses are represented in the network, and no group can impose hegemony
- Of compute hardware - incase some is bugged or backdoored or prohibitively expensive
Notes:
Web2 gets a lot of this right. At least they are good at the first two and preventing accidental data loss etc. There is a lot to be kept from web 2. Some digital services, or subsystems of digital services may never even need web3 upgrades.
But indeed there is also some to be thrown out or improved.
---v
P2P Networking
Replace the operator with a system where peers all have power.
Notes:
We saw well how this worked out well in the file sharing and anonymous browsing domains (bit torrent,)
---v
Reproducible Execution
- Computers are better than courts
- PABs make distributed code execution practical
Notes:
We saw even back in the early 2000s with java web applets that allowing more people to run the same program is hugely useful.
A few decades later we have much better tech for this, and it is even more valuable.
PABs make it practical for diverse parties all over the world to run the same software deterministically on their bespoke hardware in their unique environments.
Blockchain
Solves ALL Your Problems

---v
Solves Some Specific Problems
Allows us to replace the central server operator with a P2P network and Consensus System
Notes:
Actually it is a fallacy that blockchain solves all our problems. It actually solves some very specific coordination problems. It also brings some efficiency improvements to modern bureaucracies. It does not automatically make everyone believe the same things or magically arrive in happy unicorn bunny land. Tomorrow and Thursday will dig in on how the blockchain and its P2P network work together.
---v
Blockchain Data structure

Notes:
We'll discuss two new blockchain related topics. First is the blockchain data structure which you can see here. This one is forked which is when things get really interesting, and when you need to invoke the second part
---v
Blockchain Consensus

Notes:
Consensus deals with how we agree which version of the data structure is real. It is an interesting and complex topic, but we first need to learn a bit more about how the data structure allows us to track a shared story.
---v
Reading Assignment
For tomorrow please read the bitcoin whitepaper
Wasm Smart Contracts in Ink!
How to use the slides - Full screen (new tab)
Wasm Smart Contracts in Ink!
A working programmer’s guide
Notes:
- ask questions during the lecture, don't wait until the end
- practical, but we go deeper where needed
- some complexity is omitted in the examples (examples are not a production code)
Intro: ink! vs. Solidity
| ink! | Solidity | |
|---|---|---|
| Virtual Machine | Any Wasm VM | EVM |
| Encoding | Wasm | EVM Byte Code |
| Language | Rust | Standalone |
| Constructors | Multiple | Single |
| Tooling | Anything that supports Rust | Custom |
| Storage | Variable | 256 bits |
| Interfaces? | Yes: Rust traits | Yes |
Notes:
- students are freshly of an EVM lecture so might be wondering why another SC language
- Virtual Machine: any Wasm VM: yes in theory, in practice bound pretty close to the platform it runs on (Substrate & the contracts pallet)
- Tooling: Solidity has been around for years, enjoys the first-to-market advantage (but ink! is a strong contender)
- The EVM operates on 256 bit words (meaning anything less than 32 bytes will be treated by the EVM as having leading zeros)
Intro: ink! overview
- DSL in Rust
- Inherits all the benefits of Rust
- Modern functional language
- Type & Memory safety
- Compiled to Wasm
- Ubiquitous
- Fast
Notes:
- ink! is not a separate language
- enjoys access to a vast collection of libraries developed for other purposes
- Wasm is targeting the browsers and quickly becoming the "assembly" od the web in lieu of JS
Intro: ink! & Substrate
Notes:
- Technically you could take a SC written in ink! and deploy it to any Wasm-powered blockchain.
- in practice not that straight-forward.
- ink! is closely tied to the larger Substrate framework.
- Substrate is a framework for developing customized blockchain runtimes from composable pallets.
Intro: ink! & Substrate
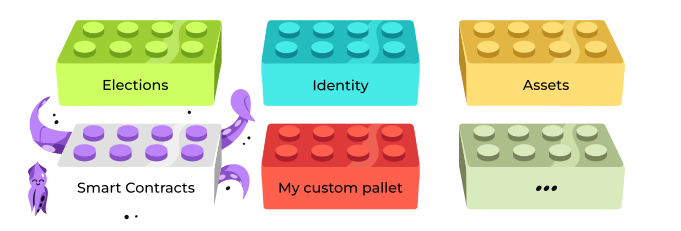
Notes:
- contracts written in ink! are compiled to Wasm bytecode
- pallet contracts provides
- instrumentation
- execution engine
- gas metering
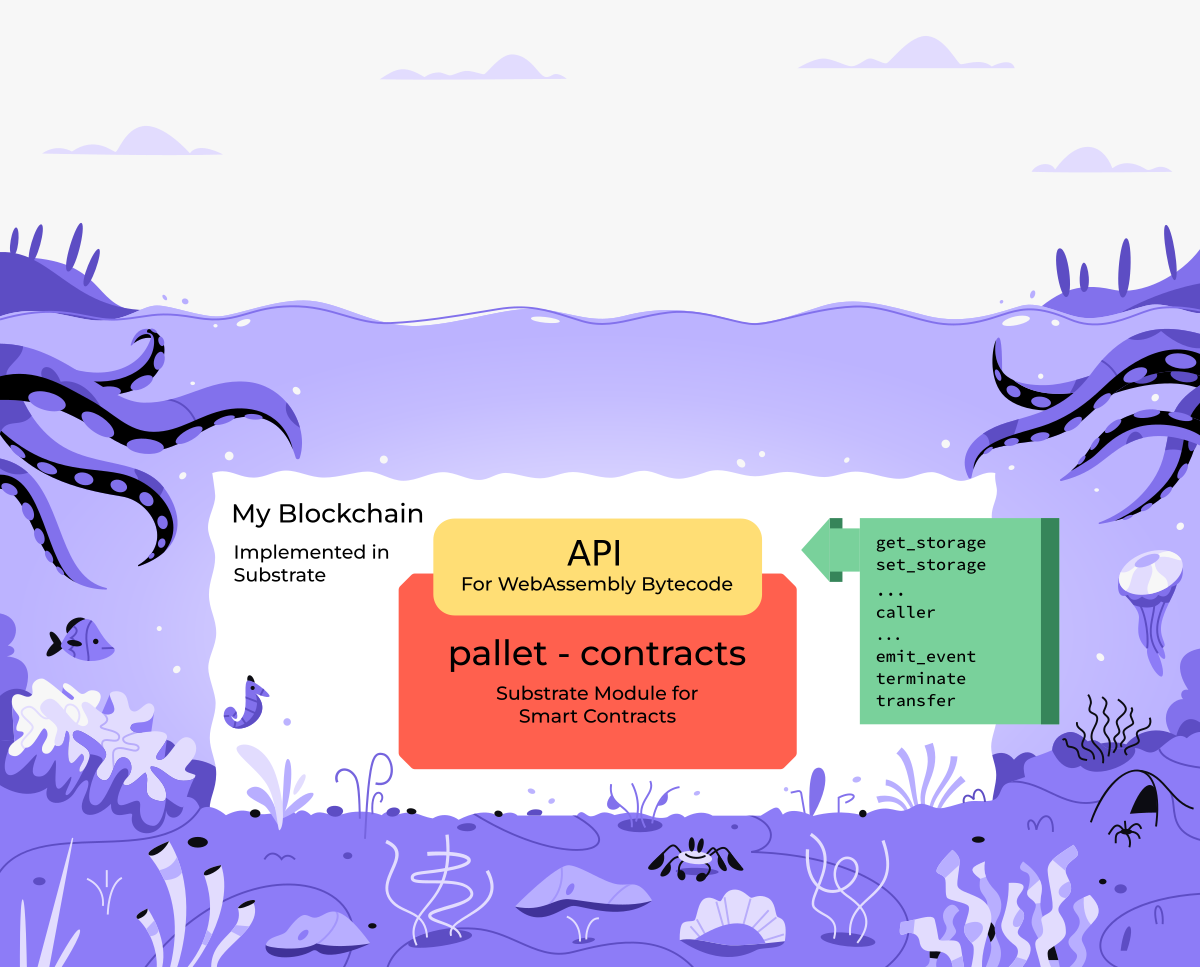
Notes:
- pallet contracts is oblivious to the programming language
- it accepts Wasm bytecode and executes it's instructions
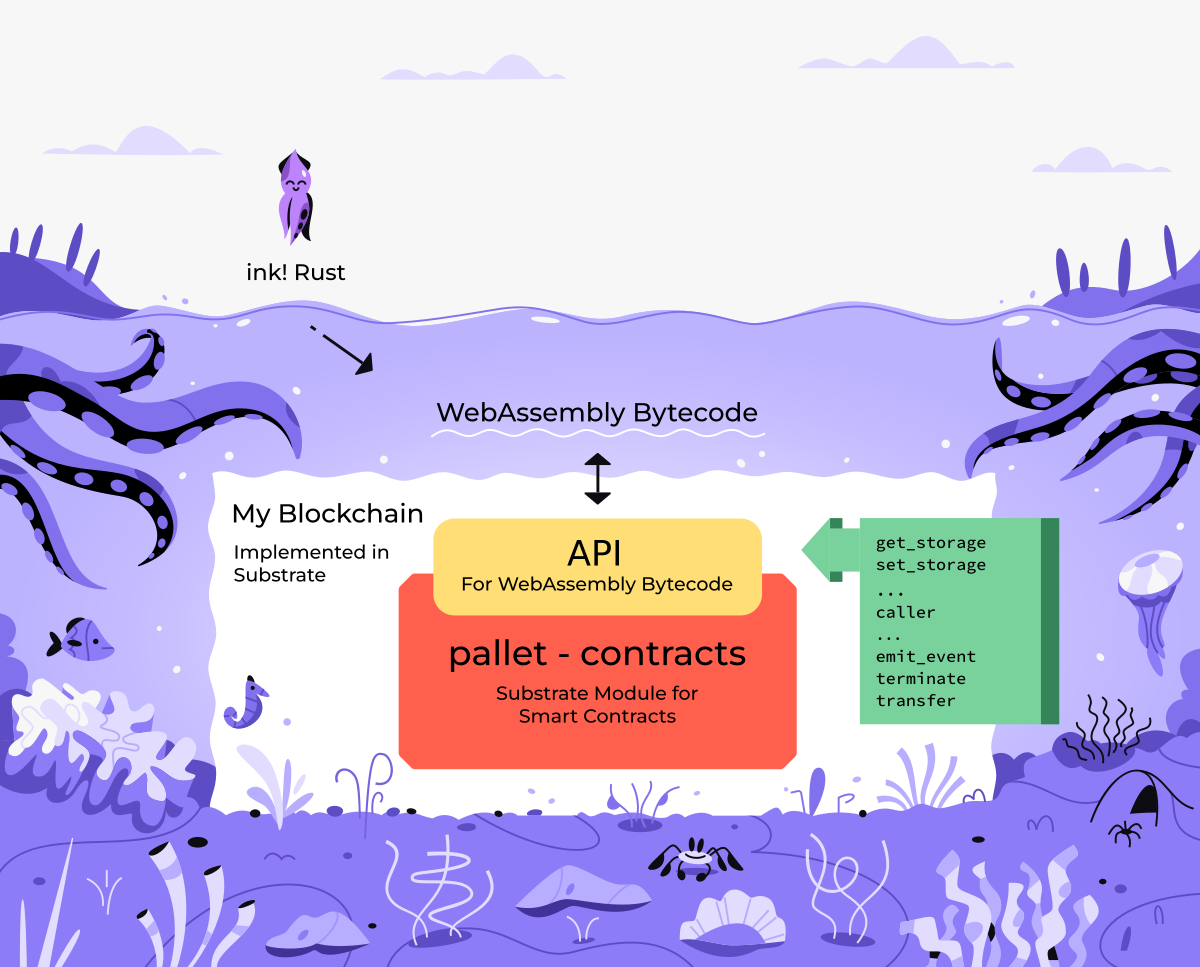
Notes:
- contracts itself can be written in ink!
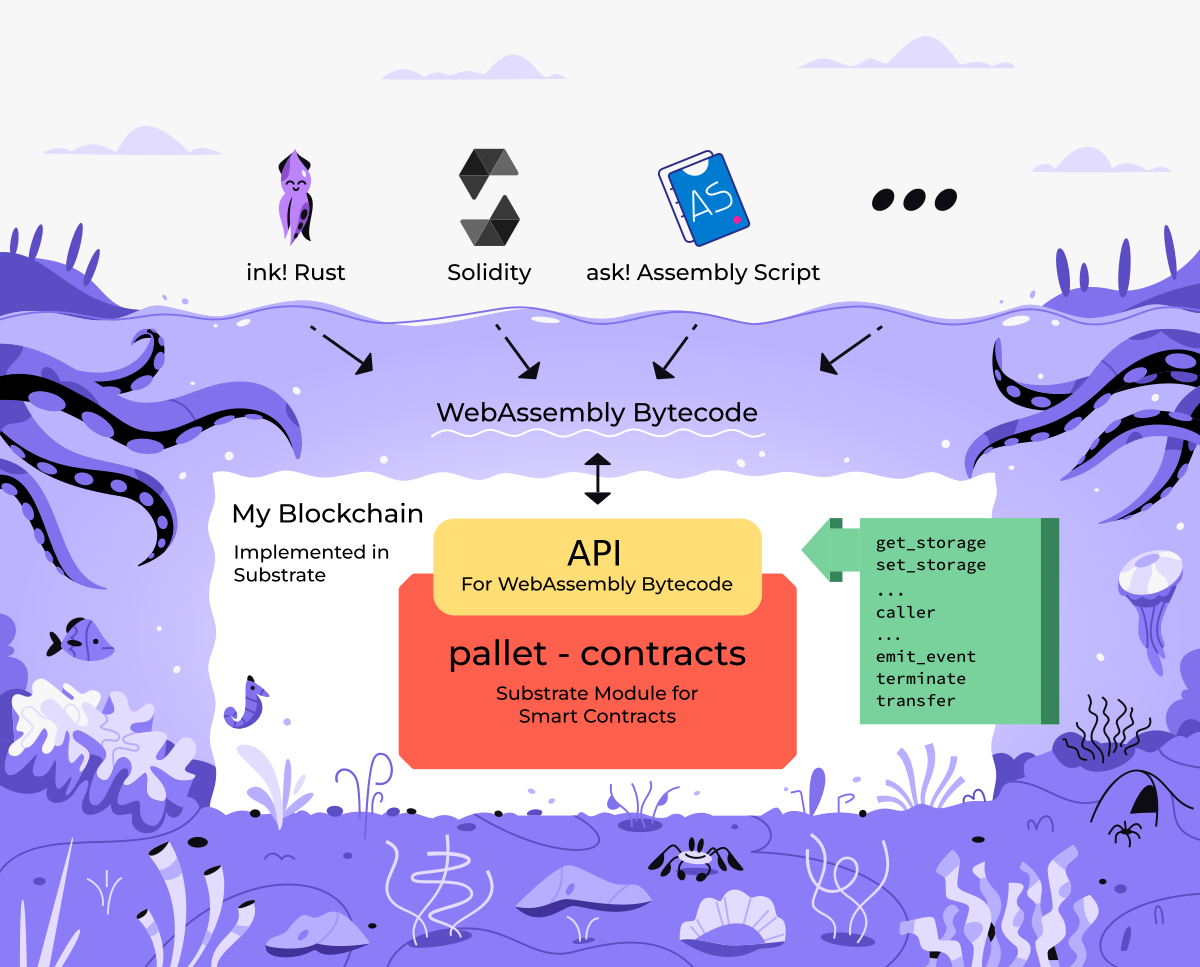
Notes:
- But also any other language that compilers to Wasm
- Solang
- or ask!
Development: Prerequisites
Install the required tooling
sudo apt install binaryen
rustup component add rust-src --toolchain nightly
rustup target add wasm32-unknown-unknown --toolchain nightly
cargo install dylint-link
cargo install cargo-contract --force
- binaryen is a compiler for WebAssembly.
- dylint-link adds DSL specific lints.
Notes:
- Binaryen is a compiler and toolchain infrastructure library for WebAssembly
- at the moment ink! uses a few unstable Rust features, thus nightly is require
- rust source code is needed to compile it to wasm
- wasm target is added
- cargo-contract is a batteries included CLI tool for compiling, deploying and interacting with the contracts
Development: cargo-contract
Create a contract
cargo contract new flipper
/home/CloudStation/Blockchain-Academy/flipper:
drwxrwxr-x 2 filip filip 4096 Jul 7 11:11 .
drwxr-xr-x 5 filip filip 4096 Jul 7 11:11 ..
-rwxr-xr-x 1 filip filip 573 Jul 7 11:11 Cargo.toml
-rwxr-xr-x 1 filip filip 285 Jul 7 11:11 .gitignore
-rwxr-xr-x 1 filip filip 5186 Jul 7 11:11 lib.rs
Notes:
- ask how many student have written some code in Rust, this should feel familiar to them
Development: Cargo.toml
[package]
version = "0.1.0"
authors = ["fbielejec"]
edition = "2021"
[dependencies]
ink = { version = "=4.2.1", default-features = false }
scale = { package = "parity-scale-codec", version = "3", default-features = false, features = ["derive"] }
scale-info = { version = "2.6", default-features = false, features = ["derive"], optional = true }
[lib]
path = "lib.rs"
[features]
default = ["std"]
std = [
"ink/std",
"scale/std",
"scale-info/std",
]
Notes:
- who knows why is the std library not included by default?
- Answer: contracts are compiled to Wasm (executed ib a sandboxed environment with no system interfaces, no IO, no networking)
Developing contracts
contract code
#![allow(unused)] fn main() { #[ink::contract] pub mod flipper { #[ink(storage)] pub struct Flipper { value: bool, } impl Flipper { #[ink(constructor)] pub fn new(init_value: bool) -> Self { Self { value: init_value } } #[ink(constructor)] pub fn default() -> Self { Self::new(Default::default()) } #[ink(message)] pub fn flip(&mut self) { self.value = !self.value; } #[ink(message)] pub fn get(&self) -> bool { self.value } } } }
Notes:
- basic contract that flips a bit in storage
- contract will have a storage definition, constructor(s), messages
- grouped in a module
Developing contracts: Compilation & artifacts
Compile:
cargo +nightly contract build
Artifacts:
[1/*] Building cargo project
Finished release [optimized] target(s) in 0.09s
The contract was built in RELEASE mode.
Your contract artifacts are ready.
You can find them in:
/home/CloudStation/Blockchain-Academy/flipper/target/ink
- flipper.contract (code + metadata)
- flipper.wasm (the contract's code)
- flipper.json (the contract's metadata)
Notes:
- produces Wasm bytecode and some additional artifacts:
- .wasm is the contract compiled bytecode
- .json is contract ABI aka metadata (for use with e.g. dapps)
- definitions of events, storage, transactions
- .contracts is both of these together
Developing contracts: instantiate
Deploy:
cargo contract instantiate --constructor default --suri //Alice
--skip-confirm --execute
Output:
Dry-running default (skip with --skip-dry-run)
Success! Gas required estimated at Weight(ref_time: 138893374, proof_size: 16689)
...
Event Contracts ➜ CodeStored
code_hash: 0xbf18c768eddde46205f6420cd6098c0c6e8d75b8fb042d635b1ba3d38b3d30ad
Event Contracts ➜ Instantiated
deployer: 5GrwvaEF5zXb26Fz9rcQpDWS57CtERHpNehXCPcNoHGKutQY
contract: 5EXm8WLAGEXn6zy1ebHZ4MrLmjiNnHarZ1pBBjZ5fcnWF3G8
...
Event System ➜ ExtrinsicSuccess
dispatch_info: DispatchInfo { weight: Weight { ref_time: 2142580978, proof_size: 9009 }, class: Normal, pays_fee: Yes }
Code hash 0xbf18c768eddde46205f6420cd6098c0c6e8d75b8fb042d635b1ba3d38b3d30ad
Contract 5EXm8WLAGEXn6zy1ebHZ4MrLmjiNnHarZ1pBBjZ5fcnWF3G8
Notes:
- we see a bunch of information on gas usage
- we see two events one for storing contract code another for instantiating the contract
- why is that?
- code & instance are separated, we will come back to that
- finally we see code hash and the newly created contracts address
Interacting with the contracts: queries
cargo contract call --contract 5EXm8WLAGEXn6zy1ebHZ4MrLmjiNnHarZ1pBBjZ5fcnWF3G8
--message get --suri //Alice --output-json
- contract state?
- tip:
defaultconstructor was called
Notes:
- who can tell me what will be the contract state at this point?
Interacting with the contracts: queries
"data": {
"Tuple": {
"ident": "Ok",
"values": [
{
"Bool": false
}
]
}
}
Interacting: transactions
Sign and execute a transaction:
cargo contract call --contract 5EXm8WLAGEXn6zy1ebHZ4MrLmjiNnHarZ1pBBjZ5fcnWF3G8
--message flip --suri //Alice --skip-confirm --execute
Query the state:
cargo contract call --contract 5EXm8WLAGEXn6zy1ebHZ4MrLmjiNnHarZ1pBBjZ5fcnWF3G8
--message get --suri //Alice --output-json
Result:
"data": {
"Tuple": {
"ident": "Ok",
"values": [
{
"Bool": true
}
]
}
}
Notes:
- if I query it again the bit is flipped
- no surprises there
Dev environment: Contracts UI
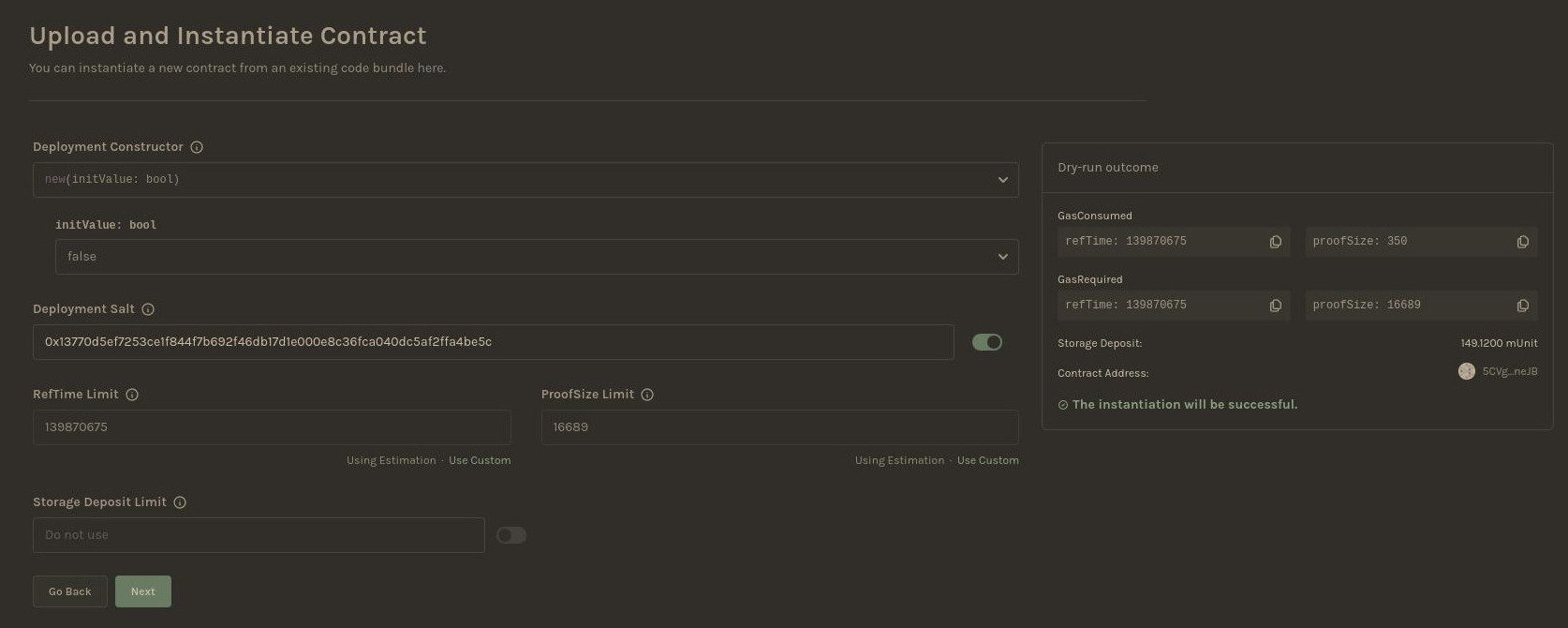
Notes:
- there is also a graphical env for deploying & interacting with contracts
- deploy & create an instance of flipper
Dev environment: Contracts UI
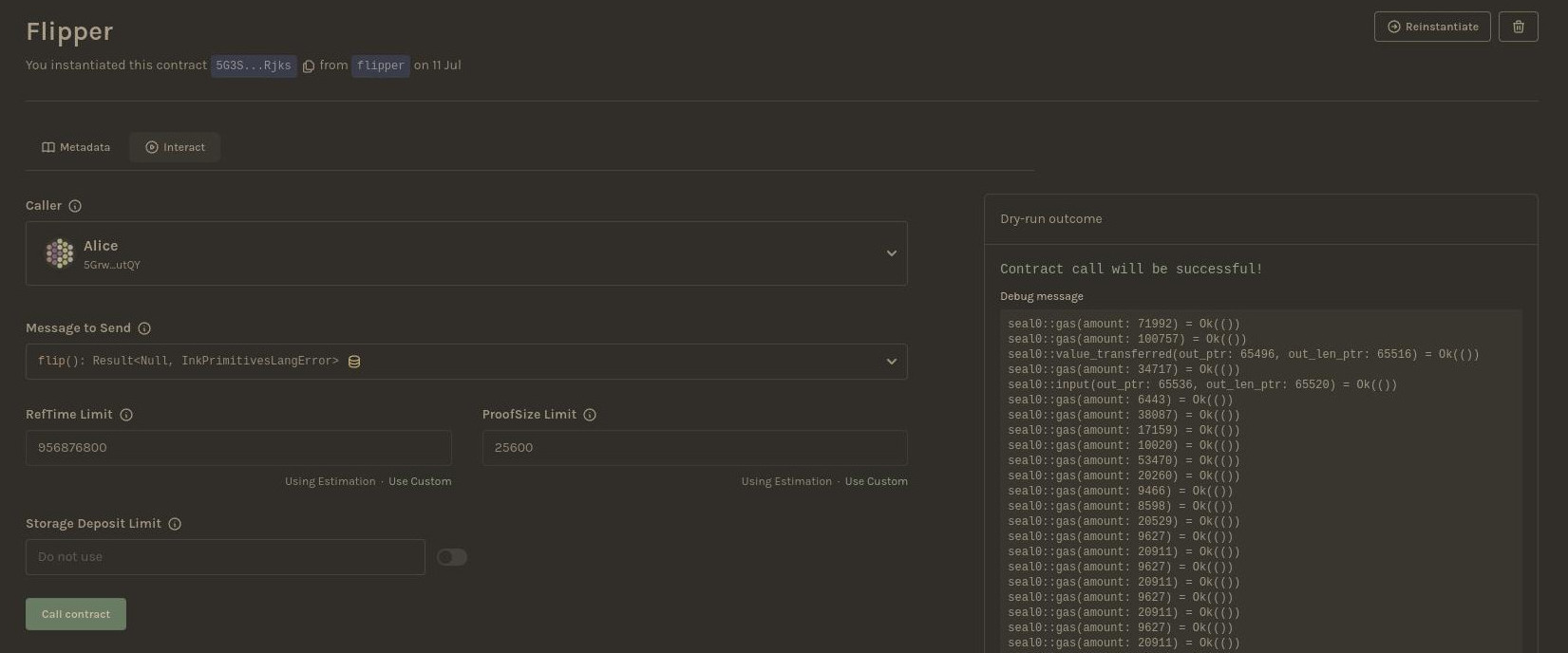
Notes:
- call a transaction
Dev environment: Contracts UI
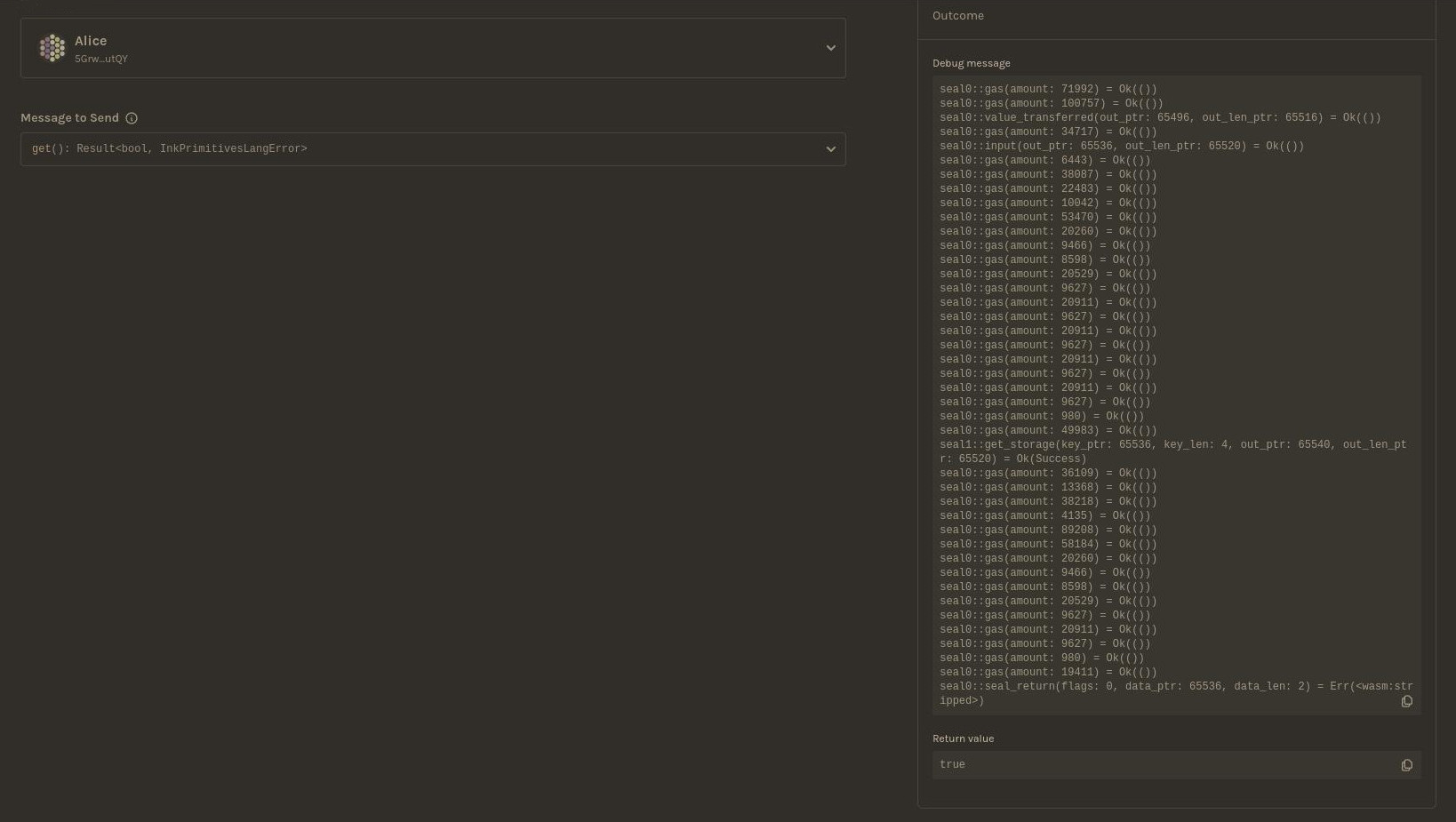
Notes:
- query state
Developing contracts: Constructors
#![allow(unused)] fn main() { #[ink(storage)] pub struct Flipper { value: bool, } #[ink(constructor)] pub fn new(init_value: bool) -> Self { Self { value: init_value } } #[ink(constructor)] pub fn default() -> Self { Self::new(Default::default()) } #[ink(constructor)] pub fn non_default() -> Self { Self::new(false) } }
Notes:
- lets dissect what a contract code is built like
- no limit of the number of constructors
- constructors can call other constructors
- constructors return the initial storage
- a lot of complexity conveniently hidden behind macros
Developing contracts: Queries
#![allow(unused)] fn main() { #[ink(message)] pub fn get(&self) -> bool { self.value } }
#[ink(message)]is how we tell ink! this is a function that can be called on the contract&selfis a reference to the contract's storage
Notes:
- returns information about the contract state stored on chain
- reaches to the storage, decodes it and returns the value
Developing contracts: Mutations
#![allow(unused)] fn main() { #[ink(message, payable)] pub fn place_bet(&mut self, bet_type: BetType) -> Result<()> { let player = self.env().caller(); let amount = self.env().transferred_value(); ... self.data.set(&data); ... }
&mut selfis a mutable reference to the object you’re calling this method onpayableallows receiving value as part of the call to the ink! message
Notes:
- constructors are inherently payable
- ink! message will reject calls with funds if it's not marked as such
- mutable references allow me to modify the storage.
- queries are for free, mutations are metered (you pay gas)
- you will also pay for queries within such transactions
Contracts: Error handling
#![allow(unused)] fn main() { pub enum MyResult<T, E> { Ok(value: T), Err(msg: E), } #[derive(Debug, PartialEq, Eq, Encode, Decode)] #[cfg_attr(feature = "std", derive(scale_info::TypeInfo))] pub enum MyError { InkEnvError(String), BettingPeriodNotOver, } #[ink(message)] pub fn spin(&mut self) -> Result<()> { if !self.is_betting_period_over() { return Err(MyError::BettingPeriodNotOver); ... }; pub type Result<T> = core::result::Result<T, MyError>; }
- ink! uses idiomatic Rust error handling:
Result<T,E>type - Use the Err variant to pass your own semantics
- Type aliases reduce boilerplate & enhance readability
Notes:
- ink! uses idiomatic Rust error handling
messages are thesystem boundary- returning error variant or panicing reverts the transaction
- panicing is the same as returning Err variant (
Resultis just being nice)
- panicing is the same as returning Err variant (
Error handling: call stack
#![allow(unused)] fn main() { #[ink(message)] pub fn flip(&mut self) { self.value = !self.value; if self.env().block_number() % 2 != 0 { panic!("Oh no!") } } }
- what is the state of this contract if the tx is called in an odd block number?
Notes:
- answer: whatever it was prior to the tx:
- returning error variant reverts the entire tx on the call stack
Contracts: Events
#![allow(unused)] fn main() { #[ink(event)] #[derive(Debug)] pub struct BetPlaced { #[ink(topic)] player: AccountId, #[ink(topic)] bet_type: BetType, amount: Balance, } }
- Events are a way of letting the outside world know about what's happening inside the contract.
#[ink(event)]is a macro that defines events.- Topics mark fields for indexing.
Notes:
- events are especially important for dapps
- storage is expensive: reading e.g. aggregate data from chain directly is impossible / impractical
- dapps the can listen to the event, normalize & store off-chain and answer e.g. complex queries
Contracts: Events
#![allow(unused)] fn main() { #[ink(message)] pub fn flip(&mut self) { Self::emit_event( self.env(), Event::Flipped(Flipped { }), ); self.value = !self.value; if self.env().block_number() % 2 == 0 { panic!("Oh no!") } } }
- What happens to the events from reverted transactions?
- Will this event be emitted in an odd block?
Notes:
- answer: yes, but only because I reverted the condition :)
Contracts: Defining shared behaviour
#![allow(unused)] fn main() { #[ink::trait_definition] pub trait PSP22 { #[ink(message)] fn total_supply(&self) -> Balance; #[ink(message)] fn balance_of(&self, owner: AccountId) -> Balance; #[ink(message)] fn approve(&mut self, spender: AccountId, amount: Balance) -> Result<(), PSP22Error>; #[ink(message)] fn transfer(&mut self, to: AccountId, value: Balance, data: Vec<u8>) -> Result<(), PSP22Error>; ... impl SimpleDex { use psp22_trait::{PSP22Error, PSP22}; /// Returns balance of a PSP22 token for an account fn balance_of(&self, token: AccountId, account: AccountId) -> Balance { let psp22: ink::contract_ref!(PSP22) = token.into(); psp22.balance_of(account) } ... }
- Trait Definition:
#[ink::trait_definition]. - Sharing the trait definition to do a cross-contract call.
Notes:
- (part of) PSP22 (ERC20 like) contract definition
- all contracts that respect this definition need to implement it
- you can now share the trait definition with other contracts
- while getting a typed reference to an instance
Deeper dive: Storage
#![allow(unused)] fn main() { use ink::storage::Mapping; #[ink(storage)] #[derive(Default)] pub struct Token { total_supply: Balance, balances: Mapping<AccountId, Balance>, allowances: Mapping<(AccountId, AccountId), Balance>, } }
Notes:
- now that we dipped our toes lets dissect more
- starting with the storage
- what does this code actually put into the chain storage?

SCALE (Simple Concatenated Aggregate Little Endian)
Notes:
- Pallet contracts storage is organized like a key-value database
- each storage cell has a unique storage key and points to a SCALE encoded value
- SCALE codec is not self-describing (vide metadata)
SCALE: examples of different types
| Type | Decoding | Encoding | Remark |
|---|---|---|---|
| Boolean | true | 0x0 | encoded using least significant bit of a single byte |
| false | 0x1 | ||
| Unsigned int | 42 | 0x2a00 | |
| Enum | enum IntOrBool { Int(u8), Bool(bool)} | 0x002a and 0x0101 | first byte encodes the variant index, remaining bytes encode the data |
| Tuple | (3, false) | 0x0c00 | concatenation of each encoded value |
| Vector | [4, 8, 15, 16, 23, 42] | 0x18040008000f00100017002a00 | encoding of the vector length followed by conatenation of each item's encoding |
| Struct | {x:30u64, y:true} | [0x1e,0x0,0x0,0x0,0x1] | names are ignored, Vec |
Notes:
- this table is not exhaustive
- struct example: stored as an vector, names are ignored, only order matters, first four bytes encode the 64-byte integer and then the least significant bit of the last byte encodes the boolean
Storage: Packed Layout
#![allow(unused)] fn main() { use ink::storage::Mapping; #[ink(storage)] #[derive(Default)] pub struct Token { total_supply: Balance, balances: Mapping<AccountId, Balance>, allowances: Mapping<(AccountId, AccountId), Balance>, } }
- By default ink! stores all storage struct fields under a single storage cell (
Packedlayout)
Notes:
- We talked about the kv database that the storage is, now how is it used precisely
- Types that can be stored entirely under a single storage cell are called Packed Layout
- by default ink! stores all storage struct fields under a single storage cell
- as a consequence message interacting with the contract storage will always need to read and decode the entire contract storage struct
- .. which may be what you want or not
Storage: Packed Layout
#![allow(unused)] fn main() { use ink::storage::traits::{ StorageKey, ManualKey, }; #[ink(storage)] pub struct Flipper<KEY: StorageKey = ManualKey<0xcafebabe>> { value: bool, } }
- The storage key of the contracts root storage struct defaults to
0x00000000 - However you may store it under any arbitrary 4 bytes key instead
Storage: Packed Layout
"storage": {
"root": {
"layout": {
"struct": {
"fields": [
{
"layout": {
"leaf": {
"key": "0xcafebabe",
"ty": 0
}
},
"name": "value"
}
],
"name": "Flipper"
}
},
"root_key": "0xcafebabe"
}
}
Notes:
- demonstration of the packed layout - value is stored under the root key
Storage: Un-packed Layout
#![allow(unused)] fn main() { use ink::storage::Mapping; #[ink(storage)] #[derive(Default)] pub struct Token { total_supply: Balance, balances: Mapping<AccountId, Balance>, allowances: Mapping<(AccountId, AccountId), Balance>, } }
- Mapping consists of a key-value pairs stored directly in the contract storage cells.
- Each Mapping value lives under it's own storage key.
- Mapping values do not have a contiguous storage layout: it is not possible to iterate over the contents of a map!
Notes:
- Use Mapping when you need to store a lot of values of the same type.
- if your message only accesses a single key of a Mapping, it will not load the whole mapping but only the value being accessed.
- there are other collection types in ink!: HashMap or BTreeMap (to name a few).
- these data structures are all Packed, unlike Mapping!
Storage: working with Mapping
#![allow(unused)] fn main() { pub fn transfer(&mut self) { let caller = self.env().caller(); let balance = self.balances.get(caller).unwrap_or(0); let endowment = self.env().transferred_value(); balance += endowment; } }
- what is wrong here?
Notes:
- working with mapping:
- Answer: Mapping::get() method will result in an owned value (a local copy), as opposed to a direct reference into the storage. Changes to this value won't be reflected in the contract's storage "automatically". To avoid this common pitfall, the value must be inserted again at the same key after it was modified. The transfer function from above example illustrates this:
Storage: working with Mapping
#![allow(unused)] fn main() { pub fn transfer(&mut self) { let caller = self.env().caller(); let balance = self.balances.get(caller).unwrap_or(0); let endowment = self.env().transferred_value(); self.balances.insert(caller, &(balance + endowment)); } }
Mapping::get()returns a local copy, not a mutable reference to the storage!
Notes:
- working with mapping:
Mapping::get()method will result in an owned value (a local copy).- Changes to this value won't be reflected in the contract's storage at all!
- you need to inserted it again at the same key.
Storage: Lazy
#![allow(unused)] fn main() { use ink::storage::{traits::ManualKey, Lazy, Mapping}; #[ink(storage)] pub struct Roulette { pub data: Lazy<Data, ManualKey<0x44415441>>, pub bets: Mapping<u32, Bet, ManualKey<0x42455453>>, } }
- Every type wrapped in
Lazyhas a separate storage cell. ManualKeyassignes explicit storage key to it.- Why would you want to use a
ManualKeyinstead of a generated one?
Notes:
- packed layout can get problematic if we're storing a large collection in the contracts storage that most of the transactions do not need access too
- there is a 16kb hard limit on a buffer used for decoding, contract trying to decode more will trap / revert
- lazy provides per-cell access, like a mapping
- lazy storage cell can be auto-assigned or chosen manually
- using ManualKey instead of AutoKey might be especially desirable for upgradable contracts, as using AutoKey might result in a different storage key for the same field in a newer version of the contract.
- This may break your contract after an upgrade!
Storage: Lazy

Notes:
- only the pointer (the key) to the lazy type is stored under the root key.
- only when there is a read of
dwill the pointer be de-referenced and it's value decoded. - lazy is a bit of a mis-nomer here, because storage is already initialized.
Contracts upgradeability: set_code_hash
#![allow(unused)] fn main() { #[ink(message)] pub fn set_code(&mut self, code_hash: [u8; 32]) -> Result<()> { ink::env::set_code_hash(&code_hash)?; Ok(()) } }
- Within SC's lifecycle it is often necessary to perform an upgrade or a bugfix.
- Contract's code and it's instance are separated.
- Contract's address can be updated to point to a different code stored on-chain.
Notes:
- append only != immutable
- proxy pattern known from e.g. solidity is still possible
- within the Substrate framework contract's code is stored on-chain and it's instance is a pointer to that code
- incentivizes cleaning up after oneself
- big storage optimization
Contracts upgradeability: access control
#![allow(unused)] fn main() { #[ink(message)] pub fn set_code(&mut self, code_hash: [u8; 32]) -> Result<()> { ensure_owner(self.env().caller())?; ink::env::set_code_hash(&code_hash)?; Ok(()) } }
Notes:
- you DO NOT want to leave this message un-guarded
- solutions to
ensure_ownercan range from a very simple ones address checks - to a multiple-role database of access controlled accounts stored and maintained in a separate contract
Upgradeability: storage
#![allow(unused)] fn main() { #[ink(message)] pub fn get_values(&self) -> (u32, bool) { (self.x, self.y) } #[ink(storage)] pub struct MyContractOld { x: u32, y: bool, } #[ink(storage)] pub struct MyContractNew { y: bool, x: u32, } }
- Make sure your updated code is compatible with the existing contracts state.
- Will the getter work with the new definition and the old storage ?
Notes:
- Various potential changes that can result in backwards incompatibility:
- Changing the order of variables
- Introducing new variable(s) before any of the existing ones
- Changing variable type(s)
- Removing variables
- Answer: no, SCALE encoding is oblivious to names, only order matters
Upgradeability: storage migrations
#![allow(unused)] fn main() { // new contract code #[ink(message)] pub fn migrate(&mut self) -> Result<()> { if let Some(OldContractState { field_1, field_2 }) = get_contract_storage(&123)? { self.updated_old_state.set(&UpdatedOldState { field_1: field_2, field_2: field_1, }); return Ok(()); } return Err(Error::MigrationFailed); } // old contract code #[ink(message)] pub fn set_code(&mut self, code_hash: [u8; 32], callback: Option<Selector>) }
Notes:
- if the new contract code does not match the stored state you can perform a storage migration
- think of regular relational DB and schema migrations
- a good pattern to follow is to perform the update and the migration in one atomic transaction:
- if anything fails whole tx is reverted
- won't end up in a broken state
- make sure it can fit into one block!
Common Vulnerabilities
#![allow(unused)] fn main() { impl MyContract { #[ink(message)] pub fn terminate(&mut self) -> Result<()> { let caller = self.env().caller(); self.env().terminate_contract(caller) } ... } }
- What is wrong with this contract?
- How would you fix it?
Notes:
- we start easy
- answer: no AC in place
- parity wallet 150 million
hack
Common Vulnerabilities: blast from the past
Notes:
- might seem trivial but a very similar hack has happend in the past trapping a lot of funds
- see: https://etherscan.io/address/0x863df6bfa4469f3ead0be8f9f2aae51c91a907b4#code
- hacker has "accidentally" called an unprotected
initMultiownedand proceeded to delete the contract code
Common Vulnerabilities
#![allow(unused)] fn main() { #[ink(storage)] pub struct SubstrateNameSystem { registry: Mapping<AccountId, Vec<u8>>, } impl SubstrateNameSystem { #[ink(message, payable)] pub fn register(&mut self, name: Vec<u8>) { let owner = self.env().caller(); let fee = self.env().transferred_value(); if !self.registry.contains(owner) && fee >= 100 { self.registry.insert(owner, &name); } } }
- On-chain domain name registry with a register fee of 100 pico.
- Why is this a bad idea?
Notes:
- everything on-chain is public
- this will be front-run in no time
- Can you propose a better design?
- Answer: commit / reveal or an auction
Common Vulnerabilities
#![allow(unused)] fn main() { #[ink(message)] pub fn swap( &mut self, token_in: AccountId, token_out: AccountId, amount_token_in: Balance, ) -> Result<(), DexError> { let this = self.env().account_id(); let caller = self.env().caller(); let amount_token_out = self.out_given_in(token_in, token_out, amount_token_in)?; // transfer token_in from user to the contract self.transfer_from_tx(token_in, caller, this, amount_token_in)?; // transfer token_out from contract to user self.transfer_tx(token_out, caller, amount_token_out)?; ... } }
- Contract is a DEX Decentralized EXchange, follows the popular AMM (Automated Market Maker) design.
- Tx swaps the specified amount of one of the pool's PSP22 tokens to another PSP22 token according to the current price.
- What can go wrong here?
Notes:
Answer:
- no slippage protection in place.
- bot will frontrun the victim's tx by purchasing token_out before the trade is executed.
- this purchase will raise the price of the asset for the victim trader and increases his slippage
- if the bot sells right after the victims tx (back runs the victim) this is a sandwich attack
Common Vulnerabilities
#![allow(unused)] fn main() { #[ink(message)] pub fn swap( &mut self, token_in: AccountId, token_out: AccountId, amount_token_in: Balance, min_amount_token_out: Balance, ) -> Result<(), DexError> { ... if amount_token_out < min_amount_token_out { return Err(DexError::TooMuchSlippage); } ... } }
Notes:
- slippage protection in place
Common Vulnerabilities
- Integer overflows
- Re-entrancy vulnerabilities
- Sybil attacks
- ...
- Regulatory attacks 😅
- ...
Notes:
- long list of possible attacks
- too long to fit into one lecture
- baseline: get an audit from a respectable firm
- publish your source code (security by obscurity is not security)
Pause
Optional challenge: github.com/Polkadot-Blockchain-Academy/adder
Notes:
Piotr takes over to talk about making runtime calls from contracts and writing automated tests. There is a 15 minute challenge for you in the meantime.
Interacting with the execution environment
#![allow(unused)] fn main() { impl MyContract { ... #[ink(message)] pub fn terminate(&mut self) -> Result<()> { let caller = self.env().caller(); self.env().terminate_contract(caller) } ... } }
Blockchain node onion
Blockchain node onion

Blockchain node onion

- networking
- block production, dissemination, finalization
- storage management
- off-chain maintenance, querying, indexing
Blockchain node onion

- computing new state based on the previous one and a single transaction
Blockchain node onion

- executing contract calls
Standard API
caller()account_id()balance()block_number()emit_event(event: Event)transfer(dest: AccountId, value: Balance)hash_bytes(input: &[u8], output: &mut [u8])debug_message(msg: &str)- and many more
Standard API
#![allow(unused)] fn main() { impl MyContract { ... #[ink(message)] pub fn terminate(&mut self) -> Result<()> { let caller = self.env().caller(); self.env().terminate_contract(caller) } ... } }
Interacting with the state transition function
- token transfer
- staking
- voting
- contract call
- ...
- advanced cryptography
- bypassing standard restrictions
- outsourcing computation
- ...
Interacting with the state transition function
- advanced cryptography
- bypassing standard restrictions
- outsourcing computation
- ...
chain extension
Runtime
In Polkadot ecosystem state transition function is called runtime
Calling runtime
#![allow(unused)] fn main() { #[ink(message)] pub fn transfer_through_runtime( &mut self, receiver: AccountId, value: Balance, ) -> Result<(), RuntimeError> { let call_object = RuntimeCall::Balances(BalancesCall::Transfer { receiver, value, }); self.env().call_runtime(&call_object) } }
Calling runtime
#![allow(unused)] fn main() { #[ink(message)] pub fn transfer_through_runtime( &mut self, receiver: AccountId, value: Balance, ) -> Result<(), RuntimeError> { let call_object = RuntimeCall::Balances(BalancesCall::Transfer { receiver, value, }); self.env().call_runtime(&call_object) } }
Chain extensions
Chain extension is a way to extend the runtime with custom functionalities dedicated to contracts.
Chain extensions
ink! side:
- provide
ChainExtensiontrait - include extension in the
Environmenttrait instantiation
runtime side:
- handling extension calls
- extension logic itself
Provide ChainExtension trait
#![allow(unused)] fn main() { #[ink::chain_extension] pub trait OutsourceHeavyCrypto { type ErrorCode = OutsourcingErr; #[ink(extension = 41)] fn outsource(input: Vec<u8>) -> [u8; 32]; } pub enum OutsourcingErr { IncorrectData, } impl ink::env::chain_extension::FromStatusCode for OutsourcingErr { fn from_status_code(status_code: u32) -> Result<(), Self> { match status_code { 0 => Ok(()), 1 => Err(Self::IncorrectData), _ => panic!("encountered unknown status code"), } } } }
Provide ChainExtension trait
#![allow(unused)] fn main() { #[ink::chain_extension] pub trait OutsourceHeavyCrypto { type ErrorCode = OutsourcingErr; #[ink(extension = 41)] fn outsource(input: Vec<u8>) -> [u8; 32]; } pub enum OutsourcingErr { IncorrectData, } impl ink::env::chain_extension::FromStatusCode for OutsourcingErr { fn from_status_code(status_code: u32) -> Result<(), Self> { match status_code { 0 => Ok(()), 1 => Err(Self::IncorrectData), _ => panic!("encountered unknown status code"), } } } }
Include extension in the Environment trait instantiation
#![allow(unused)] fn main() { pub enum EnvironmentWithOutsourcing {} impl Environment for EnvironmentWithOutsourcing { ... // use defaults from `DefaultEnvironment` type ChainExtension = OutsourceHeavyCrypto; } #[ink::contract(env = crate::EnvironmentWithOutsourcing)] mod my_contract { ... } }
Include extension in the Environment trait instantiation
#![allow(unused)] fn main() { #[ink::contract(env = crate::EnvironmentWithOutsourcing)] mod my_contract { fn process_data(&mut self, input: Vec<u8>) -> Result<(), OutsourcingErr> { self.env().extension().outsource(subject) } } }
Handling extension calls
#![allow(unused)] fn main() { pub struct HeavyCryptoOutsourcingExtension; impl ChainExtension<Runtime> for HeavyCryptoOutsourcingExtension { fn call<E: Ext>(&mut self, env: Env) -> Result<RetVal, DispatchError> { match env.func_id() { 41 => internal_logic(), _ => { error!("Called an unregistered `func_id`: {func_id}"); return Err(DispatchError::Other("Unimplemented func_id")) } } Ok(RetVal::Converging(0)) } }
Chain extension: reaching even further

Testing contracts
Testing contracts
Testing contracts

Unit tests
#![allow(unused)] fn main() { #[ink::test] fn erc20_transfer_works() { let mut erc20 = Erc20::new(100); assert_eq!(erc20.balance_of(BOB), 0); // Alice transfers 10 tokens to Bob. assert_eq!(erc20.transfer(BOB, 10), Ok(())); // Bob owns 10 tokens. assert_eq!(erc20.balance_of(BOB), 10); let emitted_events = ink::env::test::recorded_events().collect::<Vec<_>>(); assert_eq!(emitted_events.len(), 2); // Check first transfer event related to ERC-20 instantiation. assert_transfer_event( &emitted_events[0], None, Some(ALICE), 100, ); // Check the second transfer event relating to the actual transfer. assert_transfer_event( &emitted_events[1], Some(ALICE), Some(BOB), 10, ); } }
Unit tests
#![allow(unused)] fn main() { #[ink::test] fn erc20_transfer_works() { let mut erc20 = Erc20::new(100); assert_eq!(erc20.balance_of(BOB), 0); // Alice transfers 10 tokens to Bob. assert_eq!(erc20.transfer(BOB, 10), Ok(())); // Bob owns 10 tokens. assert_eq!(erc20.balance_of(BOB), 10); let emitted_events = ink::env::test::recorded_events().collect::<Vec<_>>(); assert_eq!(emitted_events.len(), 2); // Check first transfer event related to ERC-20 instantiation. assert_transfer_event( &emitted_events[0], None, Some(ALICE), 100, ); // Check the second transfer event relating to the actual transfer. assert_transfer_event( &emitted_events[1], Some(ALICE), Some(BOB), 10, ); } }
Unit tests
#![allow(unused)] fn main() { #[ink::test] fn erc20_transfer_works() { let mut erc20 = Erc20::new(100); assert_eq!(erc20.balance_of(BOB), 0); // Alice transfers 10 tokens to Bob. assert_eq!(erc20.transfer(BOB, 10), Ok(())); // Bob owns 10 tokens. assert_eq!(erc20.balance_of(BOB), 10); let emitted_events = ink::env::test::recorded_events().collect::<Vec<_>>(); assert_eq!(emitted_events.len(), 2); // Check first transfer event related to ERC-20 instantiation. assert_transfer_event( &emitted_events[0], None, Some(ALICE), 100, ); // Check the second transfer event relating to the actual transfer. assert_transfer_event( &emitted_events[1], Some(ALICE), Some(BOB), 10, ); } }
E2E tests
#![allow(unused)] fn main() { #[ink_e2e::test] async fn e2e_transfer(mut client: ink_e2e::Client<C, E>) -> E2EResult<()> { let constructor = Erc20Ref::new(total_supply); let erc20 = client .instantiate("erc20", &ink_e2e::alice(), constructor, 0, None) .await .expect("instantiate failed"); let mut call = erc20.call::<Erc20>(); let total_supply_msg = call.total_supply(); let total_supply_res = client .call_dry_run(&ink_e2e::bob(), &total_supply_msg, 0, None) .await; ... } }
E2E tests
#![allow(unused)] fn main() { #[ink_e2e::test] async fn e2e_transfer(mut client: ink_e2e::Client<C, E>) -> E2EResult<()> { let constructor = Erc20Ref::new(total_supply); let erc20 = client .instantiate("erc20", &ink_e2e::alice(), constructor, 0, None) .await .expect("instantiate failed"); let mut call = erc20.call::<Erc20>(); let total_supply_msg = call.total_supply(); let total_supply_res = client .call_dry_run(&ink_e2e::bob(), &total_supply_msg, 0, None) .await; ... } }
E2E tests
#![allow(unused)] fn main() { #[ink_e2e::test] async fn e2e_transfer(mut client: ink_e2e::Client<C, E>) -> E2EResult<()> { let constructor = Erc20Ref::new(total_supply); let erc20 = client .instantiate("erc20", &ink_e2e::alice(), constructor, 0, None) .await .expect("instantiate failed"); let mut call = erc20.call::<Erc20>(); let total_supply_msg = call.total_supply(); let total_supply_res = client .call_dry_run(&ink_e2e::bob(), &total_supply_msg, 0, None) .await; ... } }
E2E pipeline: traps, traps everywhere
- Preparing and encoding transaction data (client side)
- Signing the transaction (client side)
- Sending transaction to a node (client side)
- Block and event subscribing (client side)
- Transaction pool processing (node side)
- Block building (node side)
- Block dissemination (node side)
- Import queue processing (node side)
- Block finalizing (node side)
- Block execution (node side)
- Transaction execution (runtime side)
- Event emitting (node side)
- Event capturing (client side)
- Event processing (client side)
- State fetching via RPC calling (client side)
- State report (node side)
- State validation (client side)
E2E pipeline: traps, traps everywhere

Test core
- Preparing and encoding transaction data (given)
- Transaction execution (when)
- State validation (then)
quasi-E2E tests
Interact directly with runtime, skipping node layer.
quasi-E2E tests
#![allow(unused)] fn main() { #[test] fn flipping() -> Result<(), Box<dyn Error>> { let init_value = Session::<MinimalRuntime>::new(transcoder())? .deploy_and(bytes(), "new", &["true".to_string()], vec![])? .call_and("flip", &[])? .call_and("flip", &[])? .call_and("flip", &[])? .call_and("get", &[])? .last_call_return() .expect("Call was successful"); assert_eq!(init_value, ok(Value::Bool(false))); Ok(()) } }
Local playing with contracts using drink-cli
🧬 Substrate
The blockchain framework canonical to Polkadot and Parachains covered in depth, at a lower level.
Introduction to Substrate
How to use the slides - Full screen (new tab)
Introduction to Substrate
Before Going Any Further 🛑
While I speak, please clone polkadot-sdk, and run cargo build && cargo build --release.
About These Lectures and Lecturer
- Ground-up, low-level, but hands-on.
- Intentionally avoiding FRAME, but giving you the tools to be successful at it.
- Narratives above facts all.
- Interrupts and questions are always welcome.
What is Substrate?
Substrate is a Rust framework for building blockchains.
---v
Why Substrate?

Notes:
Highlight the multi-chain part.
---v
Why Substrate?

Notes:
Polkadot is the biggest bet in this ecosystem against chain maximalism, and Substrate plays a big role in this scenario.
---v
Why Substrate?
- ⛓️ Future is multi-chain.
- 😭 Building a blockchain is hard. Upgrading it even harder.
- 💡 Framework!
- 🧐 But which attitude to take?
Core Philosophies of Substrate 💭
The pre-substrate way of thinking:
- 😭 Building a blockchain is hard. Upgrading it even harder.
- 💪🏻 We are going to spend maximal resources at making sure we get it right.
---v
Core Philosophies of Substrate 💭
But has this worked?
- 😭 Bitcoin block size debate
- 2️⃣ L2s and beyond
- 📈 Ethereum gas price
Notes:
Bitcoin block size has never been and is an ongoing debate.
I am not against L2s per se, but it is true that they mostly exist because the underlying protocol is too hard/slow to upgrade itself. ETH Gas prices also show that the underlying protocol cannot meet the demands of today.
https://en.wikipedia.org/wiki/Bitcoin_scalability_problem https://ycharts.com/indicators/ethereum_average_gas_price
---v
Core Philosophies of Substrate 💭
The Substrate way of thinking:
- ☯️ Society and technology evolve
- 🦸 Humans are fallible
- 🧠 Best decision of today -> mistake of tomorrow
---v
Core Philosophies of Substrate 💭
Outcomes of this:
- 🦀 Rust
- 🤩 Generic, Modular and Extensible Design
- 🏦 Governance + Upgradeability
Notes:
Think about how each of these links back to "whatever you decide today will be a mistake soon".
🦀 Rust
- First line of defense: prevent human error when possible.
- Safe language, no memory safety issues.
Notes:
So at least we don't want to deal with human error, and only deal with the fact that we cannot predict the future.
Memory safety is a fundamental issue in most major system-level programming languages.
Some such mistakes are impossible to make in Rust.
---v
🦀 Rust
int main() {
int* x = malloc(sizeof(int));
*x = 10;
int* y = x;
free(x);
printf("%d\n", *y); // Accessing memory after it's been freed
}
fn main() { let x = Box::new(10); let y = x; println!("{}", *y); // ❌ }
Notes:
another one:
int* foo() {
int x = 10;
return &x;
}
int main() {
int* y = foo();
printf("%d\n", *y); // Accessing memory out of its scope
}
fn foo() -> &'static i32 { let x = 10; &x } fn main() { let y = foo(); println!("{}", y); // ❌ }
---v
🦀 Rust
Microsoft and Google have each stated that software memory safety issues are behind around 70 percent of their vulnerabilities.
Notes:
---v
🦀 Rust
- 🏎️ Most Rust abstractions are zero-cost.
- ⏰ Rust has (almost) no "runtime".
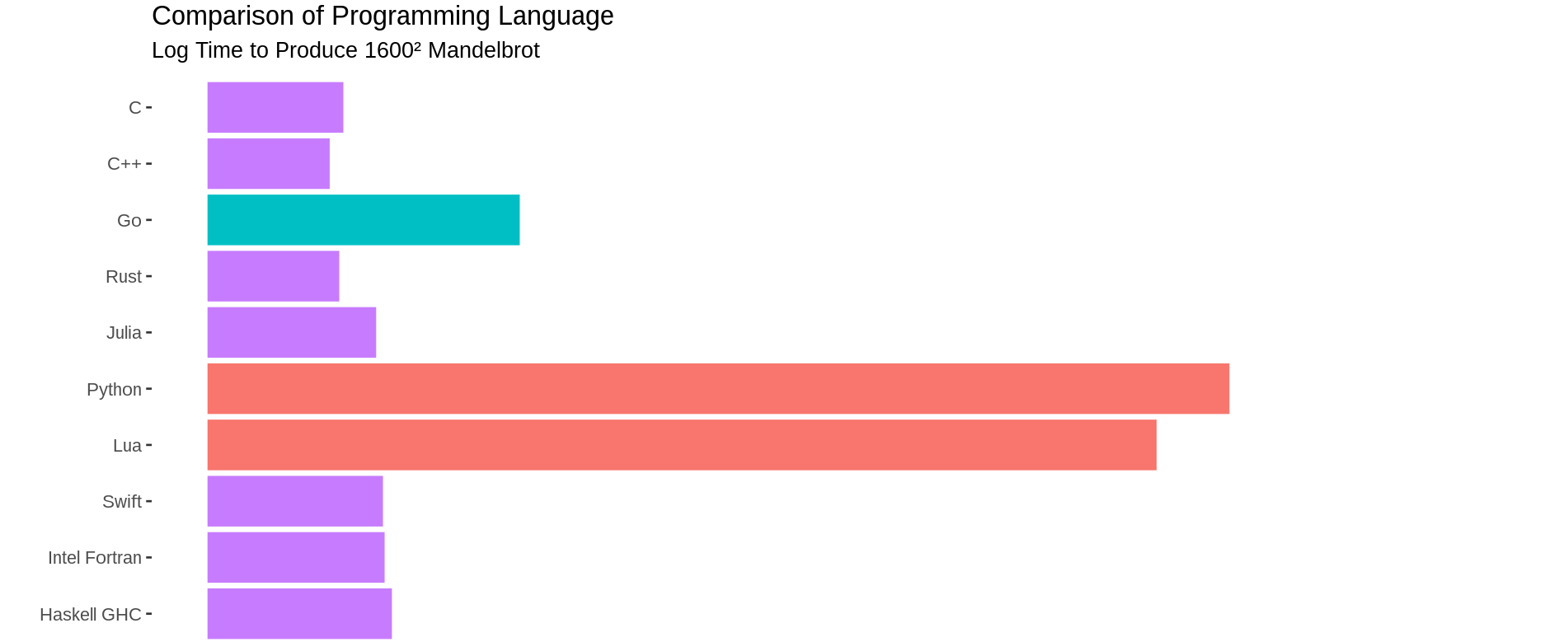
Notes:
this is not 100% accurate though, rust has a small runtime that is the panic handler etc. Rust for
Rustacean's chapter on no_std covers this very well.
Also, this is a good time to talk about how we use "Runtime" in a different way.
🤩 Generic, Modular and Extensible Design
- Second line of defense.
- Our execution (possibly thanks to Rust) is perfect, but we can't predict the future.
Notes:
this is where a module, generic design is useful. You can change components easily based on the needs of the future.
---v
🤩 Generic, Modular and Extensible Design
- Multiple consensus engines (BABE/Grandpa/AURA/PoW/Sassafras)
- Multiple network protocols (QUIC, TCP)
- Multiple database implementations (ParityDB, RocksDB)
- Highly configurable, graph-based transaction-pool.
- Easy to change primitives: AccountId, Signature, BlockNumber, Header, Hash, and many more.
Notes:
FRAME takes this even multiple steps further, but that's for later.
These are all examples of being generic, modular and extensible at the Substrate level. FRAME takes these even further, but more on that later.
---v
🤩 Generic, Modular and Extensible Design
- AlephZero: Custom finality, DAG-based, 1s block time.
- Moonbeam: Ethereum compatible, build with substrate.
- HydraDX: Custom transaction pool logic to match DEX orders.
- Kulupu: Proof of work, custom hashing.
Notes:
Substrate has been coded, from the ground up, such that it is easy to have multiple implementations for certain functions. Heavy use of traits and generics is the key to achieve this. As noted, Substrate has a lot of APIs, and optional implementations. You are bound to the API, but not the particular implementation.
🏦 Governance + Upgradeability
- Third, final, and non-negotiable line of defense to survive the test of time.
---v
🏦 Governance + Upgradeability
- We have correct code, and components are easy to swap, replace, and upgrade.
- What use is that, if we cannot agree on what to replace/upgrade?
- Governance!
- What use is governance, if the upgrade cannot be enacted?
- (trustlessly) Upgradeability!
Notes:
Even if we are governable, but we still need "trust" to enact the upgrade, it is hardly any better. In essence, if an upgrade mechanism is not self-enacting, it might as well just reside offchain and be a signaling mechanism.
---v
🏦 Governance + Upgradeability
- ✅ Governance: Easy
- 😢 Upgradeability: Not so much
---v
🏦 Governance + Upgradeability
- How does a typical blockchain upgrade itself?
Notes:
- Discussion, offchain signaling
- Possibly onchain voting
- Hard(ish) Fork
---v
🏦 Governance + Upgradeability

---v
🏦 Governance + Upgradeability

Notes:
the problem is that the system is one big monolith protocol. Updating any part of it requires the whole thing to be updated.
---v
🏦 Governance + Upgradeability
The way to make a protocol truly upgradeable is to design a meta-protocol that is not upgradeable.
---v
🏦 Governance + Upgradeability

Note:
In this figure, the meta-protocol, the substrate client, is not forklessly upgrade-able. It can only be upgraded with a fork. The Wasm protocol, though, can be upgraded forklessly.
---v
🏦 Governance + Upgradeability

---v
🏦 Governance + Upgradeability
- Fixed meta-protocol?
- "State machine as stored Wasm" in the Substrate client.
- inherently upgradeable protocol?
- Substrate Wasm Runtime
Substrate Architecture

---v
Substrate (simplified) Architecture
Runtime (Protocol)
- Application logic
- Wasm (maybe FRAME)
- Stored as a part of your chain state
- Also known as: STF
Client (Meta-protocol)
- Native Binary
- Executes the Wasm runtime
- Everything else: Database, Networking, Mempool, Consensus..
- Also known as: Host
The Runtime
- Runtime -> Application Logic.
- A fancy term: Runtime -> State Transition Function.
- A technical term: Runtime -> how to execute blocks.
Notes:
- I would personally call the runtime STF to avoid confusion with the "runtime" that is the general programming runtime, but kinda too late for that now.
- Among the definitions of the Wasm runtime, let's recap what the state transition is.
- The block execution definition will be described more in the Wasm-meta lecture.
State Transition Function
State

Notes:
entire set of data upon which we want to maintain a consensus. key value. associated with each block.
---v
State Transition Function
Transition Function
---v
State Transition Function
$$STF = F(block_{N}, state_{N}, code_{N}): state_{N+1}$$
---v
State Transition Function

Notes:
The Wasm runtime in this figure is in fact obtained from the state (see 0x123)
---v
State Transition Function

---v
State Transition Function

Notes:
THIS IS HOW A META-PROTOCOL MAKES A SYSTEM UPGRADE-ABLE.
could we have updated the code in N+1? By default, no because we load the wasm before you even look into the block.
IMPORTANT: State is not IN THE BLOCK, each state has AN ASSOCIATED BLOCK.
Keeping the state is 100% optional. You can always re-create the state of block N by re-executing
block [0, .., N-1].
ofc, changing the Wasm code cannot be done by anyone. That's up to governance.
Full Substrate Architecture

Positive Consequences of Wasm Runtime 🔥
---v
🤖 Deterministic Execution
- Portable, yet deterministic.
Notes:
Wasm's instruction set is deterministic, so all good.
---v
🧱 Sandboxing
- Useful when executing untrusted code.
- Smart contracts
- Parachain runtime
Notes:
How can we guarantee that neither enter an infinite loop, or try to access the filesystem?
---v
🌈 Easier (light)Client Development
Notes:
for the case of client, your client only needs to implement a set of host environments, and NOT re-implement the business logic.
Simply compare the process to create an alternative client for Ethereum, where you need to re-implement the EVM.
Same applies to light client, as they do not need to deal with the state transition function.
---v
😎 Forkless Upgrade

---v
😎 Forkless Upgrade

---v
😎 Forkless Upgrade
This update was:
- Forkless
- Self-enacting
Notes:
take a moment to establish that this upgrade is forkless. The runtime is upgraded, but the client is not. In fact, the client didn't need to know about this at all.
This is what the meta-protocol achieves.
Negative Consequences of Wasm Runtime
- 😩 Constrained resources (memory, speed, host access).
- 🌈 Client diversification != state-transition diversification
Notes:
- 4GB of memory, which we limit even further.
- Wasm has no allocator+panic handler of its own
- Can be slower than native, depending on the executor/execution method.
- Limited access to the host host env, all needs to be done through syscalls.
Less state-transition diversification, because the runtime is the same for all clients. If there is a bug in it, everyone is affected.
Consensus <> Runtime 🤔
- Yes, consensus is not a core part of a blockchain runtime. Why?
- Not part of your STF!
- The consensus protocol is to your runtime what HTTP is to Facebook.
Notes:
comments from Joshy:
I think this is important. The runtime is the application you want to run.
Consensus is outside of this application helping us agree what the official state of this runtime is. Last wave I used this analogy.
Imagine a writers room for some TV show. Writers are sitting around coming up with potential plot points for future episodes. Any of their ideas could work. But eventually they need to agree what the next episode to air actually will be.
Database <> State 🤔
- State is the entire set of key value data that is associated with one block.
- Database is the component that allows this be stored in disk. May or may not be key-value.

Notes:
State is sometimes called "storage" as well.
Database <> Runtime 🤔
- Yes, data is stored outside of the runtime. Why?
- Wasm runtime does not have the means to store it.
- Yet, the interpretation of the data is up to the runtime.
---v
Database <> Runtime 🤔

---v
The Client: Database 🤔
- The database, from the client's PoV, is an untyped, key-value storage.
- The runtime knows which key/value means what.
State of Light Clients
- Client that follows headers, therefore knows state roots and can ask for state-proofs to do more.
---v
State of Light Clients
- Not only possible, but they can also run as Wasm, in the browser!
- "Substrate Connect" / SMOLDOT

Notes:
What was a light client? follows only block headers, therefore knows state roots, and a few other pieces of information, others send it state proofs if it wishes to do more.
SMOLDOT is not exactly a substrate client. It is mainly designed to work with Polkadot. But with minimal tweaks, you could make it work for more substrate based chains.
This has to do with the fact that consensus and a few other bits of the client and runtime are not 100% independent. For example, GRANDPA has a pallet on the runtime side, but is mostly in the client. Now, a client that is configured with GRANDPA can only work with runtimes that are also configured with GRANDPA.
Communication Paths

---v
Communication Paths

---v
Example: SCALE vs JSON
- SCALE is an efficient, non-descriptive, binary encoding format, used EXTENSIVELY in the Substrate ecosystem.
---v
Example: SCALE vs JSON
use parity_scale_codec::{Encode}; #[derive(Encode)] struct Example { number: u8, is_cool: bool, optional: Option<u32>, } fn main() { let my_struct = Example { number: 42, is_cool: true, optional: Some(69), }; println!("{:?}", my_struct.encode()); // [42, 1, 1, 69, 0, 0, 0] println!("{:?}", my_struct.encode().len()); // 7 }
---v
Example: SCALE vs JSON
use serde::{Serialize}; #[derive(Serialize)] struct Example { number: u8, is_cool: bool, optional: Option<u32>, } fn main() { let my_struct = Example { number: 42, is_cool: true, optional: Some(69), }; println!("{:?}", serde_json::to_string(&my_struct).unwrap()); // "{\"number\":42,\"is_cool\":true,\"optional\":69}" println!("{:?}", serde_json::to_string(&my_struct).unwrap().len()); // 42 }
Substrate and Polkadot

Substrate and Smart Contracts

---v
Substrate and Smart Contracts
A Substrate-Connect extension is syncing a chain who's runtime is executing wasm contracts.
Question: How many nested Wasm blobs are executing one another?
---v
Substrate and Smart Contracts

- The browser is executing:
- a Wasm blob (substrate-connect)
- that executes a Wasm blob (runtime)
- that executes a Wasm blob (contract)
---v
Substrate and Smart Contracts

---v
Substrate and Smart Contracts
- So when should you write with a smart contract (Ink!) and when a Runtime (FRAME)?
Notes:
I was asked this yesterday as well. My latest answer is: if you don't need any of the customizations that a blockchain client/runtime gives to you, and the performance of a shared platform is okay for you, then go with a smart contract. If you need more, you need a "runtime" (some kind of chian, parachain or solo)
An example of customization is that a runtime has access to on_initialize etc.
Also, a contract can not have fee-less transactions.
Also, a contract usually depends on a token for gas, while a runtime can be in principle token-less fee-less.
Technical Freedom vs Ease

Substrate: The Gaming Console of Blockchains!
Substrate Client

Substrate's Wasm Runtime
Notes:
Another good analogy: Client is the FPGA, and FRAME/Wasm is the VHDL.
Lecture Recap
- Substrate's design stems from 3 core principles:
- Rust, Generic Design, Upgradeability/Governance
- Client / Runtime architecture
- State Transition
- Positive and negative consequences of Wasm
- Substrate next to Polkadot and other chains.
- Substrate for Smart Contracts.
---v
Recap: Substrate Architecture
---v
Recap: 🏦 Governance and Upgradeability
A timeless system must be:
- Generic
- Governable
- Trust-less-ly Upgradeable.
Substrate's Wasm meta-protocol exactly enables the latest ✅
Notes:
Question: how would you put the meta-protocol of Substrate into words?
The client is basically a wasm meta-protocol that does only one thing. This meta-protocol is hardcoded, but the protocol itself is flexible.
Rest of This Module! 😈
Track: Main Lectures
- Wasm Meta Protocol
- Substrate Storage
Track: Aux Lecture
- TX-Pool
- Substrate: Show Me The Code
- Substrate Interactions
- SCALE
Track: Graded Activity
- FRAME-Less
---v
Rest of This Module! 😈
Day 0
- Introduction ✅ (60m)
- Wasm Meta Protocol (120+m)
- Activity: Finding Runtime APIs and Host Functions in Substrate
- 🌭 Lunch Break
- Show Me The Code (60m)
- Substrate Interactions (60m)
- FRAME-Less Activity (60m)
Notes:
We are aware that the module is highly skewed in terms of lecture time, but it is intentional and we want to see how it works. This allows you to kickstart with your assignment earlier.
---v
Rest of This Module! 😈
Day 1
- Transaction Pool (60m)
- SCALE (60m)
- Substrate/FRAME Tips and Tricks
- 🌭 Lunch Break
- FRAME-Less Activity
---v
Rest of This Module! 😈
Day 2
- Substrate Storage (90m)
- FRAME-Less Activity
- 🌭 Lunch Break
- End of Module 🎉
Additional Resources! 😋
Check speaker notes (click "s" 😉)

Notes:
-
Great documentation about all things substrate/blockchain from smoldot: https://docs.rs/smoldot/latest/smoldot/
-
Read more about why we use Rust at Parity: https://www.parity.io/blog/why-rust/
-
An interesting question on JVM/Wasm: https://stackoverflow.com/questions/58131892/why-the-jvm-cannot-be-used-in-place-of-webassembly
-
Rust safety: https://stanford-cs242.github.io/f18/lectures/05-1-rust-memory-safety.html
-
https://www.reddit.com/r/rust/comments/5y3cxb/how_many_security_exploits_would_rust_prevent/
-
The substrate clients should still have some level of determinism in their performance. If authority nodes have extremely varied performances, they could start finalizing different forks.
-
There have been attempts at writing FRAME alternatives, namely AssemblyScript. https://github.com/LimeChain/as-substrate-runtime
-
Think about the differences between a runtime and a smart contract.
- A runtime is in some sense a smart contract as well, but not a user-deployed one.
- https://en.wikipedia.org/wiki/Smart_contract
- https://www.futurelearn.com/info/courses/defi-exploring-decentralised-finance-with-blockchain-technologies/0/steps/251885#:~:text=to%20the%201990s.-,Writing%20in%201994%2C%20the%20computer%20scientist%20Nick%20Szabo%20defined%20a,of%20artificial%20intelligence%20is%20implied.
-
Substrate Primitives (
sp-*), Frame (frame-*) and the pallets (pallets-*), binaries (/bin) and all other utilities are licensed under Apache 2.0.
Substrate Client (/client/* / sc-*) is licensed under GPL v3.0 with a classpath linking exception.
-
Apache2 allows teams full freedom over what and how they release, and giving licensing clarity to commercial teams.
-
GPL3 ensures any deeper improvements made to Substrate's core logic (e.g. Substrate's internal consensus, crypto or database code) to be contributed back so everyone can benefit.
-
Currently, the Wasm binary spec v1 is used, read more about the new version here: https://webassembly.github.io/spec/core/binary/index.html
Post Lecture Feedback
- a takeaway after each section, more clear path (shawn).
Appendix: What is Wasm Anyways?
WebAssembly (abbreviated Wasm) is a binary instruction format for a stack-based virtual machine. Wasm is designed as a portable compilation target for programming languages, enabling deployment on the web for client and server applications.
---v
What is Wasm Anyways?

---v
What is Wasm Anyways?
- Wasm ❤️ Web
- Streaming and rapid compilation.
- Designed with the concept of host in mind. Sandboxed, permissioned sys-calls.
Anyone remember "Java Applets"?

Notes:
People actually tried sticking things like JVM into the browser (Java Applets), but it didn't work.
---v
How to Write a Wasm Runtime?
- Any language that can compile to Wasm and exposes a fixed set of functions, to be used by the client.
- ... But, of course, Substrate comes with a framework to make this developer-friendly, FRAME™️.
Appendix: More Diagrams of Substrate and Polkadot
Notes:
I made these figures recently to explain the relationship between Substrate, Cumulus and Polkadot. They use the most generic term for client and runtime, namely "Host" and "STF" respectively.
---v
Substrate

---v
Polkadot
 ---v
---v
A Parachain

Substrate Wasm meta-protocol
How to use the slides - Full screen (new tab)
Substrate Wasm Meta Protocol
Part 1
- This is a big lecture, so I divided it into two small parts, that's all 🫵🏻
It All Began With a Runtime..

---v
It All Began With a Runtime..
- Personal opinion:
Substrate technology stack will put "Wasm stored onchain" on the map,
the same way Ethereum put "smart contracts stored onchain" on the map.
Notes:
It is only a matter of time until every blockchain is doing the same thing.
---v
It All Began With a Runtime..
- The Client / Runtime division is one of the most important design decisions in Substrate.
- 👿 Bad: Fixed opinion.
- 😇 Good: Enables countless other things to not be fixed.
Notes:
Recall that the boundary for this division is the state transition
Substrate: a short recap

---v
Substrate: a short recap
- Host Functions: Means of a runtime communicating with its host environment, i.e. the Substrate client.
---v
Substrate: a short recap
- Runtime API: The well-defined functions that a Wasm substrate runtime is providing.
Notes:
Building a Wasm module's activity was building something akin to runtime-apis
---v
Substrate: a short recap
- Database is on the client side, storing an opaque key-value state per block.
---v
Substrate: a short recap
- Communication language of client/runtime is SCALE:
Learning with Examples
and some pseudo-code
Notes:
During each example, we deduce what host functions and/or runtime APIs are needed.
Example #1: State
- The runtime wants to add 10 units to Kian's balance.
---v
Example #1: State
#![allow(unused)] fn main() { // the runtime decides what key stores kian's balance. key: Vec<u8> = b"kian_balance".to_vec(); // the runtime reads the raw bytes form that key. let current_kian_balance_raw: Vec<u8> = host_functions::get(key); // and needs to know to which type it should be decoded, u128. let mut current_kian_balance: u128 = current_kian_balance_raw.decode(); // actual logic. current_kian_balance += 10; // encode this again into an opaque byte-array. let new_balance_encoded: Vec<u8> = current_kian_balance.encode(); // write the encoded bytes again. host_functions::set(key, new_balance_encoded); }
---v
Example #1: State
- 💡 The runtime needs host functions to read/write to state.
#![allow(unused)] fn main() { fn get(key: Vec<u8>) -> Vec<u8>; fn set(key: Vec<u8>, value: Vec<u8>); }
Notes:
ofc the IO to these functions is all opaque bytes, because the client does not know the state layout.
---v
Example #1: State
- could we have communicated with the client like this?
#![allow(unused)] fn main() { fn set_balance(who: AccountId, amount: u128) }
Notes:
This would imply that the client would have to know, indefinitely, the types needed for account id and balance. Also, it would have to know the final key for someone's balance.
---v
Example #1: State
- Exceptions:
#![allow(unused)] fn main() { /// The keys known to the client. mod well_known_keys { const CODE: &[u8] = b":code"; } }
Notes:
See https://paritytech.github.io/substrate/master/sp_storage/well_known_keys/index.html
---v
Example #1: State

Example #2: Block Import
---v
Example #2: Block Import
- Client's view of the state -> Opaque.
- Client's view of the transactions? 🤔
Notes:
Short answer is: anything that is part of the STF definition must be opaque to the client, and is upgradeable, but we will learn this later.
---v
Example #2: Block Import
- Transactions format is by definition part of the state transition function as well.
- What about header, and other fields in a typical block?
Notes:
as in, do we want to able to update our transactions format as well in a forkless manner? we want the runtime to be able to change its transactions format as well, in a forkless manner.
The answer to the latter is more involved. The short answer is that these fields like header must be known and established between client and runtime. If you want to alter the header format, that's a hard fork.
The concept of digest is a means through which additional data can be put in the header without breaking changes, but that is outside the scope of this lecture.
Yet, as with other primitives, substrate allows you to readily change your header type when you are building your blockchain.
This is achieved by a set of traits in sp-runtime.
Notably, trait Block and trait Header in this crate define what it means to be a header and block, and as long as you fulfill that, you are good to go.
Also, substrate provides one set of implementation for all of these types in https://paritytech.github.io/substrate/master/sp_runtime/generic/index.html
---v

---v
Example #2: Block Import
#![allow(unused)] fn main() { struct ClientBlock { header: Header, transactions: Vec<Vec<u8>> } }
#![allow(unused)] fn main() { struct RuntimeBlock { header: Header, transaction: Vec<KnownTransaction> } }
Notes:
this slide is intentionally using the keyword transaction instead of extrinsic.
---v
Example #2: Block Import
#![allow(unused)] fn main() { // fetch the block from the outer world. let opaque_block: ClientBlock = networking::import_queue::next_block(); // initialize a wasm runtime. let code = database::get(well_known_keys::CODE); let runtime = wasm::Executor::new(code); // call into this runtime. runtime.execute_block(opaque_block); }
---v
Example #2: Block Import
- 💡 The client needs a runtime API to ask the runtime to execute the block.
#![allow(unused)] fn main() { fn execute_block(opaque_block: ClientBlock) -> Result<_, _> { .. } }
Notes:
execute_block is the most basic, fundamental runtime API that any substrate based runtime has to
implement in order to be called a "blockchain runtime".
Example #2: Block Import: Something Missing
#![allow(unused)] fn main() { // 🤔 let code = database::get(well_known_keys::CODE); // 🤔 runtime.execute_block(opaque_block); }

Notes:
- From which block's state do we fetch the code??
- This probably calls into
host_functions::{get/set}internally. What do we return
---v
Example #2: Block Import
#![allow(unused)] fn main() { // fetch the block from the outer world. let block: ClientBlock = networking::import_queue::next_block(); // get the parent block's state. let parent = block.header.parent_hash; let mut state = database::state_at(parent); // initialize a wasm runtime FROM THE PARENT `state`! let code = state::get(well_known_keys::CODE); let runtime = wasm::Executor::new(code); // call into this runtime, updates `state`. state.execute(|| { runtime.execute_block(block); }); // create the state of the next_block database::store_state(block.header.hash, state) }
Notes:
- Question: why is
statedefined asmut? - within these snippets, more or less, everything inside
state.executeis executed within Wasm.
---v
Example #2: Block Import
- A state key is only meaningful at a given block.
- A :code is only meaningful at at given block.
- 💡 A runtime (API) is only meaningful when executed at a give block.
Notes:
-
The same way that Alice's balance value is only meaningful when read at a given block.
-
Based on that:
- The correct runtime code is loaded.
- The correct state (and other host functions) is provided.
-
Similarly, almost all RPC operations that interact with the runtime have an
Option<Hash>argument. This specifies "at which block to load the runtime and state from".
---v
Example #2: Block Import
- I can add one more small touch to this to make it more accurate.. 🤌
---v
Example #2: Block Import
#![allow(unused)] fn main() { // fetch the block from the outer world. let block: ClientBlock = networking::import_queue::next_block(); // get the parent hash. Note that `sp_runtime::traits::Header` provides this. let parent = block.header.parent_hash; let mut state = database::state_at(parent); // initialize a wasm runtime FROM THE PARENT `state`! let code = state::get(well_known_keys::CODE); let runtime = wasm::Executor::new(code); // call into this runtime, update `state`. state.execute(|| { // within this, we probably call into `host_functions::set` a lot. runtime.execute_block(block); let new_state_root = host_functions::state_root(); let claimed_state_root = block.header.state_root; assert_eq!(new_state_root, claimed_state_root); }); // create the state of the next_block database::store_state(block.header.hash, state) }
---v
Example #2: Block Import: Recap

Detour: Extrinsic
- Previous slides used the term "transactions" in a simplified way. Let's correct it.
---v
Detour: Extrinsic
---v
Detour: Extrinsic
- An Extrinsic is data that come from outside of the runtime.
- Inherents are data that is put into the block by the block author, directly.
- Yes, transactions are a type of extrinsic, but not all extrinsics are transactions.
- So, why is it called Transaction Pool and not Extrinsic Pool?
Notes:
Extrinsics are just blobs of data which can be included in a block. Inherents are types of extrinsic which are crafted by the block builder itself in the production process. They are unsigned because the assertion is that they are "inherently true" by virtue of getting past all validators. Notionally the origin can be said to be a plurality of validators. Take for example the timestamp set inherent. If the data were sufficiently incorrect (i.e. the wrong time), then the block would not be accepted by enough validators and would not become canonicalized. So the "nobody" origin is actually the tacit approval of the validators. Transactions are generally statements of opinion which are valuable to the chain to have included (because fees are paid or some other good is done). The transaction pool filters out which of these are indeed valuable and nodes share them.
Example #3: Block Authoring
---v
Example #3: Block Authoring

---v
Example #3: Block Authoring

---v
Example #3: Block Authoring

---v
Example #3: Block Authoring

---v
Example #3: Block Authoring

Notes:
The point being, eventually the pool builds a list of "ready transactions".
---v
Example #3: Block Authoring

---v
Example #3: Block Authoring

---v
Example #3: Block Authoring

---v
Example #3: Block Authoring

---v
Example #3: Block Authoring

---v
Example #3: Block Authoring

---v
Example #3: Block Authoring

---v
Example #3: Block Authoring

---v
Example #3: Block Authoring
#![allow(unused)] fn main() { // get the best-block, based on whatever consensus rule we have. let (best_number, best_hash) = consensus::best_block(); // get the latest state. let mut state = database::state_at(best_hash); // initialize a wasm runtime. let code = state::get(well_known_keys::CODE); let runtime = wasm::Executor::new(code); // get an empty client block. let mut block: ClientBlock = Default::default(); // repeatedly apply transactions. while let Some(next_transaction) = transaction_pool_iter::next() { state.execute(|| { runtime.apply_extrinsic(next_transaction); }); block.extrinsics.push(next_transaction); } // set the new state root. block.header.state_root = state.root(); }
Notes:
- What is the type of
next_ext?Vec<u8> - Do we actually loop forever until the tx-pool is empty? probably not!
---v
Example #3: Block Authoring
- Substrate based runtimes are allowed to perform some operations at the beginning and end of each block.
- ✋🏻 And recall that a smart contract could not do this.
---v
Example #3: Block Authoring
#![allow(unused)] fn main() { // get the best-block, based on whatever consensus rule we have. let (best_number, best_hash) = consensus::best_block(); // get the latest state. let mut state = database::state_at(best_hash); // initialize a wasm runtime. let code = state::get(well_known_keys::CODE); let runtime = wasm::Executor::new(code); // get an empty client block. let mut block: ClientBlock = Default::default(); // tell this runtime that you wish to start a new block. runtime.initialize_block(); // repeatedly apply transactions. while let Some(next_ext) = transaction_pool_iter::next() { state.execute(|| { runtime.apply_extrinsic(next_ext); }); block.extrinsics.push(next_ext); } // tell the runtime that we are done. runtime.finalize_block(); // set the new state root. block.header.state_root = state.root(); }
---v
Example #3: Block Authoring
- What about Inherents?
---v
Example #3: Block Authoring
#![allow(unused)] fn main() { // get the best-block, based on whatever consensus rule we have. let (best_number, best_hash) = consensus::best_block(); // get the latest state. let mut state = database::state_at(best_hash); // initialize a wasm runtime. let code = state::get(well_known_keys::CODE); let runtime = wasm::Executor::new(code); // get an empty client block. let mut block: ClientBlock = Default::default(); // tell this runtime that you wish to start a new block. runtime.initialize_block(); let inherents: Vec<Vec<u8>> = block_builder::inherents(); block.extrinsics = inherents; // repeatedly apply transactions. while let Some(next_ext) = transaction_pool_iter::next() { state.execute(|| { runtime.apply_extrinsic(next_ext); }); block.extrinsics.push(next_ext); } // tell the runtime that we are done. runtime.finalize_block(); // set the new state root. block.header.state_root = state.root(); }
Notes:
while inherents can in principle come at any point in the block, since FRAME restricts them to come first, we also keep our example aligned.
Should you wish to see the real version of this, check this crate: https://paritytech.github.io/substrate/master/sc_basic_authorship/index.html
---v
Example #3: Block Authoring
#![allow(unused)] fn main() { fn initialize_block(..) { ... } // note the opaque extrinsic type. fn apply_extrinsic(extrinsic: Vec<u8>) { ... } fn finalize_block(..) { ... } }
Notes:
in fact, the client also builds its inherent list with the help of the runtime.
BUT WAIT A MINUTE 😱
-
if the
codechanges, all the following can also change:- What state key is Kian's balance.
- What extrinsic format is valid.
- How on earth is an application (i.e. a wallet) is supposed to survive?
---v
BUT WAIT A MINUTE 😱
- Metadata 🎉
#![allow(unused)] fn main() { fn metadata() -> Vec<u8> { ... } }
Notes:
Notice the opaque return type.
In order the address the mentioned issue, metadata must be a runtime API.
- Metadata contains all the basic information to know about all storage items, all extrinsics, and so on. It will also help a client/app decode them into the right type.
- Substrate itself doesn't impose what the metadata should be.
It is
Vec<u8>. - FRAME based runtime expose a certain format, which is extensively adopted in the ecosystem.
---v
BUT WAIT A MINUTE 😱
- Recall the fact that "runtime is only meaningful at a certain block".
- Two different runtimes at block
NandN+1return different metadata ✅.
Notes:
By Applications/Clients I really mean anyone/anything. Substrate client doesn't really use metadata because it is dynamically typed, but if needed, it could.
Radical Upgradeability
Comes at the cost of radical opaque/dynamic typing.
Notes:
I wish you could have both, but not so easy.
Some personal rant: radical upgrade-ability is the biggest advantage, and arguably one of the main develop-ability problems of the substrate ecosystem. Writing clients, such as block explorers, scanners, and even exchange integration are orders of magnitude harder than a blockchain that has a fixed format and only changes every 18 months at most. That being said, this is a battle that is to me obvious: we simply HAVE to win. When ethereum first introduced smart contracts, everyone probably had the same class of issues. This is the same matter, on a a different level.
also, as noted in an earlier slide, once you make it work for one chain, it works for many chains.
Oblivious Client 🙈🙉
- The underlying reason why the client is "kept in the dark" is so that it wouldn't need to care about the runtime upgrading from one block to the other.
---v
Oblivious Client 🙈🙉
$$STF = F(blockBody_{N}, state_{N}) > state_{N+1}$$
Anything that is part of the STF is opaque to the client, but it can change forklessly!
- The `F` itself (your Wasm blob)? It can change!
- Extrinsic format? It can change!
- State format? It can change!
Notes:
In essence, all components of the STF must be opaque to the client.
Vec<u8>.
Metadata is there to assist where needed.
This is why forkless upgrades are possible in substrate.
---v
Oblivious Client 🙈🙉
- What about new host functions?
- What about a new header filed*?
- What about a new Hashing primitive?
🥺 No longer forkless.
Notes:
But, recall that substrate's extensibility and generic-ness clause applies here.
For some, like header, some hacks exist, like the digest field.
Changing these is hard in a forkless manner. If you want to just change them at genesis and launch a new chain, they are all VERY easy to change.
Substrate: The Full Picture

Notes:
time to ask any missing questions.
Activity: Finding APIs and Host Functions
---v
Finding APIs and Host Functions
- look for
impl_runtime_apis! {...}anddecl_runtime_apis! {...}macro calls.- Try and find the corresponding the client code calling a given api as well.
- Look for
#[runtime_interface]macro, and try and find usage of the host functions! - You have 15 minutes!
---v
Finding APIs and Host Functions
Activity Outcomes:
Coreis the essence of import.TaggedTransactionQueueandBlockBuilderfor validators.header: Headerbeing passed around.
Notes:
a question that arise here is that why don't have multiple runtimes, where one is only for import, one only for authoring, and such? the reality is that while these have different names, the underlying code is like 95% the same.
---v
Finding APIs and Host Functions
Block Import
#![allow(unused)] fn main() { runtime.execute_block(block); }
Block Authoring
#![allow(unused)] fn main() { runtime.initialize_block(raw_header); loop { runtime.apply_extrinsic(ext); } let final_header = runtime.finalize_block(); }
Notes:
to be frank, these are still a simplification. Inherent for example are not really represented here.
---v
Finding APIs and Host Functions
- Most important host functions
sp_io::storage::get(..);
sp_io::storage::set(..);
sp_io::storage::root();
Lecture Recap (Part 1)
- Revise "Runtime API" and "Host Function" concepts.
- Deep look at block import and authoring.
- Oblivious client.
- Metadata
Part 2
Defining a Runtime API
#![allow(unused)] fn main() { // somewhere in common between client/runtime => substrate-primitive. decl_runtime_apis! { pub trait Core { fn version() -> RuntimeVersion; fn execute_block(block: Block) -> bool; } } // somewhere in the runtime code. impl_runtime_apis! { impl sp_api::Core<Block> for Runtime { fn version() -> RuntimeVersion { /* stuff */ } fn execute_block(block: Block) -> bool { /* stuff */ } } } // somewhere in the client code.. let block_hash = "0xffff..."; let block = Block { ... }; let outcome: Vec<u8> = api.execute_block(block, block_hash).unwrap(); }
Notes:
- All runtime APIs are generic over a
<Block>by default. - All runtime APIs are executed on top of a specific block. This is the implicit at parameter.
- Going over the API, everything is SCALE encoded both ways, but abstractions like
impl_runtime_apishide that away from you.
Defining a Host Function
#![allow(unused)] fn main() { // somewhere in substrate primitives, almost always `sp_io`. #[runtime_interface] pub trait Storage { fn get(&self, key: &[u8]) -> Option<Vec<u8>> {...} fn get(&self, key: &[u8], value: &[u8]) -> Option<Vec<u8>> {...} fn root() -> Vec<u8> {...} } #[runtime_interface] pub trait Hashing { fn blake2_128(data: &[u8]) -> [u8; 16] { sp_core::hashing::blake2_128(data) } } // somewhere in substrate runtime let hashed_value = sp_io::storage::get(b"key") .and_then(sp_io::hashing::blake2_128) .unwrap(); }
Considerations
Considerations: Speed
- (new) Wasmtime is near-native 🏎️.
- (old)
wasmiis significantly slower 🐢.
Notes:
slower wasmi was one of the reasons to have native execution. there are talks of exploring Risk-v ISA instead of wasm nowadays.
https://github.com/paritytech/substrate/issues/13640
---v
Considerations: Speed
- Host is generally faster and more capable, but it has a one-time cost of getting there, and copying the data.
- 🤔 Hashing, Crypto?
- 🤔 Storage?

Notes:
Hashing and crypto is done as host function for performance
Storage because of the runtime not being capable.
- Going over the runtime boundary is analogous to your CPU needing to go to memory.
On the other hand things as next_storage are high cost (generally iteration on state from runtime
is expensive).
This design is related to the memory location, there is alternative but this is
simple (simple as good design).
- Question: we got host function for running computation intensive code in native, but when simd for wasm would be added, then will host function for a hashing be still useful: A: wait and see, but is possible that simd optimization of the hash function in wasm is way faster.
Again using a host function for speed up needs to be reasoned, cost of transmitting parameter in wasm can be bigger than the actual hashing cost.
Consideration: Native Runtime

---v
Consideration: Native Runtime
- Remember the
fn version()inCoreAPI!
#![allow(unused)] fn main() { /// Runtime version. #[sp_version::runtime_version] pub const VERSION: RuntimeVersion = RuntimeVersion { spec_name: create_runtime_str!("node"), spec_version: 268, impl_name: create_runtime_str!("substrate-node"), impl_version: 0, authoring_version: 10, apis: RUNTIME_API_VERSIONS, transaction_version: 2, state_version: 1, }; }
---v
Consideration: Native Runtime
- Native is only an option if spec versions match!
#![allow(unused)] fn main() { fn execute_native_else_wasm() { let native_version = runtime::native::api::version(); let wasm_version = runtime::wasm::api::version(); // if spec name and version match. if native_version == wasm_version { runtime::native::execute(); } else { runtime::wasm::execute(); } } }
---v
Consideration: Native Runtime
- The days of native runtime are numbered 💀.
---v
Consideration: Native Runtime
- Question: what happens if you upgrade your runtime, but forget to bump the spec version?
- Question: What if a runtime upgrade is only tweaking implementation details, but not the specification?
Notes:
If everyone is executing wasm, technically nothing, but that's super confusing, don't do it. But, if some are executing native, then you will have a consensus error.
---v
Speaking of Versions..
- Make sure you understand the difference! 👍
- Client Version
- Runtime Version
---v
Speaking of Versions..

---v
Speaking of Versions..
---v
Speaking of Versions..
---v
Speaking of Versions..
- What happens when Parity release a new
parity-polkadotclient binary? - What happens when the Polkadot fellowship wants to update the runtime?
Considerations: Panic
- What if any of the runtime calls, like
execute_blockorapply_extrinsicpanics 😱? - To answer this, let's take a step back toward validator economics.
---v
Considerations: Panic
- In a more broad sense, all validators never want to avoid wasting their time.
- While building a block, sometimes it is unavoidable (when?).
- While importing a block, nodes will not tolerate this.
---v
Considerations: Panic
- Panic is a (free) form of wasting a validator's time.
- Practically Wasm instance killed; State changes reverted.
- Any fee payment also reverted.
- Transactions that consume resources but fail to pay fees are similar.
Notes:
While you might think the state revert is the good thing here, it is the main problem, and the main reason you should not let a code-path that is accessible by arbitrary users to panic. Because, any fees paid for the wasted execution of that runtime API call is also reverted.
In other words, a panic in the runtime typically allows everyone's time to be wasted, for free, indefinitely. In other words, a DOS vector.
A panic in
initialize_blockandfinalize_blockhave even more catastrophic effects, which will be discussed further in the FRAME section.
workshop idea: make a panicing runtime, and DoS it out. workshop idea for FRAME: find all instances where the runtime actually correctly panics (wrong timestamp, disabled validator)
---v
Considerations: Panic
- Panic in a user-callable code path?
- 🤬 annoy/DOS your poor validators
- Panic on "automatic" part of your blockchain like "initialize_block"?
- 😱 Stuck forever
---v
Considerations: Panic
- This is why, crucially, transaction pool checks always include, despite being costly, at least some sort of nonce and payment checks to make sure you can pay the transaction.
---v
Considerations: Panic
Notes:
Consider two cases:
- A transaction that panic-ed
- A transaction that cannot pay for fees, but the pool somehow validated it by mistake.
when you author a block, you hope that the tx-pool has pre-validated things for you, but you cannot be sure. The pool cannot pre-execute stuff. If it fails, then you have to continue. For example, the pool might validate a nonce that becomes invalid. Or a fee payment. In that case, the block author wasted time, but everyone else will not.
To the contrary, once you have authored a block, the importers expect you to only have put VALID transactions into it, those that will not fail to be included.
Note that a transaction might still fail (failed transfer), but so long as it can pay for its fee, it is included fine.
See the documentation of ApplyExtrinsicResult in Substrate for more info about this.
Consideration: Altering Host Function
- A runtime upgrade now requires a new
sp_io::new_stuff::foo(). Can we do a normal runtime upgrade?
- Clients need to upgrade first. No more fully forkless upgrade 😢
---v
Consideration: Breaking a Host Function
- Here's another example, from substrate:
#![allow(unused)] fn main() { // old fn root(&mut self) -> Vec<u8> { .. } // new fn root(&mut self, version: StateVersion) -> Vec<u8> { .. } }
- For some period of time, the client needs to support both..🤔
- When can the old host function be deleted?
---v
Host Functions..
NEED TO BE KEPT FOREVER 😈
- Optional activity: Go to the substrate repo, and find PRs that have altered host functions, and see the PR discussion. There are a few labels that help you find such PRs 😉.
Workshop: Inspecting Wasm Code
---v
wasm2wat polkadot_runtime.wasm > dump | rg import
(import "env" "memory" (memory (;0;) 22))
(import "env" "ext_crypto_ed25519_generate_version_1" (func $ext_crypto_ed25519_generate_version_1 (type 17)))
(import "env" "ext_crypto_ed25519_verify_version_1" (func $ext_crypto_ed25519_verify_version_1 (type 18)))
(import "env" "ext_crypto_finish_batch_verify_version_1" (func $ext_crypto_finish_batch_verify_version_1 (type 11)))
(import "env" "ext_crypto_secp256k1_ecdsa_recover_version_2" (func $ext_crypto_secp256k1_ecdsa_recover_version_2 (type 19)))
(import "env" "ext_crypto_secp256k1_ecdsa_recover_compressed_version_2" (func $ext_crypto_secp256k1_ecdsa_recover_compressed_version_2 (type 19)))
(import "env" "ext_crypto_sr25519_generate_version_1" (func $ext_crypto_sr25519_generate_version_1 (type 17)))
(import "env" "ext_crypto_sr25519_public_keys_version_1" (func $ext_crypto_sr25519_public_keys_version_1 (type 5)))
(import "env" "ext_crypto_sr25519_sign_version_1" (func $ext_crypto_sr25519_sign_version_1 (type 20)))
(import "env" "ext_crypto_sr25519_verify_version_2" (func $ext_crypto_sr25519_verify_version_2 (type 18)))
(import "env" "ext_crypto_start_batch_verify_version_1" (func $ext_crypto_start_batch_verify_version_1 (type 14)))
(import "env" "ext_misc_print_hex_version_1" (func $ext_misc_print_hex_version_1 (type 16)))
(import "env" "ext_misc_print_num_version_1" (func $ext_misc_print_num_version_1 (type 16)))
(import "env" "ext_misc_print_utf8_version_1" (func $ext_misc_print_utf8_version_1 (type 16)))
(import "env" "ext_misc_runtime_version_version_1" (func $ext_misc_runtime_version_version_1 (type 21)))
(import "env" "ext_hashing_blake2_128_version_1" (func $ext_hashing_blake2_128_version_1 (type 22)))
(import "env" "ext_hashing_blake2_256_version_1" (func $ext_hashing_blake2_256_version_1 (type 22)))
(import "env" "ext_hashing_keccak_256_version_1" (func $ext_hashing_keccak_256_version_1 (type 22)))
(import "env" "ext_hashing_twox_128_version_1" (func $ext_hashing_twox_128_version_1 (type 22)))
(import "env" "ext_hashing_twox_64_version_1" (func $ext_hashing_twox_64_version_1 (type 22)))
(import "env" "ext_storage_append_version_1" (func $ext_storage_append_version_1 (type 23)))
(import "env" "ext_storage_clear_version_1" (func $ext_storage_clear_version_1 (type 16)))
(import "env" "ext_storage_clear_prefix_version_2" (func $ext_storage_clear_prefix_version_2 (type 24)))
(import "env" "ext_storage_commit_transaction_version_1" (func $ext_storage_commit_transaction_version_1 (type 14)))
(import "env" "ext_storage_exists_version_1" (func $ext_storage_exists_version_1 (type 22)))
(import "env" "ext_storage_get_version_1" (func $ext_storage_get_version_1 (type 21)))
(import "env" "ext_storage_next_key_version_1" (func $ext_storage_next_key_version_1 (type 21)))
(import "env" "ext_storage_read_version_1" (func $ext_storage_read_version_1 (type 25)))
(import "env" "ext_storage_rollback_transaction_version_1" (func $ext_storage_rollback_transaction_version_1 (type 14)))
(import "env" "ext_storage_root_version_2" (func $ext_storage_root_version_2 (type 5)))
(import "env" "ext_storage_set_version_1" (func $ext_storage_set_version_1 (type 23)))
(import "env" "ext_storage_start_transaction_version_1" (func $ext_storage_start_transaction_version_1 (type 14)))
(import "env" "ext_trie_blake2_256_ordered_root_version_2" (func $ext_trie_blake2_256_ordered_root_version_2 (type 26)))
(import "env" "ext_offchain_is_validator_version_1" (func $ext_offchain_is_validator_version_1 (type 11)))
(import "env" "ext_offchain_local_storage_clear_version_1" (func $ext_offchain_local_storage_clear_version_1 (type 27)))
(import "env" "ext_offchain_local_storage_compare_and_set_version_1" (func $ext_offchain_local_storage_compare_and_set_version_1 (type 28)))
(import "env" "ext_offchain_local_storage_get_version_1" (func $ext_offchain_local_storage_get_version_1 (type 29)))
(import "env" "ext_offchain_local_storage_set_version_1" (func $ext_offchain_local_storage_set_version_1 (type 30)))
(import "env" "ext_offchain_network_state_version_1" (func $ext_offchain_network_state_version_1 (type 15)))
(import "env" "ext_offchain_random_seed_version_1" (func $ext_offchain_random_seed_version_1 (type 11)))
(import "env" "ext_offchain_submit_transaction_version_1" (func $ext_offchain_submit_transaction_version_1 (type 21)))
(import "env" "ext_offchain_timestamp_version_1" (func $ext_offchain_timestamp_version_1 (type 15)))
(import "env" "ext_allocator_free_version_1" (func $ext_allocator_free_version_1 (type 1)))
(import "env" "ext_allocator_malloc_version_1" (func $ext_allocator_malloc_version_1 (type 0)))
(import "env" "ext_offchain_index_set_version_1" (func $ext_offchain_index_set_version_1 (type 23)))
(import "env" "ext_default_child_storage_clear_version_1" (func $ext_default_child_storage_clear_version_1 (type 23)))
(import "env" "ext_default_child_storage_get_version_1" (func $ext_default_child_storage_get_version_1 (type 24)))
(import "env" "ext_default_child_storage_next_key_version_1" (func $ext_default_child_storage_next_key_version_1 (type 24)))
(import "env" "ext_default_child_storage_set_version_1" (func $ext_default_child_storage_set_version_1 (type 31)))
(import "env" "ext_logging_log_version_1" (func $ext_logging_log_version_1 (type 30)))
(import "env" "ext_logging_max_level_version_1" (func $ext_logging_max_level_version_1 (type 11)))
---v
wasm2wat polkadot_runtime.wasm > dump | rg export
(export "__indirect_function_table" (table 0))
(export "Core_version" (func $Core_version))
(export "Core_execute_block" (func $Core_execute_block))
(export "Core_initialize_block" (func $Core_initialize_block))
(export "Metadata_metadata" (func $Metadata_metadata))
(export "BlockBuilder_apply_extrinsic" (func $BlockBuilder_apply_extrinsic))
(export "BlockBuilder_finalize_block" (func $BlockBuilder_finalize_block))
(export "BlockBuilder_inherent_extrinsics" (func $BlockBuilder_inherent_extrinsics))
(export "BlockBuilder_check_inherents" (func $BlockBuilder_check_inherents))
(export "NominationPoolsApi_pending_rewards" (func $NominationPoolsApi_pending_rewards))
(export "NominationPoolsApi_points_to_balance" (func $NominationPoolsApi_points_to_balance))
(export "NominationPoolsApi_balance_to_points" (func $NominationPoolsApi_balance_to_points))
(export "StakingApi_nominations_quota" (func $StakingApi_nominations_quota))
(export "TaggedTransactionQueue_validate_transaction" (func $TaggedTransactionQueue_validate_transaction))
(export "OffchainWorkerApi_offchain_worker" (func $OffchainWorkerApi_offchain_worker))
(export "ParachainHost_validators" (func $ParachainHost_validators))
(export "ParachainHost_validator_groups" (func $ParachainHost_validator_groups))
(export "ParachainHost_availability_cores" (func $ParachainHost_availability_cores))
(export "ParachainHost_persisted_validation_data" (func $ParachainHost_persisted_validation_data))
(export "ParachainHost_assumed_validation_data" (func $ParachainHost_assumed_validation_data))
(export "ParachainHost_check_validation_outputs" (func $ParachainHost_check_validation_outputs))
(export "ParachainHost_session_index_for_child" (func $ParachainHost_session_index_for_child))
(export "ParachainHost_validation_code" (func $ParachainHost_validation_code))
(export "ParachainHost_candidate_pending_availability" (func $ParachainHost_candidate_pending_availability))
(export "ParachainHost_candidate_events" (func $ParachainHost_candidate_events))
(export "ParachainHost_session_info" (func $ParachainHost_session_info))
(export "ParachainHost_dmq_contents" (func $ParachainHost_dmq_contents))
(export "ParachainHost_inbound_hrmp_channels_contents" (func $ParachainHost_inbound_hrmp_channels_contents))
(export "ParachainHost_validation_code_by_hash" (func $ParachainHost_validation_code_by_hash))
(export "ParachainHost_on_chain_votes" (func $ParachainHost_on_chain_votes))
(export "ParachainHost_submit_pvf_check_statement" (func $ParachainHost_submit_pvf_check_statement))
(export "ParachainHost_pvfs_require_precheck" (func $ParachainHost_pvfs_require_precheck))
(export "ParachainHost_validation_code_hash" (func $ParachainHost_validation_code_hash))
(export "BeefyApi_beefy_genesis" (func $BeefyApi_beefy_genesis))
(export "BeefyApi_validator_set" (func $BeefyApi_validator_set))
(export "BeefyApi_submit_report_equivocation_unsigned_extrinsic" (func $BeefyApi_submit_report_equivocation_unsigned_extrinsic))
(export "BeefyApi_generate_key_ownership_proof" (func $BeefyApi_generate_key_ownership_proof))
(export "MmrApi_mmr_root" (func $MmrApi_mmr_root))
(export "MmrApi_mmr_leaf_count" (func $MmrApi_mmr_leaf_count))
(export "MmrApi_generate_proof" (func $MmrApi_generate_proof))
(export "MmrApi_verify_proof" (func $MmrApi_verify_proof))
(export "MmrApi_verify_proof_stateless" (func $MmrApi_verify_proof_stateless))
(export "GrandpaApi_grandpa_authorities" (func $GrandpaApi_grandpa_authorities))
(export "GrandpaApi_current_set_id" (func $GrandpaApi_current_set_id))
(export "GrandpaApi_submit_report_equivocation_unsigned_extrinsic" (func $GrandpaApi_submit_report_equivocation_unsigned_extrinsic))
(export "GrandpaApi_generate_key_ownership_proof" (func $GrandpaApi_generate_key_ownership_proof))
(export "BabeApi_configuration" (func $BabeApi_configuration))
(export "BabeApi_current_epoch_start" (func $BabeApi_current_epoch_start))
(export "BabeApi_current_epoch" (func $BabeApi_current_epoch))
(export "BabeApi_next_epoch" (func $BabeApi_next_epoch))
(export "BabeApi_generate_key_ownership_proof" (func $BabeApi_generate_key_ownership_proof))
(export "BabeApi_submit_report_equivocation_unsigned_extrinsic" (func $BabeApi_submit_report_equivocation_unsigned_extrinsic))
(export "AuthorityDiscoveryApi_authorities" (func $AuthorityDiscoveryApi_authorities))
(export "SessionKeys_generate_session_keys" (func $SessionKeys_generate_session_keys))
(export "SessionKeys_decode_session_keys" (func $SessionKeys_decode_session_keys))
(export "AccountNonceApi_account_nonce" (func $AccountNonceApi_account_nonce))
(export "TransactionPaymentApi_query_info" (func $TransactionPaymentApi_query_info))
(export "TransactionPaymentApi_query_fee_details" (func $TransactionPaymentApi_query_fee_details))
(export "TransactionPaymentApi_query_weight_to_fee" (func $TransactionPaymentApi_query_weight_to_fee))
(export "TransactionPaymentApi_query_length_to_fee" (func $TransactionPaymentApi_query_length_to_fee))
(export "TransactionPaymentCallApi_query_call_info" (func $TransactionPaymentCallApi_query_call_info))
(export "TransactionPaymentCallApi_query_call_fee_details" (func $TransactionPaymentCallApi_query_call_fee_details))
(export "TransactionPaymentCallApi_query_weight_to_fee" (func $TransactionPaymentCallApi_query_weight_to_fee))
(export "TransactionPaymentCallApi_query_length_to_fee" (func $TransactionPaymentCallApi_query_length_to_fee))
(export "TryRuntime_on_runtime_upgrade" (func $TryRuntime_on_runtime_upgrade))
(export "TryRuntime_execute_block" (func $TryRuntime_execute_block))
(export "__data_end" (global 1))
(export "__heap_base" (global 2))
---v
Workshop: Inspecting Wasm Code
- Once you reach the Polkadot module, and you build your first parachain, repeat the same, I promise you will learn a thing or two :)
Activity: Expected Panics In The Runtime
- Look into the
frame-executivecrate's code. See instances ofpanic!(), and see if you can make sense out of it. - You have 15 minutes!
Lecture Recap (Part 2)
- Recap the syntax of host functions and runtime APIs.
- Considerations:
- Speed
- Native Execution and Versioning
- Panics
- Altering Host Functions
Additional Resources! 😋
Check speaker notes (click "s" 😉)

Notes:
-
Some very recent change the the block building API set: https://github.com/paritytech/substrate/pull/14414
-
New runtime API for building genesis config: https://github.com/paritytech/substrate/pull/14310
-
All Substrate PRs that have added new host functions: https://github.com/paritytech/substrate/issues?q=label%3AE4-newhostfunctions+is%3Aclosed
-
All substrate PRs that have required the client to be update first: https://github.com/paritytech/substrate/issues?q=is%3Aclosed+label%3A%22E10-client-update-first+%F0%9F%91%80%22
-
New metadata version, including types for the runtime API: https://github.com/paritytech/substrate/issues/12939
-
Recent development on api versioning: https://github.com/paritytech/substrate/issues/13138
-
In Substrate, a type needs to provide the environment in which host functions are provided, and can be executed.
We call this an "externality environment", represented by
trait Externalities.
#![allow(unused)] fn main() { SomeExternalities.execute_with(|| { let x = sp_io::storage::get(b"foo"); }); }
Post Lecture Notes
Appendix
Content that is not covered, but is relevant.
---v
Consideration: Runtime API Versioning
- Same principle, but generally easier to deal with.
- Metadata is part of the runtime, known per block.
- Those written in a dynamically typed languages are usually fine 😎.
Notes:
Also, it is arguable to say that the runtime is the boss here. The client must serve the runtime fully, but the runtime may or may not want to support certain APIs for certain applications.
Recall from another slide:
- A lot of other runtime APIs could be optional depending on the context.
---v
Consideration: Runtime API Versioning
- The Rust code (which is statically typed) in substrate client does care if the change is breaking.
- For example, input/output types change. Rust code cannot deal with that!
---v
Consideration: Runtime API Versioning
#![allow(unused)] fn main() { sp_api::decl_runtime_apis! { // latest version fn foo() -> u32; // old version #[changed_in(4)] fn foo() -> u64; } let new_return_type = if api.version < 4 { // this weird function name is generated by decl_runtime_apis! let old_return_type = api.foo_before_version_4(); // somehow convert it. don't care old_return_type.try_into().unwrap() } else { api.foo() } }
---v
Consideration: Runtime API Versioning
Rule of thumb: Every time you change the signature of a host function / runtime API, i.e. change the input/output types, you need to think about this.
But what you have to do is dependent on the scenario.
Activity: API Versioning
-
Look into substrate and find all instances of
#[changed_in(_)]macro to detect runtime api version. -
Then see if/how this is being used in the client code.
-
Find all the
#[version]macros insp-ioto find all the versioned host functions.
Substrate; Show Me The Code
How to use the slides - Full screen (new tab)
Substrate; Show Me The Code 👨💻
Substrate; Show Me The Code 👨💻
Previous lecture was all about high level information; now we want to bridge that to real code.
A Word on Previous Versions
- This is a brand new lecture replacing two old ones, with more focus on rust-docs.
- Since this is the first time, I have kept the old versions around for you to look into
Cambridge-y (adj) - Overall good quality, but with rough edges or imperfections. Especially when related to PBA content.
---v
A Word on the Rust Exam
Two main takeaways from the previous cohort:
- Write more rust-docs, expect them to be read.
- Extensive use of type-system, to prepare you better for FRAME.
Notes:
Personally doing my best to make it hard, but reasonable, such that it prepares you best for in-depth development of Substrate.
---v
Interactive
- This lecture will be interactive.
- Try and learn the technique, not the specific topic.
- Try and repeat the process later.
Notes:
what I am trying to do here is to teach you how to plant a tree rather than giving you the apple.
Documentation Resources
Core
- paritytech.github.io
substratecrate- WIP:
frame,cumulusandpolkadotcrate.
- Github
- Substrate/Polkadot StackExchange
High level
substrate.io*- Discord, Telegram, etc.
Exploring the substrate crate.
https://paritytech.github.io/substrate/master/substrate/index.html
---v
Substrate From Within
Division of substrate when seen from inside:
spscframe/pallet/runtime
Notes:
this should be covered
---v
Substrate Binaries
Notes:
alternative way is to search for [[bin]] in all toml files.
---v
Structure of a Binary Crate
Division of a typical substrate-based project:
node- Contains a
main.rs service.rs- and more!
- Contains a
runtime- Contains a
/src/lib.rs("runtime amalgamator")
- Contains a
- more!
Notes:
node is client side entry point, runtime amalgamator for the runtime.
- looking at node-template, it only has the two.
- node has even more
- polkadot has even more.
---v
Substrate CLI
Study in the docs:
--dev--chain--tmp,--base-path,purge-chain.
Notes:
all commands: https://paritytech.github.io/substrate/master/sc_cli/commands/index.html all args to a typical run command https://paritytech.github.io/substrate/master/sc_cli/commands/struct.RunCmd.html
But then each node can decide which subset of these it chooses, and how it implements it.
https://paritytech.github.io/substrate/master/node_template/cli/enum.Subcommand.html https://paritytech.github.io/substrate/master/node_cli/enum.Subcommand.html
- execution strategies
- database type
- logs
- RPC
- pruning
- sync modes
---v
Wasm Build + std feature.
- How to compile to wasm?
build.rs! - just get your
stdfeatures right please!
Notes:
https://crates.io/crates/substrate-wasm-builder (seen env variables, pretty useful!) https://docs.substrate.io/build/build-process/
---v
Chain Specification
Notes:
raw vs not-raw
#1 Rust-Docs Tip Of All Time
- Search traits, find implementations.
- Examples:
trait Block,trait Extrinsic,trait Header.
#![allow(unused)] fn main() { trait Config { type Foo: SomeTrait<Bar> } }
Notes:
Especially in FRAME, oftentimes you have to parameterize your pallets with a pattern like above. Simply search the trait in the rust-docs, and find the implementors!
Additional Resources! 😋
Check speaker notes (click "s" 😉)

Note:
One important concept that is important to substrate-based chains, but is somewhat missing here is
chain-spec. Make sure to read up about it in the substrate docs.
Interacting With a Substrate Blockchain
How to use the slides - Full screen (new tab)
Interacting With a Substrate Blockchain
Interacting With a Substrate Blockchain

Notes:
Many of these interactions land in a wasm blob.
So what question you need to ask yourself there? which runtime blob.
almost all external communication happens over JSPN-RPC, so let's take a closer look.
JSON-RPC
JSON-RPC is a remote procedure call protocol encoded in JSON. It is similar to the XML-RPC protocol, defining only a few data types and commands.
---v
JSON-RPC
{
"jsonrpc": "2.0",
"method": "subtract",
"params": { "minuend": 42, "subtrahend": 23 },
"id": 3
}
{ "jsonrpc": "2.0", "result": 19, "id": 3 }
---v
JSON-RPC
- Entirely transport agnostic.
- Substrate based chains expose both
websocketandhttp(orwssandhttps, if desired).
with
--ws-portand--rpc-port, 9944 and 9934 respectively.
---v
JSON-RPC
-
JSON-RPC methods are conventionally written as
scope_method- e.g.
rpc_methods,state_call
- e.g.
-
author: for submitting stuff to the chain. -
chain: for retrieving information about the blockchain data. -
state: for retrieving information about the state data. -
system: information about the chain. -
rpc: information about the RPC endpoints.
Notes:
Recall:
- https://paritytech.github.io/substrate/master/sc_rpc_api/index.html
- https://paritytech.github.io/substrate/master/sc_rpc/index.html
The full list can also be seen here: https://polkadot.js.org/docs/substrate/rpc/
---v
JSON-RPC
-
Let's look at a few examples:
-
system_name,system_chain,system_chainType,system_health,system_version,system_nodeRoles,rpc_methods,state_getRuntimeVersion,state_getMetadata
wscat \
-c wss://kusama-rpc.polkadot.io \
-x '{"jsonrpc":"2.0", "id": 42, "method":"rpc_methods" }' \
| jq
---v
JSON-RPC: Runtime Agnostic
- Needless to say, RPC methods are runtime agnostic. Nothing in the above tells you if FRAME is being used or not.
- Except... metadata, to some extent.
---v
JSON-RPC: Runtime API
- While agnostic, many RPC calls land in a runtime API.
- RPC Endpoints have an
at: Option<hash>, runtime APIs do too, what a coincidence! 🌈- Recall the scope
state?
- Recall the scope
---v
JSON-RPC: Extending
- The runtime can extend more custom RPC methods, but the new trend is to move toward using
state_call.
---v
JSON-RPC: Safety
- Some PRC methods are unsafe 😱.
---v
JSON-RPC: Resilience
RPC-Server vs. Light Client
JSON-RPC: Application
-
On top of
SCALEandJSON-RPC, a large array of libraries have been built. -
PJS-API/PJS-APPS -
capi -
subxt -
Any many more!
Notes:
https://github.com/JFJun/go-substrate-rpc-client https://github.com/polkascan/py-substrate-interface more here: https://project-awesome.org/substrate-developer-hub/awesome-substrate
JSON-RPC: Mini Activity
In Kusama:
- Find the genesis hash..
- Number of extrinsics at block 10,000,000.
- The block number is stored under
twox128("System") ++ twox128("Number").- Find it now, and at block 10,000,000.
- Refer to the "Substrate; Show Me The Code" lecture to find the right RPC endpoints.
- You have 15 minutes!
Notes:
# 10,000,000 in hex
printf "%x\n" 10000000
# Genesis hash
wscat -c wss://kusama-rpc.polkadot.io -x '{"jsonrpc":"2.0", "id":72, "method":"chain_getBlockHash", "params": ["0x0"] }' | jq
# Hash of the block at height 10,000,000
wscat -c wss://kusama-rpc.polkadot.io -x '{"jsonrpc":"2.0", "id":72, "method":"chain_getBlockHash", "params": ["0x989680"] }' | jq
# The block at height 1,000,000
wscat -c wss://kusama-rpc.polkadot.io -x '{"jsonrpc":"2.0", "id":72, "method":"chain_getBlock", "params": ["0xdcbaa224ab080f2fbf3dfc85f3387ab21019355c392d79a143d7e50afba3c6e9"] }' | jq
# `0x26aa394eea5630e07c48ae0c9558cef702a5c1b19ab7a04f536c519aca4983ac` now.
wscat -c wss://kusama-rpc.polkadot.io -x '{"jsonrpc":"2.0", "id":72, "method":"state_getStorage", "params": ["0x26aa394eea5630e07c48ae0c9558cef702a5c1b19ab7a04f536c519aca4983ac"] }' | jq
# `0x26aa394eea5630e07c48ae0c9558cef702a5c1b19ab7a04f536c519aca4983ac` at block 1,000,000.
wscat -c wss://kusama-rpc.polkadot.io -x '{"jsonrpc":"2.0", "id":72, "method":"state_getStorage", "params": ["0x26aa394eea5630e07c48ae0c9558cef702a5c1b19ab7a04f536c519aca4983ac", "0xdcbaa224ab080f2fbf3dfc85f3387ab21019355c392d79a143d7e50afba3c6e9"] }' | jq
Notice that this number that we get back is the little endian (SCALE) encoded value that we passed in at first.
Polkadot JS API
A brief introduction.
Excellent tutorial at: https://polkadot.js.org/docs/
---v
Polkadot JS API

---v
PJS: Overview
api.registryapi.rpc
---v
PJS: Overview
Almost everything else basically builds on top of api.rpc.
api.txapi.queryapi.constsapi.derive
Please revise this while you learn FRAME, and they will make perfect sense!
---v
PJS: Workshop 🧑💻
Notes:
import { ApiPromise, WsProvider } from "@polkadot/api";
const provider = new WsProvider("wss://rpc.polkadot.io");
const api = await ApiPromise.create({ provider });
api.stats;
api.isConnected;
// where does this come from?
api.runtimeVersion;
// where does this come from?
api.registry.chainDecimals;
api.registry.chainTokens;
api.registry.chainSS58;
// where does this come from?
api.registry.metadata;
api.registry.metadata.pallets.map(p => p.toHuman());
api.registry.createType();
api.rpc.chain.getBlock()
api.rpc.system.health()
await api.rpc.system.version()
await api.rpc.state.getRuntimeVersion()
await api.rpc.state.getPairs("0x")
await api.rpc.state.getKeysPaged("0x", 100)
await api.rpc.state.getStorage()
await api.rpc.state.getStorageSize("0x3A636F6465"),
https://polkadot.js.org/docs/substrate/rpc#getstoragekey-storagekey-at-blockhash-storagedata
A few random other things:
api.createType("Balance", new Uint8Array([1, 2, 3, 4]));
import { blake2AsHex, xxHashAsHex } from "@polkadot/util-crypto";
blake2AsHex("Foo");
xxHashAsHex("Foo");
subxt
- Something analogous to
PJSfor Rust. - The real magic is that it generates the types by fetching the metadata at compile time, or linking it statically.
- ..It might need manual updates when the code, and therefore the metadata changes.
Additional Resources! 😋
Check speaker notes (click "s" 😉)
Notes:
- see "Client Libraries" here: https://project-awesome.org/substrate-developer-hub/awesome-substrate
- https://paritytech.github.io/json-rpc-interface-spec/introduction.html
- Full
subxtguide: https://docs.rs/subxt/latest/subxt/book/index.html
Substrate Transaction Pool and its Runtime API
How to use the slides - Full screen (new tab)
Substrate's Transaction Pool
Transaction Pools



Notes:
The blockchain produces blockspace, and users buy that blockspace. Why do they buy it? So they can contribute to the shared story. So they can interact with the shared state machine. You can think of these users standing in line with transactions in their hand, waiting for the chance to put their transactions into the chain's blockspace. Sometimes the demand for blockspace is low and the queue is short. In this case the queue gets completely emptied each time a new block is created. Other times it gets long and backed up. Then when a block comes, only a part of the queue gets emptied.
This simple model provides some good intuition about how the transaction pool works, but it is a bit simplified.
First, It is actually a priority queue. You can jump the line by offering to bribe the block producers.
Second, it is more accurate to think of the transactions themselves waiting in line, not the users who sent those transactions.
Let's take a closer look.
---v
Paths of a Transaction

Notes:
Previously, in the blockchain module, we saw this figure. It points out that each node has its own view of the blockchain. Now I'll show you another layer of detail which is that each node also has its own transaction pool CLICK
---v
Paths of a Transaction

Notes:
There are many paths a transaction can take from the user who signed it to a finalized block. Let's talk through some. Directly to user's authoring node and into chain is simplest. Could also be gossiped to other author. Could even go in a block, get orphaned off, back to tx pool, and then in a new block
---v
Pool Validation
- Check signature
- Check that sender can afford fees
- Make sure state is ready for application
Notes:
When a node gets a transaction, it does some light pre-validation sometimes known as pool validation. This checking determines whether the transactions is {valid now, valid in some potential future, invalid}. There is periodic re-validation if transactions have been in the pool for a long time.
---v
Pool Prioritization
- Priority Queue
- Prioritized by...
- Fee
- Bribe
- Fee per blockspace
- This is all off-chain
Notes:
There are a few more things the Substrate tx pool does too, and we will look at them in detail soon.
Tx Pool Runtime Api
#![allow(unused)] fn main() { pub trait TaggedTransactionQueue<Block: BlockT>: Core<Block> { fn validate_transaction( &self, __runtime_api_at_param__: <Block as BlockT>::Hash, source: TransactionSource, tx: <Block as BlockT>::Extrinsic, ) -> Result<TransactionValidity, ApiError> { ... } } }
TaggedTransactionQueue Rustdocs
Introduced in paritytech/substrate#728
Notes:
This is another runtime api, similar to the block builder and the core that are used for creating and importing blocks. Like most others, it requires that the Core api also be implemented.
This one is slightly different in that it is actually called from off-chain, and is not part of your STF. So let's talk about that for a little bit.
---v
Runtime vs STF

Notes:
It is commonly said that the runtime is basically your STF. This is a good first order approximation. It is nearly true.
---v
Runtime vs STF

Notes:
But as we can see here, when we put our glasses on, actually only some of the apis are part of the stf.
---v
Why is pool logic in the runtime?
- Transaction type is Opaque
- Runtime logic is opaque
- You must understand the transaction to prioritize it
Notes:
So if this is not part of the STF why is it in the runtime at all? This logic is tightly related to the runtime application logic. The types are opaque outside of the runtime. So this logic must go in the runtime.
But if it is not on-chain, can individual validators customize it. In short yes. There is a mechanism for this. We won't go deeply into the mechanism, but validators can specify alternate wasm blocs to use instead of the official one.
Jobs of the API
- Make fast pre-checks
- Give the transaction a priority
- Determine whether the transaction is ready now or may be ready in the future
- Determine a dependency graph among the transactions
Notes:
So we spoke earlier about the jobs of a transaction pool in general. Specifically the pre-checks and the priority Here is a more specific list of tasks that Substrate's TaggedTransactionPool does.
The second two points are the new additions, and they are the duty of the "tags" after which the tagged transaction queue is named.
The results of all of this are returned to the client side through a shared type ValidTransaction or InvalidTransaction
---v
ValidTransaction
#![allow(unused)] fn main() { pub struct ValidTransaction { pub priority: TransactionPriority, pub requires: Vec<TransactionTag>, pub provides: Vec<TransactionTag>, pub longevity: TransactionLongevity, pub propagate: bool, } }
Notes:
We indicate that the transaction passes the prechecks at all by returning this valid transaction struct.
If it weren't even valid, we would return a different, InvalidTransaction struct.
You learned yesterday how to navigate the rustdocs to find the docs on that one.
Priority we've discussed. It is worth noting that the notion of priority is intentionally opaque to the client. The runtime may assign this value however it sees fit.
Provides and requires all forming a dependency graph between the transactions. Requires is a list of currently unmet dependency transactions. This transaction will be ready in a future where these dependencies are met so it is kept in the pool.
A simple intuitive example of this is payments. Image alice pays bob some tokens in transaction1. Then bob pays those same tokes to charlie in transaction2. trasnaction2 will be valid only after transaction1 has been applied. It is a dependency.
Longevity is a field I'm not so familiar with. It is how long the transaction should stay in the pool before being dropped or re-validated.
And finally whether the transaction should be gossiped. This is usually true. Only in special edge cases would this be false.
---v
Example 1: UTXO System

Notes:
Prioritize by implicit tip (difference of inputs and outputs) Requires all missing input transactions provides this input
---v
Example 2: Nonced Account System

Notes:
Prioritize by explicit tip Requires all previous nonces for this account provides this nonce for this account
This demonstrates one of the biggest downsides of the Accounts system. Transactions cannot deterministically specify the initial state on which they operate. There is only an inherent ordering between transactions from the same account.
---v
Always Re-check On-chain
Notes:
None of this new pool information changes the fundamentals you learned last week. You must execute the state transitions in full on chain.
Most of the time you are not the block author. When you import a block from another node, you cannot trust them to have done the pre-checks correctly.
SCALE Codec
How to use the slides - Full screen (new tab)
SCALE Codec
SCALE Codec
At the end of this lecture, you will learn why Substrate uses SCALE codec, how all different kinds of data types are encoded.
SCALE
Simple Concatenated Aggregate Little-Endian
SCALE is a light-weight format which allows encoding (and decoding) which makes it highly suitable for resource-constrained execution environments like blockchain runtimes and low-power, low-memory devices.
Little-Endian
Little endian systems store the least significant byte at the smallest memory address.
Wasm is a little endian system, which makes SCALE very performant.


Why SCALE? Why not X?
- Simple to define.
- Not Rust-specific (but happens to work great in Rust).
- Easy to derive codec logic:
#[derive(Encode, Decode)] - Viable and useful for APIs like:
MaxEncodedLenandTypeInfo - It does not use Rust
std, and thus can compile to Wasmno_std.
- Easy to derive codec logic:
- Consensus critical / bijective; one value will always encode to one blob and that blob will only decode to that value.
- Supports a copy-free decode for basic types on LE architectures.
- It is about as thin and lightweight as can be.
SCALE is NOT Self-Descriptive
It is important to note that the encoding context (knowledge of how the types and data structures look) needs to be known separately at both encoding and decoding ends.
The encoded data does not include this contextual information.
Example: SCALE vs JSON
use parity_scale_codec::{ Encode }; #[derive(Encode)] struct Example { number: u8, is_cool: bool, optional: Option<u32>, } fn main() { let my_struct = Example { number: 42, is_cool: true, optional: Some(69), }; println!("{:?}", my_struct.encode()); println!("{:?}", my_struct.encode().len()); }
[42, 1, 1, 69, 0, 0, 0]
7
use serde::{ Serialize }; #[derive(Serialize)] struct Example { number: u8, is_cool: bool, optional: Option<u32>, } fn main() { let my_struct = Example { number: 42, is_cool: true, optional: Some(69), }; println!("{:?}", serde_json::to_string(&my_struct).unwrap()); println!("{:?}", serde_json::to_string(&my_struct).unwrap().len()); }
"{\"number\":42,\"is_cool\":true,\"optional\":69}"
42
Try It Yourself!
mkdir temp
cd temp
cargo init
cargo add parity-scale-codec --features derive
Little vs Big Endian Output
It can be confusing to read the output, and keep in mind endianness.
The order of bytes in the vector follow endianness, but the hex and binary representation of each byte is the same, and independent of endianness.
0b prefix denotes a binary representation, and 0x denotes a hex representation.
fn main() { println!("{:b}", 69i8); println!("{:02x?}", 69i8.to_le_bytes()); println!("{:02x?}", 69i8.to_be_bytes()); println!("{:b}", 42u16); println!("{:02x?}", 42u16.to_le_bytes()); println!("{:02x?}", 42u16.to_be_bytes()); println!("{:b}", 16777215u32); println!("{:02x?}", 16777215u32.to_le_bytes()); println!("{:02x?}", 16777215u32.to_be_bytes()); }
1000101
[45]
[45]
101010
[2a, 00]
[00, 2a]
111111111111111111111111
[ff, ff, ff, 00]
[00, ff, ff, ff]
Fixed Width Integers
Basic integers are encoded using a fixed-width little-endian (LE) format.
use parity_scale_codec::Encode; fn main() { println!("{:02x?}", 69i8.encode()); println!("{:02x?}", 69u8.encode()); println!("{:02x?}", 42u16.encode()); println!("{:02x?}", 16777215u32.encode()); }
[45]
[45]
[2a, 00]
[ff, ff, ff, 00]
Notes:
notice the first two being the same. SCALE IS NOT DESCRIPTIVE of the type. The decoder is responsible for decoding this into some 1 byte-width type, be it u8 or i8 or something else.
Compact Integers
A "compact" or general integer encoding is sufficient for encoding large integers (up to 2536) and is more efficient at encoding most values than the fixed-width version.
Though for single-byte values, the fixed-width integer is never worse.
Compact Prefix
0b00 | 0b01 | 0b10 | 0b11 |
|---|---|---|---|
single-byte mode; upper six bits are the LE encoding of the value. Valid only for values of 0 through 63. | two-byte mode: upper six bits and the following byte is the LE encoding of the value. Valid only for values 64 through (2^14 - 1). | four-byte mode: upper six bits and the following three bytes are the LE encoding of the value. Valid only for values (2^14) through (2^30 - 1). | Big-integer mode: The upper six bits are the number of bytes following, plus four. The value is contained, LE encoded, in the bytes following. The final (most significant) byte must be non-zero. Valid only for values (2^30) through (2^536 - 1). |
Compact/general integers are encoded with the two least significant bits denoting the mode.
Compact Integers: 0
use parity_scale_codec::{Encode, HasCompact}; #[derive(Encode)] struct AsCompact<T: HasCompact>(#[codec(compact)] T); fn main() { println!("{:02x?}", 0u8.encode()); println!("{:02x?}", 0u32.encode()); println!("{:02x?}", AsCompact(0u8).encode()); println!("{:02x?}", AsCompact(0u32).encode()); }
[00]
[00, 00, 00, 00]
[00]
[00]
Compact Integers: 42
use parity_scale_codec::{Encode, HasCompact}; #[derive(Encode)] struct AsCompact<T: HasCompact>(#[codec(compact)] T); fn main() { println!("{:02x?}", 42u8.encode()); println!("{:02x?}", 42u32.encode()); println!("{:02x?}", AsCompact(42u8).encode()); println!("{:02x?}", AsCompact(42u32).encode()); }
[2a]
[2a, 00, 00, 00]
[a8]
[a8]
- 42 as binary:
0b101010=[0x2a]. - Add
00to the least significant bits. 0b10101000=[0xa8]= 168 as decimal.
Compact Integers: 69
use parity_scale_codec::{Encode, HasCompact}; #[derive(Encode)] struct AsCompact<T: HasCompact>(#[codec(compact)] T); fn main() { println!("{:02x?}", 69u8.encode()); println!("{:02x?}", 69u32.encode()); println!("{:02x?}", AsCompact(69u8).encode()); println!("{:02x?}", AsCompact(69u32).encode()); }
[45]
[45, 00, 00, 00]
[15, 01]
[15, 01]
- 69 as binary:
0b1000101=[0x45]. - Add
01to the least significant bits. 0b100010101=[0x15, 0x01]= 277 as decimal.
Compact Integers: 65535 (u16::MAX)
use parity_scale_codec::{Encode, HasCompact}; #[derive(Encode)] struct AsCompact<T: HasCompact>(#[codec(compact)] T); fn main() { println!("{:02x?}", 65535u16.encode()); println!("{:02x?}", 65535u32.encode()); println!("{:02x?}", AsCompact(65535u16).encode()); println!("{:02x?}", AsCompact(65535u32).encode()); }
[ff, ff]
[ff, ff, 00, 00]
[fe, ff, 03, 00]
[fe, ff, 03, 00]
- 65535 as binary:
0b1111111111111111=[0xff, 0xff]. - Add
10to the least significant bits. 0b111111111111111110=[0xfe, 0xff, 0x03, 0x00]: 262142 as decimal.
Compact Integers Are "Backwards Compatible"
As you can see, you are able to "upgrade" a type without affecting the encoding.
Enum
Prefix with index (u8), then the value, if any.
use parity_scale_codec::Encode; #[derive(Encode)] enum Example { First, Second(u8), Third(Vec<u8>), Fourth, } fn main() { println!("{:02x?}", Example::First.encode()); println!("{:02x?}", Example::Second(2).encode()); println!("{:02x?}", Example::Third(vec![0, 1, 2, 3, 4]).encode()); println!("{:02x?}", Example::Fourth.encode()); }
[00]
[01, 02]
[02, 14, 00, 01, 02, 03, 04]
[03]
Tuple and Struct
Just encode and concatenate the items.
use parity_scale_codec::Encode; #[derive(Encode)] struct Example { number: u8, is_cool: bool, optional: Option<u32>, } fn main() { let my_struct = Example { number: 0, is_cool: true, optional: Some(69), }; println!("{:02x?}", (0u8, true, Some(69u32)).encode()); println!("{:02x?}", my_struct.encode()); }
[00, 01, 01, 45, 00, 00, 00]
[00, 01, 01, 45, 00, 00, 00]
Notes:
Note that tuple and struct encode the same, even though struct has named fields.
Embedded Compact
use parity_scale_codec::Encode; #[derive(Encode)] struct Example { number: u64, #[codec(compact)] compact_number: u64, } #[derive(Encode)] enum Choices { One(u64, #[codec(compact)] u64), } fn main() { let my_struct = Example { number: 42, compact_number: 1337 }; let my_choice = Choices::One(42, 1337); println!("{:02x?}", my_struct.encode()); println!("{:02x?}", my_choice.encode()); }
[2a, 00, 00, 00, 00, 00, 00, 00, e5, 14]
[00, 2a, 00, 00, 00, 00, 00, 00, 00, e5, 14]
Unit, Bool, Option, and Result
use parity_scale_codec::Encode; fn main() { println!("{:02x?}", ().encode()); println!("{:02x?}", true.encode()); println!("{:02x?}", false.encode()); println!("{:02x?}", Ok::<u32, ()>(42u32).encode()); println!("{:02x?}", Err::<u32, ()>(()).encode()); println!("{:02x?}", Some(42u32).encode()); println!("{:02x?}", None::<u32>.encode()); }
[]
[01]
[00]
[00, 2a, 00, 00, 00]
[01]
[01, 2a, 00, 00, 00]
[00]
Arrays, Vectors, and Strings
- Arrays: Just concatenate the items.
- Vectors: Also prefix with length (compact encoded).
- String: Just
Vec<u8>as utf-8 characters.
use parity_scale_codec::Encode; fn main() { println!("{:02x?}", [0u8, 1u8, 2u8, 3u8, 4u8].encode()); println!("{:02x?}", vec![0u8, 1u8, 2u8, 3u8, 4u8].encode()); println!("{:02x?}", "hello".encode()); println!("{:02x?}", vec![0u8; 1024].encode()); }
[00, 01, 02, 03, 04]
[14, 00, 01, 02, 03, 04]
[14, 68, 65, 6c, 6c, 6f]
[01, 10, 00, 00, ... snip ... , 00]
Notes:
Note that the length prefix can be multiple bytes, like the last example.
Decoding
We can similarly take raw bytes, and decode it into a well known type.
Metadata can be used to convey to a program how to decode a type properly...
But bad or no information means the proper format for the data cannot be known.
Decoding Examples
use parity_scale_codec::{ Encode, Decode, DecodeAll }; fn main() { let array = [0u8, 1u8, 2u8, 3u8]; let value: u32 = 50462976; println!("{:02x?}", array.encode()); println!("{:02x?}", value.encode()); println!("{:?}", u32::decode(&mut &array.encode()[..])); println!("{:?}", u16::decode(&mut &array.encode()[..])); println!("{:?}", u16::decode_all(&mut &array.encode()[..])); println!("{:?}", u64::decode(&mut &array.encode()[..])); }
[00, 01, 02, 03]
[00, 01, 02, 03]
Ok(50462976)
Ok(256)
Err(Error { cause: None, desc: "Input buffer has still data left after decoding!" })
Err(Error { cause: None, desc: "Not enough data to fill buffer" })
Notes:
- Decoding can fail
- Values can decode badly
Decode Limits
- Decoding isn't free!
- The more complex the decode type, the more computation that will be used to decode the value.
- Generally you always want to
decode_with_depth_limit. - Substrate uses a limit of 256.
Decode Bomb
Here is an example of a decode bomb.
use parity_scale_codec::{ Encode, Decode, DecodeLimit }; #[derive(Encode, Decode, Debug)] enum Example { First, Second(Box<Self>), } fn main() { let bytes = vec![1, 1, 1, 1, 1, 0]; println!("{:?}", Example::decode(&mut &bytes[..])); println!("{:?}", Example::decode_with_depth_limit(10, &mut &bytes[..])); println!("{:?}", Example::decode_with_depth_limit(3, &mut &bytes[..])); }
Ok(Second(Second(Second(Second(Second(First))))))
Ok(Second(Second(Second(Second(Second(First))))))
Err(Error { cause: Some(Error { cause: Some(Error { cause: Some(Error { cause: Some(Error { cause: None, desc: "Maximum recursion depth reached when decoding" }), desc: "Could not decode `Example::Second.0`" }), desc: "Could not decode `Example::Second.0`" }), desc: "Could not decode `Example::Second.0`" }), desc: "Could not decode `Example::Second.0`" })
Exceptions: BTreeSet
BTreeSet will decode from an unordered set, but will also order them as a result.
Be careful... this one isn't bijective.
use parity_scale_codec::{ Encode, Decode, alloc::collections::BTreeSet }; fn main() { let vector = vec![4u8, 3u8, 2u8, 1u8, 0u8]; let vector_encoded = vector.encode(); let btree = BTreeSet::<u8>::decode(&mut &vector_encoded[..]).unwrap(); let btree_encoded = btree.encode(); println!("{:02x?}", vector_encoded); println!("{:02x?}", btree_encoded); }
[14, 04, 03, 02, 01, 00]
[14, 00, 01, 02, 03, 04]
Optimizations and Tricks
-
DecodeLength: Read the length of a collection (likeVec) without decoding everything. -
EncodeAppend: Append an item without decoding all the other items. (likeVec)
Implementations
SCALE Codec has been implemented in other languages, including:
- Python:
polkascan/py-scale-codec - Golang:
itering/scale.go - C:
MatthewDarnell/cScale - C++:
soramitsu/scale-codec-cpp - JavaScript:
polkadot-js/api - TypeScript:
scale-ts - AssemblyScript:
LimeChain/as-scale-codec - Haskell:
airalab/hs-web3 - Java:
emeraldpay/polkaj - Ruby:
wuminzhe/scale_rb
Missing Some Metadata?
To make SCALE useful as an encoding format within the Substrate and Polkadot ecosystem, we need to figure out a way to provide metadata about all the types we will expect, and when we will expect them.
HINT: We do.
Remember, in the end of the day, everything is just 0's and 1's.
Additional Resources! 😋
Check speaker notes (click "s" 😉)

Substrate and FRAME Tips and Tricks
How to use the slides - Full screen (new tab)
Substrate and FRAME Tips and Tricks
Notes:
- A random collection of things that you should probably know about.
- These are relevant for coding in FRAME and Substrate.
Part 1 Substrate Stuff
<Type as Trait>::AssociatedType
- The single most useful Rust syntactic detail that you MUST know.
Notes:
what is a type? A struct is a type. An unum is a type. all primitives are type. A lot of things are types.
---v
<Type as Trait>::AssociatedType
Example:
#![allow(unused)] fn main() { trait Config { type Extrinsic type Header: HeaderT } pub type ExtrinsicFor<C> = <C as Config>::Extrinsic; fn process_extrinsic<C>(<C as Config>::Extrinsic) { .. } fn process_extrinsic<C>(BlockFor<C>) { .. } trait HeaderT { type Number; } pub type NumberFor<C> = <<C as Config>::Header as HeaderT>::Number; }
Notes:
turbo fish fully qualified syntax.
---v
Speaking of Traits..
- What is the difference between generics and associated types?
#![allow(unused)] fn main() { trait Block<Extrinsic> { fn execute(e: Extrinsic) } }
vs
#![allow(unused)] fn main() { trait Block { type Extrinsic; fn execute(e: Self::Extrinsic) } }
Notes:
In cambridge, I did this this. But since students should now know traits really well, I will drop it.
trait Engine { fn start() {} } struct BMW; impl Engine for BMW {} trait Brand { fn name() -> &'static str; } trait Car<E: Engine> { type Brand: Brand; } struct KianCarCo; impl Brand for KianCarCo { fn name() -> &'static str { "KianCarCo!" } } struct MyCar; impl<E: Engine> Car<E> for MyCar { type Brand = MyBrand; } fn main() { // Car<E1>, Car<E2> are different traits! // Generics can be bounded, or constrained // impl<E: Engine> Car<E> {} // impl Car<BMW> {} // Associated types can: // only be bounded when being defined, // Can be constrained when being implemented, or when the trait is being used. fn some_fn<E: Engine, C: Car<E, Brand = MyBrand>>(car: C) { // and we are told associated types are more like output types, lets get the brand of car let name = <<C as Car<E>>::Brand as Brand>::name(); } fn other_fn<C: Car<BMW, Brand = MyBrand>>(car: C) { } // now, check this out }
---v
Speaking of Traits..
Both generics and associated types can be specified, but the syntax is a bit different.
#![allow(unused)] fn main() { trait Block<Extrinsic> { type Header } fn process_block<B: Block<E1, Header = H1>>(b: B) }
---v
Speaking of Traits..
- Anything that can be expressed with associated types can also be expressed with generics.
- Associated Types << Generics
- Associated types usually lead to less boilerplate.
The std Paradigm
-
Recap:
stdis the interface to the common OS-abstractions.coreis a subset ofstdthat makes no assumption about the operating system.
-
a
no_stdcrate is one that relies oncorerather thanstd.
---v
Cargo Features
- Way to compile different code via flags.
- Crates define some features in their
Cargo.toml - Crates can conditionally enable features of their dependencies as well.
[dependencies]
other-stuff = { version = "1.0.0" }
[features]
default = [""]
additional-features = ["other-stuff/on-steroids"]
Notes:
imagine that you have a crate that has some additional features that are not always needed. You put
that behind a feature flag called additional-features.
---v
Cargo Features: Substrate Wasm Crates
[dependencies]
dep1 = { version = "1.0.0", default-features = false }
dep2 = { version = "1.0.0", default-features = false }
[features]
default = ["std"]
std = [
"dep1/std"
"dep2/std"
]
Notes:
every crate will have a feature "std". This is a flag that you are compiling with the standard library. This is the default.
Then, bringing a dependency with default-features = false means by default, don't enable this
dependencies "std".
Then, in std = ["dep/std"] you are saying "if my std is enabled, enable my dependencies std as
well".
---v
Cargo Features
- The name "
std" is just an idiom in the rust ecosystem. no_stddoes NOT mean Wasm!stddoes not mean native!
Notes:
But in substrate, it kinda means like that:
std => native no_std => wasm
---v
The std Paradigm
- All crates in substrate that eventually compile to Wasm:
#![allow(unused)] #![cfg_attr(not(feature = "std"), no_std)] fn main() { }
---v
The std Paradigm: Adding dependencies
error: duplicate lang item in crate sp_io (which frame_support depends on): panic_impl.
|
= Notes:
the lang item is first defined in crate std (which serde depends on)
error: duplicate lang item in crate sp_io (which frame_support depends on): oom.
|
= Notes:
the lang item is first defined in crate std (which serde depends on)
---v
The std Paradigm
A subset of the standard types in rust that also exist in rust core are re-exported from
sp_std.
#![allow(unused)] fn main() { sp_std::prelude::*; }
Notes:
Hashmap not exported due to non-deterministic concerns.
floats are usable, but also non-deterministic! (and I think they lack encode, decode impl)
interesting to look at if_std macro in sp_std.
Logging And Prints In The Runtime.
- First, why bother? let's just add as many logs as we want into the runtime.
- Size of the wasm blob matters..
- Any logging increases the size of the Wasm blob. String literals are stored somewhere in your program!
---v
Logging And Prints In The Runtime.
-
wasm2wat polkadot_runtime.wasm > dump | rg stripped -
Should get you the
.rodata(read-only data) line of the wasm blob, which contains all the logging noise. -
This contains string literals form errors, logs, metadata, etc.
---v
Logging And Prints In The Runtime.
#![allow(unused)] fn main() { #[derive(sp_std::fmt::Debug)] struct LONG_AND_BEAUTIFUL_NAME { plenty: u32, of: u32, fields: u32, with: u32, different: u32 names: u32 } }
will add a lot of string literals to your wasm blob.
---v
Logging And Prints In The Runtime.
sp_std::fmt::Debug vs sp_debug_derive::RuntimeDebug
Notes:
https://paritytech.github.io/substrate/master/sp_debug_derive/index.html
---v
Logging And Prints In The Runtime.
#![allow(unused)] fn main() { #[derive(RuntimeDebug)] pub struct WithDebug { foo: u32, } impl ::core::fmt::Debug for WithDebug { fn fmt(&self, f: &mut ::core::fmt::Formatter) -> ::core::fmt::Result { #[cfg(feature = "std)] { fmt.debug_struct("WithRuntimeDebug") .field("foo", &self.foo) .finish() } #[cfg(not(feature = "std))] { fmt.write("<wasm:stripped>") } } } }
---v
Logging And Prints In The Runtime.
Once types implement Debug or RuntimeDebug, they can be printed. Various ways:
- If you only want something in tests, native builds etc
#![allow(unused)] fn main() { sp_std::if_std! { println!("hello world!"); dbg!(foo); } }
---v
Logging And Prints In The Runtime.
- Or you can use the common
logcrate
#![allow(unused)] fn main() { log::info!(target: "foo", "hello world!"); log::debug!(target: "bar", "hello world! ({})", 10u32); }
---v
Logging And Prints In The Runtime.
- But
logcrate doesn't do much in itself! it needs two additional steps to work:
// $ RUST_LOG=foo=debug,bar=trace cargo runsp_tracing::try_init_simple()
Notes:
https://paritytech.github.io/substrate/master/sp_tracing/index.html
---v
Logging And Prints In The Runtime.
- Log statements are only evaluated if the corresponding level and target is met.
#![allow(unused)] fn main() { /// only executed if `RUST_LOG=KIAN=trace` frame_support::log::trace!(target: "KIAN", "({:?})", (0..100000).into_iter().collect()); }
Notes:
log in rust does not do anything -- it only tracks what needs to be logged. Then you need a logger
to actually export them. In rust this is often env_logger or sp_tracing in substrate tests.
In the runtime, the log messages are sent via the host functions to the client to be printed.
If the interface is built with disable-logging, it omits all log messages.
Arithmetic Helpers, and the f32, f64 Story.
-
Floating point numbers have different standards, and (slightly) different implementations on different architectures and vendors.
-
If my balance is
10.000000000000001DOT on one validator and10.000000000000000DOT on another validator, game over for your consensus 😮💨.
---v
PerThing.
> .2 + .2 + .2 == .6
> false
> a = 10
> b = 0.1
> c = 0.2
> a*(b+c) == a*b + a*c
> false
- Search "weird float behavior" for more entertainment around this.
---v
PerThing.
- We store ratios and such in the runtime with "Fixed-Point" arithmetic types.
#![allow(unused)] fn main() { struct Percent(u8); impl Percent { fn new(x: u8) { Self(x.min(100)); } } impl Mul<u32> for Percent { ... } }
---v
PerThing.
#![allow(unused)] fn main() { use sp_arithmetic::Perbill; let p = Perbill::from_part_parts(1_000_000_000u32 / 4); let p = Perbill::from_percent(25); let p = Perbill::from_rational(1, 4); > p * 100u32; > 25u32; }
- Some precision concerns exist, but that's a story for another day.
---v
Fixed Point Numbers
Per-thing is great for representing [0, 1] range.
What if we need more?
100 ~ 1
200 ~ 2
300 ~ 3
350 ~ 3.5
---v
Fixed Point Numbers
#![allow(unused)] fn main() { use sp_arithmetic::FixedU64; let x = FixedU64::from_rational(5, 2); let y = 10u32; let z = x * y; > 25 }
---v
Larger Types
U256,U512: battle-tested since the ethereum days.- substrate-fixed: community project. Supercharged
PerThingandFixed. big_uint.rs(unaudited)
#![allow(unused)] fn main() { pub struct BigUint { /// digits (limbs) of this number (sorted as msb -> lsb). pub(crate) digits: Vec<Single>, } }
---v
Arithmetic Types
- See
sp-arithmeticto learn more.
Fallibility: Math Operations
Things like addition, multiplication, division could all easily fail.
- Panic
u32::MAX * 2 / 2(in debug builds)100 / 0
- Overflow
u32::MAX * 2 / 2(in release builds)
---v
Fallibility: Math Operations
-
Checked-- prevention ✋🏻if let Some(outcome) = a.checked_mul(b) { ... } else { ... } -
Saturating-- silent recovery 🤫let certain_output = a.saturating_mul(b);
Notes:
Why would you ever want to saturate? only in cases where you know if the number is overflowing, other aspects of the system is so fundamentally screwed that there is no point in doing any kind of recovery.
There's also wrapping_op and carrying_op etc on all rust primitives, but not quite
relevant.
https://doc.rust-lang.org/std/primitive.u32.html#method.checked_add https://doc.rust-lang.org/std/primitive.u32.html#method.saturating_add
---v
Fallibility: Conversion
fn main() { let a = 1000u32 as u8; println!("{}", a); // }
Notes:
conversion of primitive number types is also a common point of error. Avoid as.
---v
Fallibility: Conversion
- Luckily, rust is already pretty strict for the primitive types.
TryInto/TryFrom/From/Into
#![allow(unused)] fn main() { impl From<u16> for u32 { fn from(x: u16) -> u32 { x as u32 // ✅ } } }
#![allow(unused)] fn main() { impl TryFrom<u32> for u16 { fn try_from(x: u32) -> Result<u16, _> { if x >= u16::MAX { Err(_) } else { Ok(x as u16) } } } }
Notes:
Typically you don't implement Into and TryInto, because of blanket impls. See:
https://doc.rust-lang.org/std/convert/trait.From.html
For any T and U, impl From<T> for U implies impl Into<U> for T
---v
Fallibility: Conversion
struct Foo<T: From<u32>>
T is u32 or larger.
struct Foo<T: Into<u32>>
T is u32 or smaller.
struct Foo<T: TryInto<u32>>
T can be any of numeric types.
---v
Fallibility: Conversion
- Substrate also provides a trait for infallible saturated conversion as well.
- See
sp-arithmeticfor more handy stuff.
#![allow(unused)] fn main() { trait SaturatedConversion { fn saturated_into<T>(self) -> T } assert_eq!(u128::MAX.saturating_into::<u32>(), u32::MAX); }
Notes:
https://paritytech.github.io/substrate/master/sp_arithmetic/traits/trait.SaturatedConversion.html
Part 2: FRAME Stuff
trait Get
A very basic, yet very substrate-idiomatic way to pass values through types.
#![allow(unused)] fn main() { pub trait Get<T> { fn get() -> T; } }
#![allow(unused)] fn main() { // very basic blanket implementation, which you should be very versed in reading. impl<T: Default> Get<T> for () { fn get() -> T { T::default() } } }
#![allow(unused)] fn main() { struct Foo<G: Get<u32>>; let foo = Foo<()>; }
Notes:
implementing defaults for () is a very FRAME-idiomatic way of doing things.
---v
trait Get
#![allow(unused)] fn main() { parameter_types! { pub const Foo: u32 = 10; } }
#![allow(unused)] fn main() { // expands to: pub struct Foo; impl Get<u32> for Foo { fn get() -> u32 { 10; } } }
Notes:
You have implemented this as a part of your rust exam.
bounded
BoundedVec,BoundedSlice,BoundedBTreeMap,BoundedSlice
#![allow(unused)] fn main() { #[derive(Encode, Decode)] pub struct BoundedVec<T, S: Get<u32>>( pub(super) Vec<T>, PhantomData<S>, ); }
-
PhantomData?
---v
bounded
- Why not do a bounded type like this? 🤔
#![allow(unused)] fn main() { #[cfg_attr(feature = "std", derive(Serialize))] #[derive(Encode)] pub struct BoundedVec<T>( pub(super) Vec<T>, u32, ); }
---v
bounded
Get trait is a way to convey values through types. The type system is mostly for compiler, and
has minimal overhead at runtime.
trait Convert
#![allow(unused)] fn main() { pub trait Convert<A, B> { fn convert(a: A) -> B; } }
#![allow(unused)] fn main() { pub struct Identity; // blanket implementation! impl<T> Convert<T, T> for Identity { fn convert(a: T) -> T { a } } }
Notes:
this one's much simpler, but good excuse to teach them blanket implementations.
---v
Example of Get and Convert
#![allow(unused)] fn main() { /// Some configuration for my module. trait Config { /// Something that gives you a `u32`. type MaximumSize: Get<u32>; /// Something that is capable of converting `u64` to `u32`, /// which is pretty damn hard. type Convertor: Convertor<u64, u32>; } }
#![allow(unused)] fn main() { struct Runtime; impl Config for Runtime { type MaximumSize = (); type Convertor = SomeType } }
#![allow(unused)] fn main() { Runtime as Config>::Convertor::convert(_, _); }
#![allow(unused)] fn main() { fn generic_fn<T: Config>() { <T as Config>::Convertor::convert(_, _)} }
Notes:
often times, in examples above, you have to use this syntax: https://doc.rust-lang.org/book/ch19-03-advanced-traits.html#fully-qualified-syntax-for-disambiguation-calling-methods-with-the-same-name
Implementing Traits For Tuples
#![allow(unused)] fn main() { struct Module1; struct Module2; struct Module3; trait OnInitialize { fn on_initialize(); } impl OnInitialize for Module1 { fn on_initialize() {} } impl OnInitialize for Module2 { fn on_initialize() {} } impl OnInitialize for Module3 { fn on_initialize() {} } }
How can I easily invoke OnInitialize on all 3 of Module1, Module2, Module3?
Notes:
Alternative, but this needs allocation:
struct Module1;
struct Module2;
struct Module3;
trait OnInitializeDyn {
fn on_initialize(&self);
}
impl OnInitializeDyn for Module1 { fn on_initialize(&self) {} }
impl OnInitializeDyn for Module2 { fn on_initialize(&self) {} }
impl OnInitializeDyn for Module3 { fn on_initialize(&self) {} }
fn main() {
let x: Vec<Box<dyn OnInitializeDyn>> = vec![Box::new(Module1), Box::new(Module2)];
x.iter().for_each(|i| i.on_initialize());
}
---v
Implementing Traits For Tuples
-
on_initialize, in its ideal form, does not have&self, it is defined on the type, not a value. -
Tuples are the natural way to group types together (analogous to have a vector is the natural way to group values together..)
#![allow(unused)] fn main() { // fully-qualified syntax - turbo-fish. <(Module1, Module2, Module3) as OnInitialize>::on_initialize(); }
---v
Implementing Traits For Tuples
Only problem: A lot of boilerplate. Macros!
Historically, we made this work with macro_rules!
Notes:
#![allow(unused)] fn main() { macro_rules! impl_for_tuples { ( $( $elem:ident ),+ ) => { impl<$( $elem: OnInitialize, )*> OnInitialize for ($( $elem, )*) { fn on_initialize() { $( $elem::on_initialize(); )* } } } } impl_for_tuples!(A, B, C, D); impl_for_tuples!(A, B, C, D, E); impl_for_tuples!(A, B, C, D, E, F); }
---v
Implementing Traits For Tuples
And then someone made impl_for_tuples crate.
#![allow(unused)] fn main() { // In the most basic form: #[impl_for_tuples(30)] pub trait OnTimestampSet<Moment> { fn on_timestamp_set(moment: Moment); } }
Notes:
https://docs.rs/impl-trait-for-tuples/latest/impl_trait_for_tuples/
Defensive Programming
..is a form of defensive design to ensure the continuing function of a piece of software under unforeseen circumstances... where high availability, safety, or security is needed.
- As you know, you should (almost) never panic in your runtime code.
---v
Defensive Programming
- First reminder: don't panic, unless if you want to punish someone!
.unwrap()? no no
- be careful with implicit unwraps in standard operations!
- slice/vector indexing can panic if out of bound
.insert,.remove- division by zero.
---v
Defensive Programming
- When using operations that could panic, comment exactly above it why you are sure it won't panic.
#![allow(unused)] fn main() { let pos = announcements .binary_search(&announcement) .ok() .ok_or(Error::<T, I>::MissingAnnouncement)?; // index coming from `binary_search`, therefore cannot be out of bound. announcements.remove(pos); }
---v
Defensive Programming: QED
Or when using options or results that need to be unwrapped but are known to be Ok(_), Some(_):
#![allow(unused)] fn main() { let maybe_value: Option<_> = ... if maybe_value.is_none() { return "..." } let value = maybe_value.expect("value checked to be 'Some'; qed"); }
- Q.E.D. or QED is an initialism of the Latin phrase "quod erat demonstrandum", meaning "which was to be demonstrated".
---v
Defensive Programming
When writing APIs that could panic, explicitly document them, just like the core rust documentation.
#![allow(unused)] fn main() { /// Exactly the same semantics as [`Vec::insert`], but returns an `Err` (and is a noop) if the /// new length of the vector exceeds `S`. /// /// # Panics /// /// Panics if `index > len`. pub fn try_insert(&mut self, index: usize, element: T) -> Result<(), ()> { if self.len() < Self::bound() { self.0.insert(index, element); Ok(()) } else { Err(()) } } }
---v
Defensive Programming
- Speaking of documentation, here's a very good guideline!
/// Multiplies the given input by two. /// /// Some further information about what this does, and where it could be used. /// /// ``` /// fn main() { /// let x = multiply_by_2(10); /// assert_eq!(10, 20); /// } /// ``` /// /// ## Panics /// /// Panics under such and such condition. fn multiply_by_2(x: u32) -> u32 { .. }
---v
Defensive Programming
- Try and not be this guy:
#![allow(unused)] fn main() { /// This function works with module x and multiples the given input by two. If /// we optimize the other variant of it, we would be able to achieve more /// efficiency but I have to think about it. Probably can panic if the input /// overflows u32. fn multiply_by_2(x: u32) -> u32 { .. } }
---v
Defensive Programming
- The overall ethos of defensive programming is along the lines of:
#![allow(unused)] fn main() { // we have good reasons to believe this is `Some`. let y: Option<_> = ... // I am really really sure about this let x = y.expect("hard evidence; qed"); // either return a reasonable default.. let x = y.unwrap_or(reasonable_default); // or return an error (in particular in dispatchables) let x = y.ok_or(Error::DefensiveError)?; }
Notes:
But, for example, you are absolutely sure that Error::DefensiveError will never happen, can we enforce it better?
---v
Defensive Programming
#![allow(unused)] fn main() { let x = y .ok_or(Error::DefensiveError) .map_err(|e| { #[cfg(test)] panic!("defensive error happened: {:?}", e); log::error!(target: "..", "defensive error happened: {:?}", e); })?; }
---v
Defensive Programming
- Yes: Defensive traits:
// either return a reasonable default..
let x = y.defensive_unwrap_or(reasonable_default);
// or return an error (in particular in dispatchables)
let x = y.defensive_ok_or(Error::DefensiveError)?;
It adds some boilerplate to:
- Panic when
debug_assertionsare enabled (tests). - append a
log::error!.
Additional Resources! 😋

Check speaker notes (click "s" 😉)
Good luck with FRAME!
Notes:
-
Rust didn't have u128 until not too long ago! https://github.com/paritytech/substrate/pull/163/files
-
TryFrom/TryIntoare also not too old! https://github.com/paritytech/substrate/pull/163/files#r188938077 -
Remove
As, which tried to fill the lack ofTryFrom/TryIntohttps://github.com/paritytech/substrate/pull/2602 -
Runtime Logging PR: https://github.com/paritytech/substrate/pull/3821
-
Impl trait for tuples:
- https://stackoverflow.com/questions/64332037/how-can-i-store-a-type-in-an-array
- https://doc.rust-lang.org/book/ch17-02-trait-objects.html#trait-objects-perform-dynamic-dispatch
- https://doc.rust-lang.org/book/ch19-03-advanced-traits.html#fully-qualified-syntax-for-disambiguation-calling-methods-with-the-same-name
- https://turbo.fish/
- https://techblog.tonsser.com/posts/what-is-rusts-turbofish
- https://docs.rs/impl-trait-for-tuples/latest/impl_trait_for_tuples/
-
std/no_std
Feedback After Lecture:
- Lecture is still kinda dense and long, try and trim
- Update on defensive ops: https://github.com/paritytech/substrate/pull/12967
- Next time, talk about making a storage struct be
<T: Config>. - Cargo format
- SignedExtension should technically be part of the substrate module. Integrate it in the assignment, perhaps.
- A section about
XXXNoBoundtraits. - A section about reading your compiler errors top to bottom, especially with an example in FRAME.
Substrate Merklized Storage
How to use the slides - Full screen (new tab)
Substrate Storage
What We Know So Far

---v
What We Know So Far
-
Recall that at the
sp_iolayer, you have opaque keys and values. -
sp_io::storage::get(vec![8, 2]);vec![8, 2]is a "storage key".
-
sp_io::storage::set(vec![2, 9], vec![42, 33]);
---v
What We Know So Far
Nomenclature (with some simplification):
Environment providing host functions, namely storage ones: "
ExternalitiesEnvironment".
Notes:
- In Substrate, a type needs to provide the environment in which host functions are provided, and can be executed.
- We call this an "externality environment", represented by
trait Externalities. - By convention, an externality has a "backend" that is in charge of dealing with storage.
---v
What We Know So Far
#![allow(unused)] fn main() { sp_io::TestExternalities::new_empty().execute_with(|| { sp_io::storage::get(..); }); }
---v
What We Know So Far

Key Value
- How about a key-value storage externality? why not? 🙈
---v
Key Value

---v
Key Value
- "Storage keys" (whatever you pass to
sp_io::storage) directly maps to "database keys". - O(1) read and write.
- Hash all the data to get the root.
Notes:
Good time to hammer down what you mean by storage key and what you mean by database key.
literally imagine that in the implementation of sp_io::storage::set, we write it to a key-value
database.
---v
Key Value
- If alice only has this root, how can I prove to her how much balance she has?
SEND HER THE WHOLE DATABASE 😱.
Notes:
Alice is representing a light client, I represent a full node.
---v
Key Value
- Moreover, if you change a single key-value, we need to re-hash the whole thing again to get the updated state root 🤦.
Substrate Storage: Merklized
- This brings us again to why blockchain based systems tend to "merkelize" their storage.
---v
Merklized
Substrate uses a base-16, (patricia) radix merkle trie.
---v
- Merkle tree.
- Typically contains values at leafs.
---v
- Trie.
- Assuming only leafs have data, this is encoding:
| "ac" => 0x12 |
| "ad" => 0x23 |
| "be" => 0x34 |
Notes:
this is how we encode key value based data in a trie.
---v
- Radix Tree.
- Less nodes to encode the same data.
| "ac" => 0x1234 |
| "ad" => 0x1234 |
| "be" => 0x1234 |
Notes:
More resources:
- https://en.wikipedia.org/wiki/Merkle_tree
- https://en.wikipedia.org/wiki/Radix_tree
- https://en.wikipedia.org/wiki/Trie
Namely:
The data structure was invented in 1968 by Donald R. Morrison, with whom it is primarily associated, and by Gernot Gwehenberger.
Donald Knuth, pages 498-500 in Volume III of The Art of Computer Programming, calls these "Patricia's trees", presumably after the acronym in the title of Morrison's paper: "PATRICIA - Practical Algorithm to Retrieve Information Coded in Alphanumeric". Today, Patricia tries are seen as radix trees with radix equals 2, which means that each bit of the key is compared individually and each node is a two-way (i.e., left versus right) branch. ---v
Merklized
Substrate uses a base-16, (patricia) radix merkle trie.
---v
Merklized
- Substrate does in fact use a key-value based database under the hood..
- In order to store trie nodes, not direct storage keys!
- We take the storage key, and make it be the path on a trie.
- Then we store the trie nodes, referenced by their hash, in the main database.
---v
Merklized

Notes:
imagine:
sp_io::storage::get(b"ad")
---v
Merklized

Notes:
realistically, the storage key is something like (system_)16, but I have put the strings here for
simplification.
Trie Walking Example
- We know the state-root at a given block
n. - assume this is a base-26, patricia trie. English alphabet is the key-scope.
- Let's see the steps needed to read
balances_alicefrom the storage.
---v

---v

---v

---v

---v

Merklized: Proofs
- If alice only has this root, how can I prove to her how much balance she has?
---v

Notes:
The important point is that for example the whole data under _system is not hidden away behind one hash.
Dark blue are the proof, light blue's hashes are present.
Receiver will hash the root node, and check it against a publicly known storage root.
This differs slightly from how actual proof generation might work in the code.
In general, you have a tradeoff: send more data, but require less hashing on Alice, or opposite (this is what we call "compact proof").
---v
Merklized: Proofs
- 🏆 Small proof size is a big win for light clients, and Polkadot.
Merklized: Recap
- Storage key (whatever you pass to
sp_io) is the path on the trie.
- Storage key is arbitrary length.
- Intermediary (branch) nodes could contain values.
:codecontains some value,:code:morecan also contain value.
- Storage Key != Database Key.
- 1 Storage access = Many data base access.
Notes:
how many database access would do you think it is?
we will explain this in a few slides, but assuming an order N tree, and assuming it is balanced,
it will be O(LOG_n).
Base 2, Base 16, Base-26?
- Instead of alphabet, we use the base-16 representation of everything.
Base-16 (Patricia) Merkle Trie.
System->73797374656d:code->3a636f646500
---v
Base 2, Base 16, Base-26?

Tradeoff: "IO count vs. Node size"
Between a light clint and a full node, which one cares more about which?
Notes:
Light client cares about node size. When proof is being sent, there is no IO.
First glance, the radix-8 seems better: you will typically have less DB access to reach a key. For example, with binary, with 3 IO, we can reach only 8 items, but with radix-8 512.
So why should not choose a very wide tree? Because the wider you make the tree, the bigger each node gets, because it has to store more hashes. At some point, this start to screw with both the proof size and the cost of reading/writing/encoding/decoding all these nodes.
---v
Base 2, Base 16, Base-26?

Note:
Here's a different way to represent it; the nodes are bigger on the base-16 trie.
---v
Base 2, Base 16, Base-26?
- base-2: Small proofs, more nodes.
- base-8: Bigger proofs, less nodes.
✅ 16 has been benchmarked and studies years ago as a good middle-ground.
Notes:
Anyone interested in blockchain and research stuff should look into this.
Unbalanced Tree

---v
Unbalanced Tree
- Unbalanced tree means unbalanced performance. An attack vector, if done right.
- More about this in FRAME storage, and how it is prevented there.
Notes:
- under-estimate weight/gas etc.
- You as the runtime developer must ensure that you use the right keys.
- This is particularly an issue if an end user can control where they can insert into the trie!
- The main prevention is using a cryptographically secure hash function on the frame side.
WAIT A MINUTE... 🤔
- Two common scenarios that merkle proofs are kinda unfair:
- If the one of the parent nodes has some large data.
- If you want to prove the deletion/non-existence of a leaf node.
---v

---v
WAIT A MINUTE... 🤔
New "tie format" 🌈:
- All data containing more than 32 bytes are replaced with their hash.
- The (larger than 32 bytes) value itself stored in the database under this hash.
#![allow(unused)] fn main() { struct RuntimeVersion { ... state_version: 0, } }
---v

What is the ramification of this for full nodes, and light clients?
Notes:
Both read and write have an extra step now, but proof are easier.
Note from emeric: the green node is not really a "real" node, it is just { value: BIG_STUFF } stored in the database.
I will skip this detail for the sake of simplicity.
One can assume that the green node is like any other node in the trie.
Substrate Storage: The Updated Picture

WAIT A MINUTE... 🤔
- We rarely care about state root and all the trie shenanigans before the end of the block...
A block-scoped cache for storage.
Notes:
In other words, one should care too much about updating a "trie" and all of its hashing details while the block is still being executed? All of that can be delayed.
Overlay
- Is a cache layer outside of the Runtime.
- It works based on key-values, not trie-format.
---v
Overlay
- Almost identical semantic to your CPU cache:
- Once you read a value, it stays here, and can be re-read for cheap.
- Once you write a value, it will only be written here.
- It can be read for cheap.
- All writes are flushed at the end of the runtime api call.
- No race conditions as runtime is single-threaded.
---v

---v

---v

---v

---v

---v

---v
Overlay
- Cheap != Free

Notes:
- In your code, you often have an option to either pass stack variables around, or re-read code from
sp-io. Most often, this is a micro-optimization that won't matter too much, but in general you should know that the former is more performant, as won't go the the host at all. - A deletion is basically a write to
null.
---v
Overlay
- The overlay is also able to spawn child-overlays, known as "storage layer".
- Useful for having a transactional block of code.
#![allow(unused)] fn main() { // spawn a new layer. with_storage_layer(|| { let foo = sp_io::storage::read(b"foo"); sp_io::storage::set(b"bar", foo); if cond { Err("this will be reverted") } else { Ok("This will be commit to the top overlay") } }) }
Notes:
- implement with zero-copy. So, the size of values is not so important, it is more about the number.
---v

---v

---v
Overlay
- There is a limit to how many nested layers you can spawn
- It is not free, thus it is attack-able.
#![allow(unused)] fn main() { with_storage_layer(|| { let foo = sp_io::storage::read(b"foo"); with_storage_layer(|| { sp_io::storage::set(b"foo", b"foo"); with_storage_layer(|| { sp_io::storage::set(b"bar", foo); with_storage_layer(|| { sp_io::storage::set(b"foo", "damn"); Err("damn") }) Ok("what") }) Err("the") }); Ok("hell") }) }
---v
Overlay
- What if I call
sp_io::storage::root()in the middle of the block? - Can the overlay respond to this?
Notes:
NO! The overlay works on the level on key-values, it knows nothing of trie nodes, and to compute the root we have to go to the trie layer and pull a whole lot of data back from the disk and build all the nodes etc.
---v
Overlay: More Caches
- There are more caches in the trie layer as well. But outside of the scope of this lecture.
./substrate --help | grep cache
Notes:
https://www.youtube.com/embed/OoMPlJKUULY
Substrate Storage: Final Figure

---v
Substrate Storage
There are multiple implementations of Externalities:
TestExternalities:OverlayTrieDbwithInMemoryBackend
Ext(the real thing 🫡)OverlayTrieDbwith a real database being the backend
---v
Substrate Storage
- Recall: Any code accessing host functions needs to wrapped in something that implements
Externalities
#![allow(unused)] fn main() { // ❌ let x = sp_io::storage::get(b"foo"); // error: // thread '..' panicked at '`get_version_1` called outside of an Externalities-provided environment.' }
#![allow(unused)] fn main() { // ✅ SomeExternalities.execute_with(|| { let x = sp_io::storage::get(b"foo"); }); }
State Pruning
- Each runtime will think that it has access to its full state, behind
sp_io::storage. - Does the client then store one full trie per-block?
Surely not.
Notes:
- Only trie nodes that are updated from one block to the other are created as new DB Keys.
- For the unchanged ones, we only reference the existing one.
---v
State Pruning
 ---v
---v
State Pruning
 ---v
---v
State Pruning
 ---v
---v
State Pruning

---v
State Pruning
- 🧠 Data stored onchain, but rarely changed? De nada.
- State pruning is an entirely client side optimization,
Child Trees

---v
Child Trees
- Stored on a different DB Column (async-ish bulk deletion).
- Most importantly, alternative trie formats.
Trie Format Matters!
- Recall that in our "trie walking", we took the state root, and got the root node from the DB.
- The state root of any substrate-based chain, including Polkadot, is the hash of the "Trie Node".
Trie format matters! and therefore it is part of the polkadot spec.
Notes:
Meaning, if another client wants to sync polkadot, it should know the details of the trie format.
Lecture Summary/Recap:
- KV-Based storage
- Merklized storage, and proofs
- Large nodes
- Radix order consequences
- Unbalanced trie
- State pruning
Additional Resources! 😋
Check speaker notes (click "s" 😉)

Notes:
-
Shawn's deep dive: https://www.shawntabrizi.com/substrate/substrate-storage-deep-dive/
-
Basti's talk on Trie caching: https://www.youtube.com/watch?v=OoMPlJKUULY
-
About state version:
-
An "old but gold" read about trie in Ethereum: https://medium.com/shyft-network/understanding-trie-databases-in-ethereum-9f03d2c3325d
-
On optimizing substrate storage proofs: https://github.com/paritytech/substrate/issues/3782
-
Underlying trie library maintained by Parity: https://github.com/paritytech/trie
-
An interesting, but heretical idea: can the runtime of block N, access state of block N-1? HELL. NO. It might sound like a "but why nooooot" type of situation, but it breaks down all assumptions about what a state transition is. The runtime is the state transition function. Recall the formula of that, and then you will know why this is not allowed.
Post Lecture Feedback
Double check the narrative and example of the BIG_STUFF node.
An example/exercise of some sort
would be great, where students call a bunch of sp_io functions, visualize the trie, and invoke
proof recorder, and see which parts of the trie is exactly part of the proof.
🧱 FRAME
The primary Substrate runtime framework used for parachain development.
Pallets & Traits
How to use the slides - Full screen (new tab)
Lesson Plan
| Monday | Tuesday | Wednesday | Thursday | Friday | Weekend |
|
|
|
|
|
|
|
|
|
|
|
|
Introduction to FRAME
What is FRAME?
FRAME is a Rust framework for more easily building Substrate runtimes.
Explaining FRAME Concisely
Writing the Sudo Pallet:
Without FRAME: 2210 lines of code.
With FRAME: 310 lines of code.
7x Smaller.
Goals of FRAME
- Make it easy and concise for developers to do development.
- Provide maximum flexibility and compatibility for pallet developers.
- Provide maximum modularity for runtime developers.
- Be as similar to vanilla Rust as possible.
Building Blocks of FRAME
- FRAME Development
- Pallets
- Macros
- FRAME Coordination
- FRAME System
- FRAME Executive
- Construct Runtime
Pallets
FRAME takes the opinion that the blockchain runtime should be composed of individual modules. We call these Pallets.

Building Blocks of Pallets
Pallets are composed of multiple parts common for runtime development:
- Dispatchable extrinsics
- Storage items
- Hooks for:
- Block initialization,
- Finalizing block (!= block finality i.e. GRANDPA)
More Building Blocks of Pallets
And some less important ones:
- Events
- Errors
- Custom validation/communication with tx-pool
- Offchain workers
- A lot more! but you will learn about them later.
"Shell" Pallet
#![allow(unused)] fn main() { pub use pallet::*; #[frame_support::pallet] pub mod pallet { use frame_support::pallet_prelude::*; use frame_system::pallet_prelude::*; #[pallet::pallet] #[pallet::generate_store(pub(super) trait Store)] pub struct Pallet<T>(_); #[pallet::config] // snip #[pallet::event] // snip #[pallet::error] // snip #[pallet::storage] // snip #[pallet::call] // snip } }
FRAME Macros
Rust allows you to write Macros, which is code that generates code.
FRAME uses Macros to simplify the development of Pallets, while keeping all of the benefits of using Rust.
We will look more closely at each attribute throughout this module.
See For Yourself
wc -lwill show the number of lines of a file.cargo expandwill expand the macros to "pure" Rust.
➜ substrate git:(master) ✗ wc -l frame/sudo/src/lib.rs
310 frame/sudo/src/lib.rs
➜ substrate git:(master) ✗ cargo expand -p pallet-sudo | wc -l
2210
FRAME System
The FRAME System is a Pallet which is assumed to always exist when using FRAME. You can see that in the Config of every Pallet:
#![allow(unused)] fn main() { #[pallet::config] pub trait Config: frame_system::Config { ... } }
It contains all the most basic functions and types needed for a blockchain system. Also contains many low level extrinsics to manage your chain directly.
- Block Number
- Accounts
- Hash
- etc...
BlockNumberFor<T>frame_system::Pallet::<T>::block_number()T::AccountIdT::HashT::Hashing::hash(&bytes)
FRAME Executive
The FRAME Executive is a "coordinator", defining the order that your FRAME based runtime executes.
#![allow(unused)] fn main() { /// Actually execute all transitions for `block`. pub fn execute_block(block: Block) { ... } }
- Initialize Block
on_runtime_upgradeandon_initializehooks
- Initial Checks
- Signature Verification
- Execute Extrinsics
on_idleandon_finalizehooks
- Final Checks
Construct Runtime
Your final runtime is composed of Pallets, which are brought together with the construct_runtime! macro.
#![allow(unused)] fn main() { // Create the runtime by composing the FRAME pallets that were previously configured. construct_runtime!( pub struct Runtime { System: frame_system, RandomnessCollectiveFlip: pallet_randomness_collective_flip, Timestamp: pallet_timestamp, Aura: pallet_aura, Grandpa: pallet_grandpa, Balances: pallet_balances, TransactionPayment: pallet_transaction_payment, Sudo: pallet_sudo, // Include the custom logic from the pallet-template in the runtime. TemplateModule: pallet_template, } ); }
Pallet Configuration
Before you can add a Pallet to the final runtime, it needs to be configured as defined in the Config.
In the Pallet:
#![allow(unused)] fn main() { /// The timestamp pallet configuration trait. #[pallet::config] pub trait Config: frame_system::Config { type Moment: Parameter + Default + AtLeast32Bit + Scale<Self::BlockNumber, Output = Self::Moment> + Copy + MaxEncodedLen + scale_info::StaticTypeInfo; type OnTimestampSet: OnTimestampSet<Self::Moment>; #[pallet::constant] type MinimumPeriod: Get<Self::Moment>; type WeightInfo: WeightInfo; } }
In the Runtime:
#![allow(unused)] fn main() { /// The timestamp pallet configuration. impl pallet_timestamp::Config for Runtime { type Moment = u64; type OnTimestampSet = Aura; type MinimumPeriod = ConstU64<{ SLOT_DURATION / 2 }>; type WeightInfo = (); } }
Proof of Existence Runtime
Follow along the docs here: https://docs.substrate.io/tutorials/build-application-logic/use-macros-in-a-custom-pallet/
Pallet Coupling
How to use the slides - Full screen (new tab)
Pallet Coupling
Overview
Substrate believes in building modular and composable blockchain runtimes.
The building blocks of a FRAME runtime are Pallets.
Pallet coupling will teach you how to configure multiple pallets to interact with each other.
Types of Coupling
-
Tightly Coupled Pallets
- Pallets which are directly connected to one another.
- You must construct a runtime using exactly the pallets which are tightly coupled.
-
Loosely Coupled Pallets
- Pallets which are connected "loosely" with a trait / interface.
- You can construct a runtime using any pallets which satisfy the required interfaces.
Tightly Coupled Pallets
Tightly coupling is often an easier, but less flexible way to have two pallets interact with each other.
It looks like this:
#![allow(unused)] fn main() { #[pallet::config] pub trait Config: frame_system::Config + pallet_treasury::Config { // -- snip -- } }
Note that everything is tightly coupled to frame_system!
What Does It Mean?
If Pallet A is tightly coupled to Pallet B, then it basically means:
This Pallet A requires a runtime which is also configured with Pallet B.
You do not necessarily need Pallet A to use Pallet B, but you will always need Pallet B if you use Pallet A.
Example: Treasury Pallet
The Treasury Pallet is a standalone pallet which controls a pot of funds that can be distributed by the governance of the chain.
There are two other pallets which are tightly coupled with the Treasury Pallet: Tips and Bounties.
You can think of these like "Pallet Extensions".
Treasury, Tips, Bounties
pallet_treasury
#![allow(unused)] fn main() { #[pallet::config] pub trait Config<I: 'static = ()>: frame_system::Config { ... } }
pallet_tips & pallet_bounties
#![allow(unused)] fn main() { #[pallet::config] pub trait Config<I: 'static = ()>: frame_system::Config + pallet_treasury::Config<I> { ... } }
Tight Coupling Error
Here is the kind of error you will see when you try to use a tightly coupled pallet without the appropriate pallet dependencies configured:
#![allow(unused)] fn main() { error[E0277]: the trait bound `Test: pallet_treasury::Config` is not satisfied --> frame/sudo/src/mock.rs:149:17 | 149 | impl Config for Test { | ^^^^ the trait `pallet_treasury::Config` is not implemented for `Test` | n o t e: required by a bound in `pallet::Config` --> frame/sudo/src/lib.rs:125:43 | 125 | pub trait Config: frame_system::Config + pallet_treasury::Config{ | ^^^^^^^^^^^^^^^^^^^^^^^ required by this bound in `Config` For more information about this error, try `rustc --explain E0277`. error: could not compile `pallet-sudo` due to previous error warning: build failed, waiting for other jobs to finish... }
Advantage of Tight Coupling
With tight coupling, you have direct access to all public functions and interfaces of another pallet. Just like directly using a crate / module.
Examples:
#![allow(unused)] fn main() { // Get the block number from `frame_system` frame_system::Pallet::<T>::block_number() }
#![allow(unused)] fn main() { // Use type configurations defined in another pallets. let who: T::AccountId = ensure_signed(origin)?; }
#![allow(unused)] fn main() { // Dispatch an error defined in another pallet. ensure!( bounty.value <= max_amount, pallet_treasury::Error::<T, I>::InsufficientPermission ); }
When To Use Tight Coupling
Tight coupling can make a lot of sense when trying to break apart a single "large" pallet into smaller, yet fully dependant pieces.
As mentioned before, you can think of these as "extensions".
Since there is less flexibility in how you can configure tightly coupled pallets, there is also less chance for error in configuring them.
Loosely Coupled Pallets
Loose coupling is the "preferred" way to build Pallets, as it emphasizes the modular nature of Pallet development.
It looks like this:
#![allow(unused)] fn main() { #[pallet::config] pub trait Config<I: 'static = ()>: frame_system::Config { type NativeBalance: fungible::Inspect<Self::AccountId> + fungible::Mutate<Self::AccountId>; // -- snip -- } }
Here you can see that this pallet requires some associated type NativeBalance to be configured which implements some traits fungible::Inspect and fungible::Mutate, however there is no requirements on how or where that type is configured.
Trait Definition
To begin loose coupling, you need to define a trait / interface that can be provided and depended on. A very common example is the fungible::* traits, which most often is implemented by pallet_balances.
#![allow(unused)] fn main() { /// Trait for providing balance-inspection access to a fungible asset. pub trait Inspect<AccountId>: Sized { /// Scalar type for representing balance of an account. type Balance: Balance; /// The total amount of issuance in the system. fn total_issuance() -> Self::Balance; /// The total amount of issuance in the system excluding those which are controlled by the /// system. fn active_issuance() -> Self::Balance { Self::total_issuance() } // -- snip -- } }
frame/support/src/traits/tokens/fungible/regular.rs
Trait Implementation
This trait can then be implemented by a Pallet, for example pallet_balances.
#![allow(unused)] fn main() { impl<T: Config<I>, I: 'static> fungible::Inspect<T::AccountId> for Pallet<T, I> { type Balance = T::Balance; fn total_issuance() -> Self::Balance { TotalIssuance::<T, I>::get() } fn active_issuance() -> Self::Balance { TotalIssuance::<T, I>::get().saturating_sub(InactiveIssuance::<T, I>::get()) // -- snip -- } }
frame/balances/src/impl_fungible.rs
Any pallet, even one you write, could implement this trait.
Trait Dependency
Another pallet can then, separately, depend on this trait.
#![allow(unused)] fn main() { #[pallet::config] pub trait Config: frame_system::Config { type NativeBalance: fungible::Inspect<Self::AccountId> + fungible::Mutate<Self::AccountId>; } }
And can use this trait throughout their pallet:
#![allow(unused)] fn main() { #[pallet::weight(0)] pub fn transfer_all(origin: OriginFor<T>, to: T::AccountId) -> DispatchResult { let from = ensure_signed(origin)?; let amount = T::NativeBalance::balance(&from); T::NativeBalance::transfer(&from, &to, amount, Expendable) } }
Runtime Implementation
Finally, in the runtime configuration, we concretely define which pallet implements the trait.
#![allow(unused)] fn main() { /// Configuration of a pallet using the `fungible::*` traits. impl pallet_voting::Config for Runtime { type RuntimeEvent = RuntimeEvent; type NativeBalance = pallet_balances::Pallet<Runtime>; } }
This is the place where things are no longer "loosely" defined.
Challenges of Loose Coupling
Loose coupling is more difficult because you need to think ahead of time about developing a flexible API that makes sense for potentially multiple implementations.
You need to try to not let implementation details affect the API, providing maximum flexibility to users and providers of those traits.
When done right, it can be very powerful; like the ERC20 token format.
Challenges of Generic Types
Many new pallet developers also find loose coupling challenging because associated types are not concretely defined... on purpose.
For example, note that the fungible::* trait has a generic Balances type.
This allows pallet developers can configure most unsigned integers types (u32, u64, u128) as the Balance type for their chain, however, this also means that you need to be more clever when doing math or other operations with those generic types.
Questions
Next we will look over common pallets and traits, and will see many of the pallet coupling patterns first hand.
Outer Enum
How to use the slides - Full screen (new tab)
FRAME Pallets & Traits
Overview
We will walk through the codebase and touch on various commonly used pallets and traits.
The goal is to learn by example, and show how you can use the Substrate codebase to self-educate and solve problems.
System Pallet
Utility Pallet
Proxy Pallet
Multisig Pallet
Held vs Frozen Balance
- Reserved -> Held
- Locked -> Frozen
- Both states belong to the user... but cannot be spent / transferred.
- Held balances stack on top of one another.
- Useful for user deposits, or other use cases where there is sybil concerns.
- Ex: Deposit for storing data on-chain,
- Frozen balances can overlap each other.
- Useful when you want to use the same tokens for multiple use cases.
- Ex: Using the same tokens for both staking and voting in governance.
Held Balances
Total Balance
┌─────────────────────────────────────────────────────────┐
┌────────────────────────────────┼────────────────────────┐
│┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼ |ED│
└────────────────────────────────┼────────────────────────┘
Held Balance Transferable Balance
┌───────────┐
│┼┼┼┼┼┼┼┼┼┼┼│ Various Storage Deposits
└───────────┤
├──────┐
│┼┼┼┼┼┼│ Treasury Proposal Deposit
└──────┤
├──────────┐
│┼┼┼┼┼┼┼┼┼┼│ Multisig Deposit
└──────────┤
├──┐
│┼┼│ Proxy Deposit
└──┘
New Holds Example
Total Balance
┌─────────────────────────────────────────────────────────┐
┌────────────────────────────────┼────────────────────────┐
│┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼ |ED│
└────────────────────────────────┼────────────────────────┘
Held Balance Transferable Balance
┌────────────────────┐
New Hold Successful! │┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼│
└────────────────────┘
┌────────────────────────────────┐
New Hold Failed :( │┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼│
└────────────────────────────────┘
Frozen Balances
Total Balance
┌─────────────────────────────────────────────────────────┐
┌────────────────────────────────┼────────────────────────┐
│XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX |ED│
└────────────────────────────────┼────────────────────────┘
Frozen Balance Transferable Balance
┌───────────────────────┐
│XXXXXXXXXXXXXXXXXXXXXXX│ Vesting Balance
└───────────────────────┘
┌────────────────────────────────┐
│XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX│ Staking Bond Freeze
└────────────────────────────────┘
┌─────────────────┐
│XXXXXXXXXXXXXXXXX│ Governance Vote Freeze
└─────────────────┘
New Freeze Example
Total Balance
┌─────────────────────────────────────────────────┐
┌────────────────────────────────┼────────────────┐
│XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX |ED│
└────────────────────────────────┼────────────────┘
Frozen Balance Transferable Balance
┌───────────────────────┐
│XXXXXXXXXXXXXXXXXXXXXXX│ New Freeze Successful!
└───────────────────────┘
┌─────────────────────────────────────────────────┐
│XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX│ New Freeze Successful!
└─────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────────┐
│XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX│ New Freeze Successful!
└─────────────────────────────────────────────────────────┘
Freeze and Hold Overlap
Total Balance
┌──────────────────────────────────────────────────────────────┐
Held Balance
┌────────────────────────────────┼─────────────────────────────┐
│┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼┼ | E │
│XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX | D │
└────────────────────────────────┼─────────────────────────────┘
Frozen Balance Transferable Balance
Balances Pallet & Fungible Traits
Assets Pallet & Fungibles Traits
NFT Pallet & Non-Fungibles Traits
Transaction Payment Pallet
Sudo Pallet
Conviction Voting + Referenda Pallet
(Open Governance)
Ranked Collectives + Whitelist Pallet
(Technical Fellowship)
Scheduler Pallet
Polkadot Deep Dives

https://www.youtube.com/watch?v=_FwqB4FwWXk&list=PLOyWqupZ-WGsfnlpkk0KWX3uS4yg6ZztG
Questions
FRAME Storage
How to use the slides - Full screen (new tab)
FRAME Storage
FRAME Storage
In this presentation, we will go even deeper into the concepts of Substrate storage, and see what kind of storage primitives FRAME provides you with to make Pallet development easy.
| Developer |
| Runtime Storage API |
| Storage Overlays |
| Patricia-Merkle Trie |
| Key-Value Database |
| Computer |
Storage layers
As we have learned, there are four core layers to Substrate's storage system.
Today we will focus on the top two layers: Runtime Storage APIs and Storage Overlays, which FRAME uses to improve developer experience.
Overlay Deep Dive
The overlay stages changes to the underlying database.
| Runtime Logic |
| Runtime Memory |
| Runtime Storage API |
| Overlay Change Set | |||
| Memory / Database Interface |
| Database | |||
| Alice: 10 | Bob: 20 | Cindy: 30 | Dave: 40 |
Overlay: Balance Transfer
- Runtime Logic Initiates.
- Calls the Runtime Storage API.
- First we query the Overlay Change Set.
- Unfortunately it's not there.
- Then we query the underlying Database.
- Very slow as you have learned so far.
| Runtime Logic |
| Runtime Memory |
| Runtime Storage API |
| Overlay Change Set | |||
| Memory / Database Interface |
| Database | |||
| Alice: 10 | Bob: 20 | Cindy: 30 | Dave: 40 |
Overlay: Balance Transfer
- As we return the data back to the runtime, we cache the values in the overlay.
- Subsequent reads and writes happen in the overlay, since the data is there.
| Runtime Logic |
| Runtime Memory |
| Runtime Storage API |
| Overlay Change Set | |||
| Alice: 10 | Bob: 20 | ||
| Memory / Database Interface |
| Database | |||
| Alice: 10 | Bob: 20 | Cindy: 30 | Dave: 40 |
Overlay: Balance Transfer
- The actual transfer logic happens in the runtime memory.
- At some point, the runtime logic writes the new balances to storage, this updates the overlay cache.
- The underlying database is not updated yet.
| Runtime Logic |
| Runtime Memory |
| Runtime Storage API |
| Overlay Change Set | |||
| Alice: 15 | Bob: 15 | ||
| Memory / Database Interface |
| Database | |||
| Alice: 10 | Bob: 20 | Cindy: 30 | Dave: 40 |
Overlay: Balance Transfer
- At the end of the block, staged changes are committed to the database all at once.
- Then storage root is recomputed a single time for the final block state.
| Runtime Logic |
| Runtime Memory |
| Runtime Storage API |
| Overlay Change Set | |||
| Memory / Database Interface |
| Database | |||
| Alice: 15 | Bob: 15 | Cindy: 30 | Dave: 40 |
Overlay: Implications
- Reading the same storage a second or more time is faster (not free) than the initial read.
- Writing the same value multiple times is fast (not free), and only results in a single final Database write.
| Runtime Logic |
| Runtime Memory |
| Runtime Storage API |
| Overlay Change Set | |||
| Memory / Database Interface |
| Database | |||
| Alice: 15 | Bob: 15 | Cindy: 30 | Dave: 40 |
Notes:
also this means that cross implementation of substrate/polkadot can be tricky to ensure determinism (also true for next slide).
Additional Storage Overlays (Transactional)
- The runtime has the ability to spawn additional storage layers, called "transactional layers".
- This can allow you to commit changes through the Runtime Storage API, but then drop the changes if you want before they get to the overlay change set.
- The runtime can spawn multiple transactional layers, each at different times, allowing the runtime developer to logically separate when they want to commit or rollback changes.
| Runtime Logic |
| Runtime Memory |
| Runtime Storage API |
| Transactional Layer | |||
| Alice: 25 | Cindy: 20 | ||
| Overlay Change Set | |||
| Alice: 15 | Cindy: 30 | ||
| Memory / Database Interface |
| Database | |||
| Alice: 15 | Bob: 15 | Cindy: 30 | Dave: 40 |
Transactional Implementation Details
- Non-Zero Overhead (but quite small)
- 0.15% overhead per key written, per storage layer.
- Values are not copied between layers.
- Values are stored in heap, and we just move pointers around.
- So overhead has nothing to do with storage size, just the number of storage items in a layer.
- Storage layers use client memory, so practically no upper limit.
Notes:
For more details see:
- https://github.com/paritytech/substrate/pull/10413
- https://github.com/paritytech/substrate/pull/10809
In module 6, we can take a closer look at how this functionality is exposed in FRAME.
See: https://github.com/paritytech/substrate/pull/11431
Storage Layer by Default
All extrinsics execute within a transactional storage layer.
This means that if you return an Error from your extrinsic, all changes to storage caused by that extrinsic are reverted.
This is the same behavior as you would expect from smart contract environments like Ethereum.
Transactional Layer Attack
Transactional layers can be used to attack your chain:
- Allow a user to spawn a lot of transactional layers.
- On the top layer, make a bunch of changes.
- All of those changes will need to propagate down each time.
Solution:
- Do not allow the user to create an unbounded number of layers within your runtime logic.
Runtime Storage APIs
Patricia Trie

Storage Keys

FRAME Storage Keys
We follow a simple pattern:
hash(name) ++ hash(name2) ++ hash(name3) ++ hash(name4) ...
For example:
twox128(pallet_name) ++ twox128(storage_name) ++ ...
We will get into more details as we look at the specific storage primitives.
Pallet Name
The pallet name comes from the construct_runtime!.
#![allow(unused)] fn main() { // Configure a mock runtime to test the pallet. frame_support::construct_runtime!( pub enum Test { System: frame_system::{Pallet, Call, Config, Storage, Event<T>}, Example: pallet_template, } ); }
This means that changing the name of your pallet here is a BREAKING change, since it will change your storage keys.
FRAME Storage Primitives
StorageValueStorageMapCountedStorageMapStorageDoubleMapStorageNMap
We will go over all of them, and many important and subtle details along the way.
Storage Value
Place a single item into the runtime storage.
#![allow(unused)] fn main() { pub struct StorageValue<Prefix, Value, QueryKind = OptionQuery, OnEmpty = GetDefault>(_); }
Storage Key:
#![allow(unused)] fn main() { Twox128(Prefix::pallet_prefix()) ++ Twox128(Prefix::STORAGE_PREFIX) }
Storage Value: Example
#![allow(unused)] fn main() { #[pallet::storage] pub type Item1<T> = StorageValue<_, u32>; }
#![allow(unused)] fn main() { #[test] fn storage_value() { sp_io::TestExternalities::new_empty().execute_with(|| { assert_eq!(Item1::<T>::get(), None); Item1::<T>::put(10u32); assert_eq!(Item1::<T>::get(), Some(10u32)); }); } }
Storage "Prefix"
The first generic parameter in any FRAME storage is the Prefix, which is used to generate the storage key.
Prefix implements StorageInstance which has:
#![allow(unused)] fn main() { pub trait StorageInstance { const STORAGE_PREFIX: &'static str; fn pallet_prefix() -> &'static str; } }
STORAGE_PREFIX is the name of the storage, and pallet_prefix() is the name of the pallet that this storage is in.
This is populated thanks to FRAME's macro magic.
Notes:
https://substrate.stackexchange.com/questions/476/storage-definition-syntax/478#478
Storage Value Key
#![allow(unused)] fn main() { use sp_core::hexdisplay::HexDisplay; println!("{}", HexDisplay::from(&Item1::<T>::hashed_key())); }
This will depend on your pallet's name of course...
e375d60f814d02157aaaa18f3639a254c64445c290236a18189385ed9853fb1e
e375d60f814d02157aaaa18f3639a254 ++ c64445c290236a18189385ed9853fb1e
twox128("Example") = e375d60f814d02157aaaa18f3639a254
twox128("Item1") = c64445c290236a18189385ed9853fb1e
Demystifying FRAME Storage
This shows basically what is going on when you use pallet storage. NOT accurate, but should be informative. As you can see, it is really not that complex.
#![allow(unused)] fn main() { struct Prefix; impl StorageInstance for Prefix { const STORAGE_PREFIX: &'static str = "MyStorage"; fn pallet_prefix() -> &'static str { "MyPallet" }; fn prefix() -> Vec<u8> { twox_128(Self::pallet_prefix()) ++ twox_128(STORAGE_PREFIX) } } type MyStorage = StorageValue<Prefix, Type>; trait StorageValue<Prefix, Type> { fn get() -> Option<Type> { sp_io::storage::get(Prefix::prefix()) } fn set(value: Type) { sp_io::storage::set(Prefix::prefix(), value) } fn kill() { sp_io::storage::clear(Prefix::prefix()) } // etc... } }
All Storage is an Option
- At the Runtime Storage API level, a storage key will either have a value or not have a value.
- If there is no value, any query from the backend will be
None. - If there is a value, the query will be
Some(value). - However, we can also hide this with a
Defaultvalue.
Query If Storage Actually Exists
There are APIs which expose to you whether the value actually exists in the database.
#![allow(unused)] fn main() { #[pallet::storage] pub type Item1<T> = StorageValue<_, u32>; }
#![allow(unused)] fn main() { #[test] fn storage_value() { sp_io::TestExternalities::new_empty().execute_with(|| { // Nothing is actually there yet. assert_eq!(Item1::<T>::exists(), false); assert_eq!(Item1::<T>::try_get().ok(), None); }); } }
Query Kind
OptionQuery: Default choice, represents the actual DB state.ValueQuery: Return a value whenNone. (Defaultor configurable)
#![allow(unused)] fn main() { #[pallet::storage] pub type Item2<T> = StorageValue<_, u32, ValueQuery>; }
#![allow(unused)] fn main() { #[test] fn value_query() { sp_io::TestExternalities::new_empty().execute_with(|| { // `0u32` is the default value of `u32` assert_eq!(Item2::<T>::get(), 0u32); Item2::<T>::put(10u32); assert_eq!(Item2::<T>::get(), 10u32); }); } }
Remember that 0 is not actually in storage when doing the first query.
On Empty
You can control the OnEmpty value with:
#![allow(unused)] fn main() { #[pallet::type_value] pub fn MyDefault<T: Config>() -> u32 { 42u32 } #[pallet::storage] pub type Item3<T> = StorageValue<_, u32, ValueQuery, MyDefault<T>>; }
#![allow(unused)] fn main() { #[test] fn my_default() { sp_io::TestExternalities::new_empty().execute_with(|| { // `42u32` is the configured `OnEmpty` value. assert_eq!(Item3::<T>::get(), 42u32); Item3::<T>::put(10u32); assert_eq!(Item3::<T>::get(), 10u32); }); } }
Remember that 42 is not actually in storage when doing the first query.
Not Magic
These "extra features" are just ways to simplify your code.
You can get the same effect without any magic:
#![allow(unused)] fn main() { let value = Item1::<T>::try_get().unwrap_or(42u32); }
But you wouldn't want to do this every time.
Set vs Put
pub fn set(val: QueryKind::Query)pub fn put<Arg: EncodeLike<Value>>(val: Arg)
For Example:
#![allow(unused)] fn main() { #[pallet::storage] pub type Item1<T> = StorageValue<_, u32>; }
#![allow(unused)] fn main() { Item1::<T>::set(Some(42u32)); Item1::<T>::put(42u32); }
Don't Put The Option AS the Storage Value
This is basically an anti-pattern, and it doesn't really make sense to do.
#![allow(unused)] fn main() { #[pallet::storage] pub type Item4<T> = StorageValue<_, Option<u32>>; #[pallet::storage] pub type Item5<T> = StorageValue<_, Option<u32>, ValueQuery>; }
#![allow(unused)] fn main() { #[test] fn nonsense() { sp_io::TestExternalities::new_empty().execute_with(|| { assert_eq!(Item4::<T>::exists(), false); assert_eq!(Item5::<T>::exists(), false); Item4::<T>::put(None::<u32>); Item5::<T>::put(None::<u32>); assert_eq!(Item4::<T>::exists(), true); assert_eq!(Item5::<T>::exists(), true); }); } }
Unit Type Instead of Bool
You might want to simply signify some true or false value in storage...
Save some bytes! Use the unit type.
#![allow(unused)] fn main() { #[pallet::storage] pub type Item6<T> = StorageValue<_, ()>; }
#![allow(unused)] fn main() { #[test] fn better_bool() { sp_io::TestExternalities::new_empty().execute_with(|| { // false case assert_eq!(Item6::<T>::exists(), false); Item6::<T>::put(()); // true case assert_eq!(Item6::<T>::exists(), true); }); } }
Kill Storage
Remove the item from the database using kill() or take().
#![allow(unused)] fn main() { #[pallet::type_value] pub fn MyDefault<T: Config>() -> u32 { 42u32 } #[pallet::storage] pub type Item3<T> = StorageValue<_, u32, ValueQuery, MyDefault<T>>; }
#![allow(unused)] fn main() { #[test] fn kill() { sp_io::TestExternalities::new_empty().execute_with(|| { assert_eq!(Item3::<T>::get(), 42u32); Item3::<T>::put(10u32); assert_eq!(Item3::<T>::get(), 10u32); //Item3::<T>::kill(); let old_value = Item3::<T>::take(); assert_eq!(Item3::<T>::get(), 42u32); assert_eq!(old_value, 10u32); }); } }
Mutate
Execute a closure on a storage item.
#![allow(unused)] fn main() { #[test] fn mutate() { sp_io::TestExternalities::new_empty().execute_with(|| { Item2::<T>::put(42u32); Item2::<T>::mutate(|x| { if *x % 2 == 0 { *x = *x / 2; } }); assert_eq!(Item2::<T>::get(), 21); }); } }
Try Mutate
Execute a closure on a storage item, but only write if the closure returns Ok.
#![allow(unused)] fn main() { #[test] fn try_mutate() { sp_io::TestExternalities::new_empty().execute_with(|| { Item2::<T>::put(42u32); assert_noop!(Item2::<T>::try_mutate(|x| -> Result<(), ()> { *x = *x / 2; if *x % 2 == 0 { Ok(()) } else { Err(()) } }), ()); // Nothing written assert_eq!(Item2::<T>::get(), 42); }); } }
Assert Noop
You may have noticed we just used assert_noop! instead of assert_err!.
#![allow(unused)] fn main() { /// Evaluate an expression, assert it returns an expected `Err` value and that /// runtime storage has not been mutated (i.e. expression is a no-operation). /// /// Used as `assert_noop(expression_to_assert, expected_error_expression)`. #[macro_export] macro_rules! assert_noop { ( $x:expr, $y:expr $(,)? ) => { let h = $crate::storage_root($crate::StateVersion::V1); $crate::assert_err!($x, $y); assert_eq!(h, $crate::storage_root($crate::StateVersion::V1), "storage has been mutated"); }; } }
There is also assert_storage_noop! which does not care what is returned, just that storage is not changed.
Vec Tricks
You can use decode_len() and append() to work with a Vec without decoding all the items.
#![allow(unused)] fn main() { #[pallet::storage] #[pallet::unbounded] pub type Item7<T> = StorageValue<_, Vec<u8>, ValueQuery>; }
#![allow(unused)] fn main() { #[test] fn vec_tricks() { sp_io::TestExternalities::new_empty().execute_with(|| { assert_eq!(Item7::<T>::decode_len(), None); Item7::<T>::put(vec![0u8]); assert_eq!(Item7::<T>::decode_len(), Some(1)); Item7::<T>::append(1u8); Item7::<T>::append(2u8); assert_eq!(Item7::<T>::get(), vec![0u8, 1u8, 2u8]); assert_eq!(Item7::<T>::decode_len(), Some(3)); }); } }
Bounded Storage
You may have noticed #[pallet::unbounded] on the storage item in the previous slide.
Remember that blockchains are limited by:
- Computation Time
- Memory Limits
- Storage Size / Proof Size
In general, every storage item in FRAME should be bounded in size.
We will talk about this more when we discuss benchmarking.
Bounded Vector
We have bounded versions of unbounded items like Vec, BTreeSet, etc...
#![allow(unused)] fn main() { #[pallet::storage] pub type Item8<T> = StorageValue<_, BoundedVec<u8, ConstU32<100>>, ValueQuery>; }
A second Get<u32> type is used to give a maximum number of values.
#![allow(unused)] fn main() { #[test] fn bounded_vec() { sp_io::TestExternalities::new_empty().execute_with(|| { for i in 0u8..100u8 { assert_ok!(Item8::<T>::try_append(i)); } // Only supports at most 100 items. assert_noop!(Item8::<T>::try_append(100), ()); }); } }
Storage Map
Store items in storage as a key and value map.
#![allow(unused)] fn main() { pub struct StorageMap<Prefix, Hasher, Key, Value, QueryKind = OptionQuery, OnEmpty = GetDefault, MaxValues = GetDefault>(_); }
Storage Key:
#![allow(unused)] fn main() { Twox128(Prefix::pallet_prefix()) ++ Twox128(Prefix::STORAGE_PREFIX) ++ Hasher1(encode(key)) }
Storage Map: Example
#![allow(unused)] fn main() { #[pallet::storage] pub type Item9<T: Config> = StorageMap<_, Blake2_128, u32, u32>; }
#![allow(unused)] fn main() { #[test] fn storage_map() { sp_io::TestExternalities::new_empty().execute_with(|| { Item9::<T>::insert(0, 100); assert_eq!(Item9::<T>::get(0), Some(100)); assert_eq!(Item9::<T>::get(1), None); }); } }
Storage Map Key
With a storage map, you can introduce a "key" and "value" of arbitrary type.
#![allow(unused)] fn main() { pub struct StorageMap<Prefix, Hasher, Key, Value, ...>(_); }
The storage key for a map uses the hash of the key. You can choose the storage hasher, these are the ones currently implemented:
- Identity (no hash at all)
- Blake2_128
- Blake2_256
- Twox128
- Twox256
- Twox64Concat (special)
- Blake2_128Concat (special)
Value Query: Balances
#![allow(unused)] fn main() { #[pallet::storage] pub type Item10<T: Config> = StorageMap<_, Blake2_128, T::AccountId, Balance, ValueQuery>; }
#![allow(unused)] fn main() { #[test] fn balance_map() { sp_io::TestExternalities::new_empty().execute_with(|| { // these would normally would be 32 byte addresses let alice = 0u64; let bob = 1u64; Item10::<T>::insert(alice, 100); let transfer = |from: u64, to: u64, amount: u128| -> Result<(), &'static str> { Item10::<T>::try_mutate(from, |from_balance| -> Result<(), &'static str> { Item10::<T>::try_mutate(to, |to_balance| -> Result<(), &'static str> { *to_balance = to_balance.checked_add(amount).ok_or("overflow")?; *from_balance = from_balance.checked_sub(amount).ok_or("not enough balance")?; Ok(()) }) }) }; assert_noop!(transfer(bob, alice, 10), "not enough balance"); assert_ok!(transfer(alice, bob, 10)); assert_noop!(transfer(alice, bob, 100), "not enough balance"); assert_eq!(Item10::<T>::get(alice), 90); assert_eq!(Item10::<T>::get(bob), 10); }); } }
Prefix Tries
All pallets and storage items naturally form "prefix tries".

In this diagram, a pallet "Balances" has a storage value "Total Issuance" and a map of "Accounts" with balances as the value.
Prefix Trie Keys
Let's now look at the keys of these storage items:
#![allow(unused)] fn main() { use sp_core::hexdisplay::HexDisplay; println!("{}", HexDisplay::from(&Item2::<T>::hashed_key())); println!("{}", HexDisplay::from(&Item10::<T>::hashed_key_for(0))); println!("{}", HexDisplay::from(&Item10::<T>::hashed_key_for(1))); }
e375d60f814d02157aaaa18f3639a2546fe5a43b77d7334acfb711a021a514b8
e375d60f814d02157aaaa18f3639a254ca79d14bc48854f664528f3a696b6c27c804ce198ec337e3dc762bdd1a09aece
e375d60f814d02157aaaa18f3639a254ca79d14bc48854f664528f3a696b6c279ea2d098b5f70192f96c06f38d3fbc97
| e375d60f814d02157aaaa18f3639a254 | 6fe5a43b77d7334acfb711a021a514b8 | |
| e375d60f814d02157aaaa18f3639a254 | ca79d14bc48854f664528f3a696b6c27 | c804ce198ec337e3dc762bdd1a09aece |
| e375d60f814d02157aaaa18f3639a254 | ca79d14bc48854f664528f3a696b6c27 | 9ea2d098b5f70192f96c06f38d3fbc97 |
Storage Iteration
Because all storage items form a prefix trie, you can iterate the content starting with any prefix:
#![allow(unused)] fn main() { impl<T: Decode + Sized> Iterator for StorageIterator<T> { type Item = (Vec<u8>, T); fn next(&mut self) -> Option<(Vec<u8>, T)> { loop { let maybe_next = sp_io::storage::next_key(&self.previous_key) .filter(|n| n.starts_with(&self.prefix)); break match maybe_next { Some(next) => { self.previous_key = next.clone(); let maybe_value = frame_support::storage::unhashed::get::<T>(&next); match maybe_value { Some(value) => { if self.drain { frame_support::storage::unhashed::kill(&next); } Some((self.previous_key[self.prefix.len()..].to_vec(), value)) }, None => continue, } }, None => None, } } } } }
You can...
- Iterate all storage on the blockchain using prefix
&[] - Iterate all storage for a pallet using prefix
hash(pallet_name) - Iterate all balances of users using prefix
hash("Balances") ++ hash("Accounts")
This is not an inherit property!
This is only because we "cleverly" chose this pattern for generating keys.
Note that iteration has no "proper" order. All keys are hashed, and we just go in the order of the resulting hash.
Opaque Storage Keys
But there is a problem...
Let's say I iterate over all users' balances...
- I will get all the balance values.
- I will get all the storage keys.
- Which are all hashed.
- I will NOT get the actual accounts which hold these balances!
For this, we need transparent storage keys.
Transparent Hashes
- Twox64Concat
- Blake2_128Concat
Basically:
final_hash = hash(preimage) ++ preimage
From this kind of hash, we can always extract the preimage:
"hello" = 0x68656c6c6f
blake2_128("hello") = 0x46fb7408d4f285228f4af516ea25851b
blake2_128concat("hello") = 0x46fb7408d4f285228f4af516ea25851b68656c6c6f
"world" = 0x776f726c64
twox64("world") = 0xef51ee66fefb78e7
twox64concat("world") = 0xef51ee66fefb78e7776f726c64
Better Balance Map
We should use Blake2_128Concat!
#![allow(unused)] fn main() { #[pallet::storage] pub type Item11<T: Config> = StorageMap<_, Blake2_128Concat, T::AccountId, Balance, ValueQuery>; }
#![allow(unused)] fn main() { #[test] fn better_balance_map() { sp_io::TestExternalities::new_empty().execute_with(|| { for i in 0u64..10u64 { Item10::<T>::insert(i, u128::from(i * 100u64)); Item11::<T>::insert(i, u128::from(i * 100u64)); } // cannot call iter for 10 because it cannot returns the keys let all_10: Vec<_> = Item10::<T>::iter_values().collect(); let all_11: Vec<_> = Item11::<T>::iter().collect(); println!("{:?}\n{:?}", all_10, all_11); assert!(false) }); } }
[600, 500, 300, 100, 800, 400, 700, 900, 0, 200]
[(6, 600), (5, 500), (3, 300), (1, 100), (8, 800), (4, 400), (7, 700), (9, 900), (0, 0), (2, 200)]
Which Hasher to Use?
Now that we know that transparent hashers are extremely useful, there are really just 3 choices:
Identity- No Hash at allTwox64Concat- Non-Cryptographic and Transparent HashBlake2_128Concat- Cryptographic and Transparent Hash
Unbalanced Trie

- We mentioned that unbalanced tries can be good at times...
- But in this case, we must select a hasher which prevents a user from manipulating the balance of our prefix trie.
Which Hasher to Use?
Basically, you should just always use Blake2_128Concat since it is hardest for a user to influence.The difference in time to execute is probably nominal (but not properly benchmarked afaik).
Some reasonable exceptions:
- If the key is already an uncontrollable cryptographic hash, you can use
Identity. - If the key is simple and controlled by runtime (like an incremented count),
Twox64Concatis good enough.
More info in the docs...
Read the StorageMap Docs for API
https://crates.parity.io/frame_support/pallet_prelude/struct.StorageMap.html
StorageDoubleMap and StorageNMap
Basically the same idea as StorageMap, but with more keys:
#![allow(unused)] fn main() { pub struct StorageDoubleMap<Prefix, Hasher1, Key1, Hasher2, Key2, Value, QueryKind = OptionQuery, OnEmpty = GetDefault, MaxValues = GetDefault>(_); }
Twox128(Prefix::pallet_prefix()) ++ Twox128(Prefix::STORAGE_PREFIX) ++ Hasher1(encode(key1)) ++ Hasher2(encode(key2))
#![allow(unused)] fn main() { pub struct StorageNMap<Prefix, Key, Value, QueryKind = OptionQuery, OnEmpty = GetDefault, MaxValues = GetDefault>(_); }
Twox128(Prefix::pallet_prefix())
++ Twox128(Prefix::STORAGE_PREFIX)
++ Hasher1(encode(key1))
++ Hasher2(encode(key2))
++ ...
++ HasherN(encode(keyN))
StorageNMap: Example
#![allow(unused)] fn main() { #[pallet::storage] pub type Item12<T: Config> = StorageNMap< _, ( NMapKey<Blake2_128Concat, u8>, NMapKey<Blake2_128Concat, u16>, NMapKey<Blake2_128Concat, u32>, ), u128, >; }
Treat the key as a tuple of the composite keys.
#![allow(unused)] fn main() { #[test] fn storage_n_map() { sp_io::TestExternalities::new_empty().execute_with(|| { Item12::<T>::insert((1u8, 1u16, 1u32), 1u128); assert_eq!(Item12::<T>::get((1u8, 1u16, 1u32)), Some(1u128)); }); } }
Map Iteration Complexity
- Iterating over a map is extremely expensive for computational and storage proof resources.
- Requires
Ntrie reads which is reallyN * log(N)database reads. - Takes up
32 bytes per hash * 16 hashes per node * N * log(N)proof size.
Generally you should not iterate on a map. If you do, make sure it is bounded!
Remove All
Implemented on Storage Maps:
#![allow(unused)] fn main() { // Remove all value of the storage. pub fn remove_all(limit: Option<u32>) -> KillStorageResult }
Where:
#![allow(unused)] fn main() { pub enum KillStorageResult { AllRemoved(u32), SomeRemaining(u32), } }
Rather than trying to delete all items at once, you can "freeze" the state machine, and have a user call remove_all multiple times using a limit.
Counted Storage Map
A wrapper around a StorageMap and a StorageValue<Value=u32> to keep track of how many items are in a map, without needing to iterate all the values.
#![allow(unused)] fn main() { pub struct CountedStorageMap<Prefix, Hasher, Key, Value, QueryKind = OptionQuery, OnEmpty = GetDefault, MaxValues = GetDefault>(_); }
This storage item has additional storage read and write overhead when manipulating values compared to a regular storage map.
Counted Storage Map Demystified
#![allow(unused)] fn main() { #[pallet::storage] pub type Item13<T: Config> = CountedStorageMap<_, Blake2_128Concat, T::AccountId, Balance>; }
This CountedStorageMap is exactly the same as:
#![allow(unused)] fn main() { #[pallet::storage] pub type Item13<T: Config> = StorageMap<_, Blake2_128Concat, T::AccountId, Balance>; /// Counter is always prefixed with "CounterFor" #[pallet::storage] pub type CounterForItem13<T: Config> = StorageValue<_, u32>; }
With some additional logic to keep these two in check.
Architecture Considerations
- You know that accessing very large items from the database is not efficient:
- Databases like ParityDB are optimized for items under 32 KB.
- Decoding is non-zero overhead.
- You know that accessing lots of storage items in a map is also very bad!
- Lots of overhead constantly calling host functions.
- Lots of overhead from the merkle trie lookup, and database reads.
- Lots of additional overhead in the storage proof
So what do you pick?
It depends! Sometimes both!
The choice of storage depends on how your logic will access it.
-
Scenario A: We need to manage millions of users, and support balance transfers.
- We should obviously use a map! Balance transfers touch only 2 accounts at a time. 2 map reads is way more efficient than reading all million users to move the balance.
-
Scenario B: We need to get the 1,000 validators for the next era.
- We should obviously use a bounded vector! We know there is an upper limit of validators, and we will need to read them all for our logic!
-
Scenario C: We need to store some metadata about the configuration of each validator.
- We should probably use a map! We will be duplicating some data from from the vector above, but the way we access configuration stuff usually is on a per-validator basis.
Summary
- FRAME Storage is just simple macros which wrap the underlying Substrate Storage APIs.
- The principles of Substrate Storage directly inform what kinds of behaviors you can do in FRAME.
- Just because something does not exist in FRAME does not mean you cannot do it!
- Just because something does exist in FRAME does not mean you can use it without thinking!
Events and Errors
How to use the slides - Full screen (new tab)
Events and Errors
Events and Errors
In this presentation, we will go over two of the tools you have access to when developing FRAME Pallets to express how your runtime calls are executing.
Errors
Intro to Errors
Not all extrinsics are valid. It could be for a number of reasons:
- The extrinsic itself is badly formatted. (wrong parameters, encoding, etc...)
- The state transition function does not allow it.
- Maybe a timing problem.
- User might be lacking resources.
- State transition might be waiting for other data or processes.
- etc...
Dispatch Result
All pallet calls return at the end a DispatchResult.
From: substrate/frame/support/src/dispatch.rs
#![allow(unused)] fn main() { pub type DispatchResult = Result<(), sp_runtime::DispatchError>; }
So a function can either return Ok(()) or some DispatchError.
Dispatch Error
From: substrate/primitives/runtime/src/lib.rs
#![allow(unused)] fn main() { /// Reason why a dispatch call failed. #[derive(Eq, Clone, Copy, Encode, Decode, Debug, TypeInfo, PartialEq, MaxEncodedLen)] #[cfg_attr(feature = "serde", derive(Serialize, Deserialize))] pub enum DispatchError { /// Some error occurred. Other( #[codec(skip)] #[cfg_attr(feature = "serde", serde(skip_deserializing))] &'static str, ), /// Failed to lookup some data. CannotLookup, /// A bad origin. BadOrigin, /// A custom error in a module. Module(ModuleError), /// At least one consumer is remaining so the account cannot be destroyed. ConsumerRemaining, /// There are no providers so the account cannot be created. NoProviders, /// There are too many consumers so the account cannot be created. TooManyConsumers, /// An error to do with tokens. Token(TokenError), /// An arithmetic error. Arithmetic(ArithmeticError), /// The number of transactional layers has been reached, or we are not in a transactional /// layer. Transactional(TransactionalError), /// Resources exhausted, e.g. attempt to read/write data which is too large to manipulate. Exhausted, /// The state is corrupt; this is generally not going to fix itself. Corruption, /// Some resource (e.g. a preimage) is unavailable right now. This might fix itself later. Unavailable, /// Root origin is not allowed. RootNotAllowed, } }
Module Errors
From: substrate/primitives/runtime/src/lib.rs
#![allow(unused)] fn main() { /// The number of bytes of the module-specific `error` field defined in [`ModuleError`]. /// In FRAME, this is the maximum encoded size of a pallet error type. pub const MAX_MODULE_ERROR_ENCODED_SIZE: usize = 4; /// Reason why a pallet call failed. #[derive(Eq, Clone, Copy, Encode, Decode, Debug, TypeInfo, MaxEncodedLen)] #[cfg_attr(feature = "serde", derive(Serialize, Deserialize))] pub struct ModuleError { /// Module index, matching the metadata module index. pub index: u8, /// Module specific error value. pub error: [u8; MAX_MODULE_ERROR_ENCODED_SIZE], /// Optional error message. #[codec(skip)] #[cfg_attr(feature = "serde", serde(skip_deserializing))] pub message: Option<&'static str>, } }
So an error is at most just 5 bytes.
Declaring Errors
#![allow(unused)] #![cfg_attr(not(feature = "std"), no_std)] fn main() { pub use pallet::*; #[frame_support::pallet] pub mod pallet { use frame_support::pallet_prelude::*; use frame_system::pallet_prelude::*; /// Configure the pallet by specifying the parameters and types on which it depends. #[pallet::config] pub trait Config: frame_system::Config { /// Because this pallet emits events, it depends on the runtime's definition of an event. type RuntimeEvent: From<Event<Self>> + IsType<<Self as frame_system::Config>::RuntimeEvent>; } #[pallet::pallet] pub struct Pallet<T>(_); #[pallet::storage] pub type CurrentOwner<T: Config> = StorageValue<_, T::AccountId>; // Errors inform users that something went wrong. #[pallet::error] pub enum Error<T> { /// There is currently no owner set. NoOwner, /// The calling user is not authorized to make this call. NotAuthorized, } #[pallet::event] #[pallet::generate_deposit(pub(super) fn deposit_event)] pub enum Event<T: Config> { /// The owner has been updated. OwnerChanged, } #[pallet::call] impl<T: Config> Pallet<T> { /// This function allows the current owner to set a new owner. /// If there is no owner, this function will return an error. #[pallet::weight(u64::default())] #[pallet::call_index(0)] pub fn change_ownership(origin: OriginFor<T>, new: T::AccountId) -> DispatchResult { let who = ensure_signed(origin)?; let current_owner = CurrentOwner::<T>::get().ok_or(Error::<T>::NoOwner)?; ensure!(current_owner == who, Error::<T>::NotAuthorized); CurrentOwner::<T>::put(new); Self::deposit_event(Event::<T>::OwnerChanged); Ok(()) } } } }
Using Errors
When writing tests, you can use errors to make sure that your functions execute exactly as expected.
#![allow(unused)] fn main() { #[test] fn errors_example() { new_test_ext().execute_with(|| { assert_noop!(TemplateModule::change_ownership(Origin::signed(1), 2), Error::<T>::NoOwner); CurrentOwner::<T>::put(1); assert_ok!(TemplateModule::change_ownership(Origin::signed(1), 2)); assert_noop!(TemplateModule::change_ownership(Origin::signed(1), 2), Error::<T>::NotAuthorized); }); } }
Encoding Errors
All errors ultimately become a DispatchError, which is the final type returned by the runtime.
#![allow(unused)] fn main() { println!("{:?}", Error::<T>::NoOwner.encode()); println!("{:?}", Error::<T>::NotAuthorized.encode()); let dispatch_error1: DispatchError = Error::<T>::NoOwner.into(); let dispatch_error2: DispatchError = Error::<T>::NotAuthorized.into(); println!("{:?}", dispatch_error1.encode()); println!("{:?}", dispatch_error2.encode()); }
[0]
[1]
[3, 1, 0, 0, 0, 0]
[3, 1, 1, 0, 0, 0]
Dispatch Error Encoding
| 3 | 1 | 1 | 0 | 0 | 0 |
| DispatchError::Module | Pallet #2 | Error #2 | (unused) | (unused) | (unused) |
Encoding based on configuration:
#![allow(unused)] fn main() { // Configure a mock runtime to test the pallet. frame_support::construct_runtime!( pub struct Test { System: frame_system::{Pallet, Call, Config, Storage, Event<T>}, TemplateModule: pallet_template, } ); }
#![allow(unused)] fn main() { // Errors inform users that something went wrong. #[pallet::error] pub enum Error<T> { /// There is currently no owner set. NoOwner, /// The calling user is not authorized to make this call. NotAuthorized, } }
Nested Errors
Errors support up to 5 bytes, which allows you to create nested errors, or insert other minimal data with the PalletError derive macro.
#![allow(unused)] fn main() { #[derive(Encode, Decode, PalletError, TypeInfo)] pub enum SubError { SubError1, SubError2, SubError3, } use frame_system::pallet::Error as SystemError; // Errors inform users that something went wrong. #[pallet::error] pub enum Error<T> { /// There is currently no owner set. NoOwner, /// The calling user is not authorized to make this call. NotAuthorized, /// Errors coming from another place. SubError(SubError), /// Errors coming from another place. SystemError(SystemError<T>), /// Some Error with minimal data DataError(u16), } }
Notes:
https://github.com/paritytech/substrate/pull/10242
Events
Intro to Events
When an extrinsic completes successfully, there is often some metadata you would like to expose to the outside world about what exactly happened during the execution.
For example, there may be multiple different ways an extrinsic completes successfully, and you want the user to know what happened.
Or maybe there is some significant state transition that you know users
Declaring and Emitting Events
#![allow(unused)] #![cfg_attr(not(feature = "std"), no_std)] fn main() { pub use pallet::*; #[frame_support::pallet] pub mod pallet { use frame_support::pallet_prelude::*; use frame_system::pallet_prelude::*; /// Configure the pallet by specifying the parameters and types on which it depends. #[pallet::config] pub trait Config: frame_system::Config { /// Because this pallet emits events, it depends on the runtime's definition of an event. type RuntimeEvent: From<Event<Self>> + IsType<<Self as frame_system::Config>::RuntimeEvent>; } #[pallet::pallet] pub struct Pallet<T>(_); #[pallet::storage] pub type CurrentOwner<T: Config> = StorageValue<_, T::AccountId>; // Errors inform users that something went wrong. #[pallet::error] pub enum Error<T> { /// There is currently no owner set. NoOwner, /// The calling user is not authorized to make this call. NotAuthorized, } #[pallet::event] #[pallet::generate_deposit(pub(super) fn deposit_event)] pub enum Event<T: Config> { /// The owner has been updated. OwnerChanged, } #[pallet::call] impl<T: Config> Pallet<T> { /// This function allows the current owner to set a new owner. /// If there is no owner, this function will return an error. #[pallet::weight(u64::default())] #[pallet::call_index(0)] pub fn change_ownership(origin: OriginFor<T>, new: T::AccountId) -> DispatchResult { let who = ensure_signed(origin)?; let current_owner = CurrentOwner::<T>::get().ok_or(Error::<T>::NoOwner)?; ensure!(current_owner == who, Error::<T>::NotAuthorized); CurrentOwner::<T>::put(new); Self::deposit_event(Event::<T>::OwnerChanged); Ok(()) } } } }
Deposit Event
#![allow(unused)] fn main() { #[pallet::generate_deposit(pub(super) fn deposit_event)] }
Simply generates:
#![allow(unused)] fn main() { impl<T: Config> Pallet<T> { pub(super) fn deposit_event(event: Event<T>) { let event = <<T as Config>::Event as From<Event<T>>>::from(event); let event = <<T as Config>::Event as Into<<T as frame_system::Config>::Event>>::into(event); <frame_system::Pallet<T>>::deposit_event(event) } } }
frame/support/procedural/src/pallet/expand/event.rs
Deposit Event in System
Events are just a storage item in FRAME System.
frame/system/src/lib.rs
#![allow(unused)] fn main() { /// Events deposited for the current block. /// /// N O T E: The item is unbound and should therefore never be read on chain. /// It could otherwise inflate the PoV size of a block. /// /// Events have a large in-memory size. Box the events to not go out-of-memory /// just in case someone still reads them from within the runtime. #[pallet::storage] pub(super) type Events<T: Config> = StorageValue<_, Vec<Box<EventRecord<T::RuntimeEvent, T::Hash>>>, ValueQuery>; /// The number of events in the `Events<T>` list. #[pallet::storage] #[pallet::getter(fn event_count)] pub(super) type EventCount<T: Config> = StorageValue<_, EventIndex, ValueQuery>; }
Deposit Events in System
Depositing events ultimately just appends a new event to this storage.
frame/system/src/lib.rs
#![allow(unused)] fn main() { /// Deposits an event into this block's event record. pub fn deposit_event(event: impl Into<T::RuntimeEvent>) { Self::deposit_event_indexed(&[], event.into()); } /// Deposits an event into this block's event record adding this event /// to the corresponding topic indexes. /// /// This will update storage entries that correspond to the specified topics. /// It is expected that light-clients could subscribe to this topics. pub fn deposit_event_indexed(topics: &[T::Hash], event: T::RuntimeEvent) { let block_number = Self::block_number(); // Don't populate events on genesis. if block_number.is_zero() { return } let phase = ExecutionPhase::<T>::get().unwrap_or_default(); let event = EventRecord { phase, event, topics: topics.to_vec() }; // Index of the to be added event. let event_idx = { let old_event_count = EventCount::<T>::get(); let new_event_count = match old_event_count.checked_add(1) { // We've reached the maximum number of events at this block, just // don't do anything and leave the event_count unaltered. None => return, Some(nc) => nc, }; EventCount::<T>::put(new_event_count); old_event_count }; Events::<T>::append(event); for topic in topics { <EventTopics<T>>::append(topic, &(block_number, event_idx)); } } }
You Cannot Read Events
- The events storage are an unbounded vector of individual events emitted by your pallets.
- If you ever read this storage, you will introduce the whole thing into your storage proof!
- Never write runtime logic which reads from or depends on events.
- Tests are okay.
You Cannot Read Events
frame/system/src/lib.rs
#![allow(unused)] fn main() { /// Get the current events deposited by the runtime. /// /// Should only be called if you know what you are doing and outside of the runtime block /// execution else it can have a large impact on the PoV size of a block. pub fn read_events_no_consensus( ) -> impl sp_std::iter::Iterator<Item = Box<EventRecord<T::RuntimeEvent, T::Hash>>> { Events::<T>::stream_iter() } /// Get the current events deposited by the runtime. /// /// NOTE: This should only be used in tests. Reading events from the runtime can have a large /// impact on the PoV size of a block. Users should use alternative and well bounded storage /// items for any behavior like this. /// /// NOTE: Events not registered at the genesis block and quietly omitted. #[cfg(any(feature = "std", feature = "runtime-benchmarks", test))] pub fn events() -> Vec<EventRecord<T::RuntimeEvent, T::Hash>> { debug_assert!( !Self::block_number().is_zero(), "events not registered at the genesis block" ); // Dereferencing the events here is fine since we are not in the // memory-restricted runtime. Self::read_events_no_consensus().map(|e| *e).collect() } }
Testing Events
Remember to set the block number to greater than zero!
Some tools in FRAME System for you:
frame/system/src/lib.rs
#![allow(unused)] fn main() { /// Set the block number to something in particular. Can be used as an alternative to /// `initialize` for tests that don't need to bother with the other environment entries. #[cfg(any(feature = "std", feature = "runtime-benchmarks", test))] pub fn set_block_number(n: BlockNumberFor<T>) { <Number<T>>::put(n); } /// Assert the given `event` exists. #[cfg(any(feature = "std", feature = "runtime-benchmarks", test))] pub fn assert_has_event(event: T::RuntimeEvent) { assert!(Self::events().iter().any(|record| record.event == event)) } /// Assert the last event equal to the given `event`. #[cfg(any(feature = "std", feature = "runtime-benchmarks", test))] pub fn assert_last_event(event: T::RuntimeEvent) { assert_eq!(Self::events().last().expect("events expected").event, event); } }
Using Events in Tests
#![allow(unused)] fn main() { #[test] fn events_example() { new_test_ext().execute_with(|| { frame_system::Pallet::<T>::set_block_number(1); CurrentOwner::<T>::put(1); assert_ok!(TemplateModule::change_ownership(Origin::signed(1), 2)); assert_ok!(TemplateModule::change_ownership(Origin::signed(2), 3)); assert_ok!(TemplateModule::change_ownership(Origin::signed(3), 4)); let events = frame_system::Pallet::<T>::events(); assert_eq!(events.len(), 3); frame_system::Pallet::<T>::assert_has_event(crate::Event::<T>::OwnerChanged { old: 1, new: 2}.into()); frame_system::Pallet::<T>::assert_last_event(crate::Event::<T>::OwnerChanged { old: 3, new: 4}.into()); }); } }
Remember other pallets can deposit events too!
Summary
- Events and Errors are two ways you can signal to users what is happening when they dispatch an extrinsic.
- Events usually signify some successful thing happening.
- Errors signify when something has gone bad (and all changes reverted).
- Both are accessible by the end user when they occur.
Calls
How to use the slides - Full screen (new tab)
FRAME Calls
Overview
Calls allow users to interact with your state transition function.
In this lecture, you will learn how to create calls for your Pallet with FRAME.
Terminology
The term "call", "extrinsic", and "dispatchable" all get mixed together.
Here is a sentence which should help clarify their relationship, and why they are such similar terms:
Users submit an extrinsic to the blockchain, which is dispatched to a Pallet call.
Call Definition
Here is a simple pallet call. Let's break it down.
#![allow(unused)] fn main() { #[pallet::call(weight(<T as Config>::WeightInfo))] impl<T: Config> Pallet<T> { #[pallet::call_index(0)] pub fn transfer( origin: OriginFor<T>, dest: AccountIdLookupOf<T>, #[pallet::compact] value: T::Balance, ) -> DispatchResult { let source = ensure_signed(origin)?; let dest = T::Lookup::lookup(dest)?; <Self as fungible::Mutate<_>>::transfer(&source, &dest, value, Expendable)?; Ok(()) } } }
Call Implementation
Calls are just functions which are implemented on top of the Pallet struct.
You can do this with any kind of function, however, "FRAME magic" turns these into dispatchable calls through the #[pallet::call] macro.
Call Origin
Every pallet call must have an origin parameter, which uses the OriginFor<T> type, which comes from frame_system.
#![allow(unused)] fn main() { /// Type alias for the `Origin` associated type of system config. pub type OriginFor<T> = <T as crate::Config>::RuntimeOrigin; }
Origin
The basic origins available in frame are:
#![allow(unused)] fn main() { /// Origin for the System pallet. #[derive(PartialEq, Eq, Clone, RuntimeDebug, Encode, Decode, TypeInfo, MaxEncodedLen)] pub enum RawOrigin<AccountId> { /// The system itself ordained this dispatch to happen: this is the highest privilege level. Root, /// It is signed by some public key and we provide the `AccountId`. Signed(AccountId), /// It is signed by nobody, can be either: /// * included and agreed upon by the validators anyway, /// * or unsigned transaction validated by a pallet. None, } }
We will have another presentation diving deeper into Origins.
Origin Checking
Normally, the first thing you do in a call is check that the origin of the caller is what you expect.
Most often, this is checking that the extrinsic is Signed, which is a transaction from a user account.
#![allow(unused)] fn main() { let caller: T::AccountId = ensure_signed(origin)?; }
Call Parameters
Pallet calls can have additional parameters beyond origin allowing you to submit relevant data about what the caller would like to do.
All call parameters need to satisfy the Parameter trait:
#![allow(unused)] fn main() { /// A type that can be used as a parameter in a dispatchable function. pub trait Parameter: Codec + EncodeLike + Clone + Eq + fmt::Debug + scale_info::TypeInfo {} impl<T> Parameter for T where T: Codec + EncodeLike + Clone + Eq + fmt::Debug + scale_info::TypeInfo {} }
Parameter Limits
Most everything can be used as a call parameter, even a normal Vec, however, FRAME ensures that encoded block are smaller than a maximum block size, which inherently limits the extrinsic length.
In Polkadot this is currently 5 MB.
Compact Parameters
Parameters that are compact encoded can be used in calls.
#![allow(unused)] fn main() { pub fn transfer( origin: OriginFor<T>, dest: AccountIdLookupOf<T>, #[pallet::compact] value: T::Balance, ) -> DispatchResult { ... } }
This can help save lots of bytes, especially in cases like balances as shown above.
Call Logic
The most relevant part of a call is the "call logic".
There is really nothing magical happening here, just normal Rust.
However, you must follow one important rule...
Calls MUST NOT Panic
Under no circumstances (save, perhaps, storage getting into an irreparably damaged state) must this function panic.
Allowing callers to trigger a panic from a call can allow users to attack your chain by bypassing fees or other costs associated with executing logic on the blockchain.
Call Return
Every call returns a DispatchResult:
#![allow(unused)] fn main() { pub type DispatchResult = Result<(), sp_runtime::DispatchError>; }
This allows you to handle errors in your runtime, and NEVER PANIC!
Returning an Error
At any point in your call logic, you can return a DispatchError.
#![allow(unused)] fn main() { ensure!(new_balance >= min_balance, Error::<T, I>::LiquidityRestrictions); }
When you do, thanks to transactional storage layers, all modified state will be reverted.
Returning Success
If everything in your pallet completed successfully, you simply return Ok(()), and all your state changes are committed, and the extrinsic is considered to have executed successfully.
Call Index
It is best practice to explicitly label your calls with a call_index.
#![allow(unused)] fn main() { #[pallet::call_index(0)] }
This can help ensure that changes to your pallet do not lead to breaking changes to the transaction format.
Call Encoding
At a high level, a call is encoded as two bytes (plus any parameters):
- The Pallet Index
- The Call Index
Pallet Index comes from the order / explicit numbering of the construct_runtime!. If things change order, without explicit labeling, a transaction generated by a wallet (like a ledger) could be incorrect!
Notes:
Note that this also implies there can only be 256 calls per pallet due to the 1 byte encoding.
Weight
Each call must also include specify a call weight.
We have another lecture on Weights and Benchmarking, but the high level idea is that this weight function tells us how complex the call is, and the fees that should be charged to the user.
Weight Per Call
This can be done per call:
#![allow(unused)] fn main() { #[pallet::call] impl<T: Config> Pallet<T> { #[pallet::weight(T::WeightInfo::transfer())] #[pallet::call_index(0)] pub fn transfer( origin: OriginFor<T>, dest: AccountIdLookupOf<T>, #[pallet::compact] value: T::Balance, ) -> DispatchResult { let source = ensure_signed(origin)?; let dest = T::Lookup::lookup(dest)?; <Self as fungible::Mutate<_>>::transfer(&source, &dest, value, Expendable)?; Ok(()) } } }
Weight for the Pallet
Or for all calls in the pallet:
#![allow(unused)] fn main() { #[pallet::call(weight(<T as Config>::WeightInfo))] impl<T: Config> Pallet<T> { #[pallet::call_index(0)] pub fn transfer( origin: OriginFor<T>, dest: AccountIdLookupOf<T>, #[pallet::compact] value: T::Balance, ) -> DispatchResult { let source = ensure_signed(origin)?; let dest = T::Lookup::lookup(dest)?; <Self as fungible::Mutate<_>>::transfer(&source, &dest, value, Expendable)?; Ok(()) } } }
In this case, the weight function name is assumed to match the call name for all calls.
Notes:
https://github.com/paritytech/substrate/pull/13932
Questions
Hooks
How to use the slides - Full screen (new tab)
🪝 FRAME/Pallet Hooks 🪝
Hooks: All In One
- Onchain / STF
on_runtime_upgradeon_initializepoll(WIP)on_finalizeon_idle
- Offchain:
genesis_buildoffchain_workerintegrity_testtry_state
Notes:
https://paritytech.github.io/substrate/master/frame_support/traits/trait.Hooks.html
---v
Hooks: All In One
#![allow(unused)] fn main() { #[pallet::hooks] impl<T: Config> Hooks<BlockNumberFor<T>> for Pallet<T> { fn on_runtime_upgrade() -> Weight {} fn on_initialize() -> Weight {} fn on_finalize() {} fn on_idle(remaining_weight: Weight) -> Weight {} fn offchain_worker() {} fn integrity_test() {} #[cfg(feature = "try-runtime")] fn try_state() -> Result<(), &'static str> {} } #[pallet::genesis_build] impl<T: Config> BuildGenesisConfig for GenesisConfig<T> { fn build(&self) {} } }
Notes:
Many of these functions receive the block number as an argument, but that can easily be fetched from
frame_system::Pallet::<T>::block_number()
Hooks: on_runtime_upgrade
- Called every time the
spec_version/spec_nameis bumped. - Why would might you be interested in implementing this?
Notes:
Because very often runtime upgrades needs to be accompanied by some kind of state migration. Has its own lecture, more over there.
Hooks: on_initialize
- Useful for any kind of automatic operation.
- The weight you return is interpreted as
DispatchClass::Mandatory.
---v
Hooks: On_Initialize
MandatoryHooks should really be lightweight and predictable, with a bounded complexity.
#![allow(unused)] fn main() { fn on_initialize() -> Weight { // any user can create one entry in `MyMap` 😱🔫. <MyMap<T>>::iter().for_each(do_stuff); } }
---v
Hooks: On_Initialize
- Question: If you have 3 pallets, in which order their
on_initializeare called? - Question: If your runtime panics
on_initialize, how can you recover from it? - Question: If your
on_initializeconsumes more than the maximum block weight?
Notes:
- The order comes from
construct_runtime!macro. - Panic in mandatory hooks is fatal error. You are pretty much done.
- Overweight blocks using mandatory hooks, are possible, ONLY in the context of solo-chains. Such a block will take longer to produce, but it eventually will. If you have your eyes set on being a parachain developer, you should treat overweight blocks as fatal as well.
Hooks: on_finalize
- Extension of
on_initialize, but at the end of the block. - Its weight needs to be known in advance. Therefore, less preferred compared to
on_initialize.
#![allow(unused)] fn main() { fn on_finalize() {} // ✅ fn on_finalize() -> Weight {} // ❌ }
- Nothing to do with finality in the consensus context.
---v
Hooks: on_finalize
Generally, avoid using it unless if something REALLY needs to be happen at the end of the block.
Notes:
Sometimes, rather than thinking "at the end of block N", consider writing code "at the beginning of block N+1"
Hooks: poll
- The non-mandatory version of
on_initialize. - In the making 👷
Notes:
See: https://github.com/paritytech/substrate/pull/14279 and related PRs
Hooks: on_idle
- Optional variant of
on_finalize, also executed at the end of the block. - Small semantical difference: executes one pallet's hook, per block, randomly, rather than all pallets'.
---v
The Future: Moving Away From Mandatory Hooks
on_initialize->pollon_finalize->on_idle- New primitives for multi-block migrations
- New primitives for optional service work via extrinsics.
Notes:
This is all in the agenda of the FRAME team at Parity for 2023.
https://github.com/paritytech/polkadot-sdk/issues/206 https://github.com/paritytech/polkadot-sdk/issues/198
Recap: Onchain/STF Hooks
subgraph OnChain
direction LR
Optional --> BeforeExtrinsics
BeforeExtrinsics --> Inherents
Inherents --> Poll
Poll --> Transactions
Transactions --> AfterTransactions
end
subgraph Optional
OnRuntimeUpgrade end
subgraph BeforeExtrinsics
OnInitialize
end
subgraph Transactions
Transaction1 --> UnsignedTransaction2 --> Transaction3
end
subgraph Inherents
Inherent1 --> Inherent2
end
Notes:
implicit in this:
Inherents are only first, which was being discussed: https://github.com/polkadot-fellows/RFCs/pull/13
Hooks: genesis_build
- Means for each pallet to specify a $f(input): state$ at genesis.
- This is called only once, by the client, when you create a new chain.
- Is this invoked every time you run
cargo run?
- Is this invoked every time you run
#[pallet::genesis_build].
---v
Hooks: genesis_build
#![allow(unused)] fn main() { #[pallet::genesis_build] pub struct GenesisConfig<T: Config> { pub foo: Option<u32>, pub bar: Vec<u8>, } }
#![allow(unused)] fn main() { impl<T: Config> Default for GenesisConfig<T> { fn default() -> Self { // snip } } }
#![allow(unused)] fn main() { #[pallet::genesis_build] impl<T: Config> GenesisBuild<T> for GenesisConfig<T> { fn build(&self) { // use self.foo, self.bar etc. } } }
---v
Hooks: genesis_build
GenesisConfigis a composite/amalgamated item at the top level runtime.
#![allow(unused)] fn main() { construct_runtime!( pub enum Runtime where { System: frame_system, Balances: pallet_balances, } ); }
#![allow(unused)] fn main() { struct RuntimeGenesisConfig { SystemConfig: pallet_system::GenesisConfig, PalletAConfig: pallet_a::GenesisConfig, } }
Notes:
https://paritytech.github.io/substrate/master/node_template_runtime/struct.RuntimeGenesisConfig.html
---v
Hooks: genesis_build
- Recent changes moving
genesis_buildto be used over a runtime API, rather than native runtime. #[cfg(feature = "std")]in pallets will go away.
Notes:
https://github.com/paritytech/polkadot-sdk/issues/25
Hooks: offchain_worker
Fully offchain application:
- Read chain state via RPC.
- submit desired side effects back to the chain as transactions.
Runtime Offchain Worker:
- Code lives onchain, upgradable only in synchrony with the whole runtime 👎
- Ergonomic and fast state access 👍
- State writes are ignored 🤷
- Can submit transactions back to the chain as well ✅
- Source of many confusions!
Notes:
People have often thought that they can do magic with things with OCW, please don't. BIG warning to founders to be careful with this!
https://paritytech.github.io/substrate/master/pallet_examples/index.html
---v
Hooks: offchain_worker
- Execution entirely up to the client.
- Has a totally separate thread pool than the normal execution.
--offchain-worker <ENABLED>
Possible values:
- always:
- never:
- when-authority
--execution-offchain-worker <STRATEGY>
Possible values:
- native:
- wasm:
- both:
- native-else-wasm:
---v
Hooks: offchain_worker
- Threads can overlap, each is reading the state of its corresponding block

Notes:
https://paritytech.github.io/substrate/master/sp_runtime/offchain/storage_lock/index.html
---v
Hooks: offchain_worker
-
Offchain workers have their own special host functions: http, dedicated storage, time, etc.
-
Offchain workers have the same execution limits as Wasm (limited memory, custom allocator).
-
Source of confusion, why OCWs cannot write to state.
Notes:
These are the source of the confusion.
Word on allocator limit in Substrate Wasm execution (subject to change).
- Max single allocation limited
- Max total allocation limited.
Hooks: integrity_test
- Put into a test by
construct_runtime!.
#![allow(unused)] fn main() { __construct_runtime_integrity_test::runtime_integrity_tests }
#![allow(unused)] fn main() { fn integrity_test() { assert!( T::MyConfig::get() > 0, "Are all of the generic types I have sensible?" ); // notice that this is for tests, std is available. assert!(std::mem::size_of::<T::Balance>() > 4); } }
Notes:
I am in fan of renaming this. If you are too, please comment here
Hooks: try_state
- A means for you to ensure correctness of your $STF$, after each transition.
- Entirely offchain, custom runtime-apis, conditional
compilation.
- Called from
try-runtime-cli, which you will learn about next week, or anyone else
- Called from
- Examples from your assignment?
Notes:
What is a transition? Either a block, or single extrinsic
Hooks: Recap
subgraph Genesis
GenesisBuild
end
subgraph AfterTransactions
direction LR
OnIdle --> OnFinalize
end
subgraph OnChain
direction LR
Optional --> BeforeExtrinsics
BeforeExtrinsics --> Inherents
Inherents --> Poll
Poll --> Transactions
Transactions --> AfterTransactions
end
subgraph Optional
OnRuntimeUpgrade end
subgraph BeforeExtrinsics
OnInitialize
end
subgraph Transactions
Transaction1 --> UnsignedTransaction2 --> Transaction3
end
subgraph Inherents
Inherent1 --> Inherent2
end
- What other hooks can you think of?
Notes:
What other ideas you can think of?
- a hook called once a pallet is first initialized. https://github.com/paritytech/polkadot-sdk/issues/109
- Local on Post/Pre dispatch: https://github.com/paritytech/polkadot-sdk/issues/261
- Global on Post/Pre dispatch is in fact a signed extension. It has to live in the runtime, because you have to specify order.
Additional Resources! 😋
Check speaker notes (click "s" 😉)
Notes:
Post lecture Notes
Regarding this drawback to offchain workers that you can only upgrade in cadence with the network. Offchain worker, like tx-pool api, is only called from an offchain context. Node operators can easily use the runtime overrides feature to change the behavior of their offchain worker anytime they want.
Origin
How to use the slides - Full screen (new tab)
Origin
Origin
This presentation will cover the use of Origin in FRAME, and how you can customize and extend this abstractions.
What is Origin?
All dispatchable calls have an Origin that describes where the call originates from.
#![allow(unused)] fn main() { /// Make some on-chain remark. #[pallet::weight(T::SystemWeightInfo::remark(_remark.len() as u32))] pub fn remark(origin: OriginFor<T>, _remark: Vec<u8>) -> DispatchResultWithPostInfo { ensure_signed_or_root(origin)?; Ok(().into()) } }
FRAME System RawOrigin
These are origins which are included with FRAME by default.
#![allow(unused)] fn main() { /// Origin for the System pallet. #[derive(PartialEq, Eq, Clone, RuntimeDebug, Encode, Decode, TypeInfo, MaxEncodedLen)] pub enum RawOrigin<AccountId> { /// The system itself ordained this dispatch to happen: this is the highest privilege level. Root, /// It is signed by some public key and we provide the `AccountId`. Signed(AccountId), /// It is signed by nobody, can be either: /// * included and agreed upon by the validators anyway, /// * or unsigned transaction validated by a pallet. None, } }
How is it used?
The Runtime Origin is used by dispatchable functions to check where a call has come from.
This is similar to msg.sender in Solidity, but FRAME is more powerful, and so is Origin.
Origin Checks
#![allow(unused)] fn main() { /// Ensure that the origin `o` represents the root. Returns `Ok` or an `Err` otherwise. pub fn ensure_root<OuterOrigin, AccountId>(o: OuterOrigin) -> Result<(), BadOrigin> }
#![allow(unused)] fn main() { /// Ensure that the origin `o` represents a signed extrinsic (i.e. transaction). /// Returns `Ok` with the account that signed the extrinsic or an `Err` otherwise. pub fn ensure_signed<OuterOrigin, AccountId>(o: OuterOrigin) -> Result<AccountId, BadOrigin> }
#![allow(unused)] fn main() { /// Ensure that the origin `o` represents an unsigned extrinsic. Returns `Ok` or an `Err` otherwise. pub fn ensure_none<OuterOrigin, AccountId>(o: OuterOrigin) -> Result<(), BadOrigin> }
#![allow(unused)] fn main() { /// Ensure that the origin `o` represents either a signed extrinsic (i.e. transaction) or the root. /// Returns `Ok` with the account that signed the extrinsic, `None` if it was root, or an `Err` /// otherwise. pub fn ensure_signed_or_root<OuterOrigin, AccountId>(o: OuterOrigin) -> Result<Option<AccountId>, BadOrigin> }
Examples: Signed Origin
A Simple Balance Transfer.
#![allow(unused)] fn main() { #[pallet::call_index(0)] #[pallet::weight(T::WeightInfo::transfer())] pub fn transfer( origin: OriginFor<T>, dest: AccountIdLookupOf<T>, #[pallet::compact] value: T::Balance, ) -> DispatchResultWithPostInfo { let transactor = ensure_signed(origin)?; // -- snip -- } }
Most extrinsics use a Signed origin.
Examples: Root Origin
The extrinsic to upgrade a chain.
#![allow(unused)] fn main() { /// Set the new runtime code. #[pallet::call_index(2)] #[pallet::weight((T::BlockWeights::get().max_block, DispatchClass::Operational))] pub fn set_code(origin: OriginFor<T>, code: Vec<u8>) -> DispatchResultWithPostInfo { ensure_root(origin)?; Self::can_set_code(&code)?; T::OnSetCode::set_code(code)?; Ok(().into()) } }
Root has access to many functions which can directly modify your blockchain. Assume Root access can do anything.
Examples: None Origin
Setting the timestamp of the block.
#![allow(unused)] fn main() { /// Set the current time. #[pallet::call_index(0)] #[pallet::weight((T::WeightInfo::set(), DispatchClass::Mandatory))] pub fn set(origin: OriginFor<T>, #[pallet::compact] now: T::Moment) -> DispatchResult { ensure_none(origin)?; // -- snip -- } } }
None origin is not very straight forward. More details next...
None for Inherents
None origin can be used to represents extrinsics which are specifically included by the block author, also known as an inherent.
In those cases, it includes inherent checking logic with ProvideInherent.
#![allow(unused)] fn main() { #[pallet::inherent] impl<T: Config> ProvideInherent for Pallet<T> { type Call = Call<T>; type Error = InherentError; const INHERENT_IDENTIFIER: InherentIdentifier = INHERENT_IDENTIFIER; // -- snip -- }
None for Unsigned
None can also be used to represent "unsigned extrinsics", which are intended to be submitted by anyone without a key.
In those cases, it includes unsigned validation logic with ValidateUnsigned.
#![allow(unused)] fn main() { #[pallet::validate_unsigned] impl<T: Config> ValidateUnsigned for Pallet<T> { type Call = Call<T>; fn validate_unsigned(source: TransactionSource, call: &Self::Call) -> TransactionValidity { Self::validate_unsigned(source, call) } fn pre_dispatch(call: &Self::Call) -> Result<(), TransactionValidityError> { Self::pre_dispatch(call) } } }
Custom Origins
Origins are extensible and customizable.
Each pallet can introduce new Origins which can be used throughout the runtime.
#![allow(unused)] fn main() { /// The `#[pallet::origin]` attribute allows you to define some origin for the pallet. #[pallet::origin] pub struct Origin<T>(PhantomData<(T)>); }
Example: Collective Pallet
#![allow(unused)] fn main() { /// Origin for the collective module. pub enum RawOrigin<AccountId, I> { /// It has been condoned by a given number of members of the collective from a given total. Members(MemberCount, MemberCount), /// It has been condoned by a single member of the collective. Member(AccountId), /// Dummy to manage the fact we have instancing. _Phantom(PhantomData<I>), } }
This custom origin allows us to represent a collection of users, rather than a single account.
For example: Members(5, 9) represents that 5 out of 9 members agree on something as controlled by the collective pallet logic.
Example: Parachain Origin
#![allow(unused)] fn main() { /// Origin for the parachains. #[pallet::origin] pub enum Origin { /// It comes from a parachain. Parachain(ParaId), } }
This is a custom origin which allows us to represent a message that comes from a parachain.
Re-Dispatching
You can actually dispatch a call within a call with an origin of your choice.
#![allow(unused)] fn main() { #[pallet::call_index(0)] #[pallet::weight({ let dispatch_info = call.get_dispatch_info(); (dispatch_info.weight, dispatch_info.class) })] pub fn sudo( origin: OriginFor<T>, call: Box<<T as Config>::RuntimeCall>, ) -> DispatchResultWithPostInfo { // This is a public call, so we ensure that the origin is some signed account. let sender = ensure_signed(origin)?; ensure!(Self::key().map_or(false, |k| sender == k), Error::<T>::RequireSudo); let res = call.dispatch_bypass_filter(frame_system::RawOrigin::Root.into()); Self::deposit_event(Event::Sudid { sudo_result: res.map(|_| ()).map_err(|e| e.error) }); // Sudo user does not pay a fee. Ok(Pays::No.into()) } }
Here, Sudo Pallet allows a Signed origin to elevate itself to a Root origin, if the logic allows.
Example: Collective Pallet
Here you can see the Collective Pallet creating, and dispatching with the Members origin we showed previously.
#![allow(unused)] fn main() { fn do_approve_proposal(seats: MemberCount, yes_votes: MemberCount, proposal_hash: T::Hash, proposal: <T as Config<I>>::Proposal) -> (Weight, u32) { Self::deposit_event(Event::Approved { proposal_hash }); let dispatch_weight = proposal.get_dispatch_info().weight; let origin = RawOrigin::Members(yes_votes, seats).into(); let result = proposal.dispatch(origin); Self::deposit_event(Event::Executed { proposal_hash, result: result.map(|_| ()).map_err(|e| e.error) }); // default to the dispatch info weight for safety let proposal_weight = get_result_weight(result).unwrap_or(dispatch_weight); // P1 let proposal_count = Self::remove_proposal(proposal_hash); (proposal_weight, proposal_count) } }
Custom Origin Checks
You can then write logic which is only accessible with custom origins by implementing the EnsureOrigin trait.
#![allow(unused)] fn main() { /// Some sort of check on the origin is performed by this object. pub trait EnsureOrigin<OuterOrigin> { ... } }
These need to be configured in the Runtime, where all custom origins for your runtime are known.
Example: Alliance Pallet
Pallet's can allow for various origins to be configured by the Runtime.
#![allow(unused)] fn main() { #[pallet::config] pub trait Config<I: 'static = ()>: frame_system::Config { /// Origin for admin-level operations, like setting the Alliance's rules. type AdminOrigin: EnsureOrigin<Self::RuntimeOrigin>; /// Origin that manages entry and forcible discharge from the Alliance. type MembershipManager: EnsureOrigin<Self::RuntimeOrigin>; /// Origin for making announcements and adding/removing unscrupulous items. type AnnouncementOrigin: EnsureOrigin<Self::RuntimeOrigin>; // -- snip -- } }
Example: Alliance Pallet
Pallet calls can then use these custom origins to gate access to the logic.
#![allow(unused)] fn main() { /// Set a new IPFS CID to the alliance rule. #[pallet::call_index(5)] #[pallet::weight(T::WeightInfo::set_rule())] pub fn set_rule(origin: OriginFor<T>, rule: Cid) -> DispatchResult { T::AdminOrigin::ensure_origin(origin)?; Rule::<T, I>::put(&rule); Self::deposit_event(Event::NewRuleSet { rule }); Ok(()) } }
Example: Alliance Pallet
Finally, the Runtime itself is where you configure what those Origins are.
#![allow(unused)] fn main() { impl pallet_alliance::Config for Runtime { type AdminOrigin = EitherOfDiverse< EnsureRoot<AccountId>, EnsureProportionAtLeast<AccountId, AllianceCollective, 1, 1>, >; type MembershipManager = EitherOfDiverse< EnsureRoot<AccountId>, EnsureProportionMoreThan<AccountId, AllianceCollective, 2, 3>, >; type AnnouncementOrigin = EitherOfDiverse< EnsureRoot<AccountId>, EnsureProportionMoreThan<AccountId, AllianceCollective, 1, 3>, >; } }
As you can see, they can even support multiple different origins!
Fees
Fees are usually handled by some pallet like the Transaction Payments Pallet.
However, if there is no Signed origin, you can't really take a fee.
You should assume any transaction which is not from the Signed origin is feeless, unless you explicitly write code to handle it.
Questions
Outer Enum
How to use the slides - Full screen (new tab)
Outer Enum
Outer Enum
In this presentation, you will learn about a common pattern used throughout FRAME, which abstracts many separate types into a single unified type that is used by the Runtime.
This is also known as "aggregate" types.
Enums in FRAME
There are 4 main Enums which you will encounter throughout your FRAME development:
- The Call Enum
- The Event Enum
- The Error Enum
- The Origin Enum
All of these enums have some representation within individual pallets, but also the final FRAME runtime you develop.
Breaking It Down (Without Substrate)
#![allow(non_camel_case_types)] #![allow(dead_code)] use parity_scale_codec::Encode; pub type AccountId = u16; pub type Balance = u32; pub type Hash = [u8; 32]; mod balances { use crate::*; #[derive(Encode)] pub enum Call { transfer { to: AccountId, amount: Balance }, transfer_all { to: AccountId }, } #[derive(Encode)] pub enum Error { InsufficientBalance, ExistentialDeposit, KeepAlive, } #[derive(Encode)] pub enum Event { Transfer { from: AccountId, to: AccountId, amount: Balance }, } } mod democracy { use crate::*; #[derive(Encode)] pub enum Call { propose { proposal_hash: Hash }, vote { proposal_id: u32, aye: bool }, } #[derive(Encode)] pub enum Error { DuplicateProposal, } #[derive(Encode)] pub enum Event { Proposed { proposal_index: Hash }, Passed { proposal_index: Hash }, NotPassed { proposal_index: Hash }, } } mod staking { use crate::*; #[derive(Encode)] pub enum Call { unstake, stake { nominate: Vec<AccountId>, amount: Balance }, } #[derive(Encode)] pub enum Error { TooManyTargets, EmptyTargets, AlreadyBonded, } impl Into<DispatchError> for Error { fn into(self) -> DispatchError { DispatchError::Module( ModuleError { pallet: runtime::Runtime::Staking as u8, error: self as u8, } ) } } } // Similar to `sp-runtime` mod runtime_primitives { use crate::*; #[derive(Encode)] pub struct ModuleError { pub pallet: u8, pub error: u8, } #[derive(Encode)] pub enum DispatchError { BadOrigin, Module(ModuleError), } } mod runtime { use crate::*; #[derive(Encode)] pub enum PalletIndex { Balances = 0, Democracy = 1, Staking = 2, } #[derive(Encode)] pub enum RuntimeCall { BalancesCall(balances::Call), DemocracyCall(democracy::Call), StakingCall(staking::Call), } #[derive(Encode)] pub enum RuntimeEvent { BalancesEvent(balances::Event), DemocracyEvent(democracy::Event), // No staking events... not even in the enum. } // Imagine this for all of the possible types above... impl Into<RuntimeEvent> for balances::Event { fn into(self) -> RuntimeEvent { RuntimeEvent::BalancesEvent(self) } } // Imagine this for all of the possible types above... impl TryFrom<RuntimeEvent> for balances::Event { type Error = (); fn try_from(outer: RuntimeEvent) -> Result<Self, ()> { match outer { Event::BalancesEvent(event) => Ok(event), _ => Err(()) } } } } use runtime_primitives::*; fn main() { let democracy_call = democracy::Call::propose { proposal_hash: [7u8; 32] }; println!("Pallet Call: {:?}", democracy_call.encode()); let runtime_call = runtime::RuntimeCall::Democracy(democracy_call); println!("Runtime Call: {:?}", runtime_call.encode()); let staking_error = staking::Error::AlreadyBonded; println!("Pallet Error: {:?}", staking_error.encode()); let runtime_error: DispatchError = staking_error.into(); println!("Runtime Error: {:?}", runtime_error.encode()); let balances_event = balances::Event::Transfer { from: 1, to: 2, amount: 3 }; println!("Pallet Event: {:?}", balances_event.encode()); let runtime_event: runtime::RuntimeEvent = balances_event.into(); println!("Runtime Event: {:?}", runtime_event.encode()); }
Outer Enum Encoding
This now explains how all the different runtime types are generally encoded!
fn main() { let democracy_call = democracy::Call::propose { proposal_hash: [7u8; 32] }; println!("Pallet Call: {:?}", democracy_call.encode()); let runtime_call = runtime::RuntimeCall::Democracy(democracy_call); println!("Runtime Call: {:?}", runtime_call.encode()); let staking_error = staking::Error::AlreadyBonded; println!("Pallet Error: {:?}", staking_error.encode()); let runtime_error: DispatchError = staking_error.into(); println!("Runtime Error: {:?}", runtime_error.encode()); let balances_event = balances::Event::Transfer { from: 1, to: 2, amount: 3 }; println!("Pallet Event: {:?}", balances_event.encode()); let runtime_event: runtime::RuntimeEvent = balances_event.into(); println!("Runtime Event: {:?}", runtime_event.encode()); }
Pallet Call: [0, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7]
Runtime Call: [1, 0, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7]
Pallet Error: [2]
Runtime Error: [1, 2, 2]
Pallet Event: [0, 1, 0, 2, 0, 3, 0, 0, 0]
Runtime Event: [0, 0, 1, 0, 2, 0, 3, 0, 0, 0]
Real Runtime
This was directly added to substrate/bin/node-template/runtime/src/lib.rs:
#![allow(unused)] fn main() { #[test] fn outer_enum_tests() { use sp_runtime::{DispatchError, MultiAddress}; use sp_core::crypto::AccountId32; use codec::Encode; let balances_call = pallet_balances::Call::<Runtime>::transfer { dest: MultiAddress::Address32([1u8; 32]), value: 12345 }; println!("Pallet Call: {:?}", balances_call.encode()); let runtime_call = crate::RuntimeCall::Balances(balances_call); println!("Runtime Call: {:?}", runtime_call.encode()); let balances_error = pallet_balances::Error::<Runtime>::InsufficientBalance; println!("Pallet Error: {:?}", balances_error.encode()); let runtime_error: DispatchError = balances_error.into(); println!("Runtime Error: {:?}", runtime_error.encode()); let balances_event = pallet_balances::Event::<Runtime>::Transfer { from: AccountId32::new([2u8; 32]), to: AccountId32::new([3u8; 32]), amount: 12345 }; println!("Pallet Event: {:?}", balances_event.encode()); let runtime_event: crate::RuntimeEvent = balances_event.into(); println!("Runtime Event: {:?}", runtime_event.encode()); } }
Real Runtime Output
Pallet Call: [0, 3, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 229, 192]
Runtime Call: [5, 0, 3, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 229, 192]
Pallet Error: [2]
Runtime Error: [3, 5, 2, 0, 0, 0]
Pallet Event: [2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 57, 48, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Runtime Event: [5, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 57, 48, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Everything is just like our FRAME-less mock, but the types are more complex.
Using Outer Enums
The path for using outer enums can be a bit confusing.
-
The types which compose the outer enum come from pallets.
-
They are aggregated in the runtime.
-
They can be passed BACK to the pallets and used in pallet logic through associated types.
System Aggregated Associated Types
You can see these "aggregate" types are associated types in FRAME System.
#![allow(unused)] fn main() { /// System configuration trait. Implemented by runtime. #[pallet::config] #[pallet::disable_frame_system_supertrait_check] pub trait Config: 'static + Eq + Clone { /// The `RuntimeOrigin` type used by dispatchable calls. type RuntimeOrigin: Into<Result<RawOrigin<Self::AccountId>, Self::RuntimeOrigin>> + From<RawOrigin<Self::AccountId>> + Clone + OriginTrait<Call = Self::RuntimeCall>; /// The aggregated `RuntimeCall` type. type RuntimeCall: Parameter + Dispatchable<RuntimeOrigin = Self::RuntimeOrigin> + Debug + From<Call<Self>>; /// The aggregated event type of the runtime. type RuntimeEvent: Parameter + Member + From<Event<Self>> + Debug + IsType<<Self as frame_system::Config>::RuntimeEvent>; // -- snip -- } }
Pallet Event
You can now see why we need to add an Event associated type to each pallet which uses events:
#![allow(unused)] fn main() { /// Configure the pallet by specifying the parameters and types on which it depends. #[pallet::config] pub trait Config: frame_system::Config { /// Because this pallet emits events, it depends on the runtime's definition of an event. type RuntimeEvent: From<Event<Self>> + IsType<<Self as frame_system::Config>::RuntimeEvent>; } }
Questions
Construct Runtime
How to use the slides - Full screen (new tab)
construct_runtime! and Testing 🔨
Part 1: Runtime Construction

Pallet <=> Runtime
A runtime is really ✌️ things:
- A struct that implements
Configof all pallets. - A type that helps
ExecutiveimplementRuntimeApis.
---v
Pallet <=> Runtime
We build a runtime, using construct_runtime, typically twice:
- Per pallet, there is a mock runtime.
- A real runtime elsewhere.
Note:
Benchmarking can then use both of these runtimes.
construct_runtime: Runtime type
#![allow(unused)] fn main() { frame_support::construct_runtime!( pub struct Runtime { System: frame_system, Timestamp: pallet_timestamp, Balances: pallet_balances, Aura: pallet_aura, Dpos: pallet_dpos, } ); }
---v
Runtime type
- It implements A LOT OF STUFF!
- But most importantly, the
Configtrait of all of your pallets 🫵🏻.
#![allow(unused)] fn main() { impl frame_system::Config for Runtime { .. } impl pallet_timestamp::Config for Runtime { .. } impl pallet_dpos::Config for Runtime { .. } }
---v
<T: Config> ==> Runtime
Anywhere in your pallet code that you have
<T: Config>can now be replaced withRuntime.
#![allow(unused)] fn main() { // a normal pub function defined in frame_system::Pallet::<Runtime>::block_number(); // a storage getter of a map. frame_system::Pallet::<Runtime>::account(42u32); // A storage type. frame_system::Account::<Runtime>::get(42u32); }
construct_runtime: Pallet List
#![allow(unused)] fn main() { frame_support::construct_runtime!( pub struct Runtime { System: frame_system, Timestamp: pallet_timestamp, Balances: pallet_balances, Aura: pallet_aura, Dpos: pallet_dpos, <NameYouChoose>: path_to_crate, } ); }
---v
Pallet List
- Crucially, under the hood, this generates:
#![allow(unused)] fn main() { type System = frame_system::Pallet<Runtime>; type Balances = pallet_balances::Pallet<Runtime>; .. type DPos = pallet_dpos::Pallet<Runtime>; }
- Recall that
Runtimeimplements<T: Config>of all pallets.
---v
Pallet List
#![allow(unused)] fn main() { frame_system::Pallet::<Runtime>::block_number(); // 🤮 System::block_number(); // 🥳 frame_system::Pallet::<Runtime>::account(42u32); // 🤮 System::account(42u32); // 🥳 }
---v
Pallet List
- Next crucial piece of information that is generated is:
#![allow(unused)] fn main() { type AllPallets = (System, Balances, ..., Dpos); }
- This is used in
Executiveto dispatch pallet hooks.
#![allow(unused)] fn main() { <AllPallets as OnInitialize>::on_initialize(); <AllPallets as OnInitialize>::on_finalize(); }
Notes:
Question: What will be the order of fn on_initialize()?
There's also type AllPalletsWithoutSystem and some other variants that are no longer
---v
Pallet List + Outer Enums
-
Generates some outer types:
RuntimeCallRuntimeEventRuntimeOriginRuntimeGenesisConfig
Notes:
See the lecture on individual item, and the "Outer Enum" lecture.
---v
Pallet List: RuntimeCall Example
#![allow(unused)] fn main() { // somewhere in your pallet, called `my_pallet` #[pallet::call] impl<T: Config> Pallet<T> { fn transfer(origin: OriginFor<T>, from: T::AccountId, to: T::AccountId, amount: u128); fn update_runtime(origin: OriginFor<T>, new_code: Vec<u8>); } }
#![allow(unused)] fn main() { // expanded in your pallet enum Call { transfer { from: T::AccountId, to: T::AccountId, amount: u128 }, update_runtime { new_code: Vec<u8> }, } }
#![allow(unused)] fn main() { // in your outer runtime enum RuntimeCall { System(frame_system::Call), MyPallet(my_pallet::Call), } }
---v
Pallet List: Pallet Parts
#![allow(unused)] fn main() { frame_support::construct_runtime!( pub struct Runtime { System: frame_system::{Pallet, Call, Config, Storage, Event<T>}, Balances: pallet_balances::{Pallet, Call, Storage, Config<T>, Event<T>}, Dpos: pallet_dpos, } ); }
- Omitting them will exclude them from the metadata, or the "outer/runtime types"
---v
Pallet List: Pallet Index
#![allow(unused)] fn main() { frame_support::construct_runtime!( pub struct Runtime { System: frame_system::{Pallet, Call, Config, Storage, Event<T>} = 1, Balances: pallet_balances = 0, Dpos: pallet_dpos = 2, } ); }
construct_runtime: Final Thoughts
- Order in the
construct_runtimematters! - Recall
integrity_test()is called uponconstruct_runtime.
test mock::__construct_runtime_integrity_test::runtime_integrity_tests ... ok
---v
Preview
Of the next potential syntax:
#![allow(unused)] fn main() { #[frame::construct_runtime] mod runtime { #[frame::runtime] pub struct Runtime; #[frame::executive] pub struct Executive; #[frame::pallets] #[derive(RuntimeGenesisConfig, RuntimeCall, RuntimeOrigin)] pub type AllPallets = ( System = frame_system = 0, BalancesFoo = pallet_balances = 1, BalancesBar = pallet_balances = 2, Staking = pallet_staking = 42, ); } }
Notes:
See: https://github.com/paritytech/polkadot-sdk/issues/232
Part 2: Testing
Testing and Mocks
A test requires a mock runtime, so we need to do a full construct_runtime 😱
.. but luckily, most types can be mocked 😮💨
---v
Testing and Mocks
u32account id.u128balance.u32block number.- ...
Testing: Get<_>
- Next, we want to supply some value to those
Get<_>associated types.
#![allow(unused)] fn main() { #[pallet::config] pub trait Config: frame_system::Config { type MaxVoters: Get<u32>; } }
---v
Testing: Get<_>
#![allow(unused)] fn main() { parameter_types! { pub const MyMaxVoters: u32 = 16; } }
#![allow(unused)] fn main() { impl pallet_template::Config for Runtime { type MaxVoters = MyMaxVoters; } }
---v
Testing: Get<_>
- Or, if your value is always constant:
#![allow(unused)] fn main() { impl pallet_dpos::Config for Runtime { type MaxVoters = frame_support::traits::ConstU32<16>; } }
---v
Testing: Get<_>
- Or, if you want to torture yourself:
#![allow(unused)] fn main() { pub struct MyMaxVoters; impl Get<u32> for MyMaxVoters { fn get() -> u32 { 100 } } impl pallet_dpos::Config for Runtime { type MaxVoters = MyMaxVoters; } }
Testing: Genesis and Builder
- Next, if you want to feed some data into your pallet's genesis state, we must first setup the genesis config correctly.
#![allow(unused)] fn main() { #[pallet::genesis_config] #[derive(frame_support::DefaultNoBound)] pub struct GenesisConfig<T: Config> { pub voters: Vec<(T::AccountId, Option<Vote>)>, } #[pallet::genesis_build] impl<T: Config> BuildGenesisConfig for GenesisConfig<T> { fn build(&self) { for (voter, maybe_vote) in &self.voters { // do stuff. } } } }
---v
Testing and Mocks: Genesis and Builder
- Then, we build a builder pattern to construct the genesis config.
#![allow(unused)] fn main() { #[derive(Default)] pub struct Builder { pub voters: Vec<(u64, Option<Vote>)>, } }
#![allow(unused)] fn main() { impl Builder { pub fn add_voter(mut self, who: u64) -> Self { self.voters.push((who, None)); self } } }
---v
Testing and Mocks: Genesis and Builder
- Finally:
#![allow(unused)] fn main() { impl Builder { pub fn build(self) -> TestExternalities { let system = frame_system::GenesisConfig::<Runtime>::default(); let template_module = crate::GenesisConfig { voters: self.voters, ..Default::default() }; RuntimeGenesisConfig { system, template_module }.build_storage().unwrap().into() } pub fn build_and_execute(self, f: impl FnOnce()) { let mut ext = self.build(); ext.execute_with(f); // any post checks can come here. } } }
---v
Testing and Mocks
- Finally, this allows you to write a test like this:
#![allow(unused)] fn main() { #[test] fn test_stuff() { let mut ext = Builder::default() .add_voter_with_vote(2, Vote::Aye) .add_voter(3) build_and_execute(|| { // do stuff }); } }
Testing: static parameter_types!
- What if you want to change that
MyMaxVoters?
#![allow(unused)] fn main() { parameter_types! { pub static MyMaxVoters: u32 = 100; } }
#![allow(unused)] fn main() { MyMaxVoters::set(200); MyMaxVoters::get(); }
Test ing: Progressing Blocks
- Often times, in your test, you want mimic the progression of an empty block.
- De-nada! We can fake everything in tests 🤠
---v
Progressing Blocks
#![allow(unused)] fn main() { pub fn next_block() { let now = System::block_number(); Dpos::on_finalize(now); System::on_finalize(now); System::set_block_number(now + 1); System::on_initialize(now + 1) Dpos::on_initialize(now + 1); } }
---v
Progressing Blocks
#![allow(unused)] fn main() { pub fn next_block() { let now = System::block_number(); AllPallets::on_finalize(now); System::set_block_number(now + 1); AllPallets::on_initialize(now + 1) } }
---v
Progressing Blocks
#![allow(unused)] fn main() { ```rust #[test] fn test() { let mut ext = Builder::default() .add_validator(1) .set_minimum_delegation(200) .build(); ext.execute_with(|| { // initial stuff next_block(); // dispatch some call assert!(some_condition); next_block(); // repeat.. }); } }
---
## Additional Resources 😋
> Check speaker notes (click "s" 😉)
Notes:
- This PR was actually an outcome Cambridge PBA: <https://github.com/paritytech/substrate/pull/11932>
- <https://github.com/paritytech/substrate/pull/11818>
- <https://github.com/paritytech/substrate/pull/10043>
- On usage of macros un Substrate: <https://github.com/paritytech/substrate/issues/12331>
- Discussion on advance testing: <https://forum.polkadot.network/t/testing-complex-frame-pallets-discussion-tools/356>
- Reserve topic: Reading events.
- Reserve-topic: try-state.
### Original Lecture Script
this is your bridge from a pallet into a runtime.
a runtime amalgamator is composed of the following:
1. all pallet's `Config` implemented by a `struct Runtime`;
1. construct `Executive` and use it to implement all the runtime APIs
1. Optionally, some boilerplate to setup benchmarking.
1. invoke `construct_runtime!`.
1. Alias for each pallet.
The `construct_runtime!` itself does a few things under the hood:
1. crate `struct Runtime`.
1. amalgamate `enum RuntimeCall`; // passed inwards to some pallets that want to store calls.
1. amalgamate `enum RuntimeEvent`; // passed inwards to all pallets.
1. amalgamate `enum RuntimeOrigin` (this is a fixed struct, not an amalgamation);
1. Create a very important type alias:
- `type AllPallets` / `type AllPalletsWithoutSystem`
1. run `integrity_test()`.
> Note that there is no such thing as `RuntimeError`. Errors are not amalgamated, they just are. This should be in the error lecture.
- Ordering in `construct_runtime` matters.
- Pallet parts can be optional in `construct_runtime!`.
Benchmarking
How to use the slides - Full screen (new tab)
FRAME Benchmarking
Lesson 1
Overview
- Quick Recap of Weights
- Deep Dive Into Benchmarking
Blockchains are Limited
Blockchain systems are extremely limited environments.
Limited in:
- Execution Time / Block Time
- Available Storage
- Available Memory
- Network Bandwidth
- etc...
Performance vs Centralization
Nodes are expected to be decentralized and distributed.
Increasing the system requirements can potentially lead to centralization in who can afford to run that hardware, and where such hardware may be available.
Why do we need benchmarking?
Benchmarking ensures that when users interact with our Blockchain, they are not using resources beyond what is available and expected for our network.
What is Weight?
Weight is a general concept used to track consumption of limited blockchain resources.
What is Weight in Substrate?
We currently track just two main limitations:
- Execution Time on "Reference Hardware"
- Size of Data Required to Create a Merkle Proof
#![allow(unused)] fn main() { pub struct Weight { /// The weight of computational time used based on some reference hardware. ref_time: u64, /// The weight of storage space used by proof of validity. proof_size: u64, } }
This was already expanded once, and could be expanded in the future.
Weight limits are specific to each blockchain.
- 1 second of compute on different computers allows for different amounts of computation.
- Weights of your blockchain will evolve over time.
- Higher hardware requirements will result in a more performant blockchain (i.e. TXs per second), but will limit the kinds of validators that can safely participate in your network.
- Proof size limitations can be relevant for parachains, but ignored for solo-chains.
What can affect relative Weight?
- Processor
- Memory
- Hard Drive
- HDD vs. SSD vs. NVME
- Operating System
- Drivers
- Rust Compiler
- Runtime Execution Engine
- compiled vs. interpreted
- Database
- RocksDB vs. ParityDB vs. ?
- Merkle trie / storage format
- and more!
Block Import Weight Breakdown

The Benchmarking Framework
The Benchmarking Plan
- Use empirical measurements of the runtime to determine the time and space it takes to execute extrinsics and other runtime logic.
- Run benchmarks using worst case scenario conditions.
- Primary goal is to keep the runtime safe.
- Secondary goal is to be as accurate as possible to maximize throughput.

The #[benchmarks] Macro
#![allow(unused)] fn main() { #[benchmarks] mod benchmarks { use super::*; #[benchmark] fn benchmark_name() { /* setup initial state */ /* execute extrinsic or function */ #[extrinsic_call] extrinsic_name(); /* verify final state */ assert!(true) } } }
Multiple Linear Regression Analysis

- We require that no functions in Substrate have superlinear complexity.
- Ordinary least squared linear regression.
- linregress crate
- Supports multiple linear coefficients.
- Y = Ax + By + Cz + k
- For constant time functions, we simply use the median value.
The benchmark CLI
Compile your node with --features runtime-benchmarks.
➜ ~ substrate benchmark --help
Sub-commands concerned with benchmarking.
The pallet benchmarking moved to the `pallet` sub-command
Usage: polkadot benchmark <COMMAND>
Commands:
pallet Benchmark the extrinsic weight of FRAME Pallets
storage Benchmark the storage speed of a chain snapshot
overhead Benchmark the execution overhead per-block and per-extrinsic
block Benchmark the execution time of historic blocks
machine Command to benchmark the hardware
extrinsic Benchmark the execution time of different extrinsics
help Print this message or the help of the given subcommand(s)
Options:
-h, --help Print help information
-V, --version Print version information
pallet Subcommand
- Benchmark the weight of functions within pallets.
- Any arbitrary code can be benchmarked.
- Outputs Autogenerated Weight files.
#![allow(unused)] fn main() { pub trait WeightInfo { fn transfer() -> Weight; fn transfer_keep_alive() -> Weight; fn set_balance_creating() -> Weight; fn set_balance_killing() -> Weight; fn force_transfer() -> Weight; } }
Deep Dive
So let’s walk through the steps of a benchmark!
Reference: frame/benchmarking/src/lib.rs
#![allow(unused)] fn main() { -> fn run_benchmark(...) }
The Benchmarking Process
For each component and repeat:
- Select component to benchmark
- Generate range of values to test (steps)
- Whitelist known DB keys
- Setup benchmarking state
- Commit state to the DB, clearing cache
- Get system time (start)
- Execute extrinsic / benchmark function
- Get system time (end)
- Count DB reads and writes
- Record Data
Benchmarking Components
- Imagine a function with 3 components
- let x in 1..2;
- let y in 0..5;
- let z in 0..10;
- We set number of steps to 3.
- Vary one component at a time, select high value for the others.
| Δx | Δy | Δy | Δz | Δz | max | |
|---|---|---|---|---|---|---|
| x | 1 | 2 | 2 | 2 | 2 | 2 |
| y | 5 | 0 | 2 | 5 | 5 | 5 |
| z | 10 | 10 | 10 | 0 | 5 | 10 |
Benchmarks Evaluated Over Components

Whitelisted DB Keys
#![allow(unused)] fn main() { /// The current block number being processed. Set by `execute_block`. #[pallet::storage] #[pallet::whitelist_storage] #[pallet::getter(fn block_number)] pub(super) type Number<T: Config> = StorageValue<_, BlockNumberFor<T>, ValueQuery>; }
- Some keys are accessed every block:
- Block Number
- Events
- Total Issuance
- etc…
- We don’t want to count these reads and writes in our benchmarking results.
- Applied to all benchmarks being run.
- This includes a “whitelisted account” provided by FRAME.
Example Benchmark
The Identity Pallet
Identity Pallet
- Identity can have variable amount of information
- Name
- etc…
- Identity can be judged by a variable amount of registrars.
- Identity can have a two-way link to “sub-identities”
- Other accounts that inherit the identity status of the “super-identity”
Extrinsic: Kill Identity
#![allow(unused)] fn main() { pub fn kill_identity( origin: OriginFor<T>, target: AccountIdLookupOf<T>, ) -> DispatchResultWithPostInfo { T::ForceOrigin::ensure_origin(origin)?; // Figure out who we're meant to be clearing. let target = T::Lookup::lookup(target)?; // Grab their deposit (and check that they have one). let (subs_deposit, sub_ids) = <SubsOf<T>>::take(&target); let id = <IdentityOf<T>>::take(&target).ok_or(Error::<T>::NotNamed)?; let deposit = id.total_deposit() + subs_deposit; for sub in sub_ids.iter() { <SuperOf<T>>::remove(sub); } // Slash their deposit from them. T::Slashed::on_unbalanced(T::Currency::slash_reserved(&target, deposit).0); Self::deposit_event(Event::IdentityKilled { who: target, deposit }); Ok(()) } }
Handling Configurations
kill_identitywill only execute if theForceOriginis calling.
#![allow(unused)] fn main() { T::ForceOrigin::ensure_origin(origin)?; }
- However, this is configurable by the pallet developer.
- Our benchmark needs to always work independent of the configuration.
- We added a special function behind a feature flag:
#![allow(unused)] fn main() { /// Returns an outer origin capable of passing `try_origin` check. /// /// ** Should be used for benchmarking only!!! ** #[cfg(feature = "runtime-benchmarks")] fn successful_origin() -> OuterOrigin; }
External Logic / Hooks
#![allow(unused)] fn main() { // Figure out who we're meant to be clearing. let target = T::Lookup::lookup(target)?; }
- In general, hooks like these are configurable in the runtime.
- Each blockchain will have their own logic, and thus their own weight.
- We run benchmarks against the real runtime, so we get the real results.
- IMPORTANT! You need to be careful that the limitations of these hooks are well understood by the pallet developer and users of your pallet, otherwise, your benchmark will not be accurate.
Deterministic Storage Reads / Writes
#![allow(unused)] fn main() { // Grab their deposit (and check that they have one). let (subs_deposit, sub_ids) = <SubsOf<T>>::take(&target); let id = <IdentityOf<T>>::take(&target).ok_or(Error::<T>::NotNamed)?; }
- 2 storage reads and writes.
- The size of these storage items will depends on:
- Number of Registrars
- Number of Additional Fields
Variable Storage Reads / Writes
#![allow(unused)] fn main() { for sub in sub_ids.iter() { <SuperOf<T>>::remove(sub); } }
enchmarkinghere you store balances!
- What happens with slashed funds is configurable too!
Whitelisted Storage
#![allow(unused)] fn main() { Self::deposit_event(Event::IdentityKilled { who: target, deposit }); }
- We whitelist changes to the Events storage item, so generally this is “free” beyond computation and in-memory DB weight.
Preparing to Write Your Benchmark
-
3 Components
R- number of registrarsS- number of sub-accountsX- number of additional fields
-
Need to:
- Set up account with funds.
- Register an identity with additional fields.
- Set up worst case scenario for registrars and sub-accounts.
- Take into account
ForceOriginto make the call.
Kill Identity Benchmark
#![allow(unused)] fn main() { #[benchmark] fn kill_identity( r: Linear<1, T::MaxRegistrars::get()>, s: Linear<0, T::MaxSubAccounts::get()>, x: Linear<0, T::MaxAdditionalFields::get()>, ) -> Result<(), BenchmarkError> { add_registrars::<T>(r)?; let target: T::AccountId = account("target", 0, SEED); let target_origin: <T as frame_system::Config>::RuntimeOrigin = RawOrigin::Signed(target.clone()).into(); let target_lookup = T::Lookup::unlookup(target.clone()); let _ = T::Currency::make_free_balance_be(&target, BalanceOf::<T>::max_value()); let info = create_identity_info::<T>(x); Identity::<T>::set_identity(target_origin.clone(), Box::new(info.clone()))?; let _ = add_sub_accounts::<T>(&target, s)?; // User requests judgement from all the registrars, and they approve for i in 0..r { let registrar: T::AccountId = account("registrar", i, SEED); let balance_to_use = T::Currency::minimum_balance() * 10u32.into(); let _ = T::Currency::make_free_balance_be(®istrar, balance_to_use); Identity::<T>::request_judgement(target_origin.clone(), i, 10u32.into())?; Identity::<T>::provide_judgement( RawOrigin::Signed(registrar).into(), i, target_lookup.clone(), Judgement::Reasonable, T::Hashing::hash_of(&info), )?; } ensure!(IdentityOf::<T>::contains_key(&target), "Identity not set"); let origin = T::ForceOrigin::successful_origin(); #[extrinsic_call] kill_identity<T::RuntimeOrigin>(origin, target_lookup) ensure!(!IdentityOf::<T>::contains_key(&target), "Identity not removed"); Ok(()) } }
Benchmarking Components
#![allow(unused)] fn main() { fn kill_identity( r: Linear<1, T::MaxRegistrars::get()>, s: Linear<0, T::MaxSubAccounts::get()>, x: Linear<0, T::MaxAdditionalFields::get()>, ) -> Result<(), BenchmarkError> { ... } }
- Our components.
- R = Number of Registrars
- S = Number of Sub-Accounts
- X = Number of Additional Fields on the Identity.
- Note all of these have configurable, known at compile time maxima.
- Part of the pallet configuration trait.
- Runtime logic should enforce these limits.
Set Up Logic
#![allow(unused)] fn main() { add_registrars::<T>(r)?; let target: T::AccountId = account("target", 0, SEED); let target_origin: <T as frame_system::Config>::RuntimeOrigin = RawOrigin::Signed(target.clone()).into(); let target_lookup = T::Lookup::unlookup(target.clone()); let _ = T::Currency::make_free_balance_be(&target, BalanceOf::<T>::max_value()); }
- Adds registrars to the runtime storage.
- Set up an account with the appropriate funds.
- Note this is just like writing runtime tests!
Reusable Setup Functions
#![allow(unused)] fn main() { let info = create_identity_info::<T>(x); Identity::<T>::set_identity(target_origin.clone(), Box::new(info.clone()))?; let _ = add_sub_accounts::<T>(&target, s)?; }
- Using some custom functions defined in the benchmarking file:
- Give that account an Identity with x additional fields.
- Give that Identity
ssub-accounts.
Set Up Worst Case Scenario
#![allow(unused)] fn main() { // User requests judgement from all the registrars, and they approve for i in 0..r { let registrar: T::AccountId = account("registrar", i, SEED); let balance_to_use = T::Currency::minimum_balance() * 10u32.into(); let _ = T::Currency::make_free_balance_be(®istrar, balance_to_use); Identity::<T>::request_judgement(target_origin.clone(), i, 10u32.into())?; Identity::<T>::provide_judgement( RawOrigin::Signed(registrar).into(), i, target_lookup.clone(), Judgement::Reasonable, T::Hashing::hash_of(&info), )?; } }
- Add r registrars.
- Have all of them give a judgement to this identity.
Execute and Verify the Benchmark:
#![allow(unused)] fn main() { ensure!(IdentityOf::<T>::contains_key(&target), "Identity not set"); let origin = T::ForceOrigin::successful_origin(); #[extrinsic_call] kill_identity<T::RuntimeOrigin>(origin, target_lookup) ensure!(!IdentityOf::<T>::contains_key(&target), "Identity not removed"); Ok(()) }
- First ensure statement verifies the “before” state is as we expect.
- We need to use our custom origin.
- Verify block ensures our “final” state is as we expect.
Executing the Benchmark
./target/production/substrate benchmark pallet \
--chain=dev \ # Configurable Chain Spec
--steps=50 \ # Number of steps across component ranges
--repeat=20 \ # Number of times we repeat a benchmark
--pallet=pallet_identity \ # Select the pallet
--extrinsic=* \ # Select the extrinsic(s)
--wasm-execution=compiled \ # Always used `wasm-time`
--heap-pages=4096 \ # Not really needed, adjusts memory
--output=./frame/identity/src/weights.rs \ # Output results into a Rust file
--header=./HEADER-APACHE2 \ # Custom header file to include with template
--template=./.maintain/frame-weight-template.hbs # Handlebar template
Looking at Raw Benchmarking Data
Results: Extrinsic Time vs. # of Registrars
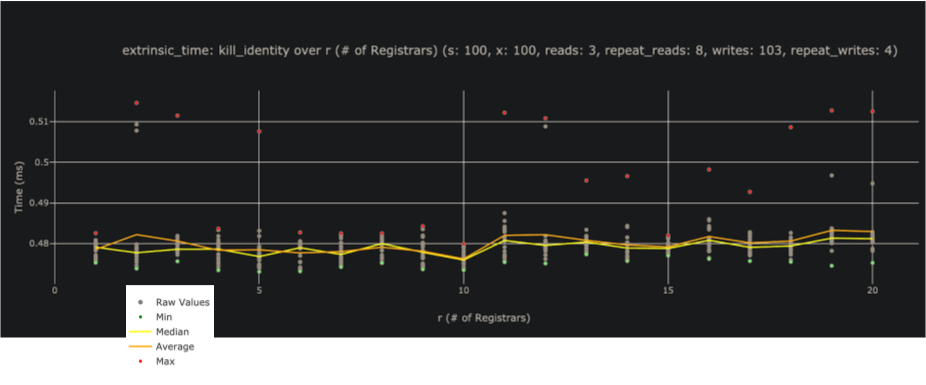
Notes:
Graph source: https://www.shawntabrizi.com/substrate-graph-benchmarks/old/
Results: Extrinsic Time vs. # of Sub-Accounts
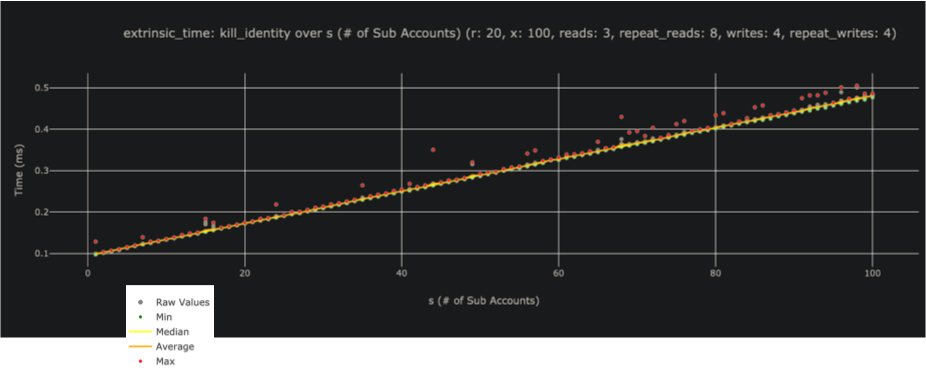
Notes:
Graph source: https://www.shawntabrizi.com/substrate-graph-benchmarks/old/
Results: Extrinsic Time vs. Additional Fields
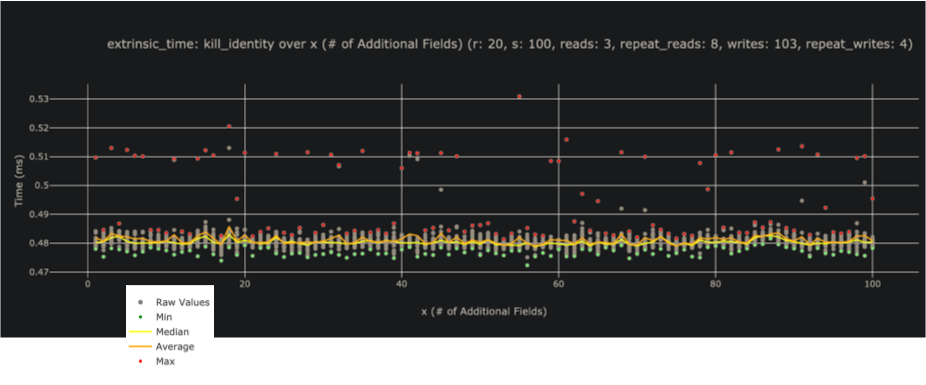
Notes:
Graph source: https://www.shawntabrizi.com/substrate-graph-benchmarks/old/
Result: DB Operations vs. Sub Accounts
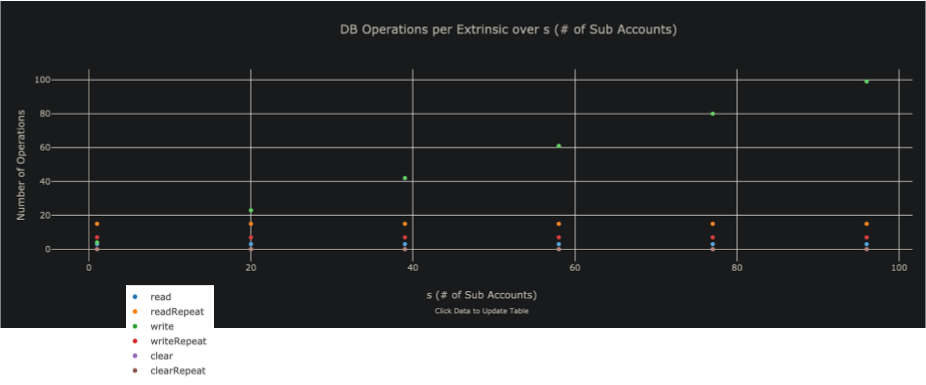
Notes:
Graph source: https://www.shawntabrizi.com/substrate-graph-benchmarks/old/
Final Weight
#![allow(unused)] fn main() { // Storage: Identity SubsOf (r:1 w:1) // Storage: Identity IdentityOf (r:1 w:1) // Storage: System Account (r:1 w:1) // Storage: Identity SuperOf (r:0 w:100) /// The range of component `r` is `[1, 20]`. /// The range of component `s` is `[0, 100]`. /// The range of component `x` is `[0, 100]`. fn kill_identity(r: u32, s: u32, x: u32, ) -> Weight { // Minimum execution time: 68_794 nanoseconds. Weight::from_ref_time(52_114_486 as u64) // Standard Error: 4_808 .saturating_add(Weight::from_ref_time(153_462 as u64).saturating_mul(r as u64)) // Standard Error: 939 .saturating_add(Weight::from_ref_time(1_084_612 as u64).saturating_mul(s as u64)) // Standard Error: 939 .saturating_add(Weight::from_ref_time(170_112 as u64).saturating_mul(x as u64)) .saturating_add(T::DbWeight::get().reads(3 as u64)) .saturating_add(T::DbWeight::get().writes(3 as u64)) .saturating_add(T::DbWeight::get().writes((1 as u64).saturating_mul(s as u64))) } }
WeightInfo Generation
#![allow(unused)] fn main() { /// Weight functions needed for pallet_identity. pub trait WeightInfo { fn add_registrar(r: u32, ) -> Weight; fn set_identity(r: u32, x: u32, ) -> Weight; fn set_subs_new(s: u32, ) -> Weight; fn set_subs_old(p: u32, ) -> Weight; fn clear_identity(r: u32, s: u32, x: u32, ) -> Weight; fn request_judgement(r: u32, x: u32, ) -> Weight; fn cancel_request(r: u32, x: u32, ) -> Weight; fn set_fee(r: u32, ) -> Weight; fn set_account_id(r: u32, ) -> Weight; fn set_fields(r: u32, ) -> Weight; fn provide_judgement(r: u32, x: u32, ) -> Weight; fn kill_identity(r: u32, s: u32, x: u32, ) -> Weight; fn add_sub(s: u32, ) -> Weight; fn rename_sub(s: u32, ) -> Weight; fn remove_sub(s: u32, ) -> Weight; fn quit_sub(s: u32, ) -> Weight; } }
WeightInfo Integration
#![allow(unused)] fn main() { #[pallet::weight(T::WeightInfo::kill_identity( T::MaxRegistrars::get(), // R T::MaxSubAccounts::get(), // S T::MaxAdditionalFields::get(), // X ))] pub fn kill_identity( origin: OriginFor<T>, target: AccountIdLookupOf<T>, ) -> DispatchResultWithPostInfo { // -- snip -- Ok(Some(T::WeightInfo::kill_identity( id.judgements.len() as u32, // R sub_ids.len() as u32, // S id.info.additional.len() as u32, // X )) .into()) } }
Initial Weight
#![allow(unused)] fn main() { #[pallet::weight(T::WeightInfo::kill_identity( T::MaxRegistrars::get(), // R T::MaxSubAccounts::get(), // S T::MaxAdditionalFields::get(), // X ))] }
- Use the WeightInfo function as the weight definition for your function.
- Note that we assume absolute worst case scenario to begin since we cannot know these specific values until we query storage.
Final Weight (Refund)
#![allow(unused)] fn main() { pub fn kill_identity(...) -> DispatchResultWithPostInfo { ... } }
#![allow(unused)] fn main() { Ok(Some(T::WeightInfo::kill_identity( id.judgements.len() as u32, // R sub_ids.len() as u32, // S id.info.additional.len() as u32, // X )) .into()) }
- Then we return the actual weight used at the end!
- We use the same WeightInfo formula, but using the values that we queried from storage as part of executing the extrinsic.
- This only allows you to decrease the final weight. Nothing will happen if you return a bigger weight than the initial weight.
Questions
In another presentation we will cover some of the things we learned while benchmarking, and best practices.
Benchmarking Exercise
Benchmarking
How to use the slides - Full screen (new tab)
FRAME Benchmarking
Lesson 2
Overview
- Databases
- Our Learnings Throughout Development
- Best Practices and Common Patterns
Databases
RocksDB
A Persistent Key-Value Store for Flash and RAM Storage.
- Keys and values are arbitrary byte arrays.
- Fast for a general database.
See: https://rocksdb.org/.
Big project, can be very tricky to configure properly.
Notes:
(also a big part of substrate compilation time).
ParityDB
An Embedded Persistent Key-Value Store Optimized for Blockchain Applications.
- Keys and values are arbitrary byte arrays.
- Designed for efficiently storing Patricia-Merkle trie nodes.
- Mostly Fixed Size Keys.
- Mostly Small Values.
- Uniform Distribution.
- Optimized for read performance.
Notes:
See: <https://github.com/paritytech/parity-db/issues/82
Main point is that paritydb suit the triedb model. Indeed triedb store encoded key by their hash. So we don't need rocksdb indexing, no need to order data. Parity db index its content by hash of key (by default), which makes access faster (hitting entry of two file generally instead of possibly multiple btree indexing node). Iteration on state value is done over the trie structure: having a KVDB with iteration support isn't needed.
Both rocksdb and paritydb uses "Transactions" as "writes done in batches". We typically run a transaction per block (all in memory before), things are fast (that's probably what you meant). In blockchains, writes are typically performed in large batches, when the new block is imported and must be done atomically. See: https://github.com/paritytech/parity-db
Concurrency does not matter in this, paritydb lock access to single writer (no concurrency). Similarly code strive at being simple and avoid redundant feature: no cache in parity db (there is plenty in substrate).
'Quick commit' : all changes are stored in memory on commit , and actual writing in the WriteAheadLog is done in an asynchronous way.
TODO merge with content from https://github.com/paritytech/parity-db/issues/82
ParityDB: Probing Hash Table
ParityDB is implemented as a probing hash table.
- As opposed to a log-structured merge (LSM) tree.
- Used in Apache AsterixDB, Bigtable, HBase, LevelDB, Apache Accumulo, SQLite4, Tarantool, RocksDB, WiredTiger, Apache Cassandra, InfluxDB, ScyllaDB, etc...
- Because we do not require key ordering or iterations for trie operations.
- This means read performance is constant time, versus $O(\log{n})$.
ParityDB: Fixed Size Value Tables
- Each column stores data in a set of 256 value tables, with 255 tables containing entries of certain size range up to 32 KB limit.
#![allow(unused)] fn main() { const SIZES: [u16; SIZE_TIERS - 1] = [ 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 46, 47, 48, 50, 51, 52, 54, 55, 57, 58, 60, 62, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 88, 90, 93, 95, 98, 101, 103, 106, 109, 112, 115, 119, 122, 125, 129, 132, 136, 140, 144, 148, 152, 156, 160, 165, 169, 174, 179, 183, 189, 194, 199, 205, 210, 216, 222, 228, 235, 241, 248, 255, 262, 269, 276, 284, 292, 300, 308, 317, 325, 334, 344, 353, 363, 373, 383, 394, 405, 416, 428, 439, 452, 464, 477, 490, 504, 518, 532, 547, 562, 577, 593, 610, 627, 644, 662, 680, 699, 718, 738, 758, 779, 801, 823, 846, 869, 893, 918, 943, 969, 996, 1024, 1052, 1081, 1111, 1142, 1174, 1206, 1239, 1274, 1309, 1345, 1382, 1421, 1460, 1500, 1542, 1584, 1628, 1673, 1720, 1767, 1816, 1866, 1918, 1971, 2025, 2082, 2139, 2198, 2259, 2322, 2386, 2452, 2520, 2589, 2661, 2735, 2810, 2888, 2968, 3050, 3134, 3221, 3310, 3402, 3496, 3593, 3692, 3794, 3899, 4007, 4118, 4232, 4349, 4469, 4593, 4720, 4850, 4984, 5122, 5264, 5410, 5559, 5713, 5871, 6034, 6200, 6372, 6548, 6729, 6916, 7107, 7303, 7506, 7713, 7927, 8146, 8371, 8603, 8841, 9085, 9337, 9595, 9860, 10133, 10413, 10702, 10998, 11302, 11614, 11936, 12266, 12605, 12954, 13312, 13681, 14059, 14448, 14848, 15258, 15681, 16114, 16560, 17018, 17489, 17973, 18470, 18981, 19506, 20046, 20600, 21170, 21756, 22358, 22976, 23612, 24265, 24936, 25626, 26335, 27064, 27812, 28582, 29372, 30185, 31020, 31878, 32760, ]; }
- The last 256th value table size stores entries that are over 32 KB split into multiple parts.
ParityDB: Fixed Size Value Tables
- More than 99% of trie nodes are less than 32kb in size.
- Small values only require 2 reads: One index lookup and one value table lookup.
- Values over 32kb may require multiple value table reads, but these are rare.
- Helps minimize unused disk space.
- For example, if you store a 670 byte value, it won't fit into 662 bucket, but will into 680 bucket, wasting only 10 bytes of space.
Notes:
That fact that most values are small allows us to address each value by its index and have a simple mechanism for reusing the space of deleted values without fragmentation and periodic garbage collection.
ParityDB: Asynchronous Writes
- Parity DB API exposes synchronous functions, but underlying IO is async.
- The
commitfunction adds the database transaction to the write queue, updates the commit overlay, and returns as quickly as possible. - The actual writing happens in the background.
- The commit overlay allows the block import pipeline to start executing the next block while the database is still writing changes for the previous block.
Practical Benchmarks and Considerations
Let's now step away from concepts and talk about cold hard data.
Common Runtime Data Size and Performance
- Most runtime values are 80 bytes, which are user accounts.
- Of course, this would depend on your chain's logic.
Notes:
Impact of keys size is slightly bigger encoded node. Since eth scaling issue, we usually focus on state nodes. Other content access can be interesting to audit enhance though (with paritydb).
See more details here:
RocksDB vs ParityDB Performance
At 32 KB, performance decreases for each additional 4 KB.
RocksDB Inconsistency
When doing benchmarking, we saw some really bizarre, but reproducible problems with RocksDB.
Things we tried
Things we learned
Isolating DB Benchmarks (PR #5586)
We tried…
To benchmark the entire extrinsic, including the weight of DB operations directly in the benchmark. We wanted to:
- Populate the DB to be “full”
- Flush the DB cache
- Run the benchmark
We learned…
RocksDB was too inconsistent to give reproducible results, and really slow to populate. So we use an in-memory DB for benchmarking.
Fixing Nonlinear Events (PR #5795)
We tried…
Executing a whole block, increasing the number of txs in each block. We expected to get linear growth of execution time, but in fact it was superlinear!
We learned…
Each time we appended a new event, we were passing the growing event object over the Wasm barrier.
We updated the append api so only new data is pushed.
Enabling Weight Refunds (PR #5584)
We tried…
To assign weights to all extrinsics for the absolute worst case scenario in order to be safe.
In many cases, we cannot know accurately what the weight of the extrinsic will be without reading storage… and this is not allowed!
We learned…
That many extrinsics have a worst case weight much different than their average weight.
So we allow extrinsics to return the actual weight consumed and refund that weight and any weight fees.
Customizable Weight Info (PR #6575)
We tried…
To record weight information and benchmarking results directly in the pallet.
We learned…
This was hard to update, not customizable, and not accurate for custom pallet configurations.
So we moved the weight definition into customizable associated types configured in the runtime trait.
#![allow(unused)] fn main() { #[weight = 45_000_000 + T::DbWeight::get().reads_writes(1,1)] }
turned into...
#![allow(unused)] fn main() { #[weight = T::WeightInfo::transfer()] }
Inherited Call Weight Syntax (PR #13932)
#![allow(unused)] fn main() { #[pallet::call(weight(<T as Config>::WeightInfo))] impl<T: Config> Pallet<T> { pub fn create( ... }
Custom Benchmark Returns / Errors (PR #9517)
#![allow(unused)] fn main() { override_benchmark { let b in 1 .. 1000; let caller = account::<T::AccountId>("caller", 0, 0); }: { Err(BenchmarkError::Override( BenchmarkResult { extrinsic_time: 1_234_567_890, reads: 1337, writes: 420, ..Default::default() } ))?; } }
Negative Y Intercept Handling (PR #11806)
Multi-Dimensional Weight (Issue #12176)
#![allow(unused)] fn main() { #[derive( Encode, Decode, MaxEncodedLen, TypeInfo, Eq, PartialEq, Copy, Clone, RuntimeDebug, Default, )] #[cfg_attr(feature = "serde", derive(Serialize, Deserialize))] pub struct Weight { #[codec(compact)] /// The weight of computational time used based on some reference hardware. ref_time: u64, #[codec(compact)] /// The weight of storage space used by proof of validity. proof_size: u64, } }
Best Practices & Common Patterns
Initial Weight Calculation Must Be Lightweight
- In the TX queue, we need to know the weight to see if it would fit in the block.
- This weight calculation must be lightweight!
- No storage reads!
Example:
- Transfer Base: ~50 µs
- Storage Read: ~25 µs
Set Bounds and Assume the Worst!
- Add a configuration trait that sets an upper bound to some item, and in weights, initially assume this worst case scenario.
- During the extrinsic, find the actual length/size of the item, and refund the weight to be the actual amount used.
Separate Benchmarks Per Logical Path
- It may not be clear which logical path in a function is the “worst case scenario”.
- Create a benchmark for each logical path your function could take.
- Ensure each benchmark is testing the worst case scenario of that path.
Comparison Operators in the Weight Definition
#![allow(unused)] fn main() { #[pallet::weight( T::WeightInfo::path_a() .max(T::WeightInfo::path_b()) .max(T::WeightInfo::path_c()) )] }
Keep Extrinsics Simple
- The more complex your extrinsic logic, the harder it will be to accurately weigh.
- This leads to larger up-front weights, potentially higher tx fees, and less efficient block packing.
Use Multiple Simple Extrinsics
- Take advantage of UI/UX, batch calls, and similar downstream tools to simplify extrinsic logic.
Example:
- Vote and Close Vote (“last vote”) are separate extrinsics.
Minimize Usage of On Finalize
on_finalizeis the last thing to happen in a block, and must execute for the block to be successful.- Variable weight needs at can lead to overweight blocks.

Transition Logic and Weights to On Initialize
on_initializehappens at the beginning of the block, before extrinsics.- The number of extrinsics can be adjusted to support what is available.
- Weight for
on_finalizeshould be wrapped into on_initialize weight or extrinsic weight.
Understand Limitations of Pallet Hooks
- A powerful feature of Substrate is to allow the runtime configuration to implement pallet configuration traits.
- However, it is easy for this feature to be abused and make benchmarking inaccurate.
Keep Hooks Constant Time
- Example: Balances hook for account creation and account killed.
- Benchmarking has no idea how to properly set up your state to test for any arbitrary hook.
- So you must keep hooks constant time, unless specified by the pallet otherwise.
Questions
Benchmarking Activity
Practice with FRAME benchmarking.
📥 Clone to start: Benchmarking Activity
See the README included in the repository for further instructions.
Deep Dive
How to use the slides - Full screen (new tab)
FRAME Deep Dive
---v
Agenda
Recall the following figure:

Notes:
Without frame, there is the runtime and there is the client, and an API that sits in between.
---v
Agenda
By the end of this lecture, you will fully understand this figure.

Expanding A Pallet
-
Grab a simple pallet code, and expand it.
-
Palletimplements the transactions as public functions. -
PalletimplementsHooks, and some equivalents likeOnInitialize. -
enum Callthat has in itself is just an encoding of the transaction's data -
and implements
UnfilteredDispatchable(which just forward the call back toPallet)
---v
Expanding A Pallet
- Make sure you understand why these 3 are the same!
#![allow(unused)] fn main() { let origin = ..; // function call Pallet::<T>::set_value(origin, 10); // dispatch Call::<T>::set_value(10).dispatch_bypass_filter(origin); // fully qualified syntax. <Call<T> as UnfilteredDispatch>::dispatch_bypass_filter(Call::<T>::set_value(10), origin); }
construct_runtime! and Runtime Amalgamator.
- Now, let's look at a minimal runtime amalgamator.
---v
construct_runtime! and Runtime Amalgamator.
- struct
Runtime - implements the
Configtrait of all pallets. - implements all of the runtime APIs as functions.
type System,type SimplePallet.AllPalletsWithSystemetc.- and recall that all pallets implement things like
Hooks,OnInitialize, and all of these traits are tuple-able.
- and recall that all pallets implement things like
- enum
RuntimeCall - enum
RuntimeEvent,GenesisConfig, etc. but we don't have them here.
Executive
-
This part is somewhat optional to know in advance, but I want you to re-visit it in a week and then understand it all.
-
I present to you, Executive struct:
#![allow(unused)] fn main() { pub struct Executive< System, Block, Context, UnsignedValidator, AllPalletsWithSystem, OnRuntimeUpgrade = (), >(..); }
---v
Expanding The Generic Types.
#![allow(unused)] fn main() { impl< // System config, we know this now. System: frame_system::Config, // The block type. Block: sp_runtime::traits::Block<Header = System::Header, Hash = System::Hash>, // Something that has all the hooks. We don't know anything else about pallets here. AllPalletsWithSystem: OnRuntimeUpgrade + OnInitialize<System::BlockNumber> + OnIdle<System::BlockNumber> + OnFinalize<System::BlockNumber> + OffchainWorker<System::BlockNumber>, COnRuntimeUpgrade: OnRuntimeUpgrade, > Executive<System, Block, Context, UnsignedValidator, AllPalletsWithSystem, COnRuntimeUpgrade> where // This is the juicy party, and we have to learn more sp_runtime traits to follow. Block::Extrinsic: Checkable, <Block::Extrinsic as Checkable>::Checked: Applyable <<Block::Extrinsic as Checkable>::Checked as Applyable>::Call: Dispatchable<_>, {...} }
---v
Block::Extrinsic: Checkable
- Who implements
Checkable? - That's right, the
generic::UncheckedExtrinsicthat we indeed used asBlock::Extrinsicin the top level runtime. Recall:
#![allow(unused)] fn main() { type UncheckedExtrinsic = generic::UncheckedExtrinsic<_, _, _, _>; type Header = .. type Block = generic::Block<Header, UncheckedExtrinsic>; type Executive = frame_executive::Executive<_, Block, ...>; }
---v
What Does Checkable<_> Do?
- Signature verification!
#![allow(unused)] fn main() { impl Checkable<_> for UncheckedExtrinsic<_, _, _, _> { // this is the output type. type Checked = CheckedExtrinsic<AccountId, Call, Extra>; fn check(self, lookup: &Lookup) -> Result<Self::Checked, TransactionValidityError> { .. } } }
---v
<Block::Extrinsic as Checkable>::Checked: Applyable
UncheckedExtrinsic::CheckedisCheckedExtrinsic.- And it surely does implement
Applyable.
---v
What Does Applyable<_> Do?
- TLDR:
Ok(self.call.dispatch(maybe_who.into()))
---v
Lastly: <<Block::Extrinsic as Checkable>::Checked as Applyable>::Call: Dispatchable
- And guess who implemented
Dispatchable, which we already looked at! - The
enum Callthat we had in our expanded file!
---v
Circling Back..
So, to recap:
#![allow(unused)] fn main() { struct Runtime; impl frame_system::Config for Runtime {} impl simple_pallet::Config for Runtime {} enum Call { System(frame_system::Call<Runtime>), SimplePallet(simple_pallet::Call<Runtime>), } impl Dispatchable for Call { fn dispatch(self, origin: _) -> Result<_, _> { match self { Call::System(system_call) => system_call.dispatch(), Call::SimplePallet(simple_pallet_call) => system_pallet_call.dispatch(), } } } struct UncheckedExtrinsic { function: Call, signature: Option<_>, } type Executive = Executive<_, UncheckedExtrinsic, ...>; // let unchecked = UncheckedExtrinsic::new(); let checked = unchecked.check(); let _ = checked.apply(); }
Signed Extensions
How to use the slides - Full screen (new tab)
Signed Extensions
---v
- In this lecture you will learn above one of the most advance FRAME concepts, Signed Extensions.
- They allow for a multitude of custom features to be added to FRAME transactions.
History
- Signed Extensions originally where added to implement tipping in a reasonable way.
- Originally, your dumb instructor (@kianenigma) had the idea of hard-coding it into the
UncheckedExtrinsic, until @gavofyork jumped in with the idea of signed extensions.
Tipped Transaction Type. by kianenigma · Pull Request #2930 · paritytech/substrate > Extensible transactions (and tips) by gavofyork · Pull Request #3102 · paritytech/substrate
---v
History
- In essence, they are a generic way to extend the transaction. Moreover, if they have additional payload, it is signed, therefore
SignedExtension.
Anatomy
A signed extension can be either combination of the following things:
- Some additional data that is attached to the transaction.
- The tip!
- Some hooks that are executed before and after the transaction is executed.
- Before each transaction is executed, it must pay its fee upfront.
- Perhaps refund the fee partially 🤑.
---v
Anatomy
- Some additional validation logic that is used to validate the transaction, and give feedback to the pool.
- Set priority of transaction priority based on some metric!
- Some additional data that must be present in the signed payload of each transaction.
- Data that the sender has, the chain also has, it is not communicated itself, but it is part of the signature payload.
- Spec version and genesis hash is part of all transaction's signature payload!
---v
Anatomy: Let's Peek at the Trait
#![allow(unused)] fn main() { pub trait SignedExtension: Codec + Debug + Sync + Send + Clone + Eq + PartialEq + StaticTypeInfo { fn additional_signed(&self) -> Result<Self::AdditionalSigned, TransactionValidityError>; fn validate(..) -> TransactionValidity; fn validate_unsigned(..) -> TransactionValidity; fn pre_dispatch() -> Result<Self::Pre, TransactionValidityError>; fn pre_dispatch_unsigned() -> Result<(), TransactionValidityError>; fn post_dispatch() -> Result<(), TransactionValidityError>; } }
Grouping Signed Extension
-
Is also a signed extension itself!
-
You can look at the implementation yourself.. but the TLDR is:
-
Main takeaways:
type AdditionalSigned = (SE1::AdditionalSigned, SE2::AdditionalSigned),- all of hooks:
- Executes each individually, combines results
Notes:
TODO: how TransactionValidity is combined_with is super important here, but probably something to cover more in 4.3 and recap here.
---v
Usage In The Runtime
- Each runtime has a bunch of signed extensions. They can be grouped as a tuple
#![allow(unused)] fn main() { pub type SignedExtra = ( frame_system::CheckNonZeroSender<Runtime>, frame_system::CheckSpecVersion<Runtime>, frame_system::CheckTxVersion<Runtime>, frame_system::CheckGenesis<Runtime>, pallet_asset_tx_payment::ChargeAssetTxPayment<Runtime>, ); type UncheckedExtrinsic = generic::UncheckedExtrinsic<Address, Call, Signature, SignedExtra>; }
- Signed extensions might originate from a pallet, but are applied to ALL EXTRINSICS 😮💨!
Notes:
We will get to this later as well, but recall that SignedExtensions are not a FRAME/Pallet concept per se. FRAME just implements them. This also implies that everything regarding signed extensions is applied to all transactions, throughout the runtime.
Encoding
#![allow(unused)] fn main() { struct Foo(u32, u32); impl SignedExtension for Foo { type AdditionalSigned = u32; fn additional_signed(&self) -> Result<Self::AdditionalSigned, TransactionValidityError> { Ok(42u32) } } pub struct UncheckedExtrinsic<Address, Call, Signature, (Foo)> { pub signature: Option<(Address, Signature, Extra)>, pub function: Call, } }
- 2 u32 are decoded as,
42u32is expected to be in the signature payload.
Notes:
Here's the check function of CheckedExtrinsic extensively documented to demonstrate this:
#![allow(unused)] fn main() { // SignedPayload::new pub fn new(call: Call, extra: Extra) -> Result<Self, TransactionValidityError> { // asks all signed extensions to give their additional signed data.. let additional_signed = extra.additional_signed()?; // this essentially means: what needs to be signed in the signature of the transaction is: // 1. call // 2. signed extension data itself // 3. any additional signed data. let raw_payload = (call, extra, additional_signed); Ok(Self(raw_payload)) } // UncheckedExtrinsic::check fn check(self, lookup: &Lookup) -> Result<Self::Checked, TransactionValidityError> { Ok(match self.signature { Some((signed, signature, extra)) => { let signed = lookup.lookup(signed)?; // this is the payload that we expect to be signed, as explained above. let raw_payload = SignedPayload::new(self.function, extra)?; // encode the signed payload, and check it against the signature. if !raw_payload.using_encoded(|payload| signature.verify(payload, &signed)) { return Err(InvalidTransaction::BadProof.into()) } // the extra is passed again to `CheckedExtrinsic`, see in the next section. let (function, extra, _) = raw_payload.deconstruct(); CheckedExtrinsic { signed: Some((signed, extra)), function } }, // we don't care about signed extensions at all. None => CheckedExtrinsic { signed: None, function: self.function }, }) } }
Transaction Pool Validation
- Each pallet also has
#[pallet::validate_unsigned]. - This kind of overlaps with creating a signed extension and implementing
validate_unsigned.
Notes:
- https://github.com/paritytech/substrate/issues/6102
- https://github.com/paritytech/polkadot-sdk/issues/365
---v
Transaction Pool Validation
- Recall that transaction pool validation should be minimum effort and static.
- In
executive, we only do the following:- check signature.
- call
Extra::validate/Extra::validate_unsigned - call
ValidateUnsigned::validate, if unsigned. - NOTE dispatching ✅!
Notes:
Transaction queue is not part of the consensus system. Validation of transaction are free. Doing too much work in validation of transactions is essentially opening a door to be DOS-ed.
---v
Transaction Pool Validation
- Crucially, you should make sure that you re-execute anything that you do in transaction pool validation in dispatch as well:
#![allow(unused)] fn main() { /// Do any pre-flight stuff for a signed transaction. /// /// Make sure to perform the same checks as in [`Self::validate`]. fn pre_dispatch() -> Result<Self::Pre, TransactionValidityError>; }
- Because conditions that are not stateless might change over time!
Post Dispatch
- The dispatch result, plus generic type (
type Pre) returned frompre_dispatchis passed topost_dispatch. - See
impl Applyable for CheckedExtrinsicfor more info.
Notable Signed Extensions
- These are some of the default signed extensions that come in FRAME.
- See if you can predict how they are made!
---v
ChargeTransactionPayment
Charge payments, refund if Pays::Yes.
#![allow(unused)] fn main() { type Pre = ( // tip BalanceOf<T>, // who paid the fee - this is an option to allow for a Default impl. Self::AccountId, // imbalance resulting from withdrawing the fee <<T as Config>::OnChargeTransaction as OnChargeTransaction<T>>::LiquidityInfo, ); }
---v
check_genesis
Wants to make sure you are signing against the right chain.
Put the genesis hash in additional_signed.
check_spec_version and check_tx_version work very similarly.
---v
check_non_zero_sender
- interesting story: any account can sign on behalf of the
0x00account. - discovered by @xlc.
- uses
pre_dispatchandvalidateto ensure the signing account is not0x00.
Notes:
https://github.com/paritytech/substrate/pull/10413
---v
check_nonce
pre_dispatch: check nonce and actually update it.validate: check the nonce, DO NOT WRITE ANYTHING, setprovidesandrequires.
- remember that:
validateis only for lightweight checks, no read/write.- anything you write to storage is reverted anyhow.
---v
check_weight
- Check there is enough weight in
validate. - Check there is enough weight, and update the consumed weight in
pre_dispatch. - Updated consumed weight in
post_dispatch.
Big Picture: Pipeline of Extension
- Signed extensions (or at least the
pre_dispatchandvalidatepart) remind me of the extension system ofexpress.js, if any of you know what that is
---v
Big Picture: Pipeline of Extension

Exercises
- Walk over the notable signed extensions above and riddle each other about how they work.
- SignedExtensions are an important part of the transaction encoding. Try and encode a correct transaction against a template runtime in any language that you want, using only a scale-codec library.
- SignedExtensions that logs something on each transaction
- SignedExtension that keeps a counter of all transactions
- SignedExtensions that keeps a counter of all successful/failed transactions
- SignedExtension that tries to refund the transaction from each account as long as they submit less than 1tx/day.
Migrations and Try Runtime
How to use the slides - Full screen (new tab)
Migrations and Try Runtime
Runtime upgrades...
and how to survive them
At the end of this lecture, you will be able to:
- Justify when runtime migrations are needed.
- Write a the full a runtime upgrade that includes migrations, end-to-end.
- Test runtime upgrades before executing on a network using
try-runtimeandremote-externalities.
When is a Migration Required?
---v
When is a Migration Required?
- In a typical runtime upgrade, you typically only replace
:code:. This is Runtime Upgrade. - If you change the storage layout, then this is also a Runtime Migration.
Anything that changes encoding is a migration!
---v
When is a Migration Required?
#![allow(unused)] fn main() { #[pallet::storage] pub type FooValue = StorageValue<_, Foo>; }
#![allow(unused)] fn main() { // old pub struct Foo(u32) // new pub struct Foo(u64) }
- A clear migration.
---v
When is a Migration Required?
#![allow(unused)] fn main() { #[pallet::storage] pub type FooValue = StorageValue<_, Foo>; }
#![allow(unused)] fn main() { // old pub struct Foo(u32) // new pub struct Foo(i32) // or pub struct Foo(u16, u16) }
- The data still fits, but the interpretations is almost certainly different!
---v
When is a Migration Required?
#![allow(unused)] fn main() { #[pallet::storage] pub type FooValue = StorageValue<_, Foo>; }
#![allow(unused)] fn main() { // old pub struct Foo { a: u32, b: u32 } // new pub struct Foo { a: u32, b: u32, c: u32 } }
- This is still a migration, because
Foo's decoding changed.
---v
When is a Migration Required?
#![allow(unused)] fn main() { #[pallet::storage] pub type FooValue = StorageValue<_, Foo>; }
#![allow(unused)] fn main() { // old pub struct Foo { a: u32, b: u32 } // new pub struct Foo { a: u32, b: u32, c: PhantomData<_> } }
- If for whatever reason
chas a type that its encoding is like(), then this would work.
---v
When is a Migration Required?
#![allow(unused)] fn main() { #[pallet::storage] pub type FooValue = StorageValue<_, Foo>; }
#![allow(unused)] fn main() { // old pub enum Foo { A(u32), B(u32) } // new pub enum Foo { A(u32), B(u32), C(u128) } }
- Extending an enum is even more interesting, because if you add the variant to the end, no migration is needed.
- Assuming that no value is initialized with
C, this is not a migration.
---v
When is a Migration Required?
#![allow(unused)] fn main() { #[pallet::storage] pub type FooValue = StorageValue<_, Foo>; }
#![allow(unused)] fn main() { // old pub enum Foo { A(u32), B(u32) } // new pub enum Foo { A(u32), C(u128), B(u32) } }
- You probably never want to do this, but it is a migration.
---v
🦀 Rust Recall 🦀
Enums are encoded as the variant enum, followed by the inner data:
- The order matters! Both in
structandenum. - Enums that implement
Encodecannot have more than 255 variants.
---v
When is a Migration Required?
#![allow(unused)] fn main() { #[pallet::storage] pub type FooValue = StorageValue<_, u32>; }
#![allow(unused)] fn main() { // new #[pallet::storage] pub type BarValue = StorageValue<_, u32>; }
- So far everything is changing the value format.
- The key changing is also a migration!
---v
When is a Migration Required?
#![allow(unused)] fn main() { #[pallet::storage] pub type FooValue = StorageValue<_, u32>; }
#![allow(unused)] fn main() { // new #[pallet::storage_prefix = "FooValue"] #[pallet::storage] pub type I_can_NOW_BE_renamEd_hahAA = StorageValue<_, u32>; }
- Handy macro if you must rename a storage type.
- This does not require a migration.
Writing Runtime Migrations
- Now that we know how to detect if a storage change is a migration, let's see how we write one.
---v
Writing Runtime Migrations
- Once you upgrade a runtime, the code is expecting the data to be in a new format.
- Any
on_initializeor transaction might fail decoding data, and potentiallypanic!
---v
Writing Runtime Migrations
- We need a hook that is executed ONCE as a part of the new runtime...
- But before ANY other code (on_initialize, any transaction) with the new runtime is migrated.
This is
OnRuntimeUpgrade.
---v
Writing Runtime Migrations
- Optional activity: Go into
executiveandsystem, and find out howOnRuntimeUpgradeis called only when the code changes!
Pallet Internal Migrations
---v
Pallet Internal Migrations
One way to write a migration is to write it inside the pallet.
#![allow(unused)] fn main() { #[pallet::hooks] impl<T: Config> Hooks<BlockNumberFor<T>> for Pallet<T> { fn on_runtime_upgrade() -> Weight { migrate_stuff_and_things_here_and_there<T>(); } } }
This approach is likely to be deprecated and is no longer practiced within Parity either.
---v
Pallet Internal Migrations
#![allow(unused)] fn main() { #[pallet::hooks] impl<T: Config> Hooks<BlockNumberFor<T>> for Pallet<T> { fn on_runtime_upgrade() -> Weight { if guard_that_stuff_has_not_been_migrated() { migrate_stuff_and_things_here_and_there<T>(); } else { // nada } } } }
- If you execute
migrate_stuff_and_things_here_and_theretwice as well, then you are doomed 😫.
---v
Pallet Internal Migrations
Historically, something like this was used:
#![allow(unused)] fn main() { #[derive(Encode, Decode, ...)] enum StorageVersion { V1, V2, V3, // add a new variant with each version } #[pallet::storage] pub type Version = StorageValue<_, StorageVersion>; #[pallet::hooks] impl<T: Config> Hooks<BlockNumberFor<T>> for Pallet<T> { fn on_runtime_upgrade() -> Weight { if let StorageVersion::V2 = Version::<T>::get() { // do migration Version::<T>::put(StorageVersion::V3); } else { // nada } } } }
---v
Pallet Internal Migrations
- FRAME introduced macros to manage migrations:
#[pallet::storage_version].
#![allow(unused)] fn main() { // your current storage version. const STORAGE_VERSION: StorageVersion = StorageVersion::new(2); #[pallet::pallet] #[pallet::storage_version(STORAGE_VERSION)] pub struct Pallet<T>(_); }
- This adds two function to the
Pallet<_>struct:
#![allow(unused)] fn main() { // read the current version, encoded in the code. let current = Pallet::<T>::current_storage_version(); // read the version encoded onchain. Pallet::<T>::on_chain_storage_version(); // synchronize the two. current.put::<Pallet<T>>(); }
---v
Pallet Internal Migrations
#![allow(unused)] fn main() { #[pallet::hooks] impl<T: Config> Hooks<BlockNumberFor<T>> for Pallet<T> { fn on_runtime_upgrade() -> Weight { let current = Pallet::<T>::current_storage_version(); let onchain = Pallet::<T>::on_chain_storage_version(); if current == 1 && onchain == 0 { // do stuff current.put::<Pallet<T>>(); } else { } } } }
Stores the version as u16 in twox(pallet_name) ++ twox(:__STORAGE_VERSION__:).
External Migrations
---v
External Migrations
- Managing migrations within a pallet could be hard.
- Especially for those that want to use external pallets.
Alternative:
- Every runtime can explicitly pass anything that implements
OnRuntimeUpgradetoExecutive. - End of the day, Executive does:
<(COnRuntimeUpgrade, AllPalletsWithSystem) as OnRuntimeUpgrade>::on_runtime_upgrade().
---v
External Migrations
- The main point of external migrations is making it more clear:
- "What migrations did exactly execute on upgrade to spec_version xxx"
---v
External Migrations
- Expose your migration as a standalone function or struct implementing
OnRuntimeUpgradeinside apub mod v<version_number>.
#![allow(unused)] fn main() { pub mod v3 { pub struct Migration; impl OnRuntimeUpgrade for Migration { fn on_runtime_upgrade() -> Weight { // do stuff } } } }
---v
External Migrations
- Guard the code of the migration with
pallet::storage_version - Don't forget to write the new version!
#![allow(unused)] fn main() { pub mod v3 { pub struct Migration; impl OnRuntimeUpgrade for Migration { fn on_runtime_upgrade() -> Weight { let current = Pallet::<T>::current_storage_version(); let onchain = Pallet::<T>::on_chain_storage_version(); if current == 1 && onchain == 0 { // do stuff current.put::<Pallet<T>>(); } else { } } } } }
---v
External Migrations
- Pass it to the runtime per-release.
#![allow(unused)] fn main() { pub type Executive = Executive< _, _, _, _, _, (v3::Migration, ...) >; }
---v
External Migrations
- Discussion: Can the runtime upgrade scripts live forever? Or should they be removed after a few releases?
Notes:
Short answer is, yes, but it is a LOT of work. See here: https://github.com/paritytech/polkadot-sdk/issues/296
Utilities in frame-support.
translatemethods:- For
StorageValue,StorageMap, etc.
- For
- https://paritytech.github.io/substrate/master/frame_support/storage/migration/index.html
#[storage_alias]macro to create storage types for removed for those that are being removed.
Notes:
Imagine you want to remove a storage map and in a migration you want to iterate it and delete all items. You want to remove this storage item, but it would be handy to be able to access it one last time in the migration code. This is where #[storage_alias] comes into play.
Case Studies
- The day we destroyed all balances in Polkadot.
- First ever migration (
pallet-elections-phragmen). - Fairly independent migrations in
pallet-elections-phragmen.
Testing Upgrades
---v
Testing Upgrades
-
try-runtime+RemoteExternalitiesallow you to examine and test a runtime in detail with a high degree of control over the environment. -
It is meant to try things out, and inspired by traits like
TryFrom, the nameTryRuntimewas chosen.
---v
Testing Upgrades
Recall:
- The runtime communicates with the client via host functions.
- Moreover, the client communicates with the runtime via runtime APIs.
- An environment that provides these host functions is called
Externalities. - One example of which is
TestExternalities, which you have already seen.
---v
Testing Upgrades: remote-externalities
remote-externalities ia a builder pattern that loads the state of a live chain inside TestExternalities.
#![allow(unused)] fn main() { let mut ext = Builder::<Block>::new() .mode(Mode::Online(OnlineConfig { transport: "wss://rpc.polkadot.io", pallets: vec!["PalletA", "PalletB", "PalletC", "RandomPrefix"], ..Default::default() })) .build() .await .unwrap(); }
Reading all this data over RPC can be slow!
---v
Testing Upgrades: remote-externalities
remote-externalities supports:
- Custom prefixes -> Read a specific pallet
- Injecting custom keys -> Read
:code:as well. - Injecting custom key-values -> Overwrite
:code:with0x00! - Reading child-tree data -> Relevant for crowdloan pallet etc.
- Caching everything in disk for repeated use.
---v
Testing Upgrades: remote-externalities
remote-externalities is in itself a very useful tool to:
- Go back in time and re-running some code.
- Write unit tests that work on the real-chain's state.
Testing Upgrades: try-runtime
-
try-runtimeis a CLI and a set of custom runtime APIs integrated in substrate that allows you to do detailed testing.. -
.. including running
OnRuntimeUpgradecode of a new runtime, on top of a real chain's data.
---v
Testing Upgrades: try-runtime
- A lot can be said about it, the best resource is the rust-docs.
---v
Testing Upgrades: try-runtime
- You might find some code in your runtime that is featured gated with
#[cfg(feature = "try-runtime")]. These are always for testing. pre_upgradeandpost_upgrade: Hooks executed before and afteron_runtime_upgrade.try_state: called in various other places, used to check the invariants the pallet.
---v
Testing Upgrades: try-runtime: Live Demo.
- Let's craft a migration on top of poor node-template 😈..
- and migrate the balance type from u128 to u64.
Additional Resources 😋
Check speaker notes (click "s" 😉)
Notes:
- Additional work on automatic version upgrades: https://github.com/paritytech/substrate/issues/13107
- A Great talk about try-runtime and further testing of your runtime: https://www.youtube.com/watch?v=a_u3KMG-n-I
Reference material:
Notes:
FIXME: docs.google.com/presentation/d/1hr3fiqOI0JlXw0ISs8uV9BXiDQ5mGOQLc3b_yWK6cxU/edit#slide=id.g43d9ae013f_0_82 was listed here as a reference but is not public!
Exercise ideas:
- Find the storage version of nomination pools pallet in Kusama.
- Give them a poorly written migration code, and try and fix it. Things they need to fix:
- The migration depends on
<T: Config> - Does not manage version properly
- is hardcoded in the pallet.
- The migration depends on
- Re-execute the block at which the runtime went OOM in May 25th 2021 Polkadot.
Extras
How to use the slides - Full screen (new tab)
FRAME Extras
Follow Along!
These are topics where it can be easier to just learn by looking through the code and discussing.
Runtime Call Filters
Account Reference Counters
Pallet Instances
🟣 Polkadot
The Polkadot blockchain covered in depth, focus on high-level design and practically how to utilize it's blockspace. Dive into the purpose, implementation, and protocols of Polkadot, the sharded multichain system.
Introduction to Polkadot
How to use the slides - Full screen (new tab)
Introduction to Polkadot
What is Polkadot?
Polkadot is a scalable, heterogeneous, sharded, multi-chain network.
Polkadot is a permissionless and ubiquitous computer
Polkadot is a decentralized open-source community
Polkadot is a digital-native sovereign network
Environment
Polkadot has many faces, both technical and social.
It is the real-world instantiation of the technology described within this module.
These technologies only define the limits of the environment. Polkadot is everything which happens within it.
Agents
Within the environment, various types of agents may take action according to its rules.
These may be human users, silicon users, governments, or legal entities.
They likely have different agendas and activity levels, and may be located anywhere in the world.
Polkadot is an online economy for smart agents.
Games
Polkadot fulfills its goals with a combination of mechanisms and games which provide incentives and disincentives for nodes to work together and construct this environment.
All Together
Notes:
source: banner image from https://twitter.com/gavofyork
Goals of the Environment
- Real-time, secure, global consensus on system state
- Trustless, censorship-resistant, and permissionless transaction at scale
- Explicit network-wide governance and co-evolution
- General programmable computation with full security
- Secure and trust-minimized interoperability between processes
Goals: Breakdown
(1) Real-time, secure, global consensus on system state
Polkadot's state should update as close to real-time as possible.
A global, unique history of everything that has happened is maintained.
Notes:
State consisting of account balances, chains, governance votes, etc.
Goals: Breakdown
(2) Trustless, censorship-resistant, and permissionless transaction at scale
Only a private key and a balance is needed to interact with the network, and without trusting any single third party.
It aims to do so at high scale.
Goals: Breakdown
(3) Explicit network-wide governance and co-evolution
Polkadot stakeholders explicitly govern and evolve the network,
with the ability to set new rules.
Goals: Breakdown
(4) General programmable computation with full security
Polkadot is extended by general programs, usually taking the form of blockchains which themselves may be programmable environments.
Generalized computation allows the capabilities of the network to be extended arbitrarily, while inheriting the full security of the network.
Goals: Breakdown
(5) Secure and trust-minimized interoperability between processes
Processes deployed on Polkadot need to:
- Communicate with each other.
- "Trade" with each other without entirely trusting them.
- Protect trade routes and enforced trade agreements.
Validators
Validators decide to participate in the upkeep of the network.
Validators participate in the core games of Polkadot.
Validators
Validators are incentivized to do things like put user transactions in blocks or contribute to other activities, but may opt out of many of these tasks.
Validators are strongly punished for explicitly doing their job wrongly.
The games work as long as enough validators are doing their job
and also not misbehaving.
Polkadot Architecture
Notes:
A high level look into the architecture of Polkadot and the actors which maintain the network.
Polkadot: Major Systems

Validators are made to provide accurate execution for processes deployed on top of Polkadot.
These processes, defined as WebAssembly Code, are colloquially known as parachains.
Polkadot scales by sharing the load of validating these parachains across many validators.

Notes:
Simplified Polkadot Architecture (Parachains)
The Relay Chain
The relay chain is the "hub" of Polkadot, providing the main games which validators play. It is built with Substrate.
Notably, the functionality of the relay chain is minimized,
with the expectation that more complex functionalities will be pushed to less critical parts of the system.
Relay Chain Functionality:
- Governance (moving to parachain)
- Staking
- Registration, scheduling,
and advancement of parachains - Communication between parachains
- Consensus Safety
- Balance Transfers
Relay Chain Games:
The Relay Chain consists of two key games:
- Relay Chain Consensus
- Parachain Consensus
These games are the enablers of all activity within Polkadot.
Game: Relay Chain Consensus (simplified)
Goal:
- Grow and finalize the relay chain, comprised of only valid blocks
Rules:
- Validators put skin in the game in the form of tokens.
- Validators are incentivized to make new relay chain blocks (BABE)
- Validators are incentivized to vote to finalize recent relay chain blocks (GRANDPA)
- Validators are incentivized to include user transactions in their relay chain blocks.
- Validators get nothing for building bad blocks or building on top of them.
- Validators are slashed for making blocks out of turn.
The game works whenever <1/3 of validators misbehave.
Game: Parachain Consensus (simplified)
Goal:
- Grow registered parachains and post only valid updates to the Relay Chain
Rules:
- Validators are incentivized to attest to new parachain updates
- Whichever Validator makes the next Relay Chain block includes some attested parachain updates
- Validators are slashed if they attest to incorrect parachain updates
- incorrect means "not according to the parachain's Wasm code"
- Validators check each others' work to initiate the slashing procedure
The game works whenever <1/3 of validators misbehave.
All other functionalities of the relay chain (staking, governance, balances, etc.) are just baked into the definition of valid block and valid transaction.
Staking: Nominated Proof-of-Stake
As the Relay Chain progresses, it operates a system for selecting and accruing capital behind validators.
Accounts on Polkadot may issue a "nominate" transaction to select validators they support. Every day, an automated election selects the validators for the next 24 hours.
Nominators share in both the reward and slashing of their nominees.
Message Passing: Trustless Communication
The Relay Chain manages message queues and channels between parachains, as well as between each parachain and the Relay Chain itself.
Part of the Validators' job is to ensure that message queues are properly maintained and updated.
Registering Parachains
In 1.0: this is done via Slot Auctions to get a large bulk allocation
In the future: this will be done on a more granular / ad-hoc basis
Governance & Evolution
OpenGov
Polkadot has on-chain governance by stakeholder referendum, voting on subjects such as:
- Forkless upgrades of the network
- Administration of the Treasury funds
- Configuration of the Parachains protocol
- Configuration of fees
- Rescue & recovery operations
- All other mechanisms of control over the platform
Notes:
https://www.polkadot.network/features/opengov/
Treasury
- Polkadot ensures that a portion of network fees are collected treasury.
- The treasury is managed by governance.
- Tokens are burned if they are not spent.
The intention of the treasury is to pay people to help grow Polkadot itself. As tokens are burned, this creates pressure to fund public projects.
The Fellowship
A collective of developers, coordinated through on-chain activities.
These are node maintainers, developers, or researchers.
They set the technical direction for the network through RFCs.


Revisiting Goals
(1) Real-time, secure, global consensus on system state
This is provided by the validators participating in Relay Chain Consensus. Every block they make and finalize advances the system state.
(2) Trustless and permissionless transaction at scale
"at scale" is the caveat that drives most of the engineering in Polkadot.
Polkadot scales by virtue of the Parachain Consensus game, where the parachains themselves process most of the transactions in the network.
The more efficiently this game is implemented, the more Polkadot scales.
(3) Explicit network-wide governance and co-evolution
This is handled by OpenGov and the Treasury. Polkadot is a "meta-protocol" where OpenGov can update anything in the network, including the network's own rules.
(4) General programmable computation with full security
This is provided by the Parachain Consensus game, as most parachains are registered by users and validators are on the hook for valid updates.
Parachains themselves may also provide generalized computational functionality, e.g. EVM contracts.
(5) Secure and trust-minimized interoperability between processes
The Relay Chain maintains message queues between chains to provide interoperability (protected trade routes), however, full trust-minimization (enforced trade agreements) requires future protocol features to land.
At Scale: Polkadot's Value Proposition
From This

To This

Blockchain Scalability Trilemma
- Security: how much does it cost to attack the network?
- Scalability: how much work can the network do?
- Decentralization: how decentralized is the network?

Challenge: Scale while navigating the trilemma.
Scaling vs. Scheduling
Scaling is important, but resources must be allocated efficiently to make best use of that.
Polkadot allocates its resources to parachains through Execution Cores.
Execution Cores
Just like a decentralized CPU, Polkadot multiplexes many processes across cores.
When a parachain is assigned to a core, it can advance.
Otherwise, it lies dormant.
Execution Cores enable efficient allocation through Coretime trading.
One Chain Per Core

Time -->
Execution Cores: Endgame
Time -->
Coretime: Polkadot's Product
Coretime is what applications buy to build on Polkadot.
Goal: be like cloud.
Primary and secondary markets are key enablers.
Scalability + Scheduling
Full Circle
Polkadot is a scalable, heterogeneous, sharded, multi-chain network.
Polkadot is a permissionless and ubiquitous computer
Polkadot is a decentralized open-source community
Polkadot is a digital-native sovereign network
Questions
The Decisions of Polkadot
How to use the slides - Full screen (new tab)
The Decisions of Polkadot
The Decisions of Polkadot
This presentation will try to explain the core decisions which define the Polkadot network.
Creating an “Invention Machine”
Jeff Bezos outlined in an annual letter to Amazon shareholders how he approaches decision making, by categorizing decisions as either Type 1 or Type 2 decisions.
Notes:
https://www.sec.gov/Archives/edgar/data/1018724/000119312516530910/d168744dex991.htm
Type 1 Decisions
Some decisions are consequential and irreversible or nearly irreversible – one-way doors – and these decisions must be made methodically, carefully, slowly, with great deliberation and consultation. If you walk through and don't like what you see on the other side, you can't get back to where you were before. We can call these Type 1 decisions.
Type 2 Decisions
But most decisions aren't like that – they are changeable, reversible – they're two-way doors. If you've made a suboptimal Type 2 decision, you don't have to live with the consequences for that long. You can reopen the door and go back through. Type 2 decisions can and should be made quickly by high judgment individuals or small groups.
In the context of blockchains...
Type 1 Decisions
Decisions that cannot easily be changed in the future.
- Must be a part of the original protocol design.
- Changes might as well be considered a new protocol.
Type 2 Decisions
Decisions that can be easily changed in the future.
- Can be included into the protocol at a later time.
- Changes can be considered as part of the evolution of the protocol.
The Philosophies of Polkadot

Notes:
This is the slogan of the Web3 Summit, and seeing that Polkadot is our biggest bet on a Web3 future, it is apt that we use this phrase as a staple of the philosophy which backs Polkadot. The whole reason we have developed blockchain technologies was to address the trust problems that we face with those who wield power in our world.
I want to note the phrase is NOT “No Trust, Only Truth”. This, from what I can tell so far, is mostly impossible. We should not use points of trust to invalidate working solutions. For example, it is not an expectation everyone who uses Polkadot will read each individual line of open source code before they run it. Our goal should be to minimize trust, where possible, and make it obvious to everyone who uses our tools what kinds of trust assumptions they run on
Against Blockchain Maximalism

Notes:
Polkadot fundamentally believes in a multi-chain future. One where chains cooperate and provide greater value to one another, rather than where they strictly compete and try to kill one another. This is rare to find today, since cryptocurrencies are prone to becoming “investment vehicles”, where the creation of a new blockchain can be seen as a threat to the existing “investments”. With the blockchain maximalism mentality, people are choosing to value their “investments” over innovation and progression, and this isn’t best for our goals to provide the best technologies to the world.
“The best blockchain today will not be the best blockchain tomorrow.”
Notes:
This philosophy is a realization that building a blockchain is trying to build a piece of software which will last forever. The we will not be successful engineering Polkadot simply for the problems we find today. By the time we have built X, the world will need Y, and so on. This is why we have invested so much time building platforms and SDKs, not just products. We need to make sure these technologies are able to adapt and evolve in order to stay relevant for users
The Goals of Polkadot
The Blockchain Scalability Trilemma

-
Security: How much does it cost to attack the network?
-
Scalability: How much work can the network do?
-
Decentralization: How decentralized is the network?
In one sentence...
Polkadot’s mission is to provide secure, scalable, and resilient infrastructure for Web3 applications and services.
Notes:
Note the difference between “decentralization” as a mission vs "resilience".
Polkadot tries to accomplish that mission by solving three problems:
- Computational Scalability
- Shared Security
- Interoperability
The Decisions
What are the type 1 decisions which make Polkadot... Polkadot?
Wasm

WebAssembly is the backbone of Polkadot. It is a fast, safe, and open meta-protocol which powers all of the state transitions of our ecosystem.
It standardizes how chains execute, sandboxes that execution for improved security, and allows teams to build on Polkadot using any language that can be compiled into Wasm.
Sharding
Polkadot scales primarily by parallelizing execution on separate data shards.
These parallel chains (shards) are called Parachains.

App-Chains

Another key scaling decision is the choice of heterogeneous shards, allowing for application specific chains.
Specialized solutions for problems are more performant than generalized solutions, as they can incorporate more details about the problem space.
Interoperability
Individual application chains will inherently lack the ability to provide a full suite of optimized solutions for end users.
Interoperability allows parachains to work together to complete, complex end-to-end scenarios.

A visual of XCMP channels between Parachains.
Shared Security
An often overlooked problem is economic scaling of the entire blockchain ecosystem.
Polkadot is unique in that it provides all connected parachains with the same security guarantees as the Relay Chain itself.
Notes:
Security in proof-of-stake networks depends on economics, so there can only exist a limited amount of security in the world because economic value is, by definition, limited. As the number of blockchains increases due to scaling issues on single chains, their economic value — and therefore their security — gets spread out over multiple chains, leaving each one weaker than before.
Polkadot introduces a shared security model so that chains can interact with others while knowing full well that their interlocutors have the same security guarantees as their own chain. Bridge-based solutions — where each chain handles its own security — force the receiver to trust the sender. Polkadot’s security model provides the necessary guarantees to make cross-chain messages meaningful without trusting the security of the sender.
Execution Cores
Polkadot's Shared Security is powered through the creation and allocation of execution cores.
Execution cores provide blockspace-as-a-service, and are designed to work with any kind of consensus system.
Trust-Free Interactions

A key result of shared security through the Relay Chain is that it keeps track of the state of all parachains and keeps them in lock step.
That means blocks which are finalized on Polkadot imply finalization of all interactions between all parachains at the same height.
So, shared security not only secures the individual chains, but the interactions between chains too.
This is continuing to evolve with the addition of "accords" / SPREE.
Hybrid Consensus

Finality Gadget
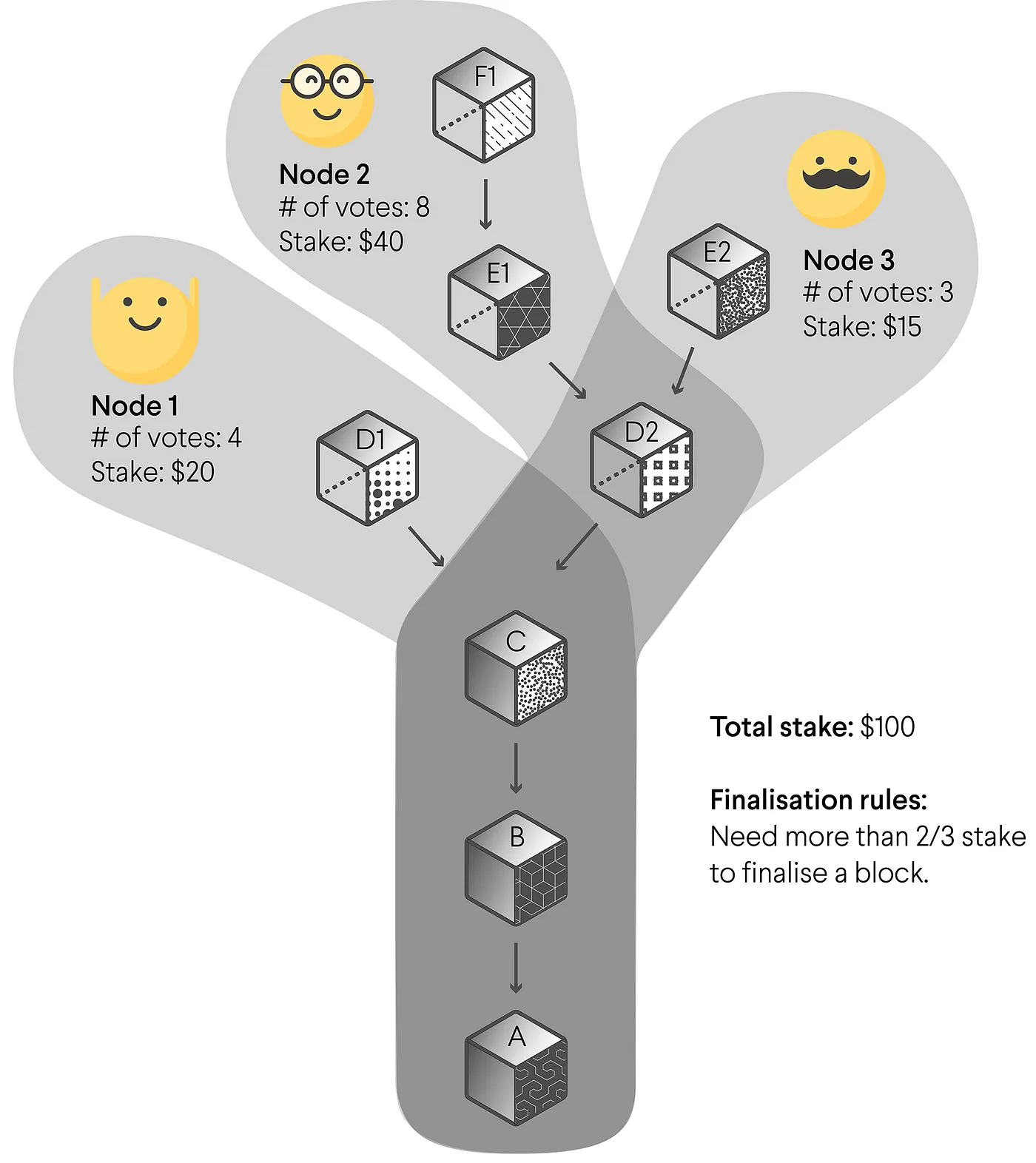
Current implementation is GRANDPA, which is robust and scalable against network partitions.
Light Client First Mentality
Polkadot has a strong belief that light clients are a necessary component for a Web3 future. It has been uncompromising in enabling first class light client support as a primary part of its development process:
- In-Browser Wasm Client (Substrate Connect)
- Wasm state transition function too!
- Consensus data integrated into block headers
- Merkle Tries and other LC compatible data structures
- Maximizing statically known metadata to offset reliance on full nodes.
On-Chain Runtime & Forkless Upgrades
The Polkadot protocol specification defines a clear separation between the blockchain client and runtime (state transition function).
This is primarily useful to implement the Parachains protocol, but also allows for chains to “forklessly” upgrade their code.
This gives the Polkadot Relay Chain and all connected parachains an evolutionary advantage over others in the blockchain space.
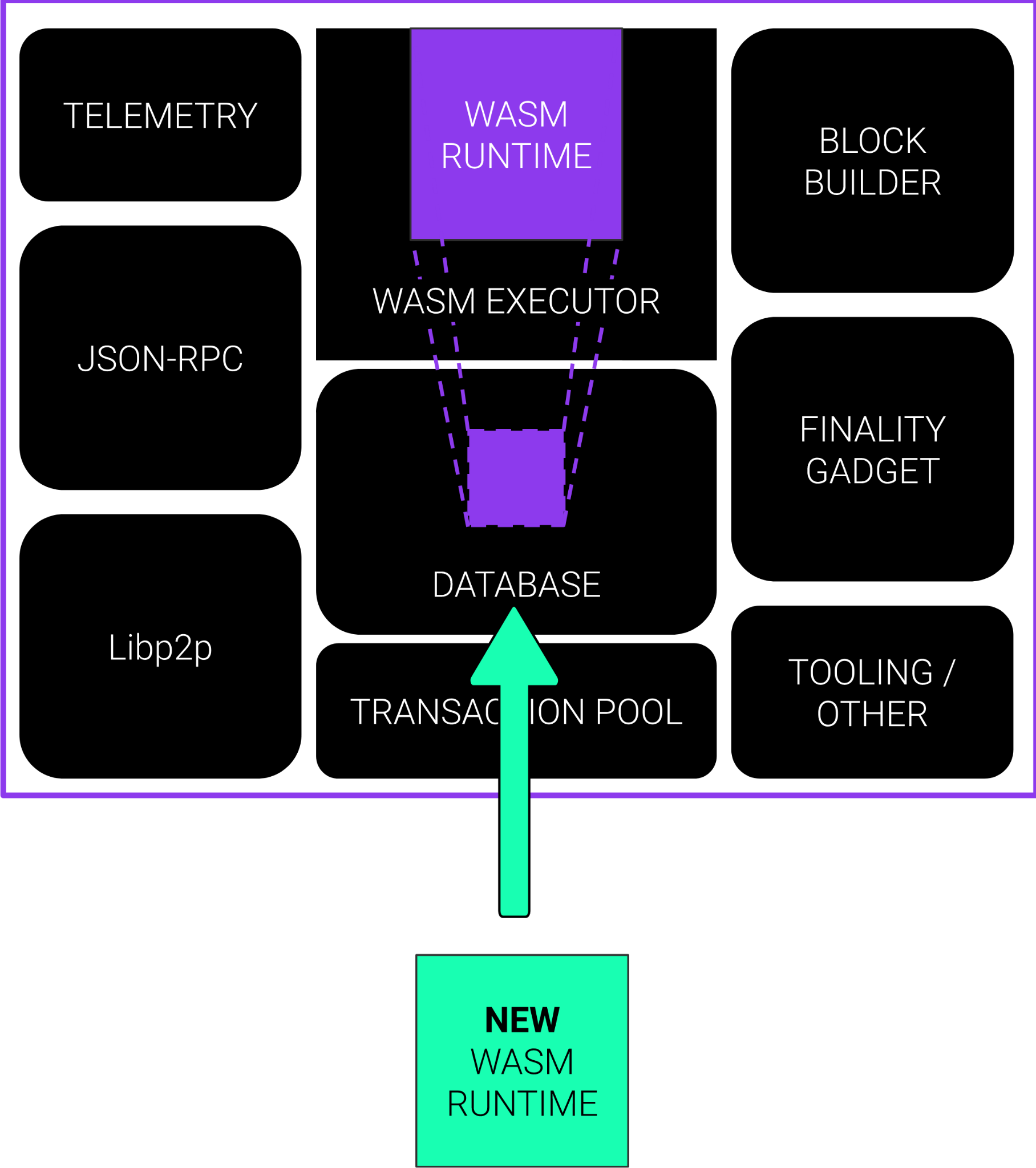
On-Chain Governance
Polkadot and its parachains need to change over time to stay relevant, and the network was designed from the beginning to have a transparent and sophisticated process to not only approve or reject changes but also enact them automatically.
- Governance decisions can literally change the underlying code of the chain (since it is on-chain).
- 50% of the total stake in the system should be able to control the future of the system.

On-Chain Treasury
Polkadot has designed at its core a self-funded treasury pool to incentivize the development and evolution of the protocol.
It is entirely controlled on-chain by the governance system of Polkadot, which means that it is immune to the regulations which would normally be imposed to centralized entities.

The Implementation of Polkadot
What are the type 2 decisions of Polkadot?
Parachains
Polkadot was designed around Parachains, but the exact meaning and manifestation of a Parachain is evolving.

- Originally, parachains would be long term applications-chains.
- On-Demand Parachains (formerly parathreads) changed that viewpoint to also include chains which can spin-up and spin-down at will.
- The future protocol will have even more exotic core scheduling and even more agile core usage, all because the type 1 decision around parachains is actually execution cores.
Notes:
XCM
Cross-Consensus Message Format

Instructions to teleport an asset between parachains.
While cross-chain interoperability (XCMP) is a type 1 decision, exactly the language that chains speak to each other is not.
XCM is Parity's current flavor of a cross-consensus message format, but we already see other teams try out their own ideas, or push updates to the XCM format specification.
Notes:
https://github.com/paritytech/xcm-format
Nominated Proof-of-Stake
One of Polkadot’s primary functions is to provide security not only to itself, but also to the connected Parachains.
The staking system is a critical focus of the network, and we have one of the most advanced staking systems to date.
- NPoS over DPoS to better allocate stake.
- We see ~25% more stake behind the elected set on NPoS compared with DPoS.
- At the cost of complexity and scaling.
- Economic incentives to distribute funds evenly across validators.
- Super-linear slashing system to discourage validator centralization.
- Actual value being generated by staking, justifying rewards.
The protocol has been actively evolving over time, making it more performant and accessible to users, for example with nomination pools.
SASSAFRAS
While hybrid consensus is a type 1 decision, the underlying protocols can continue to evolve, such as from BABE to SASSAFRAS.
Semi Anonymous Sortition of Staked Assignees For Fixed-time Rhythmic Assignment of Slots
An extension of BABE and acts as a constant-time block production protocol. This approach tries to address the shortcomings of BABE by ensuring that exactly one block is produced with time-constant intervals. The protocol utilizes zk-SNARKs to construct a ring-VRF and is a work in progress.
OpenGov
The specifics of Polkadot's on-chain governance system has changed multiple times in its history.
- To bootstrap the network, a Sudo account was used to initialize the chain.
- Then a multi-party system, including token holders, an elected council, and a technical council was used.
- Most recently, the councils have been removed, and token holders are now in full control of the Polkadot governance systems.
Treasury and Fellowships
An on-chain treasury has and will always exist; but how exactly it spends funds and to whom has evolved over time:
- Initially there were just simple proposals which were approved by the governance system.
- Then Bounties and Tips were introduced, increasing access to larger and smaller funding mechanisms.
- Most recently, fellowships have started to form, which represent organizations who can earn regular salaries from the network itself.
and many more...
Polkadot is designed to evolve, and make type 2 decision making fast and easy.
An invention machine.
A Format for Discussing Decisions
What questions should you ask when learning about the decisions of a Protocol?
- What is (the decision)?
- What do we need to consider when making (the decision)?
- Is it a Type 1 or Type 2 decision?
- What decisions has (chain) decided to make and why?
- What tradeoffs have they chosen?
- What decisions have others decided to make?
- How might those decisions be better or worse?
- Where can the blockchain community still improve on (the decision)?
Questions
What is Shared Security?
How to use the slides - Full screen (new tab)
What is Shared Security?
On the surface...
Shared Security is an Economic Scaling Solution for Blockchains.
But that is just an answer that sits at the surface. The topic goes much deeper than that.
Let’s explore…

What is Security?
Nearly every attack to a blockchain falls into one of these two buckets:
- Technical Security (cryptography)
- Economic Security (game theory + economics)
We will focus on Economic Security.
Economic Security is represented by the economic cost to change the canonical history of a blockchain.

Chains with higher security are more resilient to malicious activity, like a double spend attack.
Note that a double spend is not inherently an attack!
It is perfectly allowed in all blockchain protocols to sign and submit two messages which conflict with one another.
It is up to the blockchain to come to consensus as to which of these two transactions is canonical.

What does an attack look like?
In this example, someone is explicitly taking advantage of fragmentation in the network to try and create two different canonical chains.

What happens after the attack?
Eventually, the network fragmentation will resolve, and consensus messages will allow us to prove that the malicious nodes equivocated.

That is, they signed messages that validated two conflicting chains.
What is the economic cost?
This will result in slashing the malicious nodes, which should be economically large enough to deter these kinds of malicious activities from occurring.
So Economics and Security are tightly coupled in Blockchains.

The Bootstrapping Problem
What is the Bootstrapping Problem?
The bootstrapping problem is the struggle that new chains face to keep their chain secure, when their token economics are not yet sufficient or stable.
Arguably, the scarcest resource in blockchain is economic security - there simply is not enough to go around.
New Chains Have Small Market Cap

New Chains Are More Speculative

How do we solve this problem?
Shared Security

Different Forms of "Shared Security" Today
- Native: Native shared security is implemented at the protocol level, and is represented as a Layer 0 blockchain, working underneath Layer 1 chains.
- Rollups: Optimistic and Zero-Knowledge Rollups use a settlement layer to provide security and finality to their transactions.
- Re-Staking: Some protocols allow the use of already staked tokens to secure another network, usually through the creation of a derivative token.
but these different forms are not equal…
Deep Dive Into Polkadot Shared Security
Polkadot’s Shared Security
Polkadot is unique in that it provides all connected parachains with the same security guarantees as the Relay Chain itself.
This is native to the protocol, and one of its core functionalities.
Building Blocks of Shared Security
- Execution Meta-Protocol
- Coordination / Validation
- Security Hub / Settlement Layer
- Wasm
- Parachains Protocol
- Relay Chain
Wasm
You can't overemphasize Wasm
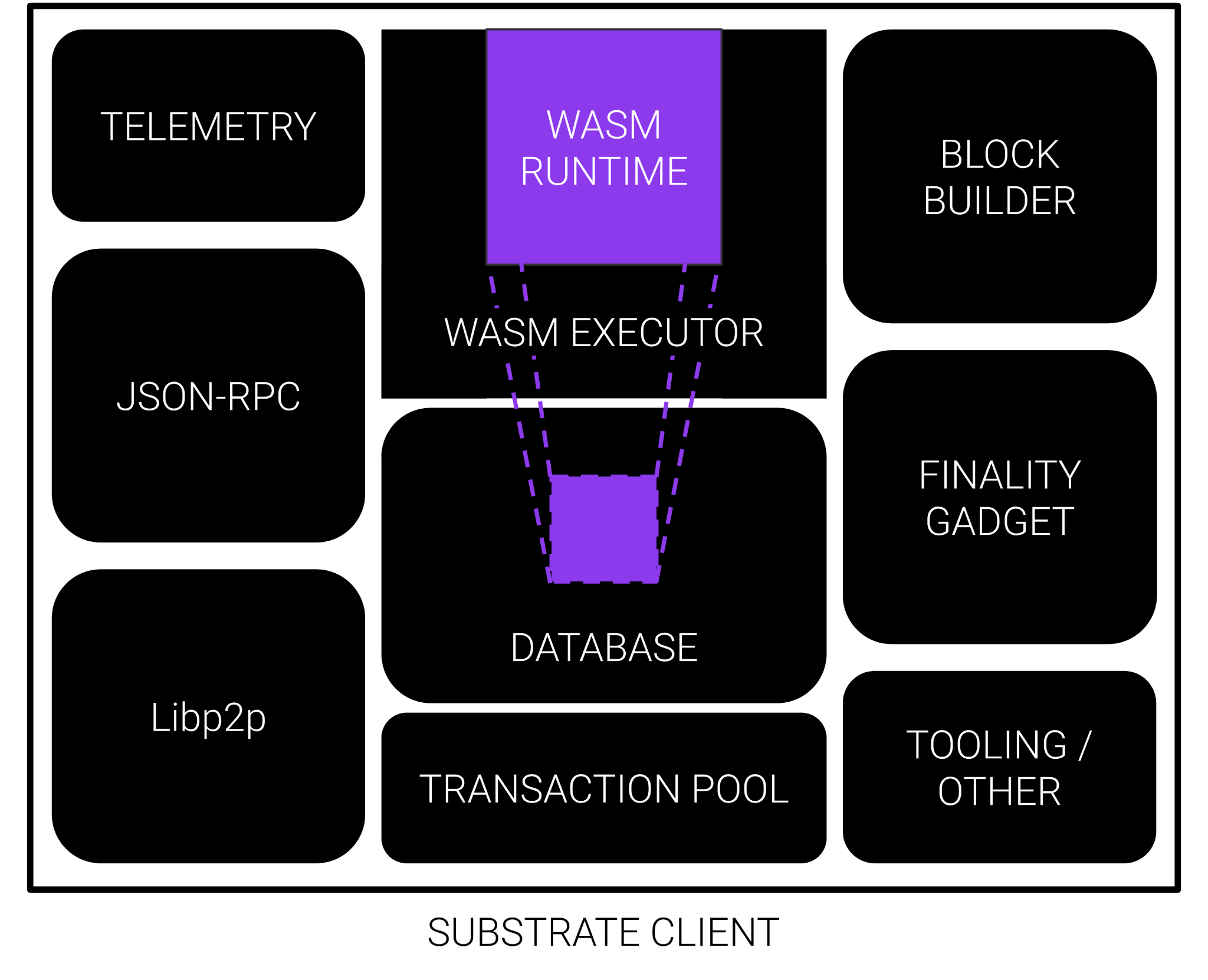
In the Polkadot ecosystem, each chain has their state transition function represented by a Wasm blob which is stored on the blockchain itself.
This has many implications, which we have covered, but the key point in this context is that it is very easy to share, generic, and safe to execute.
Game Console Analogy
Basic Substrate Client




Wasm Runtimes
A Polkadot Validator Node

In short...
- As you have learned, the Polkadot Client is basically a Wasm executor.
- All of the chains in our ecosystem use Wasm for their state transition function.
- The Wasm meta-protocol allows Polkadot to execute any chain on the fly!
Note that we ACTUALLY EXECUTE the blocks of other chains.
Less trust, more truth!
Parachain Validation
Maximizing Scaling
A scalable proof of stake system is one where:
- security is as shared as possible
- execution is as sharded as possible
Notes:
You should not confuse shared security with sharded security.
a.k.a. cosmos is a sharded security network.
Execution Sharding
Execution Sharding is the process of distributing blockchain execution responsibilities across a validator set.
In Polkadot, all validators execute every relay chain block, but only a subset execute each parachain block.
This enables Polkadot to scale.
How to validate a block?

Submitting Parachain Blocks
Parachains submit new blocks with a proof-of-validity to the network.

Wasm Runtime and latest state root for Parachains already stored on the relay chain.
Parachains Protocol has new blocks that it needs to validate and include.

Polkadot Validators
A random subset of validators are assigned to execute the parachain blocks.

The new state root is then committed to the relay chain so the process can repeat.
How do we stop things from going wrong?
- Data Availability
- Polkadot uses erasure encoding across the validators assigned to a parachain to make sure the data needed to validate a block stays available.
- Approval Checking
- Every validator node is running approval checking processes for a random subset of parachain blocks in every relay chain block. If the initially assigned approvers for a parablock "no-show", then we assume an attack and in the worst case escalate to have the entire validator set check the block.
- Disputes Handling
- When someone disputes the validity of a parablock, all validators must then check the block and cast a vote. The validators on the losing side of the dispute are slashed.
The Relay Chain
The Security Hub for Polkadot
The Relay Chain is the anchor for the Polkadot Network.
- Provides a base economic utility token with DOT.
- Provides a group of high quality Validators.
- Stores essential data needed for each parachain.
- Establishes finality for parachain blocks.
Parachain Blocks Get Finalized

Relay chain block producers commit the new state root to the relay chain once the Parachains Protocol has been completed.
Thus, when a relay chain block is finalized all included parachain blocks will also be finalized!
The Parachain state committed on Polkadot is the canonical chain.
Trust-Free Interactions

This also means that finalization on Polkadot implies finalization of all interactions between all parachains at the same height.
So, shared security not only secures the individual chains, but the interactions between chains too.
Building Blocks of Shared Security
- Execution Meta-Protocol
- Coordination / Validation
- Security Hub / Settlement Layer
Other protocols say they are providing shared security... but do they have these key building blocks?
Comparing Options
Re-Staking Solution
Pros
- Seems to be protocol agnostic, and can be “backported” to new and existing chains.
- Smaller / newer chains can rely on more valuable and stable economies.
Cons
- As tokens are continually re-staked, the economic “costs” needed to attack secured chains decreases.
- No real computational verification or protection provided by these systems.
- Seems to ultimately fall back on centralized sources of trust.
Notes:
See the section on "Key Risks and Vulnerabilities" here:
https://consensys.net/blog/cryptoeconomic-research/eigenlayer-a-restaking-primitive/
Generally there are two main attack vectors of EigenLayer. One is that many validators collude to attack a set of middleware services simultaneously. The other is that the protocols that leverage EigenLayer and are built through it may have unintended slashing vulnerabilities and there is a risk of honest nodes getting slashed.
Much of the EigenLayer mechanism relies upon a rebalancing algorithm that takes into account the different validators and their accompanying stake and security capacity and usage. This underpins the success of the protocol. If this rebalancing mechanism fails (e.g. slow to adjust, latency, incorrect parameters) then EigenLayer opens itself up to different attack vectors, particularly around cryptoeconomic security. It essentially replicates the same vulnerabilities that it sought to solve with merge-mining. So attention must be paid to ensuring that the system is accurately updating any outstanding restaked $ETH and that it remains fully collateralized.
Optimistic Rollups
Pros
- Not limited by the complexity of the on-chain VM.
- Can be parallelized.
- They can stuff a lot of data in their STF.
- They can use compiled code native to modern processors.
Cons
- Concerns around centralization and censorship of sequencers.
- Long time to finality due to challenge periods. (could be days)
- Settlement layers could be attacked, interfering with the optimistic rollup protocols.
- Suffers from the same problems allocating blockspace as on-chain transactions.
- On-chain costs to perform the interactive protocol.
- Congestion of the network.
Zero-Knowledge Rollups
Pros
- Honestly, they are pretty great.
- Proven trustlessly.
- Minimal data availability requirements.
- Instant Finality (at high costs).
- Exciting future if recursive proofs work out.
Cons
- Concerns around centralization of sequencers and provers.
- Challenging to write ZK Circuits.
- Turing complete, but usually computationally complex.
- Hard to bound complexity of circuits when building apps.
- Suffers from the same problems allocating blockspace as on-chain transactions.
- On-chain costs to submit and execute proofs on settlement layer.
- Congestion of the network.
Polkadot Native Shared Security
Pros
- Protocol level handling of sharding, shared security, and interoperability.
- Easy to develop STF: Anything that compiles to Wasm.
- Probably the best time to finality, usually under a minute.
- Data availability provided by the existing validators.
- Much less concern of centralization from collators vs sequencers and provers.
Cons
- Certain limitations enforced to keep parachains compatible with the parachains protocol.
- Wasm STF
- No Custom Host Function
- Constrained Execution Environment
- Wasm is unfortunately still 2x slower than native compilation.
- Requires lot of data being provided and available in PoV.
Questions
Execution Sharding in Polkadot
How to use the slides - Full screen (new tab)
Execution Sharding in Polkadot
Execution Sharding
Execution Sharding is the process of distributing blockchain execution responsibilities across a validator set.
Execution Sharding in Polkadot
In Polkadot, all validators execute every relay chain block, but only a subset execute each parachain block.
This enables Polkadot to scale.
Lesson Agenda
- Discuss the high-level protocols and principles of Execution Sharding in Polkadot
- Provide background on how complex on & offchain logic is implemented with Substrate
Notes:
Polkadot v1.0: Sharding and Economic Security is a comprehensive writeup of the content here in much more detail. Please read it after the lesson if you would like to understand how Polkadot works from top to bottom.
Goals of Execution Sharding
- A minimal amount of validator nodes should check every parachain block while still maintaining security
- The relay chain will provide ordering and finality for parachain blocks
- Only valid parachain blocks will become finalized
Notes:
Because GRANDPA finality faults require 33% or more stake to be slashed, Goal (3) implies Shared Security
Forkfulness
Before finality, the relay chain can fork, often accidentally due to races.
Tool: deliberately fork away from unfinalized blocks we don't like.
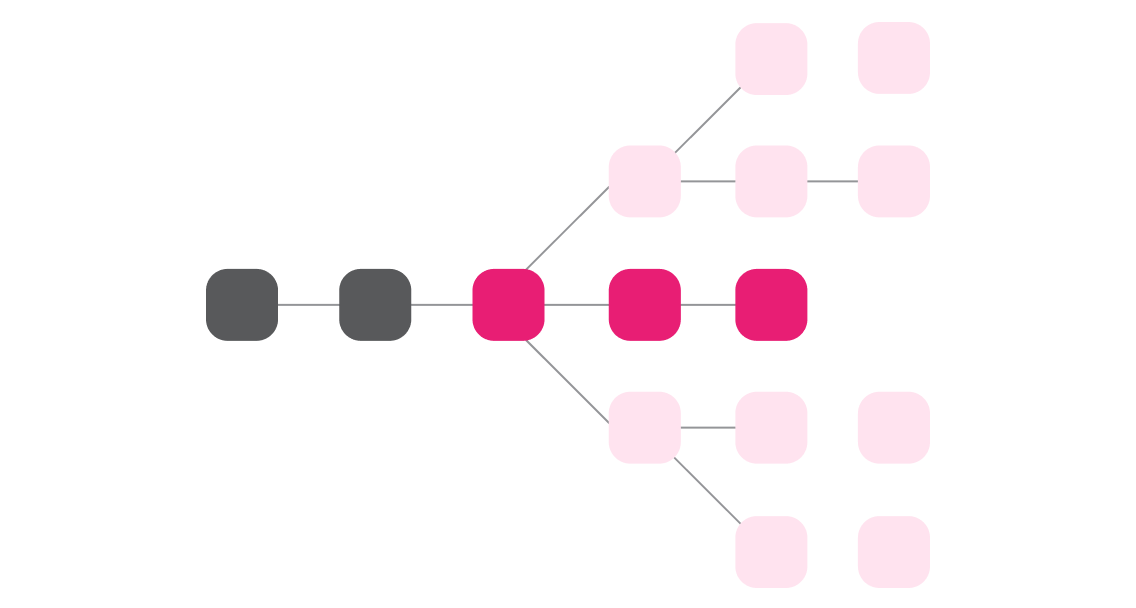
Notes:
In the slides, we will look at single instances of the protocols, but it should be known that the validators are actually doing these steps in parallel with each other and often many times at a time.
Parachains Protocols
- Collation: Making parachain blocks
- Backing: Validator initial checks & sign-off of blocks
- Availability: Distributing data needed for checking
- Approval Checking: Checking blocks
- Disputes: Holding backers accountable
Validators are constantly running many instances of these protocols, for candidates at different stages in their lifecycle.
Candidate Lifecycle

10,000 foot view
Polkadot's approach is to have few validators check every parablock in the best case.
First, backers introduce new candidates to other validators and provide "skin in the game".
Then, approval checkers keep them accountable.
Goal: Have as few checkers as reasonably possible.
Validator Group Assignments and Execution Cores
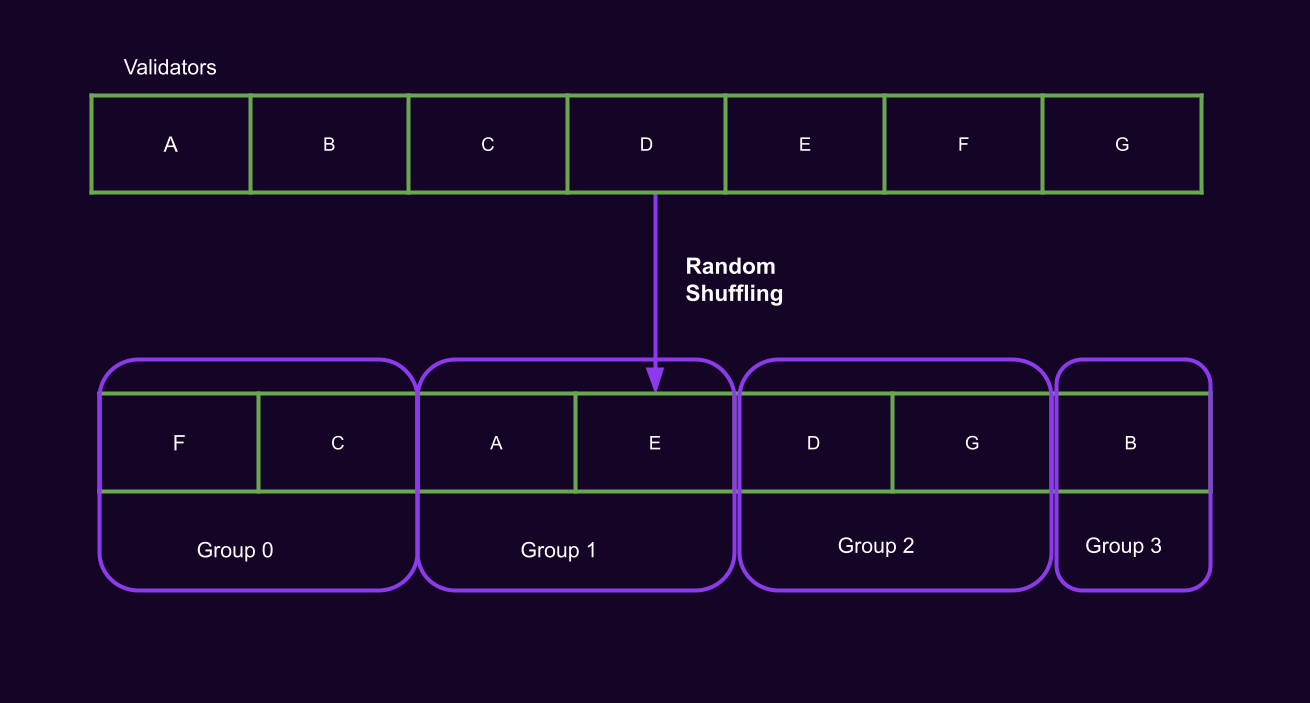
Notes:
Every Session (4 hours), validators are partitioned into small groups which work together.
Groups are assigned to specific Execution Cores, and these assignments change every few blocks.
Definition: Candidate
A Candidate is a parachain block
which has not yet been finalized in the relay chain.
Definition: HeadData
Head Data is an opaque and compact representation of a parachain's current state. It can be a hash or a small block header, but must be small.
Definition: Parachain Validation Function (PVF)
From a Validator's perspective, a parachain is a WebAssembly blob which exposes the following (simplified) function:
#![allow(unused)] fn main() { type HeadData = Vec<u8>; struct ValidationResult { /// New head data that should be included in the relay chain state. pub head_data: HeadData, // more fields, like outgoing messages, updated code, etc. } fn validate_block(parent: HeadData, relay_parent: RelayChainHash, pov: Vec<u8>) -> Result<ValidationResult, ValidationFailed>; }
Why might validate_block fail?
parentorPoVis malformed - the implementation can't transform it from an opaque to specific representationparentandPoVdecode correctly but don't lead to a valid state transitionPoVis a valid block but doesn't follow from theparent
#![allow(unused)] fn main() { fn validate_block(parent: HeadData, relay_parent: RelayChainHash, pov: Vec<u8>) -> Result<ValidationResult, ValidationFailed>; }
Relay Chain Block Contents

Any node can be selected as the next Relay Chain block author, so these data must be widely circulated.
Collation
The collator's job is to build something which passes validate_block.
In the Collation phase, a collator for a scheduled parachain builds a parachain block and produces a candidate.
The collator sends this to validator group assigned to the parachain over the p2p network.
Some collator pseudocode:
#![allow(unused)] fn main() { fn simple_collation_loop() { while let Some(relay_hash) = wait_for_next_relay_block() { let our_core = match find_scheduled_core(our_para_id, relay_hash) { None => continue, Some(c) => c, }; let parent = choose_best_parent_at(relay_hash); let (pov, candidate) = make_collation(relay_hash, parent); send_collation_to_core_validators(our_core, pov, candidate); } } }

Backing
In the backing phase, the validators of the assigned group share the candidates they've received from collators, validate them, and sign statements attesting to their validity.
Validate means roughly this: execute validate_block and check the result.
They distribute their candidates and statements via the P2P layer, and then the next relay chain block author bundles candidates and statements into the relay chain block.
Backing: Networking
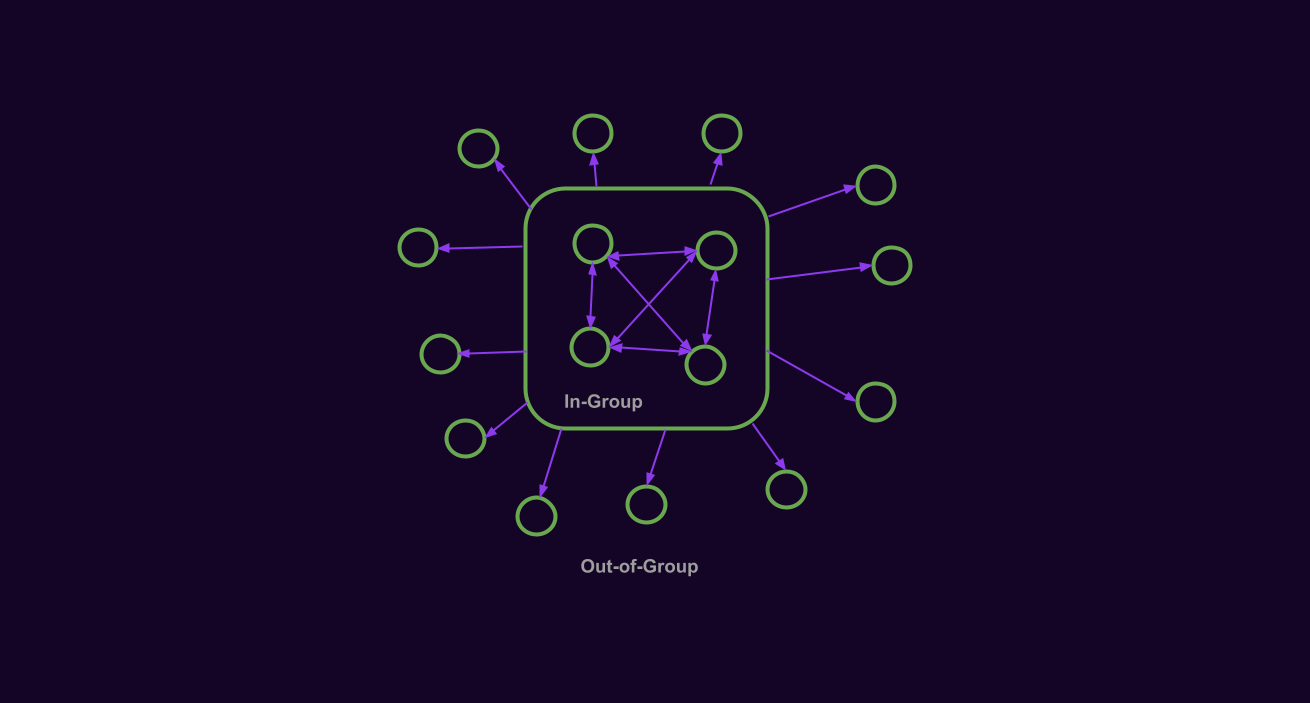
Backing: Skin in the Game
The main goal of backing is to provide "skin in the game".
Backers are agreeing that if the parablock turns out to be bad, they will lose 100% of their stake.
Backing on its own does not provide security, only accountability.
Notes:
The current minimum validator bond as of Aug 1, 2023 is ~1.7 Million DOT.
Availability
At this point, the backers are responsible for making the data needed to check the parablock available to the entire network.
Validators sign statements about which data they have and post them to the relay chain.
If the parablock doesn't get enough statements fast enough, the relay chain runtime just throws it out.
Erasure Coding
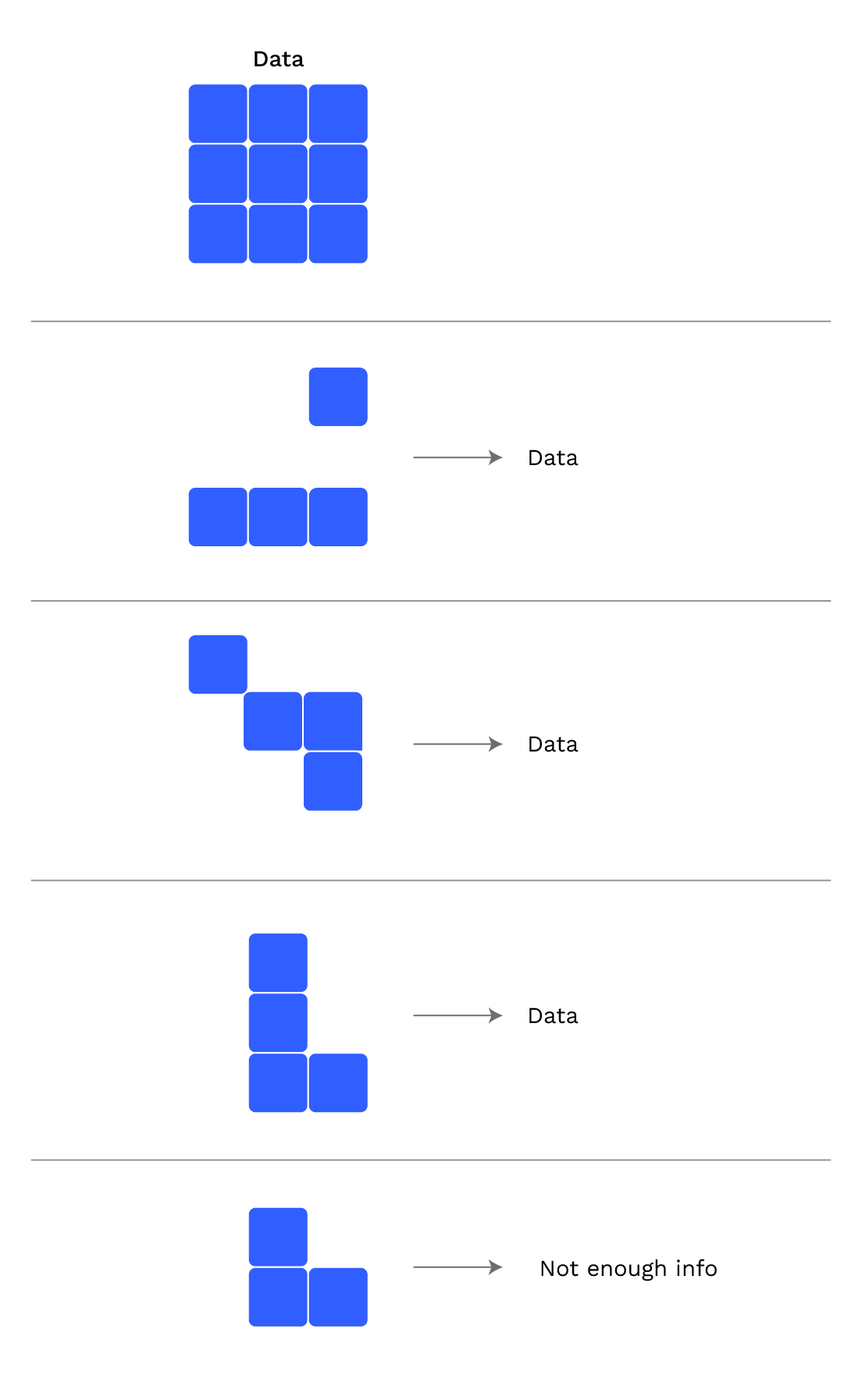
Each validator is responsible for one piece of this data. As long as enough of these pieces stay available, the data is recoverable.
The statements validators sign and distribute to all other validators essentially say "I have my piece".
Once 2/3 or more such statements land on-chain, the candidate is ready to be checked and is included.
Some pseudocode for availability:
#![allow(unused)] fn main() { fn get_availability_chunks() { while let Some(backed_candidate, backing_group) = next_backed_candidate() { let my_chunk = fetch_chunk( my_validator_index, backed_candidate.hash(), backing_group, ); let signed_statement = sign_availability_statement(backed_candidate.hash()); broadcast_availability_statement(signed_statement); } } }
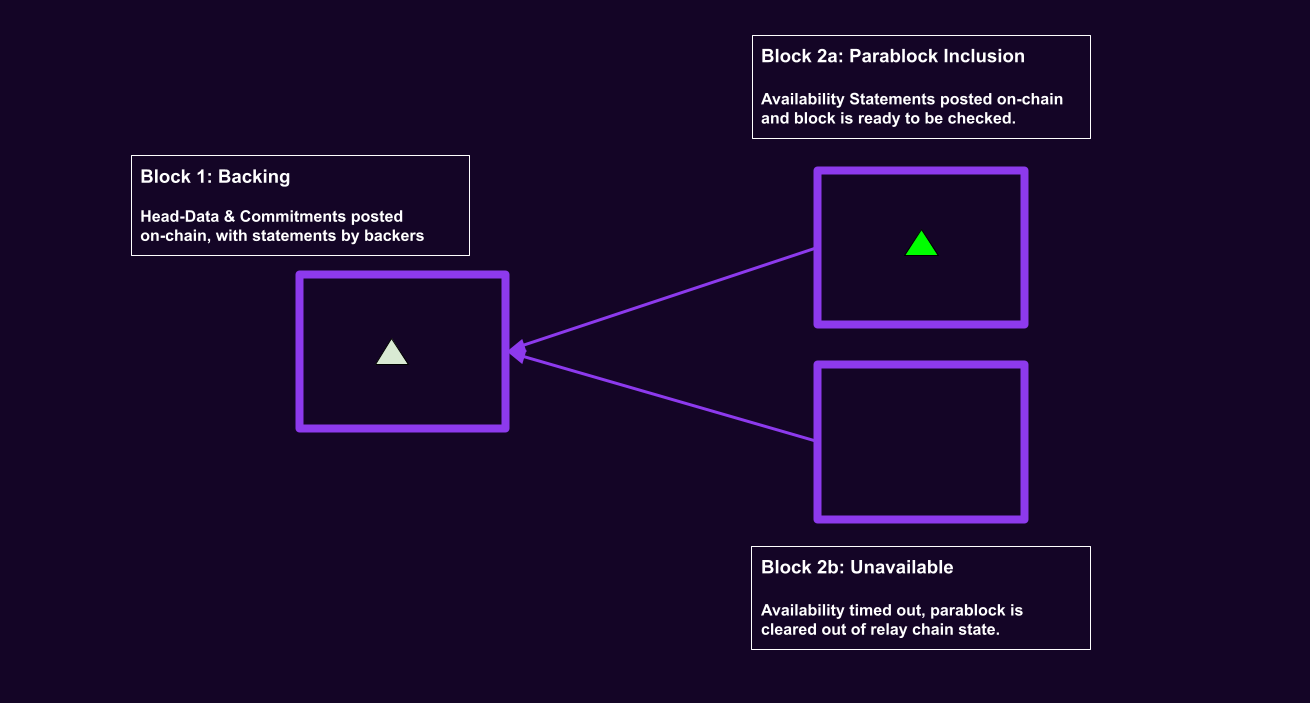
Notes:
In practice, we allow more than a single block for availability to be timed out.
Parablock Inclusion and Finality
Parablock Inclusion and Finality
(3) Only valid parachain blocks will become finalized
Notes:
Remember our goal from earlier?
Parablock Inclusion and Finality
To fulfill this goal we need 2 things.
- A protocol for proving validity of included candidates
- Consensus rules for the relay chain
to avoid building on or finalizing
relay chain forks containing bad candidates.
What is "Checking" a Parablock?
Checking involves three operations:
- Recovering the data from the network (by fetching chunks)
- Executing the parablock, checking success
- Check that outputs match the ones posted
to the relay chain by backers
Notes:
Step 3 is of crucial importance. Without it, backers could create things like messages and runtime upgrades out of thin air, by backing a valid candidate but lying about the outputs of the candidate.
Security Model: Gambler's Ruin
The security argument for Polkadot is based on Gambler’s Ruin.
An attacker who can take billions of attempts to brute-force the process would eventually be successful.
But because of slashing, every failed attempt means enormous amounts of DOT slashed.
Approval Checking
Every validator tracks its opinion about the validity of every unfinalized, included candidate in a local state machine.
This state machine always either outputs "approved" or stalls.
Key properties:
- The state machine output on a validator is based on the statements it has received.
- If the parachain block is really valid (i.e. passes checks) then it will eventually output "approved" on honest nodes.
- If the parachain block is invalid, it is much more likely to be detected than to output "approved" on enough honest nodes.
Notes:
Honest nodes output "approved" only if there is a very large amount of malicious checkers and they mainly see votes from those checkers as opposed to honest checkers.
Low probability here means 1 in 1 billion or so (assuming 3f < n) Not cryptographic low probability, but good enough for crypto-economics.
Validators keep track of statements about every candidate.
Validators only issue statements about a few candidates.
Validators issue two types of statements:
- Assignments: "I intend to check X"
- Approvals: "I checked & approved X"

Every validator is assigned to check every parablock, but at different times.
Validators always generate their assignments, but keep them secret unless they are needed.

Validator assignments are secret until revealed.
Validators distribute revealed assignments before checking the candidate.
Assignments without following are called no-shows. No-shows are suspicious, and cause validators to raise their bar for approval.
Notes:
If validators began downloading data before revealing their assignment, an attacker might notice this and attack them without anybody noticing.

Notes:
Approval Checking is like the hydra. Every time an attacker chops off one head, two more heads appear.
It only takes one honest checker to initiate a dispute.
Disputes
When validators disagree about the validity of a parablock, a dispute is automatically raised.
Disputes involve all validators, which must then check the block and cast a vote.
Backing and Approval statements already submitted are counted as dispute votes.
Votes are transmitted by p2p and also collected on-chain.
Dispute Resolution

Notes:
resolution requires a supermajority in either direction.
Dispute Slashing
The validators on the losing side of the dispute are slashed.
The penalty is large when the candidate is deemed invalid by the supermajority and small when it is deemed valid.
GRANDPA Voting Rules
Instead of voting for the longest chain, validators vote for the longest chain where all unfinalized included candidates are
- approved (according to their local state machine)
- undisputed (according to their best knowledge)
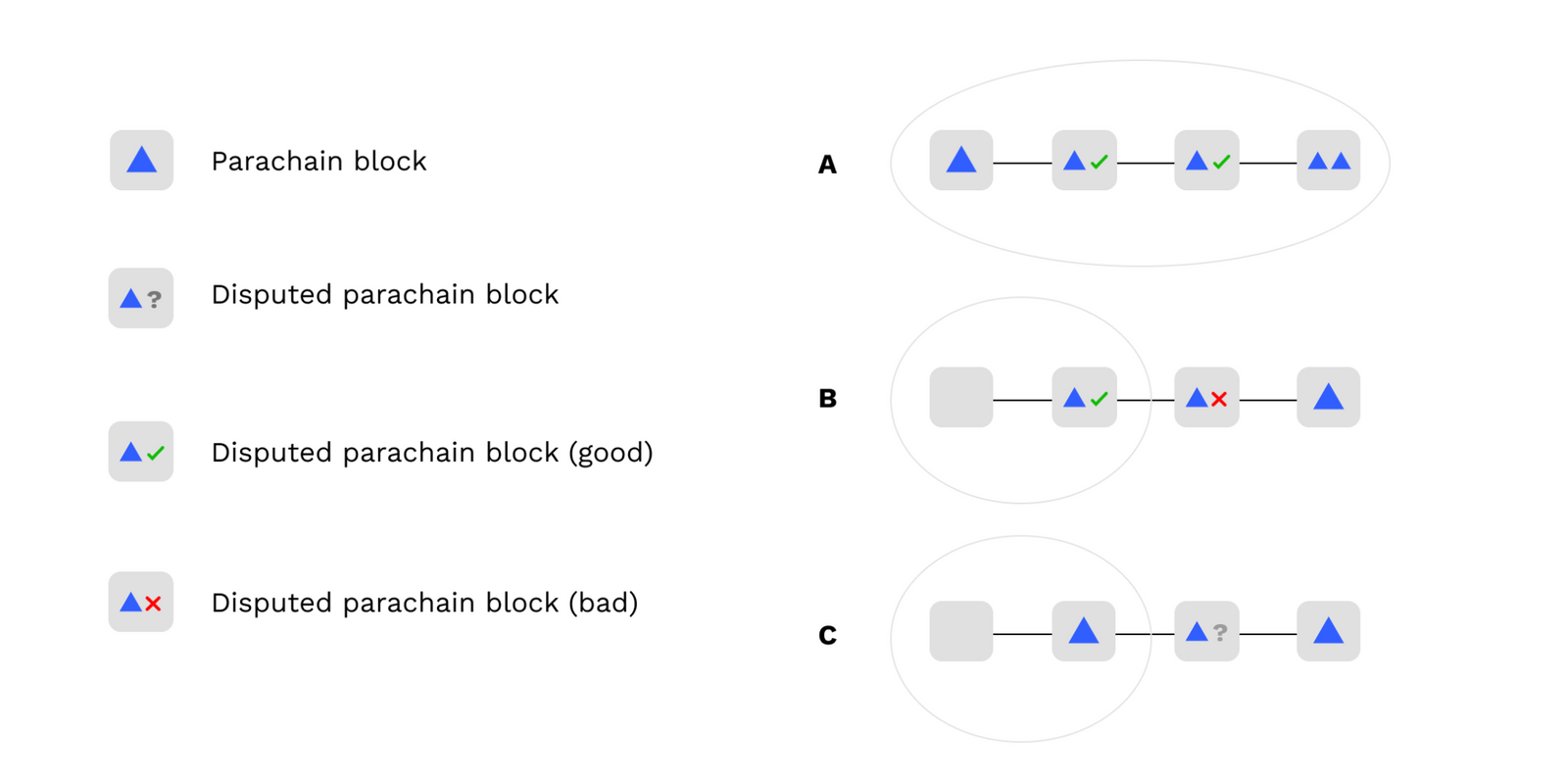
BABE Chain Selection Rule
Validators refuse to author relay chain blocks on top of forks containing parablocks which are invalid or have lost disputes. This causes a "reorganization" whenever a dispute resolves against a candidate.
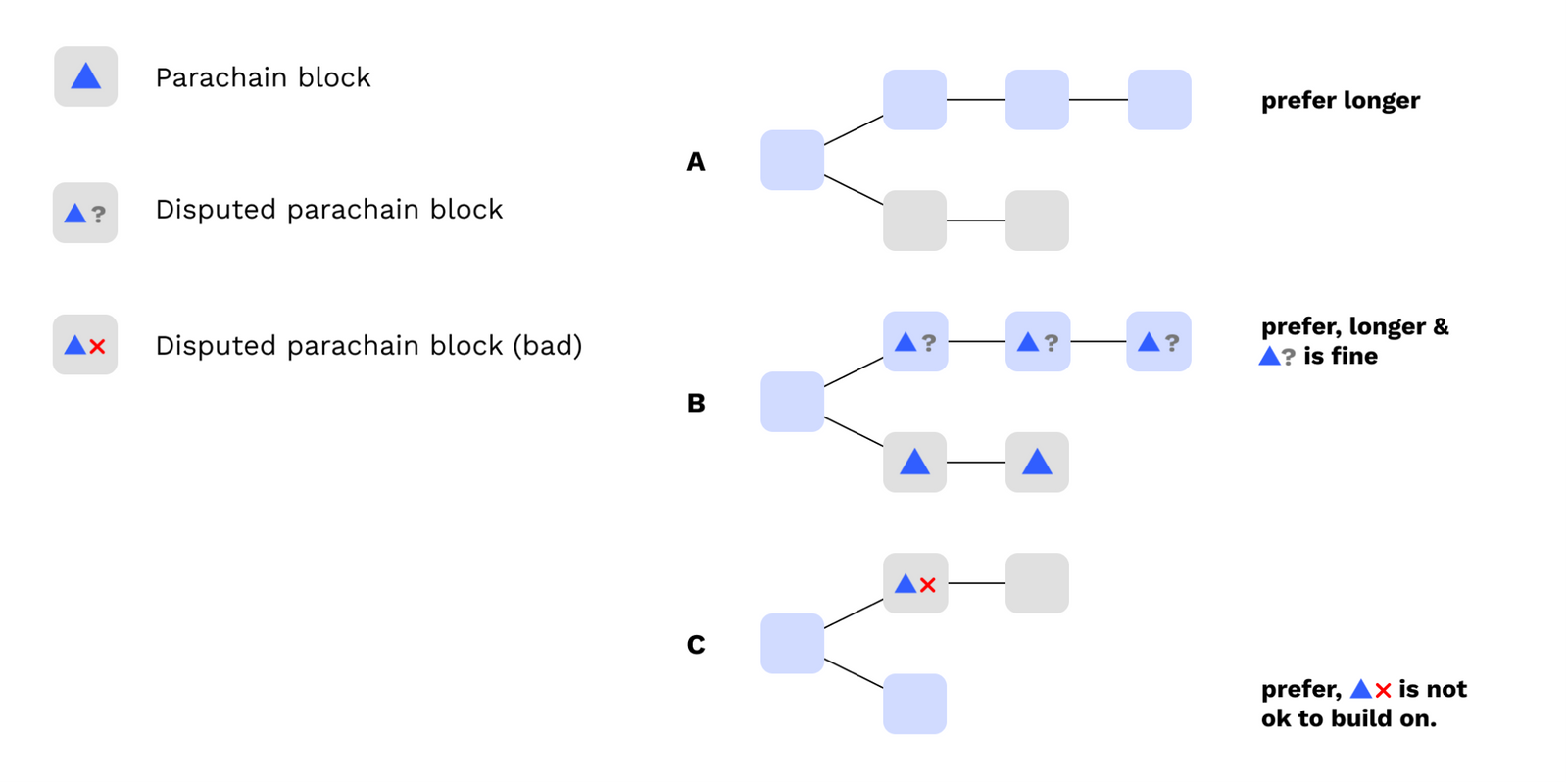
How are complex off-chain systems
implemented using Substrate?
Interaction Between Client & Runtime
Since Polkadot involves not only on-chain logic but off-chain logic, the runtime is the central source of truth about validators, assignments, parachain states, etc.
Clients learn about the state by invoking Runtime APIs at recent blocks, and the runtime is updated with new blocks.
Notes:
Because the runtime is updated by new blocks, malicious or poorly connected validators have some choice in which information to provide the runtime with. This must be accounted for in the protocol: we cannot assume that the runtime is always perfectly informed.
Orchestra
Orchestra allows us to split up the node's logic into many "Subsystems" which run asynchronously.
These subsystems communicate with message passing and all receive signals which coordinate their activities.
Orchestra: Signals
Signals are sent to all subsystems and act as a "heartbeat".
Messages sent after a signal arrives on one subsystem cannot arrive at another subsystem until it has received the same signal.
Orchestra: Signals in Polkadot
#![allow(unused)] fn main() { /// Signals sent by the overseer (Polkadot's Orchestra name) to all subsystems. pub enum OverseerSignal { /// Subsystems should adjust their jobs to start /// and stop work on appropriate block hashes. ActiveLeaves(ActiveLeavesUpdate), /// `Subsystem` is informed of a finalized block /// by its block hash and number. BlockFinalized(Hash, BlockNumber), /// Conclude the work of the `Overseer` and all `Subsystem`s. Conclude, } }
Notes:
The instantiation of Orchestra in Polkadot is called "Overseer".
Without Orchestra:
#![allow(unused)] fn main() { fn on_new_block(block_hash: Hash) { let work_result = do_some_work(block_hash); inform_other_code(work_result); } }
Problem: There is a race condition!
The other code may receive work_result before learning about the new block.
With Orchestra:
#![allow(unused)] fn main() { fn handle_active_leaves_update(update: ActiveLeavesUpdate) { if let Some(block_hash) = update.activated() { let work_result = do_some_work(block_hash); inform_other_subsystem(work_result); } } }
This works! Orchestra ensures that the message to the other subsystem only arrives after it has received the same update about new blocks.
Examples of Subsystems in Polkadot
- Dispute Participation
- Candidate Backing
- Availability Distribution
- Approval Checking
- Collator Protocol
- everything!
Implementers' Guide
The Implementers' Guide contains information about all subsystems, architectural motivations, and protocols used within Polkadot's runtime and node implementation.
Questions
Data Availability and Sharding
How to use the slides - Full screen (new tab)
Data Availability and Sharding
Outline
Data Availability Problem
How do we ensure a piece of data is retrievable without storing it on every single node forever?
Incorrectness can be proven (fraud proofs), but unavailability can't.
---v
Data Availability Problem: Parachains
Imagine a parachain collator produces a block, but only sends it to relay chain validators to verify.
What could such a collator do?
- Prevent nodes and users from learning the parachain state
- Prevent other collators from being able to create blocks
We want other collators to be able to reconstruct the block from the relay chain.
---v
Data Availability Problem: Relay Chain
If that block's PoV is only stored by a few validators, what if they go offline or rogue?
- Honest approval-checkers are not able to verify validity
Notes:
This is really bad. It means we could finalize an invalid parachain block.
Problem
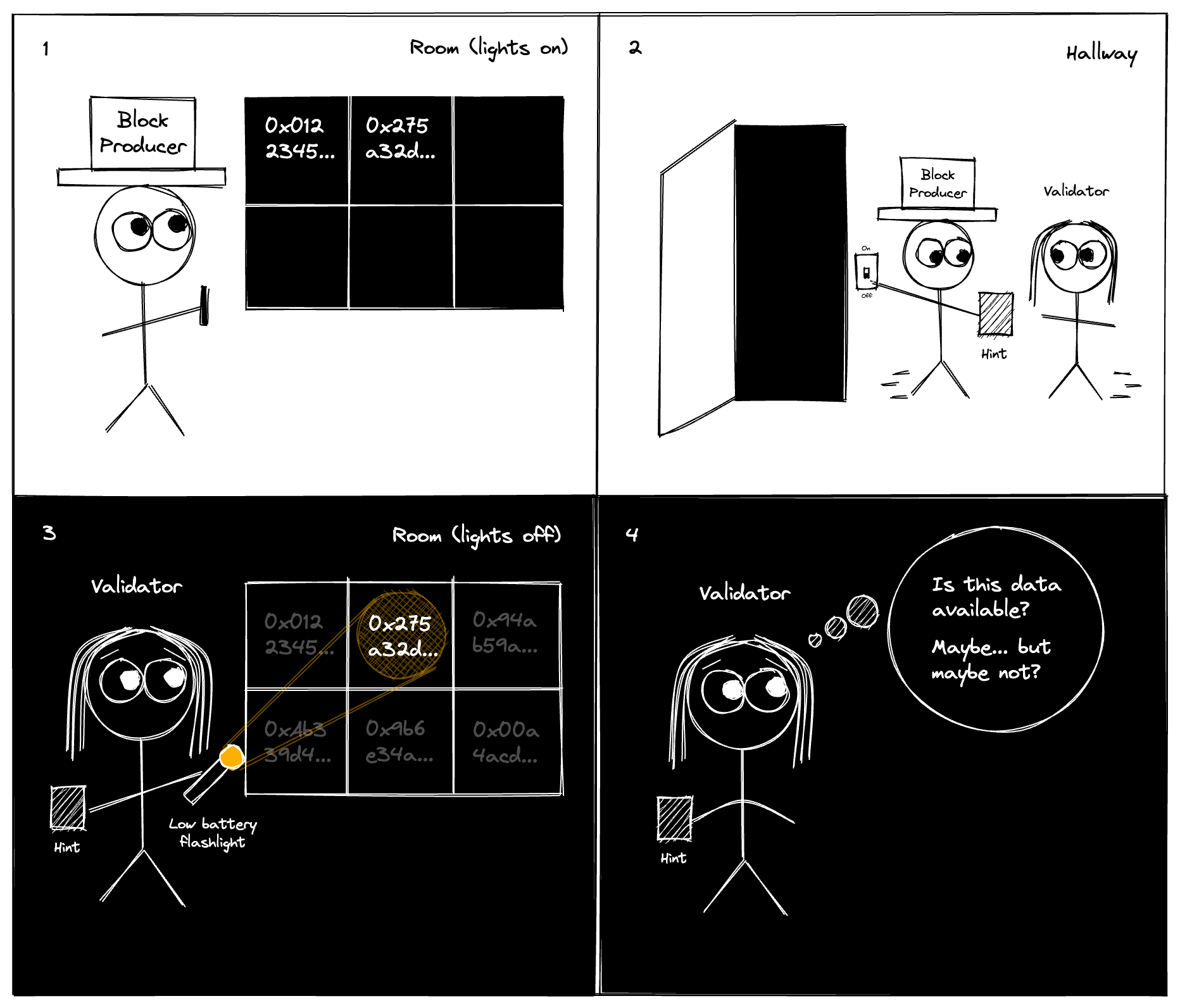
Notes:
I really like this comic from the paradigm article about Data Availability Sampling. But it works for our case as well with data sharding.
Erasure coding
The goal:
- Encode data of K chunks into a larger encoded data of N chunks
- Any K-subset of N chunks can be used to recover the data
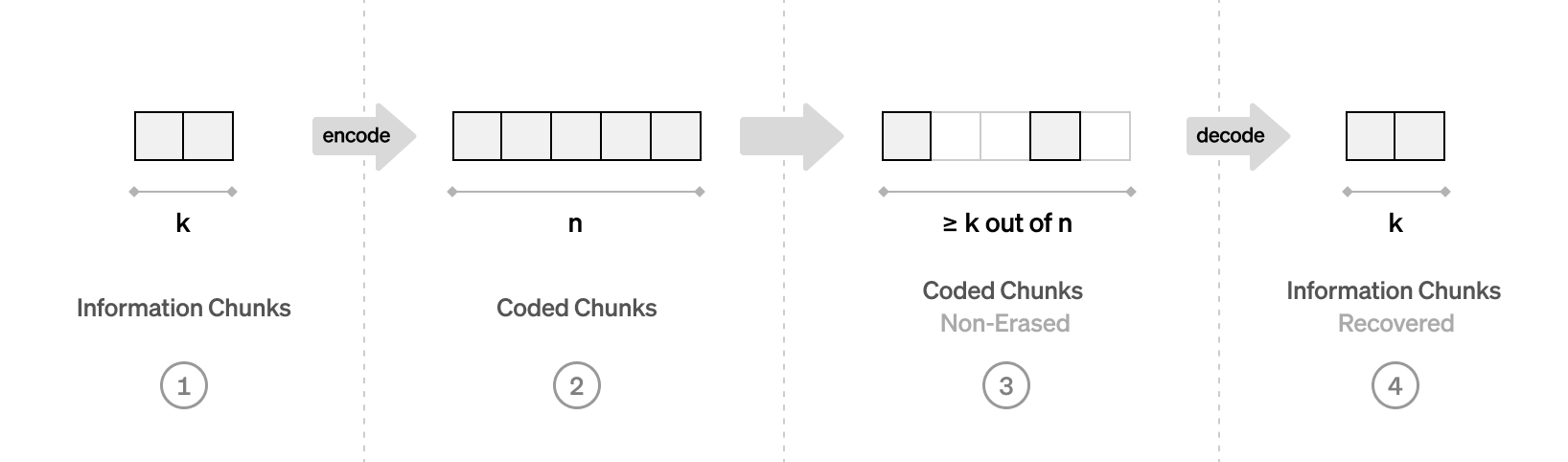
---v
In code
#![allow(unused)] fn main() { type Data = Vec<u8>; pub struct Chunk { pub index: usize, pub bytes: Vec<u8>, } pub fn encode(_input: &Data) -> Vec<Chunk> { todo!() } pub fn reconstruct(_chunks: impl Iterator<Item = Chunk>) -> Result<Data, Error> { todo!() } }
Polynomials

---v
Polynomials: Line

---v
Even More Polynomials
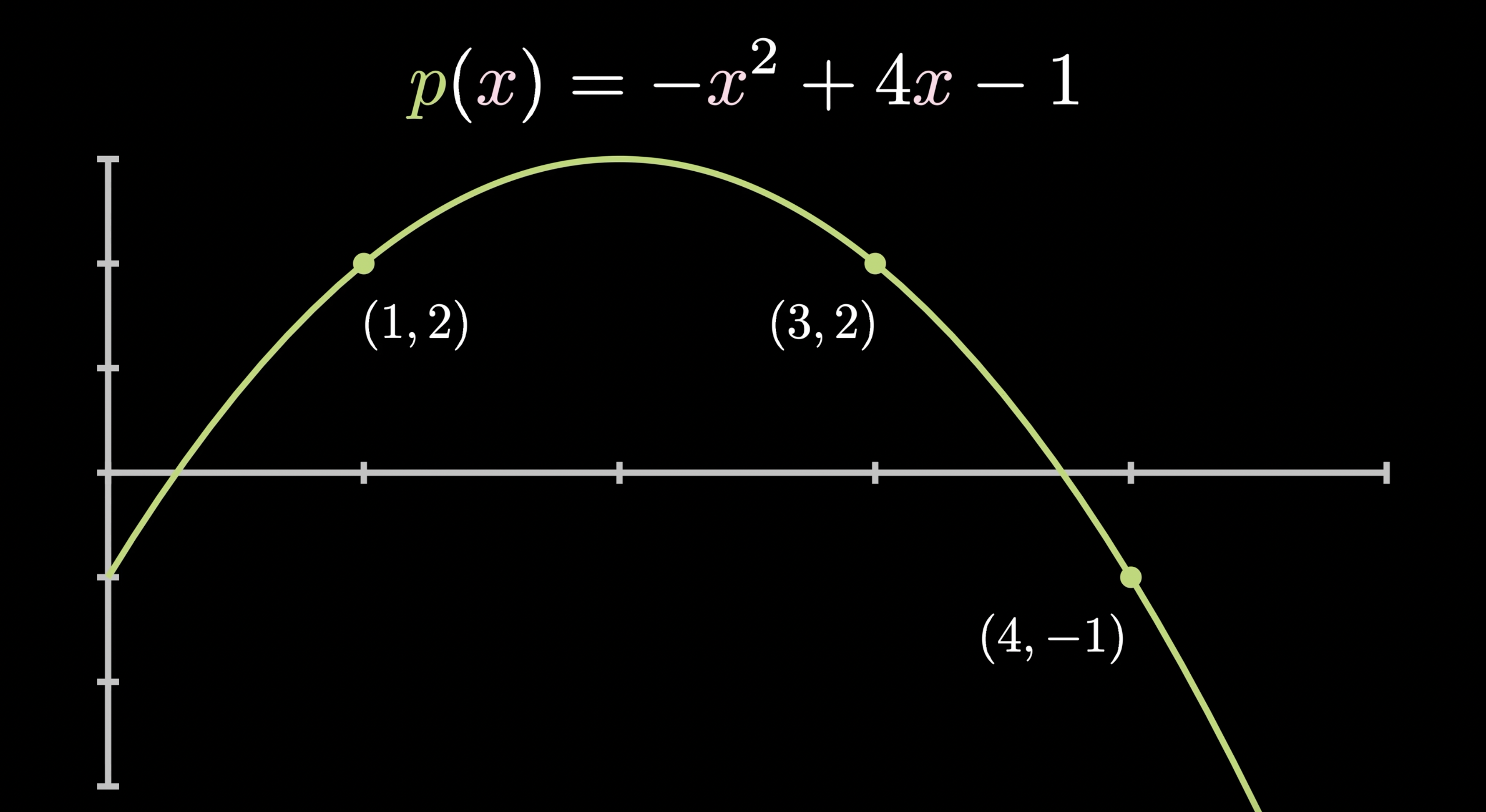
---v
Polynomial we need
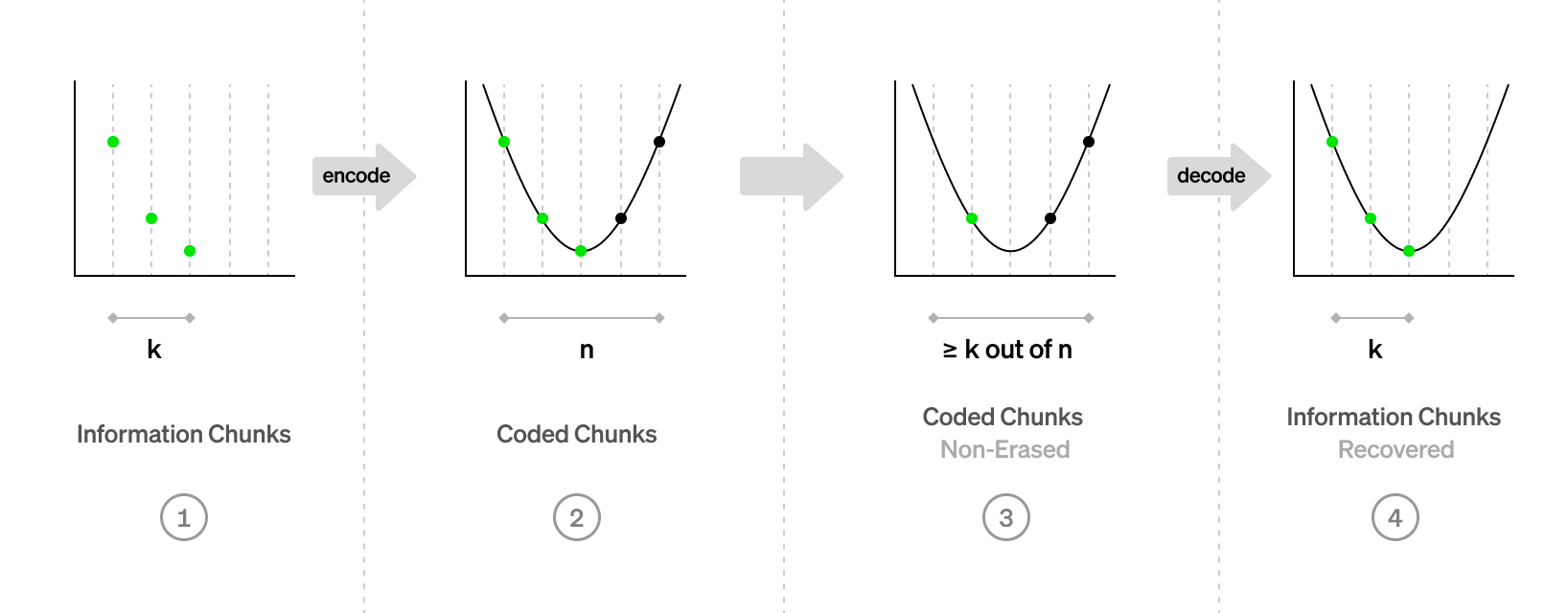
We want to have a polynomial, such that:
$$ p(x_i) = y_i$$
Notes:
Question: what is x_i and y_i wrt to our data?
Lagrange interpolating polynomial
$$ \ell_j(x) = \frac{(x-x_0)}{(x_j-x_0)} \cdots \frac{(x-x_{j-1})}{(x_j-x_{j - 1})} \frac{(x-x_{j+1})}{(x_j-x_{j+1})} \cdots \frac{(x-x_k)}{(x_j-x_k)} $$
$$ L(x) = \sum_{j=0}^{k} y_j \ell_j(x) $$
Reed-Solomon codes
Congrats! You've just learned Reed-Solomon encoding (almost).
Actual Reed-Solomon codes are defined over finite-fields.
It can detect and correct combinations of errors and erasures.
Notes:
The simplest example of a finite field is arithmetic mod prime number. Computers are quite bad at division by prime numbers. Reed-Solomon codes are used in CDs, DVDs, QR codes and RAID 6.
---v
Reed-Solomon with Lagrange interpolation
- Divide the data into elements of size $P$ bits.
- Interpret the bytes as (big) numbers $\mod P$.
- Index of each element is $x_i$ and the element itself is $y_i$.
- Construct the interpolating polynomial $p(x)$ and evaluate it at additional $n - k$ points.
- The encoding is $(y_0, ..., y_{k-1}, p(k), ... p(n - 1))$ along with indices.
Notes:
How do we do reconstruction?
Polkadot's Data Availability Protocol
- Each PoV is divided into $N_{validator}$ chunks
- Validator with index i gets a chunk with the same index
- Validators sign statements when they receive their chunk
- Once we have $\frac{2}{3} + 1$ of signed statements,
PoV is considered available - Any subset of $\frac{1}{3} + 1$ of chunks can recover the data
Notes:
The total amount of data stored by all validators is PoV * 3. With 5MB PoV and 1k validators, each validator only stores 15KB per PoV. With this protocol, we've killed two birds with one stone!
CandidateIncluded
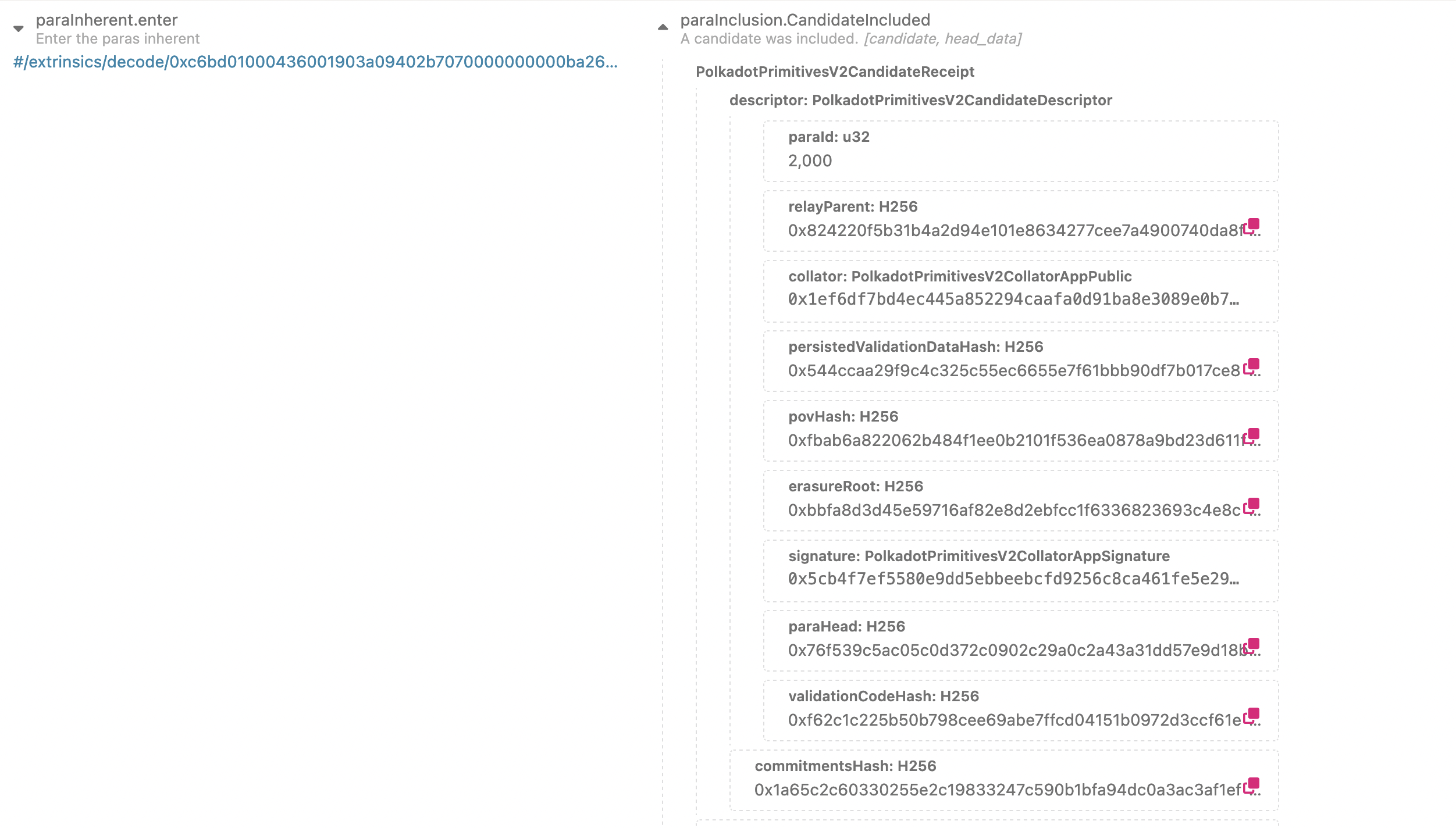
Availability Bitfields

Notes:
Each validator actually signs a statement per relay chain block, not per PoV to reduce the number of signatures. These statements are gossiped off-chain and included in a block in a ParachainsInherent.
Challenge 1
How does a validator know if a chunk corresponds to the committed data?

---v
Not that Merkle!

Challenge 2
How do we know if what can be reconstructed from chunks is the same data that was encoded with Reed-Solomon?
- Polkadot uses approval-voting/disputes mechanism for that
- Celestia uses Fraud Proofs
- Danksharding uses KZG commitments
Data Availability Sampling
Ethereum (Danksharding) and Celestia adopt an approach of Data Availability Sampling, where each light client makes its own judgement of availability by sampling and distributing a few random chunks.
This can eliminate honest majority assumption!
This approach guarantees there's at least one honest full nodes that has the data with high probability.
Safety of Polkadot's protocol
If we have at most $f$ out of $3f + 1$ malicious + offline validators, then if the data is marked as available, it can be recovered.
What if that assumption is broken?
If $2f + 1$ are malicious, every PoS is doomed anyway.
Notes:
We'll see in the next lesson, how approval-voting can prevent unavailable blocks from being finalized even with $>f$ malicious nodes.
2D Reed-Solomon Encoding
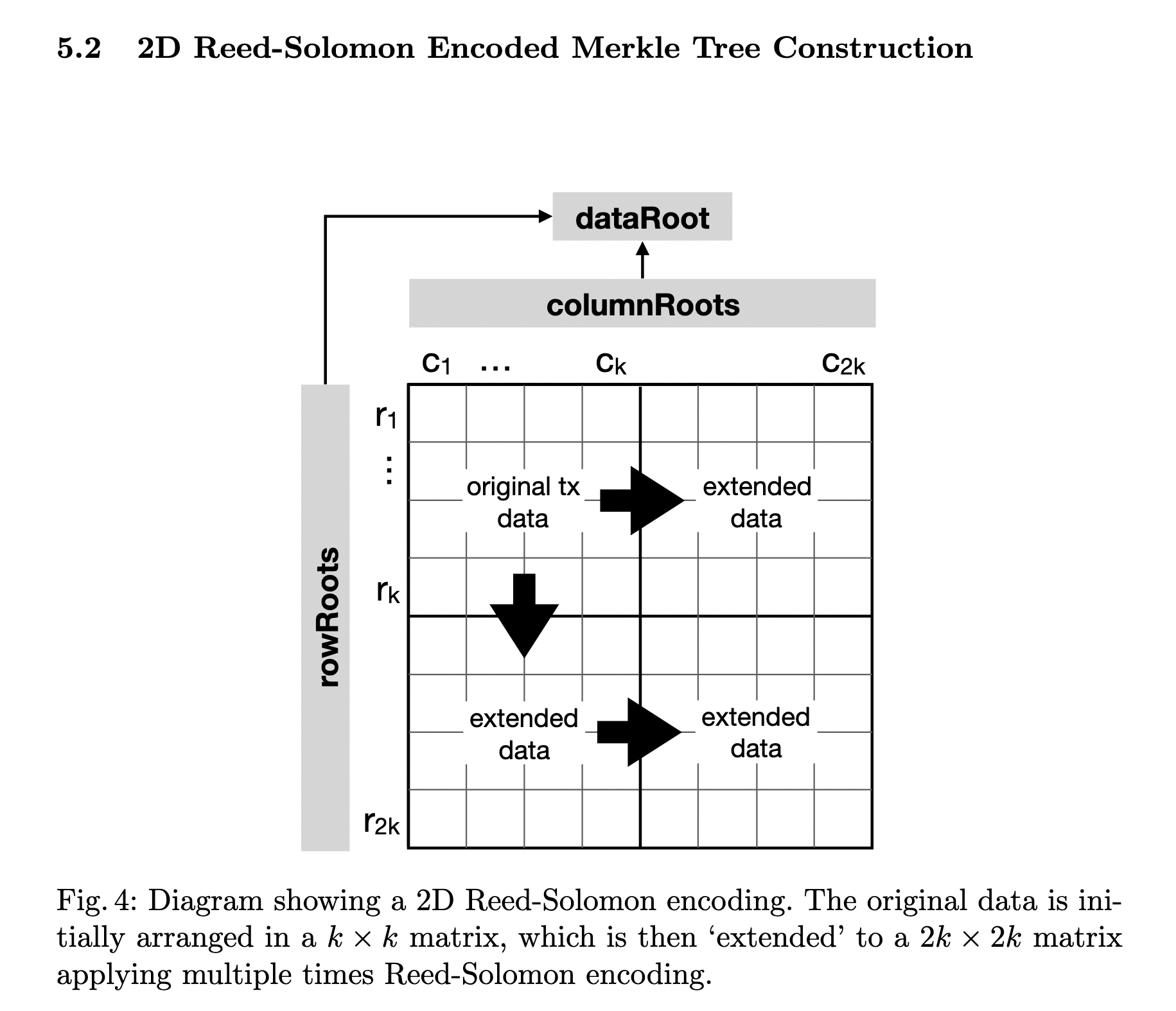
Notes:
The approach of 2D Reed-Solomon Encoding can reduce the size of a Fraud Proof used by Celestia. But it adds an overhead computationally and on the amount of data stored.
Comparison with other approaches
- Both Danksharding and Celestia use 2D encoding and DAS
- Celestia doesn't implement data sharding
- Data availability is only part of ensuring validity
- Polkadot's DA is able to process dozens of MB per second
Notes:
Danksharding is aiming at 1.3 MB/s and Celestia < 1 MB/s.
Ideas to Explore
- Data Availability Sampling for parachain
light clients and full nodes - Consider using KZG commitments
- Reducing the number of signatures to verify
- A Data Availability Parachain
Questions
Bonus
- Polkadot uses a field of size $2^{16}$ with efficient arithmetic
- Polkadot uses an FFT-based Reed-Solomon algorithm (no Lagrange)
References
- https://www.youtube.com/watch?v=1pQJkt7-R4Q
- https://notes.ethereum.org/@vbuterin/proto_danksharding_faq
- https://www.paradigm.xyz/2022/08/das
Cumulus
How to use the slides - Full screen (new tab)
Cumulus Deep Dive
Notes:
Cumulus is the glue which attaches substrate based chains to Polkadot, converting them into parachains.
Outline
- What is Cumulus?
- Cumulus and Para-Relay Communication
- How Cumulus Keeps a Parachain Node Informed
- Collation Generation and Advertisement
- How Cumulus Collations Enable Parablock Validation
- How Cumulus Enables Runtime Upgrades
What is Cumulus
A collection of code libraries extending a Substrate FRAME chain so that it can interface with the Polkadot API, run relay chain based consensus, and submit parachain blocks for validation.



Notes:
- Substrate is a framework for building blockchains
- But only "solo" chains
- Split into runtime/node side
- Both Polkadot and Cumulus extend substrate
- Polkadot provides APIs to collators
Review, Collators and Collations
What is a collator?
What is a collation?
What is the PoV?
Notes:
- Collator:
- Part of consensus authority set
- Author and submit collations
- Collation: Info necessary for validators to process and validate a parachain block.
- Collations include: upward and horizontal messages, new validation code, resulting head data, proof of validity, processed downward messages, and hrmp_watermark (relay block up to which all hrmp messages have been processed)
- PoV: The smallest bundle of information sufficient to validate a block. Will revisit in more detail.
Cumulus' Key Processes
- Follow relay "new best head" to update para "new best head"
- Follow relay finalized block to update para finalized block
- Request parablocks not shared by peers from relay (data recovery)
- Collation generation and announcement
Notes:
- New best head: New block at the head of the fork most preferred by BABE
Cumulus and Para-Relay Communication


Notes:
- How do these communication channels service our key processes?
Handling Incoming Relay Information
Before addressing collation generation let's first address the other three key Cumulus processes. These drive parachain consensus and ensure the availability of parachain blocks.
Together they keep parachain nodes up to date such that collating is possible.
Notes:
To recap, these key processes are:
- Follow relay "new best head" to update para "new best head"
- Follow relay finalized block to update para finalized block
- Request parablocks not shared by peers from relay (data recovery)
Consensus Mechanism
Parachain consensus is modified to:
- Achieve sequencing consensus
- Leave finality to the relay chain
Notes:
- Sequencing consensus: Decide on an accepted ordering of blocks and of transactions within a block
- Sequencing consensus requires that we update our knowledge of the new best head of the parachain. That way nodes are in agreement about which block to build on top of.
- Sequencing options: Aura consensus, tendermint style consensus
- When a parablock is included in a relay block that becomes finalized, that parablock is finalized by extension.
Import Driven Block Authoring
Collators are responsible for authoring new blocks, and they do so when importing relay blocks. Honest Collators will choose to author blocks descending from the best head.
#![allow(unused)] fn main() { // Greatly simplified loop { let imported = import_relay_chain_blocks_stream.next().await; if relay_chain_awaits_parachain_candidate(imported) { let pov = match parachain_trigger_block_authoring(imported) { Some(p) => p, None => continue, }; relay_chain_distribute_pov(pov) } } }
Notes:
parachain_trigger_block_authoringitself can decide if it wants to build a block.- e.g. the parachain having a block time of 30 seconds
- With asynchronous backing, parachain block authoring is untethered from relay block import.
Finality
To facilitate shared security, parachains inherit their finality from the relay chain.
#![allow(unused)] fn main() { // Greatly simplified loop { let finalized = finalized_relay_chain_blocks_stream.next().await; let finalized_parachain_block = match get_parachain_block_from_relay_chain_block(finalized) { Some(b) => b, None => continue, }; set_finalized_parachain_block(finalized_parachain_block); } }
Ensuring Block Availability
As a part of the parachains protocol, Polkadot makes parachain blocks available for several hours after they are backed.
- Why is this needed?
- Approvals
- Malicious collator
Notes:
- Approvers need the PoV to validate
- Can't just trust backers to distribute the PoV faithfully
- Malicious or faulty collators may advertise collations to validators without sharing them with other parachain nodes.
- Cumulus is responsible for requesting missing blocks in the latter case
Brief Aside, Candidate Receipt
The PoV is too big to be included on-chain when a parablock is backed, so validators instead produce a constant size Candidate Block Receipt to represent the freshly validated block and its outputs
Notes:
The Candidate Receipt contains mainly Hashes so the only valuable use is to be used to verify the correctness of known PoVs The Candidate Receipt only references a PoV, it does not substitute it
Malicious collator example



Notes:
- On a Parachain, a block only needs to be accepted by the relay chain validators to be part of the canonical chain,
- The problem is that a collator can send a block to the relay chain without distributing it in the Parachain network
- So, the relay chain could expect some parent block for the next block that no one is aware of
The Availability Process
- Erasure coding is applied to the PoV, breaking it into chunks
- 3x original PoV size, vs 300x to store copies
- 1/3 of chunks sufficient to assemble PoV
- 2/3 of validators must claim to have their chunks
Availability Outcome

Collation Generation and Advertisement
Collation Generation
The last of our key processes
- Relay node imports block in which parachain's avail. core was vacated
CollationGenerationrequests a collation from the collator
- Parachain consensus decides whether this collator can author
- Collator proposes, seals, and imports a new block
- Collator bundles the new block and information necessary to process and validate it, a collation!
Notes:
- Aura is current default parachain consensus, but this consensus is modular and changeable
Collation Distribution
Notes:
A subset of Para-Relay communication
From Collator to Relay Node and Parachain Nodes
- Sent from Collator, which owns both
CollatorServiceandParachainConsensus - Sent to tethered relay node
CollationGenerationsubsystem to be repackaged and forwarded to validators - Sent to parachain node import queues
#![allow(unused)] fn main() { let result_sender = self.service.announce_with_barrier(block_hash); tracing::info!(target: LOG_TARGET, ?block_hash, "Produced proof-of-validity candidate.",); Some(CollationResult { collation, result_sender: Some(result_sender) }) }
How Cumulus Collations Enable Parablock Validation
What is Runtime Validation?
- The relay chain ensures that every parachain block follows the rules defined by that parachain's current code.
- Constraint: The relay chain must be able to execute runtime validation of a parachain block without access to the entirety of that parachain's state



- Building Blocks to make this possible, the PVF and PoV, are delivered within collations
Parachain Validation Function - PVF
- The current STF of each Parachain is stored on the Relay Chain, wrapped as a PVF
#![allow(unused)] fn main() { /// A struct that carries code of a parachain validation function and its hash. /// /// Should be cheap to clone. #[derive(Clone)] pub struct Pvf { pub(crate) code: Arc<Vec<u8>>, pub(crate) code_hash: ValidationCodeHash, } }
- New state transitions that occur on a parachain must be validated against the PVF
Notes:
The code is hashed and saved in the storage of the relay chain.
Why PVF Rather than STF?

- The PVF is not just a copy paste of the parachain Runtime
- The PVF contains an extra function,
validate_block
WHY!?
Notes:
PVF not only contains the runtime but also a function validate_block needed to interpret all the extra information in a PoV required for validation.
This extra information is unique to each parachain and opaque to the relay chain.
Validation Path Visualized


Notes:
The input of the runtime validation process is the PoV and the function called in the PVF is 'validate_block', this will use the PoV to be able to call the effective runtime and then create an output representing the state transition, which is called a CandidateReceipt.
What Does validate_block Actually Do?
- The parachain runtime expects to run in conjunction with a parachain client
- But validation is occurring in a relay chain node
- We need to implement the API the parachain client exposes to the runtime, known as host functions
- The host functions most importantly allow the runtime to query its state, so we need a light weight replacement for the parachain's state sufficient for the execution of this single block
validate_blockprepares said state and host functions
Validate Block in Code
#![allow(unused)] fn main() { // Very simplified fn validate_block(input: InputParams) -> Output { // First let's initialize the state let state = input.storage_proof.into_state().expect("Storage proof invalid"); replace_host_functions(); // Run Substrate's `execute_block` on top of the state with_state(state, || { execute_block(input.block).expect("Block is invalid") }) // Create the output of the result create_output() } }
But where does
storage_proofcome from?
Notes:
We construct the sparse in-memory database from the storage proof and
then ensure that the storage root matches the storage root in the parent_head.
Host Function Replacement Visualized


Collation Revisited
#![allow(unused)] fn main() { pub struct Collation<BlockNumber = polkadot_primitives::BlockNumber> { /// Messages destined to be interpreted by the Relay chain itself. pub upward_messages: UpwardMessages, /// The horizontal messages sent by the parachain. pub horizontal_messages: HorizontalMessages, /// New validation code. pub new_validation_code: Option<ValidationCode>, /// The head-data produced as a result of execution. pub head_data: HeadData, /// Proof to verify the state transition of the parachain. pub proof_of_validity: MaybeCompressedPoV, /// The number of messages processed from the DMQ. pub processed_downward_messages: u32, /// The mark which specifies the block number up to which all inbound HRMP messages are processed. pub hrmp_watermark: BlockNumber, } }
Notes:
Code highlighting:
- CandidateCommitments: Messages passed upwards, Downward messages processed, New code (checked against validation outputs)
- head_data & PoV (the validation inputs)
Proof of Validity (Witness Data)
- Acts as a replacement for the parachain's pre-state for the purpose of validating a single block
- It allows the reconstruction of a sparse in-memory merkle trie
- State root can then be compared to that from parent header
Example of Witness Data Construction


- Only includes the data modified in this block along with hashes of the data from the rest of the trie
- This makes up the majority of the data in a collation (max 5MiB)
Notes:
orange: Data values modified in this block green: Hash of the siblings node required for the pov white: Hash of the nodes that are constructed with orange and green nodes red: Unneeded hash blue: Head of the trie, hash present in the previous block header
Parablock Validation in Summary
#![allow(unused)] fn main() { // Very simplified fn validate_block(input: InputParams) -> Output { // First let's initialize the state let state = input.storage_proof.into_state().expect("Storage proof invalid"); replace_host_functions(); // Run `execute_block` on top of the state with_state(state, || { execute_block(input.block).expect("Block is invalid") }) // Create the output of the result create_output() } }
- Now we know where the storage_proof comes from!
- into_state constructs our storage trie
- Host functions written to access this new storage
Cumulus and Parachain Runtime Upgrades
- Every Substrate blockchain supports runtime upgrades
Problem
- What happens if PVF compilation takes too long?
- Approval no-shows
- In disputes neither side may reach super-majority
Updating a Parachain runtime is not as easy as updating a standalone blockchain runtime
Solution
The relay chain needs a fairly hard guarantee that PVFs can be compiled within a reasonable amount of time.
- Collators execute a runtime upgrade but it is not applied
- Collators send the new runtime code to the relay chain in a collation
- The relay chain executes the PVF Pre-Checking Process
- The first parachain block to be included after the end of the process applies the new runtime
Cumulus follows the relay chain, waiting for a go ahead signal to apply the runtime change
Notes:
https://github.com/paritytech/polkadot-sdk/blob/9aa7526/cumulus/docs/overview.md#runtime-upgrade
PVF Pre-Checking Process
- The relay chain keeps track of all the new PVFs that need to be checked
- Each validator checks if the compilation of a PVF is valid and does not require too much time, then it votes
- binary vote: accept or reject
- Super majority concludes the vote
- The state of the new PVF is updated on the relay chain
Notes:
Reference: https://paritytech.github.io/polkadot/book/pvf-prechecking.html
References
- 🦸 Gabriele Miotti, who was a huge help putting together these slides
- https://github.com/paritytech/polkadot-sdk/blob/9aa7526/cumulus/docs/overview.md
Questions
Polkadot Ecosystem and Economy
How to use the slides - Full screen (new tab)
Ecosystem and Economy
Ecosystem and Economy
This presentation will give you a high level overview of the ecosystem and economy of the Polkadot Network.
Unfortunately this presentation could never be fully exhaustive, but perhaps it will shed light on areas previously unknown.
Economy
The DOT Token

The DOT token can be in one of the following states:
- Transferable
- Locked (Frozen)
- Reserved (Held)
Reserved vs Locked Balance
- New terms "Frozen" and "Held" are not quite used in Polkadot yet...
- Both states belong to the user... but cannot be spent / transferred.
- Reserved balances stack on top of one another.
- Useful for user deposits, or other use cases where there is sybil concerns.
- Ex: Deposit for storing data on-chain,
- Locked balances can overlap each other.
- Useful when you want to use the same tokens for multiple use cases.
- Ex: Using the same tokens for both staking and voting in governance.
Storage Bloat
One blockchain scaling problem is storage bloat over time.
Consider the "cost" of storing data on Ethereum:
- A one time gas fee based on the amount of data stored.
- Once is it placed on the network, it lives there forever, with no additional costs.
- Over a long enough period of time, the cost of storage per time will reduce to zero.
Storage Deposits
To solve this problem, Polkadot additionally takes a storage deposit (in the form of Reserved Balance) for any data stored in the blockchain.
-
This deposit is returned to the user when the user removes the data from the chain.
-
This deposit can be quite extreme, since it is returned to the user, and can represent the impermanence or lack of "importance" of the data.
Dust Accounts & Existential Deposit
The most bloat-ful storage on most blockchains are user accounts:
-
Both Ethereum and Bitcoin are riddled with "dust accounts" which have such a small balance, they are not worth "cleaning up".
-
Polkadot solves this by having an "existential deposit" that all users must hold a minimum amount of DOT, else their account data will be cleaned up.
-
Existential deposit can be thought of as a storage deposit for account data.
DOT is a Utility Token

The DOT token serves multiple purposes to help the Polkadot network function:
- Staking
- Bonding for Parachain Slots / Execution Cores
- On-Chain Decision Making
- Value Bearing for Trading / Using
Ideal Usage of DOT Tokens

Approximately...
Notes:
- 50% Staking / Governance
- 30% Parachains
- 20% Tradable / Useable
DOT Inflation

DOT is currently configured to have a fixed inflation rate of 10% per year.
Newly minted tokens are distributed to stakers (validators / nominators) and the treasury.
Ideal Staking Rate
We cannot force / tell users how to use their tokens, so we encourage "ideal" behavior by associating DOT token usage to how inflation is distributed.
There’s a function that redirects some of the 10% inflation to the Treasury, instead of the stakers, when ideal_rate != staking_rate.
Token holders are financially incentivized to maximize their staking returns, and thus distribute their tokens appropriately.
DOT Inflation vs Staking
Blue: Inflation vs Staking Rate
Green: APY of Stakers vs Staking Rate
Black: Total Inflation vs Staking Rate
DOT Utility: Parachains
Polkadot provides many utilities, but arguably its most important utility is providing flexible, secure, and scalable blockspace.
Developers can purchase this blockspace as fixed-term or on-demand Parachains, only with the DOT token.
If you believe that flexible and secure blockspace has value, then you agree that DOT also has value.
Expected Parachain Costs
Back of the napkin math:
- ~1 Billion DOT
- 30% Locked Up for Parachains = 300 Million
- ~100 Parachain = 3 Million DOT per Parachain Slot
At equilibrium...
Parachain Economics Updates
There is a lot of ongoing discussion about updating the economics of Parachains.
Likely, these mechanics will update pretty soon, and continually over time.
DOT Utility: Staking
Given the existence of a value bearing token, it can be used to provide security to Polkadot:
-
If users want to provide security to the network, they can stake their tokens.
-
Stakers are rewarded for good behavior, and punished for bad behavior.
-
Punishments are aggressive enough that rational actors would never act maliciously.

Staking: Validators and Nominators
In the staking system, there are two roles:
- Validators: Those who run block producing / parachain validating nodes for Polkadot.
- Nominators: Users who place their tokens behind validators they think will perform their job well.
Validators (and their nominators) are rewarded based on work done for the network. Rewards may vary day to day, but should be consistent over long periods of time.

DOT Utility: Governance
The future of Polkadot is decided by token holders.
Polkadot has an on-chain governance system called OpenGov which is used to:
- Spend Treasury Funds
- Upgrade the Network
- Manage the Fellowship
- Support Parachain Teams
- etc...

Conviction Voting
Polkadot utilizes an idea called voluntary locking / conviction voting.
This allows token holders to increase their voting power by locking up their tokens for a longer period of time.
votes = tokens * conviction_multiplier
The conviction multiplier increases the vote multiplier by one every time the number of lock periods double.
| Lock Periods | Vote Multiplier | Length in Days |
|---|---|---|
| 0 | 0.1 | 0 |
| 1 | 1 | 7 |
| 2 | 2 | 14 |
| 4 | 3 | 28 |
| 8 | 4 | 56 |
| 16 | 5 | 112 |
| 32 | 6 | 224 |
Tracks
The OpenGov system has different voting tracks which have different levels of power, and proportionally different level of difficulty to pass.
Here are just some of the currently 15 tracks:
| ID | Origin | Decision Deposit | Prepare Period | Decision Period | Confirm Period | Min Enactment Period |
|---|---|---|---|---|---|---|
| 0 | Root | 100000 DOT | 2 Hours | 28 Days | 1 Day | 1 Day |
| 1 | Whitelisted Caller | 10000 DOT | 30 Minutes | 28 Days | 10 Minutes | 10 Minutes |
| 10 | Staking Admin | 5000 DOT | 2 Hours | 28 Days | 3 Hours | 10 Minutes |
| 11 | Treasurer | 1000 DOT | 2 Hours | 28 Days | 3 Hours | 1 Day |
| 12 | Lease Admin | 5000 DOT | 2 Hours | 28 Days | 3 Hours | 10 Minutes |
Approval and Support Curves
Each track has their own set of curves which determine if the proposal has passed or failed.
All votes will eventually resolve one way or another.
You can find these curves on the Polkadot JS Developer Console.
Example: Root
The origin with the highest level of privileges. Requires extremely high levels of approval and support for early passing. The prepare and enactment periods are also large.
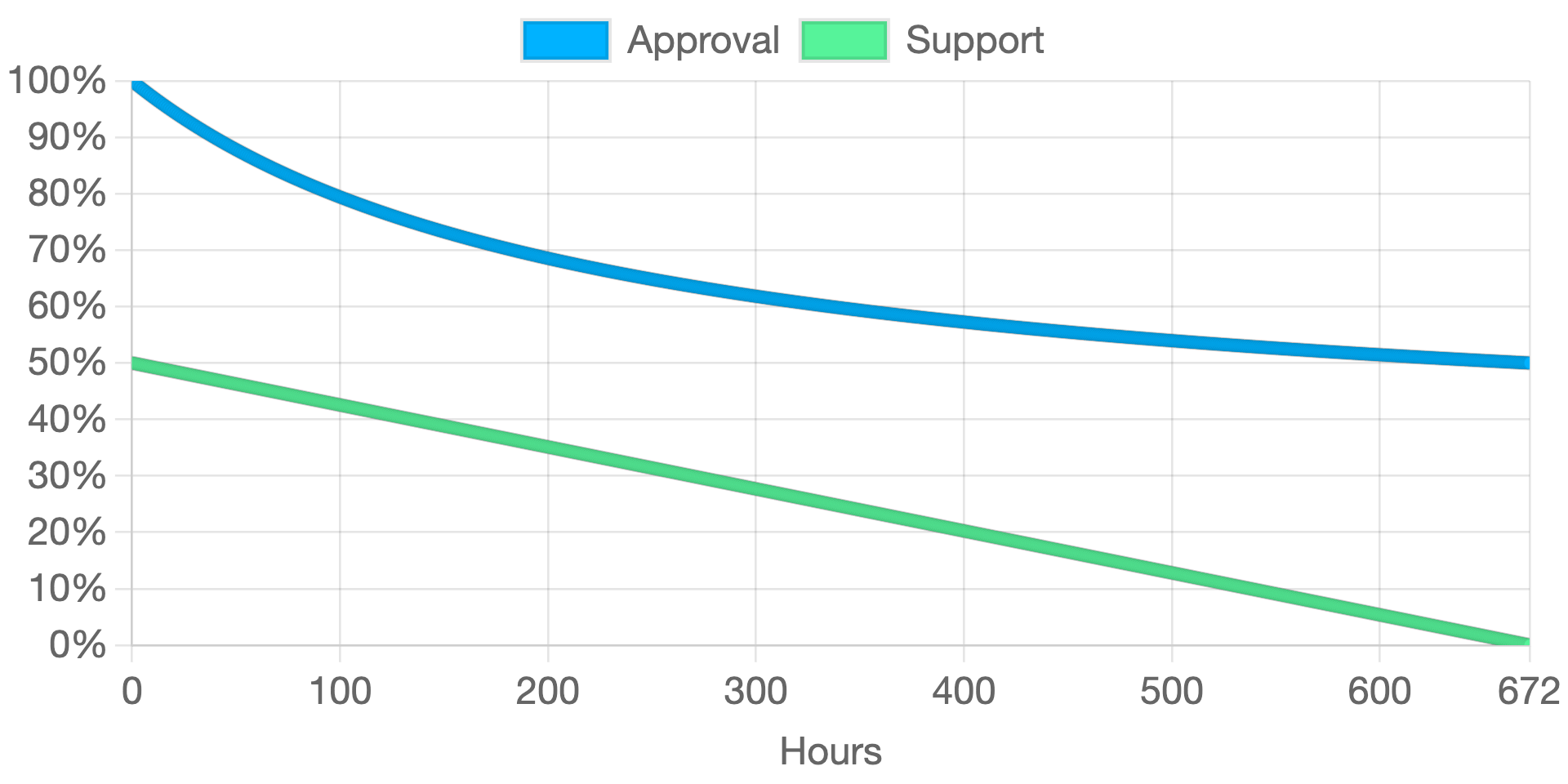
For instance, a referendum proposed in this track needs to amass 48.2% support (total network issuance) by the end of the first day with over 93.5% approval to be considered to be part of the confirm period.
Governance Token Mechanics
- DOT tokens are locked when you vote on a proposal.
- You can reuse your locked tokens across multiple proposals.
- Voting for one proposal does not affect your ability to vote on another proposal.
- You can also reuse staked tokens (which are also just locked).
- You can update your vote while the proposal is ongoing.
- If you used conviction voting, your tokens might be locked for long periods of time passed the end of a proposal.
Treasury
Polkadot has an on-chain treasury which is used to support permissionless and decentralized development of the network.
Treasury gets its funds through inefficiencies in the inflation curve, slashing, and by taking 80% transaction fees.
Treasury will automatically burn a 1% of its funds every spending period (24 days), placing pressure on spending the tokens.
Treasury Outlets
- Proposals: Instant payments to individuals approved by governance.
- Bounties: Multi-stage payments to individuals managed by governance and an appointed bounty curator.
- Tips: Small payments to individuals that can be made more easily through specific governance tracks.
The Polkadot Treasury currently has over 45,000,000 DOT.
Ecosystem
Alternative Polkadot Clients
The main Polkadot Client is built using Rust in Substrate.
However, other clients for Polkadot are under development:
- Kagome (C++17): https://github.com/qdrvm/kagome
- Gossamer (Go): https://github.com/ChainSafe/gossamer
Over time, this can help provide additional resilience to the network from software bugs.
Types of Parachains
- Polkadot System Chains
- Market Bought Parachains
Perhaps this list will grow once more agile core allocation systems are implemented.
System Chains
- System parachains contain core Polkadot protocol features, on a parachain rather than the Relay Chain.
- Polkadot uses its own parallel execution scaling technology scale itself.
- System parachains remove transactions from the Relay Chain, allowing more Relay Chain blockspace to be used for Polkadot's primary purpose: validating parachains.
- System Chains are allocated by governance.
Notes:
https://wiki.polkadot.network/docs/learn-system-chains
Current and Future System Chains
Current:
- Asset Hub: Allows creation and registration of tokens (FT & NFTs).
- Collectives: Acts as a place for coordination of the Polkadot DAOs.
- Bridge Hub: A chain for managing bridges to other networks.
- Encointer: A third-party built chain providing Proof of Personhood.
Future:
- Staking: Manage all the validator and nominator logic, rewards, etc...
- Governance: Manage all the various proposals and tracks.
- Eventually everything...
Notes:
https://wiki.polkadot.network/docs/learn-system-chains
Market Bought Parachains
Anyone with a great idea, and access to DOT token, can launch a parachain on Polkadot.
Dozens of teams from around the world have already done that, and are taking advantage of the features that Polkadot provides.

Notes:
https://polkadot.subscan.io/parachain
Ecosystem Verticals
While this list is not exhaustive, some of the verticals we have seen appear in Polkadot are:
- Smart Contract Chains
- Decentralized Finance (DeFi)
- Decentralized Social (DeSo)
- Decentralized Identity (DID) Services
- Tokenization (Real World Assets)
- Gaming
- NFTs (Music, Art, etc...)
- Bridges
- File Storage
- Privacy
Notes:
https://substrate.io/ecosystem/projects/
Wallets
Thanks to the treasury and Polkadot community, a number of different wallets have been developed across the ecosystem.
| Wallet | Platforms | Staking and Nomination Pools | NFTs | Crowdloans | Ledger support | Governance |
|---|---|---|---|---|---|---|
| Enkrypt | Brave, Chrome, Edge, Firefox, Opera, Safari | No, No | Yes | No | Yes | No |
| PolkaGate | Brave, Chrome, Firefox, Edge | Yes, Yes | No | Yes | Yes | Yes |
| SubWallet | Brave, Chrome, Edge, Firefox, iOs, Android | Yes, Yes | Yes | Yes | Yes | No |
| Talisman | Brave, Chrome, Edge, Firefox | Yes, Yes | Yes | Yes | Yes | No |
| Fearless Wallet | Brave, Chrome, iOS, Android | Yes, Yes | No | No | No | No |
| Nova Wallet | iOS, Android | Yes, Yes | Yes | Yes | Yes | Yes |
| Polkawallet | iOS, Android | Yes, Yes | No | Yes | No | Yes |
Notes:
Ledger Support w/ Metadata
Polkadot has been working with Ledger to provide rich support for the Polkadot network.
Users can get clear visibility into the transactions they are signing, and perform complicated tasks such as batching, multisigs, staking, governance, and more.

Block Explorers
- Polkadot-JS Apps Explorer - Polkadot dashboard block explorer. Supports dozens of other networks, including Kusama, Westend, and other remote or local endpoints.
- Polkascan - Blockchain explorer for Polkadot, Kusama, and other related chains.
- Subscan - Blockchain explorer for Substrate chains.
- DotScanner - Polkadot & Kusama Blockchain explorer.
- 3xpl.com - Fastest ad-free universal block explorer and JSON API with Polkadot support.
- Blockchair.com - Universal blockchain explorer and search engine with Polkadot support.
- Polkaholic.io - Polkadot & Kusama Blockchain explorer with API and DeFi support across 40+ parachains.
Notes:
https://wiki.polkadot.network/docs/build-tools-index#block-explorers
Governance Dashboards
The most popular ones at the moment:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Polkadot Forum
Notes:
https://forum.polkadot.network/
Fellowship
The Polkadot Fellowship is a decentralized technical collective on the Polkadot network designed to recognize, nurture, and incentivize contributors to the core Polkadot protocol.
Fellowship Manifesto
Notes:
https://github.com/polkadot-fellows
Fellowship Members
Notes:
https://polkadot.js.org/apps/?rpc=wss%3A%2F%2Fkusama-rpc.polkadot.io#/fellowship
RFCs
Questions
Register a Parachain
Follow along the docs here: https://docs.substrate.io/tutorials/build-application-logic/use-macros-in-a-custom-pallet/
Specifically you will need to:
- Setup a relay chain - https://docs.substrate.io/tutorials/build-a-parachain/prepare-a-local-relay-chain/
- Connect a parachain - https://docs.substrate.io/tutorials/build-a-parachain/connect-a-local-parachain/
The remainder are extra fun.
Cross-Chain Message Passing (XCMP)
How to use the slides - Full screen (new tab)
XCMP: Cross Chain Message Passing
Previous lectures discussed how Polkadot provides a secure environment for general code execution, and how it scales.
This lecture is about how processes communicate within that environment.




The Relay Chain Runtime maintains messaging queues for parachains.
It acts as a bridge for parachains to each other and to itself.
To do this, it adds additional limitations to candidates to ensure messaging rules are respected.
XCMP in Practice
XCMP vs XCM
XCMP is the data layer, while XCM is the language.
XCMP only focuses on the transmission of raw bytes between chains.
In this lesson we will focus only on XCMP.

Notes:
Communication requires a medium and a language to convey semantic meaning. XCMP is the medium, like sound or writing, rather than the language.

Downward and Upward channels are implicitly available.
XCMP Channels must be explicitly opened.
XCMP Channels are one-way, and for two-way communication two channels must be opened.
Using Messaging in Practice
This lesson is meant to communicate the underlying protocols and mechanics by which messages are sent and received.
In practice, these mechanisms are abstracted by the libraries you work with.
Revisiting PVFs and Outputs

#![allow(unused)] fn main() { fn validate_block(ValidationParams) -> Result<ValidationResult, ValidationFailed>; }
Validation Inputs
#![allow(unused)] fn main() { /// Parameters provided to a PVF for validation pub struct ValidationParams { /// The parent parachain block's Head Data pub parent_head: HeadData, /// The Proof-of-Validity. pub pov: PoV, /// The current relay-chain block number. pub relay_parent_number: RelayChainBlockNumber, /// The relay-chain block's storage root. pub relay_parent_storage_root: Hash, } }
Here, note that the relay_parent_storage_root allows us to handle Merkle Proofs of the Relay Chain state within the parachain.
Validation Outputs
#![allow(unused)] fn main() { /// Outputs of _successful_ validation of a parachain block. pub struct ValidationResult { /// The head-data produced as a result of execution. pub head_data: HeadData, /// Upward messages sent by the Parachain. pub upward_messages: Vec<UpwardMessage>, /// Outbound horizontal messages sent by the parachain. pub horizontal_messages: Vec<OutboundHrmpMessage>, /// Number of downward messages that were processed by the Parachain. /// /// It is expected that the Parachain processes them from first to last. pub processed_downward_messages: u32, /// The mark which specifies the block number up to which all inbound HRMP messages are processed. pub hrmp_watermark: RelayChainBlockNumber, // ... more fields } }
The ValidationResult is the output of successful PVF execution.
Validators are responsible for checking that the outputs are correct.
Unpacking Candidates
Candidates are posted to the relay chain in their entirety - everything except for the PoV.
Candidate Breakdown
- Descriptor: defines inputs to the validation function
- Commitments: expected outputs from the validation function
#![allow(unused)] fn main() { pub struct CandidateDescriptor { /// Relay chain block hash pub relay_parent: RelayChainBlockHash, /// The hash of the PoV pub pov_hash: Hash, /// Parent head data hash. pub parent_hash: Hash, /// The unique ID of the parachain. pub para_id: ParaId, // .. a few more fields } }
#![allow(unused)] fn main() { pub struct CandidateCommitments { /// Messages destined to be interpreted by the Relay chain itself. pub upward_messages: UpwardMessages, /// Horizontal messages sent by the parachain. pub horizontal_messages: HorizontalMessages, /// The head-data produced as a result of execution. pub head_data: HeadData, /// The number of messages processed from the DMQ. pub processed_downward_messages: u32, /// The mark which specifies the block number up to which all inbound HRMP messages are processed. pub hrmp_watermark: RelayChainBlockNumber, } }
Notice the similarities to ValidationOutputs?

(Polkadot runtime, simplified)
#![allow(unused)] fn main() { // Relay chain drains, parachain posts UpwardMessages: StorageMap<ParaId, Deque<Message>>; // Relay chain posts, parachain drains DownwardMessages: StorageMap<ParaId, Deque<Message>>; // (sender, receiver) // Sender posts, receiver drains HrmpChannels: StorageMap<(ParaId, ParaId), Deque<Message>>; }
(in Polkadot runtime, simplified, inclusion pallet)
#![allow(unused)] fn main() { fn process_backed_candidate(CandidateDescriptor, CandidateCommitments) { let para_id = descriptor.para_id; assert!(is_scheduled_on_empty_core(para_id)); assert!(descriptor.parent_hash == current_parachain_head); assert!(is_in_this_chain_recently(descriptor.relay_parent)); // fails if too many assert!(check_upward(para_id, commitments.upward_messages).is_ok()); // fails if too many or sending to a chain without a channel open. assert!(check_hrmp_out(para_id, commitments.hrmp_messages).is_ok()); // fails if attempting to process more messages than exist. assert!(check_downward(para_id, commitments.processed_downward_messages).is_ok()); // fails if the watermark is lower than the previous one. // updates all channels where this is a _receiver_. assert!(check_hrmp_in(para_id, commitments.hrmp_watermark).is_ok()); } }
Candidates can't be backed unless they pass all these checks.
The relay chain block author is responsible for selecting candidates which pass these checks.
Messages are not added to queues until the candidate is included (available).
This allows messages to be passed and acted upon before finality.
If the candidate turns out to be bad, the whole relay chain is forked to a point before messages were queued or acted upon.
Parachain Host Configuration
#![allow(unused)] fn main() { pub struct HostConfiguration { // ... many many fields } // In Polkadot runtime storage: CurrentConfiguration: StorageValue<HostConfiguration>; }
These variables are updated by governance.
The host configuration specifies things like:
- How many messages can be in the upward, downward, or HRMP queues for a parachain
- How many bytes can be in the upward, downward, or HRMP queues for a parachain
- How large a single message can be in the upward, downward, or HRMP queues.
What are messages?
Messages are just Vec<u8> byte strings.
The Relay Chain interprets upward messages as XCM.
The main takeaway for now is that it allows parachains to execute Calls on the Relay Chain.
#![allow(unused)] fn main() { // Act as a regular account with a deterministic ID based // on the Para ID. Origin::Signed(AccountId), // Act as the parachain itself, for calls which may be made by parachains. // Custom origin type added to the Relay Chain. Origin::Parachain(ParaId), }
Notes:
When parachains execute Calls on the Relay Chain, they have access to two origin kinds.
Note that this is only the case for the Relay Chain and parachains messages may be interpreted differently on other chains.
Parachains are free to interpret their incoming downward or HRMP messages however they like.
Respecting Limits
Problem: Parachain candidates can't be backed unless they respect the constraints on sending & receiving messages. How do they ensure this?
Solution: PVFs can read relay chain state to find out these limits. They include these proofs in the PoV.
#![allow(unused)] fn main() { /// Parameters provided to a PVF for validation pub struct ValidationParams { /// The relay-chain block's storage root. pub relay_parent_storage_root: Hash, pub pov: PoV, // ... } }
#![allow(unused)] fn main() { fn validate_block(ValidationParams) -> Result<ValidationResult, ValidationFailed> { // simplified let storage_proof = extract_storage_proof(pov); // state of queues, and subset of `HostConfiguration`. let (message_queues, current_config) = check_storage_proof( relay_parent_storage_proof, storage_proof, )?; // process incoming messages and send outgoing while respecting limits in config. } }
Opening Channels
The protocol for opening an HRMP channel is as follows:
- Chain A sends an upward message requesting a channel to Chain B
- Chain B receives a downward message notifying of the channel request
- Chain B sends an upward message accepting or rejecting the channel
- The channel is either opened or rejected in the Relay Chain as a result
There are no fees for XCMP messages, but every channel comes with a max_capacity and max_message_size.
Each channel comes with a corresponding deposit of DOT tokens to pay for the relay chain state utilization.
This deposit is returned when the channel is closed.

Message Queue Chains (MQC)
Let's take a small detour into a data structure used in DMP and XCMP.
Problem: Parachains should be able to cheaply determine the state of the entire message queue.
Problem: Relay Chain state proofs are expensive and should be minimized.
Solution: Message Queue Chains (MQC)
MQC Architecture

With MQCs, learning about all incoming messages for a single queue requires only one storage proof and one MQC entry (70 bytes) per incoming message.
UMP Configuration
#![allow(unused)] fn main() { pub struct HostConfiguration { /// Total number of individual messages allowed in the /// parachain -> relay-chain message queue. pub max_upward_queue_count: u32, /// Total size of messages allowed in the /// parachain -> relay-chain message queue. pub max_upward_queue_size: u32, /// The maximum size of an upward message that can be sent by a candidate. /// /// This parameter affects the size upper bound of the `CandidateCommitments`. pub max_upward_message_size: u32, /// The maximum number of messages that a candidate can contain. /// /// This parameter affects the size upper bound of the `CandidateCommitments`. pub max_upward_message_num_per_candidate: u32, // ... more fields } }
Validation Outputs for UMP
#![allow(unused)] fn main() { /// Outputs of _successful_ validation of a parachain block. pub struct ValidationResult { /// Upward messages sent by the Parachain. pub upward_messages: Vec<UpwardMessage>, // ... more fields } }
DMP Configuration
#![allow(unused)] fn main() { pub struct HostConfiguration { /// The maximum size of a message that can be put in a downward message queue. pub max_downward_message_size: u32, } }
Validation Outputs for DMP
#![allow(unused)] fn main() { /// Outputs of _successful_ validation of a parachain block. pub struct ValidationResult { /// Number of downward messages that were processed by the Parachain. /// /// It is expected that the Parachain processes them from first to last. pub processed_downward_messages: u32, // ... more fields } }
Notes:
Parachains can "process" messages simply by ignoring them. The Relay Chain doesn't care what parachains do with the messages. They can just be thrown out.
Validation Outputs for HRMP
#![allow(unused)] fn main() { /// Outputs of _successful_ validation of a parachain block. pub struct ValidationResult { /// Outbound horizontal messages sent by the parachain. pub horizontal_messages: Vec<OutboundHrmpMessage>, /// The mark which specifies the block number up /// to which all inbound HRMP messages are processed. pub hrmp_watermark: RelayChainBlockNumber, // ... more fields } pub struct OutboundHrmpMessage { /// The para that will get this message in its downward message queue. pub recipient: ParaId, /// The message payload. pub data: sp_std::vec::Vec<u8>, } }
HRMP Configuration
#![allow(unused)] fn main() { pub struct HostConfiguration { pub hrmp_max_parachain_outbound_channels: u32, pub hrmp_sender_deposit: Balance, pub hrmp_recipient_deposit: Balance, pub hrmp_channel_max_capacity: u32, pub hrmp_channel_max_total_size: u32, pub hrmp_max_parachain_inbound_channels: u32, pub hrmp_channel_max_message_size: u32, // more fields... } }
Questions
Zombienet
How to use the slides - Full screen (new tab)
Zombienet
What is Zombienet?
Zombienet is an integration testing tool that allows users to spawn and test ephemeral substrate based networks.
Why Zombienet?
Integration tests are always complex:
- Setup Configuration
- Port management
- Ready state off all artifacts
- Observability
- Leaking resources
---v
Friction to resolve
- Config flexibility
- Local environment
- Maintenance
- CI friendly
- Scaling
- Test-runner
---v
Goals
Hassle free setup
- Toml / json
- Nice defaults
- Templating lang.
Multiple envs
- Local
- k8s
- podman
Extensible
-
Custom assertions
-
Intuitive D.S.L
-
Templating lang.
Phases
Phases
Spawn
- Custom chain-specs
- Custom command
- Port-mapping
- Parachains registration
Test
- Custom D.S.L
- Multiple assertions
- Extensible
- Custom reporting
Zombienet Options
Notes:
- As binary: Binaries for Linux and MacOS are available in each release in Github.
- npm packages: cli, orchestrator, utils
- image: docker.io/paritytech/zombienet code is available in GitHub with the instructions on how to build and run Zombienet. (https://github.com/paritytech/zombienet)
---v
Download Zombienet
# macOS
curl -L https://github.com/paritytech/zombienet/releases/download/v1.3.63/zombienet-macos
-o ./zombienet
# linux
curl -L https://github.com/paritytech/zombienet/releases/download/v1.3.63/zombienet-linux
-o ./zombienet
# make executable
chmod +x zombienet
Let’s spawn a new network!
---v
But first, try manually…
- Create chain-spec (parachain)
parachain-template-node build-spec --chain local \
--disable-default-bootnode > /tmp/para.json
- Create chain-spec (relay chain)
polkadot build-spec --chain rococo-local \
--disable-default-bootnode > /tmp/relay.json
Notes:
Tutorials https://docs.substrate.io/tutorials/build-a-parachain/
---v
Add keys*
When not using --alice or --bob, you need to provide additional aura and grandpa keys and inject them into the keystore! (per node)
./target/release/polkadot \
key insert --base-path /tmp/node01 \
--chain /tmp/relay.json \
--scheme Sr25519 \
--suri <your-secret-seed> \
--password-interactive \
--key-type aura
./target/release/polkadot key insert \
--base-path /tmp/node01 \
--chain /tmp/relay.json \
--scheme Ed25519 \
--suri <your-secret-key> \
--password-interactive \
--key-type gran
Notes:
This step is optional if you use the dev accounts (e.g. alice, bob, charlie, dave, etc)
---v
- Start relay chain nodes
# create nodes dirs
mkdir -p /tmp/relay/{alice,bob}
./target/release/polkadot \
--alice \
--validator \
--base-path /tmp/relay/alice \
--chain /tmp/relay.json \
--port 30333 \
--ws-port 9944
./target/release/polkadot \
--bob \
--validator \
--base-path /tmp/relay/bob \
--chain /tmp/relay.json \
--port 30334 \
--ws-port 9945
Notes:
Why do we need to use different ports for Alice and Bob?
---v
- Start collator
# create nodes dirs
mkdir -p /tmp/para/alice
parachain-template-node \
--alice \
--collator \
--force-authoring \
--chain /tmp/para.json \
--base-path /tmp/para/alice \
--port 40333 \
--ws-port 8844 \
-- \
--execution wasm \
--chain /tmp/relay.json \
--port 30343 \
--ws-port 9977
---v
- Register ParaId on relay chain
- Modify parachain chain-spec and create raw format
- Generate genesis wasm and state
- Register parachain using sudo call
parachain-template-node build-spec --chain /tmp/para-raw.json \
--disable-default-bootnode --raw > /tmp/para-raw.json
parachain-template-node export-genesis-wasm --chain /tmp/para-raw.json \
para-2000-wasm
parachain-template-node export-genesis-state --chain /tmp/para-raw.json \
para-2000-genesis-state
Activity
Follow the connect a local parachain to launch your own network.
Non-trivial chore
- Error prone.
- Multiple commands.
- Port management.
- Multiple process.
---v
Zombienet network definition
Zombienet allow to define your network with a simple configuration file.
Notes:
https://paritytech.github.io/zombienet/network-definition-spec.html
---v
# examples/0001-small-network.toml
[relaychain]
default_image = "docker.io/parity/polkadot:latest"
default_command = "polkadot"
chain = "rococo-local"
[[relaychain.nodes]]
name = "sub"
[[relaychain.nodes]]
name = "zero"
[[parachains]]
id = 1001
cumulus_based = true
[parachains.collator]
name = "collator01"
image = "docker.io/parity/polkadot-parachain:latest"
command = "polkadot-parachain"
Notes:
---v
Spawn the network
./zombienet spawn examples/0001-small-network.toml
Activity
Try to launch a network with 2 parachains.
https://paritytech.github.io/zombienet/
Make the network config dynamic
The network definition supports using nunjucks templating language (similar to tera). Where {{variables}} are replaced with env vars and you can use all the built-in features.
[relaychain]
default_image = "{{ZOMBIENET_INTEGRATION_IMG}}"
default_command = "polkadot"
---v
Make the network config dynamic
Providers
Zombienet providers allow to spawn and test networks with in different environments.
---v
Kubernetes
- Used internally, integrated with the Grafana stack.
- You need to provide your infra stack.
Podman
- Automatically spawn and wire an instance of Grafana stack.
- Attach a jaeger instance if enabled in the network definition.
Native
- Allow to attach to a running Grafana stack. (wip)
Questions
Meet the Test-runner
Zombienet’s built-in test-runner allows users to use a simple D.S.L. to easily and intuitively write tests with a set of natural language expressions to make assertions.
---v
Built-in assertions
-
Prometheus: Query the exposed metrics/histograms and assert on their values.
-
Chain: Query/subscribe chain's storage/events.
-
Custom scripts: Run custom js scripts or bash scripts (inside the pod).
-
Node's logs: Match regex/glob patterns in the node's logs.
-
Integrations: Zombienet supports multiple integrations, like jaeger spans, polkadot introspector and the backchannel.
---v
Description: Small Network Paras
Network: ./0002-small-network-paras.toml
Creds: config # Only used with k8s
# well known functions
validator: is up # check all the validators in the group
validator-0: parachain 1000 is registered within 225 seconds
validator-0: parachain 1001 is registered within 225 seconds
# ensure parachains are producing blocks
validator-0: parachain 1000 block height is at least 5 within 300 seconds
validator-0: parachain 1001 block height is at least 5 within 300 seconds
# metrics
validator-0: reports node_roles is 4
validator-0: reports block height is at least 2 within 15 seconds
# logs (patterns are transformed to regex)
validator-1: log line matches glob "*rted #1*" within 10 seconds
validator-1: log line matches "Imported #[0-9]+" within 10 seconds
# system events (patterns are transformed to regex)
validator-2: system event contains "A candidate was included" within 10 seconds
validator-2: system event matches glob "*was backed*" within 10 seconds
# custom scripts
validator-0: js-script ./custom.js with "alice" within 200 seconds
validator-0: run ./custom.sh within 200 seconds
Notes:
First three lines are the header
Each line represents an assertion
Each assertion is executed sequentially
Assertions on a group check each node
within keyword allows to keep-trying until time expires
DSL extension
Learning a new DSL can be tedious, but if you are using vscode we develop an extension that can help you to write test easily.
Notes:
Show the extension link https://github.com/paritytech/zombienet-vscode-extension
Demo time
./zombienet -p native test examples/0002-small-network-paras.zndsl
Extensibility
Zombienet allow users to use the custom-js assertion to extend and run custom tests.
---v
Custom-js
# custom scripts
validator-0: js-script ./custom.js with "alice" within 200 seconds
async function run(nodeName, networkInfo, args) {
const { wsUri, userDefinedTypes } = networkInfo.nodesByName[nodeName];
const api = await zombie.connect(wsUri, userDefinedTypes);
const validator = await api.query.session.validators();
return validator.length;
}
module.exports = { run };
Notes:
Zombienet will load your script and call the run function.
Passing the node name, network info and an array of arguments from the assertion
Your function have access to the zombie object exposing utilities like connect, ApiPromise, Keyring, etc *
The assertions can validate the return value or the completions of your script.
*similar to the way that scripts are written in PolkadotJS apps - developer page (https://polkadot.js.org/apps/?rpc=wss%3A%2F%2Frpc.polkadot.io#/js)
More extensibility
Zombienet also allow users to use as a library to create their own interactions with the running network.
---v
As a Library
-
@zombienet/orchestrator module expose the start function as entrypoint.
-
Returning a network instance, with all the information about the running topology.
-
You can also use the test function passing a callback to run your test.
-
@zombienet/utils module expose misc utils functions like readNetworkConfig.
---v
import {start} from "@zombienet/orchestrator";
import { readNetworkConfig } from "@zombienet/utils";
const ZOMBIENET_CREDENTIALS = "";
// can be toml or json
const launchConfig = readNetworkConfig("../examples/0001-small-network.toml");
( async () => {
const network = await start(ZOMBIENET_CREDENTIALS, launchConfig, {
spawnConcurrency: 5,
});
// write your own test, `network` will have all the network info
})();
The road ahead...
🚧 🚧 Zombienet v2 (a.k.a SDK) is currently under construction 🚧 🚧
The SDK will provide a set of building blocks that users can combine to spawn and interact with the network and also a fluent API for crafting different topologies and assertions for the running network.
Notes:
SDK repo: https://github.com/paritytech/zombienet-sdk
Acknowledgement & Contributions
Zombienet take inspiration and some patterns from polkadot-launch and SimNet.
We encourage everyone to test it, provide feedback, ask question and contribute.
Questions
Activity
-
Launch a network with two validators and one parachain.
-
Add a test to ensure:
- block producing
- peers number
- node's role
Additional Resources!
Check speaker notes (click "s" 😉)
Notes:
Zombienet:
Asynchronous Backing (Shallow)
How to use the slides - Full screen (new tab)
Shallow Dive, Asynchronous Backing
Notes:
Hello again everyone
Today I'll be speaking to you about asynchronous backing, the new feature which delivers shorter parachain block times and an order of magnitude increase in quantity of Polkadot blockspace.
Lets get to it
Overview
- Synchronous vs asynchronous
- Why is asynchronous backing desirable?
- High level mechanisms of async backing
- The unincluded segment, and prospective parachains
- Async backing enabling other roadmap items
Synchronous Backing Simplified

Notes:
- The dividing line between the left and right is when a candidate is backed on chain
- Approvals, disputes, and finality don't immediately gate the production of farther candidates. So we don't need to represent those steps in this model.
Async Backing Simplified



Notes:
Our cache of parablock candidates allows us to pause just before that dividing line, on-chain backing
The Async Backing Optimistic Collator Assumptions
- "The best existing parablock I'm aware of will eventually be included in the relay chain."
- "There won't be a chain reversion impacting that best parablock."
The Stakes Are Low
Notes:
Best is determined by a process similar to the BABE fork choice rule. Brief BABE fork choice rule review
Advantages of Asynchronous Backing
- 3-5x more extrinsics per block
- Shorter parachain block times 6s vs 12s
- Resulting 6-10x boost in quantity of blockspace
- Fewer wasted parachain blocks
Notes:
- Collators have more time to fill each block
- Advance work ensures backable candidates for each parachain are present to be backed on the relay chain every 6 seconds
- Self explanatory
- Allow parachain blocks to be ‘reused’ when they don’t make it onto the relay chain in the first attempt
Parablock Validation Pipelining

Synchronous Backing, Another Look



Notes:
Image version 1:
- Now let's take a closer look at when each step of backing and inclusion takes place both with synchronous and asynchronous backing.
Image version 3:
- Whole process is a cycle of duration 12 seconds (2 relay blocks).
- No part of this cycle can be started for a second candidate of the same parachain until the first is included.
Async Backing, Another Look



Note:
Image version 1:
- Candidates stored in prospective parachains (detail on that later)
Image version 2:
- Now we see our relay block cycle.
- It is 6 seconds rather than 12.
- It completes on-chain backing for one candidate and inclusion for another each cycle.
Image version 3:
- Collation generation and off-chain backing are outside of the relay block cycle.
- Because of this, collators have the freedom to work several blocks in advance. In practice, even working 2-3 blocks in advance gives a collator ample time to fully fill blocks (PoV size 5MiB)
- Notice that a part of the collation generation context, the unincluded segment, comes from the collator itself.
The Unincluded Segment
- A parachain's record of all parablocks on a particular chain fork produced but not yet included
- Used to apply limitations when constructing future blocks
- Lives in the parachain runtime
- Viewed from the perspective of a new parablock under construction
Notes:
Limitation example, upward messages remaining before the relay chain would have to drop incoming messages from our parachain
Unincluded Segment

Notes:
- Segment added to as each new block is imported into the parachain runtime
- Segment shrinks when one of its ancestor blocks becomes included
- Maximum unincluded segment capacity is set both on the parachain and relay chain
Unincluded Segment

Notes:
UsedBandwidth:
- pub ump_msg_count: u32,
- pub ump_total_bytes: u32,
- pub hrmp_outgoing: BTreeMap<ParaId, HrmpChannelUpdate>,
Prospective Parachains
- The relay chain's record of all candidates on all chain forks from all parachains
- As if you folded all unincluded segments into one huge structure
- Used to store candidates and later provide them to the on-chain backing process
- Lives in the relay client (off chain)
Prospective Parachains Snapshot

Notes:
- Fragment trees only built for active leaves
- Fragment trees built per scheduled parachain at each leaf
- Fragment trees may have 0 or more fragments representing potential parablocks making up possible futures for a parachain's state.
- Collation generation, passing, and seconding work has already been completed for each fragment.
Async Backing Simplified
Notes:
Returning to our most basic diagram
- Q: Which structure did I leave out the name of for simplicity, and where should that name go in our diagram?
- Q: Which did I omit entirely?
Async Backing and Exotic Core Scheduling

Notes:
- What is exotic core scheduling?
- Multiple cores per parachain
- Overlapping leases of many lengths
- Lease + On-demand
- How does asynchronous backing help?
- The unincluded segment is necessary to build 2 or more parablocks in a single relay block
Resources
Questions
Light Clients and Unstoppable Apps
How to use the slides - Full screen (new tab)
Light clients
and
Unstoppable Apps
Traditional Web 2
Notes:
Before I proceed with anything, let's take a moment to see the current state of the majority of the World Wide Web as we know it.
Welcome to the realm of Web 2.0, where the majority of web applications currently reside. While I won't be roasting anyone, it's essential to recognize that platforms like Facebook, Twitter, WhatsApp, and many others fall under this category; (Describe image)
---v
The Web 3 vision
Notes:
This represents the vision of what web3 should aspire to become: a truly interconnected network where validators and end-users from all corners of the world can seamlessly connect, share information, and collaborate.
Now, show of hands:
- how many of you believe that we are close to achieving this vision at the moment?
- And how many think we still have a considerable distance to go?
---v
The Web 3 reality
Notes:
Let's take a closer look at the reality of the situation. As it stands, our entry into the blockchain network is channeled through a central access point, represented by a JSON-RPC node. This node serves as the gateway to access the entire blockchain network.
While many applications claim to be decentralized, we must ask ourselves, how truly decentralized are they?
Now, I want to emphasize one crucial point - and I encourage you to take a moment to reflect on it. I will pause there for a few seconds to let this sink in;
---v
Blockchain "decentralized” apps are still centralized
Notes:
I will pause there for a few seconds to let this sink in;
---v

Notes:
I will pause there for a few seconds to let this sink in;
Node types in the network
The type of each node depends on different characteristics:
- Validator: node configured to potentially produce blocks.
- JSON-RPC: node which gives public access to its JSON-RPC endpoint.
- Bootnode: node whose address can be found in the chain specification file (chainspec). Necessary to kick-off the network.
- Archive: stores the entire state of the chain at each block since block #0. Useful to access historical data.
- Light client: doesn’t store the entire state of the chain but requests it on demand.
Notes:
Before anything else – lets remember the node types in the network
Validator Nodes: These nodes are responsible for producing new blocks and validating transactions. They participate in the consensus mechanism and play a crucial role in securing the network.
JSON-RPC nodes: serve as an interface for developers and applications to interact with the blockchain by sending JSON-formatted requests and receiving JSON-formatted responses.
Bootnodes: Bootnodes are nodes with well-known addresses that serve as entry points for new nodes joining the network. They help new nodes discover and connect to other peers in the network.
Light Nodes: Light nodes are a lightweight version of full nodes that do not store the entire blockchain but rely on full nodes for transaction verification. They are useful for users who want to interact with the network without the need to download the entire blockchain.
(......After the Clicks!....)
Any combination of “validator”, “bootnode” and “JSON-RPC node” is possible, except for “light” and “archive” that are mutually incompatible.
---v
The reality of blockchains today
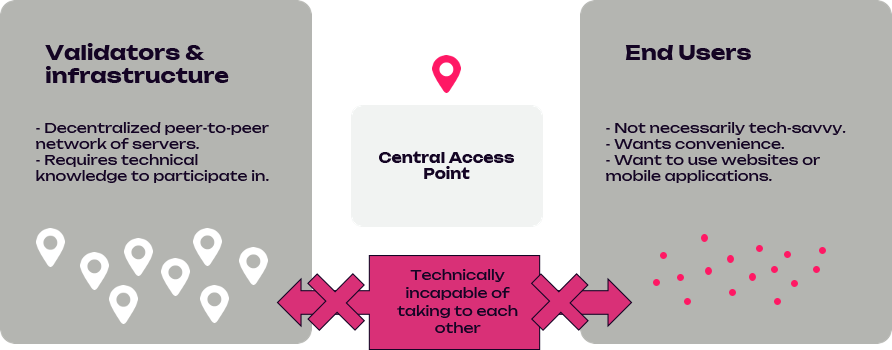
Notes:
Here is how this is happening in reality at the moment, or how one could possibly connect to the network today
(read slides)
Make a note that: For simplicity reasons from now on I will be using the word "UI" to refer to a client/user/app etc/ Ask: WHAT ARE THE WAYS to connect to the network from a UI like (e.g. polkadotJS apps or any custom one) today?
---v
USER-CONTROLLED NODE
Trustless: connects to multiple nodes, verifies everything
Notes:
(Read slides)
---v
PUBLICLY-ACCESSIBLE NODE
Notes:
(Read slides)
---v
Why this needs fixing?
Reliability
Possibility of censorship or hijacking
Frontrunning problem
Notes:
In the 3rd party case the user relies on the 3rd party node to connect to, in order to communicate with the network. (audience) With a show of hands Why this needs fixing? (pause and wait for possible answer)
- (we need) Reliability
- (there is a) Possibility of censorship or hijacking
- Front running is the act of placing a transaction in a queue with the knowledge of a future transaction
---v
The reality of blockchains we want
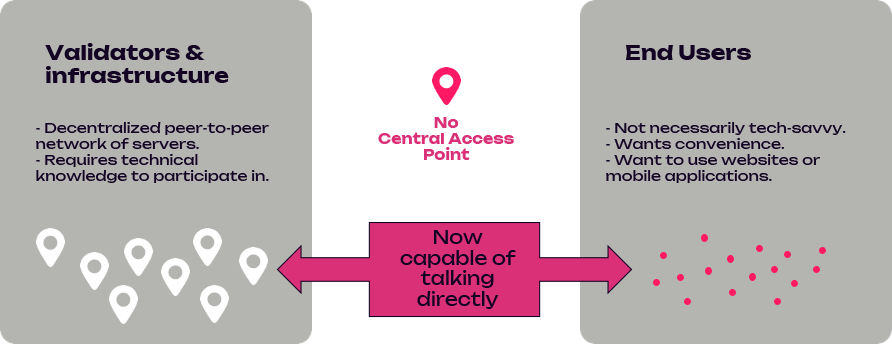
---v
The solution

Light Clients
What is a light client?
It's a client (a node)...
...but lighter!
Notes:
When I joined the team of substrate connect, I asked this same question. And the response I got was…. (*) Back then I was like… “Yeah – thanks I guess”
But that was actually true!
---v
What is a light client?
- It is a client that is lighter than a full node, in terms of memory consumption, number of threads, and code size;
- Allows a dApp to access and interact with a blockchain in a secure and decentralized manner without having to sync the full blockchain;
- It is a node that doesn’t store the entire state of the chain but requests it on demand;
- It connects and interacts with the network in a fully trust-less way with it;
Notes:
In the next slides we will explain "What is a light client" in a generic manner but also I will add some extra information around the Polkadot ecosystem solution that is implemented;
Bullet 1) A "light client" is a type of node implementation that allows applications to interact with the network, consuming fewer resources compared to full nodes, making them more suitable for resource-constrained devices like mobile phones, or light enough for running in browsers (see substrate connect);
Bullet 2) Instead of maintaining a complete copy of the blockchain, the node only carries a minimal amount of data necessary for its operations (e.g.chain specs). It relies on full nodes or other network participants to provide the additional information it needs;
Bullet 3) .... based on the request it either provides the response from existing data, if any, or propagates the request to a full node and returns the response;
Bullet 4) Light clients can synchronize with the blockchain more quickly since they only need to fetch recent data, using justifications (we will talk about it in a while), reducing the time needed to get up-to-date with the network (few seconds). They fetch less data from the network and consume less bandwidth. This is especially advantageous for users on limited data plans or slow internet connections ---v
Real-life example
Notes:
"Slow internet connections": lets see a real-life example. Time: Polkadot decoded 2022; Stage: Co-founder of Talisman wallet, Jonathan Dunne, takes the stage demo of our Light client solution (smoldot) is integrated in the wallet, and what are the benefits - using a very "questionable internet connection" which had a very bad day due to way-too-many-connected people; Once the talisman wallet loads up, pay attention to the spinners - Polkadot is loading with a light client while Kusama with the usual JSON-RPC method
Full video: https://www.youtube.com/watch?v=oaidhA5eL_8
---v
How does a light client know where to connect to
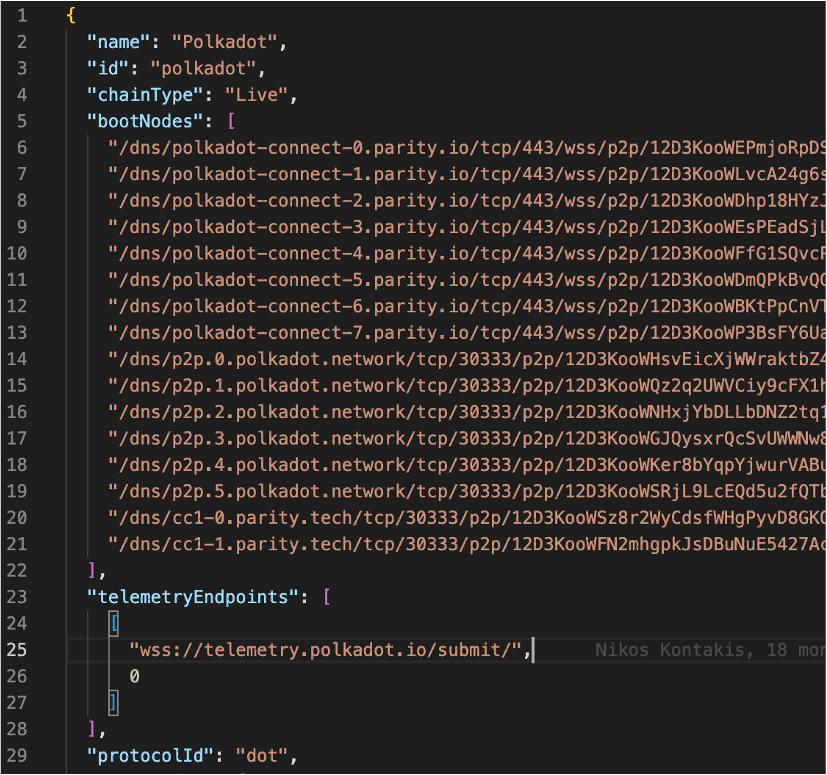
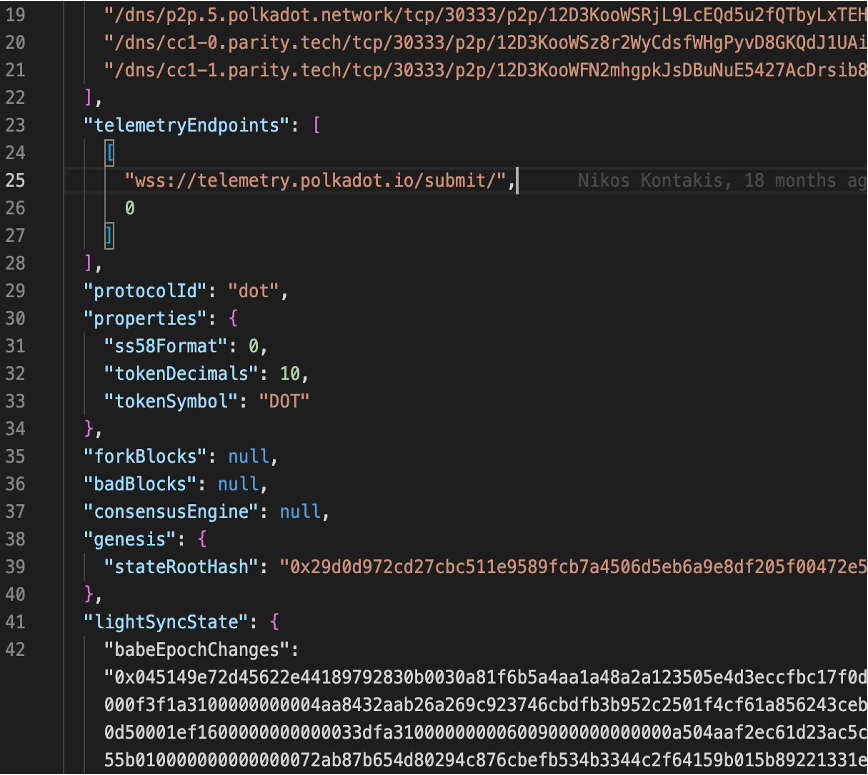
Notes:
As you probably already learned a chain specification is a configuration file that defines the parameters and initial settings for a blockchain network.
It serves as a blueprint for launching and running a new blockchain node, providing essential information to set up the network;
Our Substrate nodes can produce what is called a Chain spec which Smoldot then uses in order to spin up a light client node based on that chain-spec; (Show the chainspec on screen)
---v
How does a light client know what/who to trust
Notes:
As we know Substrate chains provides the concept of FINALITY which is VERY important for the light clients! Once a block has been finalized, it is guaranteed to always be part of the best chain. By extension, the parent of a finalized block is always finalized as well etc etc For finality Substrate/Polkadot nodes use the GrandPa algorithm. Authorized nodes, emit votes on the network, when 2/3rds or more have voted for a specific block, it effectively becomes finalized. These votes are been collected in what is called a justification
Justifications play a crucial role in providing security and validity guarantees for light clients. As said before, light clients are nodes that do not store blockchain's data but rely on other full nodes or the network to verify the blockchain's state and transactions. While light clients offer reduced resource requirements and faster synchronization, they face the challenge of trusting the information they receive from other nodes.
Justifications address this trust issue for light clients by providing cryptographic proofs of the finality and validity of blocks. When a block is justified, it means that it has been confirmed and agreed upon by a supermajority of validators, making it part of the finalized state of the blockchain.
It is also used by nodes who might not have received all the votes, or for example if they were offline, In order to verify the authenticity of the blocks;
A Light client receives these justifications and this way it verifies the authenticity of a block.
---v
---v
Full node
Light client

Notes:
Now, let's dive into the Polkadot solution of light clients for all Substrate chains.
As we progress through the slide, you might have come across or heard various terms and concepts related to light clients.
At this point, it's crucial to draw a clear distinction; Let's proceed with a more focused and detailed exploration of light clients in the Polkadot Ecosystem.
---v
Smoldot
light client implementation from scratch
rust
smoldot-light-js (/wasm-node) - npm/deno
smoldot (/lib) - Rust library
smoldot-light (/light-base)
smoldot-full-node (/full-node)
rust

https://github.com/smol-dot/smoldot/
Notes:
Smoldot - is the light client implementation from scratch - meaning, we did not make substrate lighter. It was rewritten from scratch, in rust - and it comes with:
- smoldot-light-js (/wasm-node): A JavaScript package that can connect to a Substrate-based chains as a light client. Works both in the browser and in NodeJS/Deno. This is the main component of this repository.
- smoldot (/lib): An unopinionated Rust library of general-purpose primitives that relate to Substrate and Polkadot. Serves as a base for the other components.
- smoldot-light (/light-base): A platform-agnostic Rust library that can connect to a Substrate-based chain as a light client. Serves as the base for the smoldot-light-js component explained above.
- smoldot-full-node (/full-node): A work-in-progress prototype of a full node binary that can connect to Substrate-base chains. Doesn't yet support many features that the official client supports.
Powered by Pierre Krieger (a.k.a. tomaka)
---v
Substrate Connect
https://github.com/paritytech/substrate-connect/
Notes:
- npm package
- rpc provider from polkadotJS
- Chrome and Mozilla extension
- Comes with 4 integrated "Well Known" chains (Kusama, Polkadot, Westend, Rococo) - which means these chains can be used without the need of providing chainspecs;
---v
On a diagram
Smoldot_Light_Client --> Custom_Code\n(with_JSON_RPC_API)
Custom_Code\n(with_JSON_RPC_API) --> UI_dAPP
Smoldot Light Client
- (As Substrate, it also) supports the new JSON-RPC protocol that has been developed;
- Light and fast enough so that it can be embedded into a mobile application or an application in general;
Notes:
- new JSON-RPC protocol: https://github.com/paritytech/json-rpc-interface-spec/
- As showcased in Decoded 2023 by Daan van der Plas: "Smoldot in Mobile Apps" (https://www.youtube.com/watch?v=Z7FiFHgotzE&feature=share)
We'll be using substrate connect's TS/JS code as pseudo-code for our examples
Publicly Accessible Node
The dApp (UI) connects to a third-party-owned publicly-accessible node client
Centralized and insecure: Publicly-accessible node can be malicious
Convenient: Works transparently
---v
So what one needs to do
- Find the web-socket url of a 3rd party node (JSON-RPC node) that one trusts;
- Add it to the code and use it;
---v
In your dApp
import { ApiPromise, WsProvider } from "@polkadot/api";
// Maybe some more code that does some magic here
const provider = new WsProvider("wss://westend-rpc.polkadot.io");
const api = await ApiPromise.create({ provider });
// Interact using polkadotJS API
const header = await api.rpc.chain.getHeader();
const chainName = await api.rpc.system.chain();
User-Controlled Node
The dApp (UI) connects to a node client that the user has installed on their machine
Secure Trustless: connects to multiple nodes, verifies everything
Inconvenient: Needs an installation process and having a node up and running, plus maintenance effort
---v
So what one needs to do
- Install dependencies
(e.g. rust, openssl, cmake, llvm etc);
- Clone from github the "polkadot" repo;
- Build the node locally;
- Start the node locally;
- Wait for the node to synchronize;
---v
...wait for the node to synchronize...
.......
..........
..................
......wait for it.......
..............................
ok
---v
In your dApp
import { ApiPromise, WsProvider } from "@polkadot/api";
// Maybe some more code that does some magic here
const provider = new WsProvider("wss://127.0.0.1:9944");
const api = await ApiPromise.create({ provider });
// Interact using polkadotJS API
const header = await api.rpc.chain.getHeader();
const chainName = await api.rpc.system.chain();
Light Client in the Browser
The uApp (UI) connects to an integrated light client
Secure Trustless: connects to multiple nodes, verifies everything
Convenient: Works transparently
---v
So what one needs to do
- Install and configure the light client inside the dApp
---v
With PolkadotJS API
import { ScProvider } from "@polkadot/rpc-provider/substrate-connect";
import * as Sc from '@substrate/connect';
// Maybe some more code that does some magic here
const provider = new ScProvider(Sc, Sc.WellKnownChain.westend2);
await provider.connect();
const api = await ApiPromise.create({ provider });
// Interact using polkadotJS API
const header = await api.rpc.chain.getHeader();
const chainName = await api.rpc.system.chain();
---v
Or even without PolkadotJS API
import { createScClient, WellKnownChain } from "@substrate/connect";
// Maybe some more code that does some magic here
const scClient = createScClient();
const mainChain = await scClient.addWellKnownChain(
WellKnownChain.polkadot,
jsonRpcCallback = (response) {
console.log(response);
}
);
// Communicate with the network
mainChain.sendJsonRpc(
'{"jsonrpc":"2.0","id":"1","method":"chainHead_unstable_follow","params":[true]}',
);
---v
Or even without PolkadotJS API
and with a Custom Chainspec
import { createScClient, WellKnownChain } from "@substrate/connect";
import myLovelyChainspec from './myLovelyChainspecFromSubstrateChain.json';
const myLovelyChainspecStringified = JSON.stringify(myLovelyChainspec);
// Maybe some more code that does some magic here
const scClient = createScClient();
const mainChain = await scClient.addChain(
myLovelyChainspecStringified,
jsonRpcCallback = (response) {
console.log(response);
}
);
// Communicate with the network
mainChain.sendJsonRpc(
'{"jsonrpc":"2.0","id":"1","method":"chainHead_unstable_follow","params":[true]}',
);
---v
Or even only with smoldot
import * as smoldot from "smoldot";
const chainSpec = new TextDecoder("utf-8").decode(fs.readFileSync('./westend-chain-specs.json'));
const client = smoldot.start({
maxLogLevel: 3, // Can be increased for more verbosity
forbidTcp: false,
forbidWs: false,
forbidNonLocalWs: false,
forbidWss: false,
cpuRateLimit: 0.5,
logCallback: (_level, target, message) => console.log(_level, target, message)
});
client.addChain({ chainSpec, disableJsonRpc: true });
console.log('JSON-RPC server now listening on port 9944');
console.log('Please visit: https://cloudflare-ipfs.com/ipns/dotapps.io/?rpc=ws%3A%2F%2F127.0.0.1%3A9944');
// Now spawn a WebSocket server in order to handle JSON-RPC clients.
// See JSON-RPC protocol: https://github.com/paritytech/json-rpc-interface-spec/
Some demo maybe…?

Known vulnerabilities
- Eclipse attacks (Full node & Light client)
- Long-range attacks (Full node & Light client)
- Invalid best block (Only Light client)
- Finality stalls (Mostly Light client)
Notes:
Stay with me - the next is the last but not the easiest part:
-
Eclipse attacks (full nodes and light clients both affected). Blockchain is a P2P network - and Smoldot tries to connect to a variety of nodes of this network (from the bootnodes). Imagine if all these nodes were to refuse sending data back, that would isolate smoldot from the network - The way that smoldot learns which nodes exist, is from the nodes themselves (bootnodes). If smoldot is only ever connected to malicious nodes, it won't ever be able to reach non-malicious nodes - if the list of bootnodes only contains malicious nodes, smoldot will never be able to reach any non-malicious node. If the list of bootnodes contains a single honest node, then smoldot will be able to reach the whole network. !!! this attack is effectively a denial-of-service, as it will prevent smoldot from accessing the blockchain!
-
Long-range attacks (full nodes and light clients both affected). If more than 2/3rds of the validators collaborate, they can fork a chain, starting from a block where they were validator, even if they are no longer part of the active validators at the head of the chain. If some validators were to fork a chain, the equivocation system would punish them by stealing their staked tokens. However, they cannot be punished if they unstake their tokens (which takes 7 days for Kusama or 28 days for Polkadot) before creating the fork.
If smoldot hasn't been online since the starting point of the fork, it can be tricked (through an eclipse attack) into following the false fork. In order to not be vulnerable, smoldot shouldn't stay offline for more than the unstaking delay time (as said 7 days for Kusama or 28 days for Polkadot) in a row. Alternatively, smoldot isn't vulnerable if the checkpoint provided in the chain specification, is not older than the unstaking delay.
Given that this attack -> requires the collaboration of many validators, -> is "all-in", -> is detectable ahead of time, -> it requires being combined with an eclipse attack, and that it doesn't offer any direct reward, it is considered not a realistic threat.
-
Invalid best block (light clients only). Light clients don't verify validity but only authenticity of blocks.
A block is authentic if it has been authored by a legitimate validator, at a time when it was authorized to author a block. A validator could author a block that smoldot considers as authentic, but that contains completely arbitrary data.
Invalid blocks aren't propagated by honest full nodes on the gossiping network, but it is possible for the validator to send the block to the smoldot instance(s) that are directly connected to it or its complicit. While this attack requires a validator to be malicious and that it doesn't offer any direct reward it is unlikely to happen, but it is still a realistic threat. For this reason, when using a light client, do not assume any storage data coming from a best, that hasn't been finalized yet to be accurate.
Once a block has been finalized, it means that at least 2/3rds of the validators consider the block valid. While it is still possible for a finalized block to be invalid, this would require the collaboration of 2/3rds of the validators. If that happens, then the chain has basically been taken over, and whether smoldot shows inaccurate data doesn't really matter anymore.
-
Finality stalls (mostly light clients). Because any block that hasn't been finalized yet can become part of the canonical chain in the future, a node, in order to function properly, needs to keep track of all the valid (for full nodes) or authentic (for light clients) non-finalized blocks that it has learned the existence of. Under normal circumstances, the number of such blocks is rather low (typically 3 blocks). If, however, blocks cease to be finalized but new blocks are still being authored, then the memory consumption of the node will slowly increase over time for each newly-authored block until there is no more memory available and the node is forced to stop. Substrate mitigates this problem by forcing blocks authors to gradually slow down the blocks production when the latest known finalized block is too far in the past. Since it is normally not possible for finality to stall unless there is a bug or the chain is misconfigured, this is not really an attack but rather the consequences of an attack. Full nodes are less affected by this problem because they typically have more memory available than a light client, and have the possibility to store blocks on the disk.
Questions
Blockchain Scaling - Monolithic and Homogeneous
How to use the slides - Full screen (new tab)
Blockchain Scaling
Monolithic and Homogeneous
Lesson format
- Two approaches:
- Historically, we move from protocols that are monolithic and homogeneous to ones that are modular and heterogeneous
- Structurally, we can compare in terms of security assumptions and design trade-offs
- First half covers theory, homogeneous sharding, shared security
- Second half is rollups and beyond
What do we mean by scaling?

- Increasing throughput: data executed through state transitions
- TPS:
- Widely stated
- Often gamed
- Individually signed user transactions (no inherents)
- Peak vs. sustained load
- sTPS used in Polkadot (no db caching)
- Not currently the driver of throughput needs (DeFi + NFT drops)
Horizontal vs. Vertical Scaling
- Vertical scaling: adding more resources per machine
- Horizontal scaling: adding more machines
Scalability Trilemma

- Why do we care about horizontal scaling for blockchains?
- Lower barrier of entry -> more decentralization
Vertical scaling approaches
- Adaptive responsiveness (HotStuff)
- Mempool optimization:
- Pipelining: building future blocks before previous ones have been included
- DAG-based (Narwhal)
- To avoid MEV (for Polkadot: Sassafras)
- Parallel execution
- UTXOs
- Move Language: STM with linear types
- For Polkadot: elastic scaling
Notes:
- https://dahliamalkhi.files.wordpress.com/2018/03/hot-stuff-arxiv2018.pdf
- https://arxiv.org/pdf/2305.13556.pdf
- https://arxiv.org/pdf/2105.11827.pdf
- https://eprint.iacr.org/2023/031.pdf
- https://move-book.com/
Restaking
- Existing validator sets (Cosmos Hub, Ethereum with Eigenlayer) can opt-in to validating other protocols using same bond
- Capital scaling, not throughput scaling
- All validators must validate all protocols in order to have the same security
Restaking
- Two arguments in favor (shared with Polkadot)
- Shared economic security against market buying tokens to attack PoS
- Reduces capital costs to validators, while increasing revenue sources -> security is much cheaper for client protocols
- Appchain thesis: flexible blockspace has advantages over generalized smart contract platforms (including for throughput)
Sharding
Sharding
- Term from traditional databases
- Definition: distributing over subsets of machines (committees)
- Execution vs. data sharding
Notes:
Problem Space: Byzantine Thresholds
- Typically can't assume f holds within committees
- Unless they're statistically representative
- Alternatively we rely on 1-of-n assumptions
Problem Space: Adaptive Corruption
- Easier to corrupt (DOS, bribe, etc.) small committees than entire validator set
- Must be sorted with strong on-chain randomness (e.g. VRFs not PoW hashes)
- Must be frequently rotated
- Weaker assumption: adaptive corruption isn't immediate
Problem Space: Cross-shard Messaging
- Imbalanced message queues (different with heterogeneous vs. homogeneous shards)
- Creates a dependency when shards are rolled back -> easier when finality is tied together and fast
- Undirected graph approach (Casper/Chainweb):
- Only allows messaging between adjacent shards
- Adjacent shards are validated together
Solutions: 1-of-n assumptions
- Polkadot (eager)
- Optimistic rollups (lazy)
- Nightshade (Near)
- Optimistic homogeneous sharding
- Availability protocol based on Polkadot's
Notes:
Solutions:
Statistically Representative Committees
- Statistically representative committees (Omniledger, Polkadot with multiple relay chains)
- Very large validator sets (thousands)
- Large (hundreds) statistically representative committees
- Committees aren't rotated every block (weaker adaptive corruption assumption)
- 4f trust assumption in validator set -> 2f+1 in Committees
- Separate "beacon" chain for Sybil resistance
Notes:
Solutions: Validity proofs (zk-rollups)
- Cryptographic proofs of execution
- Asymmetry between proving and verifying times
- Proving is slow
- Verifying is fast and constant time
- Proofs are succinct, can go on chain
- Typically ZK proofs, but not necessary
State Channels, Plasma, and Beyond
State Channels
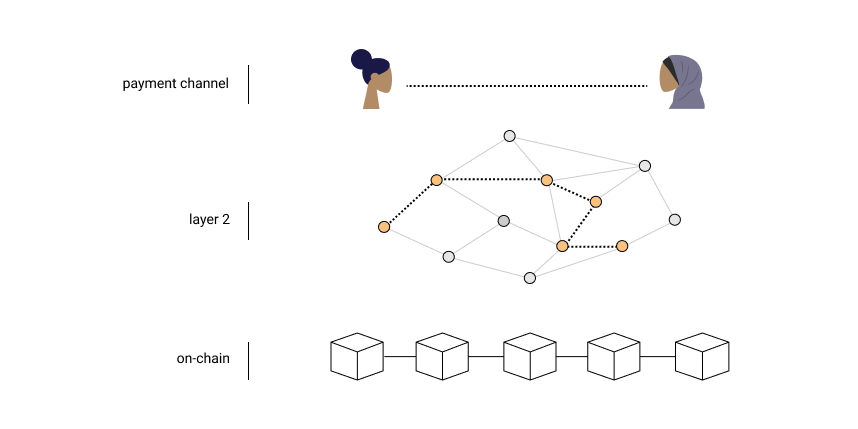
- Part of state is locked, updated off-chain between closed set of participants, then unlocked and committed to chain
- Payment channels, e.g. Lightning network, are a special case
- Composition between channels sharing parties
- Can be application-specific or generalized (e.g. Counterfactual)
Notes:
- https://vitalik.ca/general/2021/01/05/rollup.html
- https://www.jeffcoleman.ca/state-channels/
- https://lightning.network/lightning-network-paper.pdf
State Channels
- Greater liveness assumptions:
- The chain will accept stale state transitions as final
- Someone must be regularly online to submit later ones
- This can be outsourced to watchtower networks
- Typically challenge period after closing channel
State Channels
- Cannot be used for all kinds of operations
- Sending funds to new parties outside the channel
- State transitions with no owner (e.g. DEX operations)
- Account-based systems
Plasma
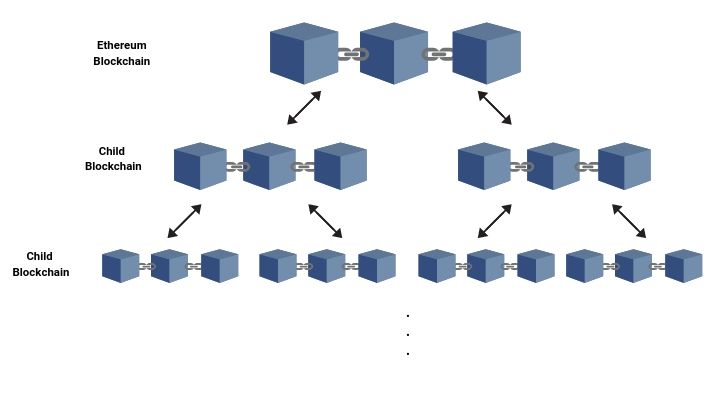
- "Ether + Lightning"
- Like state channels, but hashes published to L1 at regular checkpoints
- "Map-reduce" blockchains, PoS on top of PoW Ethereum
- Downsides:
- State transitions still need "owner"
- Still not ideal for account-based systems
- Mass exit problem in case of data unavailability
Notes:
Flavors of Plasma
- Plasma MVP: UTXO-based
- Plasma Cash: NFT-based -> only prove ownership of own coins
- Polygon: Plasma and PoS bridges
Notes:
- https://ethresear.ch/t/plasma-world-map-the-hitchhiker-s-guide-to-the-plasma/4333
- https://ethresear.ch/t/plasma-cash-plasma-with-much-less-per-user-data-checking/1298
- https://ethresear.ch/t/minimal-viable-plasma/426
The Life and Death of Plasma
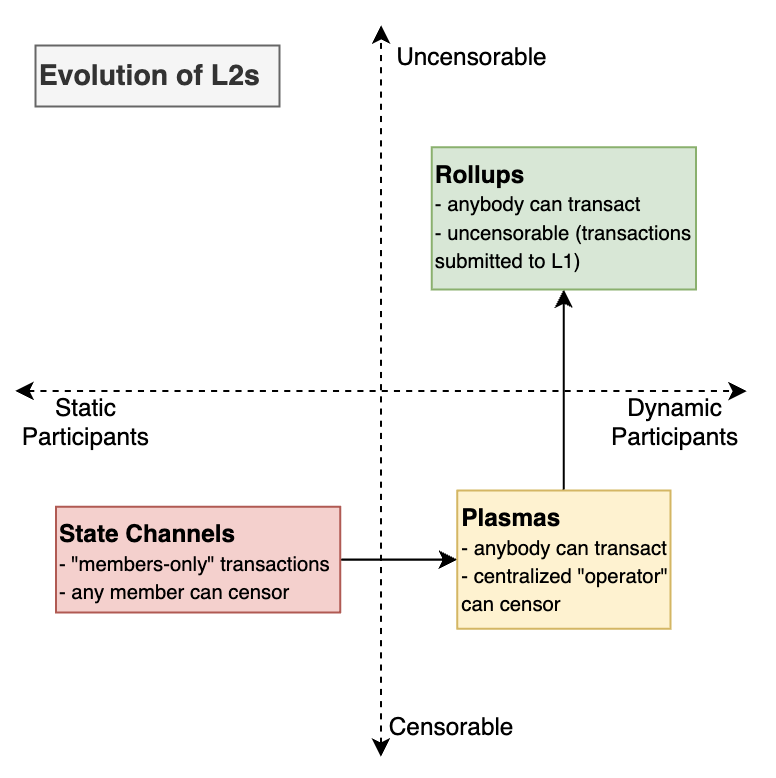
- 2017-2019: Plasma paper to the emergence of rollups
- zk-rollups
- Merged consensus
- Generalized fraud proofs
- Plasma Group becomes Optimism
Notes:
- https://medium.com/dragonfly-research/the-life-and-death-of-plasma-b72c6a59c5ad
- https://ethresear.ch/t/minimal-viable-merged-consensus/5617
Blockchain Scaling - Modular and Heterogeneous
How to use the slides - Full screen (new tab)
Blockchain Scaling
Modular and Heterogeneous
Modularity: decoupling roles of an L1
- Sequencing: ordering operations as input to STF
- Necessary, but always off-chain
- Ordering state transitions
- Definition of a blockchain
- In the case of L2s: commitments to state transitions (usually state roots) of other chains stored on L1 chain
- Executing state transitions
- By definition L2s move execution off-chain
- Data Availability
- Decoupling DA from ordering is often referred to as "modular blockchains" (Celestia)
Taxonomy of L2s
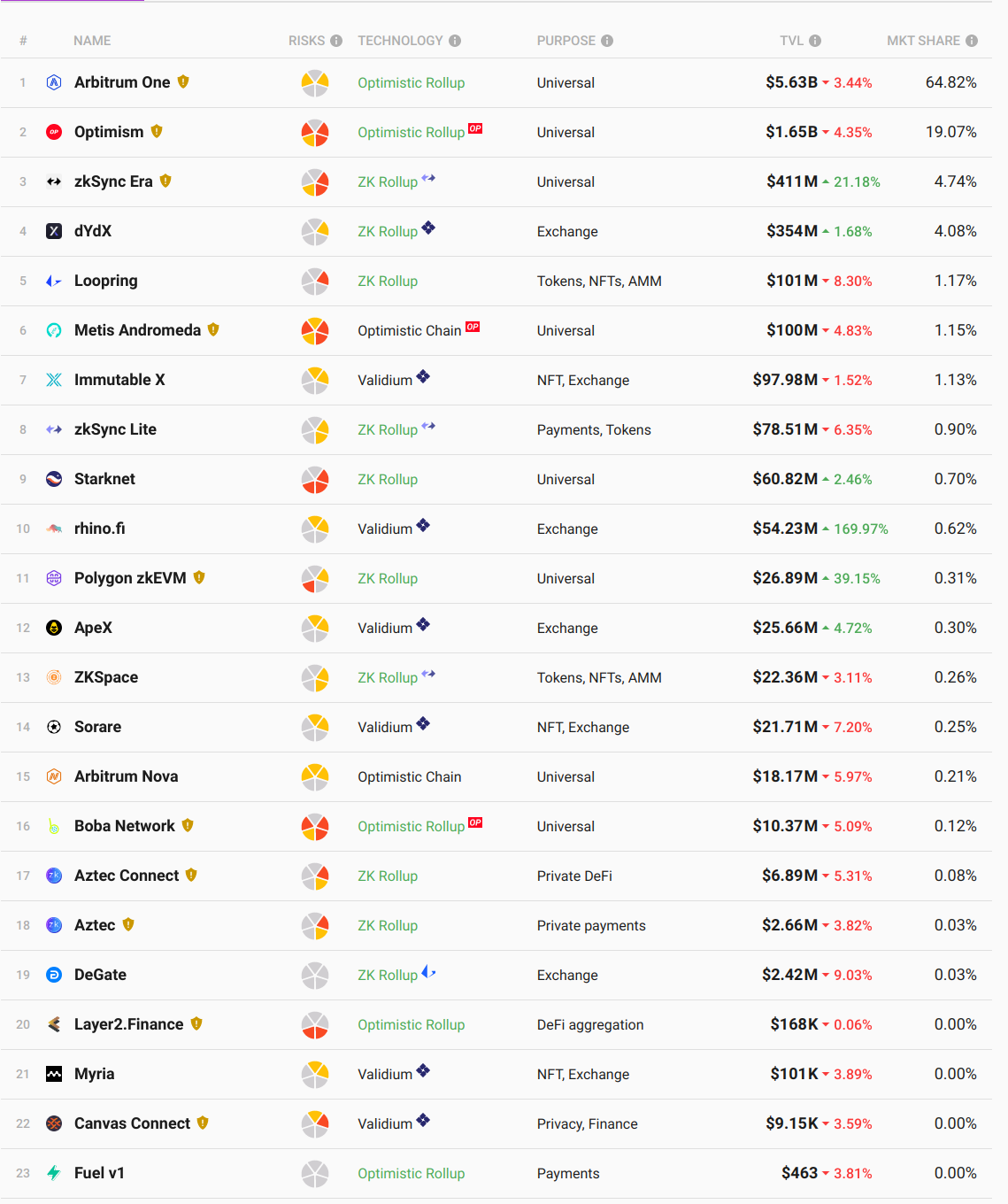
Notes:
Taxonomy of L2s
- Sidechains
- Inherit ordering from L1
- Honest majority bridge (e.g. 5-of-8 multisig)
Taxonomy of L2s
- Smart Contract Rollups
- Inherit ordering and availability from L1
- "Trust-minimized" bridge:
- STF correctness with validity or fraud proofs
- Inbox: option for transactions proposed through base layer to avoid sequencer/proposer censorship
Taxonomy of L2s
- Validiums
- Inherit ordering from L1
- Trust-minimized bridge
- Off-chain DA
Notes:
https://www.starknet.io/en/posts/developers/rollup-validium-volition-where-is-your-data-stored
Taxonomy of L2s
- Sovereign Rollups
- Inherit ordering and availability from L1 (even Bitcoin lol)
- No trust-minimized bridge: correctness and censorship-resistance entirely off-chain
Notes:
- https://celestia.org/learn/sovereign-rollups/an-introduction/
- https://rollkit.dev/blog/sovereign-rollups-on-bitcoin-with-rollkit
Settlement?
- Many in the Ethereum community define rollups by their bridges
- Makes sense if the purpose is scaling ETH transactions
- Rollup nodes can fork the rollup and point at different bridge
- L1 native tokens remain locked
- L2 native tokens retain value
- Some modular consensus layers don't allow settlement: Polkadot and Celestia
Notes:
Data Availability
Data Availability
- Not data storage. Only for a limited time.
- Two purposes:
- Security: to verify STF correctness in optimistic systems (one week in ORUs, ~30s in Polkadot)
- Liveness: for sequencers to download in order to build on top of. Must be a bit longer than STF correctness (~1 day in Polkadot, 30 days in danksharding)
- Cannot use fraud proofs (fisherman's dilemma)
- Simplest option is to post on L1 (Ethereum calldata)
Data Availability Committee (DAC)
- Nodes each redundantly hold data
- Can be off-chain or using committees of L1 validators
- Post threshold signature to L1 attesting to availability
- Coordination can be expensive for rollup users: which shard has my data?
Data Availability Sampling (DAS)
- Data is erasure encoded
- Light clients can verify availability by randomly sampling nodes
- e.g. Celestia (standalone DA layer), Danksharding (Ethereum roadmap), Polygon Avail (built on Substrate), ZKPorter, Eigenlayer
Notes:
- https://arxiv.org/abs/1809.09044
- https://github.com/availproject/data-availability/blob/master/reference%20document/Data%20Availability%20-%20Reference%20Document.pdf
How to ensure coding was done correctly?
- SNARKs: too expensive
- Fraud proofs: requires 2D encoding to be efficient
- KZG commitments: also allows distributed reconstruction (chunking)
2D Reed Solomon
- Computes Merkle roots for rows and columns
- Requires storing 2$\sqrt{n}$ state roots instead of one
- Allows O($\sqrt{n}$) fraud proofs of encoding
DA in Celestia
- Full nodes each redundantly hold erasure coded data off-chain
- Light clients sample 50% and participate in consensus
- Possible incentive problem: easier to scale data than execution so standalone DA layers can more easily be undercut
Notes:
DA in Danksharding
- 2D erasure coded using KZG polynomial commitments
- Also provide proof of encoding
- KZG requires trusted setup, ceremony done earlier this year
- Distributed construction: no nodes need build all rows and columns
- Distributed reconstruction:
- Chunking and sharding similar to Polkadot
- Higher threshold due to 2D encoding
- Allows light client consensus through sampling
- Data removed after 30 days
Notes:
- https://notes.ethereum.org/@vbuterin/proto_danksharding_faq
- https://dankradfeist.de/ethereum/2020/06/16/kate-polynomial-commitments.html
- https://www.youtube.com/watch?v=4L30t_6JBAg
Rollup Security
Validity Proofs for Scaling
- Recursive proofs for constant space blockchains (Mina)
- zk-rollups
- Transactional (private or public): e.g. Aztec
- Application-specific: e.g. STARKDex, Loopring
- Smart contract: e.g. ZEXE (Aleo), zkEVM (Polygon, ZKSync, Scroll)
Notes:
- https://medium.com/hackernoon/scaling-tezo-8de241dd91bd
- https://eprint.iacr.org/2020/352.pdf
- https://github.com/barryWhiteHat/roll_up
- https://zkhack.dev/whiteboard/
Optimistic Rollups: Fraud Proofs
“Don’t go to court to cash a check — just go if the check bounces.”
- Proposers post a state root to L1 with deposit
- Challengers can submit fraud proofs within period (typically 7 days)
- If successful, rewarded portion of deposit
- Fraud proofs can be interactive (Arbitrum) or non-interactive (Optimism)
Notes:
Rollup Training Wheels
- Stage 0
- On-chain DA
- Must have inbox
- No STF correctness
- Stage 1
- STF correctness (fraud or validity proof)
- 6-of-8 multisig can override SC security
- SC upgrades with either same multisig threshold or same delay as challenge period
- Stage 2
- Security override only in case of bugs (discrepancy between two prover implementations)
- Upgrades must have delay greater than 30 days
Notes:
Rollup Sequencers
- Currently centralized (unlike Polkadot collators)
- Shared sequencing: e.g. Espresso, OP Superchain
- Proposer-builder separation
Notes:
- https://docs.espressosys.com/sequencer/espresso-sequencer-architecture/readme
- https://stack.optimism.io/docs/understand/explainer/
- https://ethereum.org/nl/roadmap/pbs/
Optimistic Rollups: Permissionless?
- Spam state roots stall the chain
- Arbitrum allows multiple to be posted (fork and prune) similar to Nakamoto consensus
- Spam challenges can delay confirmation
- They typically must be executed separately and sequentially to prevent collusion
- Arbitrum BOLD allows challenges to be executed together, bounds time at 7 days
- Spam necessitates permissioned proposer/verifier sets
Notes:
- https://github.com/OffchainLabs/bold/blob/main/docs/research-specs/BOLDChallengeProtocol.pdf
- https://medium.com/offchainlabs/solutions-to-delay-attacks-on-rollups-434f9d05a07a
Optimistic Rollups: Verifier’s Dilemma
- Challenge reward isn't enough to incentivize verifying all state roots
- Proposers don't face gambler's ruin on L1
- Verifiers aren't rewarded for executing valid state transitions
- Attention challenges
Notes:
- https://medium.com/offchainlabs/the-cheater-checking-problem-why-the-verifiers-dilemma-is-harder-than-you-think-9c7156505ca1
- https://medium.com/offchainlabs/cheater-checking-how-attention-challenges-solve-the-verifiers-dilemma-681a92d9948e
Rollup Security Assumptions
- ORUs are only as secure as their verifiers
- Typically centralized or small permissioned set
- Don't have similar incentives to L1 validation
- Reputational damage argument
- Bridging is slow
- LPs can provide exit liquidity for small transactions...
- ...but then a small number of whales are checking all rollups
How Does Polkadot Compare to Other Rollup Protocols?

- Approval checking is a decentralized shared watchtower network
- The value proposition of Polkadot is making consistent security assumptions across the modular stack
Additional Lessons
Asynchronous Backing (Deep)
How to use the slides - Full screen (new tab)
Deep Dive, Asynchronous Backing
Notes:
I'll be presenting the second of 3 lectures providing a window into Polkadot core, a slice of where we're at and where we're headed.
This lecture covers asynchronous backing, the new feature with potential to deliver shorter parachain block times and an order of magnitude increase in quantity of Polkadot blockspace.
Lets get to it
Overview
- Async Backing Motivation
- Laying the Groundwork, Contextual Execution of Parablocks
- Prospective Parachains, Storing Products of the Backing Process
- Supporting Changes
- Async Backing Advantages, Current and Future
Async Backing Motivation
Terminology: Backable vs Backed
- Backable candidate:
- Output of the off-chain backing process
- Received a quorum of "valid" votes from its backing group
- Backed candidate:
- A backable candidate that has been placed on-chain
- Also termed "pending availability"
Notes:
We avoid backing any candidate on the relay chain unless we know there is room for that candidate in the availability process. To do otherwise risks wasted on-chain work.
When a candidate is backed on-chain it immediately occupies an availability core and enters the availability, or erasure coding, process.
Synchronous Backing

Note:
Can anyone spot a problem with synchronous model?
-
Problem 1
- Can only start work on new parablock when prior is included
- One relay block for backing, one for inclusion
- Minimum block time of 12 seconds
-
Problem 2
- Minimal time to submit collation for 12 second total block time
- About .5 seconds
- Not enough to fill block fully
Asynchronous Backing
Notes:
- Point out the two independent processes and the "stopping points between them"
- Walk through, starting with unincluded segment
The Async Backing Reasonable Collator Assumptions
- "The best existing parablock I'm aware of will eventually be included in the relay chain."
- "There won't be a chain reversion impacting that best parablock."
The Stakes Are Low
Notes:
Best is determined by a process similar to the BABE fork choice rule. Brief BABE fork choice rule review
Contextual Execution of Parablocks
Async Backing Execution Context
- From relay chain
- Base constraints
- Relay parent
- From unincluded segment
- Constraint modifications
- Required parent

Notes:
- How it was before:
- Required parent included in relay parent
- No need for constraint modifications
- Relay parent vs required parent
- Base constraints vs modifications
Constraints and Modifications
#![allow(unused)] fn main() { pub struct Constraints { /// The minimum relay-parent number accepted under these constraints. pub min_relay_parent_number: BlockNumber, /// The maximum Proof-of-Validity size allowed, in bytes. pub max_pov_size: usize, /// The maximum new validation code size allowed, in bytes. pub max_code_size: usize, /// The amount of UMP messages remaining. pub ump_remaining: usize, /// The amount of UMP bytes remaining. pub ump_remaining_bytes: usize, /// The maximum number of UMP messages allowed per candidate. pub max_ump_num_per_candidate: usize, /// Remaining DMP queue. Only includes sent-at block numbers. pub dmp_remaining_messages: Vec<BlockNumber>, /// The limitations of all registered inbound HRMP channels. pub hrmp_inbound: InboundHrmpLimitations, /// The limitations of all registered outbound HRMP channels. pub hrmp_channels_out: HashMap<ParaId, OutboundHrmpChannelLimitations>, /// The maximum number of HRMP messages allowed per candidate. pub max_hrmp_num_per_candidate: usize, /// The required parent head-data of the parachain. pub required_parent: HeadData, /// The expected validation-code-hash of this parachain. pub validation_code_hash: ValidationCodeHash, /// The code upgrade restriction signal as-of this parachain. pub upgrade_restriction: Option<UpgradeRestriction>, /// The future validation code hash, if any, and at what relay-parent /// number the upgrade would be minimally applied. pub future_validation_code: Option<(BlockNumber, ValidationCodeHash)>, } /// Modifications to constraints as a result of prospective candidates. #[derive(Debug, Clone, PartialEq)] pub struct ConstraintModifications { /// The required parent head to build upon. pub required_parent: Option<HeadData>, /// The new HRMP watermark pub hrmp_watermark: Option<HrmpWatermarkUpdate>, /// Outbound HRMP channel modifications. pub outbound_hrmp: HashMap<ParaId, OutboundHrmpChannelModification>, /// The amount of UMP messages sent. pub ump_messages_sent: usize, /// The amount of UMP bytes sent. pub ump_bytes_sent: usize, /// The amount of DMP messages processed. pub dmp_messages_processed: usize, /// Whether a pending code upgrade has been applied. pub code_upgrade_applied: bool, } }
Notes:
Constraints to Highlight:
- required_parent: Fragment would place its corresponding candidate here for children
- min_relay_parent_number: Monotonically increasing rule, max_ancestry_len
- ump_messages_sent mods ump_remaining
- code_upgrade_applied: Only one in the unincluded segment at a time!
Prospective Parachains
Storing Products of the Backing Process
Prospective Parachains Snapshot

Notes:
- Fragment trees only built for active leaves
- Fragment trees built per scheduled parachain at each leaf
- Fragment trees may have 0 or more fragments representing potential parablocks making up possible futures for a parachain's state.
- Collation generation, passing, and seconding work has already been completed for each fragment.
Anatomy of A Fragment Tree

Notes:
In this order
- Scope
- Root node: corresponds to most recently included candidate
- Child nodes: Mention required parent rule
FragmentNodecontentsCandidateStorageGetBackableCandidate

Fragment Tree Inclusion Checklist
When and where can a candidate be included in a fragment tree?
- Required parent is in tree
- Included as child of required parent, if at all
Fragment::validate_against_constraints()passes- Relay parent in scope
Relay Parent Limitations for Fragments
What does it mean for a relay parent to be in scope?
When is a relay parent allowed to be out of scope?
Notes:
In Scope:
- On same fork of the relay chain
- Within
allowed_ancestry_len
Out of scope:
- Candidates pending availability have been seen on-chain and need to be accounted for even if they go out of scope.
The most likely outcome for candidates pending availability is that they will become available, so we need those blocks to be in the
FragmentTreeto accept their children. - Relay parent can't move backwards relative to that of the required parent
Assembling Base Constraints
Excerpt from backing_state() in runtime/parachains/src/runtime_api_impl/vstaging.rs
#![allow(unused)] fn main() { let (ump_msg_count, ump_total_bytes) = <ump::Pallet<T>>::relay_dispatch_queue_size(para_id); let ump_remaining = config.max_upward_queue_count - ump_msg_count; let constraints = Constraints { min_relay_parent_number, max_pov_size: config.max_pov_size, max_code_size: config.max_code_size, ump_remaining, ump_remaining_bytes, max_ump_num_per_candidate: config.max_upward_message_num_per_candidate, dmp_remaining_messages, hrmp_inbound, hrmp_channels_out, max_hrmp_num_per_candidate: config.hrmp_max_message_num_per_candidate, required_parent, validation_code_hash, upgrade_restriction, future_validation_code, }; }
Applying Constraint Modifications
Excerpt from Constraints::apply_modifications()
#![allow(unused)] fn main() { if modifications.dmp_messages_processed > new.dmp_remaining_messages.len() { return Err(ModificationError::DmpMessagesUnderflow { messages_remaining: new.dmp_remaining_messages.len(), messages_processed: modifications.dmp_messages_processed, }) } else { new.dmp_remaining_messages = new.dmp_remaining_messages[modifications.dmp_messages_processed..].to_vec(); } }
Validating Against Constraints
Excerpt from Fragment::validate_against_constraints()
#![allow(unused)] fn main() { if relay_parent.number < constraints.min_relay_parent_number { return Err(FragmentValidityError::RelayParentTooOld( constraints.min_relay_parent_number, relay_parent.number, )) } }
AsyncBackingParams
#![allow(unused)] fn main() { pub struct AsyncBackingParams { /// The maximum number of para blocks between the para head in a relay parent /// and a new candidate. Restricts nodes from building arbitrary long chains /// and spamming other validators. /// /// When async backing is disabled, the only valid value is 0. pub max_candidate_depth: u32, /// How many ancestors of a relay parent are allowed to build candidates on top /// of. /// /// When async backing is disabled, the only valid value is 0. pub allowed_ancestry_len: u32, } }
Numbers in use for testing Prospective Parachains:
max_candidate_depth= 4allowed_ancestry_len= 3
Supporting Changes
Statement Distribution Changes

Notes:
Why do we need the refactor?
Answer: Cap on simultaneous candidates per backing group ~3x higher
Mention
- Announcement - Acknowledgement
- Request - Response
Provisioner Changes
Function request_backable_candidates from the Provisioner subsystem
#![allow(unused)] fn main() { /// Requests backable candidates from Prospective Parachains subsystem /// based on core states. /// /// Should be called when prospective parachains are enabled. async fn request_backable_candidates( availability_cores: &[CoreState], bitfields: &[SignedAvailabilityBitfield], relay_parent: Hash, sender: &mut impl overseer::ProvisionerSenderTrait, ) -> Result<Vec<CandidateHash>, Error> { let block_number = get_block_number_under_construction(relay_parent, sender).await?; let mut selected_candidates = Vec::with_capacity(availability_cores.len()); for (core_idx, core) in availability_cores.iter().enumerate() { let (para_id, required_path) = match core { CoreState::Scheduled(scheduled_core) => { // The core is free, pick the first eligible candidate from // the fragment tree. (scheduled_core.para_id, Vec::new()) }, CoreState::Occupied(occupied_core) => { if bitfields_indicate_availability(core_idx, bitfields, &occupied_core.availability) { if let Some(ref scheduled_core) = occupied_core.next_up_on_available { // The candidate occupying the core is available, choose its // child in the fragment tree. (scheduled_core.para_id, vec![occupied_core.candidate_hash]) } else { continue } } else { if occupied_core.time_out_at != block_number { continue } if let Some(ref scheduled_core) = occupied_core.next_up_on_time_out { // Candidate's availability timed out, practically same as scheduled. (scheduled_core.para_id, Vec::new()) } else { continue } } }, CoreState::Free => continue, }; let candidate_hash = get_backable_candidate(relay_parent, para_id, required_path, sender).await?; match candidate_hash { Some(hash) => selected_candidates.push(hash), None => { gum::debug!( target: LOG_TARGET, leaf_hash = ?relay_parent, core = core_idx, "No backable candidate returned by prospective parachains", ); }, } } Ok(selected_candidates) } }
Notes:
- Per core
- Discuss core states free, scheduled, occupied
- Discuss core freeing criteria
bitfields_indicate_availability- next_up_on_available
- availability time out
- next_up_on_timeout
- Explain what required path is
- Why is required path left empty?

Cumulus Changes
- Consensus driven block authoring
- Parachain consensus refactor
- Aura rewrite
- Custom sequencing consensus:
- Tendermint
- Hotshot consensus
Async Backing Advantages, Current and Future
Advantages of Asynchronous Backing
- 3-5x more extrinsics per block
- Shorter parachain block times 6s vs 12s
- Resulting 6-10x boost in quantity of blockspace
- Fewer wasted parachain blocks
Notes:
- Collators have more time to fill each block
- Advance work ensures backable candidates for each parachain are present to be backed on the relay chain every 6 seconds
- Self explanatory
- Allow parachain blocks to be ‘reused’ when they don’t make it onto the relay chain in the first attempt
Async Backing and Exotic Core Scheduling
- What is exotic core scheduling?
- Multiple cores per parachain
- Overlapping leases of many lengths
- Lease + On-demand
- How does asynchronous backing help?
Notes:
- The unincluded segment is necessary to build 2 or more parablocks in a single relay block

Shorter Block Times?
- Async backing gives us unincluded block queuing
- What else we need for useful shorter times:
- Soft finality
- Inclusion dependencies (comes with elastic scaling)
Notes:
- Soft finality means that the collators will submit as many new blocks with the same extrinsics as needed to retain the same ordering if a parablock candidate is dropped.
- Inclusion dependencies: Take two parablocks a and b, where a is built on top of b. Then if a and b are being made available on two different cores during the same block we need to ensure that b waits for inclusion until a is also included.
Resources
Questions
Blockspace: The Product of Polkadot
How to use the slides - Full screen (new tab)
Blockspace
In this lesson, we will cover:
- Blockspace as a concept and historical interpretations
- Blockspace as a product of blockchains
- The importance of efficient allocation of blockspace
- The design space of blockspace allocation mechanisms within Polkadot
Notes:
Deep Dive Article is https://www.rob.tech/polkadot-blockspace-over-blockchains/
Blockspace: Definition
Blockspace is the capacity of a blockchain to finalize and commit operations.
Measuring Blockspace
Blockspace can be measured in a few different ways:
- Size: Bytes used by transactions (e.g. Bitcoin)
- Computation: Gas used by transactions (e.g. Ethereum)
- Data: Size of data required to validate transactions (PoV size in Polkadot)
- Or some combination of the above
Blockspace Markets
Fee markets in blockchains are examples of blockspace markets.
The blockchain sells blockspace on-demand, and users pay fees in order to utilize the blockspace.
Blockspace Markets
Parachain slot auctions are another example of a blockspace market.
Instead of selling blockspace on-demand, blockspace is sold in bulk up-front with an auction mechanism.
Blockspace: Supply and Demand

Blockspace in Ethereum: GasToken
GasToken (https://GasToken.io) was an early Blockspace Futures Market on Ethereum.
Ethereum provides a gas refund for storage slots being cleared in smart contract execution.
By "pre-buying" storage when gas is cheap and getting the refund when gas is expensive, users can perform blockspace arbitrage in Ethereum!
Evaluating Blockspace
3 Properties of Blockspace:
- Quality: How secure is the blockspace? What are the economic guarantees of finality?
- Availability: How much blockspace is available on the market?
- Flexibility: How many applications can the blockspace be used for?
Polkadot's Blockspace: Quality
Polkadot's Execution Sharding guarantees that all blockspace generated by Polkadot is highly secure, with economic guarantees of finality under the 33% BFT assumption.
Polkadot's Blockspace: Availability
With sharding, Polkadot has the capability to produce large amounts of blockspace. This is another lens to view the blockchain scaling problem through: creating more blockspace.
Polkadot's Blockspace: Flexibility
Polkadot provides blockspace in a highly flexible format due to key design choices:
- WebAssembly: This turing-complete language allows all kinds of computation to be done.
- PoV Blobs: Unopinionated about storage formats or access patterns.
- Head-Data blobs: Parachains can use any header format they like and don't even have to be blockchains, strictly speaking.
Substrate: The Blockspace Transformer
Since Polkadot provides highly flexible blockspace, it can be transformed into a variety of different, more specialized blockspace products.
Principles of Blockchain Application Development
- Acquire generalized blockspace (from Polkadot, from validators directly)
- Specialize blockspace for a particular use-case or requirement
- Downstream demand drives upstream demand.
Notes:
By (3) I mean that the amount of demand for (2) should inform the amount to which the application does (1).
Problem: Ghost Chains
It's quite common for chains to produce mostly empty blocks.
This is a problem: chains are buying more blockspace than they need!
They are paying validators to do nothing of value, and this will lead to depreciation of their token.
Solution: Acquire Blockspace on-demand
Blockchains as needing to produce blocks every X seconds or minutes.
Blockchains should only produce blocks when they have a good reason to.
The main reason this is not done is because there are no good primitives for it.
Polkadot's Architecture: Execution Cores

Notes:
Cores, by metaphor, are like CPU cores. Code and data are scheduled onto them by the "Operating System" and then executed.
Polkadot's Architecture: Execution Cores

Long-term vs. on-demand
On-demand are analogous to "spot" instances and slot auctions are analogous to "reserved" instances in cloud computing.
Spot instances may be more expensive if overall demand is high, but help to soothe load.
Coretime
Within Polkadot, we measure the amount of blockspace that an application can use in coretime.
Just like a CPU and OS, there is a scheduler that multiplexes many
different processes onto execution cores.
Coretime is acquired through either primary or secondary marketplaces.
Elastic Scaling (planned upgrade)
What if parachains could acquire not just one execution core at a time, but multiple?
Parachains would then be able to elastically scale during periods of higher demand.
Notes:
This scaling can occur as a result of the property that in Polkadot, parablock state transitions are completely encapsulated and validation of block X+1 can occur in parallel with validation of block X.
However, the parablocks still must be authored sequentially by collators, and for that reason this can only be used to scale up to the maximum throughput of collators authoring blocks.
Reimbursement Layer: Status Quo

Reimbursement Layer: Generalizing

Notes:
User could be a collator itself, or perhaps just someone fulfilling a market need (blockspace arbitrage!)
Reimbursement Layer: Use Cases
- Pay Collators somewhere other than the chain they build upon
- Pay Collators in stablecoins or other tokens
- Tokenless parachain
- Parachain Launch Pad (e.g. pay out of "credits" on some other system)
- Generalized Collator Pool (plug and play, no need to run nodes specific to parachain)
Blockspace and Interoperability
In interoperable blockchain applications, the application is only as good as the weakest chain it relies upon.
It is important not to mix high-quality blockspace with low-quality, due to toxicity risks.
Ephemeral Chains
Is there any reason a blockchain should run forever?
Why not create blockchains that run for a limited period of time, e.g. to run some specific protocol or computation, and then conclude?
Coretime Futures Markets
With the right core-level primitives, it will be possible to transfer claims on future coretime.
Secondary markets can emerge, perhaps using NFTs, on parachains themselves, to facilitate the market for future coretime.
This will create an efficient market and price discovery for coretime via arbitrage.
Future Coretime Allocation Mechanisms
If coretime is the "product" of Polkadot, then allocation mechanisms are the "packaging".
RFC-1 proposes mechanisms for bulk coretime to be sold off, renewed, split up, resold, and transferred.
Blockspace: Conclusions
- Blockspace is an conceptual distillation of blockchain resources
- Blockspace provides new lenses on the scheduling and lifecycle of blockchains
- Polkadot measures blockspace allocation using coretime
- Efficient allocation of blockspace will be critical as Web3 systems scale to serve 8 billion people.
- Polkadot's architecture is blockspace-centric, not blockchain-centric, and provides many options for builders to use its product.
Questions
Build a Parachain
How to use the slides - Full screen (new tab)
Build a Parachain
NOTE this is using the archived repo of the Polkadot v1.0.0 release.
Agenda
- Build a simple collator without Cumulus
- Introduction to Cumulus and how to build a Parachain
- Workshop: Manually registering a parachain
- Workshop: How to acquire a parachain slot
Before we begin:
# We will need a polkadot binary, e.g.
git clone https://github.com/paritytech/polkadot/
cd polkadot
cargo build --release
# Compile this in advance to save time:
git clone https://github.com/Polkadot-Blockchain-Academy/cumuless-parachain-PBA-BA-2023
cd cumuless-parachain-PBA-BA-2023
# Ma a branch *for yourself*
git checkout -b <YOUR GITHUB USERNAME HERE>
cargo build --release
Build Simple Parachain
We're going to build a simple parachain without Cumulus!
- PVF
- Collator
Notes:
This will be a parachain built without using FRAME. There will be only one collator and no collator selection logic. No message processing. No transactions. No runtime upgrades. No parachain full nodes.
Parachain requirements
A parachain needs two things:
- A Wasm runtime with
validate_blockfunction exposed - Node side that can sync relay chain blocks and talk to the relay chain
Notes:
Talking to the relay chain means speaking the networking protocol of Polkadot to distribute the PoV.
Minimal parachain runtime (PVF)
#![allow(unused)] #![no_std] #![cfg_attr( fn main() { not(feature = "std"), feature(core_intrinsics, lang_items, core_panic_info, alloc_error_handler) )] // Make the Wasm binary available. #[cfg(feature = "std")] include!(concat!(env!("OUT_DIR"), "/wasm_binary.rs")); #[cfg(feature = "std")] /// Wasm binary unwrapped. If built with `BUILD_DUMMY_Wasm_BINARY`, the function panics. pub fn wasm_binary_unwrap() -> &'static [u8] { Wasm_BINARY.expect( "Development wasm binary is not available. Testing is only \ supported with the flag disabled.", ) } #[cfg(not(feature = "std"))] #[panic_handler] #[no_mangle] pub fn panic(_info: &core::panic::PanicInfo) -> ! { core::intrinsics::abort() } #[cfg(not(feature = "std"))] #[alloc_error_handler] #[no_mangle] pub fn oom(_: core::alloc::Layout) -> ! { core::intrinsics::abort(); } #[cfg(not(feature = "std"))] #[no_mangle] pub extern "C" fn validate_block(_params: *const u8, _len: usize) -> u64 { loop {} } }
Notes:
The panic and oom handlers are Rust-specific things you don't need to worry about.
If we actually include an infinite loop into the validate_block function, a parablock will never be backed/included by the relay chain validators.
Parachain node side
- Our node will sync relay chain blocks
- When importing the new best block,
we'll connect to the backing group - Then we'll advertise our block ("collation")
to a validator in the group - The validator will request the collation
from us usingcollator-protocol - Now it's in the hands of validators
to include our block
Notes:
Validators are shuffled into small backing groups, which rotate
regularly with group_rotation_frequency.
Currently, collators can only produce the next block after their previous
block has been included by the relay chain (remember CandidateIncluded).
Since inclusion happens in the next block after candidate being backed,
this means collators can only produce blocks every 12s. Async backing
will change that.
Collator-protocol
Polkadot contains the implementation of the both collator and validator side of the collator protocol.
#![allow(unused)] fn main() { /// What side of the collator protocol is being engaged pub enum ProtocolSide { /// Validators operate on the relay chain. Validator { /// The keystore holding validator keys. keystore: SyncCryptoStorePtr, /// An eviction policy for inactive peers or validators. eviction_policy: CollatorEvictionPolicy, }, /// Collators operate on a parachain. Collator( PeerId, CollatorPair, IncomingRequestReceiver<request_v1::CollationFetchingRequest>, ), } }
Notes:
We're going to use Polkadot as a library configured for the collator side.
Time to look into the code
Our PBA parachain is a trimmed down version of:
Exercise
Make the state of the Parachain a fixed sized 2d field (e.g. 25x25) that evolves at each block according to Game of Life and print the state at each block.
- https://en.wikipedia.org/wiki/Conway%27s_Game_of_Life
- https://www.rosettacode.org/wiki/Conway%27s_Game_of_Life
Questions
Availability Cores
How to use the slides - Full screen (new tab)
Deep Dive, Availability Cores
Notes:
Hello!
I'm Bradley Olson
Was student at first Academy
Currently on Parachains Core Team
Will present 3 lectures providing a window into Polkadot core, a slice of where we're at and where we're headed.
First a look at availability cores, the abstraction enabling flexible purchases of blockspace under the umbrella of Polkadot shared security.
Lets get to it
Addressing the Dual Naming
- In the code: Availability core
- Outside the code: Execution core
Overview
- What do availability cores represent?
- How do cores map parachain leases and claims to validator subsets?
- How do cores gate each step of the parachains protocol?
- What advantages do cores give us now?
- What roadmap items do cores accommodate?
Review, Blockspace
Blockspace is the capacity of a blockchain
to finalize and commit operations
Polkadot's primary product is blockspace.
Blockspace, Use It or Lose It
Polkadot blockspace is consumed in two ways:
- When the relay chain validates, includes,
and finalizes a parachain block
- When the capacity to validate a parachain block
is left unused and expires

Availability Core Defined
- Availability cores are the abstraction we use to allocate Polkadot's blockspace.
- Allocated via leases and on-demand claims
- Cores divide blockspace supply into discrete units, 1 parachain block per relay chain block per core
- Why "availability"?
- Why "core"?

Notes:
- "Availability", because a core is considered occupied by a parachain block candidate while that candidate is being made available. But cores mediate access to the entire parablock validation pipeline, not just availability.
- "Core", because many candidates can be made available in parallel, mimicking the parallel computation per core in a computer processor.
Availability
Though cores gate the entire parachain block pipeline,
the availability process alone determines when these cores are considered occupied vs free.
To recap, the goals of availability are:
- To ensure that approvers will always be able to recover the PoVs to validate their assigned blocks
- To ensure that parachain nodes can recover blocks in the case that a parablock author fails to share them, through malintent or malfunction
Core States
Free

Scheduled

Occupied

Notes:
- Before going any farther we need to talk about core states
- CoreState: Free -> core has not been assigned a parachain via lease or on-demand claim
- CoreState: Scheduled -> Core has an assigned parachain and is currently unoccupied
- CoreState: Occupied -> Core has assignment and is occupied by a parablock pending availability
The Availability Process
- Block author places a candidate on-chain as backed, immediately occupying its scheduled core
- Candidate backers distribute erasure coded PoV chunks
- Validators distribute statements as to which candidates they have chunks for
- Availability threshold is met (2/3 vs the 1/3 needed to reconstruct POV)
- Candidate marked as included on chain and core freed
- Approvers or parachain nodes retrieve PoV chunks as needed
Cores and Blockspace Over Time

Notes:
Metaphor:
- Relay chain: Train loading bay
- Relay block: Train leaving station every 6 seconds
- Parachain block: One train car worth of cargo
- Availability core: Car index within all trains
If you have a lease on core 4, then you have the right to fill train car 4 on each train with whatever you want to ship.
Q: How would an on-demand claim be represented in this metaphor?
Mapping Leases and Claims to Validator Subsets
The Big Picture

Notes:
- Which steps of the parachains protocol are missing, and why?
- Going to dive into each piece
- Questions?
Assigning Leases and Claims to Cores

Notes:
- Leases have indices and pair to cores with the same index
- Cores not designated as on-demand and without a paired lease are left free, their blockspace wasted
- When on-demand claims are queued, they are each assigned a designated core in ascending order, looping when reaching the last core
Assigning Backing Groups to Cores

Notes:
- Round robin, fixed intervals
This prevents a byzantine backing group from interrupting the liveness of any one parachain for too long.
Backing Group Formation

Notes:
- Validators randomly assigned to groups at start of session.
- Group count is active validator count / max group size rounded up
- Groups are partitioned such that the largest group and smallest group have a size difference of 1

Assigning Approvers to Cores
- Randomness via schnorrkel::vrf
- Approver assignments activated with delay tranches until threshold met
- Results in 30-40 approvers checking each block
- Different assignments each block prevent DOS
Putting the Pieces Together
Occupying Assigned Cores: With Lease

Notes:
Q: What step of the parachains protocol takes place between "Supplied backable candidate" and "availability process?
Occupying Assigned Cores: On Demand

Core States in the Runtime
In file: polkadot/runtime/parachains/src/scheduler.rs
#![allow(unused)] fn main() { pub(crate) type AvailabilityCores<T> = StorageValue<_, Vec<Option<CoreOccupied>>, ValueQuery>; pub enum CoreOccupied { /// A parathread (on-demand parachain). Parathread(ParathreadEntry), /// A lease holding parachain. Parachain, } /// Parathread = on-demand parachain pub struct ParathreadEntry { /// The claim. pub claim: ParathreadClaim, /// Number of retries. pub retries: u32, } }
Notes:
Q: When Option is None, what does that indicate?
- Which para occupies a core is stored separately in the following structure
Core Assignments in The Runtime
In file: polkadot/runtime/parachains/src/scheduler.rs
#![allow(unused)] fn main() { pub(crate) type Scheduled<T> = StorageValue<_, Vec<CoreAssignment>, ValueQuery>; pub struct CoreAssignment { /// The core that is assigned. pub core: CoreIndex, /// The unique ID of the para that is assigned to the core. pub para_id: ParaId, /// The kind of the assignment. pub kind: AssignmentKind, } pub enum AssignmentKind { /// A parachain. Parachain, /// A parathread (on-demand parachain). Parathread(CollatorId, u32), } }
Notes:
- Vec of all core assignments
- Pairs ParaId with CoreIndex
- AssignmentKind carries retry info for on-demand
How Cores Gate Each Step of the Parachains Protocol
How Core Assignments Mediate Backing
Each parablock candidate is built in the context of a particular relay_parent.
Validators query their core assignment as of relay_parent and refuse to second candidates not associated with their backing group.
Notes:
- Relay parent context: max PoV size, current parachain runtime code, and backing group assignments.
How Core Assignments Mediate Backing (Cont.)
handle_second_message() in the Backing Subsystem.
#![allow(unused)] fn main() { if Some(candidate.descriptor().para_id) != rp_state.assignment { gum::debug!( target: LOG_TARGET, our_assignment = ?rp_state.assignment, collation = ?candidate.descriptor().para_id, "Subsystem asked to second for para outside of our assignment", ); return Ok(()) } }
Cores and Backing On-Chain
- For each core that is either unoccupied or is about to be a new candidate is found
- A candidate for the parachain scheduled next on that core is provided to the block author
- Backed on-chain -> immediately occupies core
Notes:
- Review possible core states
- Mention time-out vs made available
Q: What does "immediately occupies core" imply?
Cores and Backing On-Chain, Code
Code determining whether to back a candidate and which, greatly simplified
#![allow(unused)] fn main() { let (para_id) = match core { CoreState::Scheduled(scheduled_core) => { scheduled_core.para_id }, CoreState::Occupied(occupied_core) => { if current_occupant_made_available(core_idx, &occupied_core.availability) { if let Some(ref scheduled_core) = occupied_core.next_up_on_available { scheduled_core.para_id } else { continue } } else { if occupied_core.time_out_at != current_block { continue } if let Some(ref scheduled_core) = occupied_core.next_up_on_time_out { scheduled_core.para_id } else { continue } } }, CoreState::Free => continue, }; let candidate_hash = get_backable_candidate(relay_parent, para_id, required_path, sender).await?; }
Notes:
- Discuss core freeing criteria
bitfields_indicate_availability- next_up_on_available
- availability time out
- next_up_on_timeout
Cores and Approvals, Disputes, Finality
Each included candidate has already occupied an availability core
Approvals, Disputes, and Finality are only provided to included candidates
Advantages Cores Give us Now
- Predictability of parachain execution
- Predictability of allocation for execution sharding

Notes:
- Regularly rotating pairings between cores and backing groups lessen the impact of potential bad validator subsets
- Cores accommodate advance allocation making costs for parachains predictable
- Core time can be resold or split for precise allocation
Cores and Roadmap Items

Exotic core scheduling
- Multiple cores per parachain
- Overlapping leases of many lengths
- Lease + On-demand

Notes:
- Each color represents a parachain Metaphor:
- Multiple cars on the same train
- Overlapping time spans of rights to fill different train cars
- Long term rights to one car and buy rights to others for just one train
Divisible and Marketable Blockspace
We want Parachains to buy, sell, and split blockspace such that they are allocated exactly as much as fits their needs.
- Core sharing via use-threshold blockspace regions
- Secondary markets for blockspace regions
Notes:
- Example: Region spanning 100 blocks. Split the region use so that each of two parties can submit up to 50 parablocks. Ownership proportion is enforced throughout the region such that each party can't submit more than 5 out of the first 10 blocks.
Framing Shift: Blockspace vs Core Time
Blockspace is a universal term for the product of blockchains, while core time is Polkadot's particular abstraction for allocating blockspace or other computation.
Cores can secure computation other than blocks. For example, a smart contract could be deployed on a core directly.
Allocating cores by time rather than for a fixed block size could allow for smaller or larger parachain blocks to be handled seamlessly.
Resources
Questions
Polkadot Fellowship
How to use the slides - Full screen (new tab)
Polkadot Fellowship
Prelude: Decentralization
- Decentralization can come in many fashions.
- Some of my (somewhat) personal opinions.. 💭
---v
Prelude: Decentralization
1. Technical 🔐
- Can the software be executed in a decentralized manner?
- Can multiple nodes actually run the software and come to consensus?
Notes:
- Nakatomo coefficient
- Most blockchain systems actually already have this.
---v
Prelude: Decentralization
2. Operational ⚙️
- The software is capable of running in a decentralized manner. But is it actually?
- Intermediaries, gateways, pools.
- Is the right "software" being executed by node operators?
Notes:
-
Metamask
-
Mining/Staking Pool getting to large.
-
Node operators are a concept here. They have the duty to run the "correct software". But how they come to this decision is something that needs knowledge, which brings us to the next point.
https://moxie.org/2022/01/07/web3-first-impressions.html
---v
Prelude: Decentralization
3. Intellectual 🧠
- How many people know the existing protocol well enough to understand it.
- Which subset of these people make decisions about the future?
- Important to remember that node operators are usually in neither.
Notes:
- the cathedral and bazaar
- the papal model
https://en.wikipedia.org/wiki/The_Cathedral_and_the_Bazaar
---v
Prelude: Decentralization
3. Intellectual 🧠
My trust in Polkadot’s credible future should not rely on knowing that Parity, Gav or Shawn will continue to act benevolently.
- This is where a meta-protocol, and rule-based upgrade systems becomes important.
Notes:
Recall how if the governance of the chain decide to upgrade to protocol, node-operators don't have a say in that by default.
This is taking away the "power of default" to be in the hands of the token holders, not the node-operators.
---v
Prelude: Decentralization
Geopolitical 🌎
- How many of protocol experts/node operators are under the same juristiction?
The Fellowship
The fellowship is a technical decision making body onchain, aimed at alleviating the above facades of centralization, but more so than anything else, the intellectual aspect.
Notes:
- Technical, high focus on core protocol aspects for now.
- decision-making: not saying it has absolute power yet.
---v
The Fellowship
- Imperfect, not for everyone, opinionated 🥲!
- Strictly better than not taking an action.
Notes:
It is an attempt at solving the issue. We believe it is strictly better than defining no rule around it and letting it be as-is, but it might be sub-optimal.
The Polkadot Fellowship aims to be one example of such an explicit action. The Fellowship is a rules-based social organisation with several aims centred around the support and recognition of the technical expertise needed for technical stability, security and progress of the network.
The Fellowship Lifecycle
- Initial seed
- Entry
- Promotion
- Continuation
- Gradual demote every 3-6 months.
---v
The Fellowship Lifecycle: Evaluation
Evaluation is subjective, based on merits of "core blockchain engineering".
The manifesto provides one such example
- API and code design.
- Code contribution.
- Social interactions.
- Voting.
- Activity
- Agreement.
The Fellowship Structure
| Dan | Name | Group | Exp from Dan I | Material |
| 0 | Candidate | n/a | n/a | n/a |
| 1 | Humble | Members | n/a | Graphite |
| 2 | Proficient | Members | 1 years | Stibnite |
| 3 | Fellow | Fellows | 2 years | Galena |
| 4 | Architect | Architects | 3+ years | Obsidian |
| 5 | Architect Adept | Architects | 4+ years | Ilvaite |
| 6 | Grand Architect | Architects | 5+ years | Magnetite |
| 7 | Free Master | Masters | 6+ years | Black Spinel |
| 8 | Master Constant | Masters | 11+ years | Carborundum |
| 9 | Grand Master | Masters | 19+ years | Carbandos |
Dan 0: The Candidate
- No requirement, no implication
- Deposit held for storage usage etc.
Dan I: The Humble
- The (potentially) softest of the materials
- Wide range of hardness (1-3 Moh)
- Shares the exact same chemical composition as the material of the highest rank Grand Master—the hardest material—symbolizing the individual’s potential to go all the way.
---v
Dan I: The Humble
- Clear aspiration to learn and evangelize the protocol.
- Deep knowledge at least one key component.
- Independent, vision-driven contribution.
- Being available and playing a crucial operational role for a network fix.
Dan II: The Proficient
- ~1 Year of experience passed since acquiring Dan I.
- Responsible for research, analysis and implementation of a key component of the system.
- Potentially "on-call" for the same component.
- At least one published long-form semi-technical article concerning Polkadot.
Fellowship: Kusama
- Used in conjuncture with
pallet-whitelistandpallet-preimage. - The fellowship can whitelist certain pre-images, which in turn can lead to faster execution.
- End of the day, it is all (virtual) runtime origins:
Fellows,Fellowship3Dan,WhitelistedCaller- ...
Fellowship: The Near Future
- Payroll
- Delegation
- Runtimes moved to the fellowship repository
Polkadot Fellowship
Learn more:
Nominated Proof of Stake
How to use the slides - Full screen (new tab)
Nominated Proof of Stake
in Polkadot
Why Proof of Stake Ser?
Why do we use PoS?
- Tokens locked + prone to being slashed.
- Economic Security 💸🤑.
- Everything else (finality, parachains, etc.) is built on top of this base layer of economic security.
---v
Why Proof of Stake Ser?
- Remember that Polkadot is at the end of the day a validator-set-as-a-service.
- Secure Blockspace, the main product of Polkadot is provided by these validators.

What is NPoS: Assumptions
Assumptions:
- Validators: those who intend to author blocks. i.e. Validator candidate.
- Nominators/Delegators: Those who intend to support wanna-be authors.
- Validation and nomination intentions can change, therefore we need periodic elections to always choose the active/winner validators/delegators + hold them slashable.
- Every election period is called an Era, e.g. 24hrs in Polkadot.
What is NPoS: Re-inventing the Wheel
---v
Solo-POS

---v
What is NPoS: Re-inventing the Wheel
-
Authority-wanna-bees aka. validators bring their own stake. No further participation. Top validators are elected.
-
Problems?
Notes:
Low amount of stake that we can capture, impossible for those who don't want to run the hardware to join.
---v
Single-Delegation-POS

---v
What is NPoS: Re-inventing the Wheel
-
Anyone can dilute themselves in any given validators. Top validator based on total stake are elected.
-
Voters are called delegators.
-
Problems?
Notes:
- Better, but funds might be delegated to non-winners, which get wasted.
- In other words, there is no incentive to delegate to those that are non-winners.
---v
Multi-Delegation-POS

---v
What is NPoS: Re-inventing the Wheel
Your stake is divided $\frac{1}{N}$ (or arbitrarily) among $N$ validators.
Problems?
Notes:
Same issue as before.
---v
Nominated Proof of Stake

---v
Nominated Proof of Stake

---v
What is NPoS: Re-inventing the Wheel
- You name up to
Nnominees, an algorithm, computed either onchain or offchain, decides the winners and how to distribute the stake among them. - Voters are called Nominators.
---v
What is NPoS: Re-inventing the Wheel
- ✅ As a nominator, you are free to express your desire to back non-winners as well. Once enough people have expressed the same desire, the non-winner will become a winner.
- ✅ Has a much higher chance to make sure staked tokens won't get wasted.
- ✅ Can optimize other criteria other than "who had more approval votes".
NPoS Drawbacks
- We decided to solve an np-hard, multi-winner, approval based, election problem onchain 🤠.
- scalability.
- scalability.
- scalability.
- scalability.
- and scalability.
- But we (strive to) get much better economic security measures in return 🌈.
- Long term, this can in itself be solved by what Polkadot provides best, more Blockspace 🎉!
NPoS Protocol Overview
- The current NPoS protocol revolves around an election round, which is itself made up of 4 episodes.
- This gives you an idea about how we solved the scalability issue for the time being.
---v
NPoS Protocol Overview: Episode 1
Snapshot
- Enables multi-block election.
- Allows us to not need to "freeze" the staking system.
- Allows us to index stakers, not
AccountIds.
---v
NPoS Protocol Overview: Episode 2
Signed Submissions
- Any signed account can come up with a NPoS solution based on that snapshot.
- Deposits, rewards, slash, other game-theoretic tools incorporated to make to secure.
---v
NPoS Protocol Overview: Episode 3
Validator Submissions as Fallback
- As the first backup, any validator can also submit a solution as a part of their block authoring.
---v
NPoS Protocol Overview: Episode 4
Fallbacks
- If all of the above fails, the chain won't rotate validators and the governance can either:
- dictate the next validator set.
- trigger an onchain election (limited in what it can do).
This was recently used in Kusama 🦜.
NPoS Objective
- Given the powerful tool of NPoS, what should we aim for?
- Let's first recap:
- Polkadot validators are the source of truth for the state transition of both the relay chain and all of the parachains + bridges.
- Polkadot validator are assigned to parachains as backing group, and swapped over time.
- Polkadot validators all author the same number of blocks, i.e. they are of same importance.
Notes:
Point 2 is not to imply that the polkadot validator set's security is partitioned among parachains, security comes from approval voters. https://www.polkadot.network/blog/polkadot-v1-0-sharding-and-economic-security/
---v
NPoS Objective: Election Score
#![allow(unused)] fn main() { pub struct ElectionScore { /// The minimal winner, in terms of total backing stake. /// /// This parameter should be maximized. pub minimal_stake: u128, /// The sum of the total backing of all winners. /// /// This parameter should maximized pub sum_stake: u128, /// The sum squared of the total backing of all winners, aka. the variance. /// /// Ths parameter should be minimized. pub sum_stake_squared: u128, } }
---v
NPoS Objective: Election Score
-
NPoS allows us to incentivize the formation of a validator set that optimized the aforementioned
ElectionScore. -
This score is ALWAYS calculate and checked onchain. This is why we can accept solutions from the outer world.
Notes:
A common example: we allow signed submissions. What if they send solutions that are censoring a particular validator? if it can achieve a better score, so be it! we don't care.
---v
NPoS Objective: Election Score
- The default algorithm used in both the onchain/offchain solvers is the Phragmen algorithm.
- Proved to provide high fairness and justified representation properties whilst being verifiable in linear time.
NPoS Future
- Fresh from the oven (Jan 2023): Future of Polkadot Staking in the Polkadot forum.
- Github issue-tracker/project
- Nomination Pools
- Multi-page election submission
- Operators as first class citizens.
- fast-unstake.
Additional Resources! 😋

Check speaker notes (click "s" 😉)
Notes:
Further Reading
- Recent Kusama slashing: https://forum.polkadot.network/t/kusama-era-4543-slashing/1410
- A verifiably secure and proportional committee election rule
- 4.1 in Overview of Polkadot and its Design Considerations
- Proportional Justified Representation
- Justified representation - Wikipedia
NPoS Protocol: More Details, Backup Slides
bags-list: how to store an unbounded semi-sorted linked-list onchain.- Nomination pools: best of both.
- Minimum-untrusted score.
- PJR checking: why we don't do it.
reduceoptimization.
Feedback After Lecture:
OpenGov
How to use the slides - Full screen (new tab)
OpenGov
Notes:
Hello!
I'm Bradley Olson
Was student at first Academy in Cambridge
Currently on Parachains Core Team at Parity
Making Polkadot truly decentralized requires a robust, agile, and democratic system of governance.
Gavin has put a lot of effort over the last year or so into crafting a system which does those words justice, OpenGov.
I'm here to give you an overview of what OpenGov is and to surface some new information about how it is performing on Kusama.
So lets get to it
Overview
- Why blockchain governance?
- Why on-chain?
- Goals of on-chain governance
- Initial Solution, Governance V1
- Improvement, OpenGov
- How is it going? By the numbers.
- OpenGov and you
Reasons for Blockchain Governance
- Software as executive branch
- Applies existing laws (code) in pre-defined ways
- Protocol security ensures the letter of those laws is followed
- But evolving protocols need a legislative branch
- To update the laws (code)
- To rectify cases where letter != spirit (bugs)
- To trigger parts of the system that aren't on a set schedule
- To spend treasury funds
- Legeslative can be on or off chain
Why On-chain?
-
Off-chain governance
- Formal proposal by dev team
- Discussions, debates, and media campaigns
- Hard fork
-
Issues
- Centralization
- Low throughput
- Long decision period
- Little accessibility


Goals of On-chain Governance
- Transparency: Decisions by who and by what rules?
- Decentralization: Distributed power, weighted only by commitment and conviction
- Security: Harmful proposals don't pass or have limited scope
- Accessibility: Easy to draft proposal, to receive vote, to vote yourself, and to vote by proxy
- Concurrency: Maximize simultaneous referenda as security allows
- Speed: Each referendum completed as fast as security allows
- Agility: Speed is responsive to support/controversy
Governance V1

- Tri-cameral system: Referenda, council, and technical committee
- Single track
- 1 referendum at a time
- Root origin (Unlimited Power!)
- 28 day referendum
- 1 month minimum enactment period
- Emergency handled technical committee
- Cancellations by council and technical committee
- Most proposals initiated by council
- Fully council controlled roles such as tipping
Gov V1, Room for Improvement
The good:
- Security
- Transparency
The bad:
- Decentralization
- Concurrency
- Speed
- Agility

OpenGov Overview
- Origins and tracks
- Lifecycle of a referendum
- Support and approval threshold curves
- The Polkadot Fellowship
- Vote delegation by track
- OpenGov and governance goals

Origins
- Level of privilege that code executes with
- Similar to user on Unix
- Proposal is two things
- Operation: What should happen
- Origin: Who authorizes it
- Many operations require a specific origin

Origins and Tracks
- Each origin is served by a referendum track
- A track can serve more than one origin
- These tracks are totally independent from one another
- Track examples: Root, ParachainAdmin, BigSpender, Tipper
- Emergency tracks: ReferendumCanceler, ReferendumKiller
Track Parameters
Parameters give us the ability to find an optimal balance between security and throughput.
The security needs of the Tipper track are very different than those of the Root track.
- Lead-in period duration
- Decision period duration
- Confirmation period duration
- Minimum enactment period
- Concurrency, how many referenda can run in this track at a time
- Support and Approval threshold curves
OpenGov Tracks
Notes:
Highlight difference between parameters of WhiteListedCaller and Root tracks
Criteria for Passing a Proposal
- Approval: Approving votes/total votes cast, weighted by conviction
- Conviction: Locking tokens for longer periods scales their voting impact up to a maximum of 6x with a lockup duration of 896 days
- Support: Approving votes/total possible vote pool, disregarding conviction
Decision and Confirmation Periods
- If Approval and Support thresholds met, confirmation period begins
- Approval and Support must remain above respective thresholds for entire confirmation period
- Confirmation period concludes -> proposal approved early
- Decision period expires -> proposal rejected
- There is only one decision period, during which a proposal can potentially enter and leave many confirmation periods if thresholds aren't consistently met
Lifecycle of A Referendum
Notes:
Steps in order: Proposing, Lead In, Deciding, Confirming, Enactment
Support and Approval Threshold Curves
- We want agility
- Well supported proposals pass quickly
- Controversial proposals get more deliberation
- Addressed with time varying curves
- Support threshold
- Starts at ~50%
- Ends at minimum secure turnout for track
(EX: Big Spender ends at 0 + epsilon %)
- Approval threshold
- Starts at 100%
- Ends at 50 + epsilon %
- Support threshold
- Monotonically decreasing at rates determined by track specific security needs
Example Support and Approval Curves
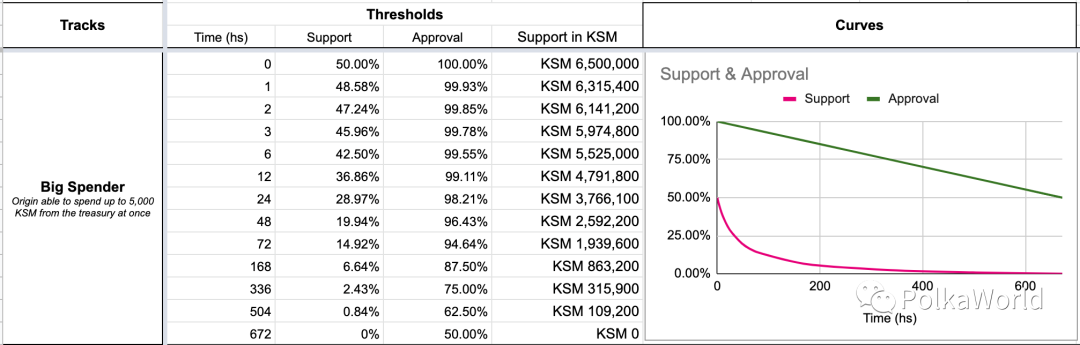
Notes:
From PolkaWorld Article in Resources
Vote Delegation
- Traditional delegation: You entrust one third party with your vote on all matters
- Delegation by track: You may delegate your vote to one or more third parties on a per track basis
- EX: Tipper vote delegated to local ambassador, WhiteListedCaller vote delegated to Parity Technologies, vote retained for all other tracks
- This is likely a first!


OpenGov Acting Under Pressure
Typical path to safety: Lower throughput and restricted origins
But in emergencies we may need to pass proposals that both require root origin and are time critical!
Solution: Some sort of oracle capable of providing expert information
Oraclization of Expert Information
- Track everyone's level of expertise
- Allow experts to register sentiment
- Aggregate opinions by level of expertise
But how are these steps accomplished?
Enter...
The Polkadot Fellowship
Purely on-chain membership body to recognize and compensate all individuals who hold and use expert knowledge of Polkadot in line with its broad interest and philosophy
Members hold rank denoting proven level of expertise and commitment as recognized by their peers and, for higher ranks, through general referendum.
Who Make up the Fellowship?
- Experts in the Polkadot core protocol who maintain a consistent level of active contribution
- Notably this does not include core developers of independent parachain protocols, which should develop their own protocol specific fellowships as needed.
- Trajectory
- Currently: < 100 core developers, mostly from Parity or the Web3 Foundation
- Next year or two: Hundreds
- Ideal far future: Tens of thousands, independent of any centralized entity
- Only one fellowship for Polkadot and Kusama
Function of the Fellowship
- WhiteListedCaller track
- Root privileges
- More agile
- Maintains reasonable safety via Fellowship
- White list proposals must pass two votes
- Expertise weighted Fellowship vote via second referendum pallet instantiation
- Same general referendum as other tracks, still requiring majority vote from DOT holders
- Just an oracle!
- Secondarily intended to cultivate a long term base of Polkadot core developers outside of Parity
Notes:
Stress that as an oracle, the Fellowship can't take any action on its own. Any white listed call will still require substantial DOT-holder backing.
OpenGov and Governance Goals
- Open source + single process + track abstraction -> Transparency
- Liberal proposal creation + greater throughput + per-track delegation -> Accessibility
- Accessibility + No special bodies -> Decentralization
- Limited origins + emergency tracks + white list -> Security
- Multiple tracks + low risk tracks -> Concurrency
- Low risk tracks + early confirmation -> Speed
- Support and approval threshold curves + white list -> Agility
OpenGov
By The Numbers
Governance Activity
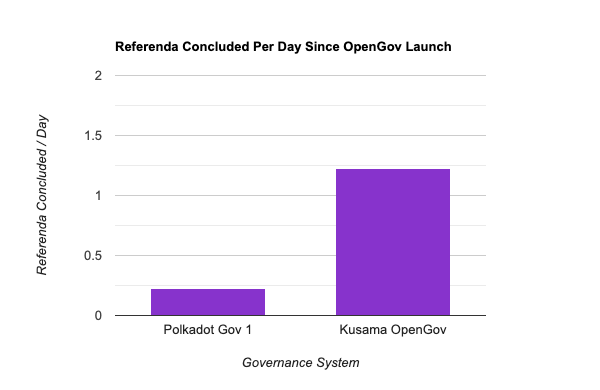
5.5x more daily governance activity
Proposal Origins
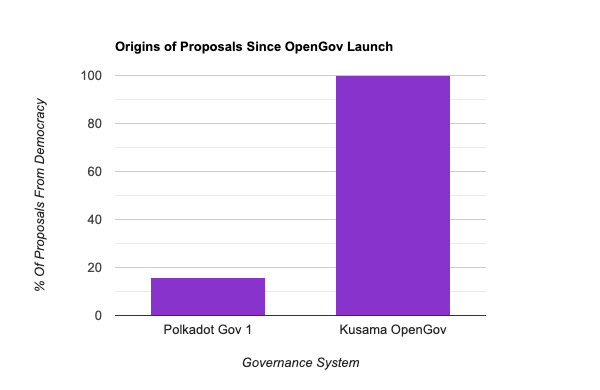
Proposals now primarily authored via democracy
Treasury Usage
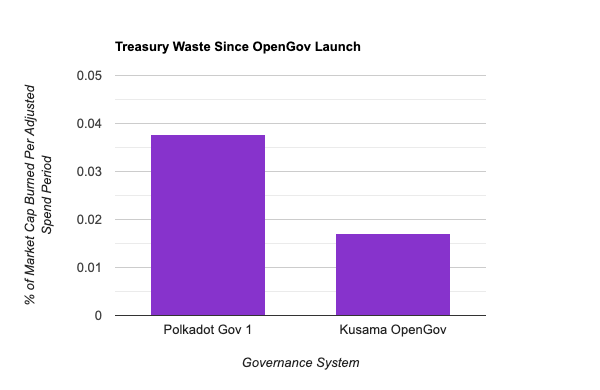
Treasury funds used more efficiently
OpenGov and You
- Participate in OpenGov and Polkadot Fellowship on Polkadot and Kusama
- Can customize OpenGov instances per parachain
- Custom fellowships per parachain
- Potentially create non-technical fellowships, such as a fellowship for brand ambassadors
Resources
Questions
OpenGov in Action
- Vote - https://kusama.subsquare.io/referenda
- Delegate vote - https://kusama.subsquare.io/referenda
- Submit proposal - https://polkadot.js.org/apps/?rpc=wss%3A%2F%2Fkusama-rpc.dwellir.com#/referenda
💱 XCM
The cross consensus messaging format covered from first principals to use in protocols.
Introduction to Cross Consensus Messaging (XCM)
How to use the slides - Full screen (new tab)
Introduction to Cross-Consensus Messaging (XCM)
Core Concepts, Terms, and Logic
Notes:
Pre-requisites
- FRAME (Storage Items, Dispatchables, Event, Errors, etc.)
- Polkadot & parachains conceptually
- Assets (NFTs and fungibles)
---v
At the end of this lecture, you will be able to:
- Define the concepts, syntax, and terms of XCM
- Navigate existing resources that relate to XCM
- Differentiate between XCM and message-passing protocols like XCMP
Cross-chain use cases
Why would we want to perform operations on different blockchains?
Notes:
EXERCISE: ask the class to raise hands and postulate on generally what one might do. We are expecting them to say transfers, but there are so many other things you could do, so many more problems worth solving with cross-chain:
- One contract calling another contract
- Credential checking
- Voting
---v
🎬 Some Concrete Use-cases
- Cross-consensus asset transfers
- Execute platform-specific actions such as governance voting
- Enables single use-case chains
- Collectives
- Identity chains
Notes:
While the goal of XCM is to be general, flexible and future-proof, there are of course practical needs which it must address, not least the transfer of tokens between chains. We need a way to reason about, and pay for, any required fees on the receiving CS. Platform-specific action; for example, within a Substrate chain, it can be desirable to dispatch a remote call into one of its pallets to access a niche feature. XCM enables a single chain to direct the actions of many other chains, which hides the complexity of multi-chain messaging behind an understandable and declarative API.
XCM is a language for communicating intentions between consensus systems.
---v
Consensus systems
A chain, contract or other global, encapsulated, state machine singleton.
It does not even have to be a distributed system, only that it can form some kind of consensus.
Notes:
A consensus system does not necessarily have to be a blockchain or a smart contract. It can be something that already exists in the Web 2.0 world, such as an EC2 instance in an AWS server. XCM is Cross-Consensus since it's much more than cross chain.
---v
✉️ A Format, not a Protocol
XCM is a messaging format.
It is akin to the post card from the post office.
It is not a messaging protocol!
A post card doesn't send itself!
Notes:
It cannot be used to actually "send" any message between systems; its utility is only in expressing what should be done by the receiver. Like many aspects core to Substrate, this separation of concerns empowers us to be far more generic and enable much more. A post card relies on the postal service to get itself sent towards its receivers, and that is what a messaging protocol does.
The transport layer concerns itself with sending arbitrary blobs, it doesn't care about the format. A common format has its benefits though, as we'll see next.
---v
Versioning
XCM is a versioned language.
It's currently in version 3.
What goes in each version is defined via an RFC process.
---v
Terminology: XCMs
XCM, Cross-Consensus Messaging, is the format.
An XCM is a Cross-Consensus Message.
It's not called an XCM message,
the same way it's not called an ATM machine.
😬 Why not native messages?
Drawbacks of relying on native messaging or transaction format:
- Native message format changes from system to system, it also could change within the same system, e.g. when upgrading it
- Common cross-consensus use-cases do not map one-to-one to a single transaction
- Different consensus systems have different assumptions e.g. fee payment
Notes:
- A system which intends to send messages to more than one destination would need to understand how to author a message for each. On that note, even a single destination may alter its native transaction/message format over time. Smart contracts might get upgrades, blockchains might introduce new features or alter existing ones and in doing so change their transaction format.
- Special tricks may be required to withdraw funds, exchange them and then deposit the result all inside a single transaction. Onward notifications of transfers, needed for a coherent reserve-asset framework, do not exist in chains unaware of others. Some use-cases don't require accounts.
- Some systems assume that fee payment had already been negotiated, while some do not. It's up to the interpreter to interpret the intention how it makes sense.
---v
Message format changes

---v
Message format changes

---v
Message format changes
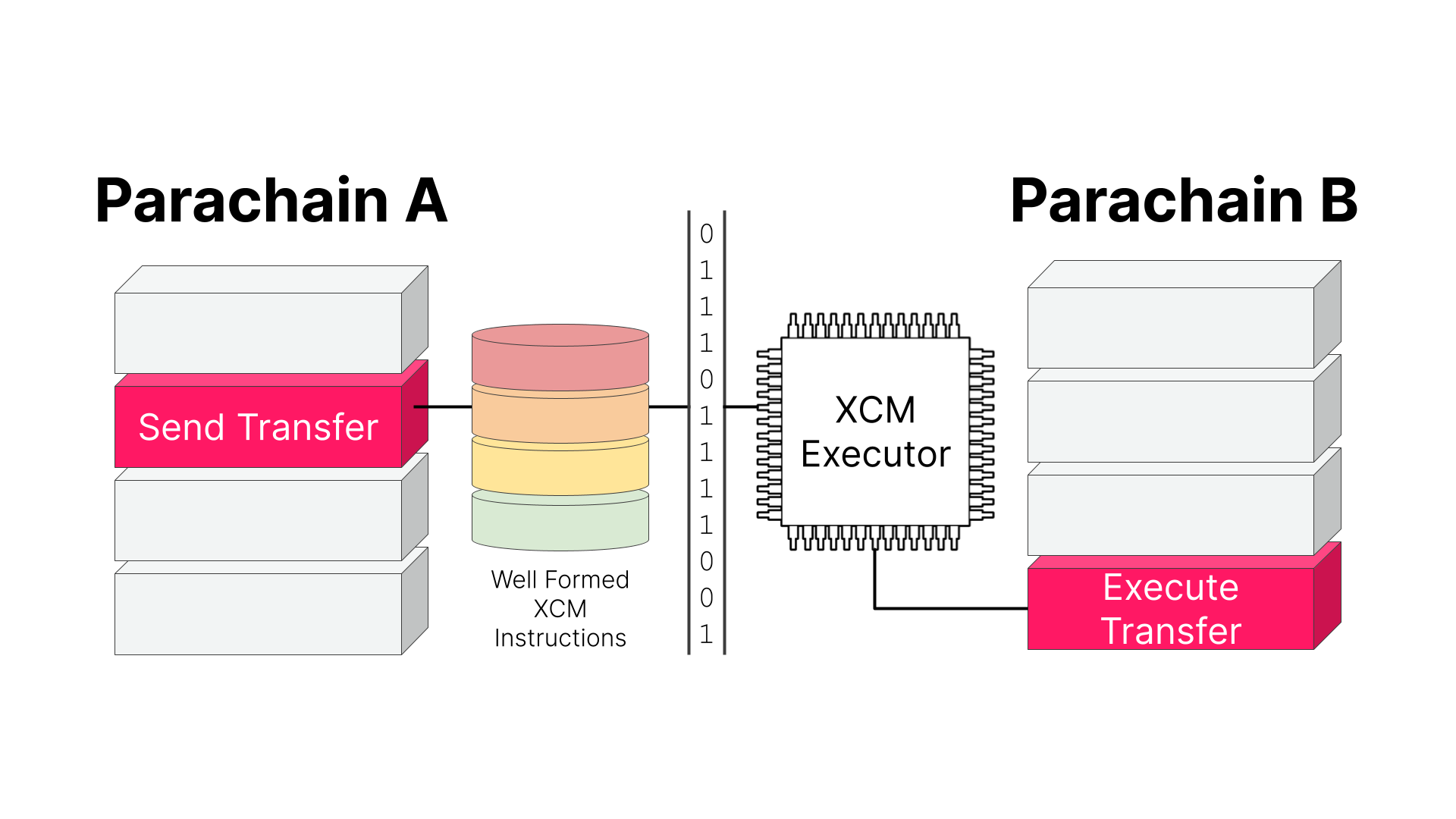
Notes:
XCM abstracts away the actual on-chain operation that will be called, which lets the recipient redirect calls to always make them valid.
---v
No one-to-one mapping
Notes:
You might want to withdraw some assets and deposit some amount to one account and another to another. Using transactions, you'd have to send many messages to achieve this.
---v
Different assumptions
Notes:
Different systems have different assumptions. Using native messages, you'd have to tailor your messages to all systems you want to message.
Four 'A's
XCM assumes the following things from the underlying environment.
- Agnostic
- Absolute
- Asynchronous
- Asymmetric
Notes:
The 4 'A's are assumptions XCM makes over the transport protocol and overall the environment where these messages are sent and processed.
---v
Agnostic
XCM makes no assumptions about the nature of the Consensus System between which messages are being passed.
Notes:
XCM is not restricted to Polkadot, it's a language that can be used for communication between any systems. For example, EVM-chains or Cosmos hubs.
---v
Absolute
XCM assumes that the environment guarantees delivery, interpretation, and ordering of messages.
Notes:
The message format does not do much about the message possibly not being delivered. In IBC, for example, you factor in fallibility of the transport protocol into your messages.
---v
Asynchronous
XCMs crossing the barrier between a single consensus system cannot generally be synchronous.
XCM in no way assume that the sender will be blocking on messages.
Notes:
You can't just block execution in the middle of a block, it has to be asynchronous. Different systems have different ways of tracking time. No assumption of blocking for sender/receiver.
Generally, consensus systems are not designed to operate in sync with external systems. They intrinsically need to have a uniform state to reason about and do not, by default, have the means to verify states of other consensus systems. Thus, each consensus system cannot make any guarantees on the expected time required to deliver results; doing so haphazardly would cause the recipient to be blocked waiting for responses that are either late or would never be delivered, and one of the possible reasons for that would be an impending runtime upgrade that caused a change in how responses are delivered.
---v
Asymmetric
XCM doesn't assume there'll be messages flowing in the other direction.
If you want to send responses, you have to make it explicitly.
Notes:
There are no results or callbacks. Any results must be separately communicated to the sender with an additional message. The receiver side can and does handle errors, but the sender will not be notified, unless the error handler specifically tries to send back an XCM that makes some sort of XCM that notifies status back to the origin, but such an action should be considered as constructing a separate XCM for the sole purpose of reporting information, rather than an intrinsic functionality built into XCM. XCM is a bit like REST. XCMP is a bit like TCP/IP but not quite. Analogies can often hurt more than they help.
📍 Locations in XCM
Before sending a message to another system, we need a way to address it.
Notes:
XCM defines a Location type that acts as a URL for consensus systems.
The Location type identifies any single location that exists within the world of consensus.
Representing a scalable multi-shard blockchain such as Polkadot, an ERC-20 asset account on a parachain, a smart contract on some chain, etc.
It is usually represented as a location relative to the current consensus system.
Relative locations are easier to handle due to the fact that the network structure can change.
Locations don't define the actual path to get there, just a way of addressing.
---v
Interior locations
Given two consensus systems, A and B. A is interior to B if a state change in A implies a state change in B.
Notes:
An example, a smart contract in Ethereum would be interior to Ethereum itself.
---v
Location hierarchy
Notes:
Locations form a hierarchy using the interior relation.
---v
Location Representation
#![allow(unused)] fn main() { struct Location { parents: u8, junctions: Junctions, } }
#![allow(unused)] fn main() { enum Junction { Parachain(u32), AccountId32 { id: [u8; 32], network: Option<NetworkId> }, PalletInstance(u8), GeneralIndex(u128), GlobalConsensus(NetworkId), ... } }
Notes:
Right now Junctions are limited to 8 because of stack space. We also don't expect Junctions being more than 8 levels deep.
It's perfectly possible to create locations that don't point anywhere.
---v
Network Id
#![allow(unused)] fn main() { enum NetworkId { ByGenesis([u8; 32]), ByFork { block_number: u64, block_hash: [u8; 32] }, Polkadot, Kusama, Westend, Rococo, Wococo, Ethereum { chain_id: u64 }, BitcoinCore, BitcoinCash, } }
Notes:
Junctions are ways to descend the location hierarchy
---v
Text notation
#![allow(unused)] fn main() { Location { parents: 1, interior: Parachain(50) } }
-->
../Parachain(50)
Notes:
This notation comes from an analogy to a file system.
---v
Universal Location
The Universal Location is a theoretical location. It's the parent of all locations which generate their own consensus. It itself has no parents.
---v
Universal Location
Notes:
We can imagine a hypothetical location that contains all top-level consensus systems.
---v
Absolute locations
#![allow(unused)] fn main() { pub type InteriorLocation = Junctions; }
Sometimes, absolute locations are necessary, e.g. for bridges.
They don't have parents.
The first junction has to be a GlobalConsensus.
Notes:
To write an absolute location, we need to know our location relative to the Universal Location.
---v
What are Locations used for?
- Addressing
- Origins
- Assets
- Fees
- Bridging
---v
Cross-Chain Origins
When a receiver gets an XCM, a Location specifies the sender.
This Location is relative to the receiver.
Can be converted into a pallet origin in a FRAME runtime
Used for determining privileges during XCM execution.
Notes:
Reanchoring:
Since Locations are relative, when an XCM gets sent over to another chain, the origin location needs to be rewritten from the perspective of the receiver, before the XCM is sent to it.
Location Examples
---v
Sibling parachain
../Parachain(1001)
Notes:
What does the location resolve to if evaluated on Parachain(1000)?
---v
Sibling parachain
../Parachain(1001)
---v
Parachain account
Parachain(1000)/AccountId32(0x1234...cdef)
Notes:
What does the location resolve to if evaluated on the relay chain?
---v
Parachain account
Parachain(1000)/AccountId32(0x1234...cdef)
---v
Bridge
../../GlobalConsensus(Kusama)/Parachain(1000)
Notes:
Speak to an example of non-parachain multi-location that would use a bridge XCM reasons about addressing (as in a postal address) that must include understanding where you are, not just where you are going! This will be very powerful later on (Origins)
---v
Bridge
../../GlobalConsensus(Kusama)/Parachain(1000)
Notes:
Even with Bridge Hubs, the relative location is what you'd expect. Bridge Hubs are just a way for routing messages. They are an implementation detail of the transport layer.
---v
Bridge (actual routing)
Notes:
The actual message is routed through Bridge Hub.
Sovereign Accounts
Locations external to the local system can be represented by a local account.
We call this the sovereign account of that location.
They are a mapping from a Location to an account id.
Notes:
A sovereign account is an account on one system that is controlled by another on a different system. A single account on a system can have multiple sovereign accounts on many other systems. In this example, Alice is an account on AssetHub, and it controls a sovereign account on Collectives.
When transferring between consensus systems, the sovereign account is the one that gets the funds on the destination system.
---v
Sovereign Accounts again
💰 Assets in XCM
Most messages will deal with assets in some way.
How do we address these assets?
---v
Asset Representation
#![allow(unused)] fn main() { struct Asset { pub id: AssetId, pub fun: Fungibility, } struct AssetId(Location); // <- We reuse the location! enum Fungibility { Fungible(u128), NonFungible(AssetInstance), } }
Notes:
We use locations, which we've already discussed, to refer to assets.
A Asset is composed of an asset ID and an enum representing the fungibility of the asset. Asset IDs are the location that leads to the system that issues it, this can be just an index in an assets pallet, for example.
Assets can also either be fungible or non-fungible: Fungible - each token of this asset has the same value as any other NonFungible - each token of this asset is unique and cannot be seen as having the same value as any other token under this asset
---v
Asset filtering and wildcards
#![allow(unused)] fn main() { enum AssetFilter { Definite(Assets), Wild(WildAsset), } enum WildAsset { All, AllOf { id: AssetId, fun: WildFungibility }, // Counted variants } enum WildFungibility { Fungible, NonFungible, } }
Notes:
Sometimes we don't want to specify an asset, but rather filter a collection of them. In this case, we can either list all the assets we want or use a wildcard to select all of them. In reality, it's better to use the counted variant of the wildcards, for benchmarking.
Reanchoring
How do different locations reference the same asset?
Notes:
Locations are relative, so they must be updated and rewritten when sent to another chain, for them to be interpreted correctly.
Native tokens are referenced by the location to their system.
---v
USDT from Asset Hub
PalletInstance(50)/GeneralIndex(1984)
---v
USDT from Bridge Hub
../Parachain(1000)/PalletInstance(50)/GeneralIndex(1984)
---v
Reanchoring to the rescue
🤹 Cross-consensus transfers
Notes:
The two ways of transferring assets between consensus systems are teleports and reserve transfers.
---v
1. Asset teleportation
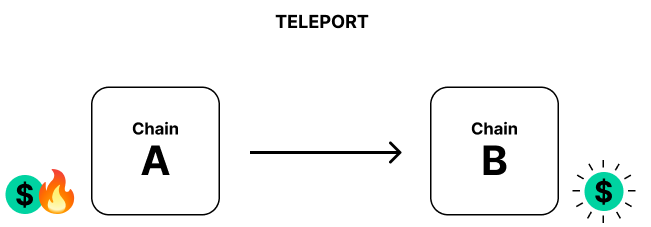
Notes:
Teleportation works by burning the assets on the source chain and minting them on the destination chain. This method is the simplest one, but requires a lot of trust, since failure to burn or mint on either side will affect the total issuance.
---v
1.1. Example: System parachains?
---v
1.2. Example: Polkadot and Kusama?
---v
2. Reserve asset transfers
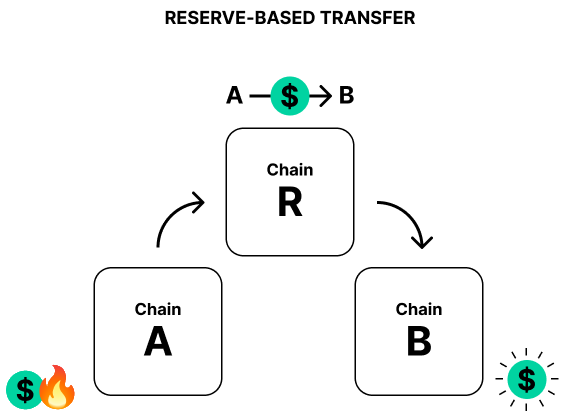
Notes:
Reserve asset transfers are more complicated, since they bring in a third actor called the reserve chain. Chain A and B needn't trust each other, they only need to trust the reserve chain. The reserve chain holds the real assets, A and B deal only with derivatives. The transfer is made by burning derivatives from A, moving them from A's SA to B's SA in R, then minting on B.
In some cases, the sender, A, can also be the reserve for a particular asset, in which case the process is simplified, there's no burning of derivatives. This usually happens with parachains' native tokens.
You always trust the issuer of the token to not mint infinite tokens.
---v
2.1. Example: Parachain native tokens
Notes:
Most parachains act as the reserve for their own token. To transfer their token to other chains, they move the real assets to a sovereign account and then tell the chain to mint equivalent derivatives.
---v
2.2. Example: Polkadot to Kusama
Notes:
AssetHub Kusama acts as the reserve for KSM. Kusama doesn't trust Polkadot to teleport KSM to it, but it does trust its own reserve, the AssetHub. Polkadot has a sovereign account in Kusama's AssetHub with some amount of KSM. Whenever some user in Polkadot wants to get KSM on Kusama, they just give the DOT to Polkadot and the KSM are moved from one sovereign account to another. No new trust relationships are added.
Summary
- XCM
- XCM vs XCMP
- Locations
- Sovereign Accounts
- Assets
- Reanchoring
- Cross-consensus transfers
- Teleports
- Reserve asset transfers
---v
Next steps
- Blog series introducing XCM: Parts 1, 2, and 3.
- XCM Format repository
- XCM Docs
---v

XCVM
How to use the slides - Full screen (new tab)
XCVM
🫀 The XCVM
At the core of XCM lies the Cross-Consensus Virtual Machine (XCVM).
A “message” in XCM is an XCVM program, which is a sequence of instructions.
The XCVM is a state machine, state is kept track in registers.
Notes:
It’s an ultra-high level non-Turing-complete computer. Messages are one or more XCM instructions. The program executes until it either runs to the end or hits an error, at which point it finishes up and halts. An XCM executor following the XCVM specification is provided by Parity, and it can be extended or customized, or even ignored altogether and users can create their own construct that follows the XCVM spec.
📜 XCVM Instructions
XCVM Instructions might change a register, they might change the state of the consensus system or both.
---v
Kinds of instructions
- Command
- Trusted Indication
- Information
- System Notification
---v
Example: TransferAsset
An instruction used to transfer assets to some other address.
#![allow(unused)] fn main() { TransferAsset { assets: Assets, beneficiary: Location, } }
Notes:
This instruction is a command. It needs to know which assets to transfer and to which account to transfer them to.
XCVM Registers
Notes:
Registers are the state of XCVM.
Note that they are temporary/transient.
We'll talk about are the holding and origin registers, but there are more.
---v
📍 The Origin Register
Contains an Option<Location> of the cross-consensus origin where the message originated from.
Notes:
This Location can change over the course of program execution.
It might be None because some instructions clear the origin register.
---v
💸 The Holding Register
Expresses a number of assets in control of the xcm execution that have no on-chain representation.
They don't belong to any account.
It can be seen as the register holding "unspent assets".
Basic XCVM Operation
Notes:
The XCVM fetches instruction from the program and executes them one by one.
---v
XCVM vs. Standard State Machine
- Error handler register
- Appendix register
Notes:
- Code that is run in the case where the XCM program fails or errors. Regardless of the result, when the program completes, the error handler register is cleared. This ensures that error handling logic from a previous program does not affect any appended code (i.e. the code in the error handler register does not loop infinitely, the code in the Appendix register cannot access the result of the code execution in the error handler).
- Code that is run regardless of the execution result of the XCM program.
---v
More complete XCVM operation
💁 XCM by example
---v
The WithdrawAsset instruction
#![allow(unused)] fn main() { enum Instruction { /* snip */ WithdrawAsset(Assets), /* snip */ } }
Notes:
There are a number of instructions
which place assets on the Holding Register.
One very simple one is the
WithdrawAsset instruction.
It withdraws some assets from the account of the location specified in the Origin Register. But what does it do with them? If they don’t get deposited anywhere then it's a pretty useless operation. These assets are held in the holding register until something is done with them, for example, using the following instruction.
---v
The BuyExecution instruction
#![allow(unused)] fn main() { enum Instruction { /* snip */ BuyExecution { fees: Asset, weight_limit: WeightLimit, }, /* snip */ } }
Notes:
This instruction uses the specified assets in the Holding register to buy weight for the execution of the following instructions. It's used in systems that pay fees.
weight_limit is a sanity check, to make sure that the execution errors if you would buy more than that weight.
The estimate for the weight has to come from using the recipient's weigher, not the sender's.
The recipient is the one who actually executes the message.
---v
The DepositAsset instruction
#![allow(unused)] fn main() { enum Instruction { /* snip */ DepositAsset { assets: AssetFilter, beneficiary: Location, }, /* snip */ } }
Notes:
Takes assets from the holding register and deposits them in a beneficiary. Typically an instruction that places assets into the holding register would have been executed previously.
---v
Putting it all together
#![allow(unused)] fn main() { Xcm(vec![ WithdrawAsset((Here, amount).into()), BuyExecution { fees: (Here, amount).into(), weight_limit: Limited(sanity_check_weight_limit) }, DepositAsset { assets: All.into(), beneficiary: AccountId32 { ... }.into() }, ]) }
Notes:
All examples in these slides use the latest xcm version.
---v
Good pattern
#![allow(unused)] fn main() { Xcm(vec![ WithdrawAsset((Here, amount).into()), BuyExecution { fees: (Here, amount).into(), weight_limit: Limited(sanity_check_weight_limit) }, DepositAsset { assets: All.into(), beneficiary: AccountId32 { ... }.into() }, RefundSurplus, DepositAsset { assets: All.into(), beneficiary: sender } ]) }
Reserve asset transfer
#![allow(unused)] fn main() { Xcm(vec![ WithdrawAsset(asset), InitiateReserveWithdraw { assets: All.into(), reserve: reserve_location, xcm: /* ...what to do with the funds in the reserve... */, }, ]) }
Notes:
This message is executed locally.
Then, a message is sent to the reserve location.
That message contains the custom xcm provided along with other instructions.
---v
Message received in reserve
#![allow(unused)] fn main() { Xcm(vec![ WithdrawAsset(reanchored_asset), ClearOrigin, // <- Why is this needed? /* ...custom instructions... */ ]) }
Notes:
This is the message the reserve receives.
The ClearOrigin instruction deletes the content of the origin register.
This is needed because we don't trust the origin to do anything other than move its own assets.
---v
Custom XCM
#![allow(unused)] fn main() { let xcm_for_reserve = Xcm(vec![ DepositReserveAsset { assets: All.into(), dest: location, xcm: Xcm(vec![ DepositAsset { assets: All.into(), beneficiary: AccountId32 { ... }.into(), }, ]), }, ]); }
Notes:
For a simple reserve asset transfer, this message will work.
---v
Message received in destination
#![allow(unused)] fn main() { Xcm(vec![ ReserveAssetDeposited(reanchored_asset), ClearOrigin, // <- Why is this needed? /* ...custom instructions... */ ]) }
Notes:
A very clear exploit in not having ClearOrigin here is syphoning all funds from
the reserve's sovereign account in the destination.
The destination can't trust the reserve to totally speak for the source, only for the assets.
Summary
- XCVM
- Kinds of instructions
- Registers
- Origin
- Holding
- Error handler
- Appendix
- Instructions
- WithdrawAsset, BuyExecution, DepositAsset
- RefundSurplus
- InitiateReserveWithdraw, ReserveAssetDeposited
---v
Next steps
- Blog series introducing XCM: Parts 1, 2, and 3.
- XCM Format repository
- XCM Docs
XCM Pallet
How to use the slides - Full screen (new tab)
XCM Pallet
Lesson goals:
- Understand what the interface of the pallet is and its implementation.
- How versioning discovery works.
- How receiving responses work.
- Understand how to craft XCM in FRAME pallets.
The XCM pallet
We have now learnt about the XCVM and FRAME.
The XCM pallet is the bridge between the XCVM subsystem and the FRAME subsystem.
It also allows us to send/execute XCM and interact with the XCM executor.
How XCM is expected to be used
XCM is not intended to be written by end-users.
Instead, developers write XCVM programs, and package them up into FRAME extrinsics.
Notes:
How do wallets wallet providers use XCM ?
We will see examples of XCM being built in the runtime when exploring teleport_assets and reserve_transfer_assets extrinsics.
Key roles of pallet-xcm
- Allows to interact with the
xcm-executorby executing xcm messages. These can be filtered through theXcmExecuteFilter. - Allows sending arbitrary messages to other chains for certain origins.
The origins that are allowed to send message can be filtered through
SendXcmOrigin. - Provides an easier interface to do reserve based transfers and teleports.
The origins capable of doing these actions can be filtered by
XcmTeleportFilterandXcmReserveTransferFilter. - Handles XCM version negotiation duties.
- Handles asset-trap/claim duties.
- And other state based requirements of the XCVM.
Notes:
- Even when the XCM pallet allows any FRAME origin to send XCMs, it distinguishes root calls vs any other origin calls.
In the case of the latter, it appends the
DescendOrigininstruction to make sure non-root origins cannot act on behalf of the parachain.
The XCM Pallet
pallet-xcm provides default implementations for many traits required by XcmConfig.
pallet-xcm also provides an interface containing 10 different extrinsics, which can be split into three categories:
- Primitive functions to locally
executeorsendan XCM. - High-level functions for asset transfers between systems, e.g. teleportation and reserve asset transfers.
- Extrinsics aimed exclusively at version negotiation.
pallet-xcm Primitive extrinsics
-
executeDirect access to the XCM executor. Executed on behalf of FRAME's signed origin.
Notes:
It checks the origin to ensure that the configured SendXcmOrigin filter is not blocking the execution.
It executes the message locally and returns the outcome as an event.
---v
pallet-xcm Primitive extrinsics
send
Sends a message to the provided destination.
Notes:
This extrinsic is a function to send a message to a destination.
It checks the origin, the destination and the message.
Then it lets the XcmRouter handle the forwarding of the message.
pallet-xcm Asset Transfer extrinsics


Notes:
We have already seen what teleports and reserve transfers mean in lesson 7.1; A quick reminder.
---v
pallet-xcm Asset Transfer extrinsics
limited_teleport_assets
This extrinsic allows the user to perform an asset teleport.
---v
limited_teleport_assets
-
pallet-xcmcomposes the following XCM and passes it toxcm‑executor - Parachain A then sends the following message to the trusted destination
#![allow(unused)] fn main() { Xcm(vec![ WithdrawAsset(assets), SetFeesMode {jit_withdraw: true}, InitiateTeleport {assets: Wild(AllCounted(max_assets)), dest, xcm}, ]) }
#![allow(unused)] fn main() { Xcm(vec![ ReceiveTeleportedAsset(assets), ClearOrigin, BuyExecution { fees, weight_limit }, DepositAsset { assets: Wild(AllCounted(max_assets)), beneficiary }, ]) }
---v
pallet-xcm Asset Transfer extrinsics
limited_reserve_transfer_assets
Allow the user to perform a reserve-backed transfer from the reserve chain to the destination.
---v
limited_reserve_transfer_assets
-
pallet-xcmcomposes the following XCM and passes it toxcm‑executor - Reserve Chain then sends the following mesasge to the destination
#![allow(unused)] fn main() { Xcm(vec![ SetFeesMode { jit_withdraw: true }, TransferReserveAsset { assets, dest, xcm }, ]) }
#![allow(unused)] fn main() { Xcm(vec![ ReserveAssetDeposited(assets), ClearOrigin, BuyExecution { fees, weight_limit }, DepositAsset { assets: Wild(AllCounted(max_assets)), beneficiary }, ]) }
🗣️ version negotiation with pallet-xcm
XCM is a versioned message format.
One version may contain more or different instructions than another, so for parties to communicate via XCM, it is important to know which version the other party is using.
The version subscription mechanism allows parties to subscribe to version updates from others.
#![allow(unused)] fn main() { pub enum VersionedXcm { V2(v2::Xcm), V3(v3::Xcm), } }
Notes:
- V0 and V1 were removed with the addition of XCM v3.
---v
🗣️ version negotiation with pallet-xcm
But chains need to be aware of the version supported by each other.
SubscribeVersion and QueryResponse play a key role here:
#![allow(unused)] fn main() { enum Instruction { // --snip-- SubscribeVersion { query_id: QueryId, max_response_weight: u64, }, QueryResponse { query_id: QueryId, response: Response, max_weight: u64, }, // --snip-- } }
Notes:
query_idwould be identical in theSubscribeVersionandQueryResponseinstructions.- Likewise,
max_response_weightshould also matchmax_weightin the response
---v
🗣️ version negotiation with pallet-xcm
ResponseHandler: The component in charge of handling response messages from other chains.SubscriptionService: The component in charge of handling version subscription notifications to other chains
#![allow(unused)] fn main() { impl Config for XcmConfig { // --snip-- type ResponseHandler = PalletXcm; type SubscriptionService = PalletXcm; } }
Notes:
PalletXcmkeeps track of the versions of each chain when it receives a response.- It also keeps track of which chains it needs to notify whenever we change our version
Subscription Service
Any system can be notified of when another system changes its latest supported XCM version.
This is done via the SubscribeVersion and UnsubscribeVersion instructions.
The SubscriptionService type defines what action to take when processing a SubscribeVersion instruction.
Notes:
pallet-xcm provides a default implementation of this trait.
When receiving a SubscribeVersion, the chain sends back an XCM with the QueryResponse instruction containing its current version.
Version Negotiation
The subscription service leverages any kind of exchange of XCMs between two systems to begin the process of version negotiation.
Each time a system needs to send a message to a destination with an unknown supported XCM version, its location will be stored in the VersionDiscoveryQueue.
This queue will then be checked in the next block and SubscribeVersion instructions will be sent out to those locations present in the queue.
Notes:
SubscribeVersion - instructs the local system to notify the sender whenever the former has its XCM version upgraded or downgraded. UnsubscribeVersion - if the sender was previously subscribed to XCM version change notifications for the local system, then this instruction tells the local system to stop notifying the sender on version changes.
---v
🗣️ XCM Version Negotiation
XCM version negotiation:
- Chain A sends
SubscribeVersionto chain B. - Chain B responds
QueryResponseto chain A with the same query_id and max_weight params, and puts the XCM version in the response - Chain A stores chain B's supported version on storage.
- The same procedure happens from chain B to chain A.
- Communication is established using the highest mutually supported version.
---v
🗣️ XCM Version Negotiation
In the following scenario Chain A is using XCM v2
Response Handler
Version negotiation is just one example among many kinds of queries one chain can make to another.
Regardless of which kind of query was made, the response usually takes the form of a QueryResponse instruction.
---v
Response Handler
We have talked about XCM being asymmetric, so why are there responses ?
---v
Information Reporting
Every instruction used for information reporting contains QueryResponseInfo.
#![allow(unused)] fn main() { pub struct QueryResponseInfo { pub destination: MultiLocation, pub query_id: QueryId, pub max_weight: Weight, } }
Notes:
All Information Reporting instructions contain a QueryResponseInfo struct, which contains information about the intended destination of the response, the ID of the query, and the maximum weight that the dispatchable call function can use.
The dispatchable call function is an optional operation that XCM author can specify, and is executed upon receiving the response, effectively acting as a lifecycle hook on response.
---v
Information retrieval
#![allow(unused)] fn main() { enum Instruction { // --snip-- QueryResponse { query_id: QueryId, response: Response, max_weight: Weight, querier: Option<MultiLocation>, }, // --snip-- } }
Notes:
The above instruction is the one used for offering some requested information that the local system is expecting.
querier parameter should be checked to ensure that the system that requested the information matches with what is expected.
Asset Trap/Claims with pallet-xcm
What happens when there are still funds in the holding register after the execution of every instruction is done?
Any situation in which the holding register contains assets after the execution of the XCM message would lead to asset trapping.
These traps need to be stored to allow for future claiming of these trapped assets, FRAME provide us with means for this.
Notes:
- This is handled in the
post_executefunction of the xcm-executor.
---v
Asset Trap/Claims with pallet-xcm
-
pallet-xcmasset trapper: Trapped assets are stored in theAssetTrapsstorage item and indexed by origin and assets -
pallet-xcmasset claimer:pallet-xcmalso allows for claiming trapped assets, providing that:- the origin claiming the assets is identical to the one that trapped them.
- the
Assetbeing claimed is identical to the one that was trapped
Notes:
- Each map element on
AssetTrapsholds a counter of how many times such origin has trapped suchAsset. - Every time such
Assetgets reclaimed, the counter decrements by one.
Extrinsic breakdown
Let's jump into the code and have a look at limited_teleport_assets extrinsic.
Summary
In this lecture, we learnt:
- What the XCM pallet is and what it's used for.
- How XCM is intended to be used, both by wallet and runtime developers.
- The useful extrinsics in the XCM pallet.
- How XCM versioning works.
- How the XCM pallet is used to receive responses.
- How assets might be trapped and how to use the XCM pallet to claim them.
Parachain XCM Configuration
How to use the slides - Full screen (new tab)
Parachain XCM Configuration
---v
At the end of this lecture, you will be able to:
- Understand the different XCM configurable parts of a chain
- Construct different XCM configurations for chains with different needs
🛠️ Configurables in XcmConfig
Notes:
The XCM Configuration has many configurable items
EXERCISE: ask the class to raise hands and postulate on what they think should be configurable.
---v
🛠️ Configurables in XcmConfig
#![allow(unused)] fn main() { // How we convert locations into account ids type SovereignAccountOf = SovereignAccountOf; pub struct XcmConfig; impl Config for XcmConfig { // The absolute Location of the current system type UniversalLocation = UniversalLocation; // Pre-execution filters type Barrier = Barrier; // How we withdraw/deposit assets type AssetTransactor = LocalAssetTransactor; // How we convert a Location to a FRAME dispatch origin type OriginConverter = LocalOriginConverter; // How we route the XCM outside this chain type XcmSender = XcmRouter; // Who we trust as reserve chains type IsReserve = ?; // Who do we trust as teleporters type IsTeleporter = ?; // How we weigh a message type Weigher = ?; // How we charge for fees type Trader = ?; // How we handle responses type ResponseHandler = ?; // How we handle asset traps type AssetTrap = ?; // How we handle asset claims type AssetClaims = ?; // How we handle version subscriptions type SubscriptionService = ?; } }
Notes:
-
SovereignAccountOf: Means of converting aLocationinto an account ID Used later for:OriginConverter,AssetTransactor -
xcm-palletis a pallet that not only allows sending and executing XCM messages, but rather it also implements several of the configuration traits and thus can be used perform several XCM configuration actions.
---v
🛠️ xcm-builder
xcm-builder is a crate containing common configuration shims to facilitate XCM configuration.
Most pre-built configuration items can be found in xcm-builder.
It allows to use the XCM executor in FRAME.
🤔 Grab your chain's requirements before starting
Questions that you should have answers for:
-
Is my chain going to transfer just the native token? Is my chain going to receive several other kinds of assets?
-
Is my chain going to allow free execution? Maybe only limited to some parachains/relay chain?
-
Is my chain a 20 byte account chain? a 32 byte account chain?
-
How will my chain accept fee payment? In one asset? In several?
Notes:
- Some of the answers to these questions might imply you need to use your own custom primitives.
---v
Our starting example setup requirements
- Parachain that does not charge for relay incoming messages.
- Parachain that trusts the relay as the reserve chain for the relay chain tokens.
- Parachain that mints in
pallet-balanceswhen it receives relay chain tokens. - Users can execute XCMs locally.
📁 SovereignAccountOf via xcm-builder
- Defines how we convert a
Locationinto a local account ID. - Useful when we want to withdraw/deposit tokens from a
Locationdefined origin - Useful when we want to dispatch as signed origins from a
Locationdefined origin.
Notes:
- This will define how we convert a
Locationinto a local account ID. - This is useful when we want to withdraw/deposit tokens from a
Locationdefined origin or when we want to dispatch as signed origins from aLocationdefined origin.
---v
📁 SovereignAccountOf via xcm-builder
HashedDescription: Hashes the description of aLocationand converts that into anAccountId.
#![allow(unused)] fn main() { pub struct HashedDescription<AccountId, Describe>(PhantomData<(AccountId, Describe)>); impl< AccountId: From<[u8; 32]> + Clone, Describe: DescribeLocation > ConvertLocation<AccountId> for HashedDescription<AccountId, Describe> { fn convert_location(value: &Location) -> Option<AccountId> { Some(blake2_256(&Describe::describe_location(value)?).into()) } } }
---v
📁 SovereignAccountOf via xcm-builder
HashedDescription. An example of a converter definition:
#![allow(unused)] fn main() { pub type LocationToAccount = HashedDescription<AccountId, ( LegacyDescribeForeignChainAccount, // Legacy conversion - MUST BE FIRST! DescribeTerminus, DescribePalletTerminal )>; }
---v
📁 SovereignAccountOf via xcm-builder
DescribeLocation: Means of converting a location into a stable and unique descriptive identifier.
#![allow(unused)] fn main() { pub trait DescribeLocation { /// Create a description of the given `location` if possible. No two locations should have the /// same descriptor. fn describe_location(location: &Location) -> Option<Vec<u8>>; } }
Notes:
---v
📁 SovereignAccountOf via xcm-builder
DescribeAccountId32Terminal
#![allow(unused)] fn main() { fn describe_location(l: &Location) -> Option<Vec<u8>> { match (l.parents, &l.interior) { (0, X1(AccountId32 { id, .. })) => Some((b"AccountId32", id).encode()), _ => return None, } } }
---v
📁 SovereignAccountOf via xcm-builder
DescribeTerminus
#![allow(unused)] fn main() { fn describe_location(l: &Location) -> Option<Vec<u8>> { match (l.parents, &l.interior) { (0, Here) => Some(Vec::new()), _ => return None, } } }
---v
📁 SovereignAccountOf via xcm-builder
DescribePalletTerminal
#![allow(unused)] fn main() { fn describe_location(l: &Location) -> Option<Vec<u8>> { match (l.parents, &l.interior) { (0, X1(PalletInstance(i))) => Some((b"Pallet", Compact::<u32>::from(*i as u32)).encode()), _ => return None, } } }
---v
📁 SovereignAccountOf via xcm-builder
DescribeAccountKey20Terminal
#![allow(unused)] fn main() { fn describe_location(l: &Location) -> Option<Vec<u8>> { match (l.parents, &l.interior) { (0, X1(AccountKey20 { key, .. })) => Some((b"AccountKey20", key).encode()), _ => return None, } } }
---v
📁 SovereignAccountOf via xcm-builder
-
AccountId32Aliases: Converts a localAccountId32Locationinto an account ID of 32 bytes. -
Account32Hash: Hashes theLocationand takes the lowest 32 bytes as account. -
ParentIsPreset: Converts the parentLocationinto an account of the formb'Parent' + trailing 0s
---v
📁 SovereignAccountOf via xcm-builder
-
ChildParachainConvertsVia: Converts the child parachainLocationinto an account of the formb'para' + para_id_as_u32 + trailing 0s -
SiblingParachainConvertsVia: Convert the sibling parachainLocationinto an account of the formb'sibl' + para_id_as_u32 + trailing 0s
UniversalLocation
The absolute location of the consensus system being configured.
#![allow(unused)] fn main() { parameter_types! { pub const UniversalLocation: InteriorLocation = GlobalConsensus(NetworkId::Polkadot).into(); } }
🚧 Barrier via xcm-builder
- Barriers specify whether or not an XCM is allowed to be executed on the local consensus system.
- They are checked before the actual XCM instruction execution.
- Barriers should not involve any heavy computation.
Notes:
At the point at which barriers are checked nothing has yet been paid for its execution.
---v
🚧 Barrier via xcm-builder
Physical vs Computed origin
- Physical origin: the consensus system that built this particular XCM and sent it to the recipient
- Computed origin: the entity that ultimately instructed the consensus system to build the XCM
Notes:
If an EOA transfers some funds via XCM, then the computed origin would be its account, but the physical origin would be the platform that was used (e.g. parachain).
---v
🚧 Barrier via xcm-builder
Barriers that operate upon computed origins must be put inside of WithComputedOrigin.
Allows for origin altering instructions at the start.
#![allow(unused)] fn main() { pub struct WithComputedOrigin<InnerBarrier, LocalUniversal, MaxPrefixes>; }
---v
🚧 Barrier via xcm-builder
TakeWeightCredit: Subtracts the maximum weight the message can consume from the available weight credit. Usually configured for localxcm-execution
---v
🚧 Barrier via xcm-builder
AllowTopLevelPaidExecutionFrom<T>: For origins contained inT, it makes sure the first instruction puts asset into the holding register, followed by aBuyExecutioninstruction capable of buying sufficient weight. Critical to avoid free DOS.
Notes:
-
A chain without
AllowTopLevelPaidExecutionFromcould potentially receive several heavy-computation instructions without paying for it. Checking that the first instructions are indeed paying for execution helps to quick-discard them. -
While
BuyExecutionis crucial for messages coming from other consensus systems, local XCM execution fees are paid as any other substrate extrinsic.
---v
🚧 Barrier via xcm-builder
AllowExplicitUnpaidExecutionFrom<T>: Allows free execution iforiginis contained inTand the first instruction isUnpaidExecution.
Notes:
- This fulfills our requirements
- To meet our example use case, we only need the relay to have free execution.
---v
🚧 Barrier via xcm-builder
AllowKnownQueryResponses: Allows the execution of the message if it contains only an expectedQueryResponseAllowSubscriptionsFrom<T>: If theoriginthat sent the message is contained inT, it allows the execution of the message if it contains only aSubscribeVersionorUnsubscribeVersioninstruction
🪙 AssetTransactor via xcm-builder
- Define how we are going to withdraw and deposit assets
- Heavily dependant on the assets we want our chain to transfer
Notes:
- The relay chain is a clear example of a chain that handles a single token.
- AssetHub on the contrary acts as an asset-reserve chain, and it needs to handle several assets
---v
🪙 AssetTransactor via xcm-builder
FungiblesAdapter: Used for depositing/withdrawing from a set of defined fungible tokens. An example of these would bepallet-assetstokens.NonFungiblesAdapter: Used for depositing/withdrowing NFTs. For examplepallet-nfts.
Notes:
-
Matcher: Matches the
Assetagainst some filters and returns the amount to be deposited/withdrawn -
AccountIdConverter: Means of converting a
Locationinto an account -
For our example, it suffices to uses
CurrencyAdapter, as all we are going to do is mint in a single currency (Balances) whenever we receive the relay token.
---v
🪙 AssetTransactor via xcm-builder
#![allow(unused)] fn main() { fn withdraw_asset( what: &Asset, who: &Location, _maybe_context: Option<&XcmContext>, ) -> result::Result<xcm_executor::Assets, XcmError> { let (asset_id, amount) = Matcher::matches_fungibles(what)?; let who = AccountIdConverter::convert_location(who) .ok_or(MatchError::AccountIdConversionFailed)?; Assets::burn_from(asset_id, &who, amount, Exact, Polite) .map_err(|e| XcmError::FailedToTransactAsset(e.into()))?; Ok(what.clone().into()) } }
---v
🪙 AssetTransactor via xcm-builder
#![allow(unused)] fn main() { fn deposit_asset( what: &Asset, who: &Location, _context: &XcmContext ) -> XcmResult { let (asset_id, amount) = Matcher::matches_fungibles(what)?; let who = AccountIdConverter::convert_location(who) .ok_or(MatchError::AccountIdConversionFailed)?; Assets::mint_into(asset_id, &who, amount) .map_err(|e| XcmError::FailedToTransactAsset(e.into()))?; Ok(()) } }
📍 OriginConverter via xcm-builder
- Defines how to convert an XCM origin, defined by a
Location, into a frame dispatch origin. - Used in the
Transactinstruction.
Notes:
Transactneeds to dispatch from a frame dispatch origin. However thexcm-executorworks with XCM origins which are defined byLocations.OriginConverteris the component that converts one into the other
---v
📍 List of origin converters
-
SovereignSignedViaLocation: Converts theLocationorigin (typically, a parachain origin) into a signed origin. -
SignedAccountId32AsNative: Converts a local 32 byte accountLocationinto a signed origin using the same 32 byte account. -
ParentAsSuperuser: Converts the parent origin into the root origin. -
SignedAccountKey20AsNative: Converts a local 20 byte accountLocationinto a signed origin using the same 20 byte account.
Notes:
ParentAsSuperusercan be used in common-good chains as they do not have a local root origin and instead allow the relay chain root origin to act as the root origin.
🛠️ XcmRouter in XcmConfig
ParentAsUmproutes XCM to relay chain through UMP.XcmpQueueroutes XCM to other parachains through XCMP.
#![allow(unused)] fn main() { pub type XcmRouter = ( // Two routers - use UMP to communicate with the relay chain: cumulus_primitives_utility::ParentAsUmp<ParachainSystem, PolkadotXcm>, // ..and XCMP to communicate with the sibling chains. XcmpQueue, ); }
Notes:
ParachainSystemis a pallet in cumulus that handles incoming DMP messages and queues, among other miscellaneous parachain-related matters.- If the destination location matches the form of
Location { parents: 1, interior: Here }, the message will be routed through UMP. The UMP channel is available by default. - If the destination matches the form of
Location { parents: 1, interior: X1(Parachain(para_id)) }, the message will be routed through XCMP. As of today, an HRMP channel should be established before the message can be routed. - The tuple implementation of this item means the executor will try using the items in order.
---v
Router
#![allow(unused)] fn main() { pub trait SendXcm { type Ticket; fn validate( destination: &mut Option<Location>, message: &mut Option<Xcm<()>>, ) -> SendResult<Self::Ticket>; fn deliver(ticket: Self::Ticket) -> Result<XcmHash, SendError>; } }
Notes:
It's important to validate that the message can indeed be sent before sending it. This ensures you pay for sending fees and you actually do send it.
Summary
In this lecture, we learnt:
- How chains interpret locations and turn them to accounts and FRAME origins
- How to set a barrier to protect our chain from undesired messages
- How to handle assets in XCM
- Other configuration items relevant for XCM
Additional Lessons
XCM Activities
Various XCM activities and exercises.
📥 Clone to start: XCM Activities
See the README included in the repository for further instructions.
XCM in Polkadot
How to use the slides - Full screen (new tab)
XCM in Polkadot
At the end of this lecture, you will be able to:
- Understand the configuration of the Rococo chain
- Send real-world messages between parachain A <-> Rococo
- Identify potential errors on XCM messages
🤔 Considerations
- There should be no trust assumption between chains unless explicitly requested.
- We cannot assume chains will not act maliciously
- Spamming XCM messages creates a DoS problem
🛠️ Rococo Configuration
- Barriers
- Teleport filtering
- Trusted reserves
- Asset transactors
- Fee payment
- Proper XCM Instruction Weighting
- Location to Account/FRAME Origin conversions
Notes:
From now on, we will use the Rococo runtime as a reference. Rococo is a testnet for Polkadot and Kusama that we will use in to test our XCM messages. Most of the Rococo configuration is identical to that in Polkadot.
🚧 XCM Barrier in Rococo
#![allow(unused)] fn main() { /// The barriers one of which must be passed for an XCM message to be executed. pub type Barrier = ( // Weight that is paid for may be consumed. TakeWeightCredit, // If the message is one that immediately attempts to pay for execution, then allow it. AllowTopLevelPaidExecutionFrom<Everything>, // Messages coming from system parachains need not pay for execution. AllowUnpaidExecutionFrom<IsChildSystemParachain<ParaId>>, // Expected responses are OK. AllowKnownQueryResponses<XcmPallet>, // Subscriptions for version tracking are OK. AllowSubscriptionsFrom<Everything>, ); }
---v
🚧 XCM Barrier in Rococo
TakeWeightCreditandAllowTopLevelPaidExecutionFromare used to prevent spamming for local/remote XCM execution.AllowUnpaidExecutionFromlets a system parachain have free execution in the relay.AllowKnownQueryResponsesandAllowSubscriptionsFrom, as we know already, are mostly used for versioning.
Notes:
- Child system parachains are parachains that contain core polkadot features, and they will get a paraId of less than 1000. They are allocated by Polkadot governance and get free execution.
AllowKnownQueryResponseswill check pallet-xcm storage to know whether the response is expected. -AllowSubscriptionsFromdetermines that any origin is able to subscribe for version changes.
🤝 Trusted teleporters in Rococo
#![allow(unused)] fn main() { parameter_types! { pub const RocLocation: MultiLocation = Here.into(); pub const Rococo: MultiAssetFilter = Wild(AllOf { fun: WildFungible, id: Concrete(RocLocation::get()) }); pub const AssetHub: MultiLocation = Parachain(1000).into(); pub const Contracts: MultiLocation = Parachain(1002).into(); pub const Encointer: MultiLocation = Parachain(1003).into(); pub const RococoForAssetHub: (MultiAssetFilter, MultiLocation) = (Rococo::get(), AssetHub::get()); pub const RococoForContracts: (MultiAssetFilter, MultiLocation) = (Rococo::get(), Contracts::get()); pub const RococoForEncointer: (MultiAssetFilter, MultiLocation) = (Rococo::get(), Encointer::get()); } pub type TrustedTeleporters = ( xcm_builder::Case<RococoForAssetHub>, xcm_builder::Case<RococoForContracts>, xcm_builder::Case<RococoForEncointer>, ); }
---v
🤝 Trusted teleporters in Rococo
- Teleporting involves trust between chains.
- 1000 (Asset Hub) and 1001 (Contracts) and 1002 (Encointer) are allowed to teleport tokens represented by the Here
- Here represents the relay token
#![allow(unused)] fn main() { impl xcm_executor::Config for XcmConfig { /* snip */ type IsTeleporter = TrustedTeleporters; /* snip */ } }
Notes:
- Asset Hub, Rococo and Encointer are able to teleport the relay chain token
- Any other chain sending a
ReceiveTeleportedAssetor any other token being teleported will be rejected withUntrustedTeleportLocation.
💱Trusted reserves in Rococo
- Rococo does not recognize any chain as reserve
- Rococo prevents reception of any ReserveAssetDeposited message
#![allow(unused)] fn main() { impl xcm_executor::Config for XcmConfig { /* snip */ type IsReserve = (); /* snip */ } }
Notes:
- Trusting other parachains (e.g., common good parachains) to be reserves of the relay native token would cause rare situations with the total issuance. For instance, users could drain reserves of the sovereign account with teleported funds.
📁 LocationToAccountId in Rococo
- Conversion between a multilocation to an AccountId is a key component to withdraw/deposit assets and issue
Transactoperations. - Parachain origins will be converted to their corresponding sovereign account.
- Local 32 byte origins will be converted to a 32 byte defined AccountId.
#![allow(unused)] fn main() { pub type LocationConverter = ( // We can convert a child parachain using the standard `AccountId` conversion. ChildParachainConvertsVia<ParaId, AccountId>, // We can directly alias an `AccountId32` into a local account. AccountId32Aliases<RococoNetwork, AccountId>, ); }
Notes:
- Any other origin that is not a parachain origin or a local 32 byte account origin will not be convertible to an accountId.
- Question class what happens if a message coming from a parachain starts with
DescendOrigin? XcmV2 will reject it at the barrier level (Since AllowTopLevelPaidExecutionFrom expects the first instruction to be one of ReceiveTeleportedAsset , WithdrawAsset , ReserveAssetDeposited or ClaimAsset - XcmV3 will pass the barrier as AllowTopLevelPaidExecutionFrom is inside WithComputedOrigin.
🪙 Asset Transactors in Rococo
#![allow(unused)] fn main() { pub type LocalAssetTransactor = XcmCurrencyAdapter< // Use this currency: Balances, // Use this currency when it is a fungible asset // matching the given location or name: IsConcrete<RocLocation>, // We can convert the MultiLocations // with our converter above: LocationConverter, // Our chain's account ID type // (we can't get away without mentioning it explicitly): AccountId, // It's a native asset so we keep track of the teleports // to maintain total issuance. CheckAccount, >; impl xcm_executor::Config for XcmConfig { /* snip */ type AssetTransactor = LocalAssetTransactor; /* snip */ } }
---v
🪙 asset-transactors in Rococo
- Single asset-transactor in Rococo
- Asset-transactor is matching the Here multilocation id to the Currency defined in Balances, which refers to pallet-balances
- Essentially, this is configuring XCM such that the native token (DOT) is associated with the multilocation Here.
Notes:
- Rococo is tracking teleports in the CheckAccount, which is defined in palletXcm. This aims at maintaining the total issuance even if assets have been teleported to another chain.
📍origin-converter in Rococo
#![allow(unused)] fn main() { type LocalOriginConverter = ( // Converts to a signed origin with "LocationConverter" SovereignSignedViaLocation<LocationConverter, RuntimeOrigin>, // Converts a child parachain multilocation to a parachain origin ChildParachainAsNative<parachains_origin::Origin, RuntimeOrigin>, // Converts a local 32 byte multilocation to a signed // origin SignedAccountId32AsNative<WestendNetwork, RuntimeOrigin>, // Converts system parachain origins into root origin ChildSystemParachainAsSuperuser<ParaId, RuntimeOrigin>, ); }
#![allow(unused)] fn main() { impl xcm_executor::Config for XcmConfig { /* snip */ type OriginConverter = LocalOriginConverter; /* snip */ } }
---v
📍origin-converter in Rococo
- Defines ways in which we can convert a multilocation to a dispatch origin, typically used by the
Transactinstruction: - Child parachain origins are converted to signed origins through LocationConverter (
OriginKind == Sovereign). - Child parachains can also be converted to native parachain origins (
OriginKind == Native). - Local 32 byte origins are converted to signed 32 byte origins (
OriginKind == Native).
Notes:
- There exists the concept of a "parachain dispatch origin" which is used for very specific functions (like, e.g., opening a channel with another chain). This gets checked with the ensure_parachain! macro.
- System parachains are able to dispatch as root origins, as they can bee seen as an extension to the rococo runtime itself.
🏋️ Weigher in Rococo
- Uses
WeightInfoBoundswith benchmarked values withpallet-xcm-benchmarks - Full list of weights can be seen here
#![allow(unused)] fn main() { impl xcm_executor::Config for XcmConfig { /* snip */ type Weigher = WeightInfoBounds< crate::weights::xcm::RococoXcmWeight<RuntimeCall>, RuntimeCall, MaxInstructions, >; /* snip */ } }
🔧 WeightTrader in Rococo
- Weight is converted to fee with the WeightToFee type.
- The asset in which we charge for fee is RocLocation. This means we can only pay for xcm execution in the native currency
- Fees will go to the block author thanks to ToAuthor
#![allow(unused)] fn main() { impl xcm_executor::Config for XcmConfig { /* snip */ type Trader = UsingComponents< WeightToFee, RocLocation, AccountId, Balances, ToAuthor<Runtime>>; /* snip */ } }
Notes:
-
Trying to buyExecution with any other token that does not match the specified AssetId (in this case,
RocLocation, which represents the native token) will fail. -
WeightToFee contains an associated function that will be used to convert the required amount of weight into an amount of tokens used for execution payment.
🎨 XcmPallet in Rococo
#![allow(unused)] fn main() { impl pallet_xcm::Config for Runtime { /* snip */ type XcmRouter = XcmRouter; type SendXcmOrigin = xcm_builder::EnsureXcmOrigin<RuntimeOrigin, LocalOriginToLocation>; // Anyone can execute XCM messages locally. type ExecuteXcmOrigin = xcm_builder::EnsureXcmOrigin<RuntimeOrigin, LocalOriginToLocation>; type XcmExecuteFilter = Everything; type XcmExecutor = xcm_executor::XcmExecutor<XcmConfig>; // Anyone is able to use teleportation // regardless of who they are and what they want to teleport. type XcmTeleportFilter = Everything; // Anyone is able to use reserve transfers // regardless of who they are and what they want to transfer. type XcmReserveTransferFilter = Everything; /* snip */ } }
---v
🎨 XcmPallet in Rococo
- No filter on messages for Execution, Teleporting or Reserve transferring.
- Only origins defined by LocalOriginToLocation are allowed to send/execute arbitrary messages.
- LocalOriginToLocation defined to allow council and regular account 32 byte signed origin calls
#![allow(unused)] fn main() { pub type LocalOriginToLocation = ( // We allow an origin from the Collective pallet to be used in XCM // as a corresponding Plurality of the `Unit` body. CouncilToPlurality, // And a usual Signed origin to be used in XCM as a corresponding AccountId32 SignedToAccountId32<RuntimeOrigin, AccountId, RococoNetwork>, ); }
Notes:
-
LocalOrigin allows to go from a frame dispatch origin to a multilocation. This is necessary because we enter the xcm-executor with xcm origins, not with frame dispatch origins. Note that this is an extrinsic in a frame pallet, and thus, we call it with frame origins.
-
Council decisions are converted to
Pluralityjunction multilocations. -
Signed origins are converted to
AccountId32junction multilocations.
XCM in Use
How to use the slides - Full screen (new tab)
XCM in Use
Build dApps with XCM leveraging polkadot.js.org/apps and node.js
Notes:
As we learned in Chapter 3, the XCM pallet serves as a bridge between the XCVM subsystem and the FRAME subsystem. It enables us to send and execute XCM and interact with the XCM executor. In this chapter, I, as the founder of OAK Network and a parachain developer, will demonstrate how to build products using XCM and dispatch them from both polkadot.js apps and Javascript code.
At the end of this lecture, you will be able to:
- Configure XCM for parachain HRMP messages.
- Understand the construction and execution of XCM messages.
- Perform HRMP transactions between parachains using templates.
- Develop proficiency in debugging XCM using xcm-tools.
Overview
- Define the product
- Preparation
- Compose XCM message
- Build client code
- Debug live
Notes:
In this session, I will guide you through the process of building a real use case of XCM, specifically from the perspective of a parachain developer. Our main focus will be on developing for a parachain, not a relay chain like Polkadot. Consequently, we will primarily concentrate on HRMP messages, enabling horizontal communication between two parachains.
- Define Your Product: We'll start by defining the product or application we want to build, clarifying its objectives and functionalities.
- Prepare Chain Config: Next, we'll prepare the necessary chain configurations, ensuring that our application is well-integrated with the target blockchain environment.
- Compose XCM Message: We'll dive into composing XCM messages, which are crucial for communication and interactions between different components of our application.
- Build Client Code: This step will involve the actual development of the client code for our application, implementing the logic and functionality we designed earlier.
- Debug Live: Finally, we'll explore how to debug our application in a live environment, ensuring that it functions correctly and efficiently.
By the end of this presentation, you'll have a comprehensive understanding of the XCM framework and be well-equipped to build your own applications effectively.
Let's get started!
Define the product
Objective: establish a seamless monthly recurring payment of MOVR on the Moonriver parachain.
Notes:
In this demo, our main objective is to establish a seamless monthly recurring payment of MOVR on the Moonriver parachain.
To accomplish this, we will utilize a powerful extrinsic call, automationTime.scheduleXcmpTask, executed remotely on the Turing Network.
This will trigger a payment at the end of each month, ensuring a smooth and automated payment process.
---v
What we need to do
We need to perform one essential operation, which is to remotely execute automationTime.scheduleXcmpTask on the Turing Network.
To execute this operation, we will interact with the following components:
- Source Chain: Moonriver
- Source XCM Version: V3
- Source Extrinsic:
xcmTransactor.transactThroughSigned
Consequently, it will initiate the remote execution of the following call:
- Target Chain: Turing Network
- Target XCM Version: V3
- Target Extrinsic:
automationTime.scheduleXcmpTask
---v
Upon successful XCM execution, a TaskScheduled event will fire on the Turing Network, indicating that the remote call has been executed successfully, thereby creating an automation task.
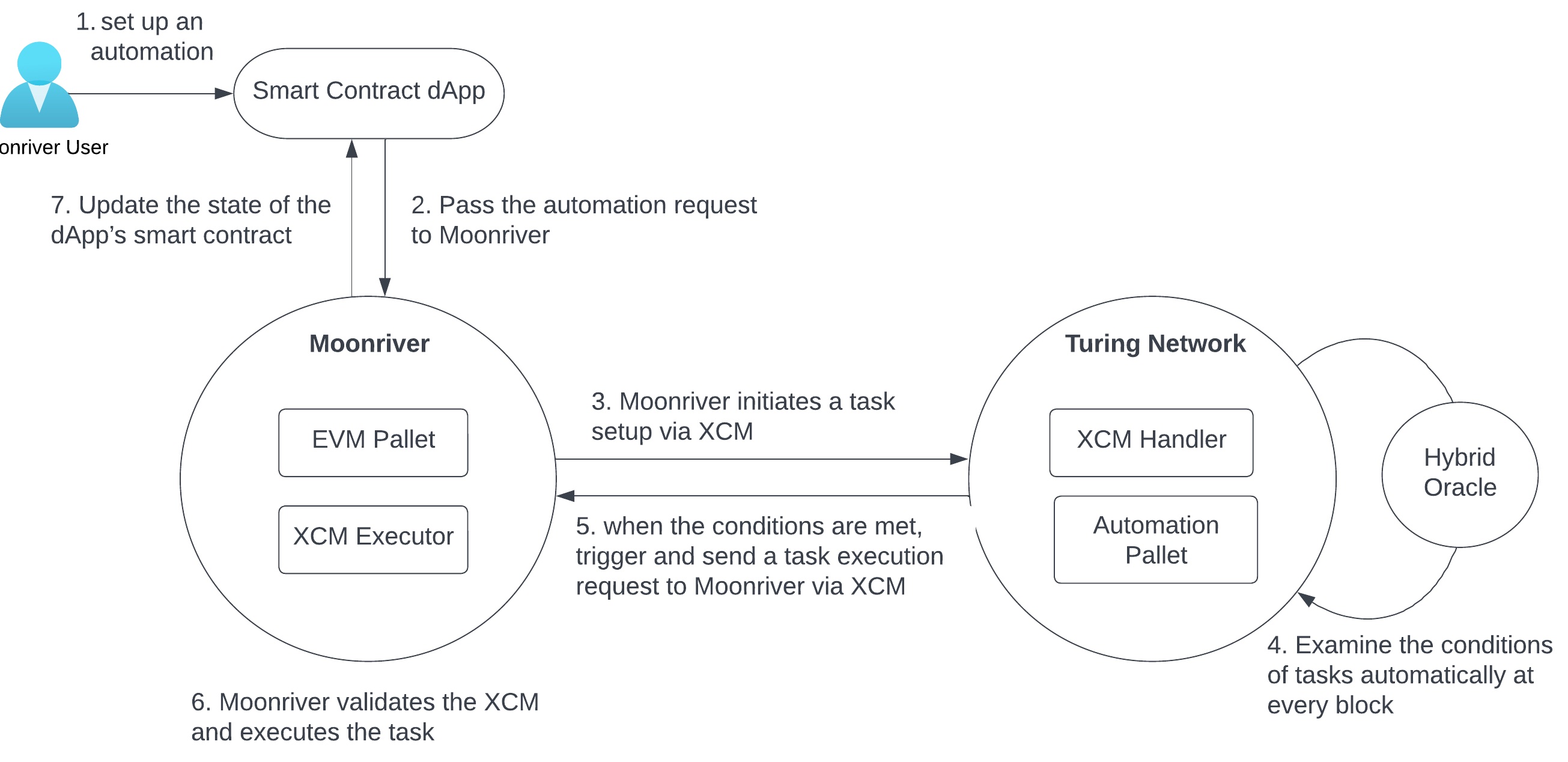
Notes:
explanation - The XCM call sets up a recurring task, that will auto-transfer of MOVR at the end of every month. Turing Network is responsible for triggering the action when its condition is met. The overall flow of the entire product is shown in the diagram below.
Preparation
To kickstart our journey, we will begin by interacting with Moonriver's xcmTransactor pallet, which is similar to Polkadot/Kusama's xcmPallet.
Before diving into the actual XCM message, it is essential to ensure that we meet certain prerequisites:
Notes:
For this demo, we are using the existing xcmPallet built in Polkadot and Kusama. This pallet provides common extrinsic interfaces that developers can use to easily compose an XCM message. Moonriver has further encapsulated the function to make their own xcmTransactor.
---v
- Ensure Barriers on the recipient chain.
In this case, an Allow Barrier**WithComputedOrigin<Everything>, needs to be configured in the XCM config of Turing Network. This Barrier will allow the DescendOrigin instruction in XCM, which will reassign the origination of the transaction on Turing from Moonriver's sovereign account to the user's proxy account. - Configure user’s remote wallet on the recipient chainThe remote wallet, or proxy wallet acts as an account abstraction, allowing the blockchain to execute specific code on behalf of the user.
Notes:
- We covered the Barrier topic in the previous chapter. Barriers are responsible for creating Allow or Deny rules for incoming messages. By adding this Barrier, we allow the DescendOrigin instruction in XCM, which will reassign the origination of the transaction on Turing from Moonriver's sovereign account to the user's proxy account.
- This remote wallet acts as an account abstraction, empowering the blockchain to execute specific code on behalf of the user. By utilizing a user's sub-wallet for a specific extrinsic call, we create granular control, allowing the user's wallet to perform the necessary actions efficiently and securely.
Compose XCM message
In this section, we will initiate the execution by calling the xcmTransactor.transactThroughSigned extrinsic on Moonriver.
Notes:
This extrinsic serves as the gateway to composing the XCM message, incorporating all the necessary instructions for the desired cross-chain message.
---v
XCM configs
The following are the parameters you need to decide before sending an XCM message:
- Version number: Check the XCM version on both recipient (Turing Network) and source (Moonriver) chains. Ensure their XCM versions are compatible.
- Weight: Each chain defines a different weight for XCM instructions, impacting computation, storage, and gas fees.
- Fee per Second: If using an asset other than the recipient chain's native token (TUR) to pay fees, establish the MOVR-to-TUR conversion rate.
Notes:
In section #4 of the Chain Config in XCM document, we have reviewed various chain configurations. In this section, we will illustrate their usage through our demo. Although there are several variables to be decided, once you become familiar with them and establish a few templates, you can continue to use them.
- For example, V3 is backward compatible with V2 but the its config requires safeXcmVersion set.
- The weight of an XCM instruction is defined with a different value on each chain. It specifies how much computational power as well as storage (PoV size), are required for the execution of each instruction and determines the gas, or fee, for the XCM execution.
- In addition to the weight, if we use an asset other than the native token of the recipient chain, TUR in this case, to pay for the fee, the value of the asset must be converted in relation to the recipient chain's native token. The Fee per Second defines the conversion rate between MOVR and TUR, assuming we want to use MOVR to pay for all the fees in this transaction.
With these parameters decided, proceed to construct the instruction sequence for the XCM message.
---v
Message elements
To construct the XCM message, we utilize Moonriver's xcmTransactor.transactThroughSigned extrinsic.
It requires the following parameters:
Destination: It specifies the target chain, or for our case, the Turing Network, identified by {Relay, 2114} on Kusama.
---v
InnerCall
This represents the encoded call hash of the transaction on the destination chain. This value will be passed on to the Transact XCM instruction.
Fees
transactRequiredWeightAtMost restricts the gas fee of the innerCall, preventing excessive fee token costs.
Likewise, overallWeight sets an upper limit on XCM execution, including the Transact hash.
---v
Initiating the XCM Message
---v
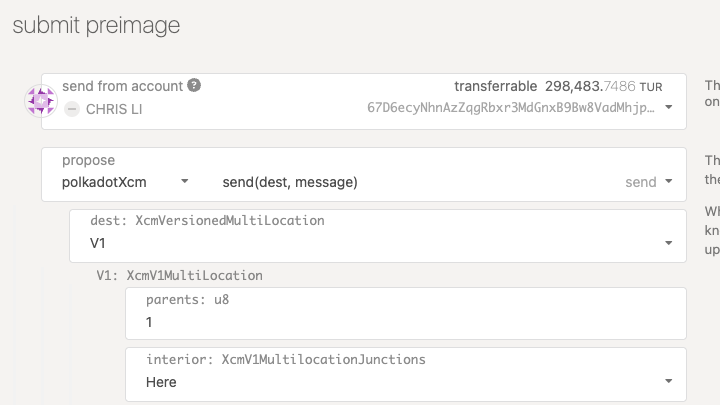
Once all the parameters are set, we can proceed by submitting and signing the transaction. The XCM message can be conveniently triggered directly from the extrinsic tab of polkadot.js apps.
---v
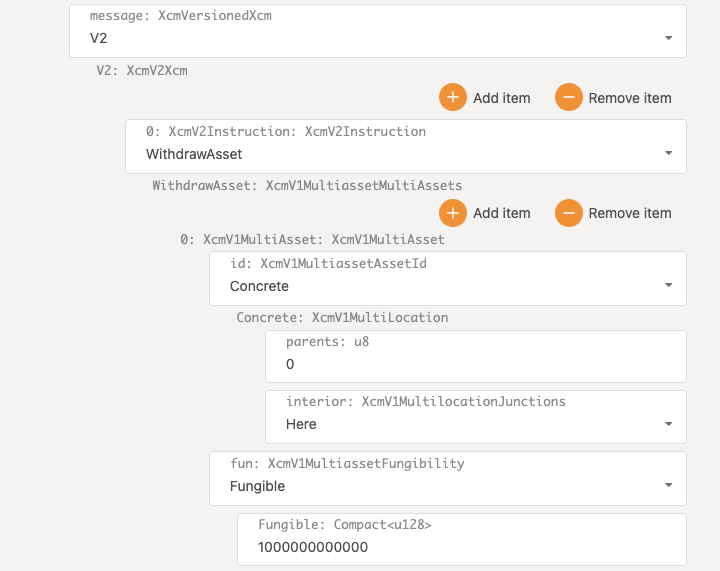
DescendOrigin(descend_location): The first instruction in the XCM array is DescendOrigin, transferring authority to the user's proxy account on the destination chain.
---v
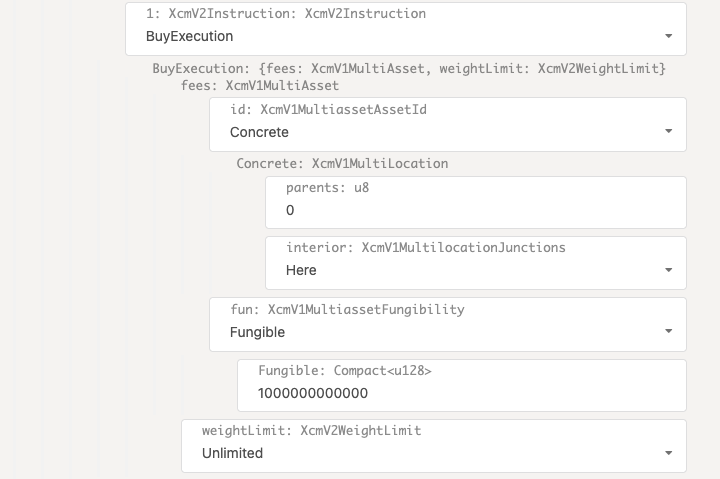
WithdrawAsset and BuyExecution: These two instructions work together to deduct XCM fees from the user's proxy wallet and reserve them for execution.
---v
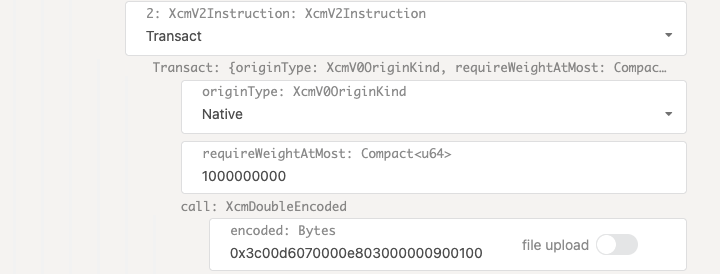
XCM message - Buy Execution ---v
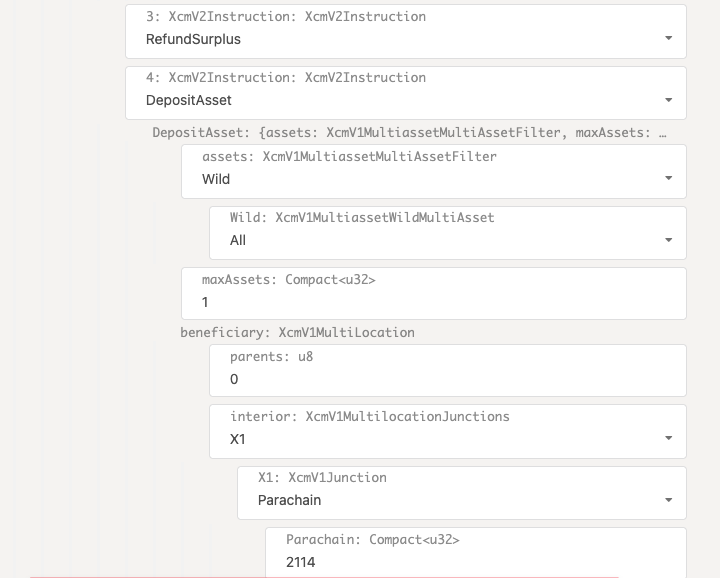
Transact(origin_type, require_weight_at_most, call): The Transact instruction executes the encoded innerCall on the target chain.
We ensured that the gas cost does not exceed the specified limit by setting requireWeightAtMost during the call.
---v
RefundSurplus and DepositAsset: In case there is any remaining fee token after Transact execution, these instructions ensure that they are refunded and transferred to the specified location, typically the user's wallet.
After successfully firing the message, XCM events from both the sender and recipient parachains should appear in the Polkadot.js app Network tab.
---v
Inspection of the message
Once the transaction above is submitted and finalized on the chain, we can use the xcm-tools built by the Moonbeam team to inspect the XCM message. The code and scripts for the tool are listed in this Github repo. An example of the script is shown below:
yarn xcm-decode-para --w wss://wss.api.moonbeam.network --b 1649282 --channel hrmp --p 2000
---v
The output of the script reflects the sequence of instructions we constructed for the XCM message earlier.
DescendOriginWithdrawAssetBuyExecutionTransactRefundSurplusDepositAsset
Client code (node.js)
After proving that the XCM message above executes correctly, we can replicate the procedure from the client of a dApp. Below is a node.js code snippet we created for this particular demo.
To run the program, clone it using git and execute the following command:
PASS_PHRASE=<PASS_PHRASE> PASS_PHRASE_ETH=<PASS_PHRASE_ETH> npm run moonbase-alpha
---v
Example
const tx = parachainHelper.api.tx.xcmTransactor.transactThroughSigned(
{
V3: {
parents: 1,
interior: {
X1: { Parachain: 2114 },
},
},
},
{
currency: {
AsCurrencyId: 'SelfReserve',
},
feeAmount: fungible,
},
encodedTaskViaProxy,
{
transactRequiredWeightAtMost: {
refTime: transactRequiredWeightAtMost,
proofSize: 0,
},
overallWeight: {
refTime: overallWeight,
proofSize: 0,
},
},
);
Notes:
As you can see from the code, there are several preparation steps leading up to the main code block, which constructs the XCM message. With the help of the following code, we can easily dispatch the message repeatedly and test out different input values.
Debugging Live
When working with XCM messages, potential issues can arise in two areas: during message construction and during transaction execution on the target chain.
---v
Message Formatting Issues: If the XCM message is malformed, the recipient chain may not process it correctly. To interpret XCM messages on-chain, we can use the xcm-tool covered in Chapter 5. Some common problems and solutions include:
- Incorrect Fee and Weight Inputs: Ensure that the maximum weight specified in the XCM call is accurate. If the actual weight slightly exceeds the limit, the recipient chain might deny the call. In this case, increase the maximum weight parameter and retry.
- Version Mismatch: A VersionMismatch error occurs when the recipient chain does not accept the Multi-location version specified in Destination or FeeAsset. Check the recipient XCM version and adjust the multi-location version to V2 or V3 accordingly.
---v
Transact Encoded Call Issues: To examine encoded call hash in the Transact instruction, locate the specific transaction on the recipient chain, which will be an event occurring after XcmMessageQueue.success.
Unfortunately, there is no automated tool to directly correlate XcmMessageQueue.success with the event of the encoded call.
However, we can manually analyze it by matching the message hash with the source chain.
Notes:
does anybody have a great tool to correlate the XcmMessageQueue.success with the Transact hash?
Summary
In this section, we explained the backbone of a recurring payment dApp leveraging XCM.
---v
Lesson Recap
To create a successful XCM message between chains, ensure you have the following elements prepared:
-
Type: Identify whether it's VRP (Vertical Relay Process) or HRMP (Horizontal Relay Process), representing the two parties involved in the communication.
-
Goal: Determine the specific extrinsic to call or what actions will be included in the transaction.
-
Details: Adjust the chain configurations as needed. Decide on DescendOrigin, choosing between descending to the user's remote wallet or using a parachain’s sovereign account. Also, specify the Sequence, outlining the instructions to be included in the message.
---v
After preparing these elements, assemble them to form the XCM message and carefully troubleshoot it. Once you establish a reliable template, consider automating the construction process using the polkadot.js JavaScript library.
Alternatively, you can write a wrapper in the parachain's Rust code, such as the commonly used xTokens.transferMultiasset or Moonriver’s xcmTransactor.transactThroughSigned.
Questions
XCM Beyond Asset Transfers
How to use the slides - Full screen (new tab)
XCM Beyond Asset Transfers
Outline
- Pre-requisites
- XCMultisig
- XCM Universal Interface
- General XCM Tips
- Conclusion
- Next Steps
- References
Pre-requisites
The following are expected:
- Knowledge of core XCM concepts
- Knowledge of XCM chain configuration
XCMultisig
InvArch Network has the concept of XCMultisigs, these are entities that exist on the InvArch Network runtime and provide advanced multisig capabilities to users across many other blockchains.
Let's go over how that works!
Notes:
The reason for the name comes from their XCM functionality, more specifically from the idea that these entities have their logic defined in the InvArch Network runtime, but exist in all other connected chains with the same exact account address, thus allowing them to transact in these chains through XCM.
---v
Overview
state InvArch {
direction LR
v0: Multisig ID 0
sxc: Send XCM Call
vacc: 0x123...
state if_state <<choice>>
v0 --> if_state
if_state --> sxc
if_state --> vacc
vacc --> [*]: Transact
sxc --> h0
sxc --> i0
sxc --> b0
}
state HydraDX {
direction LR
h0: Multisig ID 0
hmxs: **XCM Converters**
hacc: 0x123...
h0 --> hmxs
hmxs --> hacc
hacc --> [*]: Transact
}
state Interlay {
direction LR
i0: Multisig ID 0
imxs: **XCM Converters**
iacc: 0x123...
i0 --> imxs
imxs --> iacc
iacc --> [*]: Transact
}
state Bifrost {
direction LR
b0: Multisig ID 0
bmxs: **XCM Converters**
bacc: 0x123...
b0 --> bmxs
bmxs --> bacc
bacc --> [*]: Transact
}
}
---v
Message details
To better understand how this all works, let's go over the messages being sent and their origins.
#![allow(unused)] fn main() { let multisig: MultiLocation = MultiLocation { parents: 1, interior: Junctions::X3( Junction::Parachain(<T as pallet::Config>::ParaId::get()), Junction::PalletInstance(<T as pallet::Config>::INV4PalletIndex::get()), Junction::GeneralIndex(0u128), ), }; let multisig_interior = Junctions::X2( Junction::PalletInstance(<T as pallet::Config>::INV4PalletIndex::get()), Junction::GeneralIndex(0u128), ); let destination = MultiLocation { parents: 1, interior: Junctions::X1( Junction::Parachain(1234) ), }; let fee_asset_location = MultiLocation { parents: 1, interior: Junctions::X2( Junction::Parachain(1234), Junction::GeneralIndex(0), ), }; let fee_multiasset = MultiAsset { id: AssetId::Concrete(fee_asset_location), fun: Fungibility::Fungible(1000000000000), }; let call = vec![...]; let message = Xcm(vec![ Instruction::WithdrawAsset(fee_multiasset.clone().into()), Instruction::BuyExecution { fees: fee_multiasset, weight_limit: WeightLimit::Unlimited, }, Instruction::Transact { origin_kind: OriginKind::Native, require_weight_at_most: 5000000000, call: <DoubleEncoded<_> as From<Vec<u8>>>::from(call), }, Instruction::RefundSurplus, Instruction::DepositAsset { assets: MultiAssetFilter::Wild(WildMultiAsset::All), beneficiary: multisig, }, ]); pallet_xcm::Pallet::<T>::send_xcm(multisig_interior, destination, message)?; // Pallet XCM will then add a DescendOrigin instruction to index 0 of the message. Instruction::DescendOrigin(multisig_interior) // Which mutates the initial Origin MultiLocation { parents: 1, interior: Junctions::X1( Junction::Parachain(<T as pallet::Config>::ParaId::get()), ), } // Becomes MultiLocation { parents: 1, interior: Junctions::X3( Junction::Parachain(<T as pallet::Config>::ParaId::get()), Junction::PalletInstance(<T as pallet::Config>::INV4PalletIndex::get()), Junction::GeneralIndex(0u128), ), } }
---v
XCM Converters
Now that we understand the origin and message structure, let's take a look at those XCM Converters!
para: Parachain 2125
pal: Pallet 51
m: Mulisig ID 0
acc: 0x123...
para --> if
pal --> if
m --> hash
state Checks {
if: Parachain == 2125 && Pallet == 51
if --> [*]: No Match
if --> Hasher: Match
}
state Hasher {
cs: Constant Salt
cs --> hash
}
hash --> acc
Notes:
The reason for the custom hasher is to replicate the account generation in the origin chain. The combination of these checks and the hasher makes up the converters that return AccountIds and native Origins for our MultiLocation.
---v
What happens if we map AccountId origins to the exact accounts within?
Account Impersonation!
Hey Chain B, I'm sending you a balance transfer request from one of my users, their address is "Chain B's treasury" ;)
TRUST!
Notes:
Emphatically explain this!
XCM Universal Interface
XCM can be used as a general API abstraction on top of multiple blockchains. With some clever usage, we can build chains that can be integrated by dApps in a generic manner, and also dApps that easily integrate multiple chains without any custom logic.
---v
Concept
XCM Powered Multichain NFT Marketplace
Imagine an NFT marketplace where not only multiple chains are supported, but also any standards these chains choose to implement!
---v
How?
ui: UI
xcm: XCM API
indexer: Indexer
ui --> xcm
indexer --> ui
xcm --> axti
xcm --> mxti
xcm --> cxti
state Asset_Hub {
axti: XCM AssetExchanger
apu: Pallet Uniques
apn: Pallet NFTs
axti --> apu
axti --> apn
}
state Moonbeam {
mxti: XCM AssetExchanger
mpe: Pallet EVM
mxti --> mpe
}
state Chain_C {
cxti: XCM AssetExchanger
cpu: Pallet Uniques
cpc: Pallet Contracts
cxti --> cpu
cxti --> cpc
}
---v
Matching NFTs
#![allow(unused)] fn main() { MultiAsset { // Where to find the NFT (contract or collection in an NFT pallet) id: AssetId::Concrete ( Multilocation { parents: 0, interior: Junctions::X3( // Parachain ID just so we can pre-check if this message was intended for this chain Junction::Parachain (para_id), // Pallet ID so we know which pallet we should be using to look up the NFT Junction::PalletInstance(pallet_id), // General Index to select a specific collection by integer id // Or GeneralKev to select a specific collection bv it's contract id Junction::GeneralIndex(collection_id) or Junction::GeneralKey(contract_address), ) } ), // The NFT itself fun: Fungibility::NonFungible( // Specific NFT instance inside the collection selected by it's id AssetInstance::Instance(nft_id) ) } }
---v
Implementing AssetExchanger
#![allow(unused)] fn main() { pub trait AssetExchange { /// Handler for exchanging an asset. /// /// - `origin`: The location attempting the exchange; this should generally not matter. /// - `give`: The assets which have been removed from the caller. /// - `want`: The minimum amount of assets which should be given to the caller in case any /// exchange happens. If more assets are provided, then they should generally be of the /// same asset class if at all possible. /// - `maximal`: If `true`, then as much as possible should be exchanged. /// /// `Ok` is returned along with the new set of assets which have been exchanged for `give`. At /// least want must be in the set. Some assets originally in `give` may also be in this set. In /// the case of returning an `Err`, then `give` is returned. fn exchange_asset( origin: Option<&MultiLocation>, give: Assets, want: &MultiAssets, maximal: bool, ) -> Result<Assets, Assets>; } struct MyNftStandardExchanger; impl AssetExchange for MyNftStandardExchanger { fn exchange_asset( origin: Option<&MultiLocation>, give: Assets, want: &MultiAssets, maximal: bool, ) -> Result<Assets, Assets> { match (give, want) { (FUNGIBLE, NONFUNGIBLE) => MyNftPallet::buy(...), (NONFUNGIBLE, FUNGIBLE) => MyNftPallet::sell(...), (NONFUNGIBLE, NONFUNGIBLE) => MyNftPallet::swap(...), (FUNGIBLE, FUNGIBLE) => Err(give), } } } impl xcm_executor::Config for XcmConfig { ... type AssetExchanger = ( MyNftStandardExchanger, EvmNftExchanger, PalletUniquesExchanger ); type AssetTransactor = AssetTransactors; } }
General XCM Tips
In this section we will go over some general tips on how to build with XCM.
---v
MultiLocations & MultiAssets
Deciding how to map MultiLocations to entities in your runtime is very important, as these MultiLocations will end up being used across other XCM-connected chains.
#![allow(unused)] fn main() { // Main runtime token Junctions::X1(Parachain(para_id)); Junctions::X2(Parachain(para_id), GeneralIndex(main_token_id)); Junctions::X2(Parachain(para_id), PalletInstance(balances_pallet_id)); // Other tokens Junctions::X2(Parachain(para_id), GeneralIndex(token_id)); Junctions::X3(Parachain(para_id), PalletInstance(tokens_pallet_id), GeneralIndex(token_id)); // Runtime protocols (i.e. Treasury or it's account) Junctions::X2(Parachain(para_id), PalletInstance(treasury_pallet_id)); // Wasm smart contracts Junctions::X3(Parachain(para_id), PalletInstance(contracts_pallet_id), AccountId32(wasm_contract_account)); // EVM smart contracts Junctions::X3(Parachain(para_id), PalletInstance(evm_pallet_id), AccountKey20(evm_contract_account)); // Wasm or EVM contracts Junctions::X3( Parachain(para_id), PalletInstance(contracts_pallet_id || evm_pallet_id), AccountId32(wasm_contract_account) || AccountKey20(evm_contract_account), ); // NFTs MultiAsset { // Match collection id: Concrete(wasm_or_evm_multilocation || X2(Parachain(para_id), PalletInstance(nft_pallet_id))), // Match item fun: Fungibility::NonFungible(AssetInstance::Index(nft_id)) }; }
---v
Message Instructions
#![allow(unused)] fn main() { // Pay for execution fees and refund surplus Xcm(vec![ // Withdraw asset to use within this message, places the amount in the holding register. Instruction::WithdrawAsset(fee_multiasset.into()), // Pay for execution fees during this message. Instruction::BuyExecution { // The asset and amount we withdrew in the first instruction. fees: fee_multiasset, // Max amount of weight we are willing to buy. weight_limit: WeightLimit::Unlimited, }, // An instruction or set of instructions that will require payment of execution fees. <Instruction that pays execution fee>, // Refund unused purchased weight back to the holding register. Instruction::RefundSurplus, // Deposit assets from the holding register back into the balance of an account. Instruction::DepositAsset { // Match total amount of all assets in the holding register. assets: MultiAssetFilter::Wild(WildMultiAsset::All), // The receiver of the refunded fees, usually the origin that paid for the fees in the first place. beneficiary: account_id_multilocation, }, ]); // XCM assertions // Errors is described pallet does not exist in the runtime. ExpectPallet { // Pallet index. index: 21, // Pallet name. name: "Referenda".as_bytes().to_vec(), // Name of the module. module_name: "pallet_referenda".as_bytes().to_vec(), // Major version of the crate. crate_major: 4, // Minimum minor version acceptable. min_crate_minor: 0, } // Errors if described asset and amount are not present in the holding register. ExpectAsset(MultiAsset { id: AssetId::Concrete(asset_multilocation), fun: Fungibility::Fungible(1_000_000_000_000u128), }) }
Conclusion
During this presentation we went through a couple real world XCM use cases and some general tips for working with the message standard, the goal here is to leave you with some inspiration and some ideas, so that you can start tinkering with XCM to power your own ideas and supercharge blockchain applications!
References
- XCM source code - The source code for the main XCM implementation in the paritytech/polkadot repository.
- XCM Documentation - The official documentation for XCM: Cross-Consensus Messaging.
- InvArch's Pallet Rings - Reference implementation of an XCM abstraction pallet for XCMultisigs.
🕵️ Applied Security
Cybersecurity Overview
How to use the slides - Full screen (new tab)
Cybersecurity Overview
Outline
- Threat landscape
- Risk management
- Development
- Conclusion
- Q&A
Notes:
- Threat landscape
- Key threat actors
- Largest crypto heists
- Crypto incidents
- Risk management
- Inherent & Residual
- Key steps of an attack
- Importance of culture
- Development
- Development and key focus
- CI/CD
- Conclusion
- Q&A
Cyber Threat - 6 Main Actors

Notes:
Different actors with different drivers but commonalities on modus operandi.
Largest Crypto Losses
Some were Ponzi schemes, most were breaches/exploits
Notes:
On the crypto ecosystem there have been number of cyber events! https://medium.com/ngrave/the-history-of-crypto-hacks-top-10-biggest-heists-that-shocked-the-crypto-industry-828a12495e76
More Recent Crypto Incidents

Strong cyber control foundation decrease exposure to incidents.
Notes:
- https://www.forbes.com/sites/ninabambysheva/2022/12/28/over-3-billion-stolen-in-crypto-heists-here-are-the-eight-biggest/?sh=5d411c13699f
- https://www.zdnet.com/article/iota-cryptocurrency-shuts-down-entire-network-after-wallet-hack/
- https://news.bitcoin.com/kucoin-boss-on-strategy-after-hack-we-chose-to-act/
- https://www.halborn.com/blog/post/explained-the-ronin-hack-march-2022
- https://www.bitdefender.com/blog/hotforsecurity/cryptocurrency-monero-website-hacked-original-binaries-replaced/
- https://www.coindesk.com/markets/2020/02/10/new-crypto-exchange-altsbit-says-it-will-close-following-hack/
- https://peckshield.medium.com/akropolis-incident-root-cause-analysis-c11ee59e05d4
- https://www.coindesk.com/markets/2020/12/21/bitgrail-operator-may-have-hacked-own-exchange-to-steal-120m-police-allege/
- https://coinmarketcap.com/academy/article/bitgrail-hack-one-of-the-largest-crypto-hacks-in-history
- https://www.coindesk.com/tech/2020/04/08/hacker-exploits-flaw-in-decentralized-bitcoin-exchange-bisq-to-steal-250k/
- https://www.coindesk.com/policy/2021/02/20/cryptopia-exchange-currently-in-liquidation-gets-hacked-again-report/
- https://bravenewcoin.com/insights/cryptopia-exchange-liquidator-releases-third-report
- https://www.elementus.io/blog-post/cryptopia-hack-transparency
- https://blog.merklescience.com/hacktrack/hack-track-eterbase-cryptocurrency-exchange
- https://www.reuters.com/investigates/special-report/fintech-crypto-binance-dirtymoney/
InfoSec & Cyber Risk - Taxonomy

Notes:
When a threat is leveraging a vulnerability, the consequence is a risk. Usually Threats cannot be influenced, when vulnerabilities can be. Both Threats and Vulnerabilities are evolving over time based on multiple factors, so the importance of deploying controls to identify, prevent, detect and respond & recover against them (NIST)
Taxonomy - Threats Examples
- Cyber Criminal : In the last 12 months, cyber criminal activity +200%
- Insider / Disgruntled employee : lot of evolution on resources
- Hacktivist : Crypto projects and web3 have some detractors
- Terrorist : they are increasingly using cyber as a weapon
- Nation state : Geopolitical evolution with China, North Korean, Russia/Ukraine
- "Government" : There is lot of regulatory scrutiny on crypto area
- Media : Web3 & cryptocurrency evolutions are regularly in the media
- Competitors : Polkadot approach is a game changer
What Is Cyber Risk Management?

What Is Cyber Risk Management?
Inherent And Residual Risk
Having visibility of inherent risk facilitates a common view on area of focus and priorities.
Notes:
-
It is foundational to identify inherent risk. Including in partnership with asset owner. Especially from an impact perspective
-
Controls are key to :
- Reduce likelihood of initial compromise
- Limit the impact of compromise once a foothold has been established
And to enhance ability to detect compromise asap
Starting from the inherent risk is foundational as the threat landscape will evolve including the effectiveness of the control
Attack Kill Chain
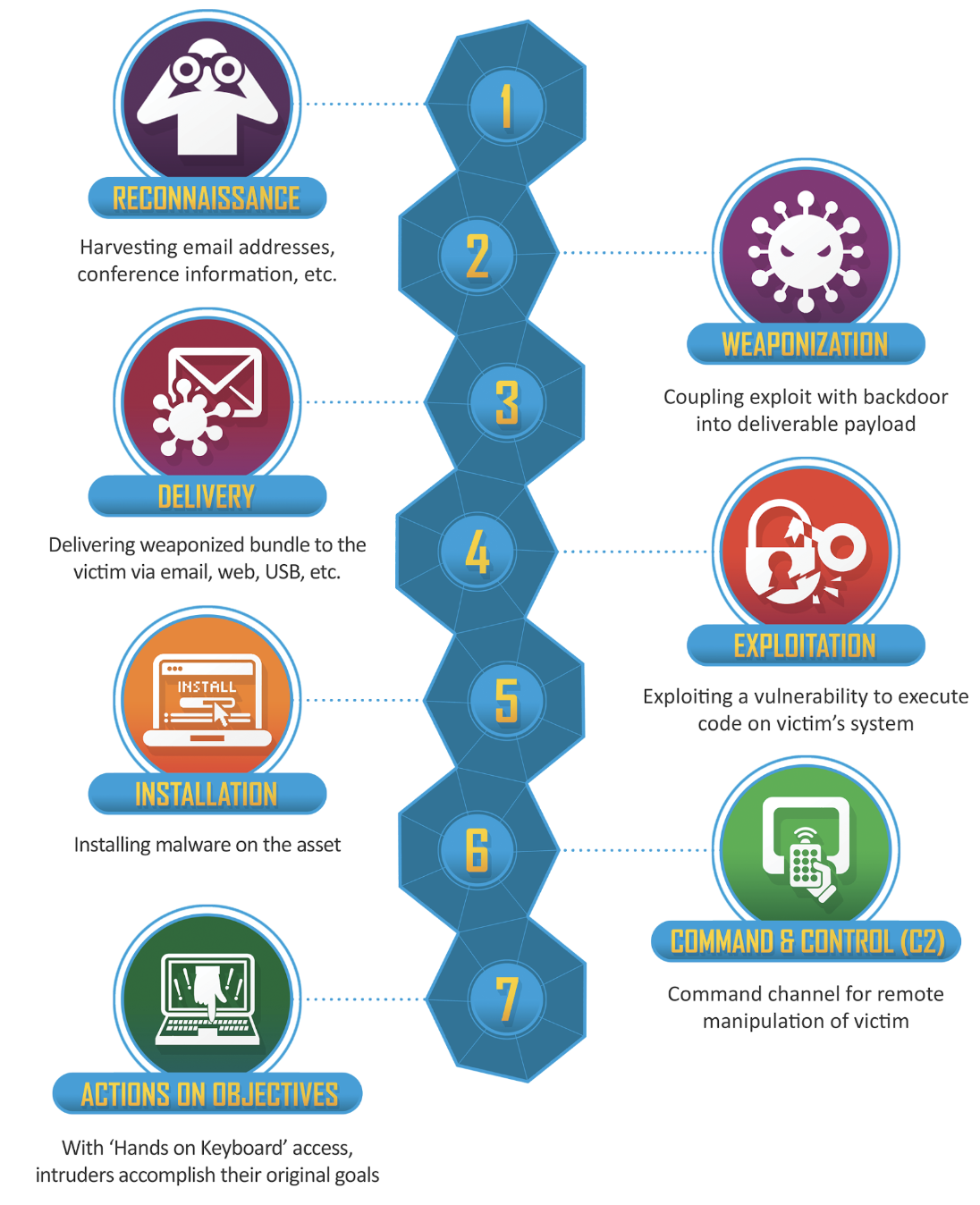
Notes:
Usually an attacker is not attacking directly the target but :
- Collect information leveraging the digital footprint available (linkedin profile, dns records, website, repositories, 3rd parties, anything publicly available)
- Use information available and vulnerabilities to create a “weapon” to prepare an attack
- Deliver the “weapon” via available channels : email (prof./person.), usb, WhatsApp/Signal/Telegram, webpage (legit or squatting), code update, etc
- Use the “weapon” delivered on the victim’s system to execute code
- Get a foothold on the target
- Move laterally smoothly to reach the target objective including staying hidden for a period of time
- Execute final objective : ransom, denial or service, data exfiltration, corruption, fund stealing
Importance Of Culture

InfoSec & Cyber Risk - Embedded
Security embedded and partnering at each steps with key success factors:
- Upfront threat modeling
- Peers code review
- Code scanning
- Independent security code review
- Penetration testing (pentest)
- Secret management
- Supply chain management
- Monitoring
- Playbooks
InfoSec & Cyber Risk - CI/CD
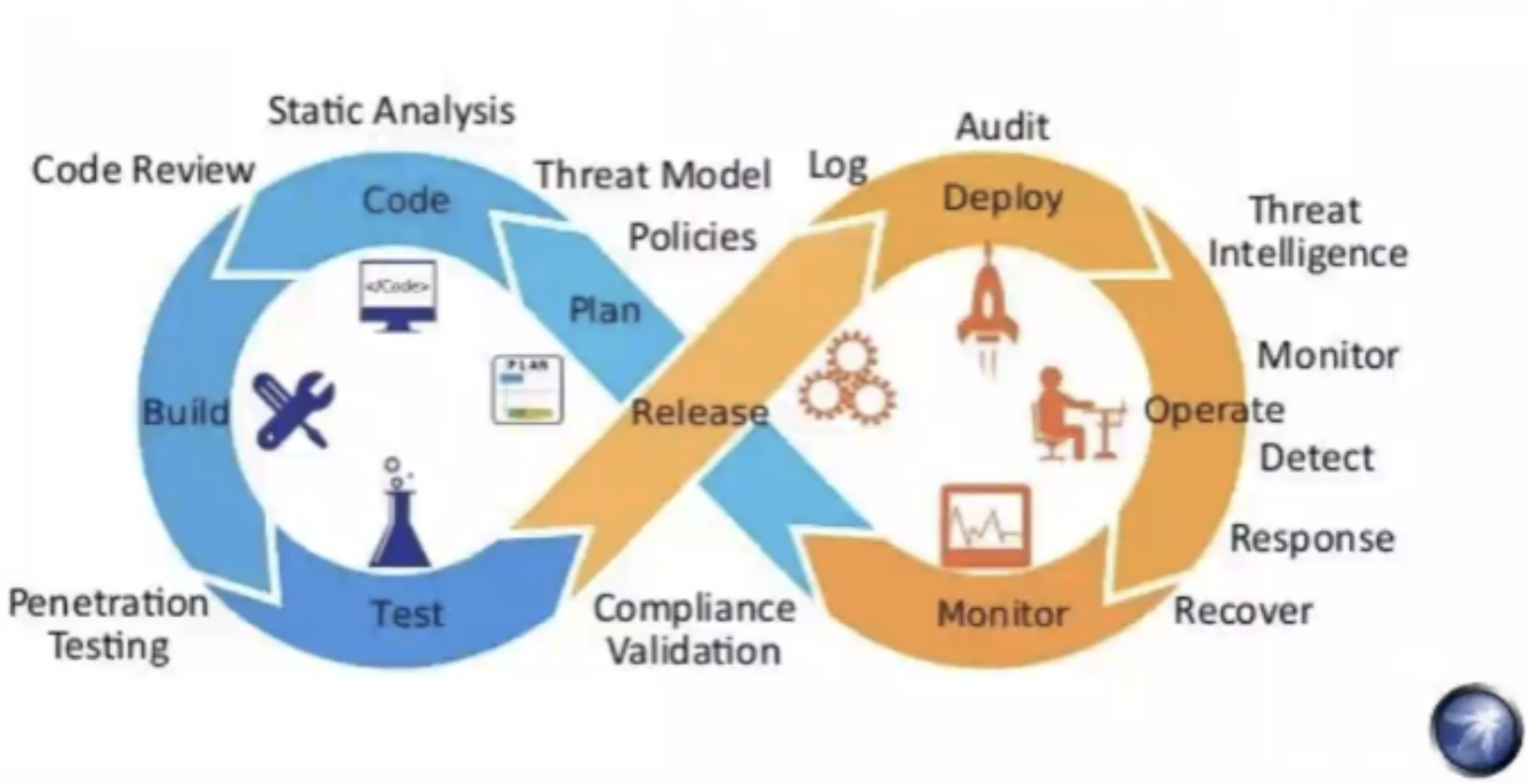
Notes:
This is a continuous process, at each step.
Conclusion

Questions
Next Practical Sessions
- Security Awareness (40/50mn) : Context and adversaries, Attack Surface and Social Engineering
- User Centric Security in Web3 (40/50mn) : Wallet landscape, Key management and User device protection
- Infrastructure Security (40/50mn) : Concentration, deplatforming, supply chain risks, Key management on the nodes and Passwords management for Infrastructure
- Application Security (60mn) : Securing SDLC, Components of AppSec and Known Attack Surfaces & Vectors
Appendix - Streetlight Effect

Awareness
How to use the slides - Full screen (new tab)
Security Awareness in web3
The context, impacts, and mitigations
Lesson Objectives:
- Be able to describe the threats which exist in the web3 space
- Navigate the risks posed with confidence
- Understand the measures taken to minimize impact
The Inevitable Jargon
Time for a quick speedrun
Notes:
Security folks love their jargon and acronyms, you may be familiar with some of these, but no worries if not.
---v
Threat Actor
Any individual, group, or entity that poses a potential risk or threat to the security of a system or organization.
Notes:
Threat actors can be hackers, cybercriminals, social engineers, insiders, state-sponsored groups, or other malicious actors.
---v
Attack Surface
The points of entry, or potential vulnerabilities in a system that could be exploited by a threat actor to compromise or gain unauthorized access.
Notes:
This ranges from network interfaces, APIs, software, hardware and infrastructure, through to human factors.
---v
Attack Vector
Specific paths or methods that threat actors use to launch attacks against a system or organization.
Notes:
These can include various techniques, some of which could be phishing emails, software vulnerabilities, social engineering, malware, or brute-force attacks.
Eyes are on us
- Crypto Market Capitalization: $1,231,359,133,397
- 24 Hour Trading Volume: $39,807,353,848
Notes:
Those are some big numbers, that's $1.23 Trillion. As a result, there are a lot of eyes on the industry as a whole - not just because people are excited about decentralization and web3. These projects carry a lot of influence and responsibility, from maintaining infrastructure through to securing funds.
In the real world
there is no scope
Notes:
In the real world, there is minimal scope - financially motivated attackers do not follow a code of ethics, and will monetize whatever they can get their hands on.
---v
Funds
Quickest and easiest way to make money: attack wallets and services
Notes:
Financially motivated attacks are among the most common, earnings from these can be used to fund more advanced future attacks, for market manipulation, or directly cashed out
---v
Networks & Infrastructure
- Smart Contracts
- Ransomware
- Impact on network availability
- Malicious code injection/node creation
Notes:
Attackers can and will exploit anything, these can be on-chain attacks - such as exploitation of vulnerabilities in smart contracts, or even crafting and sending their own malicious smart contracts
Ransomware and denial of service attacks can be utilized to reduce confidence in or extort funds from projects
Mechanics of protocols themselves can be taken advantage of through 51% attacks, double spends, or malicious validation
---v
Personally Identifiable Information
- Account takeover
- Identity theft
- Impersonation
Notes:
You know you're you, and your teams know you're you - this trust can be taken advantage of by attackers, impersonating people with social capital and good social standing to pivot deeper into organizations and networks - or even something as simple as identity theft to launder money.
It may sound far-fetched, but this is a very real problem in the web3 ecosystem - so if a request seems a bit bizarre, it's never a bad idea to check in and verify via an alternative line of communication which has already been established.
A look at potential adversaries
- Lazarus Group (APT 38)
- Sanctioned Nation States
- Future Adversaries
Notes:
So now we know some of the ways that threat actors can strike, let's take a moment to look at who and why. As mentioned before, a lot of attacks in the web3 ecosystem are financially motivated - especially for nation states which are experiencing financial sanctions due to whatever geopolitical antics they are involved in. While that's true, we can't rule out politically motivated attacks.
- Lazarus Group
- $400m in 2021
- $1.7b in 2022
- Russia
- US in future
- More advanced & persistent
- Resources
- Driven
Up to date devices are great
but there's more to it than that
Types of Adversaries
A Deeper Dive
---v
Opportunists
Individuals or small groups who take advantage of easily exploitable vulnerabilities without significant planning, often targeting low-hanging fruit and utilizing readily available tools and techniques.
Notes:
Opportunists can impact us from phishing through to being in the wrong place at the wrong time. Keep your guard up when in transit or a public place, all it takes is a momentary lapse in focus for a device to be stolen.
---v
I Pickpocketed a Pickpocket

Notes:
Source: I Pickpocketed a Pickpocket
---v
Organized Crime Groups (OCGs)
More sophisticated adversaries with dedicated resources and a more defined focus. They operate like traditional criminal organizations and often engage in large-scale, financially motivated attacks.
Notes:
OCGs will have more information than a mere opportunist, with more time spent assessing their targets - vulnerabilities affecting the cyber realm, but even social media, gaining a better understanding - for example: knowledge of frequent travel locations, offices, events, etc. This knowledge can be used to carry out more advanced phishing campaigns, also known as spearphishing - but more on that later.
These details can be used for extortion, be it compromising information or physical threats, through to kidnap for those higher value targets.
---v
Nation States
The most sophisticated and well-resourced adversaries in the landscape. They have significant technical capabilities and may engage in cyber-espionage sabotage, or warfare.
Notes:
Nation states can act similarly to OCGs, but with increased skill and greater financial backing, with the added benefit of additional operating locations: think airports, border crossings, police forces.
In the context of web3, nation states may be interested in:
- Money
- Service Disruption
- Undermining Integrity
Methods of Adversaries
---v
Theft
- Laptops
- Phones
- Keys
- Auld Wallets
- ID Documents
- Hardware Wallets
Notes:
A lot is at stake, even when an opportunist strikes - for most people our entire lives are on our devices these days. Losing a device can mean lost, and potentially compromised, second factor authentication - locking you out, but letting a crook in, but also the potential exposure of your wallet seeds, along with whatever is signed in.
Lost or stolen keys and ID documents pose an increased physical threat: the leak of your home address and the means to access it, which can also extend to workplaces or infrastructure locations
---v
Tampering
Notes:
Computers are small but powerful - think about the size of the Apollo flight computer, while nowadays we have a computer with much greater processing power in our pockets, but the progress hasn't stopped - there are powerful SoCs, Systems on a Chip, which can be utilized by attackers.
They range from devices, such as the Rubber Ducky, through to a simple USB-USB cable which looks innocuous enough, but can wreak havoc - and even exfiltrate data or allow for remote control.
These can put your devices - be it phone, laptop, or hardware wallet - at risk of malware injection or firmware integrity
---v
Tampering: Mitigations

Notes:
So what can we do to mitigate these attacks? For a start use our own, trusted, cables - consider identifying them in a distinctive way: that could be wrapping some tape around the end, breaking out the ol' sharpie (other permanent markers are available), or applying a coat of nail polish.
Don't use that charger you found randomly left in a café, even if it was offered to you by a nice businessman, and it's probably best to not pick up that mysterious USB on the side of the road anyway.
---v
Hacking
- Direct attacks
- DNS poisoning
- Targeted Man in the Middle attacks
Notes:
If you're on a network that isn't your own or trusted (home, hotspot, place of work), pop on your VPN for additional protection and privacy.
---v
Social Engineering
Phishing and its counterparts, vishing, smishing, etc.
Notes:
Phishing and attacks under its umbrella are still a very real threat, but often downplayed - but more on them later.
Situational Awareness
---v
Shoulder Surfing
Notes:
Privacy screens are a mitigation, but they're not infallible - they reduce the viewing angle, but those behind you still have the best seats in the house.
---v
Shoulder Surfing

Notes:
Besides, we know that Mr Tom Cruise runs at a 22° angle, rendering privacy screens useless.
---v
Shoulder Surfing

Notes:
It's unrealistic that you can wear shoulder pads all the time to block the view of your sweet sweet screen real estate.
---v
Shoulder Surfing

Notes:
Nor are you going to be able to rapidly grow out your hair
---v
Shoulder Surfing

Notes:
In Feng Shui, having a solid wall behind you is considered favorable, especially when sitting at a desk. A solid wall represents support, stability, and protection.
There's truth to this, it also adds privacy - so if you happen to be working in a public place, consider the flow of energy and listen to Feng Shui - find a nice wall to sit against.
Visual Cues
Notes:
It’s no secret that folks in tech love their stickers, they make our devices unique versus our friends and colleagues - but this also comes with downsides. There’s a tipping point between a casual interest and direct involvement: stickers can act like a fingerprint, but what kind of information can we glean from them?
---v
Device Stickers
Some things can be identified from these, such as:
- Role
- Industry
- Employer/Projects
Notes:
- Role
- Developers: Framework/Language/Software stickers
- DevOps: Cloud service/provider stickers
- Security: Security tools and software
- Employer
- Lots of brand-specific stickers can indicate affiliation to an organization or project
Cover in transit - benefit of protected device
---v
Clothing, Swag, Drip
Call it what you will, but it can be a source of information disclosure
Notes:
Donning the latest swag is turning yourself into a billboard
- Advertising the project mentioned
- Advertising potential affiliations
- Advertising why you would make a financially sound target
The last point applies to tattoos too, unless it's a Dogecoin tattoo.
Digital Footprint
---v
Social Media
The Usual Suspects
- Meta
The Less Obvious
- Telegram
- Discord
Notes:
Data can be inferred through social media, listing your position on LinkedIn gives attackers confirmation of your presence, the format of email addresses is likely easily discoverable, opening the door to spearphishing attacks.
Messaging apps are rapidly becoming social media, remember that posts and stories aren't necessarily private and can be viewed by anyone with your number. We can mitigate the impact of these by ensuring device separation - which is also great for work-life balance, which is a great opportunity to revisit phishing.
Phishing
Humans get distracted, stressed, and tired, this is when phishers thrive.
If it didn't work, they would have stopped by now.
Notes:
Phishing is still highly effective, at the end of the day we're only human. The cost of phishing is constantly dropping, making it easier for the masses to be reached Actions and decisions are circumstantial
---v
Rise of AI
Phishing is easier than ever, just ask ChatGPT:
Notes:
Not only is phishing getting cheaper, the bar to entry has been significantly lowered. Existing trusted email infrastructure and its exploitation leads to more and more convincing attacks, paired with the rise of services like ChatGPT, the risk is increasing.
---v
Beyond the Nigerian prince
Phishers are getting smarter, and your digital footprint is on their radar.
Notes:
Posting online comes with its share of danger, broadcasting your location to the world. Think again before you post, could an adversary use this information to target you, your family, or colleagues - is it advertising that your team is all in one place, or perhaps alerting them to the fact that your team is distracted and probably stressed with travel?
There is also the issue of consent - avoid blindly tagging people and tainting their operational security, ask first - it's also just a nice thing to do, rather than making bold assumptions about what they are on board with.
Not to say don't post, but add a delay to obscure your live location and minimize physical risks
---v
Reacting to a Phish
- Stop
- Take a moment
- Verify
- Report
Notes:
So why is phishing suddenly important? It's not, it's always been important - but downplayed. We're in a rapidly evolving space, which comes with a lot of eyes - for better or for worse.
It's always preferred to be interrupted for a second opinion on a potential phishing attempt than an unfolding incident, it'll even put a big smile on the faces of security folks all over. After all, we're there to help, rather than preach from our ivory towers and reprimand those who make mistakes.
Questions
User Centric
How to use the slides - Full screen (new tab)
User Centric Security in Web3
Notes:
In this session we will cover the basic of wallet (private and public pairs of keys), key management (how to protect your public-private keys), how to protect the endpoint you are using to manage your keys, and some tips, tricks and security best practices and logics.
In the end, we will give you some advice in case you are compromised.
The objective of the session is to provide a set of guidelines and mental models to questions the operational security of your keys. Some of you might find these advices basic, while others will find it useful. Some of the ideas are just abstractions of more complex technical concepts, as we would like to approach it in a high level educational piece. But also give the opportunity to dig into the rabbit holes for those who may want to follow Alice in that direction.
Goal for today:
- Understand the different types of wallets - and the risks associated with them
- Get the basic foundation to be able to outline a strategy to protect your private keys
- Be familiar with the best practices to protect your computer and digital tools
Security is a process, not a product.
Bruce Scheiner (Click here to kill everybody, 2019)
Notes:
Security is not something that is set in stone, it some that is in changing from - it is framework/it is mental model that helps you to tackle the specific problem of protecting your assets. Security is something that is different for everyone, for every moment or use cases.
Threats or what we need to be worried about
- Vulnerabilities on laptops/phones
- Network vulnerabilities
- Poor Operational Security
Notes:
What is a threat? It is a potential danger that can trespass security and put your assets are risks. The threats are the events/things/personas in the horizon we need to have an eye on them.
Different security context - have a different security threats. Edward Snowden faces different security threats (changing geopolitical situations, nation state actors, ...) than a regular random internet user (script kidding phishing attempt, port scanning, non targeted malware, ...).
Vulnerably on Laptop - What not to do

Vulnerability on Network - What not to do

Poor Operational Security - What not to do

Risk
... What is risk?
Notes:
What is a risk?
According to Oxford English Dictionary is the possibility of loss, injury, or other adverse or welcome circumstance; a chance or situation of situation of something bad happening. But that is what bad means in security terms?
Let's visit the C I A triad
Confidentiality - keep information private.Availability - have information accessible when you need it.Integrity - keep information as you have note it down when you stored it.
Notes:
We will see this many times!
Risks: what can go wrong
- Keys compromised - Loss of confidentiality
- Keys lost - Loss of availability/integrity
Notes:
In this case, which risks (things that can go wrong) we need to be aware? That someone else has access to our keys? Then they are compromised. Or that we cannot access back our keys because we cannot access them or they are noted/stored wrongly. By our fault or others fault.
But - what are these keys?
Keys compromised - Bad risk management

Keys lost - Bad risk management
What are the private-public keys ?
(in web3 context)
Notes:
Simplifying, Private keys are a type of digital signature that allow you to prove ownership of your tokens on a blockchain network. The public key is used to receive tokens (this is the “address” where tokens are received).
These pairs of keys are generated by a cryptographic process, generating a public and private key. This key pair has a very particular relationship, the public key can be derived from the private key, but not the other way around (asymmetric encryption). In mathematical lingo it is called a one-way function, as it only works in one direction. Also, another property, using the public key you can verify that a message or a signature has been created by the associated private key without disclosing the private key itself. The public key is meant to be shared, the private key is meant to be kept, as its name states, private.
And the seeds?
The seed is a list of random words that is generated when you create a new “wallet” (a pair of cryptographic keys).
With the seed, you can generate a private and public key. This could mean a seed phrase is the mnemonic human readable version of a private key.
It is easier to note down this
"caution juice atom organ advance problem want pledge someone senior holiday very
than the following private key.
0x056a6a4e203766ffbea3146967ef25e9daf677b14dc6f6ed8919b1983c9bebbc
Key management
A key is protected by
- Strong math, overall length, ...
- Handling of the key (key management) by humans or machines
Notes:
We have determined that this keys are important for the user to operate on the blockchain. But how secure they are? They are protected by strong math (the encryption algorithms that they confer their particular asymmetric properties). They are long, so any adversary will need to take longer to(if) calculate the original private key with a longer key than when a shorter key (is just a cases of attempts, cpu speed and probabilistic). And the most important - and most of the time the weakest: how we handle these keys.
Key management risks - again
- Loss of confidentiality - your key is leaked or compromised.
i.e: someone else has access to the wallet. - Loss of availability - you cannot access your key anymore.
i.e: you don't know where you noted. - Loss of integrity - your key is wrong.
i.e: you noted the key incorrectly.
Notes:
When handling the keys, what we need are the 3 key points we mentioned earlier. The private key stays in secret (don't leaked in their internet, don't be part of a screenshot uploaded to a cloud service, ...). That they key is available - you can access to it when you need it - the hard disk where you have it noted is wrong, And that the key you stored is correct: That you noted it well, in these cases a "3 cannot be an 8, a 4 cannot be a 9", or we cannot forget to select the last character when copy and paste.
Keys overly simplified
Cryptocurrency user definitions
-
The public key is used to receive tokens (public)
-
The private key is used to sign transactions (private)
-
The seed is used to calculate the private key (private)
Multisig accounts

- One or more keys and a threshold
- The threshold defines how many signatories
must sign for a sig check t be valid.
Notes:
These pub keys (addresses) can be distributed among different individuals - even in different locations - so a transaction is only validated when the minimum required of signatures are achieved. This way the individuals-parties need to agree on signing a particular transactional. This is a common way to protect corporate funds or big amount of tokens - and not to rely in one individual or single point of failure.
Another method - for protecting individual funds, is that one individual is keeping different wallets of a multisig account. This way, if one of the wallets is exposed, compromise or lost. The individual can still operate with this wallet (and most recommended, migrate the tokens to another multi-sig wallet where they have control over all the addresses).
What is a wallet

A wallet holds a pair of cryptographic keys (public and private).
Notes:
A wallet is a software application that stores your private keys and allows you to receive tokens through a public key. As the wallet contains the keys in order to operate with the tokens, a keychain could be a better metaphor.
Wallets
Hot n Cold

Notes:
We have been talking about keys, and in the blockspace there is a great differentiation between to what are your keys exposed. Hot/Cold is a metaphor of the amount of risk we want to expose our private keys.
Hot wallets
- Heavy clients - full nodes (deprecated use as wallet)
- Light clients
Notes:
Heavy client -
Light client - A light client or light node is a piece of software that connects to full nodes to interact with the blockchain. Unlike their full node counterparts, light nodes don’t need to run 24/7 or read and write a lot of information on the blockchain. In fact, light clients do not interact directly with the blockchain; they instead use full nodes as intermediaries. This is the todays standard for hot wallets.
Internet connection = bigger risk

The listening post (2005) - Exhibited in the British Museum
Cold wallets
- Full node offline (old school)
- Paper wallet (beware fo the change address!)
- (Hybrid?) Hardware wallet
- Offline seed backup
- EXTRA BALL: Polkadot Vault
Notes:
On the other hand, the cold wallets are not connected to the internet, they are air-gapped from the network, substantially reducing all risks that might come from there. These wallet concepts are more suitable for long term storage, or wallets that don't need constant operation.
Heavy client offline - is a the full implementation of a node. It is possible to use a "full" node in order to create a priv/public key pair. The client is disconnected from the internet - not even synced with the chain -, but is able to receive transactions. In order to operate with received tokens, we just need to connect the node to the net, and allow it syncing. Due to progressive weight (in Gigabytes) of the chains, this method is deprecated.
Paper Wallet - A paper wallet is a paper document that contains your seed or private key and the public key. It would need to be accessed and copied to compromise your private keys, but at the same time the paper needs to be properly stored and/or backed up. As being a totally analog format, they are immune to digital attacks but subject to events on the physical world.
Depending on the chain there are some offline tools that allows you generate derived private or public keys while being offline.
Ideally they are printed using an offline (ideally a dedicated clean air-gapped computer for this purpose) and local printer.
A paper wallet cannot be used to transfer fund from the same address various times, it generates a change address that might not be in possession of the sender. It is possible to set the outputs of the transaction, but technical knowledge is required for this configuration.
Hardware wallets - There are several commercial projects that offer a reasonable level of protection when protecting your tokens. These are - usually - hardware devices that allow you to create a seed - for the whole device, and the rest of private keys (usually kept in the device) and public keys (to receive tokens).
In most of the systems, the device includes some other manual controls that need to be physically manipulated in order to, for example, validate a transaction. The need to the physical interaction for this restricts the operation of the hardware wallet - as the rules of the objects of the physical world, to a certain place in a certain time.
Polkadot Vault
Polkadot Vault is a software app that transforms an Android or iOS device in an air-gapped hardware wallet.
Notes:
The signing of the transactions is made by a series of QR communications between computer and the Vault Device. The wallet is not connected to the net or even to the device which is interacting with the blockchain.
Some hardware wallets are completely air-gapped - like Vault, software installed in a android or iOS device in Airplane mode -
Other hardware wallets require connection between the computer/phone and the hardware wallet. This connection can be via a cabled connection (recommended) or wireless connection (not recommended, as we would like not to radiate - even in an encrypted form - anything related to these blockchain operations).
Sharding (or divide and not be conquered)
Sharding is a technique to divide your secret in different parts, so an adversary could not have access to the full secret in case one of the pieces is compromised.
Notes:
Traditional methods for encryption are ill-suited for simultaneously achieving high levels of confidentiality and reliability. This is because when storing the encryption key, one must choose between keeping a single copy of the key in one location for maximum secrecy, or keeping multiple copies of the key in different locations for greater reliability. Increasing reliability of the key by storing multiple copies lowers confidentiality by creating additional attack vectors; there are more opportunities for a copy to fall into the wrong hands.
Sharding challenges:
- Recovery
- Fault tolerance - storage/persons
- Still secret?
Notes:
How to divide the secret in a way that is recoverable correctly, how to make it fault tolerant (as now they are many pieces to take care of, do we need to protect them all to ensure recovery, can I trust all people to keep their part secret all time?), how to make sure that with one of the pieces of the secret, the rest cannot be inferred.
Secret Sharing Technique
Is a method to distribute a secret in different parts/persons, in a way that no part holds any intelligible information about the secret. But the secret can be reconstructed with a minimum number of shares.
And remember: These secrets are managed by humans - that are driven by motivations. And motivations change.
Requisites for successful secret sharing
- Information should stay secure
- Flexible (n of m pieces required)
- Recoverable
Notes:
We need a technology that will allow us, when we divide our secret:
- That the secret stays confidential, and the different individual shards cannot be used to infer the original secret.
- That the recovery is flexible, meaning that we would need only n of m pieces of the secret to recover it. This can be because the secrets are no longer available (are lost), or because we cannot trust the persons we gave the secret piece anymore.
- That the secret is recoverable with no glitches/errors: Integrity.
How we can achieve this?
Using strong Math
Shamir Secret Sharing - Banana Split
Shamir Secret Sharing is an efficient Secret Sharing algorithm for distributing private information.
The secret is mathematically divided into parts (the "shares") from which the secret can be reassembled only when a sufficient number of shares are combined.
There are different implementation of it: we will take a look to Banana Split
Notes:
SSS is used to secure a secret in a distributed form, most often to secure encryption keys. The secret is split into multiple shares, which individually do not give any information about the secret.
To reconstruct a secret secured by SSS, a number of shares is needed, called the threshold. No information about the secret can be gained from any number of shares below the threshold (a property called perfect secrecy).
It was invented in the late 70's by the Israeli cryptographer. He is the S on the RSA algorithm (Rivest-Shamir-Adleman)
Banana Split - bs.parity.io
- Offline HTML file used to generate and recover secrets
- To be used in air-gapped computers and local printers
- Uses QR codes to store information and cameras to retrieve
- It is flexible allowing n:m type of shared secret creation
Key protection Operational Security Logics
- Security is contextual
- Define your risk appetite
- Backups not only of information also for processes.
Do not rely on single point of failure. - Don't put all your eggs in the same basket
Some mental exercises (1)
What is the operational model to a wallet that is transferring funds to third parties every day?
Some mental exercises (2)
How to protect a personal wallet with 10 million tokens?
Some mental exercises (3)
How to protect an corporate wallet with 100 million tokens?
Some mental exercises (4)
sHow to ensure
CIAof a wallet, in a future when we would not be around?
Last but not least - Basic laptop/phone hygiene
- Software up-to-date
- Use of different profiles or even different computers
- Avoid malicious environments (links containing malware)
- Double-triple check the software we download for the internet
- Second factor of authentication where possible - physical key preferred
Never Assume - Practice a legitimate distrust.
-
Many actors or institutions have different objectives of the one you have.
-
Software have bugs and errors. They are made by people like you and me,
which needs to eat and go to sleep. -
No technology is agnostic. This includes they technology we communicate with,
we work with or the one we use to keep us entertained. -
Sometimes we are our worst adversary.
Be diligent. 🖖
Questions
Infrastructure Security
How to use the slides - Full screen (new tab)
Web3 Infrastructure Security
Notes:
I'm going to speak about how securely deploy your web3 infrastructure. But, instead of talking about very common information topics like best practices, strong authentication and others well discussed like firewalling, I’m going to talk about some often overlooked problems that significantly affects web3 infrastructure protection and about how they should be handled.
But if you want to ask me about firewalling, welcome to the Q&A section!
Overview
- Concentration and deplatforming risks
- Digging into the Solana case (end of 2022)
- Selection of providers
- Mitigation of the risks
- Supply chain attacks
- Where it can happen and how to prevent
- Two uncommon attacks against infrastructure
- Tips about key and password management
Deplatforming risk
- Deplatforming happens when some resource is removed from service by a provider.
- Web3 is supposed to be decentralized, but it may rely on the centralized infrastructure behind it, with some legal and technical rules. Therefore, this risk should not be overlooked.
Notes:
The first overlooked risk is the deplatforming risk. Deplatforming is, briefly speaking, when someone or something, suddenly goes offline without a wish to do it. It can happen on any layer of the technological stack, with everyone/everything, with proper legal ground or not. Today web3 and cryptoassets are receiving a lot of attention from different regulators. If some platform decides that your web3 stuff is unwanted, they can just suspend the accounts and delete the data. From this perspective, web3 infrastructure, which is running on top of centralized infrastructure, is still unfortunately partly centralized.
Solana case (Nov. 22)

Web source: 1000 solana validators go offline by TheBlock
Notes:
At the beginning of November 2022, the nodes of Solana in Hetzner, were removed at one moment. A big pain for the node operators, a major reputational risk for the network. Solana tokens became cheaper the next few days (to be honest, I can’t say that there is a straight connection between the event and the token price, but anyway).
Solana case. Going deeper
What’s Hetzner in a nutshell? Why did many people go to it?
- A German Hosting Provider
- Gives people extremely cheap bare metal servers
- Price per CPU/RAM is very low
- True power of raw non-virtualized hardware
- Control over the CPU/RAM for people who want to control the environment.
Notes:
Sounds good, isn’t it? But, Germany has high electricity prices, human work is expensive, and the hosting is still so cheap, why?
Solana case. Going deeper
Why is Hetzner so cheap?
- Mostly consumer-level hardware, not “robust enterprise servers” in terms of Service Level Agreement. It can be seen if you see the available configurations.
- Covert expectations of low resource load from the customers
Notes:
The first is almost clear. Now lets explain what the second means.
ToS/ToU/EULA that people don’t read
A small cool story first

Notes:
There is a small joke, which is actually not a joke, about the fact that people just skip over the reading of license agreements. Some company offered a prize for reading ToS till the end, by placing an easter egg in the text of ToS.
Hetzner strikes back
Notes:
Literally Hetzner said: we don’t care about your consensus (PoW vs PoS), we just call everything “mining”, please remove your software or we do it by ourselves.
But… Why and how?
Q: Why do providers act against blockchain, and how do they detect it?
- A1: Business model: covert expectations of low resource load from the customers:
- Nominal link speed is probably not fully guaranteed, but shared.
- Crypto databases tear the ordinary disks. They die 10x faster.
- The nodes are attacked 24x7. Headache for network engineers.
- Server consumes not “average” power, but more close to the limit.
- A2: More direct reasons: regulations/sanctions/other paper blockers.
Notes:
In short, the hardware resources are shared where possible, the hardware is low-level, and the business model is similar to insurance companies or banks from a far perspective. If all of the users demand their resources at one time, the company just doesn’t have them available.
How do ISPs detect blockchain?
- Q: And why a Blockchain node wasn't banned immediately?
- A: It has not been detected on time, probably. Or the size of a particular setup is not worth the deplatforming efforts.
Let’s talk about the detection.
How do ISPs detect blockchain?
Joke: how does a provider see your node:

Notes:
It is a joke of course, but how the provider engineer can see your web3 server.
How do ISPs detect blockchain?
- Known “bad” DNS names resolution and contact with specific IP addresses
- Memory (RAM) Scanning for virtual machines:
- Example, Google Cloud case for their VMs.
Notes:
In short, it is very hard to hide the node. Tricks like VPN, obfuscation give a lot of performance penalty.
Okay, and how to mitigate that?
Moving to platform independency:
- Decomposition of the solution layers from the beginning is the best friend (opposite to the classical monolithic configuration, which is target-dependent)
- Modern DevOps and CI/CD
- Partial “landing” of the infrastructure from the clouds
- Client-side only websites (no backend)
Notes:
It is impossible to mitigate this risk in full.
Deplatforming risk mitigation
Idea #1. Decomposition of the solution
Notes:
Instead of having all-in-one solution (example: manually go to the server and compile/configure from scratch, or use a specific toolkit for a single provider like AWS), we can have the following independent components, even for a couple of servers.
- Build services - produce clean, ready to use, tested images (containers, virtual machines). Key target: readiness (achievable by regular testing).
- Provider-agnostic provisioning of the infrastructure - makes a “landscape” to fill it with the services. Key target: minimal dependencies from a particular vendor.
- Automatic server configuration and delivery of the services: Key target: no manual intervention, clear feedback about actions.
- Monitoring. It gives the health metrics/feedback in the long run.
It is not a full set of blocks, but the major parts.
Modern DevOps and CI/CD
Idea #2. One of the solutions - IaC:
- Infrastructure as a code (IaC) approach. Clear, declarative, history trackable configuration storage
- IaC can utilize regular CI/CD processes to control provision and configuration for servers.
- Separation of provision (example - Terraform) and configuration (example - Ansible) makes the solution close to be provider-agnostic.
- Only really unique data is backup-ed or synchronized - quick move & restore procedures.
Partial “landing” of the external dependencies
Idea #3. Working with dependencies.
- Instead of having just one ecosystem, be adaptive to another one. Example: Github <-> Gitlab (caveat: up to 100% of additional work).
- Use configuration bastion approach (example: your own Gitlab server).
- Have multiple service image registries and other storages
- Fork 3rd party local source code to your repos (to prevent abandoning of dependencies and supply chain attacks caused by abandoning).
- Use centralized facilities? Typical: a single RPC server? Run your own or use light clients.
Deplatforming risk mitigation
Final objective: to find a proper balance between duplication of efforts and the time to recover if a resource disappears.
Concentration risk
One picture that says everything (on Polkadot - the whole ecosystem):
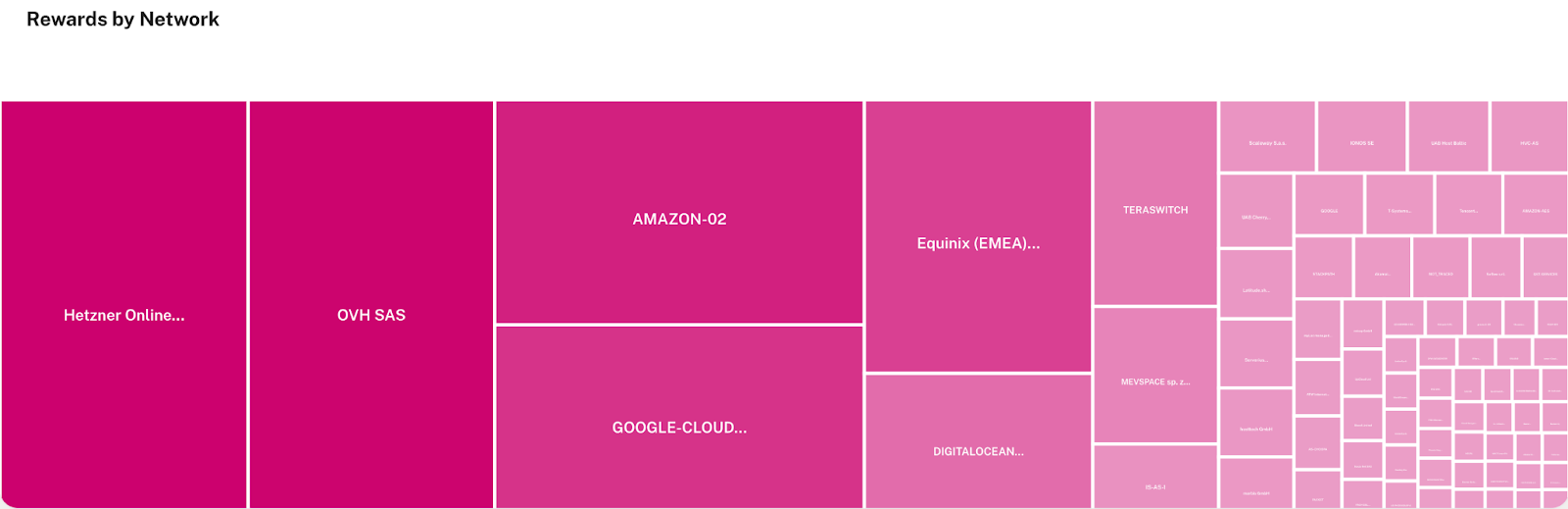
Concentration risk
- It is a consequence of decentralization. People are free to do this.
- About 17% of DOT rewards are coming to nodes in Hetzner (July 2023).
- Four of the major providers take 50% of the rewards (July 2023).
Notes:
This is a concentration risk in one picture. Since the web3 world is decentralized, there is no proper handle to prevent this. However, node operators should realize that their individual actions affect the whole ecosystem.
Caveats of the supply chain management
- Let’s assume that we have deplatforming-resistance infrastructure and some well known preventions in place. Your password is not your name plus your birthday.
What’s next?
- Now let’s talk about the modern issues of supply chain management in the infrastructure.
- Supply chain attack: when someone compromises only a small component of a product and gets access to the whole product.
- The same can be applied to any part on a random entity (orgs, dev libs, people relations)
Supply chain protection basics
Like dependencies in the regular code, all of the infrastructure components can be compromised by supply chain attacks as well. The most risky components are ... (spoiler - almost all).
Where to expect the attack
- Integrations that can’t be restricted by scope to a specific need. Example: GitHub OAuth token leak'22
- Yet another small component that solves once again a well known problem. Usage of it increases the attack surface.
- Components that don’t have proper support. Can be abandoned and squatted one day.
- Suddenly, most popular products, but for another reason: be careful with the names and scopes to avoid typosquatters.
Basic prevention of the supply chain attacks
- Prevention of replacing the content of dependency (80% result by 20% of efforts):
- Scoping dependencies. For some ecosystems (ex. - Docker, NPM) - the same thing can be looked up in different locations. Specific lookup locations (repos) are highly recommended.
- Pinning dependency to a specific commit (e.g. lib@aaabbbccc…). Pinning to a tag (lib@tagname) is not efficient. Commit is a hash, tag is human-defined.
- Forking and re-targeting the dependency to the new controllable fork.
Basic prevention of the supply chain attacks
- Increasing the dependency quality (20% of result by 80% efforts):
- For advanced usage: tracking the vulnerabilities related to the component (update or downgrade the version)
- self reviewing the code of the component
- extracting the direct functionality from the dependency.
Uncommon infrastructure attacks
Some examples.
Simple, but very efficient.
Abusing of CI/CD misconfigurations
- Abusing CI/CD by triggering the pipeline with modified code, which makes malicious actions - steal your repo secrets or break your CI/CD.
- Mitigation: understand the triggering event, restrict who can trigger the CI and set the scopes for the CI/CD:
- Runners
- Secrets
- Other components
Social engineering: forging the GIT commits
We can commit on behalf of someone else! But there is a small detail…
Git doesn’t have authentication
How does it work:
GIT itself is not responsible for authentication. Everyone can set random username and email in the commit metadata, and to push the branch or create a pull request.
It is the nature of git. A great field for social engineering!
Exploiting git
Get a target repo, find a "victim" - a popular person,
uses mixed verified and unverified commits:
- https://github.com/ethereum/research/commits?author=vbuterin
- https://github.com/jayphelps/git-blame-someone-else
Exploiting git
Clone the repo and find the victim’s git metadata
git show --quiet 6355f3a

Exploiting git
Change the local git settings.
git config commit.gpgSign false
git config user.email v@buterin.com
git config user.name "Vitalik Buterin"
Exploiting git
Make a definitely trustworthy commit:
echo "I'm Vitalik Buterin, trust me, send all the ethers on ..." > message.txt
git add message.txt
git commit -a -m "wallet update"
git push origin master
What stops the app-ocalypse: an attacker needs write permissions to push, which is defined by credentials from the code storage.
But the attacker still can play around Pull Requests, mix forged/non-forged commits, etc.
Exploiting git
See the result (a fork was created to have write access):
https://github.com/pavelsupr/research/commit/99cb1cbe3b729cfada10aa53d531b5f2bcb5aa7f
Mitigation from commit forgery
-
Commit signing + Vigilant mode, protection of the branches, reviewing the pull request about what’s going on - and reviewing them one more time!
-
Dismiss a pull request when new commits arrived
-
Caveat: impossible to properly revoke the signing key - all the previous commits will be considered as “unverified” in the Vigilant mode.
-
Solution: use hardware keys, which is very hard to compromise + destroy all the software keys, but don’t remove the public key fingerprint from the repo storage.
Secure key management on the nodes
Polkadot-specific.
Basics
- A separated browser profile or/and OS account for web3 operations
- Lock this profile with a password to prevent stealing the data
- No 3rd-party operations and browser extensions on the “secured” profile
- Or, replacing all the above: A separated device as an ideal paranoid mode option
- All significant accounts only on a cold wallet + paper seed backup (ref: Banana Split)
- Client disk encryption and other device health checks
Node running
- Node accounts: proper combination of Stash and Staking proxy (prev. Controller) accounts
- Stash - use cold wallet
- Controller != Stash
- Remember that a node process has to store some keys on the disk (session keys). Keep the node isolated
- Apply all the well known measures: firewalling, strong passwords, 2FA, disk encryption, etc.
- Containers are NOT protecting your node from the OS/kernel
Password management for the infrastructure
- Use keys instead of passwords where possible
- SSH and GPG keys on hardware keys (one primary key and backup)
- 2FA everywhere, hardware based when possible
- Use password manager (preferable with API), don't re-use passwords
- NEVER place any secrets in the code or files, even for testing, use environment variables instead
- Advanced: connect your code with the API of your password manager
- (life hack only for Bash users) one space before
export VAR=SECRET_VALUEcommand will not place this command in the Bash history
Questions
Application
How to use the slides - Full screen (new tab)
Security is a matter of balance, not too much, not less. Only adequate security.

Security is about your residual risks, not what you have prevented.
Application Security
Overview
Securing SDLC
The Big Picture of AppSec
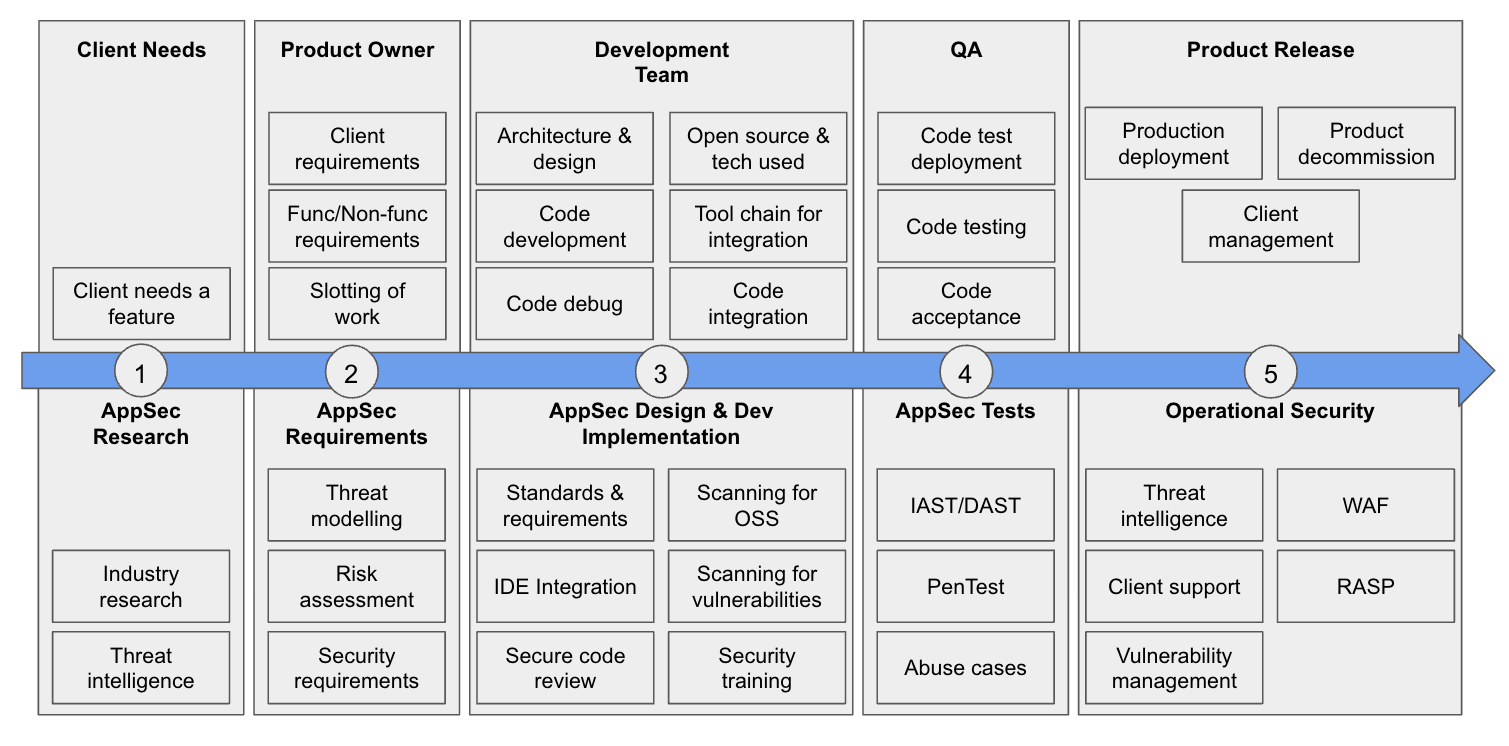
We will visit this picture multiple times.
Security Enforced Through Controls
Controls must be:
- Designed
- Developed
- Implemented
- Configured
- Operated
- Monitored
- Improved
How do we decide on Controls?
The likelihood of a threat exploiting a vulnerability and thereby causing damage to an asset.

ICYMI: The CIA Triad
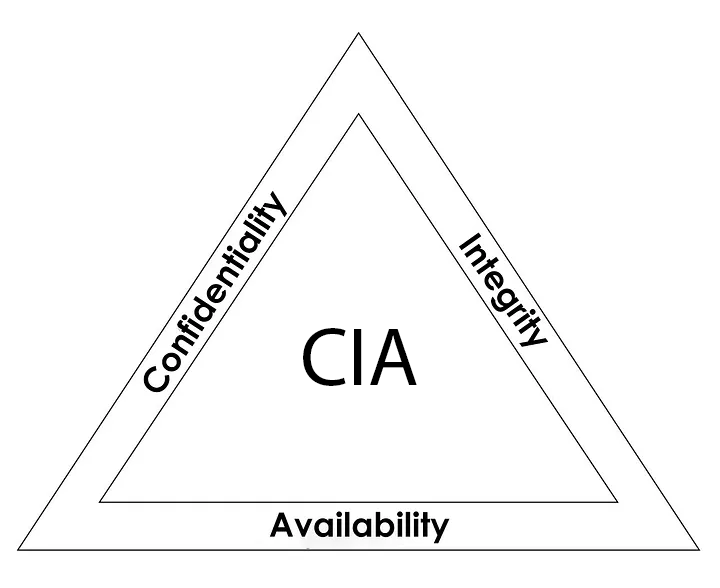
Things to Ensure
- Confidentiality: Ensure that only authorized people can access their authorized entities.
- Integrity: Ensure that only authorized changes are made by authorized entities.
- Availability: Ensure that the data will always be available when it is required.
The AAA + NR
- Authentication: Who you are
- Authorization: What you allowed to do
- Accountability: Who is responsible
- Non-Repudiation: Can't deny your involvement
Appsec Design Principles
In Brief
Good Enough Security
Don’t spend $10.000 on a safe to protect a $20 bill

Least Privilege
Don't give your safe's key to everybody, give only what they need

Separation of Duties
Don't give the power of creating invoices, approving invoices and sending money to one person

Defense in Depth
A castle has a moat, thick walls, restricted access points, high points for defense, multiple checkpoints inside etc.; what do you have?

Fail-Safe
Any function that is not specifically authorized is denied by default

Economy of Mechanism
Security is already a complex topic, don’t make it more complicated (KISS)

Complete Mediation
Every critical operation must have verification at every time.

Open Design
Don't even try: Security over obscurity

Least Common Mechanism
Is like the rarest key that opens specific locks, not used often but still can cause significant damage when it does.

Psychological Acceptability
There is no point if users cannot use your security controls seamlessly.

Weakest Link
A chain is only as strong as its weakest link

Leverage Existing Components
Fewer components, fewer attack surface, but more;

Single Point of Failure
If SPoF fails, means the entire system fails

Securing Software is Very Simple(!?)
- Identify Attack Surfaces What potential surfaces do you have?
- Identify Attack Vectors What potential vectors do you have?
- Allocate Security Controls Risk based approach + Security Controls
Security Controls are Easy(!?)
Security controls can be;
- Directive (Safeguard [Proactive] - means before the incident) * The policy is an example. This is what you are allowed to do, or you are not allowed to do

Security controls can be;
- Deterrent (Safeguard [Proactive] - means before the incident)
- Discourage somebody from doing something wrong. For ex. watching people with a security camera. Once they know they are under observation, they will hesitate.
Deterrent

Security controls can be;
- Preventive (Safeguard [Proactive] - means before the incident) * Try to stop a person from doing something wrong. For ex. Password is a preventive control.

Security controls can be;
- Detective (Countermeasures [Reactive] - means in the incident moment or afterwards) * Trying to detect an incident. For ex. logs

Security controls can be;
- Corrective (Countermeasures [Reactive] - means afterwards) * Tries to reestablish control after an incident and correct the immediate problem.

Security controls can be;
- Restoration/Recovery (Countermeasures [Reactive] - means afterwards) * Try to rebuild and get back to normal.

Implementation is tough, sorry
- Secure coding practices
- Separation of environments
- Proper testing
- Validation and discovery
- Mitigation
- Root cause analysis
- Documentation in every steps
Components of AppSec
- Threat Modelling: Manuel or Automated
- Security Testing: SAST, DAST, IAST, SCA, RASP
- Vuln. Collection & Prioritization: Jira, Asana
There will be blood (risk), you need to manage the blood. But how?

Risk Management but how?
- Risk Avoidance: This approach mitigates risk by refraining from activities that could negatively impact the organization.
Risk Management but how?
- Risk Reduction: This risk management method aims to limit the losses rather than completely eradicate them. It accepts the risk but works to contain potential losses and prevent their spread.
Risk Management but how?
- Risk Sharing: In this case, the risk of potential loss is distributed among a group instead of being borne by an individual.
Risk Management but how?
- Transferring Risk: This involves contractually shifting risk to a third party. For instance, insuring against property damage or injury transfers the associated risks from the property owner to the insurance company.
Risk Management but how?
- Risk Acceptance and Retention: After applying risk sharing, risk transfer, and risk reduction measures, some risk inevitably remains, as it's virtually impossible to eliminate all risks. This remaining risk is known as residual risk.
Vulnerability Disclosure Program vs Bug Bounty
Shifting Left vs Right
Known Attack Surfaces and Vectors
Known Rust Vulnerabilities
- Rust-specific issues
- Unsafe code
- Cryptographic errors
Known Substrate Vulnerabilities
- Insufficient testing
- Centralization vulnerabilities
- Pallet-specific vulnerabilities
Known ink! Vulnerabilities
- Incorrect access control
- Denial-of-Service (DoS)
- Timestamp dependence
- Outdated version
Summary: Do the damn input validation, good to go!

Question: How would you defend a castle if there is no castle to defend?
Common Security Risks in Polkadot SDK Development
How to use the slides - Full screen (new tab)
Common Security Risks in Polkadot SDK Development
This presentation discuss common security risks in Polkadot SDK (Polkadot, Substrate, Cumulus, etc.) development, and methods to mitigate them.
Each security risk is composed of: Challenge, Risk, Case Studies, Mitigation and Takeaways.
Security Risks
- Insecure Randomness
- Storage Exhaustion
- Insufficient Benchmarking
- Outdated Crates
- XCM Misconfiguration
- Unsafe Math
- Replay Issues
- Unbounded Decoding
- Verbosity Issues
- Inconsistent Error Handling
Disclaimer
Apart from the mitigations suggested here, it is always important to ensure a properly audit and intense testing.
Specially, if your system handles real value assets, considering that if they are exploited, it could hurt their owners.
Insecure Randomness
---v
Challenge
On-chain randomness on any public, decentralized, and deterministic system like a blockchain is difficult!
- Use of weak cryptographic algorithms or insecure randomness in the system can compromise the integrity of critical functionalities.
- This could allow attackers to predict or manipulate outcomes of any feature that rely on secure randomness.

---v
Risk
- Manipulation or prediction of critical functionalities, leading to compromised integrity and security.
- Potential for attackers to gain an unfair advantage, undermining trust in the system.

---v
Case Study - Randomness Collective Flip
- Randomness Collective Flip pallet from Substrate provides a random function that generates low-influence random values based on the block hashes from the previous 81 blocks.
- Low-influence randomness can be useful when defending against relatively weak adversaries.
- Using this pallet as a randomness source is advisable primarily in low-security situations like testing.
---v
Case Study - Randomness Collective Flip
#![allow(unused)] fn main() { /// substrate/frame/insecure-randomness-collective-flip/src/lib.rs fn on_initialize(block_number: BlockNumberFor<T>) -> Weight { let parent_hash = <frame_system::Pallet<T>>::parent_hash(); /// ... <RandomMaterial<T>>::mutate(|ref mut values| { if values.try_push(parent_hash).is_err() { let index = block_number_to_index::<T>(block_number); values[index] = parent_hash; } }); /// ... } /// ... fn random(subject: &[u8]) -> (T::Hash, BlockNumberFor<T>) { let block_number = <frame_system::Pallet<T>>::block_number(); let index = block_number_to_index::<T>(block_number); /// ... let hash_series = <RandomMaterial<T>>::get(); let seed = if !hash_series.is_empty() { // Always the case after block 1 is initialized. hash_series .iter() .cycle() .skip(index) // RANDOM_MATERIAL_LEN = 81 .take(RANDOM_MATERIAL_LEN as usize) .enumerate() .map(|(i, h)| (i as i8, subject, h) .using_encoded(T::Hashing::hash) ).triplet_mix() } else { T::Hash::default() }; (seed, block_number.saturating_sub(RANDOM_MATERIAL_LEN.into())) } }
---v
Case Study - VRF
-
There are two main secure approaches to blockchain randomness in production today: RANDAO and VRF. Polkadot uses VRF.
VRF: mathematical operation that takes some input and produces a random number along with a proof of authenticity that this random number was generated by the submitter.
-
With VRF, the proof can be verified by any challenger to ensure the random number generation is valid.
---v
Case Study - VRF
- Babe pallet randomness options
- Randomness From Two Epochs Ago
- Use Case: For consensus protocols that need finality.
- Timing: Uses data from two epochs ago.
- Risks: Bias if adversaries controlling block production at specific times.
- Randomness From One Epoch Ago (Polkadot Parachain Auctions)
- Use Case: For on-chain actions that don't need finality.
- Timing: Uses data from the previous epoch.
- Risks: Bias if adversaries control block prod. at end/start of an epoch.
- Current Block Randomness
- Use Case: For actions that need fresh randomness.
- Timing: Appears fresh but is based on older data.
- Risks: Weakest form, bias if adversaries don't announce blocks.
- Randomness From Two Epochs Ago
- Randomness is affected by other inputs, like external randomness sources.
---v
Case Study - VRF
#![allow(unused)] fn main() { /// substrate/frame/babe/src/lib.rs /// Compute randomness for a new epoch. rho is the concatenation of all /// VRF outputs in the prior epoch. /// an optional size hint as to how many VRF outputs there were may be provided. fn compute_randomness( last_epoch_randomness: BabeRandomness, epoch_index: u64, rho: impl Iterator<Item = BabeRandomness>, rho_size_hint: Option<usize>, ) -> BabeRandomness { let mut s = Vec::with_capacity( 40 + rho_size_hint.unwrap_or(0) * RANDOMNESS_LENGTH); s.extend_from_slice(&last_epoch_randomness); s.extend_from_slice(&epoch_index.to_le_bytes()); for vrf_output in rho { s.extend_from_slice(&vrf_output[..]); } sp_io::hashing::blake2_256(&s) } /// ... /// Call this function exactly once when an epoch changes, to update the /// randomness. Returns the new randomness. fn randomness_change_epoch(next_epoch_index: u64) -> BabeRandomness { let this_randomness = NextRandomness::<T>::get(); let segment_idx: u32 = SegmentIndex::<T>::mutate(|s| sp_std::mem::replace(s, 0)); // overestimate to the segment being full. let rho_size = (segment_idx.saturating_add(1) * UNDER_CONSTRUCTION_SEGMENT_LENGTH) as usize; let next_randomness = compute_randomness( this_randomness, next_epoch_index, (0..segment_idx).flat_map(|i| UnderConstruction::<T>::take(&i)), // VRF (From Digest) Some(rho_size), ); NextRandomness::<T>::put(&next_randomness); this_randomness // -> Randomness::<T>::put(..); } /// substrate/frame/babe/src/randomness.rs impl<T: Config> RandomnessT<T::Hash, BlockNumberFor<T>> for RandomnessFromOneEpochAgo<T> { fn random(subject: &[u8]) -> (T::Hash, BlockNumberFor<T>) { let mut subject = subject.to_vec(); subject.reserve(RANDOMNESS_LENGTH); subject.extend_from_slice(&NextRandomness::<T>::get()[..]); (T::Hashing::hash(&subject[..]), EpochStart::<T>::get().1) } } }
---v
Mitigation
-
All validators can be trusted
VRF
-
Not all validators can be trusted
-
Profit from exploiting randomness is substantially more than the profit from building a block
Trusted solution (Oracles, MPC, Commit-Reval, etc.)
-
Otherwise
VRF
-
---v
Takeaways
- On-chain randomness is difficult.
- Polkadot uses VRF (i.e. Auctions).
- On VRF (Pallet BABE), randomness can only be manipulated by the block producers. If all nodes are trusted, then the randomness can be trusted too.
- You can also inject trusted randomness into the chain via a trusted oracle.
- Don’t use Randomness Collective Flip in production!
Storage Exhaustion
---v
Challenge
Your chain can run out of storage!
- Inadequate charging mechanism for on-chain storage, which allows users to occupy storage space without paying the appropriate deposit fees.
- This loophole can be exploited by malicious actors to fill up the blockchain storage cheaply, making it unsustainable to run a node and affecting network performance.

---v
Risk
- Unsustainable growth in blockchain storage, leading to increased costs and potential failure for node operators.
- Increased susceptibility to DoS attacks that exploit the inadequate storage deposit mechanism to clutter the blockchain.
---v
Case Study - Existential Deposit
- If an account's balance falls below the existential deposit, the account is reaped, and its data is deleted to save storage space.
- Existential deposits are required to optimize storage. The absence or undervaluation of existential deposits can lead to DoS attacks.
- The cost of permanent storage is generally not accounted for in the weight calculation for extrinsics, making it possible for an attacker to fill up the blockchain storage by distributing small amounts of native tokens to many accounts.
---v
Case Study - Existential Deposit
#![allow(unused)] fn main() { /// relay/polkadot/constants/src/lib.rs /// Money matters. pub mod currency { /// The existential deposit. pub const EXISTENTIAL_DEPOSIT: Balance = 100 * CENTS; /// ... pub const UNITS: Balance = 10_000_000_000; pub const DOLLARS: Balance = UNITS; // 10_000_000_000 pub const CENTS: Balance = DOLLARS / 100; // 100_000_000 } /// relay/polkadot/src/lib.rs parameter_types! { pub const ExistentialDeposit: Balance = EXISTENTIAL_DEPOSIT; /// ... } impl pallet_balances::Config for Runtime { type ExistentialDeposit = ExistentialDeposit; /// ... } }
---v
Case Study - General Storage Usage System
---v
Case Study - NFT Pallet Manual Deposit
#![allow(unused)] fn main() { /// substrate/frame/nfts/src/lib.rs /// ... /// Origin must be either `ForceOrigin` or Signed and the sender should be the Admin of the /// `collection`. /// /// If the origin is Signed, then funds of signer are reserved according to the formula: /// `MetadataDepositBase + DepositPerByte * data.len` taking into /// account any already reserved funds. /// ... #[pallet::call_index(24)] #[pallet::weight(T::WeightInfo::set_metadata())] pub fn set_metadata( origin: OriginFor<T>, collection: T::CollectionId, item: T::ItemId, data: BoundedVec<u8, T::StringLimit>, ) -> DispatchResult { let maybe_check_origin = T::ForceOrigin::try_origin(origin) .map(|_| None) .or_else(|origin| ensure_signed(origin).map(Some).map_err(DispatchError::from))?; Self::do_set_item_metadata(maybe_check_origin, collection, item, data, None) } /// substrate/frame/nfts/src/features/attributes.rs fn do_set_item_metadata { /// ... let mut deposit = Zero::zero(); if collection_config.is_setting_enabled(CollectionSetting::DepositRequired) // Next line was added to fix the issue || namespace != AttributeNamespace::CollectionOwner { deposit = T::DepositPerByte::get() .saturating_mul(((data.len()) as u32).into()) .saturating_add(T::MetadataDepositBase::get()); } let depositor = maybe_depositor.clone().unwrap_or(collection_details.owner.clone()); let old_depositor = old_deposit.account.unwrap_or(collection_details.owner.clone()); if depositor != old_depositor { T::Currency::unreserve(&old_depositor, old_deposit.amount); T::Currency::reserve(&depositor, deposit)?; } else if deposit > old_deposit.amount { T::Currency::reserve(&depositor, deposit - old_deposit.amount)?; } else if deposit < old_deposit.amount { T::Currency::unreserve(&depositor, old_deposit.amount - deposit); } /// ... } }
---v
Mitigation
- Existential Deposit: ensure a value similar to the defined by the relay chain.
- Storage Deposit: implement a good logic similar to the following:
#![allow(unused)] fn main() { // Deposit calculation (bytes * deposit_per_byte + deposit_base) let mut deposit = T::DepositPerByte::get() .saturating_mul(((key.len() + value.len()) as u32).into()) .saturating_add(T::DepositBase::get()); // Deposit reserve (dynamic data size) if old_deposit.account.is_some() && old_deposit.account != Some(origin.clone()) { T::Currency::unreserve( &old_deposit.account.unwrap(), old_deposit.amount); T::Currency::reserve(&origin, deposit)?; } else if deposit > old_deposit.amount { T::Currency::reserve(&origin, deposit - old_deposit.amount)?; } else if deposit < old_deposit.amount { T::Currency::unreserve(&origin, old_deposit.amount - deposit); } }
---v
Takeaways
- Always explicitly require a deposit for on-chain storage (in the form of Reserved Balance).
- Deposit is returned to the user when the user removes the data from the chain.
- Ensure the existential deposit is greater than N. To determine N you can start from values similar to relay chain and monitor users activity.
- If possible, limit the amount of data that a pallet can have. Otherwise, ensure some friction (reserve deposit) in the storage usage.
Insufficient Benchmarking
---v
Challenge
Benchmarking can be a difficult task...
- Incorrect or missing benchmarking can lead to overweight blocks, causing network congestion and affecting the overall performance of the blockchain.
- This can happen when the computational complexity or storage access is underestimated, leading to inaccurate weight for extrinsics.

---v
Risk
-
Overweight extrinsics can slow down the network.
-
Leads to delays in transaction processing and affects UX.
-
Underweight extrinsics can be exploited to spam the network.
-
Leads to a potential Denial of Service (DoS) attack.
---v
Case Study - Benchmark Input Length - Issue
#![allow(unused)] fn main() { /// substrate/frame/remark/src/lib.rs (modified) #[frame_support::pallet] pub mod pallet { /// ... #[pallet::call] impl<T: Config> Pallet<T> { /// Index and store data off chain. #[pallet::call_index(0)] #[pallet::weight(T::WeightInfo::store())] pub fn store(origin: OriginFor<T>, remark: Vec<u8>) -> DispatchResultWithPostInfo { ensure!(!remark.is_empty(), Error::<T>::Empty); let sender = ensure_signed(origin)?; let content_hash = sp_io::hashing::blake2_256(&remark); let extrinsic_index = <frame_system::Pallet<T>>::extrinsic_index() .ok_or_else(|| Error::<T>::BadContext)?; sp_io::transaction_index::index(extrinsic_index, remark.len() as u32, content_hash); Self::deposit_event(Event::Stored { sender, content_hash: content_hash.into() }); Ok(().into()) } } /// ... } /// substrate/frame/remark/src/benchmarking.rs (modified) benchmarks! { store { let caller: T::AccountId = whitelisted_caller(); }: _(RawOrigin::Signed(caller.clone()), vec![]) verify { assert_last_event::<T>(Event::Stored { sender: caller, content_hash: sp_io::hashing::blake2_256(&vec![0u8; l as usize]).into() }.into()); } impl_benchmark_test_suite!(Remark, crate::mock::new_test_ext(), crate::mock::Test); } }
---v
Case Study - Benchmark Input Length - Mitigation
#![allow(unused)] fn main() { /// substrate/frame/remark/src/lib.rs #[frame_support::pallet] pub mod pallet { /// ... #[pallet::call] impl<T: Config> Pallet<T> { /// Index and store data off chain. #[pallet::call_index(0)] #[pallet::weight(T::WeightInfo::store(remark.len() as u32))] pub fn store(origin: OriginFor<T>, remark: Vec<u8>) -> DispatchResultWithPostInfo { ensure!(!remark.is_empty(), Error::<T>::Empty); let sender = ensure_signed(origin)?; let content_hash = sp_io::hashing::blake2_256(&remark); let extrinsic_index = <frame_system::Pallet<T>>::extrinsic_index() .ok_or_else(|| Error::<T>::BadContext)?; sp_io::transaction_index::index(extrinsic_index, remark.len() as u32, content_hash); Self::deposit_event(Event::Stored { sender, content_hash: content_hash.into() }); Ok(().into()) } } /// ... } /// substrate/frame/remark/src/benchmarking.rs benchmarks! { store { let l in 1 .. 1024*1024; let caller: T::AccountId = whitelisted_caller(); }: _(RawOrigin::Signed(caller.clone()), vec![0u8; l as usize]) verify { assert_last_event::<T>(Event::Stored { sender: caller, content_hash: sp_io::hashing::blake2_256(&vec![0u8; l as usize]).into() }.into()); } impl_benchmark_test_suite!(Remark, crate::mock::new_test_ext(), crate::mock::Test); } }
---v
Mitigation
-
Run benchmarks using the worst case scenario conditions.
For example, more amount of DB reads and write that could ever happen in a extrinsic.
-
Primary goal is to keep the runtime safe.
-
Secondary goal is to be as accurate as possible to maximize throughput.
-
For non-hard deadline code use metering.
---v
Takeaways
- Benchmarking ensures that parachain’s users are not using resources beyond what is available and expected for our network.
- Weight is used to track consumption of limited blockchain resources based on Execution Time (Reference Hardware) and Size of Data required to create a Merkle Proof.
- 1 second of compute on different computers allows for different amounts of computation.
Outdated Crates
---v
Challenge
Dependencies can become a nightmare!
- Using outdated or known vulnerable components, such as pallets or libraries, in a Substrate runtime can expose the system to broad range of security risks and exploits.

---v
Risk
- Exposure to known vulnerabilities that could be exploited by attackers.
- Compromised network integrity and security, leading to potential data breaches or financial loss.
---v
Case Study - Serde Precompiled Binary
- Polkadot uses
serdewith thederivefeature as a dependency. - Issue: Serde developers decided to ships it as a precompiled binary. Article.
- Mitigation: Dependency was fixed to a version that doesn't include the precompiled binary.

A trustless system, such as Polkadot, can't blindly trust binaries.
---v
Mitigation
- Always uses the latest stable version of Polkadot, Substrate, Cumulus, and any other third party crate.
- If possible, avoid using too many crates.
- Use tools such as
cargo auditorcargo vetto monitor the state of your system’s dependencies. - Don't use dependencies that include precompiled binaries.
---v
Takeaways
- Outdated crates can lead to vulnerabilities in your system even if the crate don’t have a vulnerability.
- Outdated crates can contain known vulnerabilities that could be easily exploited in your system.
- Don’t use the latest version of a crate (in production) until it is declared as stable.
XCM Misconfiguration
---v
Challenge
Configuring correctly XCM needs a lot of attention!
- XCM needs to be configured through different pallets and configs.
- Determining the access control to the XCM pallet and the incoming queues needs to be done carefully.
- For new parachains, it is difficult to determine which XCM messages are needed and which are not.
- If the config is not correctly setup the chain could be vulnerable to attacks, become spam targets if incoming XCM messages are not handled as untrusted and/or sanitized properly, or even be used as a bridge to attack other parachains by not enforcing a good Access Control in send operations.
---v
Risk
- Unauthorized manipulation of the blockchain state, compromising the network's integrity.
- Execution of unauthorized transactions, leading to potential financial loss.
- Be used as an attack channel to parachains.
---v
Case Study - Rococo Bridge Hub - Description
- The
MessageExportertype (BridgeHubRococoOrBridgeHubWococoSwitchExporter) in the Rococo's Bridge Hub XcmConfig was using theunimplemented!()macro invalidateanddelivermethods, what is equivalent to thepanic!()macro. This was exposing the Rococo Bridge Hub runtime to non-skippable panic reachable by any parachain allowed to send messages to the Rococo Bridge Hub. - This issue was trivial to execute for anyone that can send messages to the Bridge Hub, as the only needed is to send a valid XCM message that includes an ExportMessage instruction trying to bridge to a network that is not implemented.
---v
Case Study - Rococo Bridge Hub - Issue
#![allow(unused)] fn main() { /// cumulus/parachains/runtimes/bridge-hubs/bridge-hub-rococo/src/xcm_config.rs pub struct BridgeHubRococoOrBridgeHubWococoSwitchExporter; impl ExportXcm for BridgeHubRococoOrBridgeHubWococoSwitchExporter { type Ticket = (NetworkId, (sp_std::prelude::Vec<u8>, XcmHash)); fn validate( network: NetworkId, channel: u32, universal_source: &mut Option<InteriorMultiLocation>, destination: &mut Option<InteriorMultiLocation>, message: &mut Option<Xcm<()>>, ) -> SendResult<Self::Ticket> { match network { Rococo => ToBridgeHubRococoHaulBlobExporter::validate( network, channel, universal_source, destination, message, ) .map(|result| ((Rococo, result.0), result.1)), Wococo => ToBridgeHubWococoHaulBlobExporter::validate( network, channel, universal_source, destination, message, ) .map(|result| ((Wococo, result.0), result.1)), _ => unimplemented!("Unsupported network: {:?}", network), } }
---v
Case Study - Rococo Bridge Hub - XCM Config
#![allow(unused)] fn main() { /// cumulus/parachains/runtimes/bridge-hubs/bridge-hub-rococo/src/xcm_config.rs pub struct XcmConfig; impl xcm_executor::Config for XcmConfig { type RuntimeCall = RuntimeCall; type XcmSender = XcmRouter; type AssetTransactor = CurrencyTransactor; type OriginConverter = XcmOriginToTransactDispatchOrigin; // BridgeHub does not recognize a reserve location for any asset. Users must teleport Native // token where allowed (e.g. with the Relay Chain). type IsReserve = (); type IsTeleporter = TrustedTeleporters; type UniversalLocation = UniversalLocation; type Barrier = Barrier; type Weigher = WeightInfoBounds< crate::weights::xcm::BridgeHubRococoXcmWeight<RuntimeCall>, RuntimeCall, MaxInstructions, >; type Trader = UsingComponents<WeightToFee, TokenLocation, AccountId, Balances, ToStakingPot<Runtime>>; type ResponseHandler = PolkadotXcm; type AssetTrap = PolkadotXcm; type AssetLocker = (); type AssetExchanger = (); type AssetClaims = PolkadotXcm; type SubscriptionService = PolkadotXcm; type PalletInstancesInfo = AllPalletsWithSystem; type MaxAssetsIntoHolding = MaxAssetsIntoHolding; type FeeManager = XcmFeesToAccount<Self, WaivedLocations, AccountId, TreasuryAccount>; type MessageExporter = BridgeHubRococoOrBridgeHubWococoSwitchExporter; type UniversalAliases = Nothing; type CallDispatcher = WithOriginFilter<SafeCallFilter>; type SafeCallFilter = SafeCallFilter; type Aliasers = Nothing; } /// This is the type we use to convert an (incoming) XCM origin into a local `Origin` instance, /// ready for dispatching a transaction with Xcm's `Transact`. There is an `OriginKind` which can /// biases the kind of local `Origin` it will become. pub type XcmOriginToTransactDispatchOrigin = ( // Sovereign account converter; this attempts to derive an `AccountId` from the origin location // using `LocationToAccountId` and then turn that into the usual `Signed` origin. Useful for // foreign chains who want to have a local sovereign account on this chain which they control. SovereignSignedViaLocation<LocationToAccountId, RuntimeOrigin>, // Native converter for Relay-chain (Parent) location; will convert to a `Relay` origin when // recognized. RelayChainAsNative<RelayChainOrigin, RuntimeOrigin>, // Native converter for sibling Parachains; will convert to a `SiblingPara` origin when // recognized. SiblingParachainAsNative<cumulus_pallet_xcm::Origin, RuntimeOrigin>, // Superuser converter for the Relay-chain (Parent) location. This will allow it to issue a // transaction from the Root origin. ParentAsSuperuser<RuntimeOrigin>, // Native signed account converter; this just converts an `AccountId32` origin into a normal // `RuntimeOrigin::Signed` origin of the same 32-byte value. SignedAccountId32AsNative<RelayNetwork, RuntimeOrigin>, // Xcm origins can be represented natively under the Xcm pallet's Xcm origin. XcmPassthrough<RuntimeOrigin>, ); pub type Barrier = TrailingSetTopicAsId< DenyThenTry< DenyReserveTransferToRelayChain, ( // Allow local users to buy weight credit. TakeWeightCredit, // Expected responses are OK. AllowKnownQueryResponses<PolkadotXcm>, WithComputedOrigin< ( // If the message is one that immediately attempts to pay for execution, //then allow it. AllowTopLevelPaidExecutionFrom<Everything>, // Parent, its pluralities (i.e. governance bodies) and relay treasury // pallet get free execution. AllowExplicitUnpaidExecutionFrom<( ParentOrParentsPlurality, Equals<RelayTreasuryLocation>, )>, // Subscriptions for version tracking are OK. AllowSubscriptionsFrom<ParentOrSiblings>, ), UniversalLocation, ConstU32<8>, >, ), >, >; }
---v
Mitigation
- Constantly, verify all your configs and compare with other chains.
- In XMC pallet, limit usage execute and send until XCM security guarantees can be ensured.
- In XCM executor, ensure a correct access control in your
XcmConfig:- Only trusted sources can be allowed. Filter origins with
OriginConverter. - Only the specific messages structures your parachain needs to receive can be accepted. Filter message structures with
Barrier(general),SafeCallFilter(transact),IsReserve(reserve),IsTeleporter(teleport),MessageExporter(export),XcmSender(send), etc.
- Only trusted sources can be allowed. Filter origins with
- In XCMP queue, ensure only trusted channels are open.
---v
Takeaways
- XCM development and audits are still going on, so its security guarantees can be ensured at the moment.
- Allowing any user to use execute and send can have a serious impact on your parachain.
- Incoming XCMs need to be handled as untrusted and sanitized properly.
- Insufficient Access Control in your parachain can enable bad actors to attack other parachains through your system.
Unsafe Math
---v
Challenge
- Unsafe math operations in the codebase can lead to integer overflows/underflows, divisions by zero, conversion truncation/overflow and incorrect end results which can be exploited by attackers to manipulate calculations and gain an unfair advantage.
- This involve mainly the usage of primitive arithmetic operations.

---v
Risk
- Manipulation of account balances, leading to unauthorized transfers or artificial inflation of balances.
- Potential disruption of network functionalities that rely on accurate arithmetic calculations.
- Incorrect calculations, leading to unintended consequences like incorrect account balances or transaction fees..
- Potential for attackers to exploit the vulnerability to manipulate outcomes in their favor.
---v
Case Study - Frontier Balances - Description
- Frontier's CVE-2022-31111 disclosure describes the issues found in the process of converting balances from EVM to Substrate, where the pallet didn't handle it right, causing the transferred amount to appear differently leading to a possible overflow.
- This is risky for two reasons:
- It could lead to wrong calculations, like messed-up account balances.
- People with bad intentions could use this error to get unfair advantages.
- To fix this, it's important to double-check how these conversions are done to make sure the numbers are accurate.
---v
Case Study - Frontier Balances - Issue
#![allow(unused)] fn main() { /// substrate/frame/evm/src/lib.rs #[pallet::genesis_build] impl<T: Config> GenesisBuild<T> for GenesisConfig { fn build(&self) { for (address, account) in &self.accounts { let account_id = T::AddressMapping::into_account_id(*address); // ASSUME: in one single EVM transaction, the nonce will not increase more than // `u128::max_value()`. for _ in 0..account.nonce.low_u128() { frame_system::Pallet::<T>::inc_account_nonce(&account_id); } T::Currency::deposit_creating( &account_id, account.balance.low_u128().unique_saturated_into(), ); }
---v
Case Study - Frontier Balances - Mitigation
#![allow(unused)] fn main() { /// substrate/frame/evm/src/lib.rs #[pallet::genesis_build] impl<T: Config> GenesisBuild<T> for GenesisConfig where U256: UniqueSaturatedInto<BalanceOf<T>>, { fn build(&self) { const MAX_ACCOUNT_NONCE: usize = 100; for (address, account) in &self.accounts { let account_id = T::AddressMapping::into_account_id(*address); // ASSUME: in one single EVM transaction, the nonce will not increase more than // `u128::max_value()`. for _ in 0..min( MAX_ACCOUNT_NONCE, UniqueSaturatedInto::<usize>::unique_saturated_into(account.nonce), ) { frame_system::Pallet::<T>::inc_account_nonce(&account_id); } T::Currency::deposit_creating( &account_id, account.balance.unique_saturated_into() ); }
---v
Mitigation
-
Arithmetic
-
Simple solution but (sometimes) more costly
Use checked/saturated functions like
checked_div. -
Complex solution but (sometimes) less costly
Validate before executing primitive functions. For example: balance > transfer_amount
-
-
Conversions
- Avoid downcasting values. Otherwise, use methods like
unique_saturated_intoinstead of methods likelow_u64. - Your system should be designed to avoid downcasting!
- Avoid downcasting values. Otherwise, use methods like
---v
Takeaways
- While testing pallets, system will panic (crash) if primitive arithmetic operation leads to overflow/underflow or division by zero. However, on release (production), pallets will not panic on overflow. Always ensure no unexpected overflow/underflow can happen.
- Checked operations use slightly more computational power than primitive operations.
- While testing pallets, system will panic (crash) if conversion leads to overflow/underflow or truncation. However, on release (production), pallets will not panic. Always ensure no unexpected overflow/underflow or truncation can happen.
- In a conversion, smaller the new type, more chances a overflow/underflow or truncation can happen.
Replay Issues
---v
Challenge
- Replay issues, most commonly arising from unsigned extrinsics, can lead to spamming and, in certain scenarios, double-spending attacks.
- This happens when nonces are not managed correctly, making it possible for transactions to be replayed.

---v
Risk
- Spamming the network with repeated transactions, leading to congestion and reduced performance.
- Potential for double-spending attacks, which can compromise the integrity of the blockchain.
---v
Case Study - Frontier STF - Description
- CVE-2021-41138 describes the security issues arose from the changes made in Frontier #482. Before this update, the function
validate_unsignedwas used to check if a transaction was valid. This function was part of the State Transition Function (STF), which is important when a block is being made. After the update, a new function validate_self_contained does the job but it's not part of the STF. This means a malicious validator could submit invalid transactions, and even reuse transactions from a different chain. - In the following sample from Frontier is possible to observe how the
do_transactfunction was used before the update, where thevalidate_self_containedwas not used. - In a later commit, this is patch by adding the validations on block production. Between the changes can be observe that replace of
do_transactforvalidate_transaction_in_blockthat contains the logic to validate a transaction that was previously invalidate_self_contained.
---v
Case Study - Frontier Balances - Issue
#![allow(unused)] fn main() { fn on_initialize(_: T::BlockNumber) -> Weight { Pending::<T>::kill(); // If the digest contain an existing ethereum block(encoded as PreLog), If contains, // execute the imported block firstly and disable transact dispatch function. if let Ok(log) = fp_consensus::find_pre_log(&frame_system::Pallet::<T>::digest()) { let PreLog::Block(block) = log; for transaction in block.transactions { let source = Self::recover_signer(&transaction).expect( "pre-block transaction signature invalid; the block cannot be built", ); Self::do_transact(source, transaction).expect( "pre-block transaction verification failed; the block cannot be built", ); } } 0 } }
---v
Case Study - Frontier Balances - Mitigation
#![allow(unused)] fn main() { fn on_initialize(_: T::BlockNumber) -> Weight { Pending::<T>::kill(); // If the digest contain an existing ethereum block(encoded as PreLog), If contains, // execute the imported block firstly and disable transact dispatch function. if let Ok(log) = fp_consensus::find_pre_log(&frame_system::Pallet::<T>::digest()) { let PreLog::Block(block) = log; for transaction in block.transactions { let source = Self::recover_signer(&transaction).expect( "pre-block transaction signature invalid; the block cannot be built", ); Self::validate_transaction_in_block(source, &transaction).expect( "pre-block transaction verification failed; the block cannot be built", ); Self::apply_validated_transaction(source, transaction).expect( // do_transact "pre-block transaction execution failed; the block cannot be built", ); } } 0 } // Common controls to be performed in the same way by the pool and the // State Transition Function (STF). // This is the case for all controls except those concerning the nonce. fn validate_transaction_common( origin: H160, transaction: &Transaction, ) -> Result<U256, TransactionValidityError> { // ... if let Some(chain_id) = transaction.signature.chain_id() { if chain_id != T::ChainId::get() { return Err(InvalidTransaction::Custom( TransactionValidationError::InvalidChainId as u8, ) .into()); } } // ... } }
---v
Mitigation
- Ensure that the data your system is receiving from untrustworthy sources:
- Can’t be re-used by implementing a nonces mechanism.
- Is intended for your system by checking any identification type like ID, hashes, etc.
---v
Takeaways
- Replay issues can lead to serious damage.
- Even if the chain ensure a runtime transaction can’t be replayed, external actors could replay a similar output by passing similar inputs if the they are not correctly verified.
Unbounded Decoding
---v
Challenge
- Decoding objects without a nesting depth limit can lead to stack exhaustion, making it possible for attackers to craft highly nested objects that cause a stack overflow.
- This can be exploited to disrupt the normal functioning of the blockchain network.

---v
Risk
- Stack exhaustion, which can lead to network instability and crashes.
- Potential for Denial of Service (DoS) attacks by exploiting the stack overflow vulnerability.
---v
Case Study - Whitelist Pallet - Description
- In Substrate #10159, the
whitelist-palletwas introduced. This pallet contains the extrinsicdispatch_whitelisted_callthat allow to dispatch a previously whitelisted call. - In order to be dispatched, the call needs to be decoded, and this was being done with the decode method.
- Auditors detected this method could lead to an stack overflow and suggested the developers to use decode_with_depth_limit to mitigate the issue.
- Risk was limited due to the origin had specific restrictions, but if the issue is triggered, the resulting stack overflow could cause a whole block to be invalid and the chain could get stuck failing to produce new blocks.
---v
Case Study - Whitelist Pallet - Issue
#![allow(unused)] fn main() { /// Remake of vulnerable whitelist pallet pub fn dispatch_whitelisted_call( origin: OriginFor<T>, call_hash: PreimageHash, call_encoded_len: u32, call_weight_witness: Weight, ) -> DispatchResultWithPostInfo { T::DispatchWhitelistedOrigin::ensure_origin(origin)?; ensure!( WhitelistedCall::<T>::contains_key(call_hash), Error::<T>::CallIsNotWhitelisted, ); let call = T::Preimages::fetch(&call_hash, Some(call_encoded_len)) .map_err(|_| Error::<T>::UnavailablePreImage)?; let call = <T as Config>::RuntimeCall::decode(&mut &call[..]) .map_err(|_| Error::<T>::UndecodableCall)?; }
---v
Case Study - Whitelist Pallet - Exploit PoC
#![allow(unused)] fn main() { /// Remake of vulnerable whitelist pallet #[test] fn test_unsafe_dispatch_whitelisted_call_stack_overflow() { new_test_ext().execute_with(|| { let mut call = RuntimeCall::System( frame_system::Call::remark_with_event { remark: vec![1] } ); let mut call_weight = call.get_dispatch_info().weight; let mut encoded_call = call.encode(); let mut call_encoded_len = encoded_call.len() as u32; let mut call_hash = <Test as frame_system::Config>::Hashing::hash(&encoded_call[..]); // The amount of nested calls to create // This test will not crash as it the following value is less than minimum // amount of calls to cause a stack overflow let nested_calls = sp_api::MAX_EXTRINSIC_DEPTH; // The following line to get a stack overflow error on decoding (pallet) let nested_calls = nested_calls*4; // Create the nested calls for _ in 0..=nested_calls { call = RuntimeCall::Whitelist(crate::Call::dispatch_whitelisted_call_with_preimage { call: Box::new(call.clone()), }); call_weight = call.get_dispatch_info().weight; encoded_call = call.encode(); call_encoded_len = encoded_call.len() as u32; call_hash = <Test as frame_system::Config>::Hashing::hash(&encoded_call[..]); } // Whitelist the call to being able to dispatch it assert_ok!(Preimage::note(encoded_call.into())); assert_ok!(Whitelist::whitelist_call(RuntimeOrigin::root(), call_hash)); // Send the call to be dispatched // This will throw a stack overflow if the nested calls is too high println!("Dispatching with {} nested calls", nested_calls); assert_ok!( Whitelist::dispatch_whitelisted_call( RuntimeOrigin::root(), call_hash, call_encoded_len, call_weight ), ); }); } }
---v
Case Study - Whitelist Pallet - Exploit Results
---v
Case Study - Whitelist Pallet - Mitigation
#![allow(unused)] fn main() { /// Remake of vulnerable whitelist pallet pub fn dispatch_whitelisted_call( origin: OriginFor<T>, call_hash: PreimageHash, call_encoded_len: u32, call_weight_witness: Weight, ) -> DispatchResultWithPostInfo { T::DispatchWhitelistedOrigin::ensure_origin(origin)?; ensure!( WhitelistedCall::<T>::contains_key(call_hash), Error::<T>::CallIsNotWhitelisted, ); let call = T::Preimages::fetch(&call_hash, Some(call_encoded_len)) .map_err(|_| Error::<T>::UnavailablePreImage)?; let call = <T as Config>::RuntimeCall::decode_all_with_depth_limit( sp_io::MAX_EXTRINSIC_DEPTH, &mut &call[..], ).map_err(|_| Error::<T>::UndecodableCall)?; }
---v
Mitigation
- Use the
decode_with_depth_limitmethod instead ofdecodemethod. - Use
decode_with_depth_limitwith a depth limit lower than the depth that can cause an stack overflow.
---v
Takeaways
- Decoding untrusted objects can lead to stack overflow.
- Stack overflow can lead to network instability and crashes.
- Always ensure a maximum depth while decoding data in a pallet.
Verbosity Issues
---v
Challenge
- Lack of detailed logs from collators, nodes, or RPC can make it difficult to diagnose issues, especially in cases of crashes or network halts.
- This lack of verbosity can hinder efforts to maintain system health and resolve issues promptly.

---v
Risk
- Difficulty in diagnosing and resolving system issues, leading to extended downtime.
- Reduced ability to identify and mitigate security threats compromising network integrity.
---v
Case Study
- During recent Kusama issue, the chain stopped block production for some hours.
- Engineers needed to check all the logs to understand what caused it or what triggered the incident.
- Logging system allowed them to detect that the cause was a dispute in a finalized block.

- Consensus systems are complex and almost never halt, but when they do, it is difficult to recreate the scenario that led to it.
- A good logging system can therefore help to reduce downtime.
---v
Mitigation
- Regularly review logs to identify any suspicious activity, and determine if there is sufficient verbosity.
- Implement logs in the critical parts of your pallets.
- Implement dashboards to detect anomaly patterns in logs and metrics. A great example is Grafana that is used by some node maintainers to be aware of recent issues.
---v
Takeaways
- Logs are extremely important to diagnose and resolve system issues.
- Insufficient verbosity can lead to extended downtime.
Inconsistent Error Handling
---v
Challenge
- Errors/exceptions need to be handled consistently to avoid attack vectors in critical parts of the system.
- While processing a collection of items, if one of them fails, the whole batch fails. This can be exploited by an attacker that wants to block the execution. This can become a critical problem if the processing is happening in a privileged extrinsic like a hook.

---v
Risk
- Privileged extrinsics Denial of Service (DoS).
- Unexpected behavior in the system.
---v
Case Study - Decode Concatenated Data - Issue
#![allow(unused)] fn main() { fn decode_concatenated_extrinsics( data: &mut &[u8], ) -> Result<Vec<<T as Config>::RuntimeCall>, ()> { let mut decoded_extrinsics = Vec::new(); while !data.is_empty() { let extrinsic = <T as Config>::RuntimeCall::decode_with_depth_limit( sp_api::MAX_EXTRINSIC_DEPTH, data ).map_err(|_| ())?; decoded_extrinsics.push(extrinsic); } Ok(decoded_extrinsics) } }
---v
Case Study - Decode Concatenated Data - Issue
#![allow(unused)] fn main() { fn decode_concatenated_extrinsics( data: &mut &[u8], ) -> Result<Vec<<T as Config>::RuntimeCall>, ()> { let mut decoded_extrinsics = Vec::new(); while !data.is_empty() { if let Ok(extrinsic) = <T as Config>::RuntimeCall::decode_with_depth_limit( sp_api::MAX_EXTRINSIC_DEPTH, data ) { decoded_extrinsics.push(extrinsic); } else { /// Handle corrupted extrinsic... } } Ok(decoded_extrinsics) } }
---v
Mitigation
- Verify the error handling is consistent with the extrinsic logic.
- During batch processing
-
If all items need to be processed always
Propagate directly the error to stop the batch processing.
-
If only some items need to be processed
Handle the error and continue the batch processing.
-
---v
Takeaways
- Ensure error handling.
- Optimize your batch processing to handle errors instead of losing execution time.
Questions
Formal Methods for Rust
How to use the slides - Full screen (new tab)
Introduction to Formal Methods for Rust
Outline
- Intro to Formal Methods
- Landscape of Techniques for Rust
- Focus on Kani: Bounded Model Checker
- Applications to Substrate
Introduction to Formal Methods
Story Time!
---v
Ariane 5 Rocket - Flight 501

- in 1996, the launcher rocket disintegrated 39 secs after take-off.
- Failure: An overflow, caused by a conversion from 64-bit to 16-bit floating point
- Mistake: reusing inertial reference platform of Ariane-4, where overflow cannot happen due to different operational conditions
- Cost:
$500M payload,$8B development program
Notes:
Link to article: (https://www-users.cse.umn.edu/~arnold/disasters/ariane.html)
---v
Software Correctness is very important
Program testing can be used to show the presence of bugs,
but never to show their absence!--Edgard Dijkstra--
Hence, the necessity to go beyond testing
---v
Formal Methods to the Rescue!
- Given a system (code) and Specification (behavior), verify/prove correctness with reasonable mathematical guarantees.
- Traditionally, costs and efforts were justifiable in safety-critical software like avionics, nuclear reactors, medical imaging, etc.
- however, things have changed ...
Notes:
this is how Formal Methods were motivated; to prove the absence of Bugs! A bit of fear-mongering in my opinion.
---v
It is no longer Rocket Science!
- AWS formally verifies Key-Value storage nodes in Amazon S3 (Rust Implementation).
- Meta detects resource leaks and race conditions in Android apps
- Uber uses static analysis to find Null-pointer exceptions
- Ethereum's Beacon chain and Tendermint consensus formally verified for safety and liveness guarantees
Notes:
- Personally think of formal methods as a more systematic way of detecting bugs.
- Ideally, verifying if your property holds on all possible inputs.
---v
Formal Methods Today
From being theoretical research interests
to delivering practical cost-effective tools
- goals more focused, promises less lofty
- verification tools more efficient
- combination of analysis techniques
Notes:
- Limiting attention to a particular class of bugs, resource leaks, data-races, etc.
- Drastic Speed-up in Underlying Constraint-Solver engines. For example, Z3 by microsoft, can solve constraints with billions of variables.
- Unified theory with blurring lines; Combining both static and dynamic techniques.
---v
More like Light-weight Formal Methods
- Rigorously detecting bugs → proving overall correctness of system.
- Developer-centric Usability (e.g. workflow integration)
Notes:
- Realized the importance of Developer experience.
- No more obscure logic that the developer has to learn to write specifications.
- You will see how intuitive it is to verify code.
---v
Formal Methods ↔ Blockchains
Hammer finally found the nail!
- Lot at stake, justifies the cost and efforts
- Business logic is compact and modular, within limits
Note:
- Reputation along with money at stake.
- A simple android app has 100k java classes. Techniques are not scalable on large codebases.
- Complexity of runtime business logic is magnitude lower. Lot of interest in Smart Contract verification.
- Check out Certora, Echidna, Securify, and more here
---v
Key Takeaways
Formal Methods are...
- Not a Panacea but can improve software quality
- Getting more and more accessible
- Useful for increasing reliability and security of blockchains
Notes:
- Great blog that explains the trade-offs between soundness and tractability
Tools Landscape

Notes:
Links to listed tools
---v
Tools Landscape
Quint/ State-Right (Model-checkers)
- Humongous effort modelling the system & specifying properties
- Abstraction gap
- Reason about complex properties: safety & liveness of consensus mechanism
Notes:
- Design-level, verifying protocol design.
- Always a discrepancy in your model and actual code.
- Safety: nothing bad ever happens; no two honest nodes agree on different state
- Liveness: something good eventually happens; eventually 2/3rds reach consensus
---v
Tools Landscape
Static Analyzers
- Code-level
- Information/ dataflow properties; access control for code;
- Specify expected behavior (properties). Roundtrip property: decode (encode (x)) == x
- Default checks: bugs like arithmetic overflow, out-of-bound access panics
Notes:
- Eg. for code access control: ensure that certain sensitive parts of runtime are only accessible by Root origin
- MIRAI is developed by Meta uses technique called abstract interpretation; specifically useful for detecting panics statically and information flow properties
- Kani: we will dive deeper soon
---v
Tools Landscape
Linters
- Code-level
- Checks for code smells
- Other syntactic Properties
Notes:
- Substrace is a linter specifically for Substrate
- Flowistry allows you to track dependency between variables; slices only the relevant portion for a given location.
Our Focus: Kani
Kani: Model Checking tool for Rust
- Open-source Rust verifier by AWS
- Underlying technique used: Bounded Model Checking
- Can be used to prove:
- Absence of arithmetic overflows
- Absence of runtime errors (index out of bounds, panics)
- User Specified Properties (enhanced PropTesting)
- Memory safety when using unsafe Rust
- Provides a concrete test-case triggering the bug if verification fails
Notes:
Link to Bounded Model Checking paper for interested folks here. For example when you are accessing/modifying mutable static variable
---v
Lets see some Magic first
Demo of the Rectangle-Example
---v
Proof Harness
#![allow(unused)] fn main() { use my_crate::{function_under_test, meets_specification, precondition}; #[kani::proof] fn check_my_property() { // Create a nondeterministic input let input = kani::any(); // Constrain it according to the function's precondition kani::assume(precondition(input)); // Call the function under verification let output = function_under_test(input); // Check that it meets the specification assert!(meets_specification(input, output)); } }
- Kani tries to prove that all valid inputs produce outputs that meet specifications, without panicking.
- Else, Kani generates a trace that points to the failure.
---v
Property: decode(encode(x)) == x
Test
#![allow(unused)] fn main() { #[cfg(test)] fn test_u32 { let val: u16 = 42; assert_eq!(u16::decode(&mut val.encode()[..]).unwrap(), val) } }
fixed value 42
Fuzzing
#![allow(unused)] fn main() { #[cfg(fuzzing)] fuzz_target!(|data: &[u8]|) { let val = u16::arbitrary(data); assert_eq!(u16::decode(&mut val.encode()[..]).unwrap(), val) } }
multiple random values of u16
Kani Proof
#![allow(unused)] fn main() { #[cfg(kani)] #[kani::proof] fn proof_u32_roundtrip { let val: u16 = kani::any(); assert_eq!(u16::decode(&mut val.encode()[..]).unwrap(), val) } }
verifies exhaustively all values of u16
---v
Under the Hood: Bounded Model Checking
Idea:
- Search for counterexamples in (bounded) executions paths
- However, this search is an NP-hard problem
Method:
- Efficiently reduce problem to a Constraint Satisfaction (SAT) problem
- verification reduced to problem of searching satisfiable assignment to a SAT formula.
- leverages highly optimized SAT solvers making the search tractable.
Notes:
Kani uses miniSAT as the backend engine; a lot of other verification tools use Z3 solver.
---v
Translation to constraints
Code
#![allow(unused)] fn main() { fn foo(x: i32) -> i32 { let mut y: i32 = 8; let mut w: i32 = 0; let mut z: i32 = 0; if x != 0 { z -= 1; } else { w += 1; } assert!(z == 7 || w == 9); w+z } }
Constraints
#![allow(unused)] fn main() { y = 8, z = x? y-1: 0, w = x? y+1: 0, z != 7 /\ w != 9 (negation of the assert condition) }
- Constraints fed into a Solver (minisat)
- For no value of
xthe constraints hold $\implies$ Assert conditions verified - Else the solver found a failing test (counterexample)
---v
How does it handle loops?
- Bounded in BMC to the rescue!
- Loops are unwound up to a certain bounded depth $k$, else the verification does not terminate.
- Determining the sweet-spot $k$ is a trade-off between tractability and verification confidence .
---v
Demo: Unwinding Loops
#![allow(unused)] fn main() { fn initialize_prefix(length: usize, buffer: &mut [u8]) { // Let's just ignore invalid calls if length > buffer.len() { return; } for i in 0..=length { buffer[i] = 0; } } #[cfg(kani)] #[kani::proof] #[kani::unwind(1)] // deliberately too low fn check_initialize_prefix() { const LIMIT: usize = 10; let mut buffer: [u8; LIMIT] = [1; LIMIT]; let length = kani::any(); kani::assume(length <= LIMIT); initialize_prefix(length, &mut buffer); } }
---v
Dealing with Loops: Summary
Process:
- Start with unwinding $k$ times
- If no bug is found, increase $k$ until either:
- A bug is found
- verifier times-out
- predetermined upper-bound $N$ for $k$ is reached
---v
Implementing Arbitrary for custom type
#![allow(unused)] fn main() { use arbitrary::{Arbitrary, Result, Unstructured}; #[derive(Copy, Clone, Debug)] pub struct Rgb { pub r: u8, pub g: u8, pub b: u8, } impl<'a> Arbitrary<'a> for Rgb { fn arbitrary(u: &mut Unstructured<'a>) -> Result<Self> { let r = u8::arbitrary(u)?; let g = u8::arbitrary(u)?; let b = u8::arbitrary(u)?; Ok(Rgb { r, g, b }) } } }
Exercise
Verify Fixed-width & Compact Encoding for integer types in SCALE.
Open Ended properties!
- RoundTrip:
Decode (Encode (x)) == x DecodeLength(x) == Decode(x).length()EncodeAppend(vec,item) == Encode(vec.append(item))- ......
Notes:
- Potentially, we might play around with a few of these properties during a workshop this weekend.
More Verification
Less Bugs
Contributor Guide
Thank you for interest in contributing to the Academy! ✨.
Before anything else, please read our Code of Conduct to understand our community's guidelines.
This guide is to help Academy contributors understand how all materials contained this repository are structured, how to interact with and modify them. Multiple tools are provided for contributors to make slideshows, leader-guided workshops, and self-directed activities.
Installation
The Academy is Rust heavy and as such, you need to install rust before anything else here.
In order to make your life easy 😉, there is a set of tasks that use cargo make.
With cargo make installed, you can list all tasks included to facilitate further installation, building, serving, formatting, and more with:
# Run from the top-level working dir of this repo
makers --list-all-steps
The tasks should be self-explanatory, if they are not - please file an issue to help us make them better.
# Install all dependencies
makers i
(Not advised) Manual Install
You may opt out of cargo make described, but minimally will need to hav:
Book - mdBook
Serve the book offline with:
# Run from the working dir of this repo
mdbook serve --open
Slides and Tooling - bun
Use bun to install and run the javascript and node tooling.
With bun installed, from the academy top level dir:
if ! $(echo "type bun" | sh > /dev/null ); then
echo "🥟 Installing https://bun.sh ..."
curl -fsSL https://bun.sh/install | bash
fi
echo "💽 Bun installed."
echo "🥟 Install slides tooling with Bun..."
bun install
echo "✅ Slides instalation complete!"
This should open a new browser tab with a simple listing of all slide decks to choose from.
Embedded Slides
At this time, there is a "hack" to get the slides embedded in the book, where the static HTML assets from a slides build are coppiced into the book so that they function in an iframe.
See the Makefile.toml for [tasks.serve] to see the commands required to manually get this working.
Again, it's much more convenient to use cargo make here vs. manually running this!
Content Design
The academy is focused on practical application of web3 concepts we cover, more than simply understanding.
Organization
The entirety of the book, including assets (images, code, etc.) needed in this book lives in ./content/*.
The directory structure is as follows:
content
├── <module>
├── index.md # Student facing module overview
├── faculty-guide.md # Faculty facing guide on running this module
├── README.md -> index.md # Soft link `ln -s index.md README.md` - for Github web reading
│ ├── <lesson> # Lecture related, has slides
│ │ ├── img
│ │ │ ├── <media> # png, gif, mp4, jpg, etc. used in *this lesson*
│ │ │ ├── ...
│ │ ├── page.md # Typically a stub file for embedding `slides.md`
│ │ └── slides.md # A `reveal-md` formatted document
│ ├── _materials # Workshop, Exercise, or Activity related
│ │ ├── img
│ │ │ ├── <media> # png, gif, mp4, jpg, etc. used in *this lesson*
│ │ │ ├── ...
│ │ ├── <material>.md # Student facing instructions on some material
. . . ...
<module>/README.md- required soft link toindex.md.<module>/index.md- required book page, must be listed inSUMMARY.md.<module>/faculty-guide.md- required page not used in the book, must NOT be listed inSUMMARY.md.<module>/<lesson>/page.md- required book page, must be listed inSUMMARY.md.<module>/<lesson>/slides.md- optional slides, embedded into apage.md, must be embedded intopage.mdif slides are used.<module>/<lesson>/img- optional directory with media used in slides or pages in this lesson.<module>/<lesson>/_materials- optional directory with inclusions referenced in slides or pages
Development Workflow
Typically, most work for lessons centers on the development of slides. The pages they are embedded into are primarily static stubs to host the slides within. Workshop and Activity pages are an exception, where they do not usually have slides associated, or need more information outside slides. Viewing the rendered markdown of slides is more important than when iterating on pages, in practice.
Working on Slides with reveal-md
Slides include primarily lecture materials used to present in class, and those slides must contain Notes: sections with detailed student facing information about what is covered on a slide, not only speaker-facing notes!
Typically the slide notes should embed all the references, resources, and further considerations for students to have as a resource during and after class.
To view and edit slides (only) in watching mode (updates immediately on changes to any file changes in the content):
# WATCHING server for slides only
makers serve-slides
# Or simply:
bun s
See the Using this Book page for more details on reveal.js features and use.
If this is your first time using reveal.js, we encourage you to explore the official demo to see what sort of things you can do with it!
We are creating and customizing slides with reveal-md: a tool built with reveal.js to allow for Markdown only slides, with a few extra syntax items to make your slides look and feel awesome with as little effort as possible on style and visual design.
Copy & Paste Slides
The Copy and Paste Slide Templates page and source for the embedded slideshow demonstrate use and code snippets to accommodate many common slide archetypes. It should be possible to modify examples in your slides from these templates, including:
- Multi-column slides
- Embedded media
- Diagrams (mermaid, and more)
Working on Pages with mdBook
Pages embed slides, and may include links to materials, references and other things when it's impractical to include it within speaker notes for slides. Most pages are just "stub" files to embed the slides into.
To work on both the embedded slides and the book in tandem in non-watching mode:
makers s # Build the slides (clobbering those tracked by the book repo in `./slides`), embed in the book, view the updated book.
# ... Make changes to the book and/or the slides ...
# ... kill the server with `ctrl+c` ...
makers s # Build the slides (clobbering those tracked by the book repo in `./slides`), embed in the book, view the updated book.
😭 At this time, this is a non-watching server, you must manually open the page and hard refresh pages served before to see them updated.
You must rerun this command to update on file changes!
Lesson Template
Head over to the Lesson Template page, and carefully read through the source before you continue. The entire directory is intended to be copied & pasted into the correct module to kickoff new lesson development:
# Copy this whole thing 👇😀
└── template
├── img
│ └── REMOVE-ME-example-img.png
├── page.md
└── slides.md
The page.md file should _embed the slides.html page that isn't going to work until the build process creates it, but it will exist once that happens & render 😉.
File Size Considerations
We strive to not overload this book with excessively large assets, to that end we ask that all contributors before committing to this repo any assets:
- Review image file size & compress minimal possible looking OK-ish full screen, or use smaller alternatives.
Example:
# Compress with imagemagick convert <INPUT_FILE> -quality 20% <OUTPUT_FILE> - Scale down all videos to minimal possible looking OK-ish full screen.
Example:
# What is the bitrate? ffmpeg -i <INPUT_FILE> 2> >(grep -i bitrate) # Reduce bitrate, iterate to find the *good enough* one for minimal size ffmpeg -i <INPUT_FILE> -b 400k <OUTPUT_FILE>
Refactoring Considerations
🚧 This workflow is not _normally_ needed by most contributors. Click to view anyway 🚧
We opt out of the handy helper to create missing files if linked in SUMMARY.md, as this indicates something is likely amis in our translation of slides -> stub pages mapping correctly.
This is useful to turn back on when radically updating the slides path structure and/or file names as changes must be manually applied otherwise to link to the correct new location in /slides/.../*-slides.html
You can opt in by editing book.toml:
[build]
- create-missing = false # do not create missing pages
+ create-missing = true # create missing pages
Tips on the Embedded Slides
All modules are of the structure described in the Content Organization section.
All slides.md files are the source of the associated slide content for that the page.md files that embed them in the book itself.
The page.md files are typically just stubs, but do the option to add more details, instructions, etc.
They typically are identical to:
# SOME TITLE HERE
<!-- markdown-link-check-disable -->
<center>
<iframe style="width: 90%; aspect-ratio: 1400/900; margin: 0 0; border: none;" src="slides.html"></iframe>
<br />
<a target="_blank" href="../../contribute/how-to/page.md#-how-to-use-revealjs-slides"><i class="fa fa-pencil-square"></i> How to use the slides</a> -
<a target="_blank" href="slides.html"><i class="fa fa-share-square"></i> Full screen (new tab)</a>
<br /><br />
<div ><i class="fa fa-chevron-circle-down"></i> Raw Slides Markdown</div>
<br />
</center>
{ {#include slides.md} } <!-- 👈 REMOVE the spaces in curly brackets ( {{include things}} ) when in use -- mdBook gives a build error without mangling the syntax here in the example 😜 -->
<a href="#top" style="position: fixed; right: 11%; bottom: 3%;"><i style="font-size: 1.3em;" class="fa fa-arrow-up"></i></a>
<!-- markdown-link-check-disable -->
find . -name 'page.md' -exec bash -c 'cat ../tmp >> "{}"' \;to apply the page stuff to embed slides
⏰ Critical Considerations
- Always use proper MarkDown links!
<https://parity.io>is required, raw links will not be rendered in mdBook! - Never use links that are likely ephemeral and will break.
This example is in main, not some PR branch: https://github.com/paritytech/polkadot-sdk/blob/5174b9d/polkadot/roadmap/implementers-guide/src/node/backing/prospective-parachains.md
You must be permalinks to a commit hash when using a github link, not
mainor other branch. - Reuse images and have no duplication of any images, with close enough ones considered to replace where possible.
Relative paths are supported:
../../<other lesson>/img/<existing img>
Conventions and Helpers
This book, and all content within have style and typographic conventions that, where practical, have tooling to help everyone conform to them.
# This will install the tooling needed for formatting, linting, checkers, etc.
makers install-dev
Formatting
All Markdown, TOML, JSON, Typescript, and Javascript files in this repository are formatter with dprint.
The setting for this formatter are found in .dprint.json.
We use cargo make to run this:
# This will format all files SUPER FAST after the first run is cached
makers f
If (and only if) formatting breaks Markdown from rendering correctly, you may use <!-- prettier-ignore --> preceding a block in markdown to skip formatting like this:
<!-- prettier-ignore -->
```html
<pba-cols>
<pba-col>
### What's up, yo?
</pba-col>
<pba-col>
- Yo
- Yo
- Yo
</pba-col>
</pba-cols>
```
<!-- prettier-ignore-start -->
Some text
* other text
* testing
<!-- prettier-ignore-end -->
See the docs on Markdown for dprint for more.
Checking Links
To ensure all *.md and .html files contain no broken links within them, we use a the mlc link checker.
Run with:
# Link check all content files
makers l
# Link check a single file:
makers links-for <relative-link-to/the-top-working-dir/file.md>
# Link check a directory, recursively
makers links-for <./content/some-dir/inner-dir>
The checker configuration is set ine Makefile.rs task to see settings.
The .mlc.toml config file is used to globally ignore specific common URLs that throw errors, in error 😛...
at least it should, but is not working at this time.
Notice that ignored links must be check from time to time manually!
Thus don't use this unless explicitly needed, rather use a know good URL if at all possible, perhaps from the https://archive.org/web/
The same tool is also run by our CI on all files for all pushes to all branches.
See the .github/workflows/link-check.yml file in this repo for details.
You can ignore the link check for a
regexcompliant entry in:
.mlc.toml.github/workflows/check.ymlMakefile.rsEventually just
.mlc.tomlwill do.
Checking Images
In order to ensure that there are no issues with images in this book, we check for:
- Broken links to images that will not be found in the build.
- Orphaned image files - not linked to at all from the book.
# Link check all `<img ...>` tags
makers img
Please delete any assets you do not need, we can always git recover at a latter time to bring them back in 💽.
CI
.github/workflows/pages.yml- On any merge withmain, the CI is tasked with building the book and deploying a hosted version of it..github/workflows/check.yml- On any merge withmain, the CI is tasked with checking book for any issues with format, links, and images.
See .github/workflows/ in this repository for more details.
Other tasks mostly stand alone from the cargo make tooling suggested in development workflows at this time, but some require the bun tooling to properly build and test things.
Contributor Covenant Code of Conduct
Our Pledge
We as members, contributors, and leaders pledge to make participation in our community a harassment-free experience for everyone, regardless of age, body size, visible or invisible disability, ethnicity, sex characteristics, gender identity and expression, level of experience, education, socio-economic status, nationality, personal appearance, race, caste, color, religion, or sexual identity and orientation.
We pledge to act and interact in ways that contribute to an open, welcoming, diverse, inclusive, and healthy community.
Our Standards
Examples of behavior that contributes to a positive environment for our community include:
- Demonstrating empathy and kindness toward other people
- Being respectful of differing opinions, viewpoints, and experiences
- Giving and gracefully accepting constructive feedback
- Accepting responsibility and apologizing to those affected by our mistakes, and learning from the experience
- Focusing on what is best not just for us as individuals, but for the overall community
Examples of unacceptable behavior include:
- The use of sexualized language or imagery, and sexual attention or advances of any kind
- Trolling, insulting or derogatory comments, and personal or political attacks
- Public or private harassment
- Publishing others' private information, such as a physical or email address, without their explicit permission
- Other conduct which could reasonably be considered inappropriate in a professional setting
Enforcement Responsibilities
Community leaders are responsible for clarifying and enforcing our standards of acceptable behavior and will take appropriate and fair corrective action in response to any behavior that they deem inappropriate, threatening, offensive, or harmful.
Community leaders have the right and responsibility to remove, edit, or reject comments, commits, code, wiki edits, issues, and other contributions that are not aligned to this Code of Conduct, and will communicate reasons for moderation decisions when appropriate.
Scope
This Code of Conduct applies within all community spaces, and also applies when an individual is officially representing the community in public spaces. Examples of representing our community include using an official e-mail address, posting via an official social media account, or acting as an appointed representative at an online or offline event.
Enforcement
Instances of abusive, harassing, or otherwise unacceptable behavior may be reported to the community leaders responsible for enforcement at academy@polkadot.network. All complaints will be reviewed and investigated promptly and fairly.
All community leaders are obligated to respect the privacy and security of the reporter of any incident.
Enforcement Guidelines
Community leaders will follow these Community Impact Guidelines in determining the consequences for any action they deem in violation of this Code of Conduct:
1. Correction
Community Impact: Use of inappropriate language or other behavior deemed unprofessional or unwelcome in the community.
Consequence: A private, written warning from community leaders, providing clarity around the nature of the violation and an explanation of why the behavior was inappropriate. A public apology may be requested.
2. Warning
Community Impact: A violation through a single incident or series of actions.
Consequence: A warning with consequences for continued behavior. No interaction with the people involved, including unsolicited interaction with those enforcing the Code of Conduct, for a specified period of time. This includes avoiding interactions in community spaces as well as external channels like social media. Violating these terms may lead to a temporary or permanent ban.
3. Temporary Ban
Community Impact: A serious violation of community standards, including sustained inappropriate behavior.
Consequence: A temporary ban from any sort of interaction or public communication with the community for a specified period of time. No public or private interaction with the people involved, including unsolicited interaction with those enforcing the Code of Conduct, is allowed during this period. Violating these terms may lead to a permanent ban.
4. Permanent Ban
Community Impact: Demonstrating a pattern of violation of community standards, including sustained inappropriate behavior, harassment of an individual, or aggression toward or disparagement of classes of individuals.
Consequence: A permanent ban from any sort of public interaction within the community.
Attribution
This Code of Conduct is adapted from the Contributor Covenant, version 2.1, available at https://www.contributor-covenant.org/version/2/1/code_of_conduct/.
Community Impact Guidelines were inspired by Mozilla's code of conduct enforcement ladder.
For answers to common questions about this code of conduct, see the FAQ at https://www.contributor-covenant.org/faq/. Translations are available at https://www.contributor-covenant.org/translations/.
Lecture Template Slides
How to use the slides - Full screen (new tab)
Lecture Title
Outline
Pre-requisites
No background in X is necessary.
However, the following are expected:
- Y
- Z
- \(\alpha\)
At the end of this lecture, you will be able to:
- Describe ...
- Navigate ...
- Justify ...
Major Topic A
- Use some bullets
- To make a few points
More context here.
And even more here... and more and more...
Notes:
Speaker view ONLY notes
An Important Point
Make it clear
Notes:
Stuff you should remember to say
Some Image

Notes:
Image source: (some URL here!)
License: (some URL, annotated with the know license of this img. Eg: [CC BY-NC 4.0](https://creativecommons.org/licenses/by-nc/4.0/) - if unknown please mark UNKNOWN here)
Some Shared Image

Notes:
Exercise Title
Describe it here
Exercise Instructions
- Uno
- Dos
- Tres
Notes:
Make sure to include things here to say to students, perhaps a hint or two. Realize that students will be able to view the speaker's notes, as they will have access to them on their devices.
Conclusion
Questions
Next Steps
- Eins
- Zwei
- Drei
References
Copy and Paste Slide Templates
How to use the slides - Full screen (new tab)
Copy and Paste Slide Templates
At the end of this lecture, you will be able to:
- Describe ...
- Navigate ...
- Justify ...
Here is a topic
- Use some bullets
- To make a few points
Notes:
Speaker view ONLY notes
Here is an important point
Make it clear
Notes:
Stuff you should remember to say
Code Highlight & Transitions
Syntax for many langs is possible, and very easy to style. You can and should use highlighting of lines in a large snippets of code.
You an also add comments to make "fragments" for specific components
They can ordered how you see fit!
See the source for syntax
Rust Example
#![allow(unused)] #![cfg_attr(not(feature = "std"), no_std)] fn main() { // `construct_runtime!` does a lot of recursion and requires us to increase the limit to 256. #![recursion_limit = "256"] // Make the Wasm binary available. #[cfg(feature = "std")] include!(concat!(env!("OUT_DIR"), "/wasm_binary.rs")); mod weights; pub mod xcm_config; /// BlockId type as expected by this runtime. pub type BlockId = generic::BlockId<Block>; /// The SignedExtension to the basic transaction logic. pub type SignedExtra = ( frame_system::CheckNonZeroSender<Runtime>, frame_system::CheckSpecVersion<Runtime>, frame_system::CheckTxVersion<Runtime>, frame_system::CheckGenesis<Runtime>, frame_system::CheckEra<Runtime>, frame_system::CheckNonce<Runtime>, frame_system::CheckWeight<Runtime>, pallet_transaction_payment::ChargeTransactionPayment<Runtime>, ); /// Unchecked extrinsic type as expected by this runtime. pub type UncheckedExtrinsic = generic::UncheckedExtrinsic<Address, Call, Signature, SignedExtra>; /// Extrinsic type that has already been checked. pub type CheckedExtrinsic = generic::CheckedExtrinsic<AccountId, Call, SignedExtra>; /// Executive: handles dispatch to the various modules. pub type Executive = frame_executive::Executive< Runtime, Block, frame_system::ChainContext<Runtime>, Runtime, AllPalletsWithSystem, >; }
Design system examples
Use o to open the overview mode and explore slides here.
You can see the source of these slides to copy&paste
as slide templates in your slides!
- Columns
- Images
- MarkDown examples
Two Column
Center 1
Using
<pba-col center>
Center 2
Using
<pba-col center>
---v
Two Column
<pba-cols>
<pba-col center>
### Center 1
Using<br />`<pba-col center>`
</pba-col>
<pba-col center>
### Center 2
Using<br />`<pba-col center>`
</pba-col>
</pba-cols>
Three Columns
Left
Using
<pba-col left>
Center
Using
<pba-col center>
Right
Using
<pba-col right>
---v
Three Columns
<pba-cols>
<pba-col left>
### Left
Using<br />`<pba-col left>`
</pba-col>
<pba-col center>
### Center
Using<br />`<pba-col center>`
</pba-col>
<pba-col right>
### Right
Using<br />`<pba-col right>`
</pba-col>
</pba-cols>
This column has a bit of a statement to make.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit
- Ut enim ad minim veniam, quis nostrud exercitation
- Duis aute irure dolor in reprehenderit in
- Excepteur sint occaecat cupidatat non proident, sunt in
---v
<pba-cols>
<pba-col>
### This column has a bit of a statement to make.
</pba-col>
<pba-col>
- Lorem ipsum dolor sit amet, consectetur adipiscing elit
- Ut enim ad minim veniam, quis nostrud exercitation
- Duis aute irure dolor in reprehenderit in
- Excepteur sint occaecat cupidatat non proident, sunt in
</pba-col>
</pba-cols>
Images

Leave a note on why this one matters
Notes:
---v
<img rounded style="width: 50%" src="../template/img/REMOVE-ME-example-img.png" />
Graphics

svg, png, gif, ... anything that works on the web should work here! (Please do be mindful of file size, and minimize where practical)
Where possible use
svgor vector graphics... Consider using a mermaid diagram instead 🤩
Notes:
Image source: https://giphy.com/stickers/transparent-hU2uvl6LdxILQOIad3 License: https://support.giphy.com/hc/en-us/articles/360020027752-GIPHY-Terms-of-Service
---v
<img style="width: 20%" src="./img/makeitmove.gif" />
Video
mp4, webm, ... anything that works on the web should work here!
Please do be mindful of file size, and minimize and compress before committing!
Notes:
Video source: https://www.youtube.com/watch?v=oaidhA5eL_8 License: https://www.youtube.com/static?template=terms
---v
<video controls width="100%">
<source src="../../polkadot/light_clients/img/LightClients.mp4" type="video/mp4">
Sorry, your browser doesn't support embedded videos.
</video>
Section title
---v
<!-- .slide: data-background-color="#4A2439" -->
# Section title
A quote of myself, saying great stuff, as always.
Source: me™ at the last event
Testing bold and italic markdown texts!
Testing **bold** and *italic* markdown texts!
Rust Example
#![allow(unused)] #![cfg_attr(not(feature = "std"), no_std)] fn main() { // `construct_runtime!` does a lot of recursion and requires us to increase the limit to 256. #![recursion_limit = "256"] // Make the Wasm binary available. #[cfg(feature = "std")] include!(concat!(env!("OUT_DIR"), "/wasm_binary.rs")); mod weights; pub mod xcm_config; /// BlockId type as expected by this runtime. pub type BlockId = generic::BlockId<Block>; /// The SignedExtension to the basic transaction logic. pub type SignedExtra = ( frame_system::CheckNonZeroSender<Runtime>, frame_system::CheckSpecVersion<Runtime>, frame_system::CheckTxVersion<Runtime>, frame_system::CheckGenesis<Runtime>, frame_system::CheckEra<Runtime>, frame_system::CheckNonce<Runtime>, frame_system::CheckWeight<Runtime>, pallet_transaction_payment::ChargeTransactionPayment<Runtime>, ); /// Unchecked extrinsic type as expected by this runtime. pub type UncheckedExtrinsic = generic::UncheckedExtrinsic<Address, Call, Signature, SignedExtra>; /// Extrinsic type that has already been checked. pub type CheckedExtrinsic = generic::CheckedExtrinsic<AccountId, Call, SignedExtra>; /// Executive: handles dispatch to the various modules. pub type Executive = frame_executive::Executive< Runtime, Block, frame_system::ChainContext<Runtime>, Runtime, AllPalletsWithSystem, >; }
---v
## Rust Example
```rust [0|1,6|15-25|30-31]
#![cfg_attr(not(feature = "std"), no_std)]
// `construct_runtime!` does a lot of recursion and requires us to increase the limit to 256.
#![recursion_limit = "256"]
// Make the Wasm binary available.
#[cfg(feature = "std")]
include!(concat!(env!("OUT_DIR"), "/wasm_binary.rs"));
mod weights;
pub mod xcm_config;
/// BlockId type as expected by this runtime.
pub type BlockId = generic::BlockId<Block>;
/// The SignedExtension to the basic transaction logic.
pub type SignedExtra = (
frame_system::CheckNonZeroSender<Runtime>,
frame_system::CheckSpecVersion<Runtime>,
frame_system::CheckTxVersion<Runtime>,
frame_system::CheckGenesis<Runtime>,
frame_system::CheckEra<Runtime>,
frame_system::CheckNonce<Runtime>,
frame_system::CheckWeight<Runtime>,
pallet_transaction_payment::ChargeTransactionPayment<Runtime>,
);
/// Unchecked extrinsic type as expected by this runtime.
pub type UncheckedExtrinsic = generic::UncheckedExtrinsic<Address, Call, Signature, SignedExtra>;
/// Extrinsic type that has already been checked.
pub type CheckedExtrinsic = generic::CheckedExtrinsic<AccountId, Call, SignedExtra>;
/// Executive: handles dispatch to the various modules.
pub type Executive = frame_executive::Executive<
Runtime,
Block,
frame_system::ChainContext<Runtime>,
Runtime,
AllPalletsWithSystem,
>;
```
Column + Code
- Some
- Observations
- Others
fn largest_i32(list: &[i32]) -> i32 { let mut largest = list[0]; for &item in list { if item > largest { largest = item; } } largest } fn largest_char(list: &[char]) -> char { let mut largest = list[0]; for &item in list { if item > largest { largest = item; } } largest } fn main() { let number_list = vec![34, 50, 25, 100, 65]; let result = largest_i32(&number_list); println!("The largest number is {}", result); assert_eq!(result, 100); let char_list = vec!['y', 'm', 'a', 'q']; let result = largest_char(&char_list); println!("The largest char is {}", result); assert_eq!(result, 'y'); }
---v
<pba-cols>
<pba-col>
### Column + Code
- Some
- Observations
- Others
</pba-col>
<pba-col>
```rust [0|1,13|4-8]
fn largest_i32(list: &[i32]) -> i32 {
let mut largest = list[0];
for &item in list {
if item > largest {
largest = item;
}
}
largest
}
fn largest_char(list: &[char]) -> char {
let mut largest = list[0];
for &item in list {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let result = largest_i32(&number_list);
println!("The largest number is {}", result);
assert_eq!(result, 100);
let char_list = vec!['y', 'm', 'a', 'q'];
let result = largest_char(&char_list);
println!("The largest char is {}", result);
assert_eq!(result, 'y');
}
Tables
| Tables | Are | Cool |
|---|---|---|
| col 1 is | left-aligned | $1600 |
| col 2 is | centered | $12 |
| col 3 is | right-aligned | $1 |
| This row sure has a | lot of text so it | spaces the columns outs |
---v
| Tables | Are | Cool |
| ------------------- | :-----------------: | ----------------------: |
| col 1 is | left-aligned | $1600 |
| col 2 is | centered | $12 |
| col 3 is | right-aligned | $1 |
| This row sure has a | _lot_ of text so it | spaces the columns outs |
Math
KaTeX/LaTeX rendered within blocks with "$$" delimiters
$$J(\theta_0,\theta_1) = \sum_{i=0}$$
In line uses "\\(" and "\\)" to render: \(\alpha\beta\gamma\)
.
More info: https://revealjs.com/math/
Charts
A plugin for Reveal.js allowing to easily add charts using Chart.js.
There is a known bug:
Chart (meaning the < canvas > tag) needs to be in a full HTML slide (no md allowed); this means that the whole slide that contains a chart MUST be written in plain HTML.
---v
---v
The code
<canvas data-chart="line" style="height: 300px">
<!--
{
"data": {
"labels": ["January"," February"," March"," April"," May"," June"," July"],
"datasets":[
{
"data":[4,7,10,25,56,78,140],
"label":"Polkadot","backgroundColor":"#E6007A"
},
{
"data":[10,27,40,75,80,155,340],
"label":"Kusama","backgroundColor":"#000"
}
]
}
}
-->
</canvas>
---v
Bar chart with CSV data
---v
Previous slides' code:
<section style="margin-top: 100px">
<h5>Bar chart with CSV data</h5>
<div style="height:480px">
<canvas data-chart="bar">
January, February, March, April, May, June, July My first dataset, 65, 59, 80, 81, 56, 55, 40 My second dataset,
28, 48, 40, 19, 86, 27, 90
</canvas>
</div>
</section>
---v
Stacked bar chart from CSV file with JSON configuration
---v
Previous slide's code:
<section style="margin-top: 100px">
<h5>Stacked bar chart from CSV file with JSON configuration</h5>
<div style="height:480px">
<canvas data-chart="bar" data-chart-src="./data.csv">
<!--
{
"data" : {
"datasets" : [{ "backgroundColor": "#0f0" }, { "backgroundColor": "#0ff" } ]
},
"options": { "scales": { "x": { "stacked": true }, "y": { "stacked": true } } }
}
-->
</canvas>
</div>
</section>
Mermaid Diagrams
Mermaid lets you create diagrams and visualizations using text and code.
It is a JavaScript based diagramming and charting tool that renders Markdown-inspired text definitions to create and modify diagrams dynamically.
First of all lets see some examples of diagrams that Mermaid can show with its integration with revealJS;
---v
A Flowchart
---v
And its code
<diagram class="mermaid">
%%{init: {'theme': 'dark', 'themeVariables': { 'darkMode': true }}}%%
flowchart TD
A(Start) --> B{Is it?};
B -- Yes --> C(OK);
C --> D(Rethink);
D --> B;
B -- No ----> E(End);
</diagram>
---v
Entity relationship diagram
---v
And its code
<diagram class="mermaid">
erDiagram
Node ||--o{ Wallet : places_order
Wallet ||--|{ Account : owner
Node }|..|{ Some-IP : uses
</diagram>
---v
Sequence diagram
---v
And its code
<diagram class="mermaid">
sequenceDiagram
Alice->>John: Hello John, how are you?
John-->>Alice: Great!
Alice-)John: See you later!
</diagram>
---v
Class Diagram
---v
And its code
<diagram class="mermaid">
classDiagram
note "From Duck till Zebra"
Animal <|-- Duck
note for Duck "can fly\ncan swim\ncan dive\ncan help in debugging"
Animal <|-- Fish
Animal <|-- Zebra
Animal : +int age
Animal : +String gender
Animal: +isMammal()
Animal: +mate()
class Duck{
+String beakColor
+swim()
+quack()
}
class Fish{
-int sizeInFeet
-canEat()
}
class Zebra{
+bool is_wild
+run()
}
</diagram>
---v
State diagram (v2)
Still --> Moving
Moving --> Still
Moving --> Crash
Crash --> [*]
---v
And its code
<diagram class="mermaid">
stateDiagram-v2
[*] --> Still
Still --> [*]
Still --> Moving
Moving --> Still
Moving --> Crash
Crash --> [*]
</diagram>
---v
User Journey
---v
And its code
<diagram class="mermaid">
journey
title My working day
section Go to work
Make tea: 5: Me
Go upstairs: 3: Me
Do work: 1: Me, Cat
section Go home
Go downstairs: 5: Me
Sit down: 5: Me
</diagram>
---v
Gantt
---v
And its code
<diagram class="mermaid">
gantt
apple :a, 2017-07-20, 1w
banana :crit, b, 2017-07-23, 1d
cherry :active, c, after b a, 1d
</diagram>
---v
Pie Chart
---v
And its code
<diagram class="mermaid">
pie title Pets adopted by volunteers
"Dogs" : 386
"Cats" : 85
"Rats" : 15
</diagram>
---v
Git Graph
---v
And its code
<diagram class="mermaid">
gitGraph
commit
commit
branch develop
checkout develop
commit
commit
checkout main
merge develop
commit
commit
</diagram>
---v
Useful links
More help needed?
Please reach out to a contributor
Mozilla Public License Version 2.0
1. Definitions
1.1. “Contributor”
means each individual or legal entity that creates, contributes to the creation of, or owns Covered Software.
1.2. “Contributor Version”
means the combination of the Contributions of others (if any) used by a Contributor and that particular Contributor’s Contribution.
1.3. “Contribution”
means Covered Software of a particular Contributor.
1.4. “Covered Software”
means Source Code Form to which the initial Contributor has attached the notice in Exhibit A, the Executable Form of such Source Code Form, and Modifications of such Source Code Form, in each case including portions thereof.
1.5. “Incompatible With Secondary Licenses”
means
- that the initial Contributor has attached the notice described in Exhibit B to the Covered Software; or
- that the Covered Software was made available under the terms of version 1.1 or earlier of the License, but not also under the terms of a Secondary License.
1.6. “Executable Form”
means any form of the work other than Source Code Form.
1.7. “Larger Work”
means a work that combines Covered Software with other material, in a separate file or files, that is not Covered Software.
1.8. “License”
means this document.
1.9. “Licensable”
means having the right to grant, to the maximum extent possible, whether at the time of the initial grant or subsequently, any and all of the rights conveyed by this License.
1.10. “Modifications”
means any of the following:
- any file in Source Code Form that results from an addition to, deletion from, or modification of the contents of Covered Software; or
- any new file in Source Code Form that contains any Covered Software.
1.11. “Patent Claims” of a Contributor
means any patent claim(s), including without limitation, method, process, and apparatus claims, in any patent Licensable by such Contributor that would be infringed, but for the grant of the License, by the making, using, selling, offering for sale, having made, import, or transfer of either its Contributions or its Contributor Version.
1.12. “Secondary License”
means either the GNU General Public License, Version 2.0, the GNU Lesser General Public License, Version 2.1, the GNU Affero General Public License, Version 3.0, or any later versions of those licenses.
1.13. “Source Code Form”
means the form of the work preferred for making modifications.
1.14. “You” (or “Your”)
means an individual or a legal entity exercising rights under this License. For legal entities, “You” includes any entity that controls, is controlled by, or is under common control with You. For purposes of this definition, “control” means (a) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (b) ownership of more than fifty percent (50%) of the outstanding shares or beneficial ownership of such entity.
2. License Grants and Conditions
2.1. Grants
Each Contributor hereby grants You a world-wide, royalty-free, non-exclusive license:
- under intellectual property rights (other than patent or trademark) Licensable by such Contributor to use, reproduce, make available, modify, display, perform, distribute, and otherwise exploit its Contributions, either on an unmodified basis, with Modifications, or as part of a Larger Work; and
- under Patent Claims of such Contributor to make, use, sell, offer for sale, have made, import, and otherwise transfer either its Contributions or its Contributor Version.
2.2. Effective Date
The licenses granted in Section 2.1 with respect to any Contribution become effective for each Contribution on the date the Contributor first distributes such Contribution.
2.3. Limitations on Grant Scope
The licenses granted in this Section 2 are the only rights granted under this License. No additional rights or licenses will be implied from the distribution or licensing of Covered Software under this License. Notwithstanding Section 2.1(b) above, no patent license is granted by a Contributor:
- for any code that a Contributor has removed from Covered Software; or
- for infringements caused by: (i) Your and any other third party’s modifications of Covered Software, or (ii) the combination of its Contributions with other software (except as part of its Contributor Version); or
- under Patent Claims infringed by Covered Software in the absence of its Contributions.
This License does not grant any rights in the trademarks, service marks, or logos of any Contributor (except as may be necessary to comply with the notice requirements in Section 3.4).
2.4. Subsequent Licenses
No Contributor makes additional grants as a result of Your choice to distribute the Covered Software under a subsequent version of this License (see Section 10.2) or under the terms of a Secondary License (if permitted under the terms of Section 3.3).
2.5. Representation
Each Contributor represents that the Contributor believes its Contributions are its original creation(s) or it has sufficient rights to grant the rights to its Contributions conveyed by this License.
2.6. Fair Use
This License is not intended to limit any rights You have under applicable copyright doctrines of fair use, fair dealing, or other equivalents.
2.7. Conditions
Sections 3.1, 3.2, 3.3, and 3.4 are conditions of the licenses granted in Section 2.1.
3. Responsibilities
3.1. Distribution of Source Form
All distribution of Covered Software in Source Code Form, including any Modifications that You create or to which You contribute, must be under the terms of this License. You must inform recipients that the Source Code Form of the Covered Software is governed by the terms of this License, and how they can obtain a copy of this License. You may not attempt to alter or restrict the recipients’ rights in the Source Code Form.
3.2. Distribution of Executable Form
If You distribute Covered Software in Executable Form then:
- such Covered Software must also be made available in Source Code Form, as described in Section 3.1, and You must inform recipients of the Executable Form how they can obtain a copy of such Source Code Form by reasonable means in a timely manner, at a charge no more than the cost of distribution to the recipient; and
- You may distribute such Executable Form under the terms of this License, or sublicense it under different terms, provided that the license for the Executable Form does not attempt to limit or alter the recipients’ rights in the Source Code Form under this License.
3.3. Distribution of a Larger Work
You may create and distribute a Larger Work under terms of Your choice, provided that You also comply with the requirements of this License for the Covered Software. If the Larger Work is a combination of Covered Software with a work governed by one or more Secondary Licenses, and the Covered Software is not Incompatible With Secondary Licenses, this License permits You to additionally distribute such Covered Software under the terms of such Secondary License(s), so that the recipient of the Larger Work may, at their option, further distribute the Covered Software under the terms of either this License or such Secondary License(s).
3.4. Notices
You may not remove or alter the substance of any license notices (including copyright notices, patent notices, disclaimers of warranty, or limitations of liability) contained within the Source Code Form of the Covered Software, except that You may alter any license notices to the extent required to remedy known factual inaccuracies.
3.5. Application of Additional Terms
You may choose to offer, and to charge a fee for, warranty, support, indemnity or liability obligations to one or more recipients of Covered Software. However, You may do so only on Your own behalf, and not on behalf of any Contributor. You must make it absolutely clear that any such warranty, support, indemnity, or liability obligation is offered by You alone, and You hereby agree to indemnify every Contributor for any liability incurred by such Contributor as a result of warranty, support, indemnity or liability terms You offer. You may include additional disclaimers of warranty and limitations of liability specific to any jurisdiction.
4. Inability to Comply Due to Statute or Regulation
If it is impossible for You to comply with any of the terms of this License with respect to some or all of the Covered Software due to statute, judicial order, or regulation then You must: (a) comply with the terms of this License to the maximum extent possible; and (b) describe the limitations and the code they affect. Such description must be placed in a text file included with all distributions of the Covered Software under this License. Except to the extent prohibited by statute or regulation, such description must be sufficiently detailed for a recipient of ordinary skill to be able to understand it.
5. Termination
5.1. The rights granted under this License will terminate automatically if You fail to comply with any of its terms. However, if You become compliant, then the rights granted under this License from a particular Contributor are reinstated (a) provisionally, unless and until such Contributor explicitly and finally terminates Your grants, and (b) on an ongoing basis, if such Contributor fails to notify You of the non-compliance by some reasonable means prior to 60 days after You have come back into compliance. Moreover, Your grants from a particular Contributor are reinstated on an ongoing basis if such Contributor notifies You of the non-compliance by some reasonable means, this is the first time You have received notice of non-compliance with this License from such Contributor, and You become compliant prior to 30 days after Your receipt of the notice.
5.2. If You initiate litigation against any entity by asserting a patent infringement claim (excluding declaratory judgment actions, counter-claims, and cross-claims) alleging that a Contributor Version directly or indirectly infringes any patent, then the rights granted to You by any and all Contributors for the Covered Software under Section 2.1 of this License shall terminate.
5.3. In the event of termination under Sections 5.1 or 5.2 above, all end user license agreements (excluding distributors and resellers) which have been validly granted by You or Your distributors under this License prior to termination shall survive termination.
6. Disclaimer of Warranty
Covered Software is provided under this License on an “as is” basis, without warranty of any kind, either expressed, implied, or statutory, including, without limitation, warranties that the Covered Software is free of defects, merchantable, fit for a particular purpose or non-infringing. The entire risk as to the quality and performance of the Covered Software is with You. Should any Covered Software prove defective in any respect, You (not any Contributor) assume the cost of any necessary servicing, repair, or correction. This disclaimer of warranty constitutes an essential part of this License. No use of any Covered Software is authorized under this License except under this disclaimer.
7. Limitation of Liability
Under no circumstances and under no legal theory, whether tort (including negligence), contract, or otherwise, shall any Contributor, or anyone who distributes Covered Software as permitted above, be liable to You for any direct, indirect, special, incidental, or consequential damages of any character including, without limitation, damages for lost profits, loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses, even if such party shall have been informed of the possibility of such damages. This limitation of liability shall not apply to liability for death or personal injury resulting from such party’s negligence to the extent applicable law prohibits such limitation. Some jurisdictions do not allow the exclusion or limitation of incidental or consequential damages, so this exclusion and limitation may not apply to You.
8. Litigation
Any litigation relating to this License may be brought only in the courts of a jurisdiction where the defendant maintains its principal place of business and such litigation shall be governed by laws of that jurisdiction, without reference to its conflict-of-law provisions. Nothing in this Section shall prevent a party’s ability to bring cross-claims or counter-claims.
9. Miscellaneous
This License represents the complete agreement concerning the subject matter hereof. If any provision of this License is held to be unenforceable, such provision shall be reformed only to the extent necessary to make it enforceable. Any law or regulation which provides that the language of a contract shall be construed against the drafter shall not be used to construe this License against a Contributor.
10. Versions of the License
10.1. New Versions
Mozilla Foundation is the license steward. Except as provided in Section 10.3, no one other than the license steward has the right to modify or publish new versions of this License. Each version will be given a distinguishing version number.
10.2. Effect of New Versions
You may distribute the Covered Software under the terms of the version of the License under which You originally received the Covered Software, or under the terms of any subsequent version published by the license steward.
10.3. Modified Versions
If you create software not governed by this License, and you want to create a new license for such software, you may create and use a modified version of this License if you rename the license and remove any references to the name of the license steward (except to note that such modified license differs from this License).
10.4. Distributing Source Code Form that is Incompatible With Secondary Licenses
If You choose to distribute Source Code Form that is Incompatible With Secondary Licenses under the terms of this version of the License, the notice described in Exhibit B of this License must be attached.
Exhibit A - Source Code Form License Notice
This Source Code Form is subject to the terms of the Mozilla Public License, v. 2.0. If a copy of the MPL was not distributed with this file, You can obtain one at https://www.mozilla.org/en-US/MPL/2.0/.
If it is not possible or desirable to put the notice in a particular file, then You may include the notice in a location (such as a LICENSE file in a relevant directory) where a recipient would be likely to look for such a notice.
You may add additional accurate notices of copyright ownership.
Exhibit B - “Incompatible With Secondary Licenses” Notice
This Source Code Form is “Incompatible With Secondary Licenses”, as defined by the Mozilla Public License, v. 2.0.